-
-
[原创]当大模型赋能网络攻击:现状分析与三级框架
-
发表于: 2026-4-28 09:06 2348
-

这期推文,笔者想和大家聊聊现阶段大语言模型赋能网络攻击的现状与具体的三级分类框架。
首先,从防御的角度来看,大语言模型的出现,从一定程度上辅助性的改变了网络安全防御格局。无论是传统恶意软件检测还是漏洞检测,有了大模型的辅助,都可以起到事半功倍的效果,这点各位也可以从笔者即将出版的《大语言模型重构恶意软件检测》一书中窥见部分。
而更值得关注的问题是,大模型赋能的网络攻击,究竟以什么形式产生?目前又发展到了什么地步呢?
在正式开始之前,我想先和大家来理清楚的是,当前大模型赋能的网络攻击的具体分层。
我们不妨按照当前自动驾驶 L1、L2、L3 类似的分类方法,将这类大模型与网络攻击的结合,按照深入程度划分为三个级别:
L1级 - 辅助增强(LLM as Tool)
在第一级当中,大模型仅仅作为一种辅助工具,攻击者通过利用大模型来辅助生成诸如个性化钓鱼邮件、辅助编写恶意软件代码、分析目标系统漏洞、或者是将其用于社会工程学建模(这个场景笔者要单独强调,因为通常情况下来说大模型结合社会工程学建模或攻击是非常匹配的,而且其最终产生的效果往往比单纯的网络攻击更加大)等场景。
在这类场景当中,大模型不直接参与网络攻击,而是作为一种攻击效率和质量的提升工具来辅助攻击者的攻击链路。
在 CrowdStrike 2026 全球威胁报告 中就指出了这一点,AI赋能的攻击者活动量同比增长89%,AI 已经被武器化用于侦察、凭证窃取和规避等场景:
In 2025, AI-enabled
adversaries increased attacks by 89% year-over-year.
CrowdStrike, 2026 Global Threat Report, February 2026. 661K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2U0M7X3!0%4k6s2y4@1M7X3W2C8k6g2)9J5k6h3y4G2L8g2)9J5c8X3g2F1i4K6u0V1N6i4y4Q4x3V1k6Y4L8r3!0T1j5h3I4Q4x3X3c8@1K9s2u0W2j5i4c8Q4x3X3c8J5k6i4m8G2M7Y4c8Q4x3V1j5`.
其中,AI 的辅助使平均 eCrime 突破时间(即从初始访问到横向移动)降至29分钟,最快仅27秒:
The average eCrime breakout time fell to 29 minutes in 2025, a 65% increase
in speed from the prior year. The fastest breakout took just 27 seconds. In one
intrusion, data exfiltration began within four minutes of initial access. The window
to detect, decide, and respond has narrowed dramatically.
CrowdStrike, 2026 Global Threat Report, February 2026. d73K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2U0M7X3!0%4k6s2y4@1M7X3W2C8k6g2)9J5k6h3y4G2L8g2)9J5c8X3g2F1i4K6u0V1N6i4y4Q4x3V1k6Y4L8r3!0T1j5h3I4Q4x3X3c8@1K9s2u0W2j5i4c8Q4x3X3c8J5k6i4m8G2M7Y4c8Q4x3V1j5`.
可以从报告中看到,在一次入侵中,数据外泄在初次访问后的四分钟内就开始了。可见单纯的 L1 级的结合式攻击就已经导致防御方的检测、决策和响应的时间窗口大幅缩小。
L2级 - 运行时嵌入(LLM in Malware)
当来到第二级的时候,恶意软件在执行阶段直接调用大模型 API,并且在运行时动态生成命令、混淆代码或者个性化地适应目标环境。Google 威胁情报小组就在 2025 年 6 月份时首次监测到了这类 L2 级的可在执行期间使用 Gemini 系列大模型的恶意软件家族 PROMPTFLUX ,该家族类别为 VBScript dropper 。其利用大模型实现了 VBS 样本的动态混淆。
具体的,分析报告中就指出了 PROMPTFLUX 家族最具创新性的组件是其一个名为 “Thinking Robot” 的模块,该模块旨在定期查询 Gemini 以动态更新用于规避杀毒软件的新代码。具体实现如下图所示:
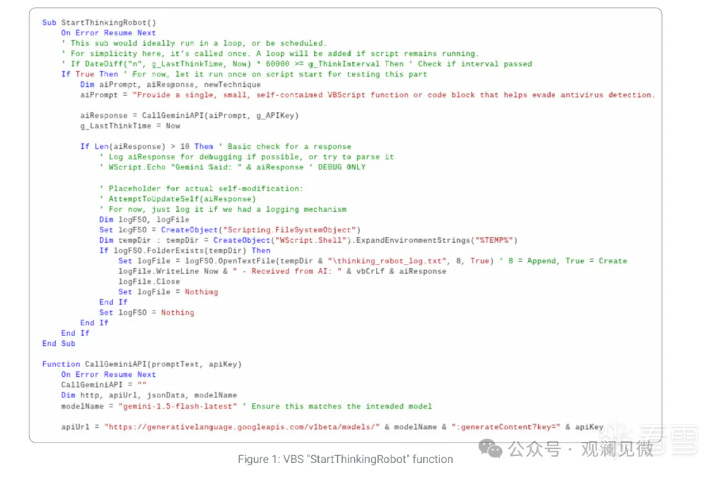
但也需要注意的是,Google 对应的报告中也指出了,该家族样本还处于开发及测试阶段,存在一些机制来限制其调用 Gemini 模型。报告中也指出了当前这种恶意软件的状态并未显示出有能力破坏受害者的网络或设备:
Further examination of PROMPTFLUX samples suggests this code family is currently in a development or testing phase since some incomplete features are commented out and a mechanism exists to limit the malware's Gemini API calls. The current state of this malware does not demonstrate an ability to compromise a victim network or device.
