|
|
[讨论]IDA Pro代码破解揭秘
另外,IDA PRO 权威指南及其第二版也是非常好的书;要把IDA 用好用精非读它不可,少了这本书,自己钻研IDA的许多高级功能也相当花时间。 |
|
|
[讨论]IDA Pro代码破解揭秘
51cto 站点的下载频道有 IDA PRO 代码破解揭秘的 PDF 版,以及该书的配套源码资源 具体可以访问 down.51cto.com 下面是我搜到的资源列表 
|
|
|
各种HTTPS站点的SSL证书 ,密钥交换和身份验证机制汇总(含SSL握手实战!)
例如,我们下载并且安装了 BurpSuite 开发公司的 SSL 证书(PostSwigger CA)作为本地操作系统上的“受信任的根证书颁发机构”: 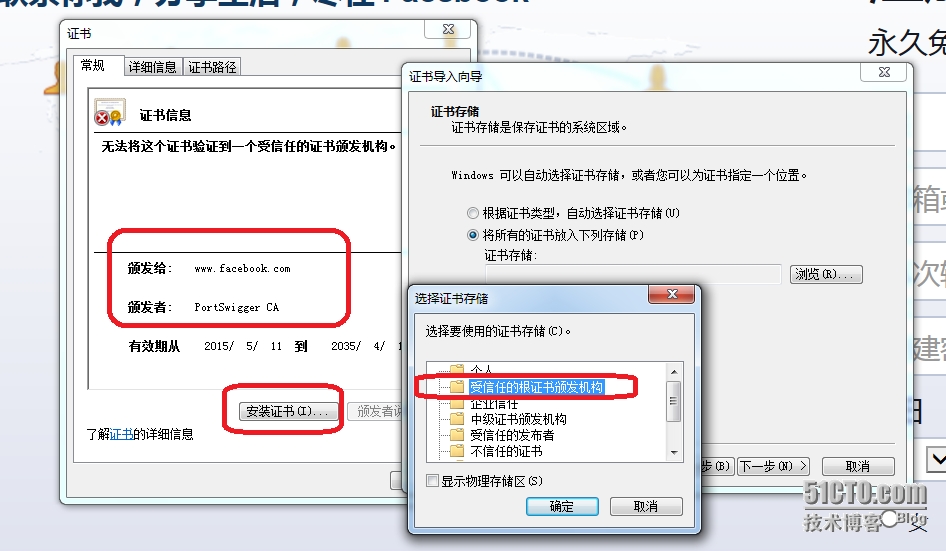 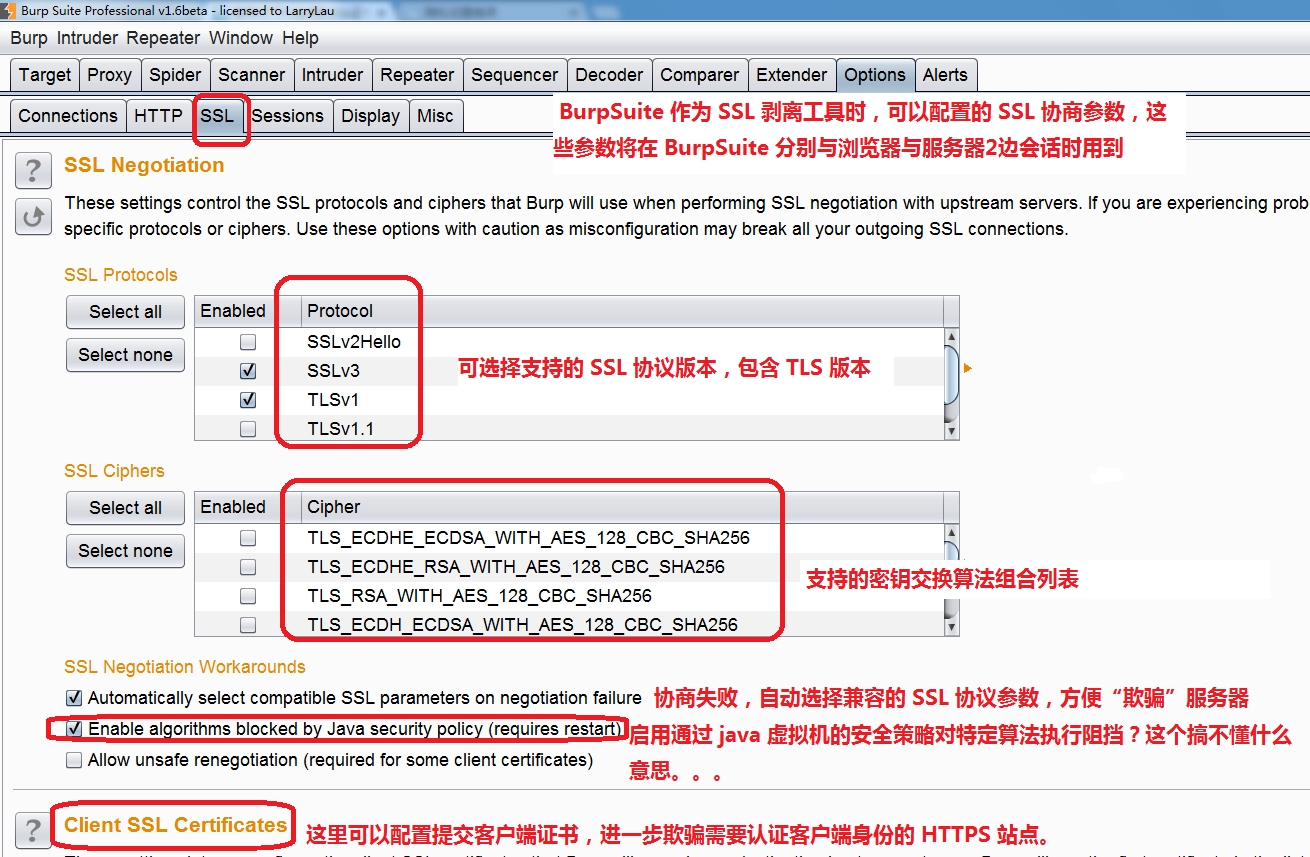 上面这一招对普通的 HTTPS 站点有效,例如 https://www.google.com.tw ,但是对 facebook 则无效,因为 facebook 使用了“HTTPS 严格传输安全”(HTTPS Strict-Transport-Security,HSTS),强制要求浏览器使用 HTTPS 与其进行通信,不能提供给用户忽略有问题的证书的选项。而实际上也是如此,在使用 BurpSuite 充当中间 SSL 代理时,Chrome 与 FireFox 都不会“上当”,它们知道服务器(BurpSuite )返回的证书是伪造的,因此拒绝与其建立 HTTPS 连接,并且遵循 HSTS 规范,禁止用户忽略有问题的证书: 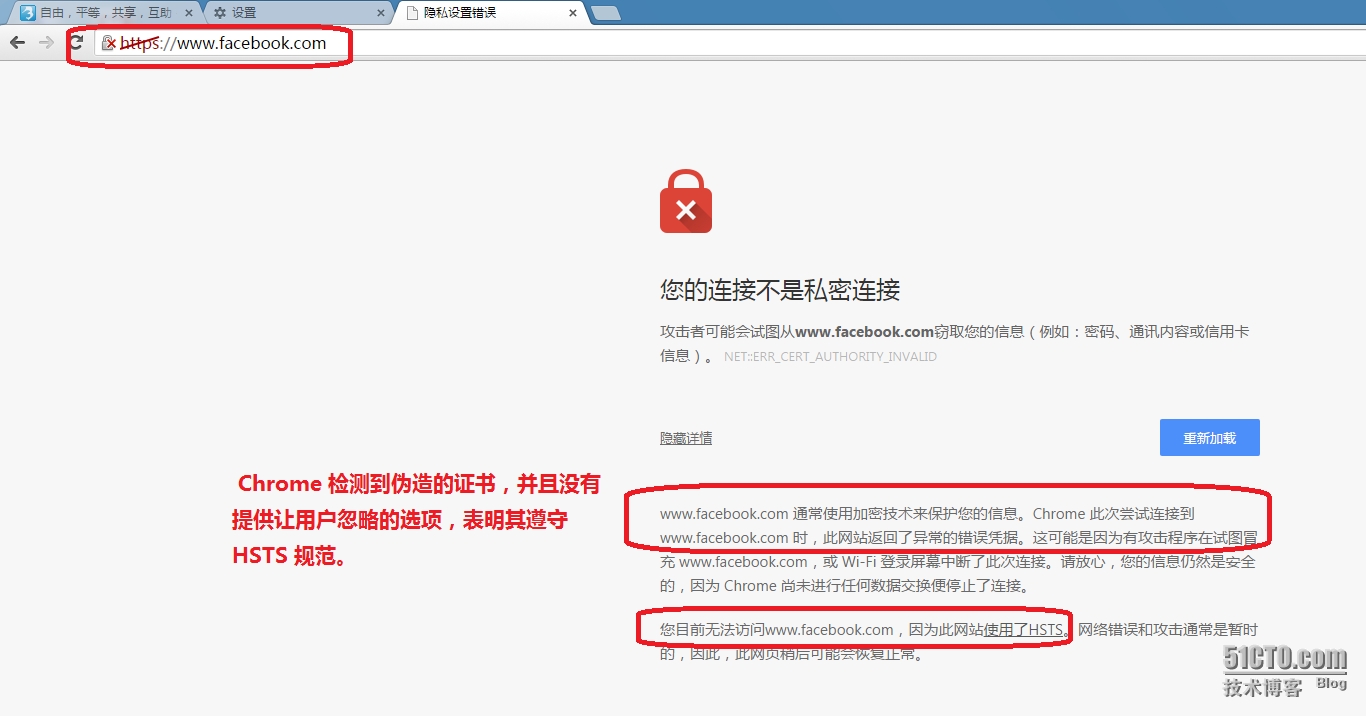 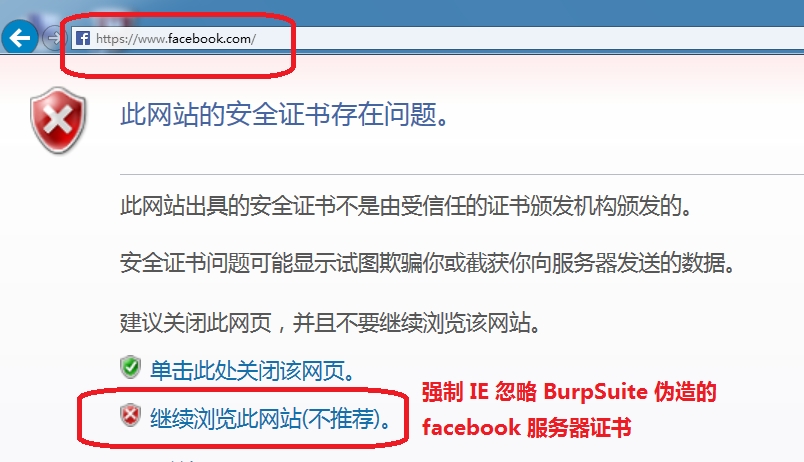 
