给 unidbg 装上原生时间片:如何让模拟器真正跑起多线程
当你用 unidbg 模拟一个带 worker 线程池的 SO 时,worker 从不执行、futex wait 永远超时、最终输出不对——本文记录了从「不断打补丁」到「重构调度层」的全过程。
摘要
我们在逆向一个 SO 时发现,它内部包含一个 worker 线程池。Worker 需要和主线程交错执行才能完成业务。但 unidbg 默认的协作式调度模型依赖 safe-point 主动让出 CPU,worker 从来没有机会真正运行。
我们尝试了十几种补丁:时间片补丁、safe-point 补丁、futex 补丁、drain 窗口补丁——每一项局部都有效,但最终业务输出纹丝不动。
问题不在任何一个 patch 上,而在补丁所在的层。协作式调度模型从根本上缺少一样东西:可预期的指令级中断。
解决方案是在 Unicorn C 后端增加一个轻量的原生时间片 hook——每 N 条指令自动停下来,告诉 Java 层「我停了,原因是时间片耗尽」,然后由 Java 调度器根据任务状态决定下一个跑谁。核心 C 代码只有 30 行。
一、问题来源:SO 里的 worker 线程池
1.1 一个真实的逆向场景
在逆向某个 SO 时,我们发现它的核心逻辑依赖多线程协作:
主线程(producer)
↓ 入队工作项
共享队列
↓ 出队工作项
worker 线程池(3-5 个 consumer)
↓
执行业务回调 → 生产新 item → signal → 入队
主线程负责把工作项放入队列,worker 线程负责消费。消费者没有工作时通过 futex / pthread_cond_wait 挂起,生产者通过 pthread_cond_signal 唤醒它们。业务逻辑只有在 worker 消费了特定工作项之后才会被触发。
在真机上,操作系统调度器在线程之间公平分配 CPU 时间,这套模型完美运转。在 unidbg 上,所有代码共享同一个 CPU 核心,问题立刻暴露。
1.2 观察到的症状
| 症状 |
说明 |
pthread_create 返回了 tid |
线程确实创建了 |
| worker 从不执行 |
对应的函数从未被调用 |
futex wait 永远超时 |
FUTEX_WAIT 设了条件,但同一个地址上的 FUTEX_WAKE 要么不来,要么来的时候没有等待者 |
1.3 为什么是线程调度的问题
排查过程大致如下:
第一步:确认资源没问题。 文件系统、环境变量、JNI 回调路径全部正确,SO 确实读到了所有必要数据。
第二步:确认控制流没问题。 目标函数的调用链在 unidbg 和真机上完全一致,条件分支都走了正确的路径。
第三步:确认 worker 确实创建了。 pthread_create syscall 返回了正确的 tid,Java 层的线程对象也正确创建。
第四步:确认 worker 没有执行。 通过 Frida 在 worker 入口函数下断点,真机上断下来了,unidbg 上断不下来。
此时问题范围已经收窄到「线程创建了但没有被调度执行」。在单核模拟器上,这只能是调度模型的问题。
二、为什么现有补丁都无效
2.1 unidbg 的协作式调度模型
unidbg 的 UniThreadDispatcher 是一个协作式调度器。它的默认行为是:
1. 主线程开始执行
2. 主线程跑到一个 safe-point(syscall 入口、callback 返回等)
3. safe-point 代码把主线程 rotate 到队尾,尝试调度 worker
4. worker 跑一小段,进入下一个 safe-point
5. 回到步骤 2
这个模型在大部分场景下工作良好。但有两个根本性缺陷:
缺陷一:safe-point 依赖主动让出。 worker 想被调度,必须先跑到一个 safe-point。但如果 worker 代码在到达 safe-point 之前就进入了 futex wait——而主线程此时不在 WAKE 的代码路径上——worker 就会永远等在那里。
缺陷二:时间窗口不重叠。 真机上是并发的,WAIT 和 WAKE 在时间轴上天然重叠。在 unidbg 的串行模型下,要么先 WAKE(此时没有等待者),要么先 WAIT(此时没有人来 WAKE)。这个时间窗口错位在协作式调度下是常态,不是例外。
2.2 为什么打补丁无效:五条路线的逐一复盘
这一节不是流水账。我们把每条路线走到的边界说清楚——包括它为什么局部有效,以及它的天花板在哪里。
路线一:窗口式 drain
