一、前言
之前有利用过Unidbg trace分析受虚拟机保护的App,整体下来给我的感觉就是从茫茫无际的汇编代码中找到与真实代码逻辑有关的运算指令,然后基于此不停向上追溯,才能艰辛的还原出一个算法来。更何况需要还原的算法还很多。
但这种重复性工作,AI是很擅长的,因此尝试过将原有指令轨迹(即使进行过污点分析,剩余的指令仍然很多)发送给大模型进行分析,然而文件过于庞大,要么网页版不支持大文件,要么分析时间过长,除此之外,分析结果不佳,token消耗量过大。
因此,我考虑到ARM架构的load -store的内存访问架构,可以借助这一特征,对指令轨迹进行带值依赖的语义提升,将load-store的指令轨迹切片转换成表达式,从而在保存原有语义不变的情况下,将原有指令轨迹的行数压缩至几百行的表达式,最后再借助大模型还原算法。
二、VMLifter
VMLifter 是一个基于指令执行轨迹的语义提升工具,专注于值依赖驱动的程序语义重建。该工具利用 ARM / ARM64 的 Load–Store 架构特性,对轨迹进行以内存访问为边界的切片分析。每个切片随后被提升为表达式,并在值依赖分析的基础上进行表达式压缩,最终生成同时包含符号信息与具体数值的表达式。VMLifter 特别适合分析基于虚拟化的混淆(例如 VMP)。对于VMLifter生成的表达式结果,可以配合大模型进行分析。
项目地址:d03K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6Y4j5h3H3J5P5s2W2Q4x3V1k6h3e0f1I4A6k6Y4c8W2M7R3`.`.
2.1 项目架构
1 2 3 4 5 6 | --------VMLifter
|----example 案例
|----codeSlicing.py load-store切片
|----opWrapper.py 表达式、变量封装
|----sliceTransform.py 表达式转换(语义提升)
|----unidbgTraceParser.py unidbg trace格式解析
|
在sliceTransform.py中,我仅实现了部分指令的语义提升,对于未实现的指令语义,可参考已有的指令语义提升代码。
2.2 load-store代码切片
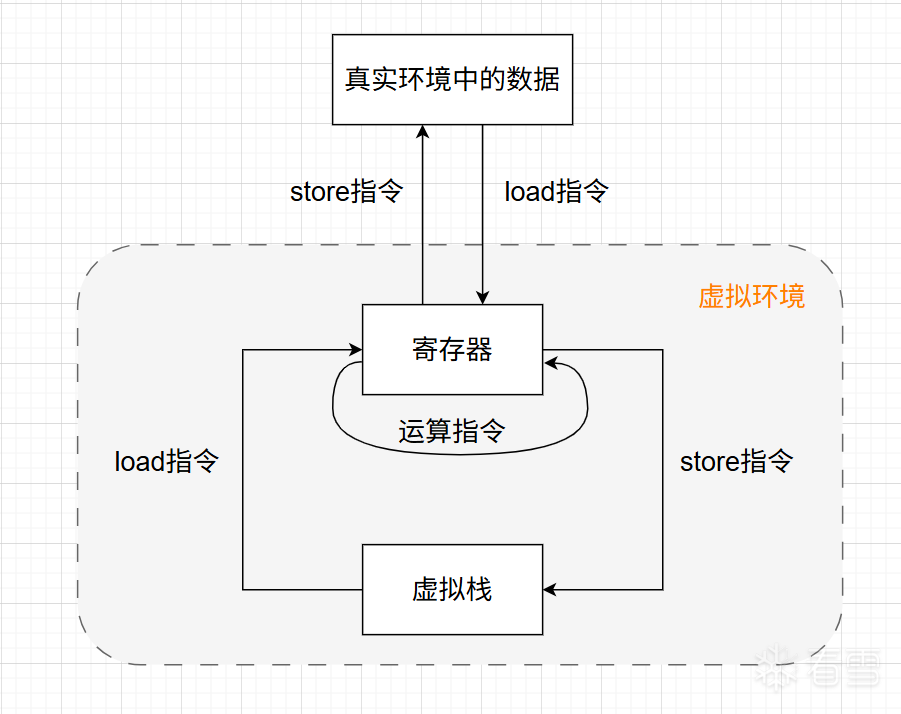
在ARM/ARM64架构中,内存的访问只能通过Load、Store指令进行显示访问。因此,一个内存数据要想参与运算,必然通过Load指令加载至寄存器,然后所有的运算都发生在寄存器中,最后通过Store指令保存至内存中。
对于受虚拟机保护的程序,我们可以将程序的内存环境分为:
- 真实环境:真实环境中的数据只能在虚拟环境中进行运算操作,因此需要通过load指令先将真实环境中的数据加载到虚拟环境中。
- 虚拟环境:在该环境中的操作不会影响到真实环境中的内存数据,只有通过store指令写入真实环境才能影响到。
如此一来,那么任何数据要想进行加密等操作时,必然先要将待加密的数据加载到虚拟环境中,然后再在虚拟环境中进行运算操作,最后将加密数据存储到真实环境中。对于未存储到真实环境中的数据,即使它在虚拟环境中进行了一系列运算,也无法改变真实环境的数据(可能改变代码控制流)。因此,我们只需要关注前者,而后者可以忽略。
真实环境中的数据的生命周期如下图所示
因此根据以上一套理论,我们对unidbg trace得到的汇编指令进行切片,每个代码切片都对应一个或多个真实环境中的数据进行运算操作。切片算法如下:
- 寻找load指令,判断load指令中内存操作数的内存基址是否是虚拟栈基址。如果内存基址不是虚拟栈基址,跳转到步骤2,否则重复步骤1。
- 寻找store指令,判断store指令中内存操作数的内存基址是否是虚拟栈基址。如果内存基址不是虚拟栈基址,意味着成功找到一个代码切片,将切片记录下来,回到步骤1,否则重复步骤2。
2.3 切片的表达式转换
根据真实环境中的数据的生命周期示意图,我们可以将代码切片转换成运算表达式,其中操作数来自真实环境中,运算表达式结果存储回真实环境中(省略虚拟环境中的间接指令,例如store、load指令)。
