-
-
[原创]从零构建杀毒引擎系列之扫描器核心逻辑设计与实现(下)
-
发表于: 2026-4-28 09:15 1411
-

1.4.4 Database模块
Ⅰ. Database 模块设计
在正式实现之前,我们先明确 Database 模块的职责与对外接口。为了给CoreEngine模块提供访问我们设计的Sqlite3病毒数据库的接口,我们应该在Database模块下提供这些接口:
intdb_lookup_sha256(constchar*sha256_hash)
SHA-256检索接口:用于在病毒库中检索指定的SHA-256值是否存在。
返回值:命中返回1,未命中返回0,错误返回-1
intdb_load_signatures(SignatureEntry**out_sigs, int*out_count)
这里的 SignatureEntry 是我们自己定义的结构体,在后续部分会详细说明。
特征码读取接口:用于读取病毒库内的所有特征码并返回字符串数组指针与数量,提供给引擎比对检测。
返回值:成功返回0,失败返回-1
Ⅱ. Database 模块实现
在设计好Database模块后,我们接下来将着手实现这个模块。首先我们来实现最简单的db_lookup_sha256函数。db_lookup_sha256函数的流程非常简单,下面的图片就很好的解释的这个函数的工作流程:
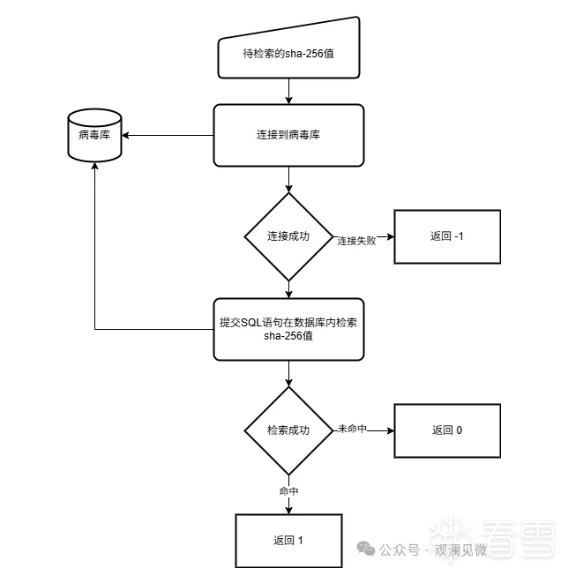
首先我们在函数内初始化sqlite3连接:
sqlite3*virus_db=NULL;
intret=0;
// 尝试打开数据库
ret=sqlite3_open(VIRUS_DB_PATH, &virus_db);
if(ret!=SQLITE_OK)
{
// 打开失败,输出错误信息并返回-1
fprintf(stderr,"Cannot open the Virus database :%s\n",sqlite3_errmsg(virus_db));
sqlite3_close(virus_db);
return-1;
}接下来我们需要构建查询SQL语句,这里我们需要用sqlite3_prepare_v2接口来编译我们的SQL语句,同时使用sqlite3_bing_text绑定参数:
constchar*sql="SELECT COUNT(*) FROM virus_sha256 WHERE sha256 = ?;";
sqlite3_stmt*stmt=NULL;
// 编译SQL语句
ret=sqlite3_prepare_v2(virus_db, sql, -1, &stmt, NULL);
if(ret!=SQLITE_OK)
{
// 编译失败,输出错误信息并返回-1
fprintf(stderr, "SQL prepare failed: %s\n", sqlite3_errmsg(virus_db));
sqlite3_close(virus_db);
return-1;
}
// 绑定查询参数
sqlite3_bind_text(stmt, 1, sha256_hash, -1, SQLITE_TRANSIENT);使用参数绑定方法构建SQL语句可以有效防止SQL注入的风险。参数绑定方式将查询条件作为参数传递,而不是把查询条件拼接入SQL语句中,可以有效防止恶意内容被解释为SQL语法的一部分,从而规避SQL注入攻击。