思路:在业务生命周期的特定节点(如"插件加载完成"、"某命令返回后"),一次性把 pending 队列里的 worker 全部拉起来跑一段。相当于在串行执行的主线上开了几个"排水窗口"。
为什么局部有效:如果 drain 窗口恰好开在主线程刚往共享队列里扔了工作项之后,worker 被唤醒后确实能消费那个工作项,输出会增加一小截。这是我们最早看到的"worker 终于动了"的现象。
为什么不够用:真实的多线程程序中,生产者和消费者的执行窗口天然重叠——主线程可能在 worker 还没来得及取走数据之前就已经修改了那块内存。而 drain 窗口是固定时间点,开早了 worker 还没准备好,开晚了主线程的上下文(寄存器、栈帧、TLS)已经变化,worker 拿到的状态不是正确的执行起点。
更根本的问题是:drain 是单次快照,不是调度策略。Worker 跑完一段进入 futex wait 之后,下一个 drain 窗口如果不来碰它,它就永远等在那里——而下一个 drain 窗口的开与不开,取决于主线程的控制流,不是 worker 的需求。
路线二:全局 handoff flag
思路:设一个布尔值 flag,每当业务逻辑到达某个关键点时设 flag,调度器主循环每次迭代检查这个 flag。如果 flag 为真,主动把当前任务切到队尾,调度下一个。
为什么局部有效:在那些"关键点"之后的下一次调度确实发生了——worker 获得了更多的执行机会。
为什么不够用:当业务逻辑中存在多个这样的关键点(service done、callback returned、handoff armed、clone first wait……),flag 的组合状态开始爆炸:
flag_A=true, flag_B=false → 行为 X
flag_A=false, flag_B=true → 行为 Y
flag_A=true, flag_B=true → 行为 ???
更危险的是:flag 是全局共享的,而业务逻辑是状态机。设 flag 的代码和读 flag 的调度代码不在同一个执行上下文里,race condition 从设计层面就存在。一旦出现"flag 刚被检查完但业务状态已变化",调度器会切到一个错误的上下文。
从实现层面说,handoff flag 本质上是在把"业务调度决策"编码到"调度器"里——两个本应正交的层被耦合在一起。维护成本随 flag 数量线性增长,行为不可预测。
路线三:safe-point yield
思路:在回调函数返回点、JNI 入口、syscall 入口等"安全位置"插入 yield,强制当前任务让出 CPU。
为什么局部有效:在有回调返回点的场景下,yield 确实让调度器有机会切到其他线程。
为什么不够用:这个路线的根本前提是 worker 必须首先到达某个 safe-point。但如果 worker 从一开始就没被调度过——也就是说它从未获得过 CPU 时间片——那 safe-point 永远不会触发。
在单核模拟器上,主线程一直在跑。只有当主线程主动让出(比如执行了一个 syscall 或触发了 hook),调度器才有机会切到 worker。而 safe-point yield 本身就是在等这个让出动作。这是一个循环依赖:worker 需要被调度才能到达 safe-point,但 safe-point 是触发调度的条件。
其次,safe-point 的位置取决于 native 代码结构,不是调度器能控制的。有些函数可能执行数千条指令才到达一个 syscall,中间的所有状态都是黑盒。
路线四:PC redirect
思路:在 code hook 里直接读取目标函数的地址,然后修改 PC(程序计数器)寄存器,让 CPU 跳转到目标函数去执行。
为什么局部有效:在纯计算场景下(比如让 worker 直接执行某个不依赖线程上下文的函数),PC redirect 能跑通,并产生输出。
为什么不够用:PC redirect 跳过去的函数,其执行依赖于完整的线程上下文:TLS 寄存器、栈指针、thread-local 变量。hook 执行的上下文里,这些值是不完整的或错误的。当目标函数内部调用了 pthread_create 或 futex_wait 时,这些调用会静默失败——函数返回了,但没有创建线程,没有正确的 errno,也没有更新任务队列。
更深层的问题是:PC redirect 跳进去的代码,在调度器眼里是"不存在的"。调度器不知道这个任务正在执行什么,它只是在某个 hook 回调里偷偷改了 PC 寄存器。一旦目标函数内部再触发一个 hook,调度器没有这个函数的栈帧信息,无法正确保存和恢复上下文。