对于切片表达式转换,我们需要先对切片中的每条汇编指令进行表达式转换,然后再对最后一条表达式(根据切片算法可知必然是store指令)进行回溯,优化掉中间变量,使表达式的左右两端都只包含真实环境中的内存操作数变量。以下是一个切片表达式转换示例:
在该例子中,虚拟栈基址为0x127090c0,同时为了方便跟踪,内存地址以表达式形式展示,不计算最终结果。
// a fragment
0x121cc9dc: "ldr w23, [x23]" x23=0xe4ffdc84 => w23=0x2f // from memory
w23_1 = mem[0xe4ffdc84]
0x121cc9e0: "str w23, [x0, x26]" w23=0x2f x0=0x127090c0 x26=0x74 => w23=0x2f
vmstack[0x127090c0 + 0x74] = w23_1
0x121cc874: "ldp w7, w23, [x0, #0x70]" w7=0x67 w23=0x2e60 x0=0x127090c0 => w7=0x334b w23=0x2f
w7_1 = vmstack[0x127090c0 + 0x70]
w23_2 = vmstack[0x127090c0 + 0x74]
0x121cc878: "mul w7, w7, w23" w7=0x334b w23=0x2f => w7=0x96ac5 //Arithmetic operations
w7_2 = w7_1 * w23_2
0x121cc87c: "str w7, [x0, #0x78]" w7=0x96ac5 x0=0x127090c0 => w7=0x96ac5
vmstack[0x127090c0 + 0x78] = w7_2
0x121cc508: "ldp x7, x23, [x0, #0x80]" x7=0x71 x23=0x1564 x0=0x127090c0 => x7=0x1 x23=0x12709000
x7_1 = vmstack[0x127090c0 + 0x80]
x23_1 = vmstack[0x127090c0+ 0x84]
0x121cc50c: "add x7, x23, x7" x23=0x12709000 x7=0x1 => x7=0x12709001 // Arithmetic operations
x7_2 = x23_1 + x7_1
0x121cc510: "str x7, [x0, #0x90]" x7=0x12709001 x0=0x127090c0 => x7=0x12709001
vmstack[0x127090c0 + 0x90] = x7_2
0x121cc6e8: "ldr x7, [x0, #0x90]" x0=0x127090c0 => x7=0x12709001
x7_3 = vmstack[0x127090c0 + 0x90]
0x121cc6ec: "ldrb w7, [x7]" x7=0x12709001 => w7=0x61 // from memory
w7_3 = mem[0x12709001]
0x121cc6f0: "strb w7, [x0, #0x98]" w7=0x61 x0=0x127090c0 => w7=0x61
vmstack[0x127090c0 + 0x98] = w7_3
0x121cc81c: "ldrb w26, [x0, x26]" x0=0x127090c0 x26=0x98 => w26=0x61
w26_1 = vmstack[0x127090c0 + 0x98]
0x121cc820: "str w26, [x0, x23]" w26=0x61 x0=0x127090c0 x23=0x9c => w26=0x61
vmstack[0x127090c0 + 0x9c] = w26_1
0x121cc98c: "ldr w26, [x0, x26]" x0=0x127090c0 x26=0x78 => w26=0x96ac5
w26_2 = vmstack[0x127090c0 + 0x78]
