-
-
[原创]2026腾讯游戏安全竞赛决赛安卓客户端安全分析
-
发表于: 2026-4-25 12:15 8704
-
1. 分析过程
2. 算法逻辑分析
3. 安全机制解析
4. 附录文件
第一,Godot 安卓题不能先押单线。初赛已经证明,只要一上来就认定“脚本一定是主线”或者“native 一定才是真核心”,后面就很容易在错误方向上投入过多时间。更稳的做法,是先把资源层、对象层、native 层都保留成候选入口,再让证据去决定谁先走。
第二,资源层可见不等于资源层可直接利用。初赛里已经反复遇到过这种情况:APK 里能看见 .gdc、场景文件、pack 文件,但它们并不等于可直接阅读的源码,也不等于真实执行时看到的那一份逻辑。这个经验直接影响了决赛的开局判断,也就是不能因为看到了 project.binary、assets.sparsepck、token.gdc 和 Trigger/*.gdc,就立刻把主战场押在资源恢复上。
第三,真实样本优先于完整理解。初赛里真正帮助主线快速收束的,从来不是先把所有文件都解释清楚,而是尽快拿到一组真实 token -> flag 或真实对象触发样本。因为只有样本到手之后,后面的脚本分析、native 还原、逆算法验证才有硬约束。这个经验到了决赛里依然成立,所以后面的路线才会不断强调“先撞到真块、先看到真输出、先抓到真样本”。
第四,动态窗口必须优先稳定。初赛已经说明,Godot 和 native 混合题如果动态窗口不稳定,后面的对象枚举、脚本实例化、运行时调用、VM trace 全都无从谈起。所以决赛一开始并不是先去深挖某个算法函数,而是先判断启动期和注册期的探针应该落在哪里,才能保证进程真的活着进入主场景。
也正因为有了这四条经验,决赛开局的判断顺序才会显得比较“克制”:先判断哪一层最有机会快速形成闭环,而不是看到哪一层信息多就一股脑扎进去。
从 APK 结构上看,题目同时给出了三类非常明显的入口信号:
因此最初并没有理由武断地认为“题目一定主要靠资源层”或者“题目一定主要靠 VM”。更合理的做法,是先把三层都保留成候选主线,再用证据决定谁先走。
决赛里最终形成的总体分工如下:
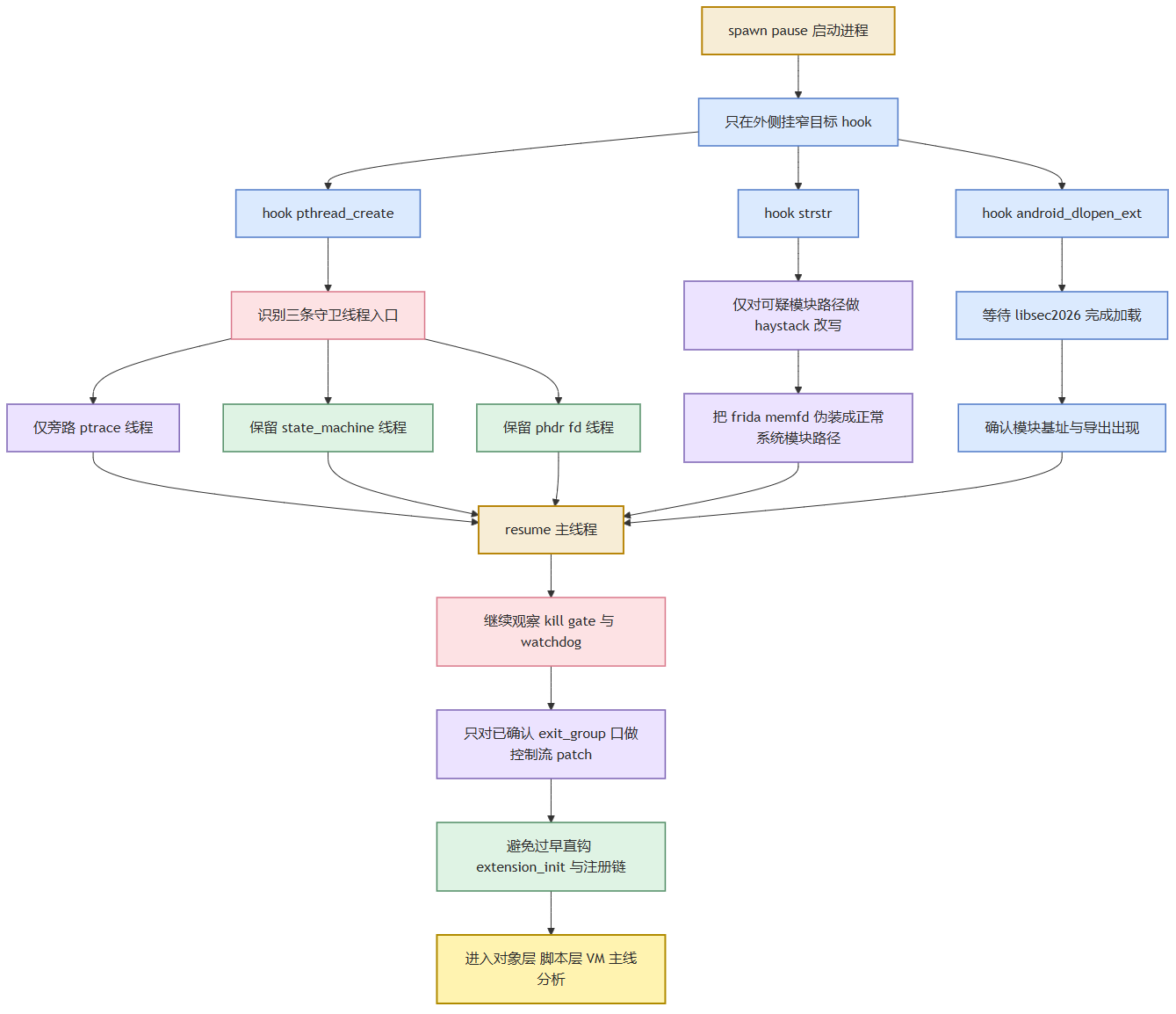
本题后续所有实机样本获取、对象层验证、脚本运行时调用和 VM 取证,都建立在启动窗口可稳定利用这一前提之上。因此在进入三个 Part 的具体逆向之前,需要先交代启动期反调试链是如何被压缩到可工作的分析窗口中的。只有这一窗口稳定下来,后面的截图、日志和运行时证据才具备可重复性。
最初的教训是:不要太早把 hook 压到库内直钩上。实际对照现象非常明显:
随后又通过线程级隔离实验确认:
这组实验把策略从“整条守卫线程静音”修正成了“只旁路纯反调试线程,保留兼带初始化职责的线程,只改它看到的危险输入”。这不是风格选择,而是被崩溃现象强制出来的工程结论。
后续之所以采用:
本质上就是因为前面的试错已经证明:如果想继续在真机上拿样本、截屏、dump 脚本对象、trace VM,就必须优先保证这条动态基线足够稳定。
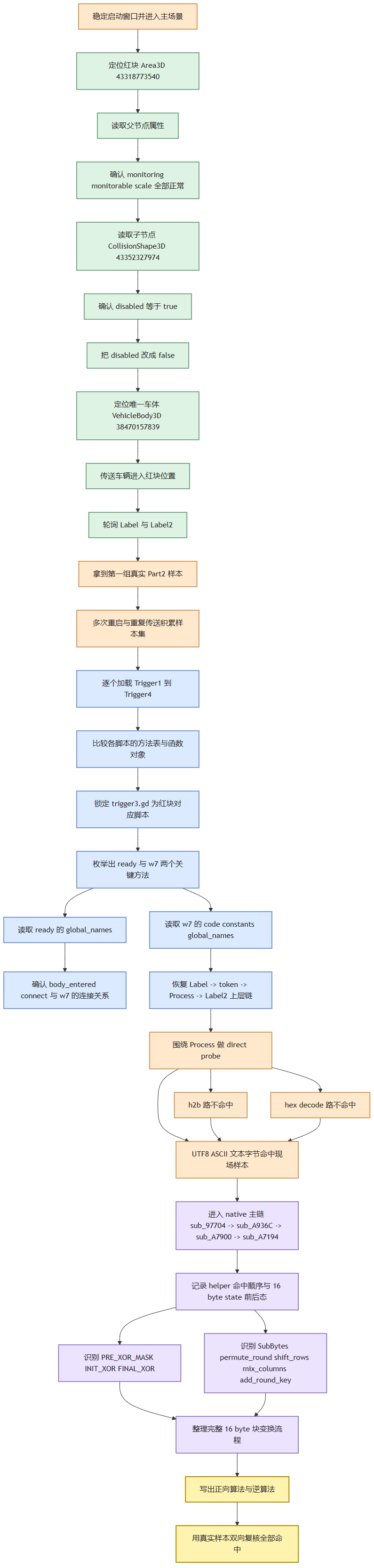
本题的总体推进顺序可以概括为下图。
因重要程度,反调试/反注入和详细的入口线程、关键字符串、kill gate 具体会在第三章说明,本章节只写逆向分析过程。稳定动态基线的关键是两步:
对应的关键运行日志如下,已经足够说明启动期模块白名单检查被压制,而进程不会立刻在 %resume 后死亡:
而在继续给 libc 的 exit / abort / __assert2 加观测后,又能看到进程终止前并不会命中这些高层终止接口:
这组对照意味着:后续所有算法分析都不是在“裸奔环境”里进行,而是在已经穿过启动期检测窗口之后进行的。也正因为如此,后续三条主线才能分别闭环,而不是反复卡死在 attach/spawn 阶段。
Part1 的关键并不是“先把 native VM 完全逆干净”,而是先确认绿色块到底走哪条真实生成链。这个判断在推进过程中经历过一次明显的路线修正。
最早的直觉是:题目既然显式带有 libsec2026.so 和 VMEntry,那绿色块很可能也会落进 native VM 主线。因此最初一段时间的工作重点,确实放在了:
但随着样本积累,这个判断被证据推翻了。后续主线改到脚本层,直接原因就是 trigger2.gd 的运行时调用结果与真实样本一致。
对象层先给出了第一批硬证据。我在外侧挂三类窄目标 hook:android_dlopen_ext 用来确认 libsec2026.so 何时加载,pthread_create 用来识别三条守卫线程并仅旁路 thread_ptrace_fork_watch,strstr 用来把 /memfd:frida-agent-64.so (deleted) 这类危险模块名伪装成正常系统模块路径。主线程 %resume 之后,再进入场景树枚举对象。用于稳定这个窗口的关键 Frida 代码如下:
在这个窗口稳定之后,主场景里可以直接枚举到四个关键 Area3D:
结合题面和后续实测,这四个对象分别对应:
这里还有一个很容易被忽略但实际非常重要的观察:绿色 Part1 方块的 y 值明显高于其他几个方块,达到 11.673913...。这和后续实机截图中“绿色方块在屋顶附近”的画面是互相吻合的。也就是说,绿色块不是“代码上能出分但玩家一定碰不到”的伪目标,而是一个可以直接通过对象层传送验证的真实得分点。
Part1 这条线的第一步动作不是先读脚本,而是先把车移动到绿色块,先确认题面的绿色目标在实机里到底会不会真正出分。场景树里只有一个可控车体,运行时对象为 VehicleBody3D id=38470157839,初始位置约为 (7.119446, 3.489174, -16.001696);绿色块 Area3D id=43251664672 的位置约为 (-14.960197, 11.673913, -3.083051)。因此对象层的第一步,就是把这辆车直接传送到绿色块上方一点,再轮询左上角 Label 和右上角 Label2。
frida代码如下:
也就是先通过 set(global_position) 把唯一车体放到绿色块附近,再立即回读位置,确认对象层传送已经生效。完成这一步后,轮询左上角 Label 和右上角 Label2,就能直接拿到第一组绿色块真样本:
这一步先把对象层的三个关键事实固定了下来:
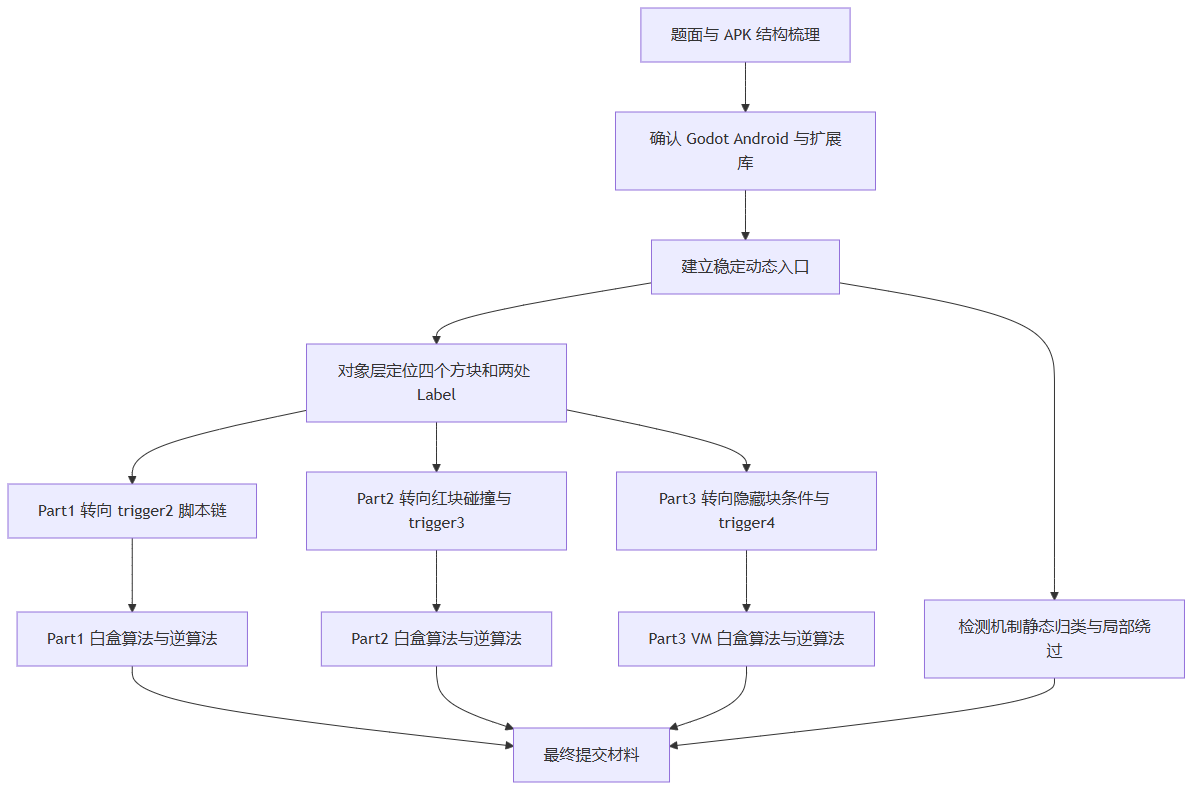
实机截图也对应了同一条对象层链路。下图是绿色块 Part1 命中截图,可以看到左上角是实时 Token: 4a23ab75,右上角已经显示 flag{sec2026_PART1_203703fc},说明绿色块现场输出和后续恢复出来的脚本算法是一致的。
在对象层拿到绿色块真样本之后,再回到资源层补脚本归属。trigger2.gd 在运行时可以被 ResourceLoader 直接加载、实例化,并且方法列表中能稳定看到以下辅助函数:
这一组命名已经非常关键,因为它同时覆盖了:
这说明 trigger2.gd 并不是简单触发器,而是已经带有完整的脚本级算法管线。
与之形成对照的是 token.gd。运行时日志显示,token.gd 的方法表只有 _mk 和 _ready 两个核心方法,并且直接调用 _mk(8) 会返回形如 52303553 这类 8 位 token。它说明 token.gd 负责的是“左上角 token 从哪里来”,而不是“右上角 Part1 怎么算”。这一步在过程里也很关键,因为它帮助我们把“token 生成脚本”和“flag 生成脚本”明确分开,避免把两条职责不同的脚本误混在一起。
确认 trigger2.gd 之后,下一步并不是继续猜 _fe 里面做了什么,而是先在运行时直接把这个方法调起来,看它到底是不是右上角那条真实 flag 链。这里采用的是 Godot 自身的 ResourceLoader -> script.new() -> Variant.call() 路线,而不是去手工构造 Java 层假对象。
frida关键代码如下:
如果 _fe 真的是 Part1 主入口,那么它对真实 token 的返回值就应该直接等于现场右上角看到的 Part1 结果;如果它不是,那这些返回值最多只会是中间态,而不会直接命中最终 flag。
返回如下:
从这个结果可以直接得到三件事:
在 _fe 被确认后,后续工作就从“猜它做了什么”切换成“把它拆干净”。这里没有直接去看 native,而是继续沿 Godot 运行时对象本身往前推:既然 trigger2.gd 的方法表里已经有 _h2b / _rf / _xb / _b2h,那么最稳的做法就是把这些 helper 一个个直接调出来。
对应的 Frida 调用方式如下:
首先,脚本中的固定 key 被直接读到:
其次,_h2b / _rf / _xb / _b2h 这条管线也能被逐段验证:
结合这些运行时返回值,可以把 Part1 的脚本级结构先写成下面这版伪代码:
因此 Part1 的核心为 8 轮 Feistel 结构。
再往前一步看,这条 helper 链本身也非常有“脚本级后处理”的特征:
虽然 Part1 的主入口已经确认是 _fe,但 native GameExtension.Process 不能完全略过,因为它正好对应分析过程中一条必须被排除掉的误判路线。当时需要明确区分的是:Part1 到底是不是“token 直接进 native -> native 直接出最终后缀”。
为此,在同一批运行时对象上继续做了一个最小对照实验:同一个 trigger2.gd fresh instance,一边调用 _gx.Process(...),一边调用 _fe(...),比较两者是否给出同样的结果。对应调用方式如下:
实际返回如下:
返回结果说明:
所以这里应该写成:GameExtension.Process 在 Part1 里负责给出 32 位 hex 中间态,而 _fe 负责把这条中间态重新收缩成右上角看到的 8 位后缀。这样写既符合日志,也能解释为什么早期只盯 native 输出时,始终无法和现场 Part1 样本对上。
Part1 最终可以用一句话概括:先通过对象层拿到绿色块真实触发与真实样本,再通过资源层把 trigger2.gd::_fe 确认为主入口,最后把 _h2b -> _rf -> _xb -> _b2h -> _fe 收敛成可离线复现的 8 轮 Feistel 结构。
其真实分析链路可以概括如下:

红色块的第一道门槛根本不是算法,而是“碰撞条件不成立”。红块对象 id、坐标和 UI 样本都能稳定对上,说明它就是 Part2 真触发点;父 Area3D 的各项属性正常而子 CollisionShape3D.disabled=true,说明首要阻塞不是算法,而是碰撞被关闭;而 _h2b(token) 和 hex_decode() 都无法命中 live 样本,则进一步说明 Part2 的输入模型必须重建,不能照搬 Part1。因此 Part2 的分析顺序不是“一上来就读懂脚本”,而是先在对象层确认红块身份、碰撞条件和真实样本,再回头把脚本和 native 逐步压成白盒。
对象层首先给出了红块的精确定位。主场景中枚举到的红块对象和其子节点如下:
继续读取红块父节点和子节点属性后,可以看到父 Area3D 本身并没有被禁用:
真正的限制位在子节点 CollisionShape3D:
为了确认这不是一次性的读值误判,而确实是 Godot 对象层真正生效的碰撞开关,运行时直接对这个子节点调用 setter,再立刻回读:
把这个布尔位改掉之后,再读回状态就变成了:
这一步把题面里“红色方块需要开启碰撞 单个因素”对应到对象层的真实落点说明白了:红块子节点 CollisionShape3D.disabled = true -> false。
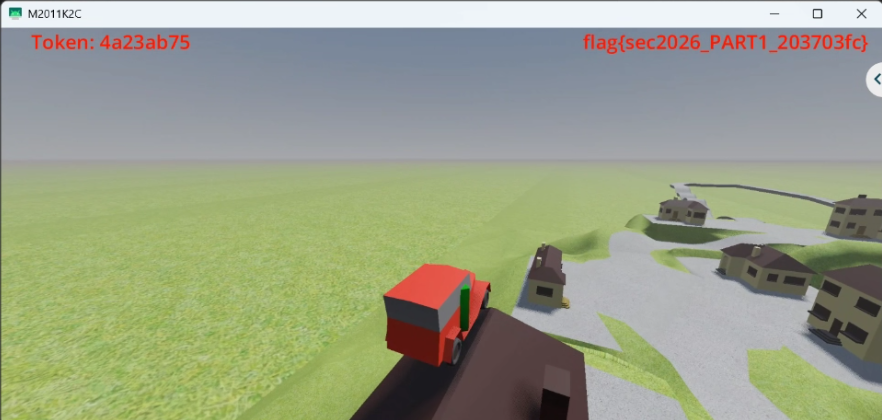
在红块碰撞开启之后,再把车辆传送到红块位置,实时日志就会出现完整的 Token 与 Part2 flag:
我们撰写脚本多次重启进程多次传送,得到以下多组输入输出:
这批红块现场样本构成了后续脚本层与 native 层分析的统一对照基准。
Part2 拿到红块真实样本之后,还不能直接进入 native 算法分析。因为此时只能证明“红块能触发 Part2”,但还不知道触发后上层脚本到底做了什么:它是直接把 token 原始字节传给 native,还是先做 hex_decode(),或者只是负责拼接最终字符串。题目资源里与方块触发最相关的就是 Trigger/*.gd 这一组脚本,所以这里先逐个加载这些脚本,确认红块对应的触发逻辑到底落在哪一个文件里,具体代码如下:
在这一轮对照里,trigger3.gd 很快就显出与红块线路的直接对应关系。原因是它的方法和函数对象同时暴露出下面这组信息:
也就是说,真正把脚本线路锁到 trigger3.gd 上的,是这三层同时成立的结构证据:
在确认脚本对象就是 trigger3.gd 之后,才继续往下追它内部的方法入口。这里同样不是先猜 _w7,而是先从运行时方法表里把名字枚举出来,再去追对应的 GDScriptFunction。用于完成这一步的关键调用如下:
因此,_ready 和 _w7 的名字不是根据脚本文件“脑补”出来的,而是先在运行时方法表中被直接枚举到,随后才继续去追它们各自的函数对象。
先看 _ready。运行时读到的关键信息如下:
这组信息已经足够说明 _ready() 的职责不是生成 flag,而是做信号连接。因为它同时出现了:
这意味着 trigger3.gd 的 _ready() 会在场景初始化阶段把碰撞信号接到 _w7。也就是说,红块被撞到之后,脚本侧真正继续向下执行的入口是 _w7,而不是 _ready() 自己在做后缀计算。
再看 _w7 的函数对象。这里读取到的不是普通字符串,而是 GDScriptFunction 自身携带的常量池和全局名信息。其中最关键的是两组内容:
仅凭这两组信息,就已经足够把 _w7 的职责压缩到一个很小的范围里。它不是:
它真正关心的是:
这里的“结合字节码恢复”,具体指的是:在运行时方法枚举已经锁定 _ready 和 _w7 之后,再根据 GDScriptFunction 中的 code、constants、global_names 去翻译控制流和数据流,而不是只停留在名字匹配层面。继续把 _w7 的 code 字段、常量池和全局名对照之后,可以把它收敛成下面这版高层伪代码:
这里的 _ar 是 body_entered 信号传进来的占位参数,但从函数对象信息和后续样本对照都可以看出,它并不是后缀算法输入本身。红块线路虽然由碰撞事件触发,但真正进入 native 的数据来自左上角 Label.text.substr(7) 取出的那 8 位 token 文本。至此,Part2 的脚本层职责已经可以明确分成两部分:
因为 Part1 走的是 _h2b -> _rf -> _xb -> _b2h,所以一开始我们假设:
但这个假设必须靠运行时逐个试掉。这里采用的方式不是继续猜字节码,而是直接在 fresh trigger3 实例和 _gx.Process 上做候选输入对照,把几条最可能的输入路径逐条喂给 native,比谁和红块现场样本一致。对应写法可以概括为:
样本 35bddf45 的对照结果如下:
而红块实机样本恰好也是:
这组对照直接说明:
如果不先把输入模型纠正过来,后面对 native 轮函数的恢复就会一直建立在错误明文上,任何中间态都不可能和红块 live 样本对应。因此这里不是“猜测更像 to_utf8_buffer()”,而是把 _h2b、hex_decode、to_utf8_buffer、to_ascii_buffer 四条路都跑过以后,只有文本字节路径能与红块现场一致。
与 Part1 不同,Part2 到了这里并没有停在脚本层,而是顺着 _gx.Process(token_ascii_bytes) 继续往 native 核心走,原因如下:
沿着这条链继续向下,运行时和静态都指向同一条 native 主线:
其中 sub_97704 对应的是 Process(PackedByteArray) -> String 入口包装层,sub_A936C 负责把 8-byte token 文本块整理成 native 核心所需的输入格式,sub_A7900 主要承担本次调用的上下文装配,而真正持续推进 16-byte state 的核心在 sub_A7194 及其一组 helper 周围。
这一步没有直接硬读平坦化伪代码,而是先用本地模拟把“大框架”钉死,再逐个识别 helper 的职责。具体做法是:对 sub_A936C(0xA936C) 建立本地模拟环境,只记录几个关键 helper 的命中顺序以及每次进入、退出时的 16-byte state。这样做的目的,是先确认轮函数结构,再回头解释细节,避免一开始就被平坦化状态机淹没。
用样本 35bddf45 跑通这一条链之后,命中顺序非常稳定:
这一步先把 Part2 native 核心的骨架钉死了:它不是单轮散装调用,而是一条非常完整的 16-byte 块变换。随后再结合每个 helper 的前后态对比,就能把它们逐层翻译成更容易写进 WP 的结构。
最先被识别出来的是两层固定异或:
再往中间看,轮函数结构也逐步被拆清:
把这些 helper 对齐之后,Part2 的 native 结构就已经可以在第一章里直接写成下面这版:
也就是说,Part2 并不是“脚本做一点、native 做一点但还说不清怎么分工”的状态,而是已经在第一章这一步收出了完整的分层结构:
到这里,Part2 的脚本层和 native 层分工已经固定下来:脚本层负责读取 Label.text.substr(7)、整理输入并拼接最终 flag,native 层负责实际生成 32 位后缀。
Part2 这一条线的核心经验可以概括为:
其真实推进链如下图所示:
从目前来看 Part3 至少存在四种可能。第一种是继续沿用 Part2 的对象层思路,只改一个碰撞位;但很快发现父 Area3D 的 monitoring / monitorable / scale 也一起被关掉,这条路立刻就不够用了。第二种是怀疑 label2.gd 会像 trigger3._w7 一样自己拼 flag;后来 _k7w / _ready / _process 被白盒恢复后,确认它只负责显示。第三种是怀疑 trigger4.gd 直接在脚本里算完整后缀;可它的元数据更像显隐、状态推进和信号发射脚本,而不是字符串算法脚本。最后剩下的那条路线,就是真正的 native VM 主线。也就是说,Part3 不是靠一次命中就锁定入口,而是靠一轮轮排除错误入口,最后才把问题压回 VM。这一点也解释了为什么 Part3 的过程文字必须写得比 Part1 和 Part2 更细,因为它真正难的不是公式本身,而是入口收缩过程。
对象层先给出了隐形块的精确定位:
对它的父子节点继续读属性之后,可以立刻看到它和红块的差异。红块只有子节点碰撞被关掉,而隐形块在父节点上就已经同时关闭了多个开关:
运行时对这四个条件做的不是内存硬写,而是沿 Godot 对象接口逐项改值、逐项回读:
而是对象层可以直接看到的四个具体状态:
进一步把这四项全部改掉之后,日志就会变成:
把多因素条件打开之后,再把车辆传送到隐形块坐标,就能在右上角直接看到 Part3 真实 flag。第一组关键日志如下:
另一轮独立复验时又拿到了第二组样本:
这一步的意义非常大,因为 Part3 从这一刻开始不再是“没有真实输出的黑盒 VM 题”,而是变成了“已有真实 token -> suffix 样本的 VM 白盒题”。后面的所有 static/dynamic 工作,都是围绕这些真样本来约束和验证的。
也正是从这一刻开始,Part3 的路线不再适合继续留在“只看对象层”阶段。因为一旦真实样本已经出现,后面最关键的问题就变成:
这两个问题都不可能只靠继续改碰撞属性来回答,所以流程必须继续往脚本和 native 层收束。
这也是 Part3 和 Part2 的另一个重要差别。Part2 拿到红块 live 样本后,脚本层几乎立刻就能给出 _w7 -> Process 的清晰入口;而 Part3 即使拿到 live 样本,脚本层仍然没有出现一个类似 _fe / _w7 那样明显“读 token -> 出后缀”的函数。因此 Part3 的 live 样本更像是“给 native 收口提供约束”,而不是“直接暴露脚本入口”。
对应截图已经整理进提交目录。图中左上角是实时 Token: 32b3d131,右上角已经显示 flag{sec2026_PART3_e469db00e99fa597}。
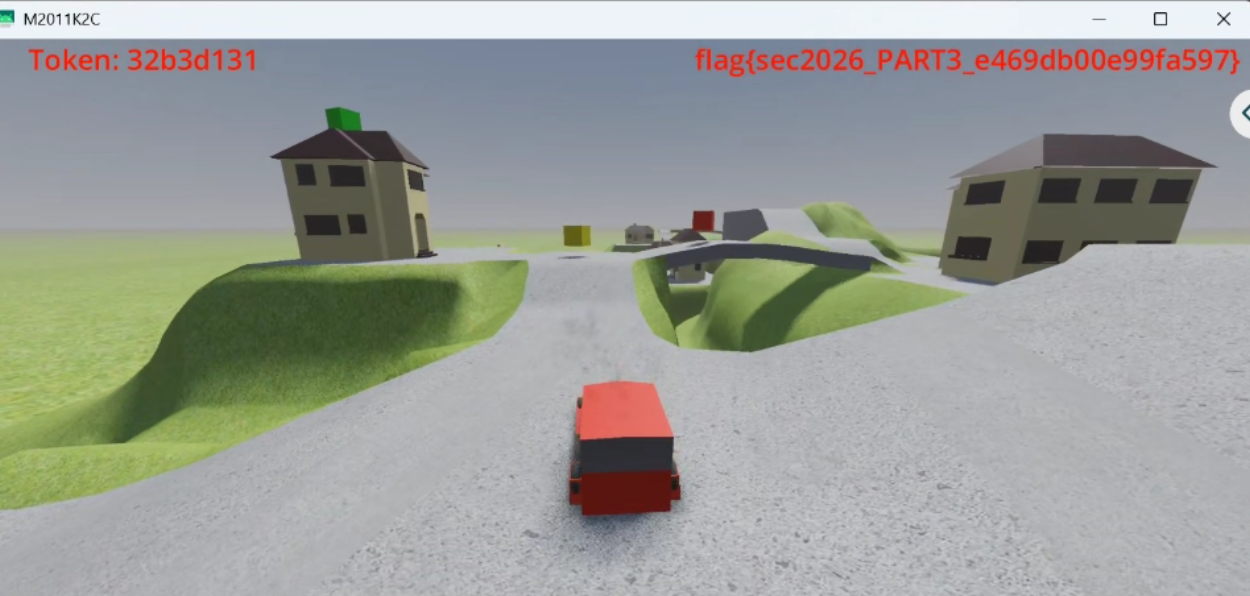
拿到 Part3 真样本之后,右上角的 Label2 自然会成为优先怀疑对象。因为它直接显示 flag,所以需要先弄清楚:它是像 trigger3._w7 一样自己生成字符串,还是只是一个被动显示器。这里采用的方法和 Part2 一样,先从运行时把 label2.gd 的函数对象吐出来,再看 FN_CODE / FN_CONSTANTS / FN_GLOBAL_NAMES。也就是说,先回答“它到底有哪些方法、这些方法用到了哪些常量和全局名”,再决定要不要继续把它当算法入口追。
运行时读取 label2.gd 函数对象时,核心动作可以概括为:
label2.gd::_k7w(p_arg) 的函数对象恢复后,能被直接翻译成如下伪代码:
而 _ready() 的字节码则说明它会主动去找一组 Trigger,把它们的 collided_with 信号全部连到 _k7w:
也就是说,label2.gd 在 Part3 线路中的职责非常纯粹:
这个判断很关键,因为它把一条非常容易走偏的路线明确关掉了:Part3 最终 suffix 不是在 label2.gd 里拼出来的。label2 只是显示层,不是算法层。
从这批函数对象里看到的结果很明确:_k7w 只把传入字符串写到 text,_ready 只负责把一组 Trigger 的 collided_with 信号连到 _k7w,_process 也只是简单维护内部计数。因此这里应该写成:通过运行时函数对象 dump,可以把 label2.gd 从算法入口里排除掉,它在 Part3 线路中只承担输出职责。需要补充的一点是,这批函数对象数据吐完以后现场最终出现了 SIGBUS,但关键的 FN_RESOLVED / FN_CODE / FN_CONSTANTS / FN_GLOBAL_NAMES 已经在崩溃前完整拿到,所以这个崩溃不会影响结论;相反,它说明继续扩大 label2 探针只会增加噪声,收益已经很低。
把 label2.gd 排除之后,trigger4.gd 的职责边界就需要重新定义。这里不是直接根据文件名去猜它“应该负责隐藏块”,而是先把这个脚本在运行时真实暴露出来的方法、属性、信号全部列出来,再继续读取关键方法对应的函数对象。也就是说,这一步分成两层:
第一层用到的是 Godot 自带的脚本反射接口,而不是离线猜测。对应的运行时调用可以概括为:
也正是通过这一步,先把 trigger4.gd 的基础元数据稳定取了出来。当前已经能直接列出的运行时元数据如下:
其中:
这一步的意义是先把 trigger4.gd 的轮廓固定下来。仅从这个轮廓就已经能看出,它和 trigger2.gd、trigger3.gd 很不一样:方法更少,属性更偏状态位和插值量,信号里还直接带了 collided_with(name)。因此后面的重点不是去找一个像 _fe、_w7 那样显眼的字符串入口,而是继续判断这些方法里谁更像显隐和状态推进逻辑。
第二层才是函数对象恢复。这里沿用前面 trigger3.gd 那套方法,对 _m3、_ready、_process 分别定位 GDScriptFunction,再读取关键字段:
其中 _m3() 的常量池是:
全局名是:
这说明 _m3() 更像可视化/动画更新 helper,而不是 flag 生成函数。再结合 _process(_d) 的函数对象里只出现 Tick 和 _m3 两个全局名,就可以把 trigger4.gd 的角色收敛为:
到这里,Part3 的对象层职责已经明确分层:
这三个角色一旦分清,后面的每一步就都变得更可解释了:
也就是说,Part3 看上去最复杂,但实际上在中后期反而是职责分层最清楚的一条线。
如果把这一阶段的角色拆分用一句话概括,那就是:隐形块 Area3D#43385882408 提供真实触发条件和多因素 patch 落点,trigger4.gd 负责控制显隐、状态推进和信号发射,label2.gd 只负责接收上游字符串并显示到右上角,而真正的 16 位后缀生成核心则落在 VMEntry / vm_dispatch_opcode_f / worktrace 这条 native VM 链上。角色一旦这样分清,后面的每一层工作才不会互相混淆;这也是为什么后续的 VM 分析不再需要反复回头解释“这到底是不是 UI 层脚本在干活”。
在 Part3 里,native VM 确实最终成为主战场,但和最初直接盯 VMEntry 时已经完全不同。此时它手上已经有了:
在这个前提下,Part3 的 native 逆向不是从“整条 VM 指令全翻译”开始的,而是先把几个必须先坐实的层次逐个钉住。实际过程分成了四步。
第一步,先把 host 侧注册关系钉死。回到 vm_init_state_blobs(0xA9A7C) 这条初始化链后,先不急着看算法,而是优先确认它到底把哪些 callback 挂进了 VM 环境。静态上可以直接看到两处关键注册点:
这一步的意义是先把“输入 callback”和“输出 callback”分清。也就是说,后面动态观察时,不是盲目地去找“哪一段代码像算法”,而是已经知道:
第二步,先把三段虚拟区和它们的 backing 坐实。这里没有一上来就长时间挂整个引擎热路径,而是先在 vm_init_state_blobs 返回后读取 record 描述符,确认 VM 运行时到底搭起了哪三块区域。对应的窄目标探针可以概括为:
运行时对 VM 只保留了窄目标 hook。核心思路是:一处看输入进入 VM,一处看输出离开 VM,中间只记录主工作区槽位,而不去长期挂整个引擎热路径。对应的探针可以概括成:
用这组探针,先把 VM 的三段 backing 区固定了下来:
随后再把 record0 整段 dump 出来,可以看到它虽然映射长度是 0x4000,但真实非零程序区只有约 0x1523 字节。这一步直接把三块区域的职责分清了:
第三步,先把输入和输出两端的宿主语义钉死。输入侧,opcode 101 = VMEntry 这件事,不只来自注册点,也来自 live 行为:VMEntry 命中时,输入缓冲会把 token 按 ASCII 视角送入 VM;输出侧,opcode 102 = vm_dispatch_opcode_f 则负责把已经算好的两个 32-bit word 格式化成最终 16 位 hex。这里最关键的 live 证据,不是“它被命中了”,而是它命中时栈上两个 word 已经准备好,随后直接写入输出缓冲:
这说明:
第四步,才是 worktrace 级逆向。这里没有把整条 VM 当成黑盒去广撒网,而是只保留几类固定证据:
围绕这几组固定槽位去看 stage=1..N 的快照之后,Part3 的 VM 推进过程才真正开始变得可写:
进一步对比多组样本的 stage 快照后,可以稳定看到几条重复规律:
最终这一步收敛出的不是一句“落到 VM 了”,而是完整的逆向过程:
到这里,Part3 的职责划分和 native 逆向过程都已经固定下来:trigger4.gd 负责隐藏块的状态推进与信号发射,label2.gd 负责右上角显示,而实际生成 16 位后缀的计算层则落在 VMEntry / vm_dispatch_opcode_f / worktrace 这一条 native VM 链上。
回顾整个 Part3 过程,可以看到它非常符合本题的整体节奏:
如果一开始就跳过前两步,直接硬拆 VMEntry,会面对两个非常麻烦的问题:
正因为先把对象层和脚本层职责理顺了,最后 native VM 的白盒收口才变成“有约束的公式恢复”,而不是“无约束的状态机猜谜”。
因此 Part3 这条线最值得写进 WP 的,不只是最后那 28 轮公式,而是它是怎样一步步排除错误入口之后才回到 VM 的:
这种排除式推进方式,恰恰是 Part3 过程最有说服力的地方。
如果只看最后结论,Part3 很像“一道 native VM 数学题”;但从真实分析过程看,它更像“先解对象层门槛,再解脚本层职责,再解 native 数学核心”的三段式题目。也正因为三段都走过,所以最终提交材料里 Part3 不应只剩一条 28 轮公式,而应该把这种逐层排除和逐层收束的过程完整保留下来。