路线五:单点 futex 修复
思路:针对某个具体的 futex 条件变量,分别修复 WAIT 和 WAKE 的实现,确保它们的语义正确。
为什么局部有效:针对那些已经被识别出来的关键条件变量(通过日志分析发现其 WAIT/WAKE 总是错位),逐个修复确实能让那一对 WAIT/WAKE 正确配对。
为什么不够用:futex 的语义要求 WAIT 和 WAKE 在时间窗口上必须重叠。修复一个条件变量只能解决这一对的问题,而一个 worker 线程池可能涉及数十个不同的条件变量。更关键的是,即使所有条件变量都各自配对正确了,主线程和 worker 线程的执行顺序仍然是由主线程控制的——worker 只是在"被唤醒"后才能跑,而不是"主动"获得 CPU。
而且,单点修复是在追赶症状。修复了 A 地址的 WAIT/WAKE,B 地址的问题可能就暴露出来了。这变成了一场永无止境的打地鼠游戏。
五条路线的共同教训
把它们放在一起看,问题的根源逐渐清晰:
| 路线 |
试图解决 |
实际假设 |
为什么站不住 |
| 窗口式 drain |
worker 执行机会 |
drain 窗口能对齐业务状态 |
drain 是快照,业务是流 |
| 全局 handoff flag |
调度时机 |
flag 组合状态可控 |
业务状态机 + 全局 flag = 组合爆炸 |
| safe-point yield |
worker 被调度 |
worker 能先到达 safe-point |
循环依赖:需要调度才能到 safe-point |
| PC redirect |
worker 执行入口 |
hook 上下文有完整 TLS |
PC redirect 绕过了任务调度上下文 |
| 单点 futex 修复 |
WAIT/WAKE 配对 |
只有这一个条件变量有问题 |
条件变量有 N 个,且执行顺序仍由主线程控制 |
每个补丁局部有效,但补丁之间没有统一的执行契约。 协作式调度失败的根本原因是:所有这些补丁都在回答"什么时候该切",但没有任何机制保证"什么时候能切"。没有可预期的指令级中断,所有的让出动作都是在猜——猜主线程什么时候会停,猜 worker 什么时候准备好,猜下一次 drain 窗口开的时候上下文还对不对。
三、解决思路:把「什么时候停」和「下一个跑谁」拆开
正确的做法是:让模拟器在每 N 条指令后自动停下来,把停止原因告诉 Java 层,然后由 Java 调度器根据任务状态决定下一个执行者。
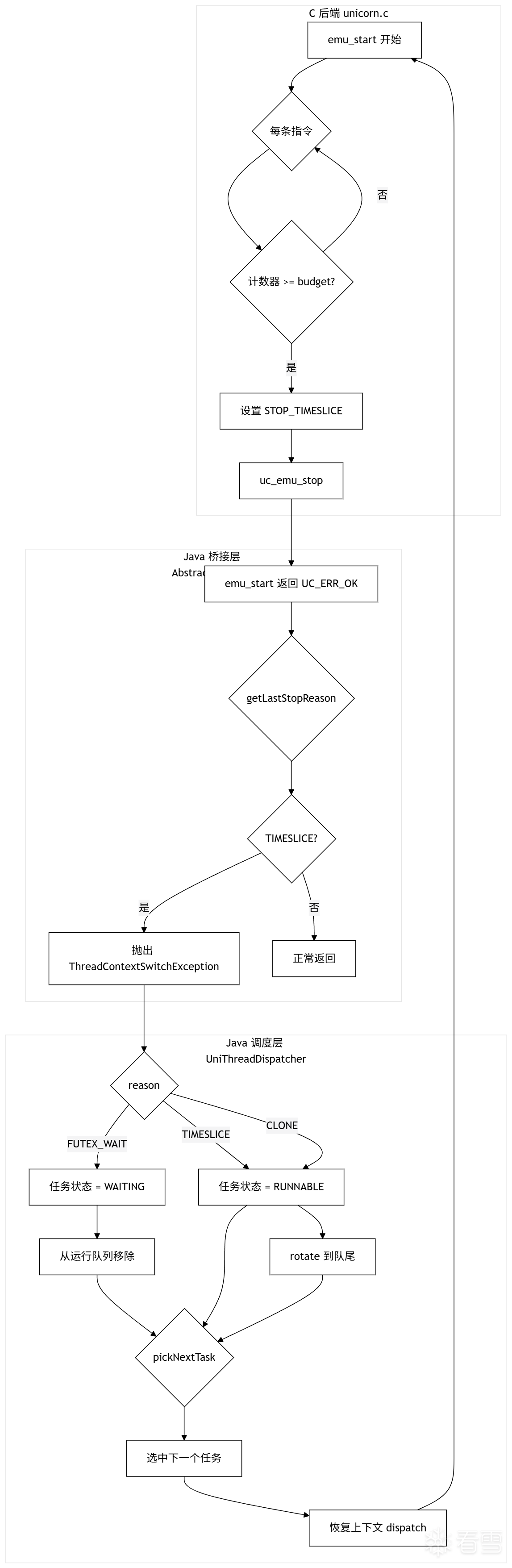
设计原则只有三条:
- C 层只做一件事:跑 N 条指令后停下来,告诉上层「为什么停」
- Java 调度器只做一件事:根据停止原因决定「下一个跑谁」
- 两层之间的接口只有一个枚举值 + 一个 PC 值
四、C 后端实现:30 行代码
4.1 停止原因枚举
public enum BackendStopReason {
NONE(0),
NORMAL(1),
TIMESLICE(2),
EMU_STOP(3),
FAULT(4);
}
有了明确的停止原因,Java 层不需要再猜「是正常返回还是预算耗尽」。
4.2 Backend 接口
public interface Backend {
BackendStopReason getLastStopReason();
long getLastStopPc();
void clearLastStopReason();
boolean supportsNativeTimeslice();
void configureNativeTimeslice(long instructionBudget);
void setNativeTimesliceEnabled(boolean enabled);
}
supportsNativeTimeslice() 让其他后端返回 false,完全不受影响。
4.3 时间片 hook(核心代码)
static void native_timeslice_cb(struct uc_struct *uc,
uint64_t address,
uint32_t size,
void *user_data) {
t_unicorn unicorn = (t_unicorn) user_data;
if (!unicorn->timeslice_enabled) return;