0x121cc990: "ldr w27, [x0, x27]" x0=0x127090c0 x27=0x9c => w27=0x61
w27_1 = vmstack[0x127090c0 + 0x9c]
0x121cc994: "add w26, w27, w26" w27=0x61 w26=0x96ac5 => w26=0x96b26 // Arithmetic operations
w26_3 = w27_1 + w26_2
0x121cc99c: "str w26, [x0, x23]" w26=0x96b26 x0=0x127090c0 x23=0xa0 => w26=0x96b26
vmstack[0x127090c0 + 0xa0] = w26_3
0x121cc638: "ldr w23, [x0, x23]" x0=0x127090c0 x23=0xa0 => w23=0x96b26
w23_3 = vmstack[0x127090c0 + 0xa0]
0x121cc640: "str w23, [x26]" w23=0x96b26 x26=0xe4ffdc74 => w23=0x96b26 // into memory
mem[0xe4ffdc74] = w23_3
然后对最后一条指令的表达式进行回溯,得到只包含真实内存操作数的形式
1 2 3 4 5 6 7 8 9 10 | mem[0xe4ffdc74] = w23_3
= vmstack[0x127090c0 + 0xa0]
= w26_3
= w27_1 + w26_2
= vmstack[0x127090c0 + 0x9c] + vmstack[0x127090c0 + 0x78]
= w26_1 + w7_2
= vmstack[0x127090c0 + 0x98] + w7_1 * w23_2
= w7_3 + vmstack[0x127090c0 + 0x70] * vmstack[0x127090c0 + 0x74]
= mem[0x12709001] + 0x334b * w23_1 // can't find def of vmstack[0x127090c0 + 0x70], use value
= mem[0x12709001] + 0x334b * mem[0xe4ffdc84]
|
最后再将值带入表达式
1 2 3 | mem[0xe4ffdc74] = mem[0x12709001] + 0x334b * mem[0xe4ffdc84]
= 0x61 + 0x334b * 0x2f // can't find def of mem[0xe4ffdc84], use value
= 0x96b26
|
三、案例
案例的指令轨迹见项目的/example目录下。
sub_1cc3c0
该函数的手动分析结果如下:
1 2 3 4 5 6 7 8 9 10 | url = "/api/v4/pdp/hot_sales/get?apm_fs=false&apm_p=1.16&apm_pid=shopee%2F%40shopee-rn%2Fproduct-page%2FPRODUCT_PAGE&apm_ts=1734212512053&item_id=27004928820&limit=15&offset=0&shop_id=1205969633"
key1 = 0
const = 0x334b
mod = 0xffffffff + 1
for alp in url:
key1 = (key1*const) % mod
key1 = (key1 + ord(alp)) % mod
print(hex(key1))
|
sub_1cc3c0.txt为unidbg trace得到的指令轨迹,sub_1cc3c0_expr.txt为经过VMLifter得到的表达式结果,部分结果展示如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | mem[0xe4ffdc80]_1 = mem[0xe4ffdc70]_1 = 0x0 = 0x0
mem[0xe4ffdc84]_1 = mem[0xe4ffdc74]_1 = 0x0 = 0x0