这一条主线可以概括为下图:

至此,第一章三条主线的真实排查路径已经齐全:
第一章保留这些过程,目的不是重复给出“最后答案”,而是说明三个计分点分别是如何在真实运行环境里被定位、验证和收缩的。后面的第二章之所以可以直接讨论白盒算法,第三章之所以可以把检测机制按评分点逐项展开,前提都是这一章已经把真实触发对象、真实样本、脚本职责和 native 承接关系逐项说明白了。
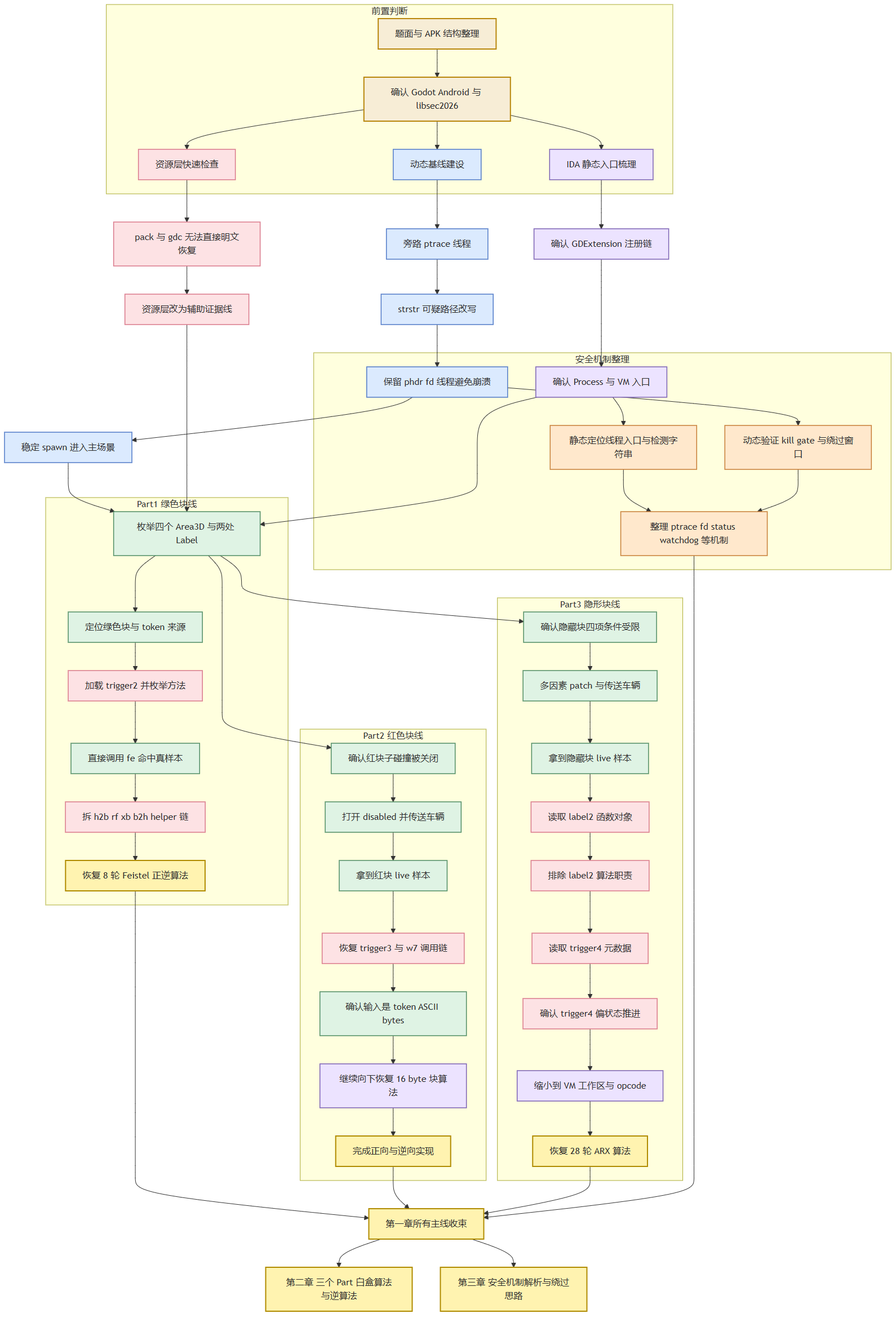
为了便于整体阅读,可以把第一章的真实推进顺序压缩成下面这张总图。它不是新的结论图,而是把前面已经展开讲过的三层切换、三条计分线和安全机制整理过程重新放到同一张图里,方便从全局视角理解整场分析是如何一步步收束的。
Part1 的最终白盒逻辑完全落在 trigger2.gd 脚本 helper 链上,核心结构是 8 轮 Feistel。当前已经分别给出了对应的 Python 实现以及正向、逆向 C++ 实现,三者使用同一套轮函数和样本集。
Part1 的输入不是 ASCII 字符串本身,而是 8 位十六进制 token 解析后的 4 个原始字节。
例如:
这 4 个字节再被拆成两个 2-byte 半块:
最终输出是:
也就是说,Part1 的后缀长度固定为 8 个十六进制字符,对应 4 字节结果。
当前已经确认的唯一核心常量是:
它以 UTF-8 形式进入 _rf:
_rf 的精确白盒表达如下:
这里有三个连续变换:
Part1 正向算法本质上是一个 8 轮 Feistel 结构:
从数据流看,这一链条可以画成:

这个结构解释了为什么 Part1 最终既不像 Part2 那样生成 32 hex,也不像 Part3 那样进入 VM:它本身就是一个脚本层可逆 Feistel 变换。
因为 Part1 是标准 Feistel 结构,所以逆向算法不需要暴力搜索,只需要从第 7 轮倒推到第 0 轮:
由于 _rf 本身只参与 Feistel 轮函数,而不直接覆盖两个半块,所以不需要单独对 _rf 求逆;这也是 Part1 逆算法能非常稳定落地成 C/C++ 的原因。
Part1 的复核依据不是单靠离线拟合,而是下面三层证据同时对齐:
这一点可以用已验证样本直接说明:
这三组样本都来自真实运行时 _fe(token) 返回值,而不是人工伪造。
Part2 的白盒逻辑由脚本入口 trigger3.gd::_w7 和 native 块变换两部分构成。脚本层只负责输入整形和输出拼接,真正的 32 hex 后缀完全由 native 侧生成。
Part2 最大的特征,是输入 token 不是按十六进制值解析,而是按 ASCII 字节直接进入 native。
例如:
native 入口会把这 8 个 ASCII 字节复制两次,拼成 16-byte 明文块:
最终输出模板由 _w7 负责拼装:
当前 Part2 的白盒主线已经可以写成一条完整的块变换流程:
可以看到它整体上有 AES-like 的轮结构,但并不是标准 AES。它的 S-box、轮重排、ShiftRows 方向、MixColumns 矩阵和最终 key 异或都被改过,因此必须按题目自己的白盒逻辑实现。
把这条链按算法步骤展开,可以画成下面这张流程图:

Part2 当前最关键的白盒组件如下表:
其中 mix_columns 的矩阵已经完全确定为:
Part2 里最容易被误判成“黑盒 helper”的两个组件,其实都已经被压成显式公式。
permute_round(round_idx):
add_round_key(round_idx):
也就是说,Part2 并没有保留“只知道调用顺序、还看不懂 helper”的灰色区域;主要 helper 已经全部翻译成了可直接提交的高层伪代码。
Part2 的逆算法同样不是暴力搜索,而是逐层撤销每一个白盒组件:
这里最后一步的 left == right 检查非常关键,因为它正好对应正向阶段里“8-byte token ASCII 重复两次”的输入构造。也正因为这一步成立,逆算法恢复出的前 8 个字节就是原始 token。
Part2 的复核依据可以压缩成下面四层对照:
当前已经验证通过的样本如下:
逆向也已全部命中:
到这里,Part2 已经满足题面对算法实现和逆算法实现的双向要求。
Part3 是三个 Part 里 native 色彩最强的一条,但它最终也已经收口成纯白盒实现,不依赖 libsec2026.so、Frida 或运行时黑盒接口。当前已经分别给出 Python 版本、头文件定义以及正向、逆向 C++ 版本,它们都基于同一套显式公式。
Part3 的第一步不是把 token 当 32-bit 十六进制值使用,而是把 8 位 token 当作 8 个 ASCII 字符,然后分成两个 4-char 半块,各自按小端打包成 32-bit 整数:
因此:
这一点和 Part1、Part2 都不同:
Part3 的轮函数已经被压成标准的 32-bit 双字更新形式。核心常量如下:
正向轮函数可以直接写成:
从结构上看,它最接近一类双字 ARX / TEA-like 变体:
Part3 的一个关键问题不是只恢复“单轮公式”,而是确定轮数和最终输出顺序。当前这一点已经被真实样本确认:
最终只有一个组合能同时命中所有样本:
因此 Part3 的最终后缀表达式为:
这也是为什么最终整理样本时全部按 v1||v0 形式落地,而不是更直觉的 v0||v1。
把输入打包和轮函数放在一起后,Part3 正向算法已经可以写成完整白盒:
上层 flag 只是再加一层固定前后缀:
数据流如下:

Part3 的逆算法也已经完全白盒,不依赖爆破。由于每一轮更新顺序是先 v0 后 v1,因此逆向时只需要:
精确写法如下:
因为初始输入本来就是合法 ASCII 4-char + 4-char,所以逆向结束后直接 little-endian -> ASCII 即可恢复原始 token。
Part3 的复核依据来自“对象层真样本 + native worktrace + 白盒 solver”三方对照,而不是单靠离线拟合:
当前已经验证通过的样本如下:
逆向也已全部命中:
sub_99094(0x99094) 是启动期线程分发器,会连续 pthread_create 三条守卫线程:
从静态结构上看,这三条线程职责并不相同:
因此最终稿里的绕过描述不能写成“整条线程静音”,而应当写到每条线程内部的检测链和具体控制流落点。
检测机制与对应绕过综述
补充说明:
共享 syscall wrapper
/proc/self/maps、/proc/self/fd 与 /proc/self/task/%s/status 这几条链里,都没有完全走 libc 高层接口,而是复用了库内的原生 syscall wrapper。三处最重要的 wrapper 如下:
这也是为什么这里不适合只在 libc 层全局 hook open/read/readlinkat/close。
分析
这条链的静态入口是 sub_9C654(0x9C654)。函数一开始就出现:
并且它还会调用两个专门的寄存器操作 helper:
这说明它不是普通的“一次 ptrace 是否成功”检测,而是带有父子进程配合和寄存器读写能力的完整反调试链。
详细检测机制
从 0x9C654 往后看,至少能确认以下关键块:
这类组合通常用于:
绕过
这条链更适合在“线程创建点”定点旁路,而不是全局 hook ptrace。原因是它本身是一条独立线程,入口在 sub_99094 里单独创建,和另外两条守卫线程没有共享 start_routine。
更稳的做法有两种:
如果做静态 patch,优先级应当是先改 sub_99094 的第一处 pthread_create,其次才是把 sub_9C654 开头直接改成返回;这样更容易保持周围控制流和栈收尾完整。
关键 Frida 绕过代码
这个写法的关键点是:
证据
分析
这条链不是独立线程入口,而是 thread_phdr_fd_watch 内部的一部分。当前已经坐实:
进一步补齐的两段静态字符串为:
这说明它不是“随手枚举一下模块”,而是在围绕合法目标模块 libgodot_android.so 做两件事:
详细检测机制
静态骨架如下:
这里要特别说明两点:
绕过
这条链不能通过“整条线程静音”解决,因为 thread_phdr_fd_watch 被整体替换后会直接崩;现在又已经确认它还负责 "/proc/self/maps" 与 mprotect,所以更不能整段删除。
更稳的绕过有两种:
关键 Frida 绕过代码
它不是伪造 strstr 的返回值,而是直接把被比较的模块路径改成目标模块路径,这样更符合状态机的真实语义,也不会破坏后面继续围绕 libgodot_android.so 做 maps 定位和页权限处理的主线。
证据
分析
这条链同样落在 thread_phdr_fd_watch 的状态机内部,但和 dl_iterate_phdr / maps 是另一条并行输入源。已经确认的关键块是:
当前已经恢复出的关键明文字符串是:
这些字符串并不是 ELF 明文里直接摆着的,而是运行时解码出来的。
详细检测机制
本链涉及三组关键 helper:
基于这些 helper,状态机会执行:
这条链的意义非常明确:
绕过
这条链最重要的经验不是“怎么改值”,而是“哪里绝对不能硬砍”:
绕过方式:
如果直接把整个扫描链短路掉,极有可能重现之前的 Bad access due to invalid address。
关键 Frida 绕过代码
这里真正敏感的输入不是目录枚举本身,而是 readlinkat("/proc/self/fd/%s") 读回来的目标字符串。
证据
分析
这一条是当前已经单独坐实的一条独立检测机制,和 /proc/self/fd 不同,它不是看 fd 目标,而是逐线程去读 status。已静态恢复出的关键明文字符串是:
这四个字符串同时出现在 thread_state_machine_watch(0x9CDC4) 的状态机里,并且都能挂回实际 syscall 路径,因此它可以单独列成一个评分点。
详细检测机制
当前已经能把完整链路串起来:
这条链不是泛化的 /proc/self/status 检测,而是逐线程枚举 /proc/self/task,逐个打开 status,再用 Frida/GLib 线程名做匹配。
绕过
更稳的绕过有两种:
关键 Frida 绕过代码
证据
分析
sub_9AD68(0x9AD68) 当前在 IDA 里已经能明确归类为 monotonic_delta_watchdog_worker。它不是算法主线,而是单独的时间窗口检测 worker。
最关键的两个状态块是:
然后它把结果写入 qword_1834B8,并用 llabs 做绝对值比较。
详细检测机制
目前已能恢复出的核心语义是:
0x989680 十进制是 10000000,也就是 10 秒量级的微秒阈值。
这意味着它更像一个“长暂停/长卡顿/长时间挂起”的 watchdog:
都可能把状态机推进异常路径。
绕过
绕过方式:
这里要特别注意:0x9AE98 和 0x9AECC 两个 svc #0 不是 kill 点,而是功能性时间采样点,不能像 exit_group 一样粗暴删掉。
关键 Frida 绕过代码
这部分目前没有专门针对 watchdog 的 Frida patch,更适合给出低噪声 attach 模板,尽量不要先把 watchdog 打响:
证据
分析
这条机制不是“检测输入”,而是前面所有检测命中后的最终 kill 手段。
对 exit、abort、__assert2 与 android_set_abort_message 全部加监控后,可以确认:
但进程仍然直接结束,因此最合理的解释就是 native 自己发起了原生 syscall 退出。
详细检测机制
目前已经确认的四个明确 kill 点是:
这些点的共同语义都是:
因此只 hook libc exit/abort 是看不到它们的。
同时已经确认,下面这些 svc #0 不是 kill 点,而是功能性 syscall wrapper:
所以这里不能采取“把所有 svc #0 都 NOP 掉”的粗暴方案。
绕过
当前已经验证过的更安全静态 patch,是改控制流而不是直接抹掉 svc:
这样做的好处是:
关键 Frida 绕过代码
前半段的意义是证明“终止前没有经过 libc 终止族函数”,后半段是 attach 版等价绕过思路,语义上等价于当前已经验证过的静态控制流 patch。
证据
当前可以看见的是:
因此更准确的结论是:
更稳的动态模板如下:
实际采用的流程图:
 对应如下表:
对应如下表:
附录文件已经统一整理到 3、附录文件 目录
本文档在逆向分析、材料整理、文字润色和版式调整阶段均使用了 AI 辅助工具,部分分析思路梳理、文字表述、流程图导出与文档转换由 AI 协助完成;样本获取、关键验证、算法还原与最终结论均结合实际分析结果整理并复核。
| Token | 正向输出 | 逆向恢复 |
|---|---|---|
16663b2a |
sec2026_PART1_879d0d6c |
879d0d6c -> 16663b2a |
0ddc38e5 |
sec2026_PART1_b39e34c8 |
b39e34c8 -> 0ddc38e5 |
d6ca2bda |
sec2026_PART1_1f5a7f25 |
1f5a7f25 -> d6ca2bda |
| 组件 | 已确认逻辑 |
|---|---|
| 输入整形 | token.encode("ascii") * 2 形成 16-byte 明文块 |
| 预处理 1 | state ^= PRE_XOR_MASK |
| 预处理 2 | state ^= INIT_XOR |
SubBytes |
使用运行时恢复的自定义 256-byte S-box |
permute_round(round_idx) |
不是标准置换,而是“按列重排 + 递推字节流异或” |
shift_rows |
是自定义方向,不是标准 AES 方向 |
mix_columns |
GF(2^8) 上的自定义线性层,约化多项式是 0x71 |
add_round_key |
不仅异或轮密钥,还异或 ((round_idx * 0x5b) + row) & 0xff 这一层偏置 |
| 尾处理 | state ^= FINAL_XOR |
| Token | 正向输出 |
|---|---|
