此帖是记录笔者研究Intel Management Engine 以及 Intel-SA-00086 安全漏洞的记录笔记。笔者也不知道能研究多深入,所以研究一点是一点,顺便发出来也给各位大佬参考以及讨论。(也是下班给自己找点事做,上班一直做Agent开发太无聊了)
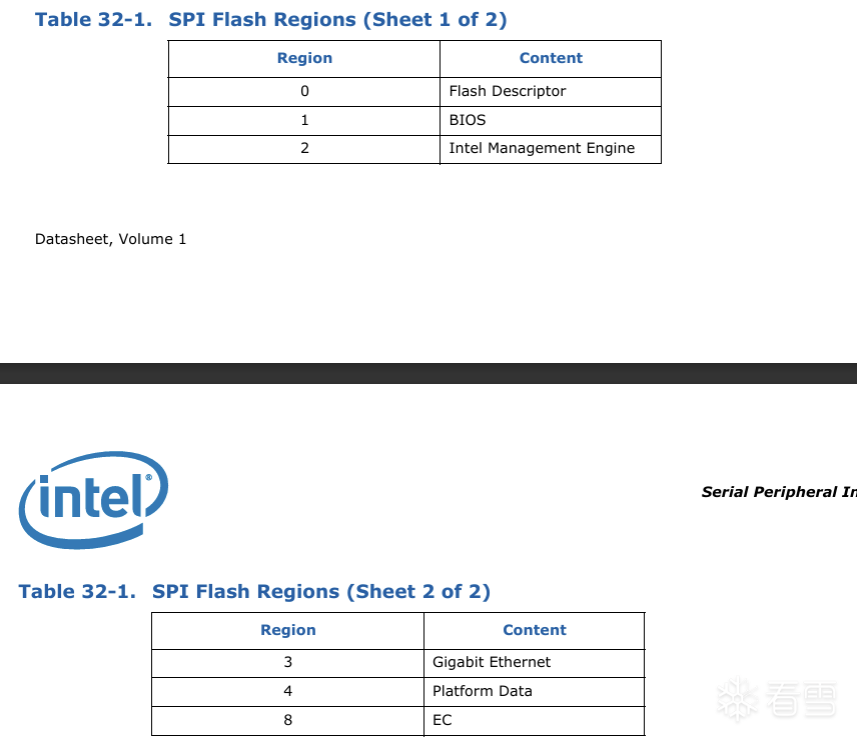
基于之前Kaokao那篇文章(具体可以去看github或者其他平台由相关参考)。