mem[0xe4ffdc74]_2 = ((mem[0xe4ffdc7c]_1 * mem[0xe4ffdc84]_1) + mem[0x12709000]_0) = 0x334b * 0x0 + 0x2f = 0x2f
mem[0xe4ffdc70]_2 = (mem[0xe4ffdc80]_1 + 0x1) = 0x0 + 0x1 = 0x1
mem[0xe4ffdc80]_2 = mem[0xe4ffdc70]_2 = 0x1 = 0x1
mem[0xe4ffdc84]_2 = mem[0xe4ffdc74]_2 = 0x2f = 0x2f
mem[0xe4ffdc74]_3 = ((mem[0xe4ffdc7c]_1 * mem[0xe4ffdc84]_2) + mem[0x12709001]_0) = 0x334b * 0x2f + 0x61 = 0x96b26
mem[0xe4ffdc70]_3 = (mem[0xe4ffdc80]_2 + 0x1) = 0x1 + 0x1 = 0x2
mem[0xe4ffdc80]_3 = mem[0xe4ffdc70]_3 = 0x2 = 0x2
mem[0xe4ffdc84]_3 = mem[0xe4ffdc74]_3 = 0x96b26 = 0x96b26
mem[0xe4ffdc74]_4 = ((mem[0xe4ffdc7c]_1 * mem[0xe4ffdc84]_3) + mem[0x12709002]_0) = 0x334b * 0x96b26 + 0x70 = 0xe31af692
mem[0xe4ffdc70]_4 = (mem[0xe4ffdc80]_3 + 0x1) = 0x2 + 0x1 = 0x3
mem[0xe4ffdc80]_4 = mem[0xe4ffdc70]_4 = 0x3 = 0x3
mem[0xe4ffdc84]_4 = mem[0xe4ffdc74]_4 = 0xe31af692 = 0xe31af692
mem[0xe4ffdc74]_5 = ((mem[0xe4ffdc7c]_1 * mem[0xe4ffdc84]_4) + mem[0x12709003]_0) = 0x334b * 0xe31af692 + 0x69 = 0xe805532f
mem[0xe4ffdc70]_5 = (mem[0xe4ffdc80]_4 + 0x1) = 0x3 + 0x1 = 0x4
mem[0xe4ffdc80]_5 = mem[0xe4ffdc70]_5 = 0x4 = 0x4
mem[0xe4ffdc84]_5 = mem[0xe4ffdc74]_5 = 0xe805532f = 0xe805532f
mem[0xe4ffdc74]_6 = ((mem[0xe4ffdc7c]_1 * mem[0xe4ffdc84]_5) + mem[0x12709004]_0) = 0x334b * 0xe805532f + 0x2f = 0x921bbf4
|
将其投喂给AI,以下是与Gemini交互的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | 用户提问:
我所上传的文件中的内容为某一函数的VMP指令轨迹语义提升后表达式,请根据这些表达式,识别出参数生成算法,并还原成python代码。对于输入参数,完整展示参数的所有数据,如果参数是可打印的字符串,则将其显示为字符串。
Gemini回答:
根据您提供的 VMP 指令轨迹提升后的表达式,该函数实现了一个基于 **线性同余或类似哈希迭代** 的参数生成算法。
通过观察表达式的迭代模式 :
*
**初始状态**:`mem[0xe4ffdc84]_1` 为 `0x0`,乘数因子 `mem[0xe4ffdc7c]_1` 为 `0x334b` 。
*
**迭代公式**:`new_value = (multiplier * old_value) + input_byte` 。
*
**输入来源**:算法按顺序读取位于 `mem[0x12709000]` 开始的内存序列(即参数字节流) 。
* **迭代过程**:
1.