if (unicorn->timeslice_budget == 0) return;
if (++unicorn->timeslice_counter >= unicorn->timeslice_budget) {
unicorn->timeslice_counter = 0;
unicorn->last_stop_pc = address;
unicorn->last_stop_reason = STOP_TIMESLICE;
uc_emu_stop(uc);
}
}
这段代码的核心逻辑:每执行一条指令,计数器加一;达到预算时,设置停止原因,然后调用 uc_emu_stop() 让 Unicorn 停下来。
没有 JNI 调用,没有复杂的逻辑,只有两个条件判断和一个 uc_emu_stop()。在指令 hook 里调 JNI 会导致 GC 风险和性能损失,所以这里的做法是只设置 flag——Java 层在下一次 emu_start 返回后读取这些 flag。
4.4 emu_start 包装
JNIEXPORT void JNICALL
Java_com_github_unidbg_arm_backend_unicorn_Unicorn_emu_1start
(JNIEnv *env, jclass cls, jlong handle,
jlong begin, jlong until, jlong timeout, jlong count) {
t_unicorn unicorn = (t_unicorn) handle;
unicorn->timeslice_counter = 0;
unicorn->last_stop_reason = STOP_NONE;
uc_err err = uc_emu_start(eng, begin, until, timeout, count);
if (err != UC_ERR_OK) {
unicorn->last_stop_reason = STOP_FAULT;
throwException(env, err);
} else if (unicorn->last_stop_reason == STOP_TIMESLICE) {
return;
} else if (unicorn->last_stop_reason == STOP_EMU_STOP) {
return;
} else {
unicorn->last_stop_reason = STOP_NORMAL;
}
}
关键点:uc_emu_start 返回 UC_ERR_OK 时,不一定代表「正常执行完毕」——它也可能是因为时间片耗尽或者被显式停止。这段代码把两种情况区分开来,Java 层通过 getLastStopReason() 拿到真实原因。
4.5 为什么不用 Unicorn 自带的 count 参数
Unicorn 的 uc_emu_start 第四个参数就是指令计数预算。但它有一个致命缺陷:到达预算后 uc_emu_start 仍然返回 UC_ERR_OK,Java 层无法区分「正常执行到 until 地址」和「预算耗尽」。
我们的 hook 给出了一个确定的 TIMESLICE 原因,不需要从 PC 来反推。
五、Java 桥接层
在 AbstractEmulator.emulate() 中,时间片路径和旧路径并存:
boolean timesliceEnabled = enableNativeTimeslice();
BackendStopReason reason = BackendStopReason.NONE;
try {
backend.emu_start(begin, until, 0, 0);
} finally {
if (timesliceEnabled) {
reason = backend.getLastStopReason();
set(TIMESLICE_REASON_KEY, reason);
set(TIMESLICE_STOP_PC_KEY, backend.getLastStopPc());
disableNativeTimeslice();
}
}
if (timesliceEnabled && reason == BackendStopReason.TIMESLICE) {
set(EMU_TIMESLICE_KEY, Boolean.TRUE);
throw new ThreadContextSwitchException()