最后提交查询并返回结果:
// 执行查询
ret=sqlite3_step(stmt);
if(ret==SQLITE_ROW)
{
// 获取查询结果条数
intcount=sqlite3_column_int(stmt, 0);
sqlite3_finalize(stmt);
sqlite3_close(virus_db);
returncount>0?1 : 0;
}
//查询失败
sqlite3_finalize(stmt);
sqlite3_close(virus_db);
return-1;以上就是db_lookup_sha256的全部实现过程,下面的是整合代码:
intdb_lookup_sha256(constchar*sha256_hash)
{
sqlite3*virus_db=NULL;
intret=0;
// 尝试打开数据库
ret=sqlite3_open(VIRUS_DB_PATH, &virus_db);
if(ret!=SQLITE_OK)
{
// 打开失败,输出错误信息并返回-1
fprintf(stderr,"Cannot open the Virus database :%s\n",sqlite3_errmsg(virus_db));
sqlite3_close(virus_db);
return-1;
}
constchar*sql="SELECT COUNT(*) FROM virus_sha256 WHERE sha256 = ?;";
sqlite3_stmt*stmt=NULL;
// 编译SQL语句
ret=sqlite3_prepare_v2(virus_db, sql, -1, &stmt, NULL);
if(ret!=SQLITE_OK)
{
// 编译失败,输出错误信息并返回-1
fprintf(stderr, "SQL prepare failed: %s\n", sqlite3_errmsg(virus_db));
sqlite3_close(virus_db);
return-1;
}
// 绑定查询参数
sqlite3_bind_text(stmt, 1, sha256_hash, -1, SQLITE_TRANSIENT);
// 执行查询
ret=sqlite3_step(stmt);
if(ret==SQLITE_ROW)
{
// 获取查询结果条数
intcount=sqlite3_column_int(stmt, 0);
sqlite3_finalize(stmt);
sqlite3_close(virus_db);
returncount>0?1 : 0;
}
//查询失败
sqlite3_finalize(stmt);
sqlite3_close(virus_db);
return-1;
}接下来我们再回顾一下db_load_signatures函数,db_load_signatures函数负责从本地病毒库中加载所有存储的特征码(Signatures)并以字符串数组的形式返回给调用者,以供后续扫描引擎模块的调用。函数流程如下:
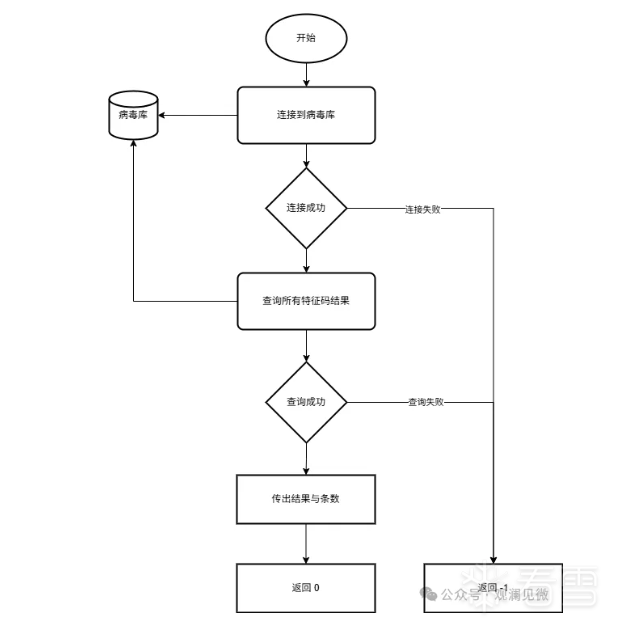
接下来定义SignatureEntry结构体用于表示读取到的特征码条目:
typedefstruct {
char*name;// 病毒名称
char*signature;// 特征码字符串,比如"E803......"