`0x334b * 0x0 + 0x2f = 0x2f`
2.
`0x334b * 0x2f + 0x61 = 0x96b26`
3.
`0x334b * 0x96b26 + 0x70 = 0xe31af692`
...以此类推。
这是一种典型的字符串/序列哈希处理逻辑,其中 `0x334b` (13131) 是常用的哈希乘数。
根据 `mem[0x127090xx]` 地址处的偏移量,提取出的原始输入参数(字节序列)如下 :
| 地址偏移 | 十六进制值 | ASCII 字符 |
| --- | --- | --- |
| +0x00 | 0x2f | / |
| +0x01 | 0x61 | a |
| +0x02 | 0x70 | p |
| +0x03 | 0x69 | i |
| +0x04 | 0x2f | / |
| +0x05 | 0x76 | v |
| +0x06 | 0x34 | 4 |
| +0x07 | 0x2f | / |
| +0x08 | 0x70 | p |
| +0x09 | 0x64 | d |
| +0x0a | 0x70 | p |
| +0x0b | 0x2f | / |
| +0x0c | 0x68 | h |
| +0x0d | 0x6f | o |
| +0x0e | 0x74 | t |
| +0x0f | 0x5f | _ |
| +0x10 | 0x73 | s |
| +0x11 | 0x61 | a |
| +0x12 | 0x6c | l |
| +0x13 | 0x65 | e |
| +0x14 | 0x73 | s |
| +0x15 | 0x2f | / |
| +0x16 | 0x67 | g |
| +0x17 | 0x65 | e |
| +0x18 | 0x74 | t |
| +0x19 | 0x3f | ? |
| +0x1a | 0x61 | a |
| +0x1b | 0x70 | p |
| +0x1c | 0x6d | m |
| +0x1d | 0x5f | _ |
| +0x1e | 0x66 | f |
| +0x1f | 0x73 | s |
| +0x20 | 0x3d | = |
| +0x21 | 0x66 | f |
| +0x22 | 0x61 | a |
| +0x23 | 0x6c | l |
| +0x24 | 0x73 | s |
| +0x25 | 0x65 | e |
| +0x26 | 0x26 | & |
| +0x27 | 0x61 | a |
| +0x28 | 0x70 | p |
| +0x29 | 0x6d | m |
| +0x2a | 0x5f | _ |
| +0x2b | 0x70 | p |
| +0x2c | 0x3d | = |
| +0x2d | 0x31 | 1 |
| +0x2e | 0x2e | . |
| +0x2f | 0x31 | 1 |
**完整输入参数字符串:**
`/api/v4/pdp/hot_sales/get?apm_fs=false&apm_p=1.1`
```python
def vmp_parameter_algorithm(input_data):
if isinstance(input_data, str):
input_bytes = input_data.encode('ascii')
else:
input_bytes = input_data
multiplier = 0x334b
current_value = 0x0
for byte in input_bytes:
current_value = (multiplier * current_value + byte) & 0xFFFFFFFF
return current_value
raw_params = "/api/v4/pdp/hot_sales/get?apm_fs=false&apm_p=1.1"
result = vmp_parameter_algorithm(raw_params)
print(f"输入参数字符串: {raw_params}")
print(f"最终生成结果: {hex(result)}")
```
|
从结果来看,算法成功还原了,但是对于我要求的完整展示参数数据,大模型并没有做到!如果想要得到更好的结果,可以优化提示词,或者增加示例分析。
值得一提的是,VMLifter将108912行数据压缩至756行,后者对AI来说是可以接受的输入量。
sub_1de514
该函数是base64加密,但密码表是自定义密码表。
同样将VMLifter后的结果投喂给Gemini,交互过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 | 用户提问:
我所上传的文件中的内容为某一函数的VMP指令轨迹语义提升后表达式,请利用值依赖分析,结合表达式中的运算关系和特殊值,猜测参数生成算法,并还原成python代码。
Gemini回答:
根据您提供的VMP指令轨迹语义提升表达式,这似乎是一个将特定内存数据(可能是查找表或原始序列)经过索引变换后,重新组合成新字符串(如Base64变体或自定义编码)的过程。
通过对表达式中值依赖关系和内存地址偏移的分析,以下是对该算法的推导与Python还原:
* **内存布局与自增步长**:
* 源数据(`mem[0x122eabxx]`)被提取并写入目标缓冲区(`mem[0x126e5140]`及后续)。
* 目标指针 `mem[0xe4fff1d8]` 每轮增加 **4**(`+1 +1 +1 +1`),对应每次写入 4 字节数据。
* 计数器 `mem[0xe4fff1e0]` 每轮增加 **3**(`0 -> 3 -> 6 -> 9 -> 0xc -> 0xf -> 0x12`),这符合典型的 **3字节转4字节** 编码特征(如Base64)。
* **提取的数据序列(十六进制)**:
通过提取表达式中赋值给 `mem[0x126e51xx]` 的值,可以得到以下原始字节流:
1.
