将 debugger 关键字的 token 换成 null, 添加一个自己关键字
因为不是阅读 v8 代码的文章, 不在介绍怎么从头跟了, 直接看 v8/src/parsing/scanner-inl.h 中的 V8_INLINE Token::Value Scanner::ScanSingleToken 函数, 解释器的第一步, 将扫描文本生成 token 找到识别关键字的代码
向前跟两补到达 V8_INLINE Token::Value Scanner::ScanIdentifierOrKeywordInner 函数, 来看看这段代码:
阻碍我们添加关键字的第一道门槛是 CanBeKeyword(scan_flags) 预判断, 关键字经过它后才能进入 KeywordOrIdentifierToken 函数做一个完全判断。让我们看看 scan_flags 是怎么生成的, 关键地方是这里:
v8 在辨别是关键字还是变量的预判断中做了一个映射表, 即判断哪些标识符可能是关键字, 哪些标识符一看就不可能, 直接筛去一部分, 以提高运行效率。以 flags 的形式记录, 让我们看看 character_scan_flags 是怎么生成的:
总结来说就是将 0-127 输入 GetScanFlags 函数, 然后与结果做一个映射, 用 py 实现就是:
因为 char 实际上是一个 0-127 直接的数字, 所以可以直接使用。接下来重点放在 CanBeKeywordCharacter IsKeywordStart 函数, 先来看 CanBeKeywordCharacter:
利用了递归模板元编程已经一些宏的骚操作, 总的来说就是将所用的关键字全拼接起来形成一个长字符串, 像这样 "asyncawaitbreakcase..." 然后如果要检查的字符在这堆字符串中就返回 true, 如果遍历完了这段字符串也没找到就返回 false,
然后是 IsKeywordStart
简单来说就是检查开头, 如果首字符对不上就是 false, 对上了就认为可能是关键字。
好了, 现在我们可以通过 KeywordOrIdentifierToken 函数跟入 v8/src/parsing/keywords-gen.h 中的 PerfectKeywordHash::GetToken 函数了:
这是最小完美哈希的实现, 通过精心构造的哈希函数,确保所有关键字的哈希值在 [0, 127] 范围内互不冲突。每个关键字映射到唯一的桶(key), 有现成的算法可以生成完美哈希。
我们用 py 简单模拟一下:
这就是 v8 判断关键字的全部流程。
让我们从 v8/src/parsing/keywords-gen.h 开始。事实上官方提供了生成脚本 v8/tools/gen-keywords-gen-h.py 配合 v8/src/parsing/keywords.txt, 可以生成对应的 v8/src/parsing/keywords-gen.h, 因为我是在 windows 上开发的, 不太好使用 gperf 工具, 所以就不从自定义 keywords.txt 文件开始, 生成 keywords-gen.h 文件了
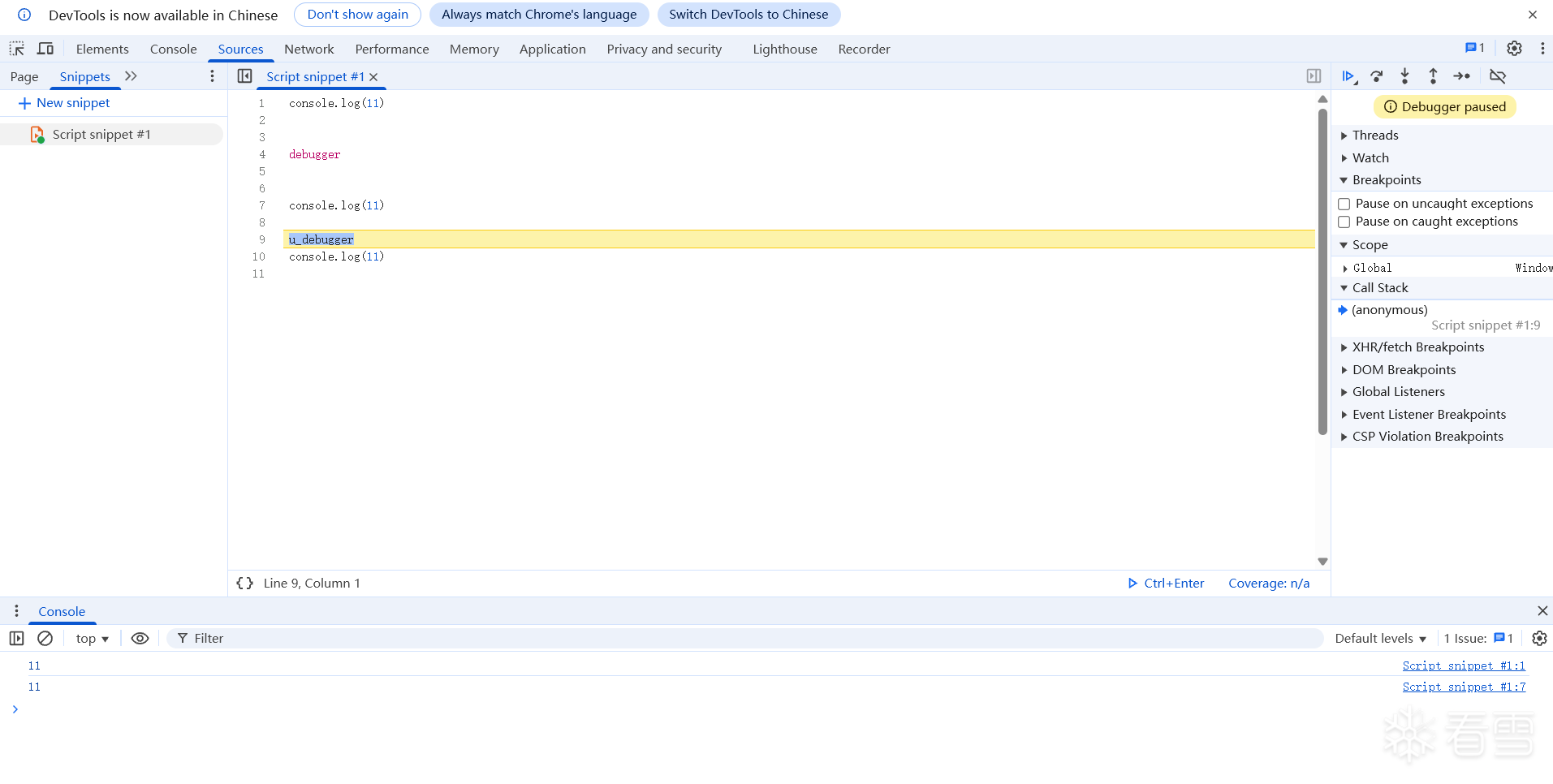
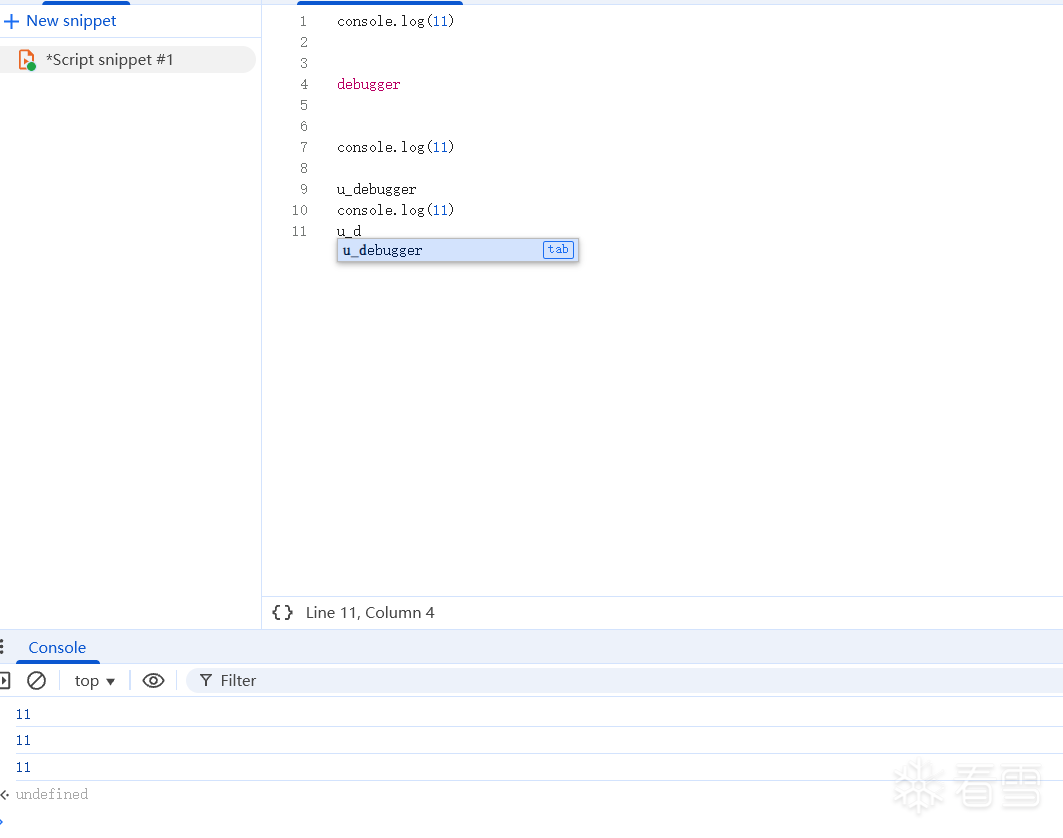
理想的情况是不改变 PerfectKeywordHash::Hash 函数中的 asso_values, 而是在 kPerfectKeywordHashTable 空闲的位置自定义一个关键字。好消息是有非常多的空闲位置, 如 u_debugger 对应的 hash 值为 111

这样只是做好了第一步, 还要往回看, 关键字的预判断
来到 v8/src/parsing/scanner-inl.h 文件的 #define KEYWORDS(KEYWORD_GROUP, KEYWORD), 增加:
这里 KEYWORD("debugger", Token::kDebugger) 中的 Token::kDebugger 可以不用修改, 因为没用到
两个 debugger 对比
代码提示
附件方法 738K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6F1L8%4c8Z5K9h3&6Y4i4K6u0V1x3U0x3K6x3#2)9J5c8V1y4Z5M7X3!0E0K9i4g2E0e0h3!0V1
case Token::kIdentifier:
return ScanIdentifierOrKeyword();
case Token::kIdentifier:
return ScanIdentifierOrKeyword();
if (!CanBeKeyword(scan_flags)) return Token::kIdentifier;
base::Vector<const uint8_t> chars =
next().literal_chars.one_byte_literal();
return KeywordOrIdentifierToken(chars.begin(), chars.length());
if (!CanBeKeyword(scan_flags)) return Token::kIdentifier;
base::Vector<const uint8_t> chars =
next().literal_chars.one_byte_literal();
return KeywordOrIdentifierToken(chars.begin(), chars.length());
AdvanceUntil([this, &scan_flags](base::uc32 c0) {
if (V8_UNLIKELY(static_cast<uint32_t>(c0) > kMaxAscii)) {
scan_flags |=
static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath);
return true;
}
uint8_t char_flags = character_scan_flags[c0];
scan_flags |= char_flags;
if (TerminatesLiteral(char_flags)) {
return true;
} else {
AddLiteralChar(static_cast<char>(c0));
return false;
}
});
AdvanceUntil([this, &scan_flags](base::uc32 c0) {
if (V8_UNLIKELY(static_cast<uint32_t>(c0) > kMaxAscii)) {
scan_flags |=
static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath);
return true;
}
uint8_t char_flags = character_scan_flags[c0];
scan_flags |= char_flags;
if (TerminatesLiteral(char_flags)) {
return true;
} else {
AddLiteralChar(static_cast<char>(c0));
return false;
}
});
static constexpr const uint8_t character_scan_flags[128] = {
#define CALL_GET_SCAN_FLAGS(N) GetScanFlags(N),