.setReason(ThreadContextSwitchException.Reason.TIMESLICE);
}
enableNativeTimeslice() 根据当前运行的任务类型选择 budget:
private long getTimesliceBudget() {
RunnableTask runningTask = threadDispatcher.getRunningTask();
boolean isWorker = runningTask instanceof Task
&& !((Task) runningTask).isMainThread();
return isWorker ? 12000L : 50000L;
}
默认值是 bootstrap 值,后续可以通过 instruction-count sampling 校准。
5.1 任务切换后的寄存器隔离:TPIDR 和 SP 的污染问题
时间片中断带来了协作式调度不会遇到的隐患:任务切换后,前一个任务的寄存器残留会污染下一个任务。
在真实的操作系统上,每个线程有独立的 TPIDR_EL0(线程本地存储寄存器)和栈指针,切换线程时硬件或内核自动保存/恢复。但在 unidbg 的单引擎模型下,所有任务共享同一个 CPU 寄存器组。调度器做 context save/restore 时,TPIDR_EL0 的恢复时机和 Native 代码的预期不一致——这会导致一个隐蔽的 bug。
问题现象:主线程执行某个命令时,读到了一个本属于 worker TLS 区域的地址。这说明主线程恢复执行时,TPIDR_EL0 仍残留着 worker 的 TLS 基址,而不是主线程自己的。
根因:调度器保存的是任务被时间片中断时的 PC/SP 等通用寄存器,但 TPIDR_EL0 是一个特殊的系统寄存器。在时间片耗尽的 hook 点,TPIDR_EL0 的值没有随着任务切换一起更新。当 worker park 后调度器切回主线程,主线程拿到的 TPIDR 仍是 worker 的。
这在单次调度时不会触发——第一次调度时 TPIDR 由线程初始化代码正确设置。但随着调度轮次增加,worker 和 main 反复切换,TPIDR 的残留值就会在某个时刻恰好被业务代码读取,产生错误的内存寻址。
修复方案分两处:
第一处:Native 入口显式写回 SP。 Function64 / NativeWorkerTask64 在每个 JNI/native 函数入口处,显式把当前入口的 SP(栈指针)写回到任务上下文。这确保了每次进入 native 代码时,栈指针是当前任务的正确值,而不是上一个任务残留的。
public void onNativeEntry(long sp) {
currentTask.setEntrySp(sp);
}
第二处:主线程 TPIDR 污染时恢复。 调度器在切回主线程时,检查 TPIDR_EL0 是否被 worker 污染。如果发现主线程的 TPIDR 指向了 worker TLS 区域,就从最早捕获的主线程 TPIDR 快照中恢复。
private void restoreMainTpidrIfPolluted() {
long currentTpidr = backend.reg_read(UC_ARM64_REG_TPIDR_EL0);
long mainBase = getMainTlsBase();
long workerBase = getWorkerTlsBase();
if (currentTpidr >= workerBase && currentTpidr < workerBase + TLS_SIZE) {
backend.reg_write(UC_ARM64_REG_TPIDR_EL0, mainTpidrSnapshot);
}
}
为什么这个 patch 不算"业务补丁":它修复的是调度基础设施的隔离性,不是某个业务函数的返回值或某个算法参数。任何使用 worker 线程池的 SO 在 unidbg 上跑,都可能遇到同样的 TPIDR 污染问题。这和修复某个 syscall 偏移或某个 JNI 函数路径属于同一层——都是让模拟器正确模拟 pthread runtime,而不是替 SO 算业务结果。
六、Java 调度器:任务状态机
6.1 状态定义
enum TaskState {
NEW,
RUNNABLE,
RUNNING,
WAITING,
FINISHED,
}
每个任务有一个元数据对象保存状态和统计信息:
static class TaskMeta {