|
|
|
[原创]Windows下的无线热点蜜罐
蜜罐通常是用来引诱入侵者与攻击者上钩,进而对其调查,取证,并将其阻挡在外的部署环境。而这里讲的免费的馅饼wi-fi热点,更像是无线钓鱼平台,引诱普通人上钩! |
|
|
[分享]《Windows 内核设计思想》看雪论坛独家连载,附PDF下载
话说只有访谈过windows系统架构师们的《深入解析windows操作系统》丛书才能窥探这个软件工程史上奇迹般的商业系统的设计思想,不过该书第6版下册中文版迟迟不出,是翻译遇到困难还是其它情况就不得而知了,现在考虑自行翻译阅读了 |
|
|
web基础设施知识;web前端安全攻防,客户端安全基础
1。BurpSuite 在 web 安全以及渗透测试领域的强大威力; 2。服务器除了可以在响应头中设置 cookie 外,也可以在响应体中的 HTML 文档的 script 标签内设置 cookie,2 种方式设置的 cookie 会被总合起来作为当前页面文档的 cookie; 3。没有指定 HttpOnly 属性的任何 cookie ,在 FireFox 中均可以用 document.cookie 读取(Chrome 的沙箱模型对于 javascript 代码的执行环境有严格限制,即便没有设置 HttpOnly 属性,默认情况也不能读取页面文档的 cookie) 首先在 BurpSuite Proxy 拦截到的 bws 响应数据中,切换到 “HTML”视图,这将仅显示响应体中的 HTML 文档,然后在最底部的搜索框中输入“</head>”字符串,目的是定位其后的 