INT_0_TO_127_LIST(CALL_GET_SCAN_FLAGS)
#undef CALL_GET_SCAN_FLAGS
};
constexpr uint8_t GetScanFlags(char c) {
return
(IsAsciiIdentifier(c) && !CanBeKeywordCharacter(c)
? static_cast<uint8_t>(ScanFlags::kCannotBeKeyword)
: 0) |
(IsKeywordStart(c)
? 0
: static_cast<uint8_t>(ScanFlags::kCannotBeKeywordStart)) |
(!IsAsciiIdentifier(c)
? static_cast<uint8_t>(ScanFlags::kTerminatesLiteral)
: 0) |
((c == '\'' || c == '"' || c == '\n' || c == '\r' || c == '\\')
? static_cast<uint8_t>(ScanFlags::kStringTerminator)
: 0) |
(c == '\\' ? static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath)
: 0) |
(c == '\n' || c == '\r' || c == '*'
? static_cast<uint8_t>(
ScanFlags::kMultilineCommentCharacterNeedsSlowPath)
: 0);
}
#define INT_0_TO_127_LIST(V) \
V(0) V(1) V(2) V(3) V(4) V(5) V(6) V(7) V(8) V(9) \
V(10) V(11) V(12) V(13) V(14) V(15) V(16) V(17) V(18) V(19) \
V(20) V(21) V(22) V(23) V(24) V(25) V(26) V(27) V(28) V(29) \
V(30) V(31) V(32) V(33) V(34) V(35) V(36) V(37) V(38) V(39) \
V(40) V(41) V(42) V(43) V(44) V(45) V(46) V(47) V(48) V(49) \
V(50) V(51) V(52) V(53) V(54) V(55) V(56) V(57) V(58) V(59) \
V(60) V(61) V(62) V(63) V(64) V(65) V(66) V(67) V(68) V(69) \
V(70) V(71) V(72) V(73) V(74) V(75) V(76) V(77) V(78) V(79) \
V(80) V(81) V(82) V(83) V(84) V(85) V(86) V(87) V(88) V(89) \
V(90) V(91) V(92) V(93) V(94) V(95) V(96) V(97) V(98) V(99) \
V(100) V(101) V(102) V(103) V(104) V(105) V(106) V(107) V(108) V(109) \
V(110) V(111) V(112) V(113) V(114) V(115) V(116) V(117) V(118) V(119) \
V(120) V(121) V(122) V(123) V(124) V(125) V(126) V(127)
static constexpr const uint8_t character_scan_flags[128] = {