35bddf45 |
flag{sec2026_PART2_f1f025a5f11ea16bf1da0eeed81ab2cc} |
1440cbd9 |
flag{sec2026_PART2_2f2c727a1941317644ddfab5be75fb90} |
b83894bf |
flag{sec2026_PART2_ce0c9388bb33d29cc014892533b6db3a} |
db4ff573 |
flag{sec2026_PART2_439ea68fbdb0653e760e305b560ce8c3} |
0af8d3ee |
flag{sec2026_PART2_aa761e018840980c6d442ae640e8bdbd} |
| 后缀 | 恢复 Token |
|---|---|
f1f025a5f11ea16bf1da0eeed81ab2cc |
35bddf45 |
2f2c727a1941317644ddfab5be75fb90 |
1440cbd9 |
ce0c9388bb33d29cc014892533b6db3a |
b83894bf |
439ea68fbdb0653e760e305b560ce8c3 |
db4ff573 |
aa761e018840980c6d442ae640e8bdbd |
0af8d3ee |
| Token | 正向输出 |
|---|---|
cd779bb7 |
flag{sec2026_PART3_09495e9eb8c4f6b4} |
5fedf124 |
flag{sec2026_PART3_4bf93aac888ff600} |
b0a8714f |
flag{sec2026_PART3_ef67dae4f56442e9} |
8f14b3d6 |
flag{sec2026_PART3_ec909d2bcbb1ead1} |
38897a4a |
flag{sec2026_PART3_16cf679ddbe8c2ee} |
ff5f9bf5 |
flag{sec2026_PART3_6a913474062fb50a} |
fd150fbd |
flag{sec2026_PART3_cfd132411cda99d6} |
| 后缀 | 恢复 Token |
|---|---|
09495e9eb8c4f6b4 |
cd779bb7 |
4bf93aac888ff600 |
5fedf124 |
ef67dae4f56442e9 |
b0a8714f |
ec909d2bcbb1ead1 |
8f14b3d6 |
16cf679ddbe8c2ee |
38897a4a |
6a913474062fb50a |
ff5f9bf5 |
cfd132411cda99d6 |
fd150fbd |
| 编号 | 检测机制 | 入口 | 关键证据 | 绕过位置 |
|---|---|---|---|---|
| 1 | 父子进程 ptrace 反调试链 | sub_99094 -> sub_9C654 | 0x990CC 的第一条 pthread_create 指向 sub_9C654。<br>sub_9C654 内直接出现 getpid、fork、waitpid、ptrace。<br>sub_95CC0、sub_95E3C 分别对应 GETREGSET、SETREGSET。 | 改 sub_99094 的第一处 pthread_create。<br>或让 sub_9C654 开头立即返回。 |
| 2 | 模块枚举与映射定位链 | sub_9B7D8 -> sub_96A00 / sub_9EFB4 | 0x96A74 调 dl_iterate_phdr,0x9F1EC 调 strstr。<br>静态可解出 libgodot_android.so 与 /proc/self/maps。<br>同线程后续在 0x9BCC4 调 mprotect。 | 只改 sub_9EFB4 命中后的异常归因块。<br>或把 0x9F1EC 的命中路径改成忽略异常模块。 |
| 3 | /proc/self/fd 解析与 linjector 检测 | sub_9B7D8 -> sub_99CC8 / sub_9A0D0 | 0x99D84 为 opendir,0x99EF8 为 readdir。<br>0x99530 经 sub_9AD3C 发起 readlinkat,0x9A104 为 lstat。<br>静态恢复出 /proc/self/fd、/proc/self/fd/%s、linjector。 | 改 0x9A048 解出的关键字缓冲区。<br>或改 0x9973C 到 0x997A0 的匹配状态转移。 |
| 4 | task/status 线程状态扫描 | loc_9CDC4 状态机线程 | 静态解出 /proc/self/task、/proc/self/task/%s/status、gum-js-loop、gmain。<br>代码路径回收到 opendir、readdir、openat、read、close。 | 改 0x9DA8C 与 0x9D16C 解出的关键字缓冲区。<br>或改 0x9E488 到 0x9E4F8、0x9DF5C 到 0x9DFAC 的匹配状态转移。 |
| 5 | 单调时钟差值 watchdog | sub_9AD68 | 0x9AE98 与 0x9AECC 两次采样 CLOCK_MONOTONIC。<br>0x9AF08 与 0x9AF14 组出阈值 0x989680。<br>0x9AF24 执行超时比较。 | 改 0x9AF08 到 0x9AF14 的阈值常量。<br>或改 0x9AF24 到 0x9AF3C 的比较结果。 |
| 6 | 原生 exit_group 自杀口 | 多条异常出口 | 明确 kill gate 为 0x96BB8、0x96BC4、0x9A1DC、0x9E9C0。<br>功能性 syscall wrapper 与 kill gate 已可区分。 | 只改这 4 个 kill gate 的控制流。<br>保留其余功能性 syscall wrapper。 |
| wrapper | 偏移 | 指令特征 | 主要用途 |
|---|---|---|---|
| sub_9AD3C | 0x9AD3C | MOV X8, X0; ...; SVC 0; RET | 六参数直 syscall;当前主要承载 openat、readlinkat 等 |
| sub_9AD20 | 0x9AD20 | MOV X8, X0; ...; SVC 0; RET | 三参数 read |
| sub_9CB30 | 0x9CB30 | MOV X8, X0; ...; SVC 0; RET | close |
| 阶段 | 动作 | 目的 | 结果 |
|---|---|---|---|
| 1 | 使用 spawn --pause 启动,不把 attach 当主路线 | 先于主线程恢复布置最小探针 | 主线程恢复前即可就位 |
| 2 | 只在 pthread_create、android_dlopen_ext、strstr 这三个外侧位置下窄目标 hook | 避免过早直钩库内注册链 | 先看到线程、加载、模块比较三类事件 |
| 3 | 从 pthread_create 中识别三条守卫线程 | 区分 ptrace、状态机、phdr/fd 三条链 | 后续可以按职责分别处理 |
| 4 | 只把 thread_ptrace_fork_watch 替换成空线程 | 压掉纯反调试线程,不破坏初始化 | 父子进程 ptrace 链被稳定旁路 |
| 5 | 保留 thread_state_machine_watch 与 thread_phdr_fd_watch | 两条线程混有初始化职责,粗暴 noop 会崩 | 进程能继续走到主场景 |
| 6 | 仅在 libsec2026.so 发起的 strstr 比较里改写 haystack | 避免命中 frida memfd 这类危险字符串 | 危险输入被伪装成正常系统模块路径 |
| 7 | 等待 android_dlopen_ext 与模块出生完成后,再确认 libsec2026.so 基址和关键入口 | 避免在最敏感窗口过早下库内直钩 | 后续可以安全转入对象层、脚本层和 VM 观察 |
| 8 | 对四个已确认 exit_group kill gate 做控制流 patch | 命中异常分支后不会立即自杀 | 进程保留继续分析的窗口 |
| 9 | 不整条删除 dl_iterate_phdr、/proc/self/maps、/proc/self/fd、mprotect 主链 | 检测链里混着主体运行逻辑 | 只修危险输入和 kill gate,主逻辑保留 |
| 10 | 在窗口稳定后再进入绿块、红块、隐藏块和 VM 主线 | 第一章所有样本、截图、trace 都依赖这一步 | Part1、Part2、Part3 可以持续推进 |
| 文件名 | 对应内容 | 作用说明 |
|---|---|---|
| 关键脚本/脚本01_启动期反调试旁路.js | 第 1 章、第 3 章 | 在 spawn 窗口里旁路 ptrace 线程并改写可疑模块路径,建立可工作的动态入口。 |
| 关键脚本/脚本02_Part1绿色块传送取样.js | 第 1.2 节 | 定位车辆与绿色块,完成对象层传送,并读取左上角 Token 与右上角 Part1 flag。 |
| 关键脚本/脚本03_Part2红块碰撞开启与传送.js | 第 1.3 节 | 打开红块碰撞条件,把车辆送入红块区域,获取 Part2 现场样本。 |
| 关键脚本/脚本04_Part2红块现场w7跟踪.js | 第 1.3 节 | 在真实撞块现场跟踪脚本层调用链,收口到 trigger3 的 _w7。 |
| 关键脚本/脚本05_Part2_Process白盒探针.js | 第 1.3 节、第 2.2 节 | 对 GameExtension.Process 做 direct probe,核对文本输入边界和 32 hex 输出。 |
| 关键脚本/脚本06_Part3_label2函数对象导出.js | 第 1.4 节 | 导出 label2 运行时函数对象,证明它只负责显示与拼接,不承担 Part3 核心算法。 |
| 关键脚本/脚本07_Part3_trigger4函数对象导出.js | 第 1.4 节 | 导出 trigger4 的方法、属性、信号与常量池,确认其职责更接近状态推进。 |
| 关键脚本/脚本08_Part3隐藏块触发与工作区跟踪.js | 第 1.4 节、第 2.3 节 | 打开隐藏块条件、触发 Part3,并同步记录 VM 工作区与右上角 flag。 |
| 关键脚本/脚本09_Part3轨迹时间线整理.py | 第 1.4 节、第 2.3 节 | 把 VM 工作区跟踪日志整理为时间线,辅助还原 28 轮执行过程。 |
| 关键脚本/脚本10_Part3迷你反汇编.py | 第 1.4 节、第 2.3 节 | 对导出的 VM 记录做轻量反汇编,输出更便于写白盒算法的伪指令序列。 |
| 文件名 | 对应内容 | 作用说明 |
|---|---|---|
| 关键日志/日志01_启动期终止口观测.txt | 第 3 章 | 记录 exit、abort、assert 等高层终止接口观测结果,用来区分 kill gate 与常规库接口。 |
| 关键日志/日志02_Part1_trigger2入口探针.txt | 第 1.2 节 | 记录 trigger2 的方法表与 _fe 相关调用结果,用来确认 Part1 脚本入口。 |
| 关键日志/日志03_Part1_native调用链跟踪.txt | 第 1.2 节、第 2.1 节 | 记录 Part1 从脚本层进入 native Process 的参数与返回值,用来校对 _fe 和 native 边界。 |
| 关键日志/日志04_Part2_live_w7_trace.txt | 第 1.3 节 | 记录红块现场 _w7 的 live trace,支撑 Part2 的脚本入口定位。 |
| 关键日志/日志05_Part2_Process_direct_probe.txt | 第 1.3 节、第 2.2 节 | 记录对 Process 的 direct probe 结果,用来确认输入是文本字节而不是 _h2b(token)。 |
| 关键日志/日志06_Part3_label2函数对象导出.txt | 第 1.4 节 | 记录 label2 运行时函数对象和常量池,用来剥离 Part3 的显示层职责。 |
| 关键日志/日志07_Part3_trigger4函数对象导出.txt | 第 1.4 节 | 记录 trigger4 运行时方法、属性、信号与常量信息,用来重建隐藏块上层调用链。 |
| 关键日志/日志08_Part3_VM_dispatch_ctx.txt | 第 1.4 节、第 2.3 节 | 记录 VM dispatch 上下文,用来确认工作区地址、轮数推进和关键寄存状态。 |
| 关键日志/日志09_Part3_隐藏块出分工作区跟踪.txt | 第 1.4 节、第 2.3 节 | 记录隐藏块真机出分时的工作区变化,直接支撑 Part3 白盒算法恢复。 |
[PTHREAD_BYPASS] thread_ptrace_fork_watch start=0x7088cba654
[PTHREAD_SEEN] thread_state_machine_watch start=0x7088cbadc4
[PTHREAD_SEEN] thread_phdr_fd_watch start=0x7088cb97d8
[STRSTR_REWRITE] caller=0x7088cbd1f0
orig_haystack=/memfd:frida-agent-64.so (deleted)
needle=libgodot_android.so
fake_haystack=/system/lib64/libgodot_android.so
[*] hook exit @ 0x73fc1374f0
[*] hook abort @ 0x73fc132318
[*] hook __assert2 @ 0x73fc132b88
[*] hook android_set_abort_message @ 0x73fc1325d4
...