body 元素,并且在该元素的现有 script 标签内部插入自定义代码,模拟注入场景:  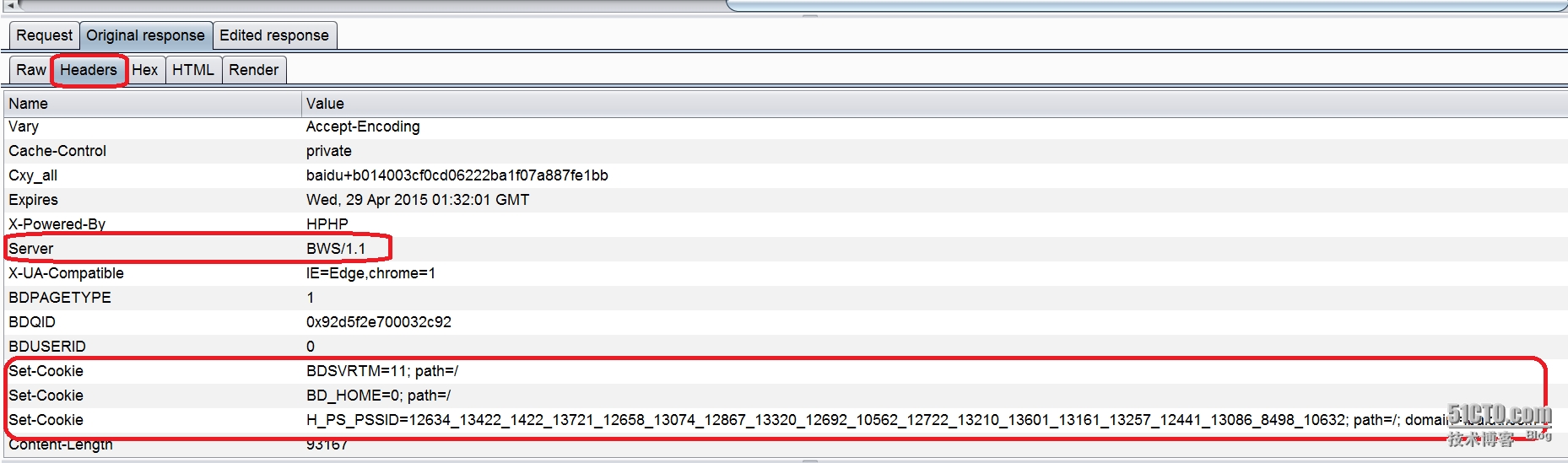 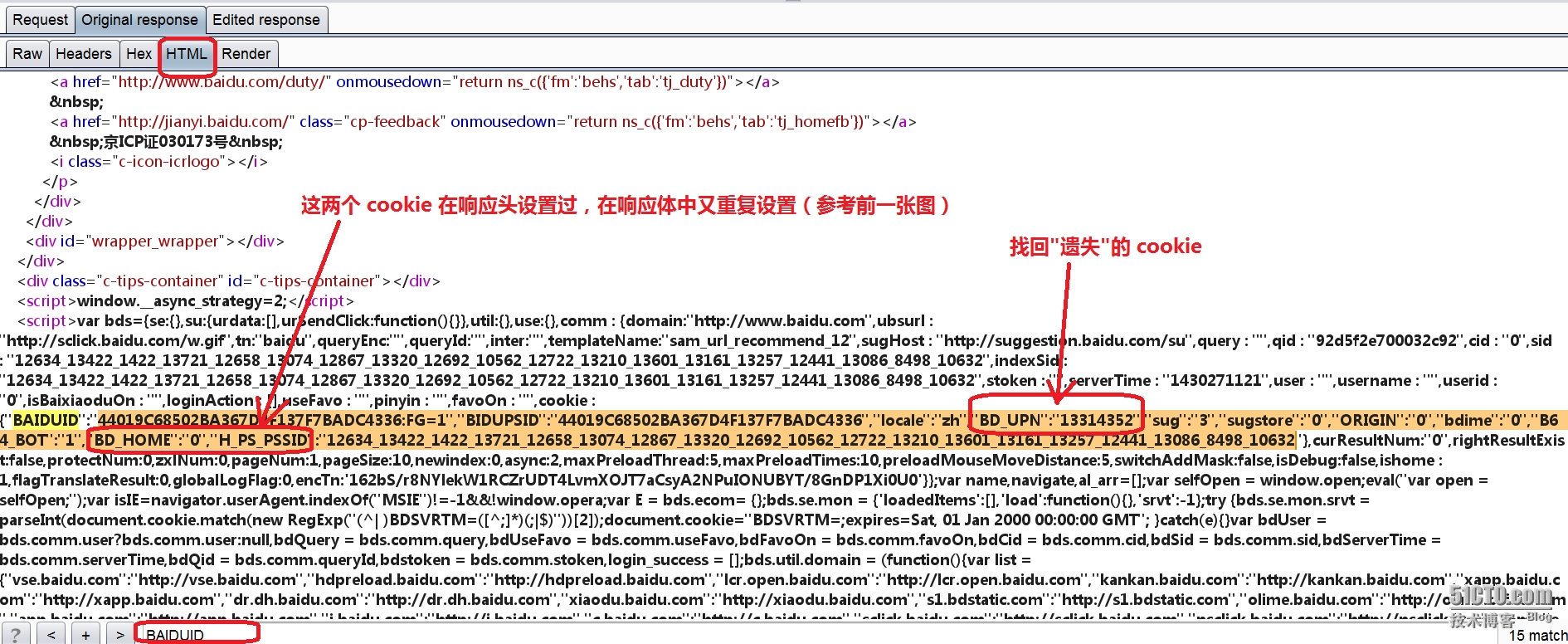  |
|
|
web前端安全基础与攻防(续篇)
假设用于生成短信链接的输入框的初始 HTML 代码如下: <a href="></a> 1。双引号元素属性闭合; 2。 onmouseover 事件结合 eval 函数执行任意代码; 3。对 URL 进行 UTF-16 编码绕过 XSS 防火墙; 4。利用社会工程学攻击来引诱用户点击链接; http://t.co@" style="font-size:99px;" onmouseover="eval(location.href='http:\u002f\u002fwww.baidu.com\u002f')" class/ 为了增强链接的视觉诱惑性,我在 a 元素的 innerHTML 中,添加了名为“邀请码发放页面”的文本节点(请勿在论坛中尝试!),最终的注入效果(即存储到服务器上的漏洞页面)如下所示: <!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=UTF-8" />
<title>XssPayloadTest</title>
</head>
<body >
<a href="http://t.co@" style="font-size:99px;" onmouseover="eval(location.href='http:\u002f\u002fwww.baidu.com\u002f')" class/">邀请码发放页面</a>