}SignatureEntry;下面的代码片段展示了对应的结果读取与写入传出方法:
intcapacity=32;// 定义初始容量为32条
SignatureEntry*entries=malloc(sizeof(SignatureEntry) *capacity);
if (!entries) {
fprintf(stderr, "Out of memory.\n");
sqlite3_finalize(stmt);
sqlite3_close(db);
return-1;
}
// 读取结果并写入
intcount=0;
while ((ret=sqlite3_step(stmt)) ==SQLITE_ROW) {
if (count>=capacity) {
// 条数超过容量,扩容
capacity*=2;
entries=realloc(entries, sizeof(SignatureEntry) *capacity);
if (!entries) {
fprintf(stderr, "Realloc failed.\n");
sqlite3_finalize(stmt);
sqlite3_close(db);
return-1;
}
}
// 读取结果
constchar*name= (constchar*)sqlite3_column_text(stmt, 0);
constchar*sig = (constchar*)sqlite3_column_text(stmt, 1);
// 写入数据
entries[count].name=_strdup(name);
entries[count].signature=_strdup(sig);
if (!entries[count].name||!entries[count].signature) {
fprintf(stderr, "Memory error while copying signature.\n");
// 释放已有资源
for (inti=0; i<count; ++i) {
free(entries[i].name);
free(entries[i].signature);
}
free(entries);
sqlite3_finalize(stmt);
sqlite3_close(db);
return-1;
}
count++;
}
sqlite3_finalize(stmt);
sqlite3_close(db);
// 传出结果
*out_entries=entries;
*out_count=count;在读取完特征码之后,我们需要在使用过后释放动态分配的内存,否则会造成内存泄漏。为此我们将实现一个释放函数db_free_signatures,用于释放创建的SignatureEntry指针数组:
voiddb_free_signatures(SignatureEntry*entries, intcount) {
for (inti=0; i<count; ++i) {
free(entries[i].name);
free(entries[i].signature);
}
free(entries);
}释放函数应该在db_load_signatures调用结束并完成扫描流程后:
SignatureEntry*entries=NULL;
intcount=0;
if (db_load_signatures(&entries, &count) ==0) {
// ...扫描流程
db_free_signatures(entries, count);
}1.4.5 Scanner模块
我们将在本小节中实现扫描器模块的核心逻辑,包括SHA-256计算、特征码匹配等。
Ⅰ. Scanner 模块设计
Scanner模块将调用Database模块提供的接口,实现对目标文件的扫描与病毒识别。我们应该在Scanner模块中提供如下接口:
boolcalculate_sha256(constchar*filepath, char*out_hash_hex)
SHA-256计算函数,用于计算文件的SHA-256值并传出。
返回值:成功返回true,失败返回false。
boolread_file_to_buffer(constchar*filepath, unsignedchar**out_buffer, size_t*out_size);
以二进制字符串形式读取文件内容函数,用于特征码检测。
返回值:成功返回true,失败返回false。
Ⅱ. Scanner 模块实现
calculate_sha256 函数的目标是读取目标文件内容并使用 Windows 平台下的 CNG(Cryptography Next Generation)API(bcrypt.dll) 计算其 SHA-256哈希值。在本项目中,SHA-256 用于实现病毒指纹匹配检测,因此这也是检测流程中的第一道防线。计算流程如下图所示:
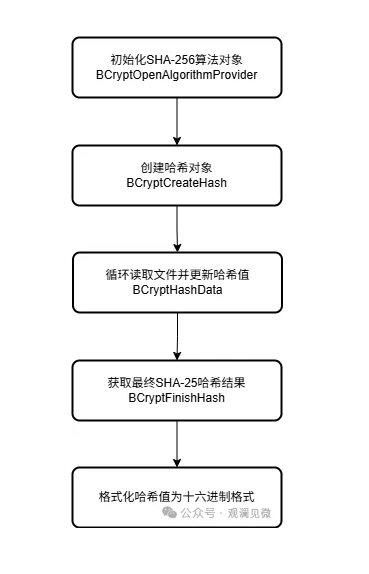
1. 初始化变量与算法句柄:
BCRYPT_ALG_HANDLEhAlg=NULL;
BCRYPT_HASH_HANDLEhHash=NULL;
NTSTATUSstatus;
DWORDhashLen=HASH_LENGTH;
BYTEhash[HASH_LENGTH] = { 0 };
BYTEbuffer[4096];
size_tbytesRead;2. 加载 SHA-256 算法:
status=BCryptOpenAlgorithmProvider(&hAlg, BCRYPT_SHA256_ALGORITHM, NULL, 0);
if (status!=0) {
fprintf(stderr, "BCryptOpenAlgorithmProvider failed: 0x%x\n", status);
fclose(file);
returnfalse;
}3. 创建哈希对象:
status=BCryptCreateHash(hAlg, &hHash, NULL, 0, NULL, 0, 0);
if (status!=0) {
fprintf(stderr, "BCryptCreateHash failed: 0x%x\n", status);
