Frida Gum 是一个底层代码插桩库,可在多个平台和架构上提供动态二进制插桩功能。它支持通过函数钩子(fun hooking GumInterceptor)、指令级跟踪(include-level tracing GumStalker)、内存访问监控(memory access monitoring GumMemoryAccessMonitor)和代码生成来运行时操作本地代码。该库支持 Darwin(macOS/iOS)、Linux、Windows、FreeBSD 和 QNX 平台上的 x86、x86_64、ARM、ARM64 和 MIPS 架构。
以Native层的Hook为例
这些JS API在bindings/gumjs/gumquickinterceptor.c绑定了Native层函数。
Interceptor.attach绑定gumjs_interceptor_attach函数。
调用gum_interceptor_attach函数,传入的第四个参数(即flags)为GUM_ATTACH_FLAGS_NONE = 0。
而对于Interceptor.replace,其绑定的是gumjs_interceptor_replace,额外有另一个函数是gumjs_interceptor_replace_fast。它们都调用相同的方法gum_interceptor_replace_with_type,不同之处在于replace模式下传入的第二个参数为GUM_INTERCEPTOR_TYPE_DEFAULT= 0。而replace fast模式下传入的第二个参数为GUM_INTERCEPTOR_TYPE_FAST=1。
尽管如此,gum_interceptor_replace_with_type跟gum_interceptor_attach的关键代码调用相同,因此以gum_interceptor_attach为例进行分析。
gum_interceptor_attach整个代码逻辑是通过事务的方式进行处理的。它首先调用gum_interceptor_resolve()函数以获取真实的函数入口地址。然后调用gum_interceptor_instrument()函数生成底层的跳板代码(相较于一级跳板),最后调用gum_interceptor_transaction_end提交Hook事务,里面会生成一级跳板。
该函数功能主要是递归以穿透跳板代码,获取到真实的hook地址。具体来说,它通过_gum_interceptor_backend_resolve_redirect函数获取目标地址处的前16字节中的首个相对跳转指令,解析出跳转地址,如果存在相对跳转,则进一步递归调用gum_interceptor_resolve函数以获取无相对跳转指令的空间用于inline hook。
gum_ensure_code_readable函数会对目标平台是Android的进行额外处理。对于Android 10以下的版本则不做处理,对于Android 10及以上版本则调用gum_try_mprotect 函数修改页权限。
这里寻找前16字节中的第一个相对跳转指令,解析出跳转的目标地址并返回。
调用gum_interceptor_backend_create_thunks函数预先生成跳板代码thunks,具体来说是enter_thunk和leave_thunk,这些小片段通常负责保存所有寄存器状态 、调用 C 层的拦截函数 、恢复寄存器状态 。