#define CALL_GET_SCAN_FLAGS(N) GetScanFlags(N),
INT_0_TO_127_LIST(CALL_GET_SCAN_FLAGS)
#undef CALL_GET_SCAN_FLAGS
};
constexpr uint8_t GetScanFlags(char c) {
return
(IsAsciiIdentifier(c) && !CanBeKeywordCharacter(c)
? static_cast<uint8_t>(ScanFlags::kCannotBeKeyword)
: 0) |
(IsKeywordStart(c)
? 0
: static_cast<uint8_t>(ScanFlags::kCannotBeKeywordStart)) |
(!IsAsciiIdentifier(c)
? static_cast<uint8_t>(ScanFlags::kTerminatesLiteral)
: 0) |
((c == '\'' || c == '"' || c == '\n' || c == '\r' || c == '\\')
? static_cast<uint8_t>(ScanFlags::kStringTerminator)
: 0) |
(c == '\\' ? static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath)
: 0) |
(c == '\n' || c == '\r' || c == '*'
? static_cast<uint8_t>(
ScanFlags::kMultilineCommentCharacterNeedsSlowPath)
: 0);
}
#define INT_0_TO_127_LIST(V) \
V(0) V(1) V(2) V(3) V(4) V(5) V(6) V(7) V(8) V(9) \
V(10) V(11) V(12) V(13) V(14) V(15) V(16) V(17) V(18) V(19) \
V(20) V(21) V(22) V(23) V(24) V(25) V(26) V(27) V(28) V(29) \
V(30) V(31) V(32) V(33) V(34) V(35) V(36) V(37) V(38) V(39) \
V(40) V(41) V(42) V(43) V(44) V(45) V(46) V(47) V(48) V(49) \
V(50) V(51) V(52) V(53) V(54) V(55) V(56) V(57) V(58) V(59) \
V(60) V(61) V(62) V(63) V(64) V(65) V(66) V(67) V(68) V(69) \
V(70) V(71) V(72) V(73) V(74) V(75) V(76) V(77) V(78) V(79) \
V(80) V(81) V(82) V(83) V(84) V(85) V(86) V(87) V(88) V(89) \
V(90) V(91) V(92) V(93) V(94) V(95) V(96) V(97) V(98) V(99) \
V(100) V(101) V(102) V(103) V(104) V(105) V(106) V(107) V(108) V(109) \
V(110) V(111) V(112) V(113) V(114) V(115) V(116) V(117) V(118) V(119) \
V(120) V(121) V(122) V(123) V(124) V(125) V(126) V(127)
character_scan_flags = []
for i in range(0, 127):