[STRSTR_REWRITE] caller=0x70898c31f0 orig_haystack=/memfd:frida-agent-64.so (deleted)
Process terminated
const TARGET = "libsec2026.so";
let secBase = null;
function safeCString(p) {
try {
return !p || ptr(p).isNull() ? null : ptr(p).readCString();
} catch (_e) {
return null;
}
}
const noopThread = new NativeCallback(function () {
return ptr(0);
}, "pointer", ["pointer"]);
Interceptor.attach(Module.getExportByName("libdl.so", "android_dlopen_ext"), {
onEnter(args) {
this.path = safeCString(args[0]);
},
onLeave() {
if (this.path && this.path.indexOf(TARGET) !== -1) {
secBase = Process.findModuleByName(TARGET).base;
}
}
});
Interceptor.attach(Module.getExportByName("libc.so", "pthread_create"), {
onEnter(args) {
const start = args[2];
if (secBase && start.equals(secBase.add(0x9C654))) {
args[2] = noopThread;
}
}
});
Interceptor.attach(Module.getExportByName("libc.so", "strstr"), {
onEnter(args) {
const hay = safeCString(args[0]);
const needle = safeCString(args[1]);
if (hay && needle &&
hay.indexOf("/memfd:frida-agent-64.so") !== -1 &&
needle.indexOf("libgodot_android.so") !== -1) {
args[0] = Memory.allocUtf8String("/system/lib64/libgodot_android.so");
}
}
});
[AREA] id=43201333021 pos=-12.845476150512695,5.8220415115356445,-15.349905967712402
[AREA] id=43251664672 pos=-14.960197448730469,11.67391300201416,-3.0830507278442383
[AREA] id=43318773540 pos=-13.811505317687988,6.613474369049072,-22.492664337158203
[AREA] id=43385882408 pos=3.749691963195801,4.5928826332092285,-16.55986785888672
const vehicle = objectFromId("38470157839");
const greenTarget = vector3(-14.960197, 12.173913, -3.083051);
variantSet(vehicle, "global_position", greenTarget);
const curPos = variantGet(vehicle, "global_position");
左上角 Label = Token: 16663b2a
右上角 Label2 = flag{sec2026_PART1_879d0d6c}
const script = loadResource("res://Trigger/trigger2.gd");
const instance = variantCall(script, "new", []);
const r1 = variantCall(instance, "_fe", ["16663b2a"]);
const r2 = variantCall(instance, "_fe", ["0ddc38e5"]);
const r3 = variantCall(instance, "_fe", ["d6ca2bda"]);
调用 _fe("16663b2a") -> sec2026_PART1_879d0d6c
调用 _fe("0ddc38e5") -> sec2026_PART1_b39e34c8
调用 _fe("d6ca2bda") -> sec2026_PART1_1f5a7f25
const keyUtf8 = stringToUtf8Buffer("Sec2026_Godot");
const tokenRaw = variantCall(instance, "_h2b", ["16663b2a"]);
const rfOut = variantCall(instance, "_rf", [tokenRaw, keyUtf8, 8]);
const xbOut = variantCall(instance, "_xb", [tokenRaw, rfOut]);
const rfHex = variantCall(instance, "_b2h", [rfOut]);
const xbHex = variantCall(instance, "_b2h", [xbOut]);
常量文本 = Sec2026_Godot
UTF-8 十六进制 = 536563323032365f476f646f74
_h2b("16663b2a") -> [22, 102, 59, 42]
_rf(token, key_utf8, 8) -> [249, 58, 13, 95]
_xb(token, rf_out) -> [239, 92, 54, 117]
KEY = b"Sec2026_Godot"
def rf(block: bytes, key: bytes, round_idx: int) -> bytes:
out = bytearray()
for i, cur in enumerate(block):
key_byte = key[(i + round_idx) % len(key)]
mixed = cur ^ key_byte
mixed = (mixed * 7 + round_idx) & 0xFF
mixed = ((mixed << 3) | (mixed >> 5)) & 0xFF
out.append(mixed)
return bytes(out)
def token_to_suffix(token_hex: str) -> str:
raw = bytes.fromhex(token_hex)
left = raw[:2]
right = raw[2:]
for round_idx in range(8):
t = rf(right, KEY, round_idx)
mixed = bytes(a ^ b for a, b in zip(left, t))
left, right = right, mixed
return (left + right).hex()
const gx = variantGet(instance, "_gx");
const raw = variantCall(instance, "_h2b", ["16663b2a"]);
const nativeOut = variantCall(gx, "Process", [raw]);
const finalOut = variantCall(instance, "_fe", ["16663b2a"]);
调用 Process(raw_token) -> f29c86f23fe372ac85b529d7ab2e56c8
调用 _fe("16663b2a") -> sec2026_PART1_879d0d6c
[PART2_AREA_PICK] red_id=43318773540
red_pos=-13.811505317687988,6.613474369049072,-22.492664337158203
子节点 0 -> id=43352327974 class=CollisionShape3D
monitoring = true
monitorable = true
scale = (1.0, 1.0, 1.0)
CollisionShape3D.disabled = true
const area = objectFromId("43318773540");
const shape = variantCall(area, "get_child", [0]);
const before = variantCall(shape, "get_disabled", []);
variantCall(shape, "set_disabled", [false]);
const after = variantCall(shape, "get_disabled", []);
CollisionShape3D.disabled = false
[TELEPORT_DONE] sync loop completed
左上角 Label = Token: 0af8d3ee
右上角 Label2 = flag{sec2026_PART2_aa761e018840980c6d442ae640e8bdbd}
for (const path of [
"res://Trigger/trigger1.gd",
"res://Trigger/trigger2.gd",
"res://Trigger/trigger3.gd",
"res://Trigger/trigger4.gd"
]) {
const script = loadResource(path);
const instance = variantCall(script, "new", []);
dumpMethodList(instance);
}
const script = loadResource("res://Trigger/trigger3.gd");
const instance = variantCall(script, "new", []);
const methods = dumpMethodList(instance);
const fnReady = findFunctionObject(script, "_ready");
const fnW7 = findFunctionObject(script, "_w7");
dumpField(fnReady, "code");
dumpField(fnReady, "constants");
dumpField(fnReady, "global_names");
dumpField(fnW7, "code");
dumpField(fnW7, "constants");
dumpField(fnW7, "global_names");
方法名:_ready
global_names:_w7 | body_entered | connect
func _w7(_ar):
var label2 = get_node("/root/TownScene/Label2")
var label = get_node("/root/TownScene/Label")
var token_text = str(label.text).substr(7)
var token_arg = token_text.to_utf8_buffer()
var suffix = _gx.Process(token_arg)
label2.text = "flag{" + "sec2026" + "_PART2_" + suffix + "}" + " "
const token = "35bddf45";
const p1 = variantCall(gx, "Process", [variantCall(trigger3, "_h2b", [token])]);
const p2 = variantCall(gx, "Process", [hexDecode(token)]);
const p3 = variantCall(gx, "Process", [toUtf8Buffer(token)]);
const p4 = variantCall(gx, "Process", [toAsciiBuffer(token)]);
Process(_h2b(token)) -> 6e75e5dc727ee034440adfa94a419c77
Process(token.hex_decode()) -> 4467ff6f4447611d6108bdd88303d4b4
Process(token.to_utf8_buffer()) -> f1f025a5f11ea16bf1da0eeed81ab2cc
Process(token.to_ascii_buffer()) -> f1f025a5f11ea16bf1da0eeed81ab2cc
35bddf45 -> f1f025a5f11ea16bf1da0eeed81ab2cc
trigger3.gd::_w7
-> _gx.Process(token_ascii_bytes)
-> sub_97704
-> sub_A936C
-> sub_A7900
-> sub_A7194
[06 03 05 02]
[02 06 03 05]
[05 02 06 03]
[03 05 02 06]
[PART3_AREA_PICK] hidden_id=43385882408
hidden_pos=3.749691963195801,4.5928826332092285,-16.55986785888672
monitoring = false
monitorable = false
scale = (1.0, 1.0, 1.0)
CollisionShape3D.disabled = true
const area = objectFromId("43385882408");
const shape = variantCall(area, "get_child", [0]);
variantSet(area, "monitoring", true);
variantSet(area, "monitorable", true);
variantSet(area, "scale", vector3(8.0, 8.0, 8.0));
variantCall(shape, "set_disabled", [false]);
monitoring = true
monitorable = true
scale = (8.0, 8.0, 8.0)
CollisionShape3D.disabled = false
[TELEPORT_DONE] sync loop completed
左上角 Label = Token: f7bd8cb9
右上角 Label2 = flag{sec2026_PART3_59c17f8a42cb35e6}
左上角 Label = Token: 10f2bd71
右上角 Label2 = flag{sec2026_PART3_f51a0761891b5a8a}
const script = loadResource("res://label2.gd");
const fnK7w = findFunctionObject(script, "_k7w");
const fnReady = findFunctionObject(script, "_ready");
dumpField(fnK7w, "code");
dumpField(fnK7w, "constants");
dumpField(fnReady, "global_names");
func _k7w(p_arg):
_q2m = p_arg
if _q2m.length() > 0:
text = _q2m
func _ready():
var arr = []
var i = 1
while i < 5:
var path = "/root/TownScene/Trigger" + str(i)
var node = get_node(NodePath(path))
arr.append(node)
i += 1
for node in arr:
node.collided_with.connect(_k7w)
const script = loadResource("res://Trigger/trigger4.gd");
const instance = variantCall(script, "new", []);
const methods = variantCall(instance, "get_script_method_list", []);
const props = variantCall(instance, "get_script_property_list", []);
const signals = variantCall(instance, "get_script_signal_list", []);
const fnM3 = findFunctionObject(script, "_m3");
const fnReady = findFunctionObject(script, "_ready");
const fnProcess = findFunctionObject(script, "_process");
dumpField(fnM3, "code");
dumpField(fnM3, "constants");
dumpField(fnM3, "global_names");
dumpField(fnReady, "code");
dumpField(fnReady, "constants");
dumpField(fnReady, "global_names");
dumpField(fnProcess, "code");
dumpField(fnProcess, "constants");
dumpField(fnProcess, "global_names");
MeshInstance3D | <null> | 1.0 | 0.2 | 3.0 | 0.1
rotation | y | position | scale
Interceptor.attach(base.add(0xA9A7C), {
onLeave() {
dumpRecordDesc();
dumpBytes(record0Backing, 0x100);
}
});
Interceptor.attach(base.add(0xA6BEC), {
onEnter() {
dumpWords(record1Base.add(0x14000), 0x88);
dumpWords(record2Base.add(0x1cfc8), 0x18);
}
});
hookOpcode(101, function () {
dumpBytes(tokenBlobPtr, 8);
});
hookOpcode(102, function () {
dumpWords(resultPtr, 8);
});
VMDISPATCH_FMT
stack_word0 = ...
stack_word1 = ...
blob1836E0 = ...