BCryptCloseAlgorithmProvider(hAlg, 0);
fclose(file);
returnfalse;
}4. 分块读取文件并进行哈希更新:
while ((bytesRead=fread(buffer, 1, sizeof(buffer), file)) >0) {
status=BCryptHashData(hHash, buffer, (ULONG)bytesRead, 0);
if (status!=0) {
fprintf(stderr, "BCryptHashData failed: 0x%x\n", status);
BCryptDestroyHash(hHash);
BCryptCloseAlgorithmProvider(hAlg, 0);
fclose(file);
returnfalse;
}
}5. 获取最终哈希值:
status=BCryptFinishHash(hHash, hash, hashLen, 0);
if (status!=0) {
fprintf(stderr, "BCryptFinishHash failed: 0x%x\n", status);
BCryptDestroyHash(hHash);
BCryptCloseAlgorithmProvider(hAlg, 0);
returnfalse;
}
BCryptDestroyHash(hHash);
BCryptCloseAlgorithmProvider(hAlg, 0);6. 格式化哈希值(转换为16进制字符串格式):
for (inti=0; i<hashLen; ++i) {
sprintf(out_hash_hex+i*2, "%02x", hash[i]);
}
out_hash_hex[64] ='\0';最后,我们可以这样调用calculate_sha256函数:
charhash_hex[65];
if (calculate_sha256("C:\\test\\sample.exe", hash_hex)) {
printf("SHA-256: %s\n", hash_hex);
} else {
printf("Hash calculation failed.\n");
}接下来我们将实现read_file_to_buffer函数:
read_file_to_buffer函数将使用基础的C语言文件操作函数实现文件二进制内容的读取:
boolread_file_to_buffer(constchar*filepath, unsignedchar**out_buffer, size_t*out_size)
{
// 打开文件
FILE*fp=fopen(filepath, "rb");
if (!fp) {
fprintf(stderr, "Failed to open file: %s\n", filepath);
returnfalse;
}
// 计算文件大小
if (fseek(fp, 0, SEEK_END) !=0) {
fprintf(stderr, "Failed to seek file: %s\n", filepath);
fclose(fp);
returnfalse;
}
longfile_size=ftell(fp);
if (file_size<0) {
fprintf(stderr, "Failed to get file size: %s\n", filepath);
fclose(fp);
returnfalse;
}
// 恢复文件指针
rewind(fp);
// 分配内存缓冲区
unsignedchar*buffer= (unsignedchar*)malloc(file_size);
if (!buffer) {
fprintf(stderr, "Out of memory when reading file: %s\n", filepath);
fclose(fp);
returnfalse;
}
// 读取文件内容
size_tread_size=fread(buffer, 1, file_size, fp);
if (read_size!= (size_t)file_size) {
fprintf(stderr, "Failed to read file fully: %s\n", filepath);
free(buffer);
fclose(fp);
returnfalse;
}
fclose(fp);
// 传出buffer
*out_buffer=buffer;
*out_size=read_size;
returntrue;
}由于从病毒库读取的特征码以十六进制字符串形式表示,而read_file_to_buffer函数直接以二进制形式读取文件内容,所以这里还需要对特征码进行格式转化才能进行匹配,我们新建一个函数hexstr_to_bytes用于转化格式:
inthexstr_to_bytes(constchar*hexstr, unsignedchar**out_bytes)
{
size_tlen=strlen(hexstr);
if (len%2!=0) {
return-1; // 十六进制字符串长度必须为偶数
}
size_tout_len=len/2;
unsignedchar*result=malloc(out_len);
if (!result) return-1;
for (size_ti=0; i<out_len; ++i) {
charbyte_str[3] = { hexstr[2*i], hexstr[2*i+1], '\0' };
// 验证是否为合法十六进制字符
if (!isxdigit(byte_str[0]) ||!isxdigit(byte_str[1])) {
free(result);
return-1;
}
result[i] = (unsignedchar)strtol(byte_str, NULL, 16);
}
*out_bytes=result;
return (int)out_len;
}1.4.6 CoreEngine模块
恭喜,你已经完成了大部分重要的工作,现在只需要在 CoreEngine 模块里面调用函数我们写好的接口就可以实现我们的第一个杀毒引擎了!