给thunks分配内存后,之后调用gum_memory_patch_code函数(第三个参数传入的是gum_emit_thunks函数指针),该函数主要是对thunks内存的权限进行RWX修复,然后回调gum_emit_thunks函数。
这部分可以不用看,大概就是给thunks所占的页赋予RWX权限,最后回调gum_emit_thunks函数。
创建数组存储thunks所占用的页,从代码逻辑上来看,thunks所占用的页是连续的。之后调用gum_memory_patch_code_pages函数,第三个参数为gum_apply_patch_code函数指针。
修改thunks块所占用的页的权限为RWX。由于thunks本身分配的页就是连续的,因此只回调一次gum_apply_patch_code函数。
往上追溯func来源可以知道是gum_emit_thunks函数,第一个参数mem + page_offset就是thunks的起始地址,第二个参数user_data就是_gum_interceptor_backend_create函数中创建的GumInterceptorBackend结构体。
主要调用gum_emit_enter_thunk函数和gum_emit_leave_thunk函数分别构建enter_thunk跳板以及leave_thunk跳板。
生成的跳板代码如下:
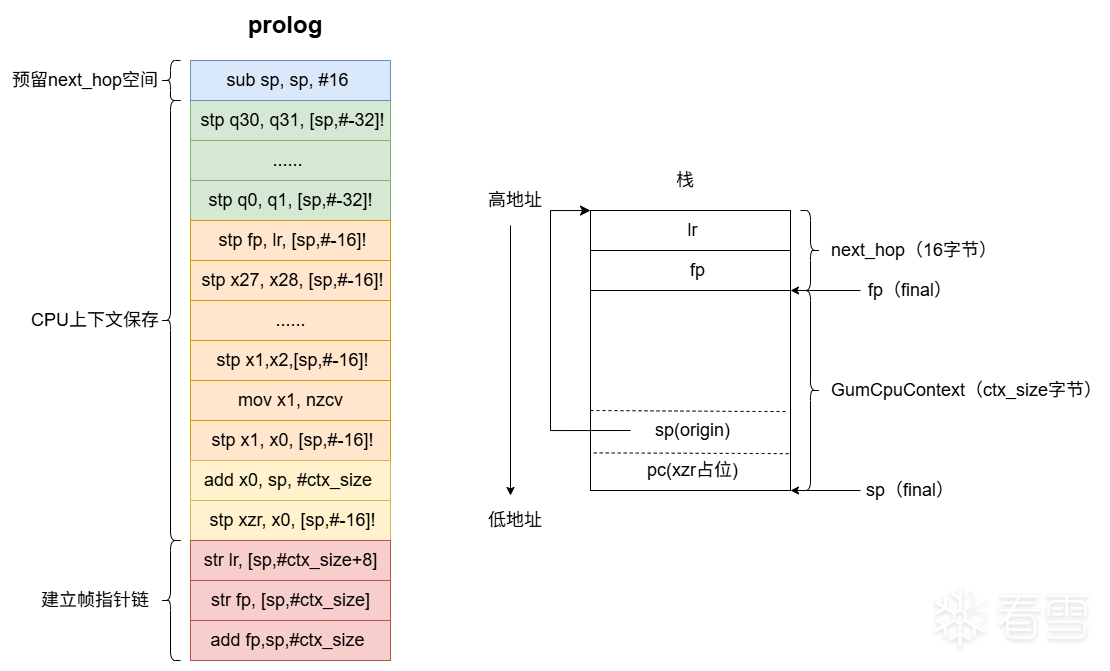
该部分主要生成具有如下功能的代码:在函数进入钩时,保存所有 CPU 寄存器和设置帧指针链,以便后续恢复。构建的指令以及栈布局如下:
为什么会存储两次LR、FP寄存器?这是因为第一次是用于构建GumCpuContext,以便在hook执行后能够恢复原始CPU上下文。第二次是用于构造帧指针链,这是 ARM64 的标准调试/栈回溯机制。每个栈帧存储前一个栈帧的 FP 和 LR,允许调试器、性能分析器或异常处理器遍历调用栈。
回到gum_emit_enter_thunk中,接下来的指令如下:
如果存在onLeave hook,则将function_ctx和caller_ret_addr压入invocation_stack,之后会在_gum_function_context_end_invocation函数中取出并使用。
然后通过执行监听器的on_enter方法进入到自定义的onEnter逻辑。
如果后续存在onLeave hook,就修改栈上保存的GumCpuContext中的lr寄存器的值修改成on_leave_trampoline入口地址,这样后续原函数执行完后,通过ret指令就会回到on_leave_trampoline入口处。
之后根据不同hook类型对栈上的next_hop进行不同修改:如果是replace hook,则修改next_hop为replacement_function地址,否则修改成on_invoke_trampoline地址,这样一来,后续执行完enter_thunk最后一条指令br x16后,就会跳转到目标地址处。
恢复CPU上下文,最终x16寄存器指向next_hop前8字节(此值在_gum_function_context_begin_invocation根据不同情况赋予了不同的值),x17寄存器存储了原来的LR寄存器的值。
当执行最后一条指令时,对于进行了replace hook的情况,则是跳转到replacement_function处,对于非replace hook(即onEnter onLeave hook),则跳转到on_invoke_trampoline处。
这部分对应的伪汇编指令如下:
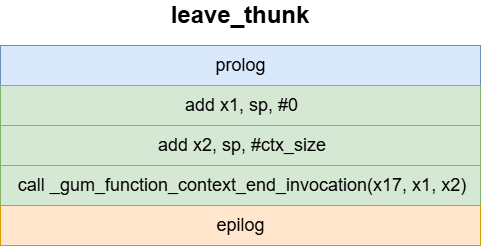
gum_emit_prolog函数和gum_emit_epilog函数前面已经分析过了,这里直接看_gum_function_context_end_invocation函数。
修改next_hop设置为之前在invocation_stack保存的返回地址,这样执行完leav_thunk最后一条指令br x16后,就会跳转到目标地址处(被hook函数的caller ret address)。之后on_leave执行自定义的onLeave代码。
至此,thunks的生成代码已经分析完毕,Hook生成的代码逻辑最终回到gum_interceptor_instrument中,接下来执行的是_gum_interceptor_backend_create_trampoline。
由于该函数太大了,这里就根据功能划分成多个部分进行分析。
首先调用gum_interceptor_backend_prepare_trampoline来获取最大可用于重定向的空间(可用于inline hook空间),给ctx->trampoline_slice分配内存空间用于编写跳板,同时判断是否需要中继器(deflector),以及获取可用的临时寄存器x16或x17。然后初始化writer(其base、code初始化为相同的值)。
之后根据hook类型给中继器跳转目标设置不同的地址:replace fast hook 需要设置中继器目标为replacement_function地址。非replace fast hook(replace与attach)设置中继器目标为on_enter_trampoline的地址,并初始化on_enter_trampoline的起始地址。
对于需要中继器的,则计算相关地址,并调用gum_code_allocator_alloc_deflector为中继器分配内存空间。然后向trampoline_slice写入ldp x0,lr, [sp, #-16]!指令。对于中继器这一块的分析,我将其放置文章末尾了,此处分析没有中继器的情况,这两种情况生成的trampoline_slice差不多,唯一的区别就是多了个刚刚生成的ldp x0,lr, [sp, #-16]!。
对于非replace fast hook,则编写跳板on_enter_trampoline和on_leave_trampoline分别用于跳转到enter_thunk和leave_thunk。
此处开始,不区分hook模式,都设置on_invoke_trampoline的写入地址,它的地址紧挨着on_leave_trampoline,用于跳转到invoke_trampoline。
这部分就是对重定向区域内的原指令进行LR修复并写入on_invoke_trampoline中。
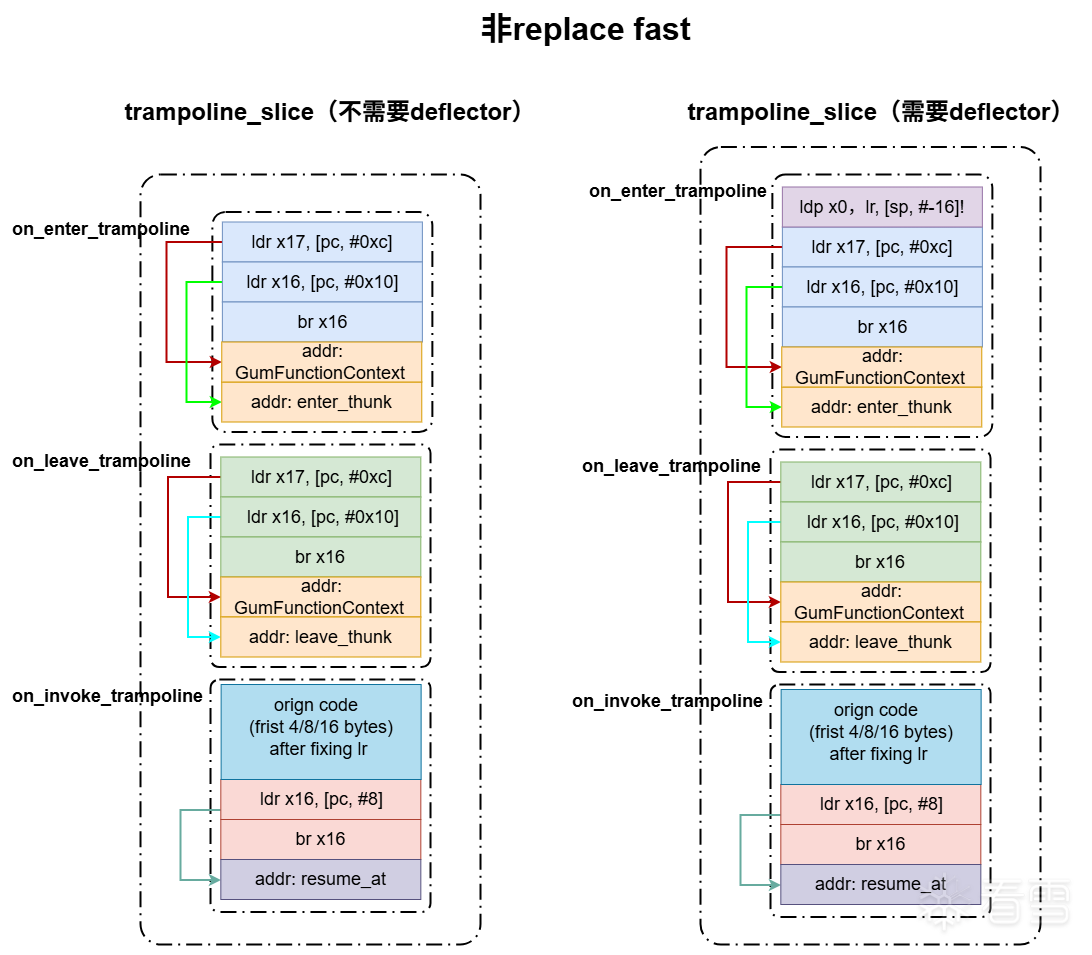
这里继续构造on_invoke_trampoline,用于跳转到后续的原函数代码。以上代码最终生成的跳板指令如下图所示。
备份原函数中inline hook所占用的指令。
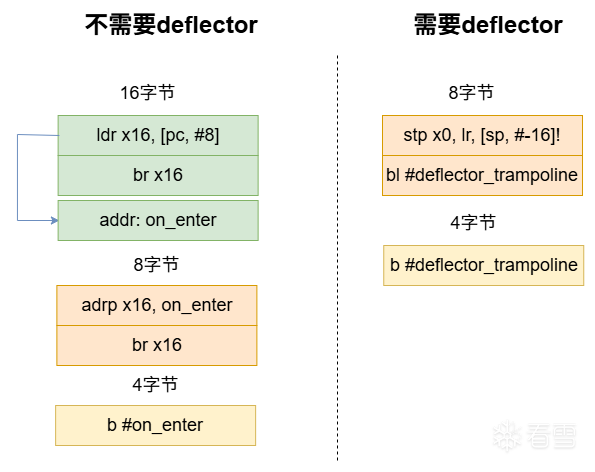
这个函数主要是判断最大可用于重定向的空间(可用于inline hook空间),对于16字节的inline hook,不需要中继器(deflector),而对于4字节或8字节的inline hook,先尝试通过gum_code_allocator_try_alloc_slice_near 函数探寻附近页中是否存在足够可用的空余空间,如果没有找到,则需要中继器(deflector)。之后就是给ctx->trampoline_slice分配内存空间用于编写跳板,同时获取可用的临时寄存器x16或x17。