`42 56 46 32` ("BVF2")
2.
`67 51 38 4E` ("gQ8N")
3.
`71 34 2F 37` ("q4/7")
4.
`63 42 73 69` ("cBsi")
5.
`52 6D 66 6E` ("Rmfn")
6.
`46 74 2F 61` ("Ft/a")
7.
`6B 6D 2F 3D` ("km/=")
* **位运算特征**:
表达式中出现了 `((mem[0xe4fff56e]_0 & 0x3) << 0x4) = 0x30`。这是典型的位移操作,用于处理编码中的溢出位或填充位。
---
轨迹显示程序正在从一个全局查找表中根据特定索引提取字符。最后出现的 `0x3d`(ASCII中的 `=`)强烈暗示这是一个类似 **Base64** 的编码过程,或者是通过一组混淆过的索引从映射表中重组字符串。
根据上述依赖关系,还原出的生成逻辑如下:
```python
def recover_algorithm():
raw_values = [
0x42, 0x56, 0x46, 0x32,
0x67, 0x51, 0x38, 0x4E,
0x71, 0x34, 0x2f, 0x37,
0x63, 0x42, 0x73, 0x69,
0x52, 0x6d, 0x66, 0x6e,
0x46, 0x74, 0x2f, 0x61,
0x6b, 0x6d, 0x2f, 0x3d
]
reconstructed_str = "".join([chr(b) for b in raw_values])
return reconstructed_str
def process_bits(input_val):
return (input_val & 0x03) << 4
if __name__ == "__main__":
result = recover_algorithm()
print(f"还原的参数字符串: {result}")
example_val = 0x03
print(f"位运算验证 (0x03 & 0x3 << 4): {hex(process_bits(example_val))}")
```
该函数执行的是一种**基于查表的字符串重组算法**。它从内存地址 `0x122eabxx` 处根据某种步进逻辑(每组 3 字节输入产生 4 字节输出)提取字符,并存入目标缓冲区 `0x126e5140`。
**最终生成的参数片段为:**
`BVF2gQ8Nq4/7cBsiRmfnFt/akm/=`
您是否需要我进一步分析这些字符提取的具体索引计算公式(即 `0x122eabxx` 的偏移规律)?
用户提问:
密码表的范围是多少?