</body>
</html>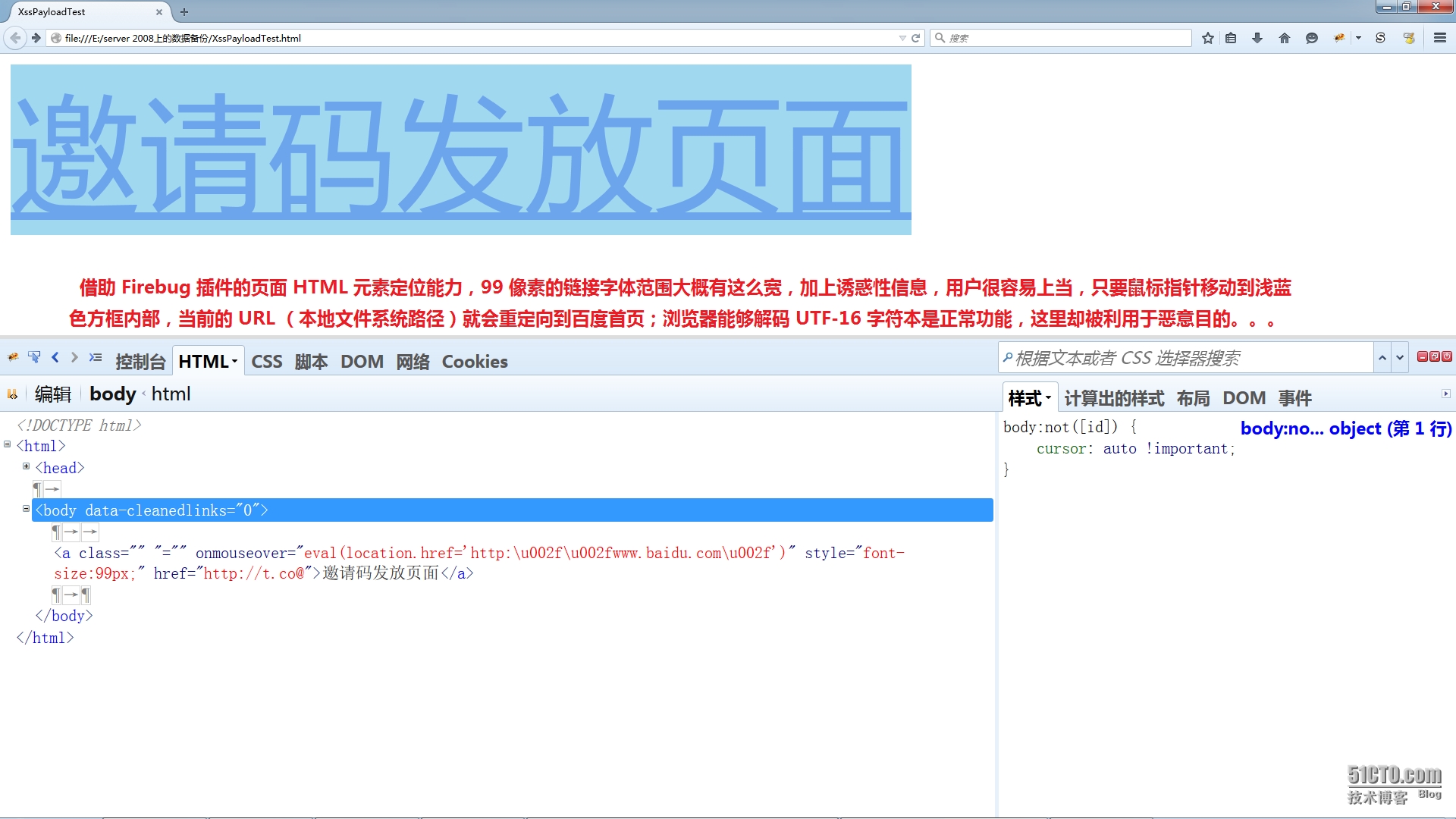
|
|
|
web前端安全基础与攻防(续篇)
实现逻辑如下: <!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=UTF-8" />
<title>XssPayloadTest</title>
</head>
<body>
<script>
document.write(navigator.userAgent);
document.write("<br><br>");
var isIE = navigator.userAgent.indexOf('Trident') > 0;
var isChrome = navigator.userAgent.indexOf('Chrome') > 0;
var isFirefox = navigator.userAgent.indexOf('Firefox') > 0;
var isOpera = navigator.userAgent.indexOf('OPR') > 0;
if (isIE){
document.write('<b>您使用的是IE浏览器</b>');
}else if (isChrome){
if (isOpera){
document.write('<b>您使用的是Opera浏览器</b>');
}else{
document.write('<b>您使用的是Chrome浏览器</b>');
}
}else if (isFirefox){