token = "16663b2a"
h2b(token) = [0x16, 0x66, 0x3b, 0x2a]
sec2026_PART1_<8hex>
Sec2026_Godot
53 65 63 32 30 32 36 5f 47 6f 64 6f 74
def rf(block: bytes, key: bytes, round_idx: int) -> bytes:
out = bytearray()
for i, cur in enumerate(block):
key_byte = key[(i + round_idx) % len(key)]
mixed = cur ^ key_byte
mixed = (mixed * 7 + round_idx) & 0xff
mixed = ((mixed << 3) | (mixed >> 5)) & 0xff
out.append(mixed)
return bytes(out)
def token_to_suffix(token_hex: str) -> str:
raw = bytes.fromhex(token_hex)
left = raw[:2]
right = raw[2:]
for round_idx in range(8):
t = rf(right, KEY, round_idx)
mixed = bytes(a ^ b for a, b in zip(left, t))
left, right = right, mixed
return (left + right).hex()
def suffix_to_token(suffix_or_flag: str) -> str:
cipher = bytes.fromhex(normalize_suffix(suffix_or_flag))
left = cipher[:2]
right = cipher[2:]
for round_idx in range(7, -1, -1):
prev_right = left
prev_left = bytes(a ^ b for a, b in zip(right, rf(left, KEY, round_idx)))
left, right = prev_left, prev_right
return (left + right).hex()
token = "35bddf45"
ascii(token) = [0x33, 0x35, 0x62, 0x64, 0x64, 0x66, 0x34, 0x35]
state0 = token_ascii[0:8] || token_ascii[0:8]
flag{sec2026_PART2_<32hex>}
PRE_XOR_MASK = bytes.fromhex("1d7e8816cf2dff7171ff2dcf16887e1d")
INIT_XOR = bytes.fromhex("de4f8a37c16b59e273ad1f94b806d542")
FINAL_XOR = bytes.fromhex("7ce32891a65df014bb6907d84a35ec80")
def process_part2(token: str) -> str:
state = token.encode("ascii") * 2
state = xor_bytes(state, PRE_XOR_MASK)
state = xor_bytes(state, INIT_XOR)
state = add_round_key(state, 0)
for round_idx in range(1, 11):
state = sub_bytes(state)
state = permute_round(state, round_idx)
state = shift_rows(state)
state = mix_columns(state)
state = add_round_key(state, round_idx)
state = sub_bytes(state)
state = permute_round(state, 11)
state = shift_rows(state)
state = add_round_key(state, 11)
state = xor_bytes(state, FINAL_XOR)
return state.hex()
[06 03 05 02]
[02 06 03 05]
[05 02 06 03]
[03 05 02 06]
def permute_round(state: bytes, round_idx: int) -> bytes:
out = bytearray(16)
key = (0x47 - 0x63 * round_idx) & 0xFF
for col in range(4):
for row in range(4):
out[col * 4 + row] = state[(3 - row) * 4 + col] ^ key
key = (0x2F - 0x3D * key) & 0xFF
return bytes(out)
def add_round_key(state: bytes, round_idx: int) -> bytes:
out = bytearray(state)
base = round_idx * 16
round_bias = (round_idx * 0x5B) & 0xFF
for i in range(16):
out[i] ^= ROUND_KEYS[base + i] ^ ((i & 3) + round_bias)
return bytes(out)
def reverse_suffix(suffix: str) -> str:
state = bytes.fromhex(suffix)
state = xor_bytes(state, FINAL_XOR)
state = add_round_key(state, 11)
state = inv_shift_rows(state)
state = inv_permute_round(state, 11)
state = inv_sub_bytes(state)
for round_idx in range(10, 0, -1):
state = add_round_key(state, round_idx)
state = inv_mix_columns(state)
state = inv_shift_rows(state)
state = inv_permute_round(state, round_idx)
state = inv_sub_bytes(state)
state = add_round_key(state, 0)
state = xor_bytes(state, INIT_XOR)
state = xor_bytes(state, PRE_XOR_MASK)
left = state[:8]
right = state[8:]
assert left == right
return left.decode("ascii")
def pack_ascii_u32(text4: str) -> int:
return int.from_bytes(text4.encode("ascii"), "little")
token = "fd150fbd"
v0 = pack_ascii4("fd15")
v1 = pack_ascii4("0fbd")
ROUNDS = 28
DELTA = 0x29E59C9F
K0 = 0xF95D664A
K1 = 0x12AA364C
K2 = 0x33AD3CEE
K3 = 0xAABBCCDD
sum_ = (sum_ + 0x29E59C9F) & 0xffffffff
v0 = (v0 + (
(((v1 << 4) & 0xffffffff) + 0xF95D664A) ^
((sum_ + v1) & 0xffffffff) ^
((v1 >> 7) + 0x12AA364C)
)) & 0xffffffff
v1 = (v1 + (
(((v0 << 6) & 0xffffffff) + 0x33AD3CEE) ^
((sum_ + v0) & 0xffffffff) ^
((v0 >> 5) + 0xAABBCCDD)
)) & 0xffffffff
suffix = f"{v1:08x}{v0:08x}"
def forward_suffix(token: str) -> str:
v0 = pack_ascii_u32(token[:4])
v1 = pack_ascii_u32(token[4:])
sum_ = 0
for _ in range(28):
sum_ = (sum_ + DELTA) & 0xffffffff
v0 = (v0 + ((((v1 << 4) & 0xffffffff) + K0) ^
((sum_ + v1) & 0xffffffff) ^
((v1 >> 7) + K1))) & 0xffffffff
v1 = (v1 + ((((v0 << 6) & 0xffffffff) + K2) ^
((sum_ + v0) & 0xffffffff) ^
((v0 >> 5) + K3))) & 0xffffffff
return f"{v1:08x}{v0:08x}"
def forward_flag(token: str) -> str:
return f"flag{{sec2026_PART3_{forward_suffix(token)}}}"
def reverse_suffix(suffix: str) -> str:
v1 = int(suffix[:8], 16)
v0 = int(suffix[8:], 16)
sum_ = (28 * DELTA) & 0xffffffff
for _ in range(28):
v1_prev = (v1 - (
(((v0 << 6) & 0xffffffff) + K2) ^
((sum_ + v0) & 0xffffffff) ^
((v0 >> 5) + K3)
)) & 0xffffffff
v0_prev = (v0 - (
(((v1_prev << 4) & 0xffffffff) + K0) ^
((sum_ + v1_prev) & 0xffffffff) ^
((v1_prev >> 7) + K1)
)) & 0xffffffff
v0, v1 = v0_prev, v1_prev
sum_ = (sum_ - DELTA) & 0xffffffff
return unpack_ascii_u32(v0) + unpack_ascii_u32(v1)
const TARGET_MODULE = "libsec2026.so";
const PTRACE_THREAD_OFF = 0x9c654;
const noopThread = new NativeCallback(function (_arg) {
send("[THREAD_BYPASS] noop thread entered");
return ptr(0);
}, "pointer", ["pointer"]);
function findLibcExport(name) {
return Process.findModuleByName("libc.so").findExportByName(name);
}
Interceptor.attach(findLibcExport("pthread_create"), {
onEnter(args) {
const start = ptr(args[2]);
const owner = Process.findModuleByAddress(start);
if (!owner || owner.name !== TARGET_MODULE) {
return;
}
if (start.equals(owner.base.add(PTRACE_THREAD_OFF))) {
args[2] = noopThread;
send(`[PTHREAD_BYPASS] ptrace watch replaced: ${start}`);
}
}
});
const TARGET_MODULE = "libsec2026.so";
const SUSPICIOUS = ["frida", "gum", "gmain", "gdbus", "linjector", "memfd:"];
const keepAlive = [];
function safeCString(p) {
try {
return !p || ptr(p).isNull() ? null : ptr(p).readCString();
} catch (_e) {
return null;
}
}
function textHasSuspiciousKeyword(text) {
if (!text) return false;
const lower = text.toLowerCase();
return SUSPICIOUS.some(k => lower.indexOf(k) !== -1);
}
const strstrPtr = Process.findModuleByName("libc.so").findExportByName("strstr");
Interceptor.attach(strstrPtr, {
onEnter(args) {
const caller = this.returnAddress;
const owner = Process.findModuleByAddress(caller);
if (!owner || owner.name !== TARGET_MODULE) {
return;
}
const haystack = safeCString(args[0]);
const needle = safeCString(args[1]);
if (!textHasSuspiciousKeyword(haystack)) {
return;
}
if (!needle || needle.indexOf(".so") === -1) {
return;
}
const fakeHaystack = `/system/lib64/${needle}`;
const fakePtr = Memory.allocUtf8String(fakeHaystack);
keepAlive.push(fakePtr);
args[0] = fakePtr;
send(`[STRSTR_REWRITE] ${haystack} -> ${fakeHaystack}`);
}
});
const base = Process.findModuleByName("libsec2026.so").base;
const syscall6 = base.add(0x9ad3c);
function readCString(p) {
try {
return p.isNull() ? null : p.readCString();
} catch (_e) {
return null;
}
}
Interceptor.attach(syscall6, {
onEnter(args) {
this.sysno = args[0].toInt32();
if (this.sysno !== 0x4e) return; // readlinkat
const path = readCString(ptr(args[2]));
if (!path || path.indexOf("/proc/self/fd/") !== 0) return;
this.fdPath = path;
this.outBuf = ptr(args[3]);
},
onLeave(retval) {
if (!this.outBuf) return;
const n = retval.toInt32();
if (n <= 0) return;
const text = this.outBuf.readUtf8String(n);
if (text.indexOf("linjector") === -1) return;
const fake = "/system/bin/linker64";
Memory.writeUtf8String(this.outBuf, fake);
retval.replace(ptr(fake.length));
send(`[FD_READLINK_SANITIZE] ${this.fdPath} -> ${fake}`);
}
});
const base = Process.findModuleByName("libsec2026.so").base;
const syscall6 = base.add(0x9ad3c); // openat
const syscallRead = base.add(0x9ad20); // read
const syscallClose = base.add(0x9cb30); // close
const trackedStatusFds = new Map();
function readCString(p) {
try {
return p.isNull() ? null : p.readCString();
} catch (_e) {
return null;
}
}
Interceptor.attach(syscall6, {
onEnter(args) {
this.sysno = args[0].toInt32();
if (this.sysno !== 0x38) return; // openat
const path = readCString(ptr(args[2]));
if (!path) return;
if (path.indexOf("/proc/self/task/") !== 0) return;
if (!path.endsWith("/status")) return;
this.statusPath = path;
},
onLeave(retval) {
if (!this.statusPath) return;
const fd = retval.toInt32();
if (fd >= 0) trackedStatusFds.set(fd, this.statusPath);
}
});
Interceptor.attach(syscallRead, {
onEnter(args) {
this.sysno = args[0].toInt32();
if (this.sysno !== 0x3f) return; // read
const fd = args[1].toInt32();
if (!trackedStatusFds.has(fd)) return;
this.fd = fd;
this.buf = ptr(args[2]);
},
onLeave(retval) {
if (!this.buf) return;
const n = retval.toInt32();
if (n <= 0) return;
const text = this.buf.readUtf8String(n);
const fixed = text
.replace(/gum-js-loop/g, "RenderThread")
.replace(/\bgmain\b/g, "main");
if (fixed === text) return;
Memory.writeUtf8String(this.buf, fixed);
retval.replace(ptr(fixed.length));
send(`[TASK_STATUS_SANITIZE] fd=${this.fd} path=${trackedStatusFds.get(this.fd)}`);
}
});
Interceptor.attach(syscallClose, {
onEnter(args) {
this.sysno = args[0].toInt32();
if (this.sysno !== 0x39) return; // close
this.fd = args[1].toInt32();
},
onLeave() {
if (this.fd !== undefined) {
trackedStatusFds.delete(this.fd);
}
}
});
const TARGET_MODULE = "libsec2026.so";
let moduleSeen = false;
const libdl = Process.findModuleByName("libdl.so");
const androidDlopenExt = libdl.findExportByName("android_dlopen_ext");
Interceptor.attach(androidDlopenExt, {
onEnter(args) {
this.path = args[0].isNull() ? null : args[0].readCString();
},
onLeave(retval) {
if (this.path && this.path.indexOf(TARGET_MODULE) !== -1) {
send(`[DLOPEN] path=${this.path} handle=${retval}`);
}
}
});
setInterval(function () {
const module = Process.findModuleByName(TARGET_MODULE);
if (module && !moduleSeen) {
moduleSeen = true;
send(`[MODULE_SEEN] base=${module.base} extension_init=${module.findExportByName("extension_init")}`);
}
}, 20);
const libc = Process.findModuleByName("libc.so");