TaskState state = TaskState.NEW;
ThreadContextSwitchException.Reason lastReason;
long lastPc, lastSp;
long slices;
}
6.2 调度主循环
private Number runWithTimeslice(long timeout, TimeUnit unit) {
long start = System.currentTimeMillis();
Task previous = null;
while (true) {
promoteRunnableThreads();
cleanupFinishedTasks();
if (taskList.isEmpty()) return null;
Task task = pickNextRunnableTask();
if (task == null) return null;
emulator.set(Task.TASK_KEY, task);
previous = task;
if (task.isContextSaved()) {
task.restoreContext(emulator);
}
this.runningTask = task;
Number ret = task.dispatch(emulator);
if (ret != null) {
task.destroy(emulator);
if (task.isMainThread()) return ret;
taskList.remove(task);
continue;
}
task.saveContext(emulator);
ThreadContextSwitchException.Reason reason = consumeEmuReason();
TaskMeta meta = getOrCreateTaskMeta(task);
meta.slices++;
if (reason == ThreadContextSwitchException.Reason.FUTEX_WAIT) {
meta.state = TaskState.WAITING;
taskList.remove(task);
} else {
meta.state = TaskState.RUNNABLE;
rotateTaskToEnd(task);
}
if (System.currentTimeMillis() - start >= timeout) {
return null;
}
}
}
关键设计:WAIT 状态的任务从 taskList 中移除,直到被 WAKE 重新唤醒。 这样调度器不会在一个永远阻塞的任务上浪费选择。
6.3 任务选择策略:FIFO + wake priority
private Task pickNextRunnableTask() {
for (Task t : taskList) {
TaskMeta meta = taskMetaMap.get(t);
if (meta != null && meta.lastReason == FUTEX_WAKE
&& meta.state == TaskState.RUNNABLE) {
meta.state = TaskState.RUNNING;
return t;
}
}
for (Task t : taskList) {
TaskMeta meta = getOrCreateTaskMeta(t);
if (meta.state == TaskState.RUNNABLE
|| meta.state == TaskState.NEW) {
meta.state = TaskState.RUNNING;
return t;
}
}
return null;
}
刚被唤醒的任务优先获得 CPU,这是 futex 语义的正确实现——WAKE 发生时应该立即执行等待者。
6.4 为什么不用优先级队列
因为真实的多线程程序中,worker 线程池通常按 FIFO 从队列取任务执行。用 FIFO + 一个 wake priority 标记,比多级优先级队列更容易调试,也更接近实际行为。
七、Futex 的正确实现
7.1 WAIT:不直接等待,而是标记状态
case FUTEX_WAIT: {
RunnableTask rt = emulator.getThreadDispatcher().getRunningTask();
if (old != val) {