Github仓公开爆料的是TXE平台,并没有我们常规的酷睿平台。由于在国内外网站没找到一模一样的硬件并且Intel和华硕官网都找不到相关硬件的固件和资料想要复现极难。
首先我们需要找到SPI芯片,并且Dump当前Bios中的数据。
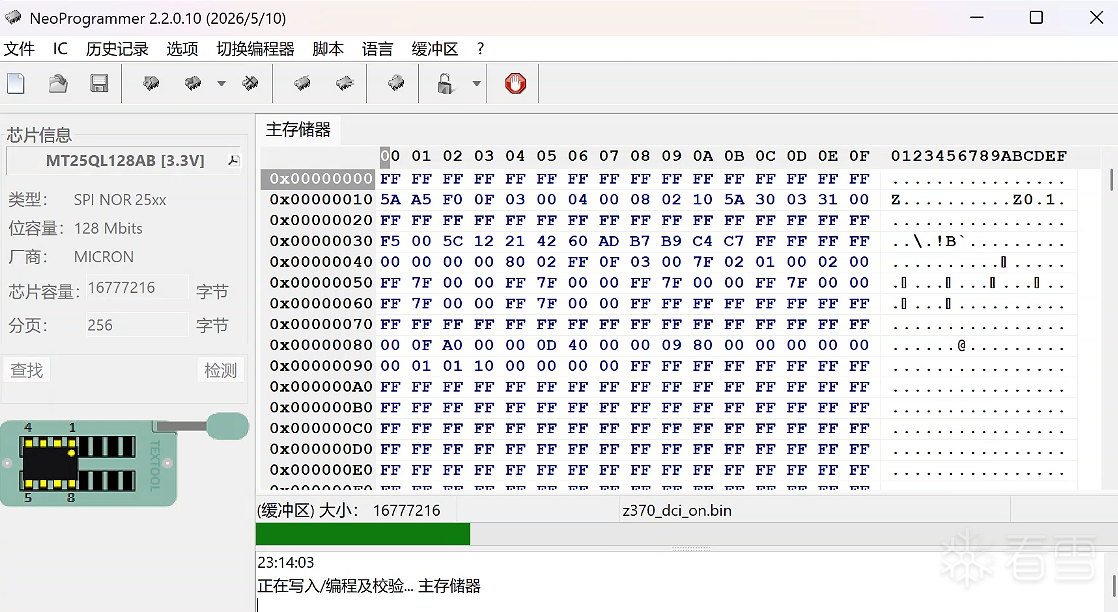
使用我们的NeoProgrammer工具Dump下来我们的文件
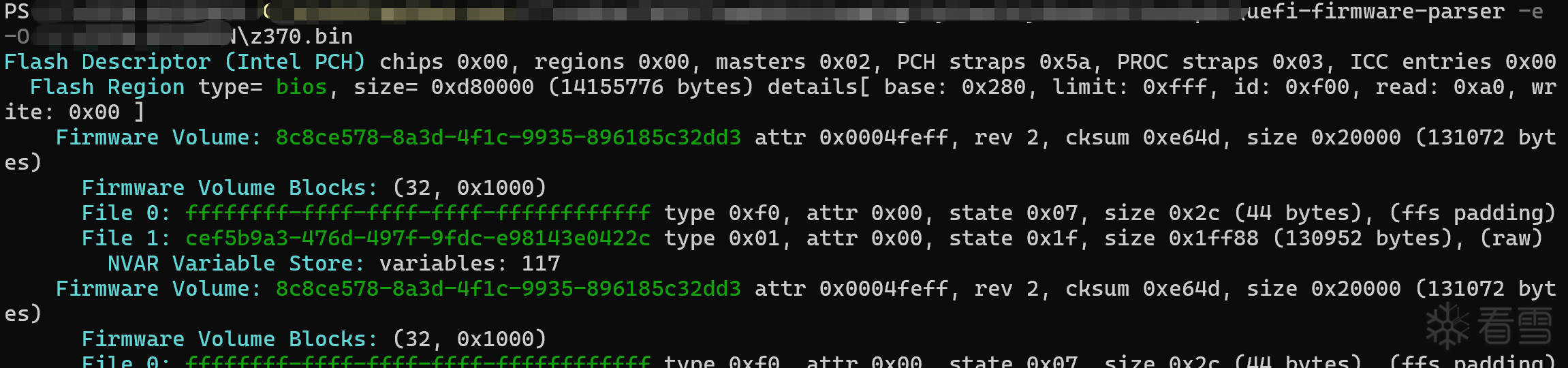