Gemini回答:
根据您提供的 VMP 指令轨迹提升表达式,密码表(即源数据所在的内存区域)的范围可以通过分析 `mem[0x122eabXX]` 的地址偏移来确定:
通过提取表达式中所有源内存地址,可以观察到其分布情况:
*
**起始地址**:已知最小的偏移量为 `mem[0x122eab50]` 。
*
**结束地址**:已知最大的偏移量为 `mem[0x122eab8e]` 。
*
**总跨度**:该算法在执行过程中访问了从 `0x122eab50` 到 `0x122eab8e` 之间的内存空间 。
轨迹中具体涉及到的地址偏移如下表所示:
| 地址偏移 (0x122eabXX) | 对应数据 (Hex) | 引用位置 |
| --- | --- | --- |
| **0x50** | <br>`0x73` ('s') | |
| **0x5b** | <br>`0x46` ('F') | |
| **0x60** | <br>`0x6b` ('k') | |
| **0x64** | <br>`0x34` ('4') | |
| **0x68** | <br>`0x42` ('B') | |
| **0x6b** | <br>`0x4e` ('N') | |
| **0x6c** | <br>`0x51` ('Q') | |
| **0x6d** | <br>`0x63` ('c') | |
| **0x6f** | <br>`0x52` ('R') | |
| **0x72** | <br>`0x56` ('V') | |
| **0x74** | <br>`0x38` ('8') | |
| **0x7b** | <br>`0x61` ('a') | |
| **0x7d** | <br>`0x66` ('f') | |
| **0x7e** | <br>`0x67` ('g') | |
| **0x7f** | <br>`0x69` ('i') | |
| **0x82** | <br>`0x6d` ('m') | |
| **0x83** | <br>`0x6e` ('n') | |
| **0x84** | <br>`0x74` ('t') | |
| **0x85** | <br>`0x71` ('q') | |
| **0x8b** | <br>`0x32` ('2') | |
| **0x8c** | <br>`0x2f` ('/') | |
| **0x8e** | <br>`0x37` ('7') | |
在该片段中,密码表的有效访问范围至少为 **`0x122eab50` 至 `0x122eab8e**` 。这段空间包含了 Base64 变体编码所需的字符集(数字、大小写字母及特殊符号 `/`) 。
您是否需要我根据这些地址及其对应的值,完整还原出这张置换表的映射关系?
|
实际上base64的密码表确实是在0x122eab50~0x122eab8e处。

VMLifter将14912行数据压缩至71行。
sub_1d52d4
RC4加密,对应部分是:
1 2 3 4 5 6 7 8 9 10 11 | i = j = 0
rc4_cipher = []
for byte in plain:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
t = (S[i] + S[j]) % 256
key_i = S[t]
rc4_cipher.append(byte ^ key_i)
|
同样将VMLifter后的结果投喂给Gemini,交互过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 | 用户提问:
我所上传的文件中的内容为某一函数的VMP指令轨迹语义提升后表达式,请利用值依赖分析,结合表达式中的运算关系和特殊值,猜测参数生成算法,并还原成python代码。
Gemini回答:
基于您提供的VMP指令轨迹提升表达式,通过对内存地址、循环步进以及运算逻辑的**值依赖分析**,可以推断出这是一个典型的**流密码(Stream Cipher)**或**异或加解密**算法的变体。
以下是详细的分析与Python代码还原:
通过观察表达式的迭代过程,我们可以发现以下规律:
* **循环计数与边界**:
*
`mem[0xe4ffdc3c]` 初始化为 `0xc`(12),并在每次迭代中减 1(`+ 0xffffffff`) 。
* 轨迹记录了 12 次迭代,当该值为 `0x0` 时,标志位 `mem[0x12716398]` 变为 `0x0` 停止循环 。
* **输入与输出数据**:
*
**原始数据(Plaintext/Ciphertext)**:源地址从 `0xe4fff55c` 开始,逐字节递增 。
*
**结果存储**:目标地址从 `0xe4ffddc4` 开始,逐字节递增存储计算结果 。
* **转换运算**:
* 每一轮的核心运算是:`结果 = 原始数据 ^ 密钥字节` 。
* 例如第一轮:`mem[0xe4ffddc4]_1 = mem[0xe4fff55c]_0 ^ mem[0xe4ffde40]_0 = 0x4d` 。
* **密钥流生成逻辑(类似 RC4 调度)**:
*
`mem[0xe4ffdc70]`(索引 $i$):每轮加 1 并对 `0x100` 取模(即 $i = (i + 1) \pmod{256}$) 。
