在现代软件保护技术中,控制流混淆(Control Flow Obfuscation)是一种常见且有效的手段,用于增加逆向工程的难度。OLLVM 是基于 LLVM 编译器框架的一个扩展,它通过插入复杂的控制流混淆逻辑,使得生成的二进制代码难以被分析和理解。间接调用和控制流平坦化是 OLLVM 中最具代表性的混淆技术之一,它通过将程序的控制流打散并引入调度器逻辑,极大地增加了逆向工程的复杂性。
本篇笔记将从以下几个方面展开:
通过这些内容,希望能够帮助读者更好地理解 OLLVM 的工作原理,并掌握应对复杂混淆技术的分析方法,毕竟有谁能拒绝参加一场顶级玩家之间的攻防游戏呢?
下载网络上大佬开源的 ollvm 项目,goron 是我实际测试比较好用的版本,提供了额外的几种强度不错的混淆 Pass,选择 9.0 版本则是考虑到这个版本网络上可供学习的资料比较多,非常适合学习使用。
没有 clion的可以用命令行编译 clang,生成 release 编译配置文件
编译 release
将 ndk 中的 clang 加入环境变量
使用编译器打开 ollvm/llvm-project-9.0.1/llvm/CMakeLists.txt
编译器 file — settings — Build,Execution,Deployment — Cmake — Cmake options,配置 Cmake, 添加 Release 选项并设置 CMake options 如下
编译器主界面将工程切换为 clang 并将模式切换为 Release 模式,最后点击运行开始编译
使用 VSCode 打开 ollvm/llvm-project-9.0.1
新建文件夹 .vscode
创建文件 .vscode/launch.json
创建文件 .vscode/tasks.json
运行和调试 --> 启动
将 clang 添加到临时环境变量中
测试编译
交叉编译 arm64 需要先安装 gcc-aarch64 和 g++-aarch64
交叉编译 arm64
Ollvm 编译 X86 版本的可执行文件
Ollvm 编Arm64 版本的可执行文件
下载 android-ndk-r21e
将之前编译的 ollvm 中的 lib 和 bin 文件夹拷贝到 ndk 文件夹中
在 android studio 工程中 local.properties 中自定义 ndk 路径
在 CMakeLists.txt 中添加编译时使用的 ollvm 命令
c
在 LLVM 编译过程中,首先需要将 .c 文件通过前端编译器(如 Clang)转换为 LLVM IR(中间表示)。
ll
LLVM Assembly 文件是一种类似于汇编语言的中间表示。它是一种人类可读的文本格式,用于表示 LLVM IR。这种格式在跨平台上具有一定的可移植性。
bc