for (const name of ["exit", "abort", "__assert2", "android_set_abort_message"]) {
const p = libc.findExportByName(name);
if (!p) continue;
Interceptor.attach(p, {
onEnter() {
send(`[TERM_MONITOR] ${name} caller=${this.returnAddress}`);
}
});
}
const base = Process.findModuleByName("libsec2026.so").base;
function jumpAt(fromOff, toOff) {
Interceptor.attach(base.add(fromOff), {
onEnter() {
this.context.pc = base.add(toOff);
}
});
}
function retAt(fromOff) {
Interceptor.attach(base.add(fromOff), {
onEnter() {
this.context.pc = this.context.lr;
}
});
}
jumpAt(0x96bb8, 0x96b84);
jumpAt(0x96bc4, 0x96b84);
retAt(0x9a1dc);
jumpAt(0x9e9c0, 0x9e99c);
const TARGET_MODULE = "libsec2026.so";
let moduleSeen = false;
function safeCString(p) {
try {
return !p || ptr(p).isNull() ? null : ptr(p).readCString();
} catch (_e) {
return null;
}
}
const libdl = Process.findModuleByName("libdl.so");
const androidDlopenExt = libdl.findExportByName("android_dlopen_ext");
Interceptor.attach(androidDlopenExt, {
onEnter(args) {
this.path = safeCString(args[0]);
},
onLeave(retval) {
if (this.path && this.path.indexOf(TARGET_MODULE) !== -1) {
send(`[DLOPEN] path=${this.path} handle=${retval}`);
}
}
});
setInterval(function () {
const module = Process.findModuleByName(TARGET_MODULE);
if (module && !moduleSeen) {
moduleSeen = true;
send(`[MODULE_SEEN] base=${module.base} extension_init=${module.findExportByName("extension_init")} VMEntry=${module.findExportByName("VMEntry")}`);
}
}, 20);
| Token | 正向输出 | 逆向恢复 |
|---|---|---|
16663b2a |
sec2026_PART1_879d0d6c |
879d0d6c -> 16663b2a |
0ddc38e5 |
sec2026_PART1_b39e34c8 |
b39e34c8 -> 0ddc38e5 |
d6ca2bda |
sec2026_PART1_1f5a7f25 |
1f5a7f25 -> d6ca2bda |
| 组件 | 已确认逻辑 |
|---|---|
| 输入整形 | token.encode("ascii") * 2 形成 16-byte 明文块 |
| 预处理 1 | state ^= PRE_XOR_MASK |
| 预处理 2 | state ^= INIT_XOR |
SubBytes |
使用运行时恢复的自定义 256-byte S-box |
permute_round(round_idx) |
不是标准置换,而是“按列重排 + 递推字节流异或” |
shift_rows |
是自定义方向,不是标准 AES 方向 |
mix_columns |
GF(2^8) 上的自定义线性层,约化多项式是 0x71 |
add_round_key |
不仅异或轮密钥,还异或 ((round_idx * 0x5b) + row) & 0xff 这一层偏置 |
| 尾处理 | state ^= FINAL_XOR |
| Token | 正向输出 |
|---|---|
35bddf45 |
flag{sec2026_PART2_f1f025a5f11ea16bf1da0eeed81ab2cc} |
1440cbd9 |
flag{sec2026_PART2_2f2c727a1941317644ddfab5be75fb90} |
b83894bf |
flag{sec2026_PART2_ce0c9388bb33d29cc014892533b6db3a} |
db4ff573 |
flag{sec2026_PART2_439ea68fbdb0653e760e305b560ce8c3} |
0af8d3ee |
flag{sec2026_PART2_aa761e018840980c6d442ae640e8bdbd} |
| 后缀 | 恢复 Token |
|---|---|
f1f025a5f11ea16bf1da0eeed81ab2cc |
35bddf45 |
2f2c727a1941317644ddfab5be75fb90 |
1440cbd9 |
ce0c9388bb33d29cc014892533b6db3a |
b83894bf |
439ea68fbdb0653e760e305b560ce8c3 |
db4ff573 |
aa761e018840980c6d442ae640e8bdbd |
0af8d3ee |
| Token | 正向输出 |
|---|---|
cd779bb7 |
flag{sec2026_PART3_09495e9eb8c4f6b4} |
5fedf124 |
flag{sec2026_PART3_4bf93aac888ff600} |
b0a8714f |
flag{sec2026_PART3_ef67dae4f56442e9} |
8f14b3d6 |
flag{sec2026_PART3_ec909d2bcbb1ead1} |
38897a4a |
flag{sec2026_PART3_16cf679ddbe8c2ee} |
ff5f9bf5 |
flag{sec2026_PART3_6a913474062fb50a} |
fd150fbd |
flag{sec2026_PART3_cfd132411cda99d6} |
| 后缀 | 恢复 Token |
|---|---|
09495e9eb8c4f6b4 |
cd779bb7 |
4bf93aac888ff600 |
5fedf124 |
ef67dae4f56442e9 |
b0a8714f |
ec909d2bcbb1ead1 |
8f14b3d6 |
16cf679ddbe8c2ee |
38897a4a |
6a913474062fb50a |
ff5f9bf5 |
cfd132411cda99d6 |
fd150fbd |
| 编号 | 检测机制 | 入口 | 关键证据 | 绕过位置 |
|---|---|---|---|---|
| 1 | 父子进程 ptrace 反调试链 | sub_99094 -> sub_9C654 | 0x990CC 的第一条 pthread_create 指向 sub_9C654。<br>sub_9C654 内直接出现 getpid、fork、waitpid、ptrace。<br>sub_95CC0、sub_95E3C 分别对应 GETREGSET、SETREGSET。 | 改 sub_99094 的第一处 pthread_create。<br>或让 sub_9C654 开头立即返回。 |
| 2 | 模块枚举与映射定位链 | sub_9B7D8 -> sub_96A00 / sub_9EFB4 | 0x96A74 调 dl_iterate_phdr,0x9F1EC 调 strstr。<br>静态可解出 libgodot_android.so 与 /proc/self/maps。<br>同线程后续在 0x9BCC4 调 mprotect。 | 只改 sub_9EFB4 命中后的异常归因块。<br>或把 0x9F1EC 的命中路径改成忽略异常模块。 |
| 3 | /proc/self/fd 解析与 linjector 检测 | sub_9B7D8 -> sub_99CC8 / sub_9A0D0 | 0x99D84 为 opendir,0x99EF8 为 readdir。<br>0x99530 经 sub_9AD3C 发起 readlinkat,0x9A104 为 lstat。<br>静态恢复出 /proc/self/fd、/proc/self/fd/%s、linjector。 | 改 0x9A048 解出的关键字缓冲区。<br>或改 0x9973C 到 0x997A0 的匹配状态转移。 |
| 4 | task/status 线程状态扫描 | loc_9CDC4 状态机线程 | 静态解出 /proc/self/task、/proc/self/task/%s/status、gum-js-loop、gmain。<br>代码路径回收到 opendir、readdir、openat、read、close。 | 改 0x9DA8C 与 0x9D16C 解出的关键字缓冲区。<br>或改 0x9E488 到 0x9E4F8、0x9DF5C 到 0x9DFAC 的匹配状态转移。 |
| 5 | 单调时钟差值 watchdog | sub_9AD68 | 0x9AE98 与 0x9AECC 两次采样 CLOCK_MONOTONIC。<br>0x9AF08 与 0x9AF14 组出阈值 0x989680。<br>0x9AF24 执行超时比较。 | 改 0x9AF08 到 0x9AF14 的阈值常量。<br>或改 0x9AF24 到 0x9AF3C 的比较结果。 |
| 6 | 原生 exit_group 自杀口 | 多条异常出口 | 明确 kill gate 为 0x96BB8、0x96BC4、0x9A1DC、0x9E9C0。<br>功能性 syscall wrapper 与 kill gate 已可区分。 | 只改这 4 个 kill gate 的控制流。<br>保留其余功能性 syscall wrapper。 |
| wrapper | 偏移 | 指令特征 | 主要用途 |
|---|---|---|---|
| sub_9AD3C | 0x9AD3C | MOV X8, X0; ...; SVC 0; RET | 六参数直 syscall;当前主要承载 openat、readlinkat 等 |
| sub_9AD20 | 0x9AD20 | MOV X8, X0; ...; SVC 0; RET | 三参数 read |
| sub_9CB30 | 0x9CB30 | MOV X8, X0; ...; SVC 0; RET | close |
| 阶段 | 动作 | 目的 | 结果 |
|---|---|---|---|
| 1 | 使用 spawn --pause 启动,不把 attach 当主路线 | 先于主线程恢复布置最小探针 | 主线程恢复前即可就位 |
| 2 | 只在 pthread_create、android_dlopen_ext、strstr 这三个外侧位置下窄目标 hook | 避免过早直钩库内注册链 | 先看到线程、加载、模块比较三类事件 |
| 3 | 从 pthread_create 中识别三条守卫线程 | 区分 ptrace、状态机、phdr/fd 三条链 | 后续可以按职责分别处理 |
| 4 | 只把 thread_ptrace_fork_watch 替换成空线程 | 压掉纯反调试线程,不破坏初始化 | 父子进程 ptrace 链被稳定旁路 |
| 5 | 保留 thread_state_machine_watch 与 thread_phdr_fd_watch | 两条线程混有初始化职责,粗暴 noop 会崩 | 进程能继续走到主场景 |
| 6 | 仅在 libsec2026.so 发起的 strstr 比较里改写 haystack | 避免命中 frida memfd 这类危险字符串 | 危险输入被伪装成正常系统模块路径 |
| 7 | 等待 android_dlopen_ext 与模块出生完成后,再确认 libsec2026.so 基址和关键入口 | 避免在最敏感窗口过早下库内直钩 | 后续可以安全转入对象层、脚本层和 VM 观察 |
| 8 | 对四个已确认 exit_group kill gate 做控制流 patch | 命中异常分支后不会立即自杀 | 进程保留继续分析的窗口 |
| 9 | 不整条删除 dl_iterate_phdr、/proc/self/maps、/proc/self/fd、mprotect 主链 | 检测链里混着主体运行逻辑 | 只修危险输入和 kill gate,主逻辑保留 |
| 10 | 在窗口稳定后再进入绿块、红块、隐藏块和 VM 主线 | 第一章所有样本、截图、trace 都依赖这一步 | Part1、Part2、Part3 可以持续推进 |
| 文件名 | 对应内容 | 作用说明 |
|---|---|---|
| 关键脚本/脚本01_启动期反调试旁路.js | 第 1 章、第 3 章 | 在 spawn 窗口里旁路 ptrace 线程并改写可疑模块路径,建立可工作的动态入口。 |
| 关键脚本/脚本02_Part1绿色块传送取样.js | 第 1.2 节 | 定位车辆与绿色块,完成对象层传送,并读取左上角 Token 与右上角 Part1 flag。 |
| 关键脚本/脚本03_Part2红块碰撞开启与传送.js | 第 1.3 节 | 打开红块碰撞条件,把车辆送入红块区域,获取 Part2 现场样本。 |
| 关键脚本/脚本04_Part2红块现场w7跟踪.js | 第 1.3 节 | 在真实撞块现场跟踪脚本层调用链,收口到 trigger3 的 _w7。 |
| 关键脚本/脚本05_Part2_Process白盒探针.js | 第 1.3 节、第 2.2 节 | 对 GameExtension.Process 做 direct probe,核对文本输入边界和 32 hex 输出。 |
| 关键脚本/脚本06_Part3_label2函数对象导出.js | 第 1.4 节 | 导出 label2 运行时函数对象,证明它只负责显示与拼接,不承担 Part3 核心算法。 |
| 关键脚本/脚本07_Part3_trigger4函数对象导出.js | 第 1.4 节 | 导出 trigger4 的方法、属性、信号与常量池,确认其职责更接近状态推进。 |
| 关键脚本/脚本08_Part3隐藏块触发与工作区跟踪.js | 第 1.4 节、第 2.3 节 | 打开隐藏块条件、触发 Part3,并同步记录 VM 工作区与右上角 flag。 |
| 关键脚本/脚本09_Part3轨迹时间线整理.py | 第 1.4 节、第 2.3 节 | 把 VM 工作区跟踪日志整理为时间线,辅助还原 28 轮执行过程。 |
| 关键脚本/脚本10_Part3迷你反汇编.py | 第 1.4 节、第 2.3 节 | 对导出的 VM 记录做轻量反汇编,输出更便于写白盒算法的伪指令序列。 |
| 文件名 | 对应内容 | 作用说明 |
|---|---|---|
| 关键日志/日志01_启动期终止口观测.txt | 第 3 章 | 记录 exit、abort、assert 等高层终止接口观测结果,用来区分 kill gate 与常规库接口。 |
| 关键日志/日志02_Part1_trigger2入口探针.txt | 第 1.2 节 | 记录 trigger2 的方法表与 _fe 相关调用结果,用来确认 Part1 脚本入口。 |
| 关键日志/日志03_Part1_native调用链跟踪.txt | 第 1.2 节、第 2.1 节 | 记录 Part1 从脚本层进入 native Process 的参数与返回值,用来校对 _fe 和 native 边界。 |
| 关键日志/日志04_Part2_live_w7_trace.txt | 第 1.3 节 | 记录红块现场 _w7 的 live trace,支撑 Part2 的脚本入口定位。 |
| 关键日志/日志05_Part2_Process_direct_probe.txt | 第 1.3 节、第 2.2 节 | 记录对 Process 的 direct probe 结果,用来确认输入是文本字节而不是 _h2b(token)。 |
| 关键日志/日志06_Part3_label2函数对象导出.txt | 第 1.4 节 | 记录 label2 运行时函数对象和常量池,用来剥离 Part3 的显示层职责。 |
| 关键日志/日志07_Part3_trigger4函数对象导出.txt | 第 1.4 节 | 记录 trigger4 运行时方法、属性、信号与常量信息,用来重建隐藏块上层调用链。 |
| 关键日志/日志08_Part3_VM_dispatch_ctx.txt | 第 1.4 节、第 2.3 节 | 记录 VM dispatch 上下文,用来确认工作区地址、轮数推进和关键寄存状态。 |
| 关键日志/日志09_Part3_隐藏块出分工作区跟踪.txt | 第 1.4 节、第 2.3 节 | 记录隐藏块真机出分时的工作区变化,直接支撑 Part3 白盒算法恢复。 |
- 3.1 启动期总览
- 3.2 机制一:父子进程 ptrace 反调试链
- 3.3 机制二:目标模块枚举与映射定位链
- 3.4 机制三:/proc/self/fd 目标解析与 linjector 关键字检测
- 3.5 机制四:/proc/self/task/%s/status 线程状态 anti-Frida 扫描
- 3.6 机制五:单调时钟差值 watchdog
- 3.7 机制六:原生 svc #0 自杀口
- 3.8 启动期库内直钩与注册期时序敏感窗口
- 3.9 最终绕过执行流程
project.binaryassets.sparsepcktoken.gdcTrigger/*.gdc.gdextension
- 题面直接说明存在四种方块、车辆、左右上下载具操作
- 这意味着真实场景对象、碰撞体、Label 文本都能成为动态切入点
libsec2026.soextension_initVMEntry- 多条可疑导入:
ptrace、dl_iterate_phdr、opendir/readdir/lstat
sub_A82C8sub_A8F00(round_idx)sub_AADE8sub_A6F20sub_AAB64(round_idx)
sub_A82C8sub_A8F00(11)sub_AADE8sub_AAB64(11)
- 本质是把输入块和一层固定 16-byte 掩码异或
- 可以直接写成:
state ^= PRE_XOR_MASK- 常量为:
1d7e8816cf2dff7171ff2dcf16887e1d
- 表现为另一层固定 16-byte 常量异或
- 可以直接写成:
state ^= INIT_XOR- 常量为:
de4f8a37c16b59e273ad1f94b806d542
- 是尾部固定异或
- 可以直接写成:
state ^= FINAL_XOR- 常量为:
7ce32891a65df014bb6907d84a35ec80
- 对 16-byte state 逐字节查表
- 对应一张运行时生成的自定义
S-box - 因而可以确定这是
SubBytes
- 只做索引搬移
- 对应的是自定义方向的
ShiftRows
- 是 GF(2^8) 上的 4x4 线性层
- 约化多项式不是 AES 的
0x1b,而是0x71 - 轮矩阵为:
- 不是普通置换
- 本质是“按列重排 + 递推字节流异或”
- 其中递推字节流满足:
k0 = (0x47 - 0x63 * round_idx) & 0xffk_{n+1} = (0x2f - 0x3d * k_n) & 0xff
- 不只是异或 round key
- 还会额外异或一层行偏置:
((round_idx * 0x5b) + row) & 0xff
SubBytespermute_roundshift_rowsmix_columnsadd_round_key
SubBytespermute_roundshift_rowsadd_round_key
v0_final || v1_finalv1_final || v0_final
- 只拦
pthread_create - 当
start_routine == sub_9C654时,把它替换成空线程 - 其余线程保持不动
- 直接在
sub_99094把第一处pthread_create改为跳过 - 或者让
sub_9C654开头立即返回
sub_99094(0x99094)在0x990CC处第一次pthread_create的start_routine就是sub_9C654(0x9C654)- 同一函数在
0x990E4和0x990FC分别再创建loc_9CDC4与sub_9B7D8
0x9C69C:BLR X8; getpid0x9C6AC:BLR X8; fork0x9C820、0x9C95C、0x9CA0C:BLR X8; ptrace0x9C8A8、0x9C9E0:BLR X8; waitpid
sub_95CC0(0x95CC0)在0x95D48调ptrace(PTRACE_GETREGSET, ..., 1026, ...)sub_95E3C(0x95E3C)在0x95E64调ptrace(PTRACE_SETREGSET, ..., 1026, ...)