return -UnixEmulator.EAGAIN;
}
if (rt != null) {
rt.setWaiter(emulator, new FutexNanoSleepWaiter(uaddr, val, ts));
throw new ThreadContextSwitchException()
.setReason(ThreadContextSwitchException.Reason.FUTEX_WAIT);
}
break;
}
这里的关键理解:throw 不是「立即切换线程」,而是「表明当前任务不可继续执行」。 ThreadContextSwitchException 从 emulate() 向上传播,dispatch() 返回 null,调度器在主循环中把任务标记为 WAITING。
7.2 WAKE:不直接跑 woken 任务,只做状态迁移
case FUTEX_WAKE: {
int woken = 0;
for (Task t : getAllTasks()) {
Waiter w = t.getWaiter();
if (w instanceof FutexWaiter && w.wakeUp(uaddr)) {
markTaskRunnable(t);
if (++woken >= val) break;
}
}
return woken;
}
markTaskRunnable 只是把任务状态从 WAITING 改为 RUNNABLE,加入可运行队列。不调用 emu_start,不尝试在 syscall handler 里启动任务调度。
这是最重要的设计决策之一。如果 WAKE 在 syscall handler 里直接 emu_start woken worker,就相当于在 syscall 里嵌套了一个 emu_start。Unicorn 不支持嵌套 emu_start,而且 hook 上下文里没有正确的 TLS 和 errno 状态——这正是之前大量补丁崩溃的根本原因。
八、验证结果
Phase A:C 后端 stop reason
[native_timeslice.backend] budget=1 reason=TIMESLICE pc=0x10000
[native_timeslice.backend] budget=50000 reason=NORMAL pc=0x1001c
Tests run: 3, Failures: 0, Errors: 0, Skipped: 0
BUILD SUCCESS
时间片耗尽时 stop reason 正确为 TIMESLICE,正常执行到 until 地址时为 NORMAL。
Phase B:Java 桥接层
[native_timeslice.bridge] backendReason=TIMESLICE
exceptionReason=TIMESLICE
savedContext=true stopPc=0x10000
[native_timeslice.bridge.off] ret=0x0 reason=NORMAL
Tests run: 2, Failures: 0, Errors: 0
BUILD SUCCESS
Backend 的 TIMESLICE reason 正确传递为 ThreadContextSwitchException,主线程正常返回时 reason 为 NORMAL。
Phase C:调度器 FIFO 轮转
[native_timeslice.pick] from=<none> to=main tid=2688 saved=false
[native_timeslice.slice] task=main tid=2688 reason=TIMESLICE
state=RUNNABLE slices=1 pc=0x10000 sp=0xbffff710
[native_timeslice.pick] from=main to=worker tid=2689 saved=false
[native_timeslice.slice] task=worker tid=2689 reason=TIMESLICE
state=RUNNABLE slices=1 pc=0x11000 sp=0xbffff710
[native_timeslice.scheduler] mainSaved=true workerSaved=true taskCount=2