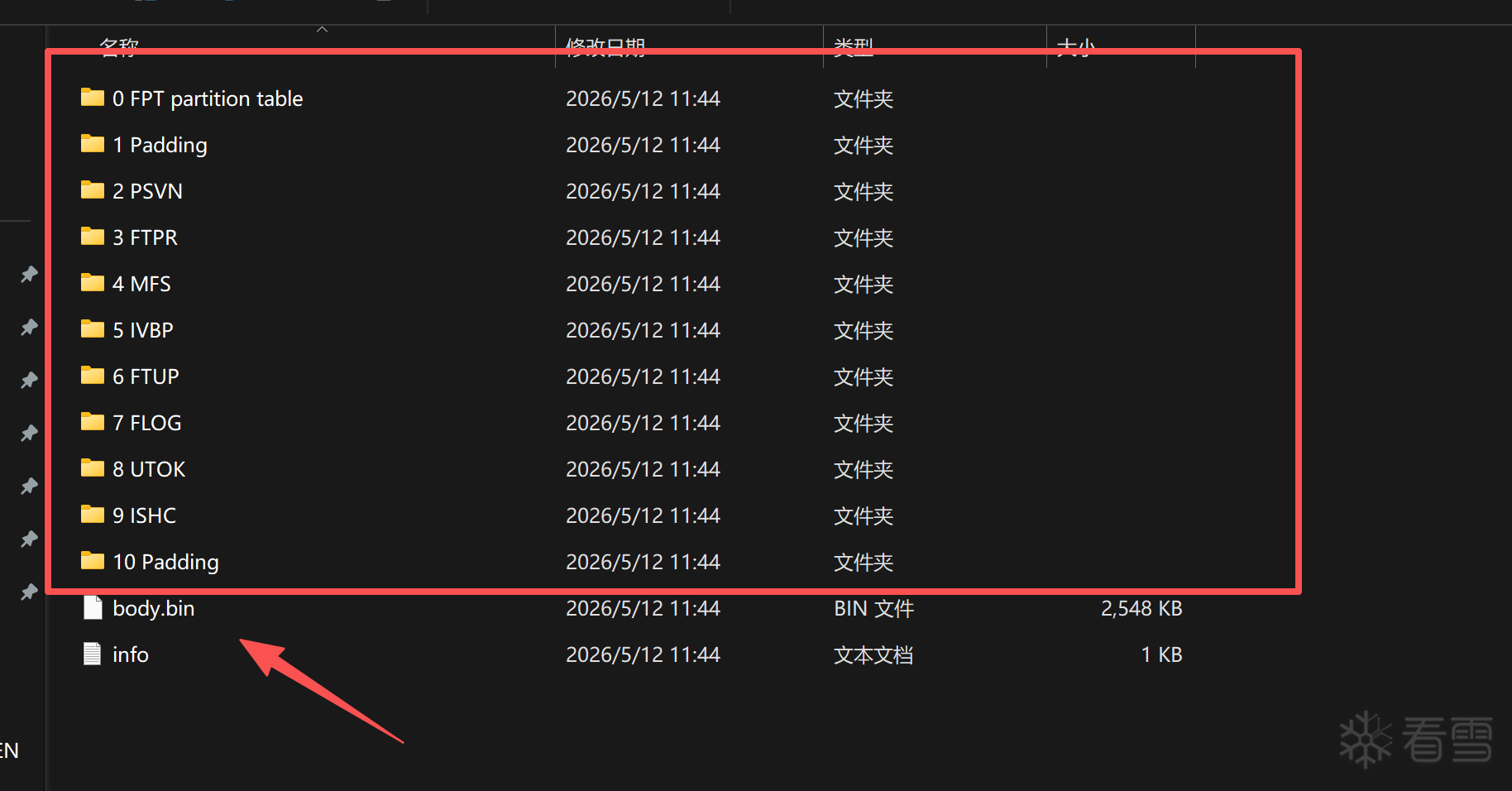
首先我们需要对dump数据进行解包,并且拿到我们的bios分区。在主板中并没有开启DCI接口的选项,所以我们需要通过魔改Bios来做到。
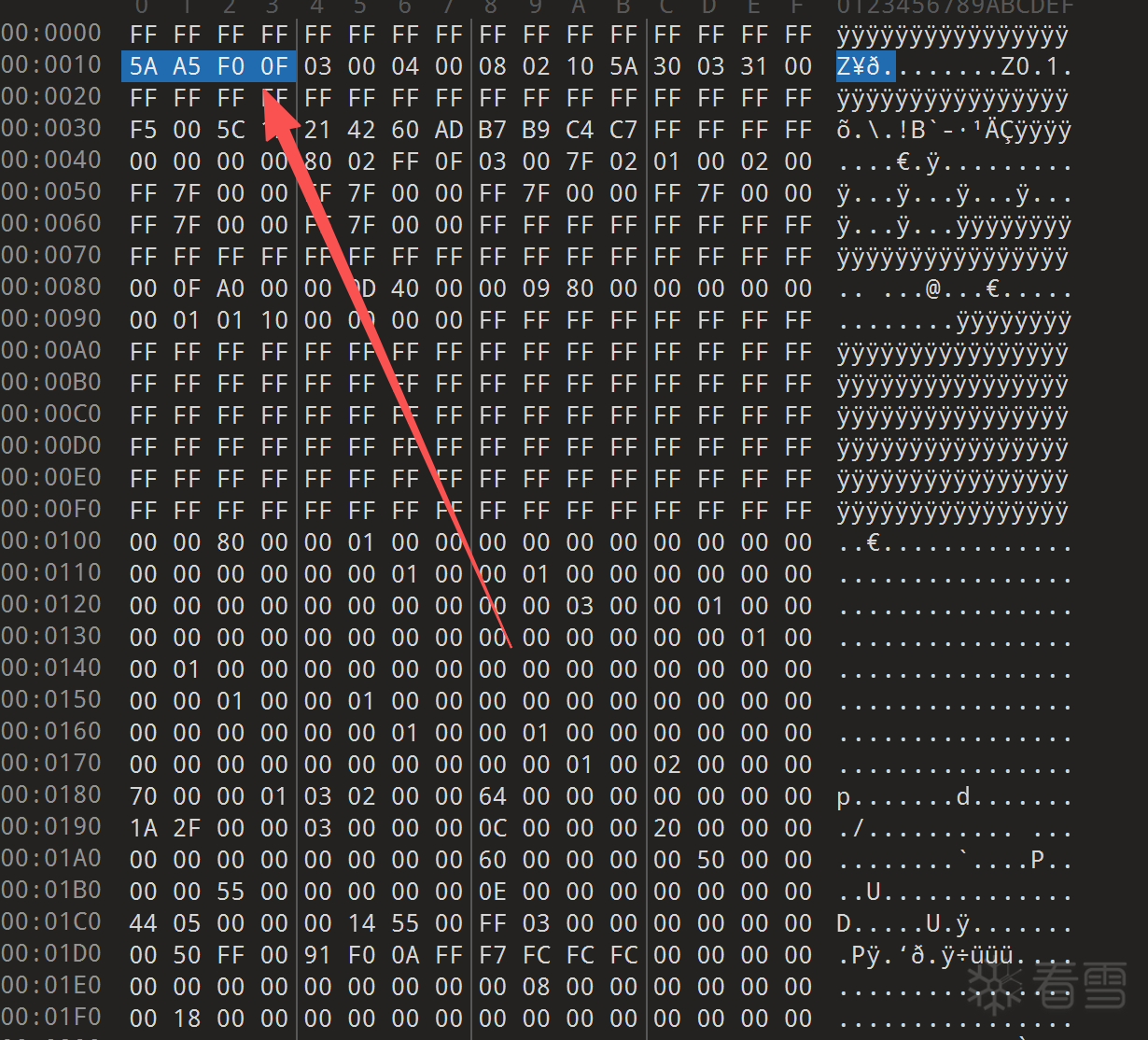
整理一下就如上表格,主要有魔术字段和FLMAP0偏移以及Region Table组成。有这些才能把Bios从Bin中切出来。
注意这个04实际上就是Offset指向 Region Table表。算法就是 0x04 << 4 = 0x40
所以地址就是0X280000,范围是 0XFFFFFF:
解包出来就是这个:
核心实际上就是这个:section0.pe
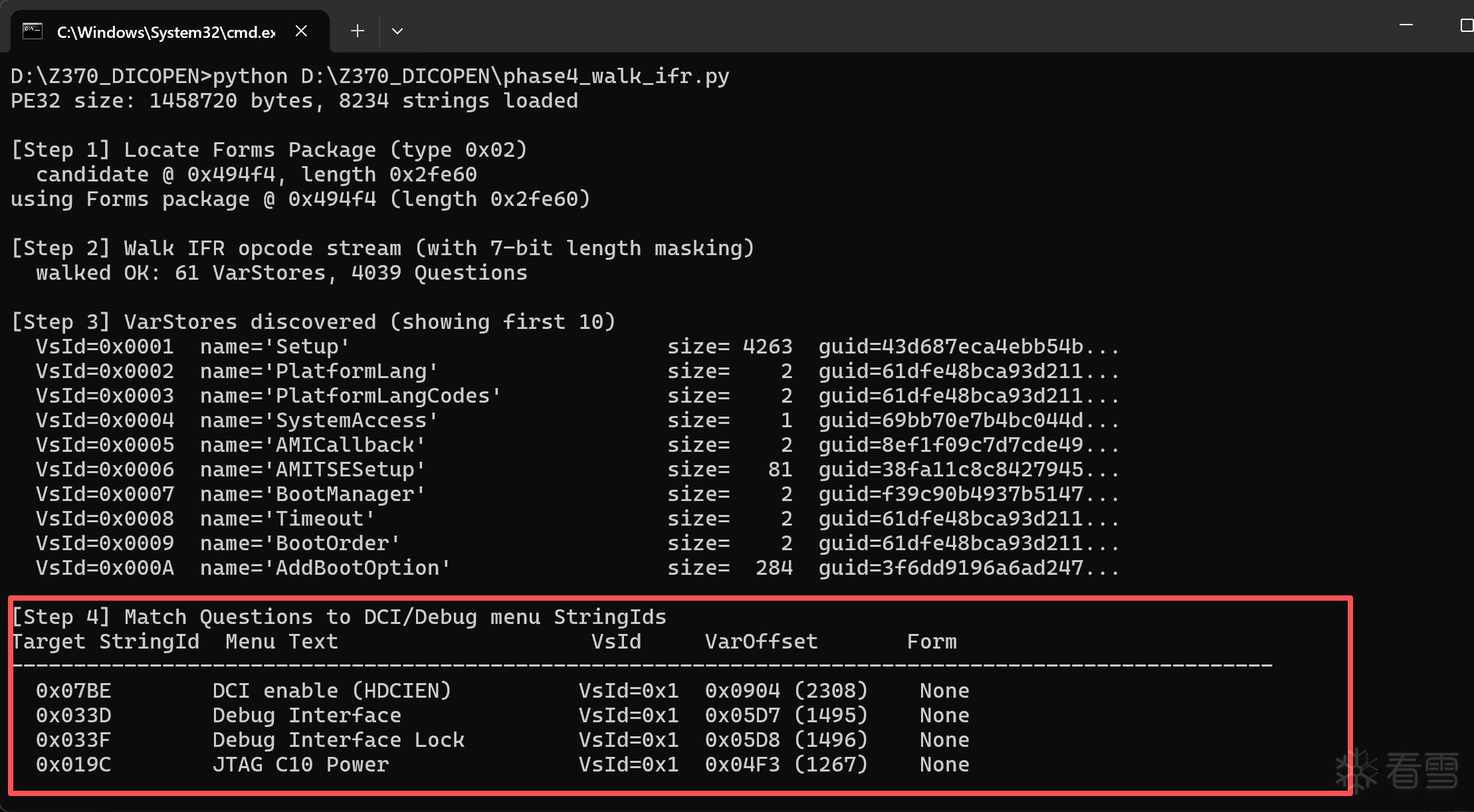
我们的核心就是解析 String Package 和 Forms Package 并且将他们映射起来,就能找到我们想要的开关。
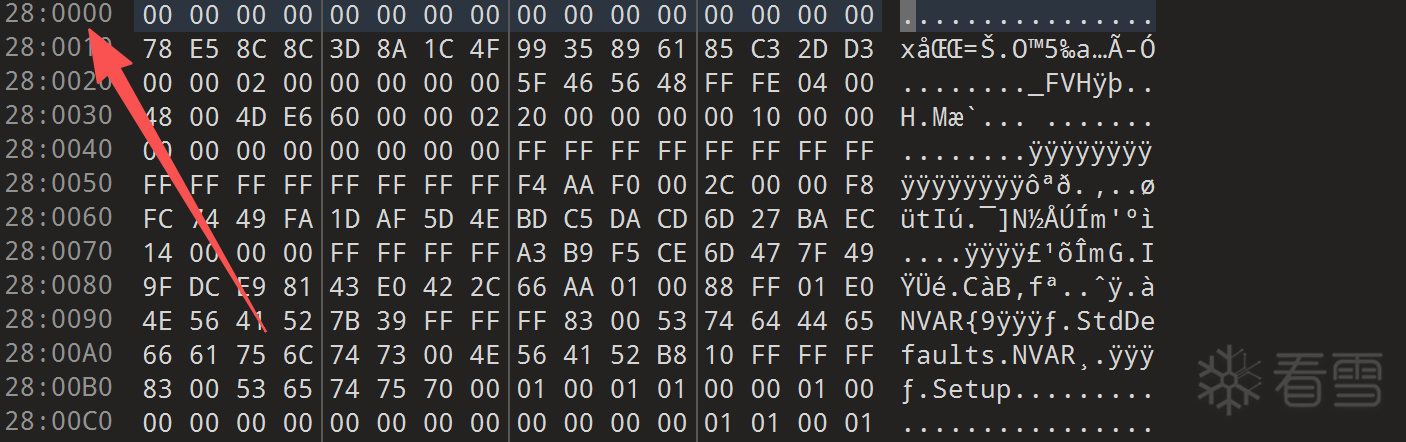
