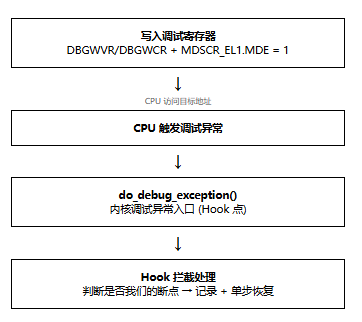
/ 写入监视点值寄存器 DBGWVR<n>_EL1
static inline void write_dbgwvr(int n, unsigned long val)
{
switch (n) {
case 0: asm volatile("msr dbgwvr0_el1, %0" : : "r" (val)); break;
case 1: asm volatile("msr dbgwvr1_el1, %0" : : "r" (val)); break;
case 2: asm volatile("msr dbgwvr2_el1, %0" : : "r" (val)); break;
case 3: asm volatile("msr dbgwvr3_el1, %0" : : "r" (val)); break;
}
asm volatile("isb");
}
static inline void write_dbgwcr(int n, unsigned long val)
{
switch (n) {
case 0: asm volatile("msr dbgwcr0_el1, %0" : : "r" (val)); break;
case 1: asm volatile("msr dbgwcr1_el1, %0" : : "r" (val)); break;
case 2: asm volatile("msr dbgwcr2_el1, %0" : : "r" (val)); break;
case 3: asm volatile("msr dbgwcr3_el1, %0" : : "r" (val)); break;
}
asm volatile("isb");
}
static void set_watchpoint_on_cpu(void *info)
{
int slot = ((int *)info)[0];
unsigned long addr = g_watchpoints[slot].address;
int type = g_watchpoints[slot].type;
int len = g_watchpoints[slot].len;
unsigned long wcr;
unsigned long mdscr;
unsigned long aligned_addr;
aligned_addr = (addr & 0x00FFFFFFFFFFFFFFULL) & ~0x7UL;
mdscr = read_mdscr_el1();
if (!(mdscr & DBG_MDSCR_MDE)) {
mdscr |= DBG_MDSCR_MDE;
write_mdscr_el1(mdscr);
}
write_dbgwvr(slot, aligned_addr);
wcr = build_wcr(type, len, addr);
write_dbgwcr(slot, wcr);
}