Ⅰ. CoreEngine 模块设计
在 CoreEngine 里,我们要理清调用逻辑和流程:
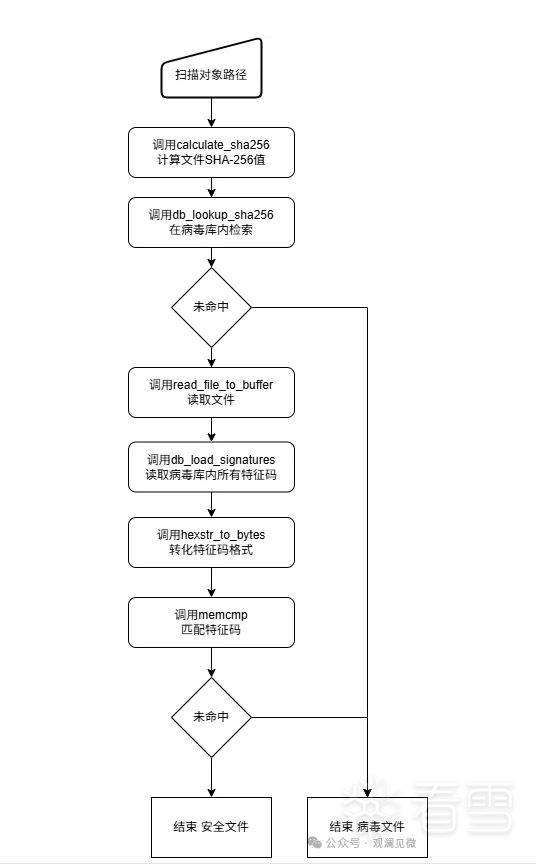
Ⅱ. CoreEngine 模块实现
intmain(intargc, char*argv[])
{
if (argc<2)
{
printf("用法: %s <文件路径>\n", argv[0]);
return1;
}
constchar*filepath=argv[1];
charsha256[65] = { 0 };
// 1. SHA-256 检测
if (!calculate_sha256(filepath, sha256))
{
printf("计算文件SHA-256失败: %s\n", filepath);
return2;
}
printf("文件: %s\nSHA-256: %s\n", filepath, sha256);
intresult=db_lookup_sha256(sha256);
if (result<0)
{
printf("查询病毒库失败!\n");
return3;
} elseif (result==1)
{
printf("警告:该文件已被病毒库标记为病毒!\n");
} else
{
printf("该文件未在病毒库中发现。\n");
}
// 2. 特征码检测
unsignedchar*file_buffer=NULL;
size_tfile_size=0;
if (!read_file_to_buffer(filepath, &file_buffer, &file_size))
{
printf("读取文件内容失败: %s\n", filepath);
return4;
}
SignatureEntry*entries=NULL;
intentry_count=0;
if (db_load_signatures(&entries, &entry_count) ==0)
{
intfound=0;
for (inti=0; i<entry_count; ++i)
{
unsignedchar*sig_bytes=NULL;
intsig_len=hexstr_to_bytes(entries[i].signature, &sig_bytes);
if (sig_len<=0||!sig_bytes) continue;
// 简单的二进制特征码查找
for (size_tj=0; j+sig_len<=file_size; ++j)
{
if (memcmp(file_buffer+j, sig_bytes, sig_len) ==0)
{
printf("警告:检测到特征码病毒 [%s]!\n", entries[i].name);
found=1;
free(sig_bytes);
break;
}
}
free(sig_bytes);
if (found) break;
}
if (!found)
{
printf("未检测到已知特征码病毒。\n");
}
db_free_signatures(entries, entry_count);
} else
{
printf("加载特征码库失败,无法进行特征码检测。\n");
}
free(file_buffer);
return0;
}这样我们就实现了一个基础的单文件检测功能,接下来需要完善逻辑,使其可以对传入的目录路径进行遍历扫描,这里我们将使用Windows API中的FindFirstFile,FindNextFile 等函数来实现对目录的遍历,同时将其封装为一个扫描函数,以此来实现对传入目录路径的扫描以及main函数的逻辑简化。
首先我们需要将已有的main函数中的单文件扫描逻辑提取为一个单文件扫描函数scan_file:
// 提取后的单文件扫描函数
voidscan_file(constchar*filepath)
{
charsha256[65] = { 0 };
// 1. SHA-256 检测
if (!calculate_sha256(filepath, sha256))
{
printf("计算文件SHA-256失败: %s\n", filepath);
return;
}
printf("文件: %s\nSHA-256: %s\n", filepath, sha256);
intresult=db_lookup_sha256(sha256);
if (result<0)
{
printf("查询病毒库失败!\n");
return;
}
elseif (result==1)
{
printf("警告:该文件已被病毒库标记为病毒!\n");
}
else {
printf("该文件未在病毒库中发现。\n");
}
// 2. 特征码检测
unsignedchar*file_buffer=NULL;
size_tfile_size=0;