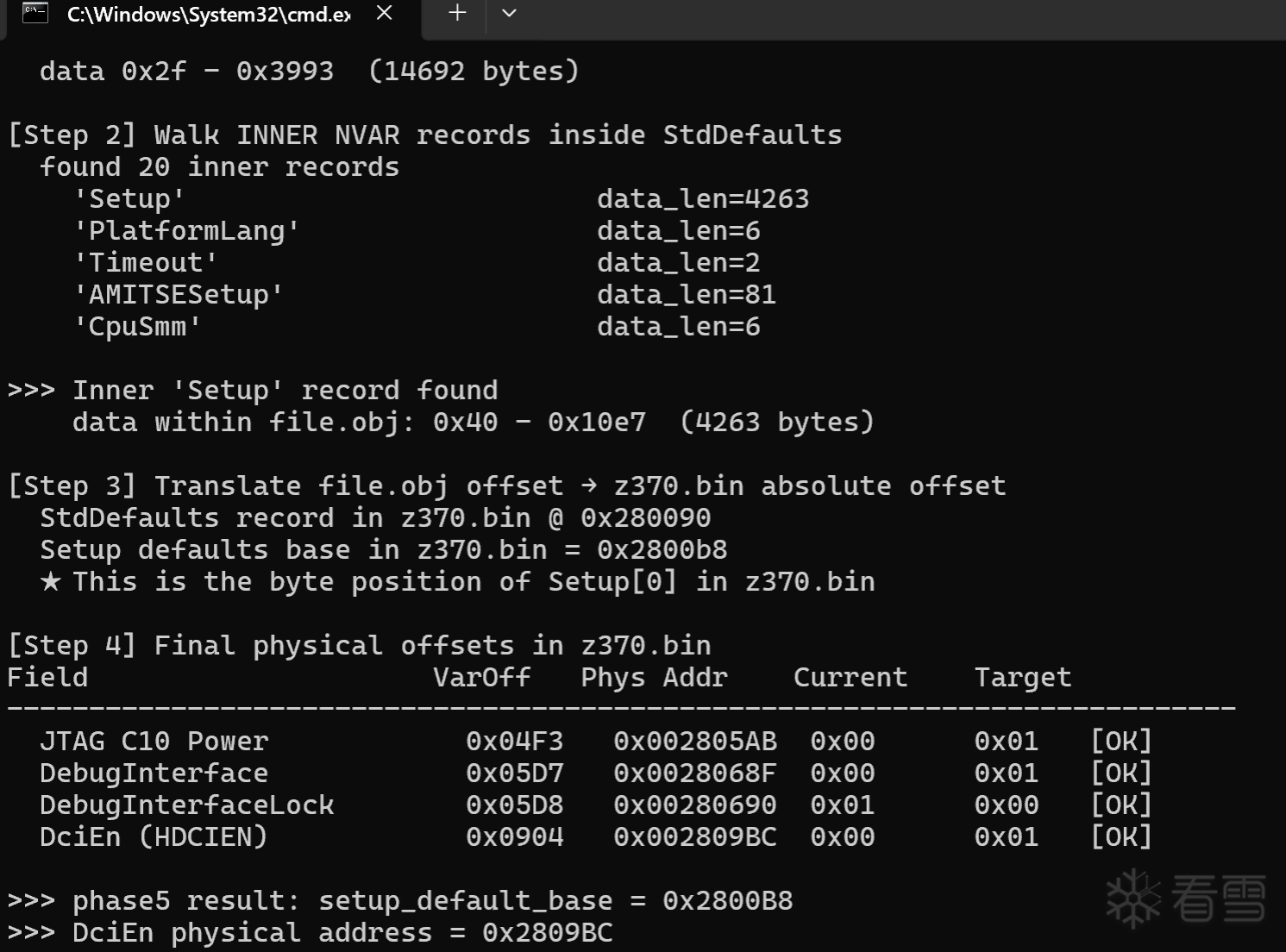
找到对应的dci的偏移值:
首先需要解析 AMI NVAR 的私有格式。好在通过Ai搜寻 UEFITool 源码中是有参考的。这里写了一个脚本来寻找并且Patch一下:
这里已经解析并且计算出真实的偏移是多少,由于NVRAM 容器是没有被压缩,就可以在对应文件中进行patch就完事了这里具体不展开了。
两个方案:
因为uefi-firmware-parser 解包出来得缺少body(说白了切得时候少切了内容,这也是我遇到的一个坑)。我们需要使用UEFIExtract 进行解包:
字典参考:57dK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3N6s2u0W2M7$3g2S2M7X3y4Z5i4K6u0r3N6h3&6y4c8e0p5I4 这个项目。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。