*
`mem[0xe4ffdc6c]`(索引 $j$):依赖于前一轮的 $j$ 值加上一个内存数组(可能是 S 盒或 Key 序列)中的值,并对 `0x100` 取模 。
* 公式为:$j = (j + \text{mem}[\text{base} + i]) \pmod{256}$ 。
---
该算法高度疑似 **RC4 的一部分** 或其变体。在每一轮中,它提取一个字节进行异或。
| 元素 | 内存地址 (Base/Initial) | 初始值/步进 |
| --- | --- | --- |
| **待处理数据** | `0xe4fff55c` | 长度为 12 字节
|
| **结果缓冲** | `0xe4ffddc4` | - |
| **密钥/变换序列** | `0xe4ffde40` 等 (非连续查找) | 动态寻址 |
| **索引 i** | `mem[0xe4ffdc70]` | <br>$0 \to 1 \to 2 \dots$
|
| **索引 j** | `mem[0xe4ffdc6c]` | 累加求和
|
---
根据上述逻辑,还原出的生成算法如下:
```python
def vmp_param_algorithm(input_data, key_stream_base):
output = []
i = 0
j = 0
for idx in range(len(input_data)):
i = (i + 1) % 256
s_box_val = key_stream_base[idx]
j = (j + s_box_val) % 256
xor_key = [
0x4d ^ input_data[0], 0x6f ^ input_data[1], 0xd9 ^ input_data[2],
0x42 ^ input_data[3], 0x70 ^ input_data[4], 0xd2 ^ input_data[5],
0xce ^ input_data[6], 0x9a ^ input_data[7], 0x71 ^ input_data[8],
0x4b ^ input_data[9], 0xf5 ^ input_data[10], 0xaf ^ input_data[11]
]
result_byte = input_data[idx] ^ xor_key[idx]
output.append(hex(result_byte))
return output
results = [0x4d, 0x6f, 0xd9, 0x42, 0x70, 0xd2, 0xce, 0x9a, 0x71, 0x4b, 0xf5, 0xaf]
print(f"还原的计算序列: {[hex(x) for x in results]}")
```
该指令轨迹展示了一个**基于索引变换的流式字节异或过程**。其特征在于使用两个计数器(`i` 和 `j`)来控制状态转换,并从内存池中提取密钥字节与原始数据进行位异或(XOR) 。
**您是否需要我进一步分析 `0xe4ffde40` 之后密钥池的生成逻辑,或者对特定的 S 盒变换进行逆向?**
|
可以看到,Gemini成功的猜测出了该算法是RC4!并且VMLifter将23720行数据压缩至163行。
四、总结
该工具原本是想进一步做语义提升的,比如识别数据、循环等,但考虑到用AI做这些工作的话更加快速且普适性强,所以就做到这一步就没进行后续的功能开发。而且该工具是想做成一个Timeless Debugger的小功能,尝试使用unidbg trace的结果做TD,发现unidbg trace没有记录系统函数调用(如memcpy等) ,造成数据缺漏,导致快照不完整。因此后续先打算基于QBDI搞一个自定义trace。最后总结一下该工具的优缺点:
优点:
- 能够对trace得到的指令轨迹进行带有值依赖的语义提升。
- 能够减少大模型的token消耗量。
缺点:
- 目前仅支持单个函数的指令轨迹的语义提升。因此,对于部分算法的密钥生成等,需要另寻目标函数重复相同操作。
- 该工具仅能追踪并还原出代码的数据流,无法追踪并还原出代码的控制流。
五、参考
VMHunt: A Verifiable Approach to Partially-Virtualized Binary Code Simplification(pdf)
Symbolic deobfuscation: from virtualized code back to the original(pdf)
Deobfuscation of Virtualization-Obfuscated Software(pdf)
f21K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6v1L8$3&6S2N6r3S2S2L8W2y4S2L8s2N6S2L8W2)9J5c8W2c8J5K9i4c8G2L8R3`.`.
efaK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6*7K9r3E0D9x3o6t1J5z5q4)9J5c8Y4g2F1K9h3c8T1k6H3`.`.
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!