document.write('<b>您使用的是Firefox浏览器</b>');
}else{
document.write('<b>您使用的是其它浏览器</b>');
}
</script>
</body>
</html>第8行直接在当前页面输出打开该页面的浏览器的用户代理字串;第11~14行分别查找各种浏览器的用户代理字串中,能够唯一识别浏览器类型的关键词,这是由于,在早期的“浏览器世界大战”中,许多 web 页面的特定内容仅支持 Netscape Navigator 浏览器(网景公司的产品,其 “Mozilla” 字串就是它首创的,含义为“Mosaic Killer”,即浏览器鼻祖 Mosaic 的杀手),而其它品牌浏览器为了提高自身市场份额与竞争力,也在其用户代理中添加了“Mozilla”字串,用于告诉目标站点:“我是与 Mozilla 兼容的浏览器”,如此一来,站点就会返回原本仅响应给 Mozilla 浏览器的页面内容,而这个内容通常是比较丰富的; 最终效果就是, IE 浏览器的用户访问某站点获得的内容与 Netscape Navigator 浏览器的用户获得的内容一致,因为 IE 在它的用户代理字串中,添加了“Mozilla”字串。 其它浏览器相继模仿这个做法,导致通过“Mozilla”字串根本无法实际识别浏览器类型,所以,必须找到用户代理字串中,每个浏览器都不一样的关键词,这就是第11~14行代码的工作,例如第11行查找用户代理字串中的“Trident”,后者是 IE 浏览器的 HTML 渲染引擎内核代号,然后保存在一个变量中,第15~16行代码通过判断这个变量的值来输出用户使用的是 IE 浏览器(在实际开发时,应该把这里的内容替换成仅 IE 浏览器支持的页面代码,其它类型浏览器以此类推)。 