[native_timeslice.pick] from=worker to=main tid=2688 saved=true
[native_timeslice.slice] task=main tid=2688 reason=TIMESLICE
state=RUNNABLE slices=2 pc=0x1003c sp=0xbffff710
Tests run: 3, Failures: 0, Errors: 0
BUILD SUCCESS
main 和 worker 交替被选中,FIFO 轮转生效,context save/restore 正确。
Phase D:线程创建
[native_timeslice.clone] tid=2690 parent=2688 fn=0x197438 arg=0x40296400
action=runnable lr=0x11000
[native_timeslice.pick] from=main to=worker tid=2690 saved=false
[native_timeslice.slice] task=worker tid=2690 reason=TIMESLICE
state=RUNNABLE slices=1
Tests run: 2, Failures: 0, Errors: 0
BUILD SUCCESS
pthread_create 创建的 child task 正确加入 runnable 队列,调度器在下一轮 pick 中选中它。
Phase E:Futex wait/wake 重叠
[native_timeslice.futex.wait] cmd=WAIT task=26880 uaddr=0x20000
val=0x2 old=0x2 timeoutMs=-1 action=park
[native_timeslice.futex.wake] cmd=WAKE uaddr=0x20000 val=0x1 woken=1
[native_timeslice.pick] from=main to=worker tid=26881 saved=false
[native_timeslice.futex.test] waitSaved=true wakeRet=1 canDispatch=true
Tests run: 2, Failures: 0, Errors: 0
BUILD SUCCESS
WAIT 正确 park 任务,WAKE 正确唤醒,调度器在下一轮 pick 中选中 woken worker——这是协作式调度下永远无法实现的 wait/wake 时间窗口重叠。
九、几个反直觉的设计决策
1. C hook 里绝对不能调 Java。
JNI 回调在每个指令 hook 上触发会导致数十倍的性能损失,而且 GC、死锁、JNI 引用管理在 hook 上下文里完全不可预测。设一个 flag、uc_emu_stop(),足够了。
2. 30 行 C 代码 ≠ 小改。
它改变的是信息传递方式:从「Java 层靠猜」,变成「C 层明确告诉 Java 为什么停」。这个接口契约变了,所有上层逻辑才能建立在这个确定性的基础上。
3. Phase gate 是防止调参循环的唯一手段。
没有分阶段验收,你很容易在 C 后端还没稳定时就跳去调业务参数,然后陷入「为什么还没好」的循环。用独立测试逐阶段验收,才能在每个阶段确认「这一层是对的」。
4. 时间片不是银弹。
它只解决「worker 能被调度」的问题。如果 worker 的业务逻辑本身有其他问题(比如 TLS 上下文错误、queue 消费路径有 bug),调度器帮不了你。
结语
打补丁打了两个月,始终差最后一层。最后意识到问题不是「怎么修这个 patch」,而是缺少一个干净的基础设施。
当你需要模拟一个内部包含 worker 线程池通过 futex 和队列协作的 SO 时,你不需要打几十个补丁。你只需要告诉调度器「每 N 条指令停一次」。
剩下的,交给任务状态机和 FIFO 轮转。
攻防不在明处——不在你看到的日志、下的断点、调通的 syscall,而在你看不见的地方:调度器的模型假设、hook 上下文的语义缺失、以及那些「局部有效但全局无效」的补丁之间的缝隙。承认自己的模型有天花板,比再打一个补丁要难得多。
本文适用于 unidbg 框架的 Unicorn2 后端。未涉及任何目标 SO 的内部函数名、偏移、数据布局或业务逻辑。如有侵权,请联系删除
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!