- 只 hook
libc.so!strstr - 只处理
libsec2026.so发起的调用 - 只处理
haystack含frida/gum/gmain/gdbus/linjector/memfd:的情况 - 把
haystack改写成与当前needle对应的正常系统路径,例如/system/lib64/libgodot_android.so
- 在
sub_9EFB4的比较分支里,把“未知模块 -> 异常”改成“未知模块 -> 忽略” - 保留
"/proc/self/maps"与mprotect主链,只去掉异常模块命中后的归因和 kill 传播
"libgodot_android.so""/proc/self/maps"
sub_96A00(0x96A00)在0x96A74调dl_iterate_phdrsub_9EFB4(0x9EFB4)是 PHDR 回调,0x9F1EC为strstr调用点0x9BE98通过sub_9AD3C发起openat("/proc/self/maps", ...)0x9BCC4为真实mprotect
- 不去 hook libc 的
readlinkat,因为这里走的是库内 direct syscall wrapper - 直接拦
sub_9AD3C - 仅当 syscall 号为
0x4E且路径前缀为"/proc/self/fd/"时,篡改返回缓冲区里的可疑目标
- 把
sub_9A0D0中的符号链接异常分支改成普通分支 - 把
"linjector"命中的状态写回改成安全状态 - 保留
opendir/readdir/readlinkat/lstat自身流程不动,只改最终异常归因
"/proc/self/fd""/proc/self/fd/%s""linjector"
0x99D84:opendir0x99EF8:readdir0x99530:sub_9AD3C->readlinkat0x9A104:lstat
- 不去全局 hook libc 的
open / read - 只拦库内的 direct syscall wrapper:
sub_9AD3C、sub_9AD20、sub_9CB30 - 只对
"/proc/self/task/%s/status"打开的 fd 生效 - 在读回缓冲区后把
gum-js-loop / gmain改成安全名字
- 保留
opendir/readdir/openat/read/close主链 - 只把
"gum-js-loop"/"gmain"命中后的异常状态写回改成安全状态 - 或直接让命中分支改成忽略
"/proc/self/task""/proc/self/task/%s/status""gum-js-loop""gmain"
0x9D050:opendir0x9DA0C:readdir0x9DB10:sub_9AD3C->openat0x9D854:sub_9AD20->read0x9DBF0:sub_9CB30->close
- 缩短 attach 窗口
- 避免在热点路径挂重型常驻 hook
- 不要一上来就全局拦
syscall
- 把阈值
0x989680调大 - 让第二次比较前始终刷新基线
- 或者直接把“超时 -> 异常”的状态切换改成“超时 -> 继续”
0x9AE94:MOV W8, #0x710x9AE98:SVC 00x9AEC8:MOV W8, #0x710x9AECC:SVC 00x9AEB4:把第一次采样基线写入qword_1834B80x9AF08 + 0x9AF14:拼出阈值0x9896800x9AF24:CMP X0, X10
0x989680 = 10000000,单位是微秒,即约10秒- 这条 worker 的职责就是两次单调时钟采样后计算差值,并把超时结果送回状态机
0x96BB8:B loc_96B840x96BC4:B loc_96B840x9A1DC:RET0x9E9C0:B loc_9E99C
0x9AD34:sub_9AD20内的SVC 00x9AD50:sub_9AD3C内的SVC 00x9AE98 / 0x9AECC:watchdog 的两次时间采样0x9B09C:功能性SVC 00x9CB48:sub_9CB30内的SVC 00x9EB70:功能性SVC 0
- 资源层信号:
project.binaryassets.sparsepcktoken.gdcTrigger/*.gdc.gdextension
- 对象层信号:
- 题面直接说明存在四种方块、车辆、左右上下载具操作
- 这意味着真实场景对象、碰撞体、Label 文本都能成为动态切入点
- native 层信号:
libsec2026.soextension_initVMEntry- 多条可疑导入:
ptrace、dl_iterate_phdr、opendir/readdir/lstat
- 资源层负责解决“脚本归属”和“方法名字”。
- 对象层负责解决“怎么真实触发”和“真实样本是什么”。
- native 层负责解决“检测机制是什么”和“最后的白盒算法怎么写”。
- 只观察
libdl.so!android_dlopen_ext和模块出生时,进程可以继续存活 - 一旦在
libsec2026.so内部关键点过早下 inline hook,进程往往会在注册期前后直接终止
thread_ptrace_fork_watch可以单独旁路thread_state_machine_watch单独旁路不会立刻崩thread_phdr_fd_watch不能整体noop,否则会直接Bad access
- 仅旁路
thread_ptrace_fork_watch - 保留
thread_phdr_fd_watch - 只对
strstr的可疑模块名做 haystack 改写
- 只旁路
thread_ptrace_fork_watch,不整体删掉thread_phdr_fd_watch。 - 只在
libsec2026.so发起的strstr比较里改写可疑模块路径,把/memfd:frida-agent-64.so (deleted)伪装成正常系统模块名。
- 沿 GDExtension 注册链枚举类和方法。
- 观察
GameExtension.Process(PackedByteArray) -> String这类 native 接口。 - 判断 32 位十六进制中间值是否能直接折叠成
Part1后缀。
43201333021:黄色示例方块。43251664672:绿色Part1方块。43318773540:红色Part2方块。43385882408:隐形Part3方块。
43251664672的确是绿色Part1真得分块。- 右上角输出并不是离线构造出来的,而是现场撞块直接出现的真实结果。
- 后续所有脚本分析都必须回到这组现场样本上来对齐。
_h2b_rf_xb_b2h_fe
hex string -> bytes- 基于 key/round 的字节级处理
- 字节异或
bytes -> hex string- 最终封装函数
Part1的真实入口就是trigger2.gd::_fe。- 绿色块线路并不要求先把
libsec2026.so里的 VM 作为主分析对象。 - native
GameExtension.Process虽然仍然参与中间态计算,但它不是最适合拿来做第一性定位的入口。
_h2b明确把 8 位 hex token 变成 4 个原始字节_rf明确做“字节 + key + round”的局部混合_xb明确是逐字节异或_b2h明确把结果重新转回 hex
GameExtension.Process返回的是 32 位 hex 中间态。_fe返回的才是最后的sec2026_PART1_xxxxxxxx。- 因此只盯 native 输出,会把自己带进“32 hex 如何再压成 8 hex”的错误方向。
35bddf45 -> flag{sec2026_PART2_f1f025a5f11ea16bf1da0eeed81ab2cc}1440cbd9 -> flag{sec2026_PART2_2f2c727a1941317644ddfab5be75fb90}b83894bf -> flag{sec2026_PART2_ce0c9388bb33d29cc014892533b6db3a}db4ff573 -> flag{sec2026_PART2_439ea68fbdb0653e760e305b560ce8c3}0af8d3ee -> flag{sec2026_PART2_aa761e018840980c6d442ae640e8bdbd}
_ready的global_names里直接出现_w7 | body_entered | connect;_w7的常量池里直接出现"/root/TownScene/Label2"、"/root/TownScene/Label"、"flag{"、"_PART2_";_w7的global_names里直接出现text、str、substr、Process。
_ready表现出典型的碰撞信号连接逻辑;_w7直接携带Part2的字符串模板;_w7同时出现 UI 文本读取和 nativeProcess调用。
body_enteredconnect_w7
- 常量池中出现
"/root/TownScene/Label2"、"/root/TownScene/Label"、"flag{"、"_PART2_"。 - 全局名中出现
text、str、substr、Process。
- 控制碰撞开关的对象层函数;
- 做场景树遍历的辅助函数;
- 再套一层
Part1风格的_rf/_xb/_b2h脚本链。
- 读取
Label和Label2; - 从
Label.text中截取 token; - 调用
_gx.Process(...); - 把结果按
flag{sec2026_PART2_...}的格式写回Label2.text。
_ready()负责把红块碰撞信号接到_w7;_w7()负责把Label -> token -> Process -> Label2这条链推进到底。
Part2也许会把 8 位 hex token 先转成 4 个原始字节。- 或者至少会先走
hex_decode()之类的路径。
_w7喂给 nativeProcess的不是 4-byte token 原值。- 输入是 8 个十六进制字符本身的 ASCII/UTF-8 字节。
- 也就是
"35bddf45"被当成[0x33, 0x35, 0x62, 0x64, 0x64, 0x66, 0x34, 0x35]使用。
_w7负责拼 flag,但它本身没有再对Process返回值做切片或折叠。- 这说明真正的 32 hex 后缀就是 native 直接算出来的。
- 既然上层输入和输出边界都已经钉死,那么继续追 native 轮函数就是低风险、高收益的下一步。
sub_A7944sub_AAB64(round=0)- round 1..10 循环:
sub_A82C8sub_A8F00(round_idx)sub_AADE8sub_A6F20sub_AAB64(round_idx)
- round 11:
sub_A82C8sub_A8F00(11)sub_AADE8sub_AAB64(11)
sub_A84A4
- 输入预处理
sub_AA9B0- 本质是把输入块和一层固定 16-byte 掩码异或
- 可以直接写成:
state ^= PRE_XOR_MASK- 常量为:
1d7e8816cf2dff7171ff2dcf16887e1d
sub_A7944- 表现为另一层固定 16-byte 常量异或
- 可以直接写成:
state ^= INIT_XOR- 常量为:
de4f8a37c16b59e273ad1f94b806d542
sub_A84A4- 是尾部固定异或
- 可以直接写成:
state ^= FINAL_XOR- 常量为:
7ce32891a65df014bb6907d84a35ec80
sub_A82C8- 对 16-byte state 逐字节查表
- 对应一张运行时生成的自定义
S-box - 因而可以确定这是
SubBytes
sub_AADE8- 只做索引搬移
- 对应的是自定义方向的
ShiftRows
sub_A6F20- 是 GF(2^8) 上的 4x4 线性层
- 约化多项式不是 AES 的
0x1b,而是0x71 - 轮矩阵为:
sub_A8F00- 不是普通置换
- 本质是“按列重排 + 递推字节流异或”
- 其中递推字节流满足:
k0 = (0x47 - 0x63 * round_idx) & 0xffk_{n+1} = (0x2f - 0x3d * k_n) & 0xff
sub_AAB64- 不只是异或 round key
- 还会额外异或一层行偏置:
((round_idx * 0x5b) + row) & 0xff
- 输入不是 4-byte token 原值,而是
8-byte ASCII token - 把这 8 个 ASCII 字节重复两次,形成
16-byte明文块 - 先做
PRE_XOR_MASK - 再做
INIT_XOR - round 0 先做一次
AddRoundKey - round 1..10 每轮执行:
SubBytespermute_roundshift_rowsmix_columnsadd_round_key
- round 11 执行:
SubBytespermute_roundshift_rowsadd_round_key
- 最后再做
FINAL_XOR - 输出 32 位 hex,并由上层脚本拼成
flag{sec2026_PART2_...}
trigger3._w7负责读取Label.text.substr(7)、把 token 变成文本字节、调用Process、再拼回Label2sub_97704 -> sub_A936C -> sub_A7900 -> sub_A7194负责真正的 16-byte 块变换- 最终输出后缀就是这条 native 变换的直接结果
- 先解决红块无碰撞属性。
- 先用对象层把限制因素打掉,拿到真样本。
- 再回到脚本层定位
_w7。 - 最后通过输入模型纠偏,把 native 侧完整白盒收口。
- 父
Area3D.monitoring = false - 父
Area3D.monitorable = false - 父
Area3D.scale = (1,1,1) - 子
CollisionShape3D.disabled = true
- 上游到底是谁把这 16 位后缀算出来的
- 这 16 位后缀是如何从 token 演化出来的
- 它是一个 UI 聚合器。
- 它负责订阅多个
Trigger的collided_with信号。 - 上游谁发来字符串,它就显示谁。
- 先用脚本列表接口确认
trigger4.gd到底暴露了什么; - 再对
_m3、_ready、_process这几个方法继续读取GDScriptFunction的code / constants / global_names。
- 方法:
_m3()、_ready()、_process(_d) - 属性:
_f0、_f1、_tv、_ix、_gx、_rv - 信号:
collided_with(name)
- 方法列表来自
get_script_method_list()的返回值; - 属性列表来自
get_script_property_list()的返回值; - 信号列表来自
get_script_signal_list()的返回值。
- 负责隐藏块显隐、状态推进、碰撞启用。
- 在条件满足后,通过
collided_with(name)把某个字符串往label2送。 - 它自身并不像
trigger2._fe、trigger3._w7那样直接暴露完整字符串算法。
trigger4.gd:负责“什么时候能触发”。label2.gd:负责“触发后显示什么”。- native VM:负责“真正 16 hex suffix 是怎么算出来的”。
- 对象层继续负责拿样本、做截图、验证触发条件
- 脚本层继续负责确认信号是怎么接起来的、字符串是怎么送到 Label2 的
- native 层继续负责最后的数学结构恢复
- 隐形块的真实触发条件。
- 多组真实
token -> suffix样本。 label2只是显示层的结论。trigger4更偏向状态推进层的结论。
0xAA564:注册opcode 0x65 ('e') -> VMEntry0xAA588:注册opcode 0x66 ('f') -> vm_dispatch_opcode_f
VMEntry负责输入侧;vm_dispatch_opcode_f负责输出侧;- 真正的运算过程应该落在两者之间的 VM 工作区推进里。
record0:start=0x10000,len=0x4000,flags=0x5record1:start=0x14000,len=0x8000,flags=0x3record2:start=0x1c000,len=0x1000,flags=0x3
record0是程序/字节码区;record1是主工作区;record2是 scratch/辅助区。
vm_dispatch_opcode_f不是最终算术核心;- 它承担的是“从 VM 句柄/引用里取出两个 32-bit word,再格式化成 hex”;
- 因而真正的逆向重点必须继续落回
record1 / record2的阶段推进过程。
record0 / record1 / record2的区间和权限;opcode 101 / opcode 102的宿主语义;0x14000 ~ 0x14088这一组主工作槽的阶段快照;0x1cfc8 / 0x1cfd0 / 0x1cfd8这一组三元 scratch 窗口。
stage=1不是正式 round,而是 seed 阶段;stage>=2进入重复的 round body;0x14000 ~ 0x14080是主状态槽;0x1cfc8 / 0x1cfd0 / 0x1cfd8是轮尾 rolling scratch;round_index = stage - 1。
stage=1时,前半个 token half-block 已经被 packed 进主工作区;- 从
stage=2 -> stage=3开始,下一轮开头的某些状态槽直接继承上一轮尾部状态; 0x1cfc8这一路 scratch 会按固定步长滚动,表现出典型的 round-sum 特征;- 把这些滚动关系和静态常量块对齐之后,可以把轮函数压成双字 ARX / TEA-like 变体,而不是散装状态机。
- 先通过
vm_init_state_blobs和注册点把opcode 101/102锁死; - 再通过 record 描述符把
record0 / record1 / record2的职责锁死; - 再通过
vm_dispatch_opcode_f入口 live 把最终输出载体和输出顺序锁死; - 最后用
0x14000 ~ 0x14088和0x1cfc8 ~ 0x1cfd8的阶段快照,把中间那条运算链压成 28 轮双字 ARX 模型。
- 先用对象层打开隐藏块多因素碰撞,拿到真样本。
- 再用资源/脚本层排除错误入口,明确
label2只是显示器。 - 最后回到 native VM,把工作区和轮函数完整白盒化。
- 不知道真样本是什么,难以约束输出。
- 不知道上层谁在实际显示 flag,很容易把 UI 层逻辑误判成算法层逻辑。
- 先排除“是否只改一个碰撞因素就够”
- 再排除“是否
label2本身在生成 flag” - 再排除“是否
trigger4直接在脚本里拼完后缀” - 最后才把剩余所有证据收束到 native VM
Part1:通过trigger2.gd::_fe确认脚本主入口,并把 helper 链拆成 8 轮 Feistel。Part2:先恢复红块单因素碰撞,再由trigger3.gd::_w7把输入边界收缩到文本字节,随后继续追到 native 主算法。Part3:先恢复隐藏块多因素触发条件,再排除label2与trigger4的算法职责,最后把问题收束到 native VM 工作区与轮函数。
left = raw[:2]right = raw[2:]
- 先和轮偏移后的 key 字节异或。
- 再做一次乘
7后加round_idx的 8-bit 线性变换。 - 最后做 3 bit 左旋。
- 运行时直接调用
_fe(token),精确返回真机Part1样本。 trigger2.gd的 helper 链_h2b -> _rf -> _xb -> _b2h -> _fe已被运行时枚举和局部 probe 验证。- Python 版与 C++ 版对真实样本都能正算、逆推。
- 红块真机碰撞触发拿到了真实
token -> flag样本。 _w7已经证明它只是Label.text.substr(7) -> to_utf8_buffer()/to_ascii_buffer() -> _gx.Process -> 拼 flag。- 直接 probe 已经证明
_h2b(token)、hex_decode()都不命中,只有 ASCII/UTF-8 输入和真样本一致。 - Python 版与 C++ 版对所有真实样本均可正算、可逆推。
Part1把 token 当 4-byte 原始值处理Part2把 token 当 8-byte ASCII 并复制成 16-byte 明文块Part3则把 token 拆成两个 4-char ASCII half,分别作为两个 32-bit 状态字
- 状态始终是两个 32-bit 词
v0 / v1 - 每轮先更新
sum - 再以
v1生成混合量更新v0 - 再以新的
v0生成混合量更新v1
- 用多组
token -> suffix真样本同时校验 - 穷举轮数
1..64 - 对每个轮数同时测试两种输出顺序:
v0_final || v1_finalv1_final || v0_final
- 轮数必须是
28 - 输出顺序必须是
v1_final || v0_final
- 从
sum = 28 * DELTA开始 - 先撤销
v1的更新 - 再撤销
v0的更新 - 最后
sum -= DELTA
- 隐形块多因素 patch 后,真机已经能稳定显示
Part3flag label2.gd被排除为纯显示层,因此后缀不可能来自 UI 拼接- native worktrace 已经证明输入确实先被按 ASCII half 打包,再在 VM 中推进
- 轮数、常量和输出顺序经过多组真样本同时约束,只有
28轮和v1||v0这一种组合能全部命中 - Python 版与 C++ 版都已通过样本自测
sub_9C654(0x9C654),下文记为thread_ptrace_fork_watchloc_9CDC4(0x9CDC4),下文记为thread_state_machine_watchsub_9B7D8(0x9B7D8),下文记为thread_phdr_fd_watch
thread_ptrace_fork_watch直接承载ptrace / fork / waitpidthread_state_machine_watch承载 task/status 线程扫描thread_phdr_fd_watch同时承载 PHDR、maps、fd 与 kill gate 相关状态
thread_state_machine_watch与thread_phdr_fd_watch都承载了多条输入源,因此正文按“检测链”而不是按“线程”拆分。thread_phdr_fd_watch内部在0x9BCC4可见mprotect,说明同一线程兼带页权限相关职责,因此正文只写局部补丁落点,不写整线程删除方案。- 为便于评委核对,正文的“确认机制”只统计上表这
6条;工程性补充放在后文单独说明。
getpidfork- 多个
waitpid - 多个
ptrace
sub_95CC0(0x95CC0):ptrace(PTRACE_GETREGSET, pid, 1026, ...)sub_95E3C(0x95E3C):ptrace(PTRACE_SETREGSET, pid, 1026, ...)
0x9C69C:getpid0x9C6AC:fork0x9C820:一处ptrace0x9C8A8:一处waitpid0x9C95C:一处ptrace0x9C9E0:另一处waitpid0x9C9EC:调用sub_95CC00x9CA0C:另一处ptracesub_95CC0内读PTRACE_GETREGSETsub_95E3C内读PTRACE_SETREGSET
- 父子进程互相建立 trace 关系,排斥外部调试器
- 观察子进程停顿/异常状态,判断是否被第三方接管
- 直接读写寄存器集,验证执行上下文是否被篡改
- 动态低噪声绕过:
- 只拦
pthread_create - 当
start_routine == sub_9C654时,把它替换成空线程 - 其余线程保持不动
- 只拦
- 静态绕过:
- 直接在
sub_99094把第一处pthread_create改为跳过 - 或者让
sub_9C654开头立即返回
- 直接在
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|