另一方面,当前的 chrome 与 Opera 浏览器的用户代理字串中,都包含了“Chrome”关键词,所以仅凭它无法区分这2个浏览器,需要检查在包含“Chrome”关键词的用户代理字串中,是否含有“OPR”字串,如果有,则能识别出 Opera 浏览器,反之,则为 chrome 浏览器;而这就是第17~22行的嵌套 if-else 语句的工作。顺便提一下,这2个浏览器的 HTML 解析引擎内核都源于苹果公司开发 Safari 浏览器时的内核 WebKit;google 公司在 WebKit 的基础上开发出新的内核称为 Blink;这2个浏览器厂商“饮水思源”的做法导致你在使用这2个浏览器打开上述文档时,看到了各自的用户代理字串都包含“AppleWebKit”:   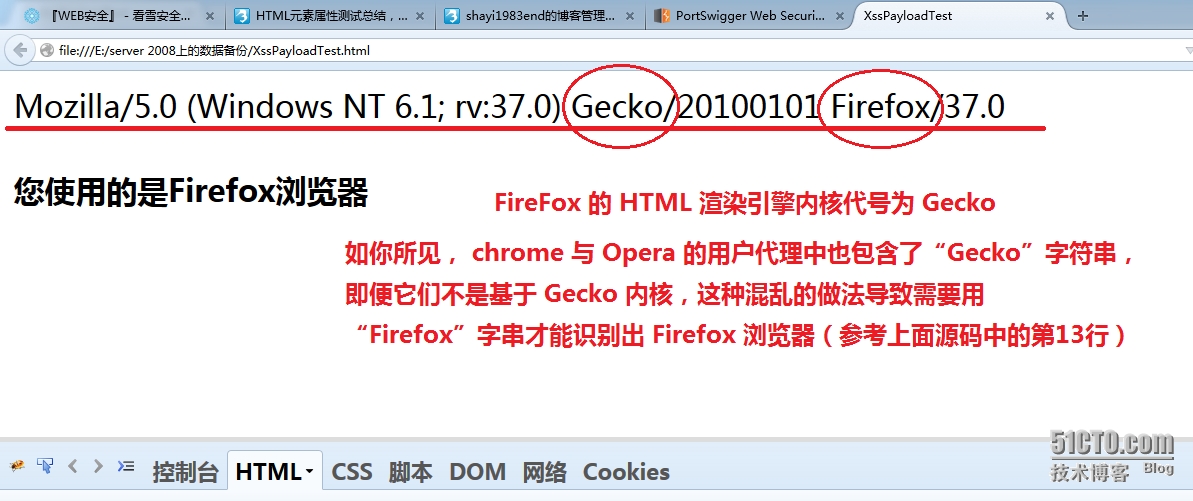  |
|
|
web前端安全基础与攻防(续篇)
UTF-7 编码是 unicode 编码的一类子集,后者包含的其它编码类型有 UTF-8,UTF-16LE(小端法,将代表编码字符的最低有效字节放在前面),UTF-16BE(大端法,将代表编码字符的最高有效字节放在前面),UTF-32LE,UTF-32BE 等等。在 UTF-7 编码方案中,左尖括号被编码成“+ADW-”;右尖括号被编码成“+AD4-”,其中的加号与减号分别标识着 UTF-7 编码序列的开始与结束;如果服务器端的 XSS 过滤器没有过滤这两个UTF-7 编码格式的左右尖括号,(或没有将其编码成其它无害形式的字符),并且客户端浏览器的版本过于老旧(例如 IE 7),那么当被注入攻击载荷的页面返回至客户端时,浏览器将解码 script 标签前后的 +ADW- 与 +AD4- 字符,还原成明文的左右尖括号,从而执行 script 标签内部的恶意代码: <!