对于可用空间为4/8字节的inline hook,其跳转范围受限,因此引入中继器(deflector),先让一级跳板跳转到中继器,然后由于中继器可用空间足够,可以像16字节的inline hook一样,跳转的地址不再受到限制。
接下来的代码逻辑回到gum_interceptor_instrument函数中, 下一步调用的关键函数是
传入的第三个参数为gum_interceptor_activate函数指针。
这段代码主要功能是将一个 Hook 更新任务(Update Task)按“内存页”进行归类并排期。在 Frida 中,为了提高性能并确保线程安全,修改内存(Patching)通常不是立即执行的,而是先收集所有任务,最后统一修改。由于修改内存涉及到修改页属性,按页归类可以确保每一页只被执行一次权限切换操作。
接下来的代码逻辑回到gum_interceptor_attach函数中, 下一步调用的关键函数是
关键部分是调用gum_memory_patch_code_pages函数,这个函数在前面已经分析过了,但这里传入的第三个参数是gum_apply_updates函数指针。
这里回调的是gum_interceptor_transaction_schedule_update函数中给update->func设置的gum_interceptor_activate函数。
这里就是一级跳板生成的地方了,该函数主要负责把被hook函数开头的几字节替换成跳转到下一跳板处(on_enter_trampoline或者deflector)的指令。根据可用空间和距离,它可能生成的指令如下图所示。
这里续接二级跳板生成时需要中继器(deflector)的情况,对应代码为
这里通过gum_code_allocator_alloc_deflector函数为中继器分配内存空间。
这里分为两种情况,对于8字节inline hook,先查找已有的deflector dispatcher是否可以复用(目标dispatcher在±128MB内),如果没有找到,则同4字节的inline hook一样,调用gum_code_deflector_dispatcher_new函数创建新的deflector dispatcher。
对于Android ARM32,则会通过gum_process_enumerate_modules枚举现有模块,对每个模块利用 gum_probe_module_for_code_cave 函数在其中找一段没用的、被对齐填充出来的空白区域(Code Cave)。然后这部分空白区域就被当作delfector dispatcher,写入跳转指令(目标为on_enter_trampoline或者replacement_function)。
对于8字节空间的inline hook,额外开辟新的页给到thunk,然后回调gum_write_thunk函数写入跳板代码。
之后4/8字节的inline hook,回调gum_insert_deflector函数往dispatcher(附近页找到的空白区域cave)写入跳板代码。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-5-9 14:22
被gal2xy编辑
,原因: 标题修改