character_scan_flags.append(GetScanFlags(i))
character_scan_flags = []
for i in range(0, 127):
character_scan_flags.append(GetScanFlags(i))
template <int N>
constexpr bool IsInString(const char (&s)[N], char c, size_t i = 0) {
return i >= N ? false : s[i] == c ? true : IsInString(s, c, i + 1);
}
inline constexpr bool CanBeKeywordCharacter(char c) {
return IsInString(
#define KEYWORD_GROUP_CASE(ch) // Nothing
#define KEYWORD(keyword, token) keyword
KEYWORDS(KEYWORD_GROUP_CASE, KEYWORD)
#undef KEYWORD
#undef KEYWORD_GROUP_CASE
,
c);
}
#define KEYWORDS(KEYWORD_GROUP, KEYWORD) \
KEYWORD_GROUP('a') \
KEYWORD("async", Token::kAsync) \
KEYWORD("await", Token::kAwait) \
KEYWORD_GROUP('b') \
KEYWORD("break", Token::kBreak) \
KEYWORD_GROUP('c') \
KEYWORD("case", Token::kCase) \
KEYWORD("catch", Token::kCatch) \
KEYWORD("class", Token::kClass) \
KEYWORD("const", Token::kConst) \
KEYWORD("continue", Token::kContinue) \
KEYWORD_GROUP('d') \
KEYWORD("debugger", Token::kDebugger) \
KEYWORD("default", Token::kDefault) \
KEYWORD("delete", Token::kDelete) \
KEYWORD("do", Token::kDo) \
KEYWORD_GROUP('e') \
KEYWORD("else", Token::kElse) \
template <int N>
constexpr bool IsInString(const char (&s)[N], char c, size_t i = 0) {
return i >= N ? false : s[i] == c ? true : IsInString(s, c, i + 1);
}
inline constexpr bool CanBeKeywordCharacter(char c) {
return IsInString(
#define KEYWORD_GROUP_CASE(ch) // Nothing
#define KEYWORD(keyword, token) keyword
KEYWORDS(KEYWORD_GROUP_CASE, KEYWORD)
#undef KEYWORD
#undef KEYWORD_GROUP_CASE
,
c);
}
#define KEYWORDS(KEYWORD_GROUP, KEYWORD) \
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2025-6-5 19:38
被nothing233编辑
,原因:








