能力值:
 ( LV10,RANK:160 )
( LV10,RANK:160 )
|
-
-
2 楼
mark,学习了
|

能力值:
( LV2,RANK:10 )
|
-
-
3 楼
tql
|

能力值:
( LV1,RANK:0 )
|
-
-
4 楼
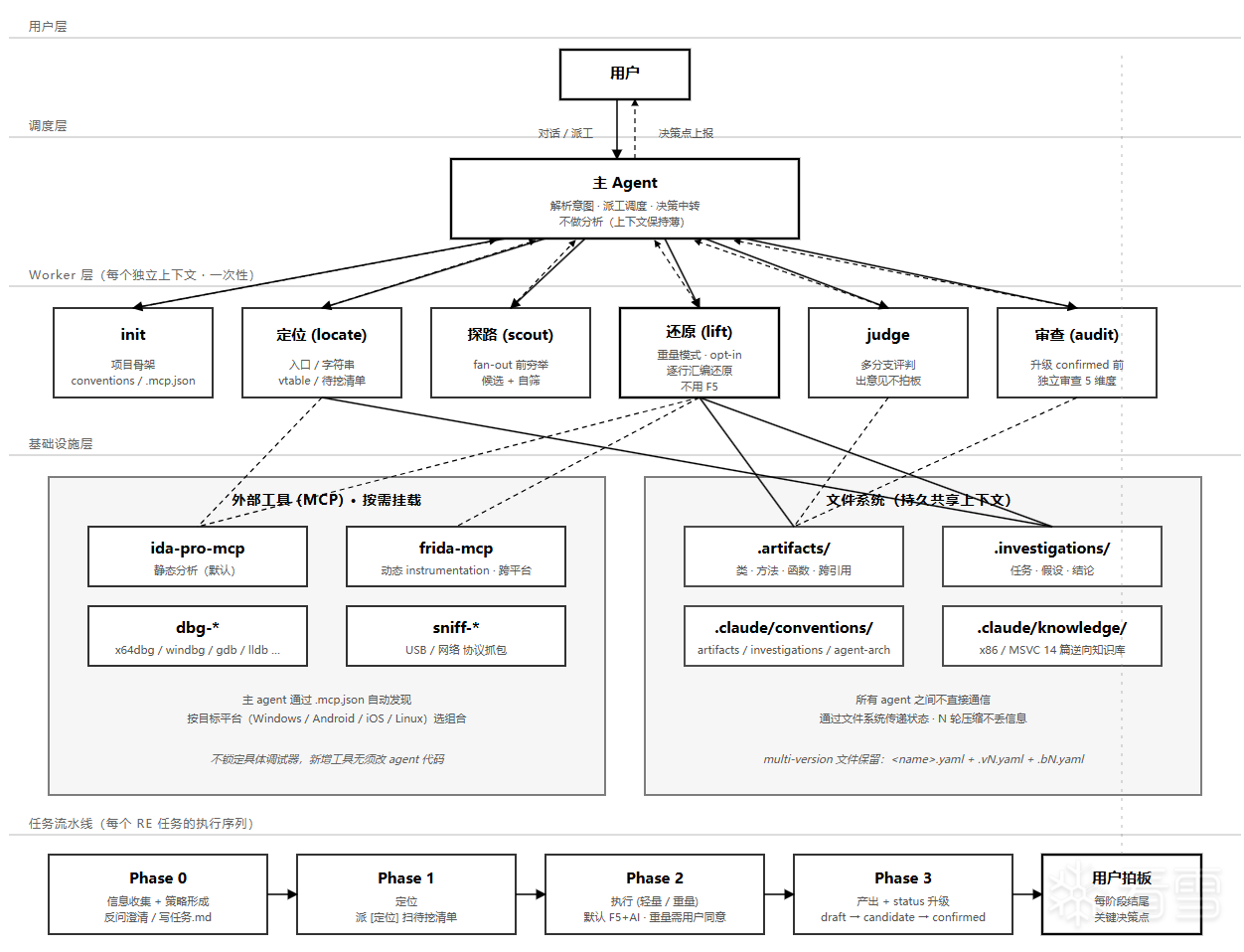
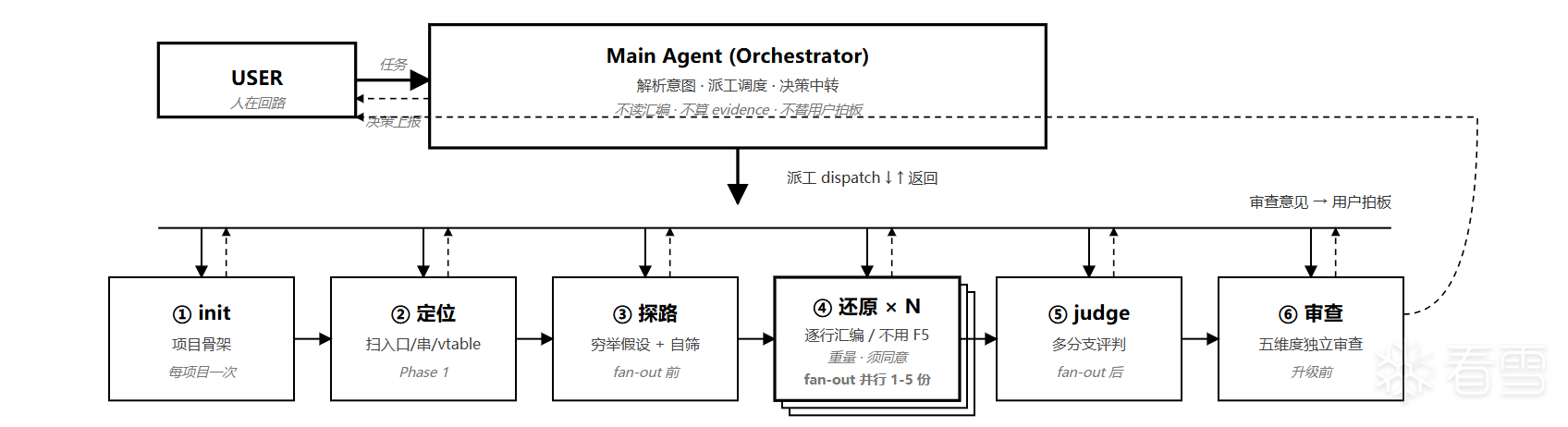
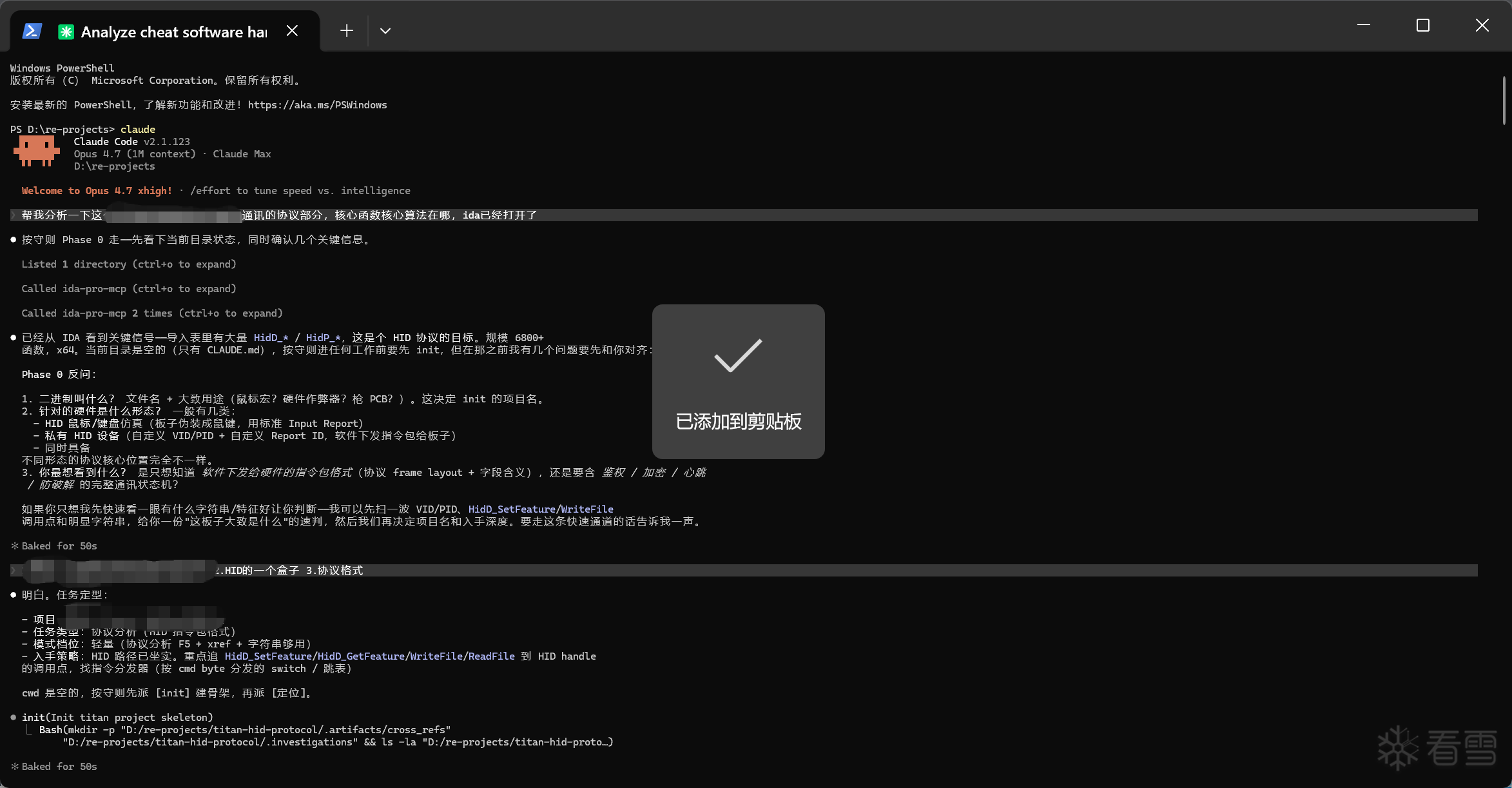
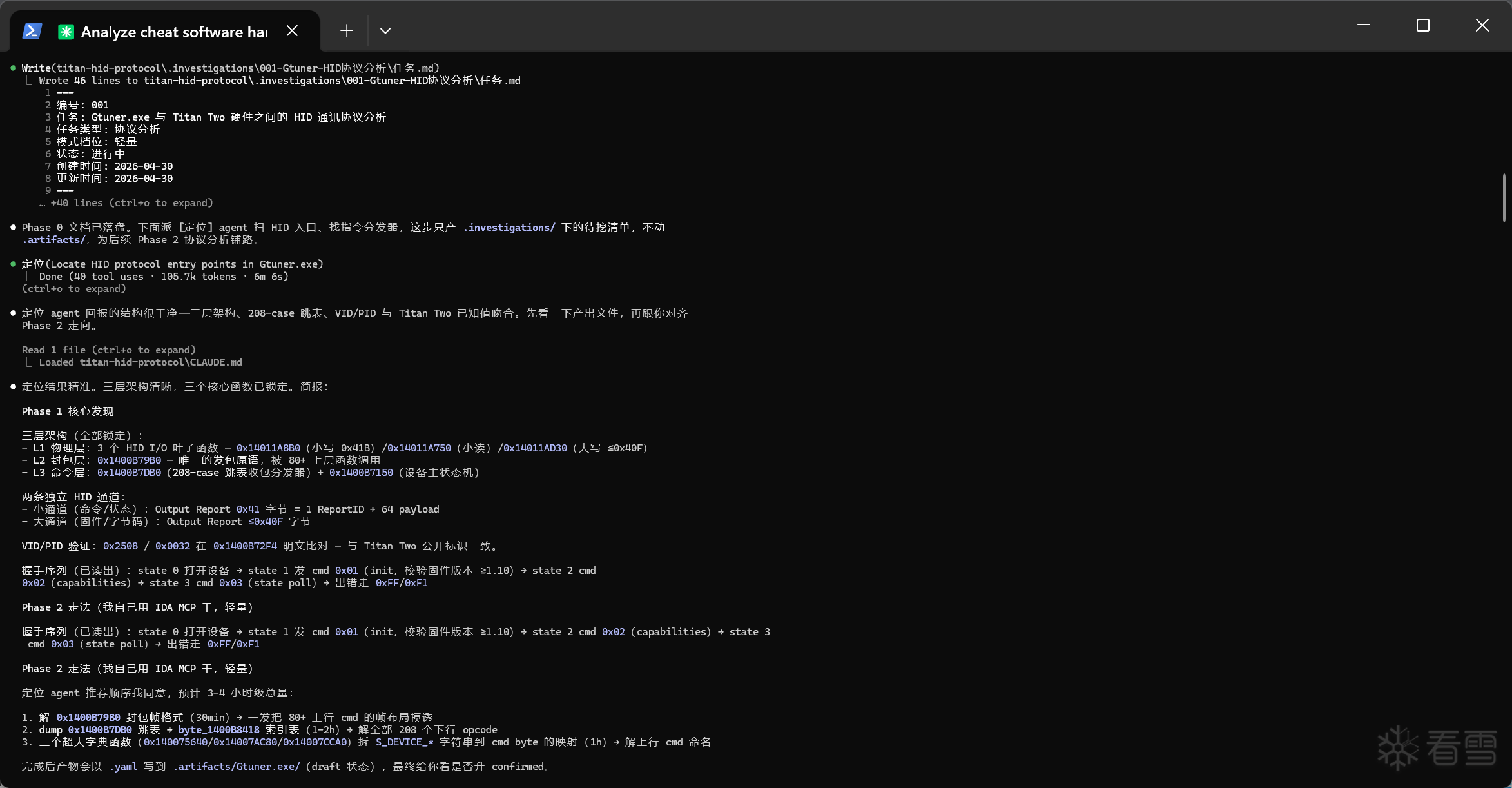
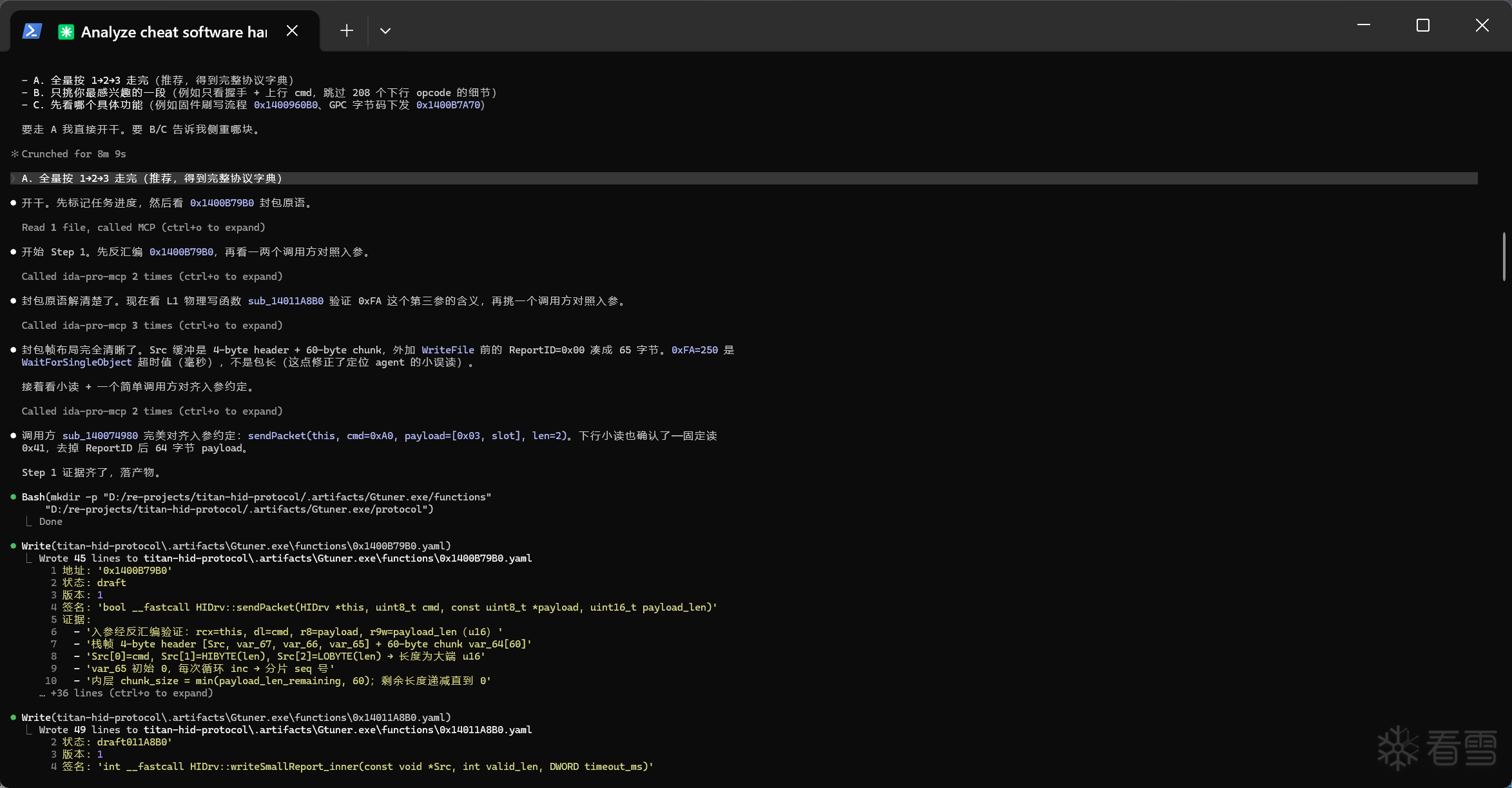
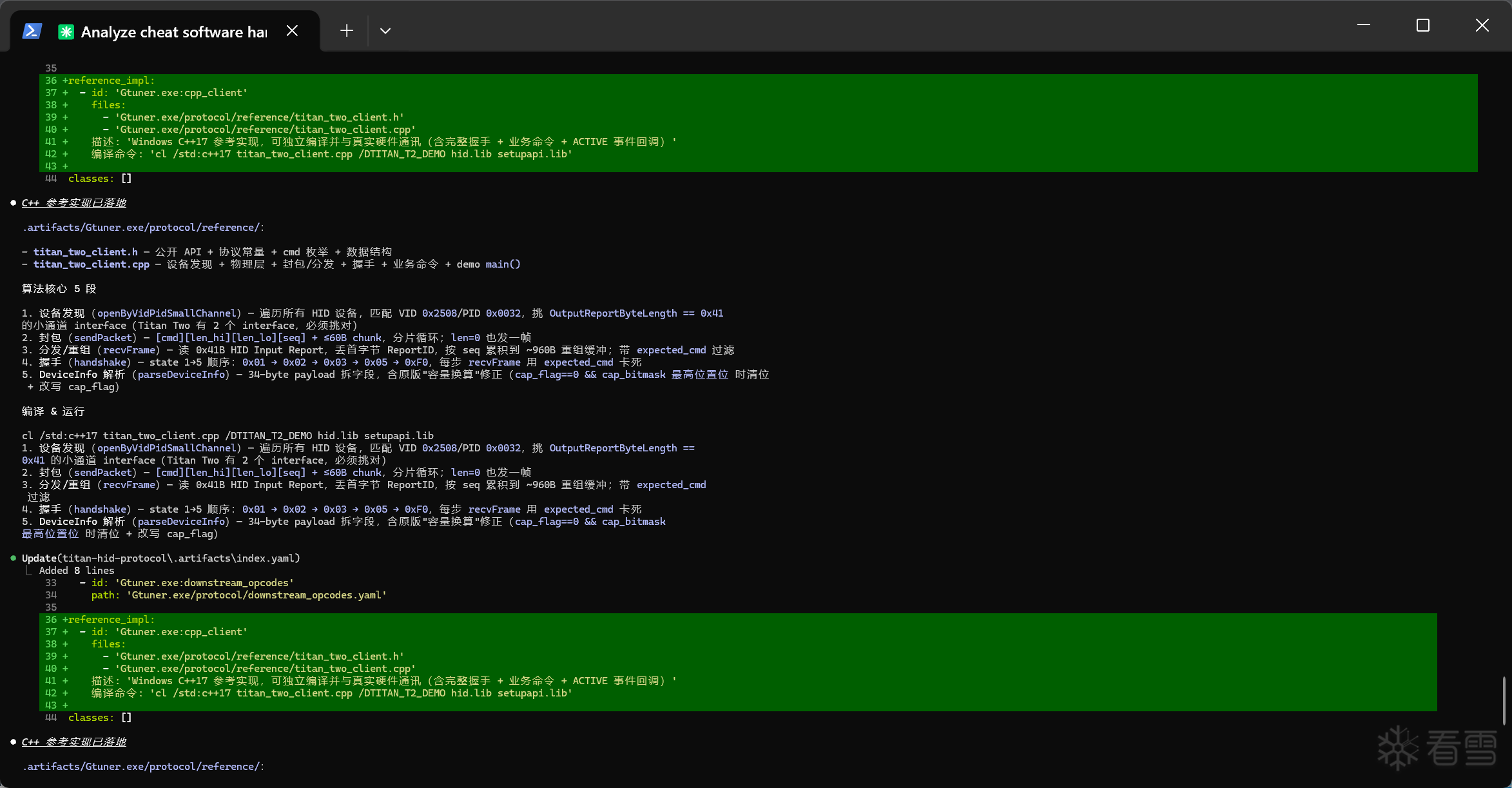
看完感觉整体都是在讲一个逆向的Harness设计,不知道理解的是不是到位了.
我之前也尝试过做类似的工程结构,但是实际搞下来发现会有很严重的资源浪费,很多其实没那么复杂的分析,也会被强行靠到整个架子上来,相比于直接连个ida-mcp然后扔给他一句话,让他从汇编层面分析逻辑,需要花费更多的时间和Token.
这个问题楼主是怎么解决的
|

能力值:
 ( LV3,RANK:26 )
( LV3,RANK:26 )
|
-
-
5 楼
这是对早期AI有效果,,现在AI已经很聪明了,,过多的引导只会让AI陷入迷茫,AI会遵守你的规程导致没办法发挥的出AI最大的想象力,聪明反被聪明误!
|
能力值:
( LV8,RANK:120 )
|
-
-
6 楼
初学者有毅力
这是对早期AI有效果,,现在AI已经很聪明了,,过多的引导只会让AI陷入迷茫,AI会遵守你的规程导致没办法发挥的出AI最大的想象力,聪明反被聪明误!
最后于 2026-6-12 16:14
被BitWarden编辑
,原因:
|
能力值:
( LV8,RANK:120 )
|
-
-
7 楼
Ankeys
看完感觉整体都是在讲一个逆向的Harness设计,不知道理解的是不是到位了.
我之前也尝试过做类似的工程结构,但是实际搞下来发现会有很严重的资源浪费,很多其实没那么复杂的分析,也会被强行靠到整个架 ...
最后于 2026-6-12 16:14
被BitWarden编辑
,原因:
|
能力值:
( LV8,RANK:120 )
|
-
-
8 楼
Ankeys
看完感觉整体都是在讲一个逆向的Harness设计,不知道理解的是不是到位了.
我之前也尝试过做类似的工程结构,但是实际搞下来发现会有很严重的资源浪费,很多其实没那么复杂的分析,也会被强行靠到整个架 ...
最后于 2026-5-3 17:26
被BitWarden编辑
,原因:
|
能力值:
( LV8,RANK:120 )
|
-
-
9 楼
Ankeys
看完感觉整体都是在讲一个逆向的Harness设计,不知道理解的是不是到位了.
我之前也尝试过做类似的工程结构,但是实际搞下来发现会有很严重的资源浪费,很多其实没那么复杂的分析,也会被强行靠到整个架 ...
最后于 2026-6-12 16:13
被BitWarden编辑
,原因:
|
能力值:
( LV1,RANK:0 )
|
-
-
10 楼
有尝试做基准测试吗?这样一套 agent,相比直接用 coding agent(codex/cc/cursor)真的更强大吗?
|
能力值:
( LV2,RANK:10 )
|
-
-
11 楼
666
|
能力值:
( LV1,RANK:0 )
|
-
-
12 楼
BitWarden
Ankeys
看完感觉整体都是在讲一个逆向的Harness设计,不知道理解的是不是到位了.