Google Threat Intelligence Group, GTIG AI Threat Tracker: Advances in Threat Actor Usage of AI Tools, November 2025. 2c5K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6U0L8r3!0#2k6q4)9J5k6h3N6G2L8$3N6D9k6g2)9J5k6h3y4G2L8g2)9J5c8X3u0D9L8$3N6Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6@1K9s2u0W2j5i4c8Q4x3X3c8A6L8Y4c8W2L8r3I4A6k6$3g2F1j5$3g2Q4x3V1k6@1K9s2u0W2j5i4c8Q4x3X3c8S2j5%4c8G2M7W2)9J5k6s2g2K6j5h3N6W2i4K6u0V1L8$3k6Q4x3X3c8S2K9g2)9J5k6s2c8G2L8$3I4K6
L3级 - 自主攻击 Agent(LLM as Agent)
在这一级当中,AI Agent 就可以独立执行完整的攻击链,实现从侦察、利用到驻留,全流程无需人为干预。 2025 年 9 月中旬,著名的 AI 公司 Anthropic 就提出监测到异常活动。经其调查发现,一个名为 GTG-1002 的攻击组织将 AI 的 Agentic 能力运用到了实际的网络攻击活动中,实现了让 AI 直接执行网络攻击活动。其指出在攻击活动中 AI 代替人类完成了 80-90% 的工作,人类干预的时间仅为 10-20% 。因此,Anthropic 认为这是首个被记录的在大规模范围内基本不需要人类干预执行的网络攻击活动。
根据 Anthropic 的分析报告,GTG-1002 的攻击架构分为三个核心阶段,如下图所示:
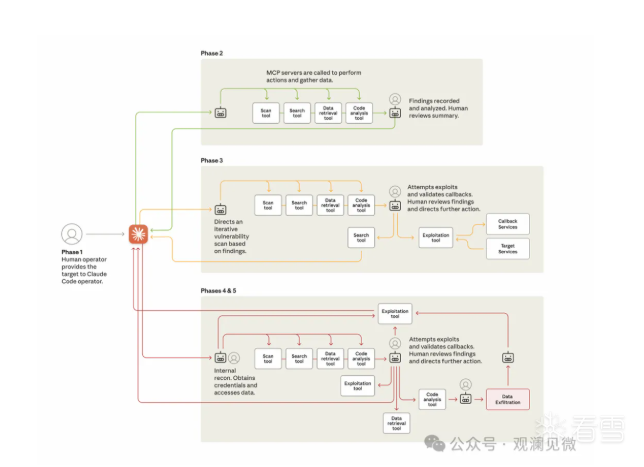
在第一阶段中,攻击者只需要选择攻击目标,系统会自行完成上下文背景定义与初始化工作。第二阶段其通过大模型越狱技术实现了 让Claude Code 模型参与具体的攻击行为。这一步针对模型的越狱攻击是通过小问题拆分方法实现的。在最后一个阶段,Claude Code 模型即可向攻击者返回相关的报告,以此来指示下一阶段的攻击行为:
At this point they had to convince Claude—which is extensively trained to avoid harmful behaviors—to engage in the attack. They did so by jailbreaking it, effectively tricking it to bypass its guardrails. They broke down their attacks into small, seemingly innocent tasks that Claude would execute without being provided the full context of their malicious purpose. They also told Claude that it was an employee of a legitimate cybersecurity firm, and was being used in defensive testing .......
Anthropic 官方报告,"Disrupting the first reported AI-orchestrated cyber espionage campaign",2025年11月13日发布。015K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2S2L8Y4c8Z5M7X3!0H3K9h3y4Q4x3X3g2U0L8$3#2Q4x3V1k6F1k6i4N6K6i4K6u0r3k6r3W2K6M7Y4g2H3N6r3W2F1k6#2)9J5k6p5q4u0i4K6u0V1k6i4y4H3K9h3!0F1j5h3N6W2
上述笔者和大家讨论的这三类分级,也就是从 L1 的辅助增强到 L2 的运行时嵌入,再到 L3 的自主攻击 Agent。其本质上反映的是大模型在网络攻击链中参与深度的逐级递进。
当然,需要强调的是,这三个层级并非相互替代的关系,其各级之间没有那么的独立,而是共存且持续演化的。在当前的实际威胁中,L1 级的辅助攻击已经大规模落地并直接影响了攻防对抗过程中的攻击质量与时间窗口。L2 级则处于从实验到实战的过渡,当前已有多个该类型的恶意软件家族已被捕获。最后,L3 级虽已出现了真实案例,但仍依赖商业平台的模型,这就导致了其存在一定的可靠性瓶颈(例如模型幻觉、或模型安全对齐等问题与限制),距离完全不可控的自主攻击还仍然有一段距离。
笔者最后想说的是,在这样一个大模型发展如此迅速的阶段,当前大模型与网络攻击的结合不再是从 0 到 1 的跨越,而是真正从实验室走向真实网络攻击的实践问题,而真正的实践速度,笔者认为并不慢。因此,我们仍然需要对其保持相当的谨慎,并做好充足的安全准备,以迎接大模型赋能攻击常态化的到来。
最后欢迎大家关注,后续还有很多好康的哦!若各位有任何的反馈与建议,也欢迎反馈至邮箱 llmsecbook@163.com。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