if (!read_file_to_buffer(filepath, &file_buffer, &file_size))
{
printf("读取文件内容失败: %s\n", filepath);
return;
}
SignatureEntry*entries=NULL;
intentry_count=0;
// 加载所有特征字符串
if (db_load_signatures(&entries, &entry_count) ==0)
{
intfound=0;
for (inti=0; i<entry_count; ++i) {
unsignedchar*sig_bytes=NULL;
// 转换特征字符串为字节序列用于匹配
intsig_len=hexstr_to_bytes(entries[i].signature, &sig_bytes);
if (sig_len<=0||!sig_bytes)
{
continue;
}
for (size_tj=0; j+sig_len<=file_size; ++j)
{
if (memcmp(file_buffer+j, sig_bytes, sig_len) ==0)
{
printf("警告:检测到特征码病毒 [%s]!\n", entries[i].name);
found=1;
free(sig_bytes);
break;
}
}
free(sig_bytes);
if (found) break;
}
if (!found)
{
printf("未检测到已知特征码病毒。\n");
}
// 释放特征码内存空间
db_free_signatures(entries, entry_count);
}
else
{
printf("加载特征码库失败,无法进行特征码检测。\n");
}
free(file_buffer);
}接下来实现scan_path函数用于遍历目录以及处理单文件的扫描。首先需要判断传入路径的合法性,可以GetFileAttributesA函数来获取目录属性,当无法获取目录属性时输出错误信息并返回:
DWORDattr=GetFileAttributesA(path);
if (attr==INVALID_FILE_ATTRIBUTES) {
printf("路径无效: %s\n", path);
return;
}判断路径合法性后,拼接扫描路径并执行FindFirstFile函数完成第一次文件遍历:
charsearch_path[MAX_PATH];
snprintf(search_path, MAX_PATH, "%s\\*", path);
WIN32_FIND_DATAAfindData;
HANDLEhFind=FindFirstFileA(search_path, &findData);
if (hFind==INVALID_HANDLE_VALUE) {
printf("无法遍历目录: %s\n", path);
return;
}随后对目录继续进行遍历,并对每一个遍历到的文件调用前面提取出来的单文件检测函数scan_file函数进行检测:
do {
if (strcmp(findData.cFileName, ".") ==0||strcmp(findData.cFileName, "..") ==0)
continue;
charchild_path[MAX_PATH];
snprintf(child_path, MAX_PATH, "%s\\%s", path, findData.cFileName);
if (findData.dwFileAttributes&FILE_ATTRIBUTE_DIRECTORY) {
scan_path(child_path); // 递归
}
else {
scan_file(child_path);// 检测遍历到的文件
}
} while (FindNextFileA(hFind, &findData));
FindClose(hFind);主函数入口:
intmain(void)
{
// 输出欢迎信息
printWelcomeCLI();
charfilepath[MAX_PATH] = { 0 };
charsha256[65] = { 0 };
// 获取用户输入的文件路径
scanf("%s", filepath);
if (strlen(filepath) ==0) {
printf("未输入文件路径,请重新运行程序。\n");
return1;
}
// 扫描指定路径或文件
printf("[INFO] 开始扫描路径: %s\n", filepath);
scan_path(filepath);
return0;
}以上就是扫描器核心逻辑设计与实现的下半部分
最后欢迎大家关注,后续还有很多好康的哦!若各位有任何的反馈与建议,也欢迎反馈至邮箱 llmsecbook@163.com。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