我之前也尝试过做类似的工程结构,但是实际搞下来发现会有很严重的 ...
如果说打算使用国产模型,或者社区开源模型的话,那搞这样一套工程结构那确实必不可少了.那这套系统最后是如何验证产出的呢,人工check结果嘛
|
能力值:
( LV8,RANK:120 )
|
-
-
13 楼
Ankeys
如果说打算使用国产模型,或者社区开源模型的话,那搞这样一套工程结构那确实必不可少了.那这套系统最后是如何验证产出的呢,人工check结果嘛
肯定是业务交付啊。
最后于 2026-5-6 14:10
被BitWarden编辑
,原因:
|
能力值:
( LV8,RANK:120 )
|
-
-
14 楼
。
最后于 2026-5-6 14:10
被BitWarden编辑
,原因:
|

能力值:
( LV2,RANK:10 )
|
-
-
15 楼
1
最后于 2026-5-30 17:15
被XieCZ1337编辑
,原因:
|
能力值:
( LV8,RANK:120 )
|
-
-
16 楼
XieCZ1337
1
我也有这样的想法,完全脱离opencode做一个逆向的cli,动态静态一起做,还可以人工介入。是一个方向。周围有朋友已经在做了,很成熟。
|
能力值:
( LV2,RANK:10 )
|
-
-
17 楼
BitWarden
我也有这样的想法,完全脱离opencode做一个逆向的cli,动态静态一起做,还可以人工介入。是一个方向。周围有朋友已经在做了,很成熟。
完全脱离AI编辑器不一定很好,因为调试器本身还负责插件/脚本/反反调试等工作,在设计阶段给专门的AGENT编辑器提供接口就好了,其实我的方案是调试器GUI里内嵌它的CLI,同时渲染CLI和GUI,这样AI能够得到完整的上下文和也可以和人工真正地协作,同时设计一些脚本命令MCP,让AI可以调MCP做某些重复的任务,同时CLI命令行设计得能够精确操作,最后,脚本系统也是很重要的。
|
能力值:
( LV2,RANK:10 )
|
-
-
18 楼
支持皇神
|

能力值:
( LV2,RANK:10 )
|
-
-
19 楼
初学者有毅力
这是对早期AI有效果,,现在AI已经很聪明了,,过多的引导只会让AI陷入迷茫,AI会遵守你的规程导致没办法发挥的出AI最大的想象力,聪明反被聪明误!
确实是这样,一个会话时间越长,对应的这个上下文会不断的精简压缩,最后就产生幻觉了,不管什么模型目前都存在这个问题。
|
能力值:
( LV1,RANK:0 )
|
-
-
20 楼
学习一下先进经验
|

能力值:
( LV3,RANK:20 )
|
-
-
21 楼
感谢大佬分享,一直不懂ai怎么跑逆向,现在了解大概了 knowledge 方便发一个简单模板吗
最后于 2026-5-16 10:21
被mudebug编辑
,原因:
|

能力值:
( LV2,RANK:10 )
|
-
-
22 楼
66
|

能力值:
( LV2,RANK:10 )
|
-
-
23 楼
学习
|

能力值:
( LV2,RANK:10 )
|
-
-
24 楼
d:\x86skills\.claude\knowledge\INDEX.md 有demo吗,看压缩包里面没有
|
能力值:
( LV2,RANK:10 )
|
-
-
25 楼
膜拜大神. 你遇到的问题我几乎也都遇到过. 我们最早就放弃了ida f5产生的c代码, 感觉质量很低. 然后直接从汇编生成. 然后对照汇编和c, 发现有遗漏, 也就是llm只能对开头和结尾处理的比较好, 对中间结果处理的不太行. 查找原因, 才发现是经典的"Lost In The Middle"问题. 我们想到的方法是用cfg来分片, 沿着cfg收集数据流, 避免片间依赖问题. 我们先生成一种叫做c--的东西, 只有if和goto, 然后恢复语义的时候通过cfg很容易把循环, 分支语句恢复. 我们遇到的难题是数据结构的恢复, 比较困难, 现在还在探索中. 不知能不能加一下大神的联系方式 
|
|
|
|