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html;charset=UTF-7" />
<title>XssPayloadTest</title>
</head>
<body>
+ADW-script+AD4-alert("xss")+ADW-/script+AD4-
</body>
</html>1。如果 web 服务器在返回的 HTTP Content-Type 响应头中,没有明确设置字符集编码,并且响应体中的 HTML 文档中的 meta 元素内,也没有设置字符集编码,那么浏览器在碰到任何 UTF-7 字符时,都会尝试确定其编码方案,并且解码还原成明文字符,以上述文档为例,就会弹出提示框; 2。如果 web 服务器在返回的 HTTP Content-Type 响应头中,明确设置字符集编码为 UTF-8,并且响应体中的 HTML 文档中的 meta 元素内设置的字符编码为 UTF-7,那么浏览器最终将按照响应头中的设置(响应头的优先级比响应体中 meta 标签的优先级高 ),以上述文档为例,不会弹出提示框(因为采用 UTF-8 字符编码时,浏览器无法识别,解码 +ADW- 与 +AD4- 字符); 3。如果 web 服务器在返回的 HTTP Content-Type 响应头中,设置字符集编码为 UTF-7,并且响应体中的 HTML 文档中的 meta 元素内设置的字符编码为 UTF-8, 根据浏览器的采用优先级原则,上述文档将会弹出提示框; 总结,应对 UTF-7 XSS攻击,从最终用户防御的角度来看,应该确保浏览器总是处在当前的最新版本状态;从 web 站点防御的角度来看,应该明确在响应头与响应体的 HTML 文档中,设置字符编码为 UTF-8 或者其它安全的编码方案; 对于每个包含HTML内容的响应,web应用需要在其中包含 Content-type 头部,并且用“charset=”指令设置一个标准的,(浏览器)可辨识的字符集, 例如: Content-Type: text/html; charset=utf-8 或者: Content-Type: text/html; charset=ISO-8859-1 (如前所述,还要确保响应中的所有可能位置指定了相同的字符集) 并且过滤掉任何 UTF-7 危险字符,如果没有把握通过编程屏蔽所有危害字符,则可以模仿浏览器的 HTML 解析引擎将用户输入的内容在内存中保留一份副本,将其渲染成 HTML 页面,在渲染结果中查找任何明文的危害字符,对其进行编码过滤,然后再次渲染,再过滤,直到完全清除干净后,才可以把最终的文档返回给客户端。 (这也是许多优秀的服务器端 XSS 过滤器,WAF 采用的工作模式) |
|
|
web前端安全基础与攻防(续篇)
什么样的实验?你们是互联网公司还是安全公司 |
|
|
|

操作理由
RANk
{{ user_info.golds == '' ? 0 : user_info.golds }}
雪币
{{ experience }}
课程经验
{{ score }}
学习收益
{{study_duration_fmt}}
学习时长
基本信息
荣誉称号:
{{ honorary_title }}
勋章
兑换勋章

证书
证书查询 >
能力值