LLVM Bitcode 文件是一种中间表示的二进制格式,具有跨平台和跨编译器的特性。.bc 文件包含了经过前端编译器生成的 LLVM IR,但已经被编译成了一种更加紧凑的二进制形式。
s
汇编语言文件 .s 文件是汇编语言程序的源代码文件,包含了目标机器的汇编指令。在 LLVM 编译过程的最后阶段,LLVM IR 会被转换为特定目标机器的汇编代码,存储在 .s 文件中。这种格式通常不跨平台,因为汇编指令是特定于目标体系结构的。
生成 ll 文件
ll 文件也是可以执行的(需要在clion中先将 lli 编译出来)
生成 bc 文件(需要在clion中先将 llvm-as 编译出来)
生成 s 文件 (需要在clion中先将 llc 编译出来)
s 文件生成可执行文件
bc 文件生成可执行文件
ll 文件生成可执行文件
这部分除了理解 IR 汇编的基本语法,还必须理解 IR 语言中代码块的概念,这样我们才能理解 OLLVM 中最难的控制流平坦化的技术原理
C 代码
IR 汇编
C 代码
IR 汇编
C 代码
IR 汇编
C 代码
IR 汇编
这里只给出笔者认为比较重要的代码片段,其中注释多为 AI 分析(让 AI 辅助我们理解复杂的工程是个很棒的主意),也包含少量的笔者在分析时插入的日志 LOG,笔者总结的经验就是在分析的时候多插入LOG,在关键代码前后多打印对应的 IR 汇编,对比前后的区别,将下面的任意一个 Pass 分析透彻后,熟悉了 LLVM 操作 IR 汇编的函数,接下来的源码分析会越来越得心应手。
核心功能:加密函数调用地址,将 bl lable 指令转变为 blr reg ,抵抗反编译器的静态分析
核心功能:加密块间的调用地址,将 b lable 指令转变为 br reg,抵抗反编译器的静态分析
核心功能:控制流平坦化,OLLVM 中最核心的保护手段,将函数中的所有代码块编号放到一个巨大的 while switch case 中进行分发执行,抵抗反编译器的静态分析
Unicorn 是一个模拟 CPU 执行的框架,Unicorn 在 OLLVM 反混淆中的作用为计算 BR 寄存器的值以及控制流平坦化中作为 SWITCH ID 的寄存器的值,这里附上一段笔者学习 Unicorn 的代码,希望可以帮助大家理解 Unicorn 的用法。
flare-emu 的核心功能是通过 Unicorn 的仿真能力,为 IDA 二进制分析提供强大的动态仿真支持。它支持多种架构(包括 x86、x86_64、ARM 和 ARM64),并提供了五种主要的仿真接口,以及一系列相关的辅助和实用函数。
项目地址:cb3K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6E0j5h3&6V1K9h3q4F1N6q4)9J5c8X3k6D9j5i4u0W2i4K6u0V1k6h3#2#2i4K6u0W2k6$3W2@1
C 代码
编译三种混淆的二进制文件
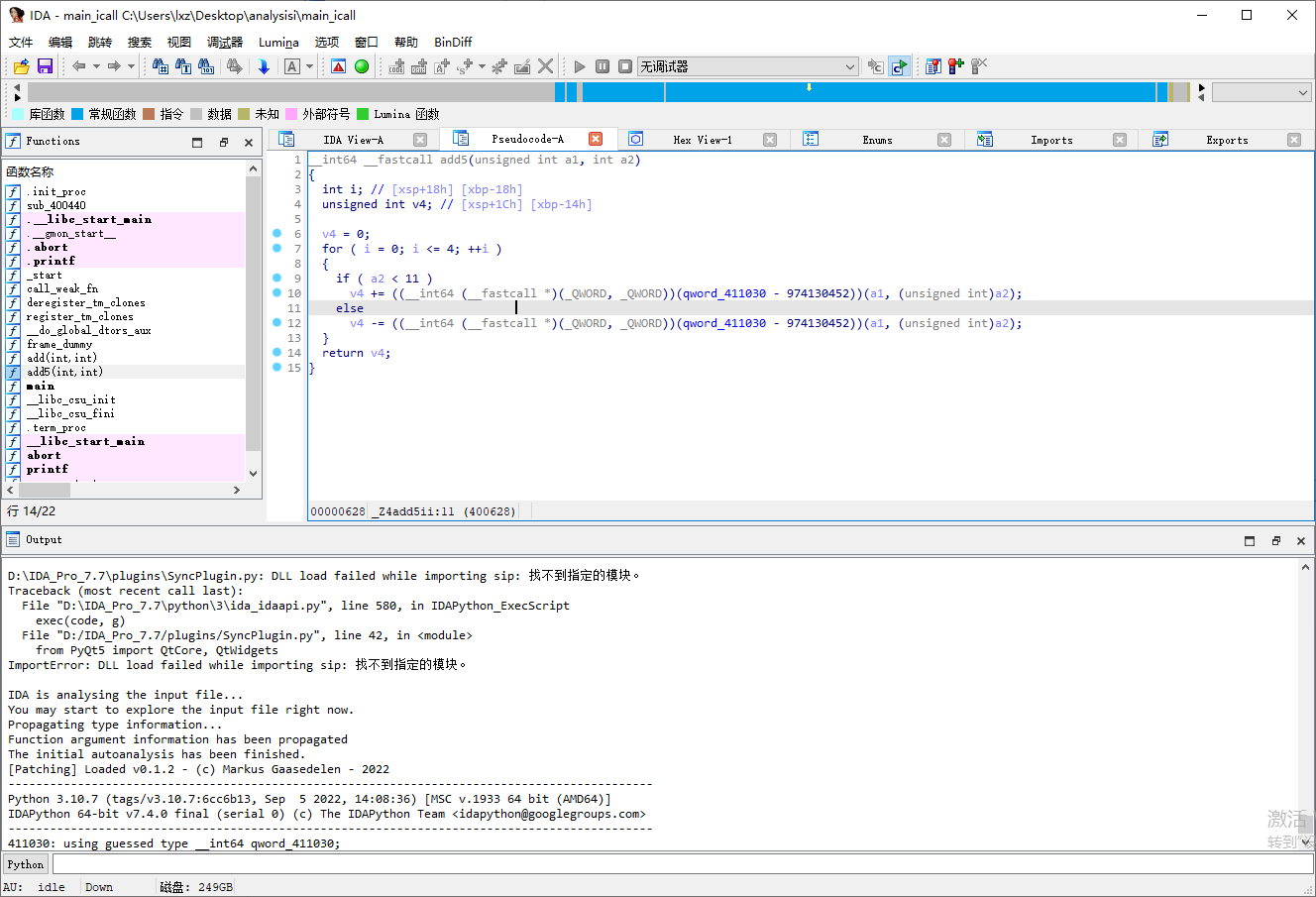
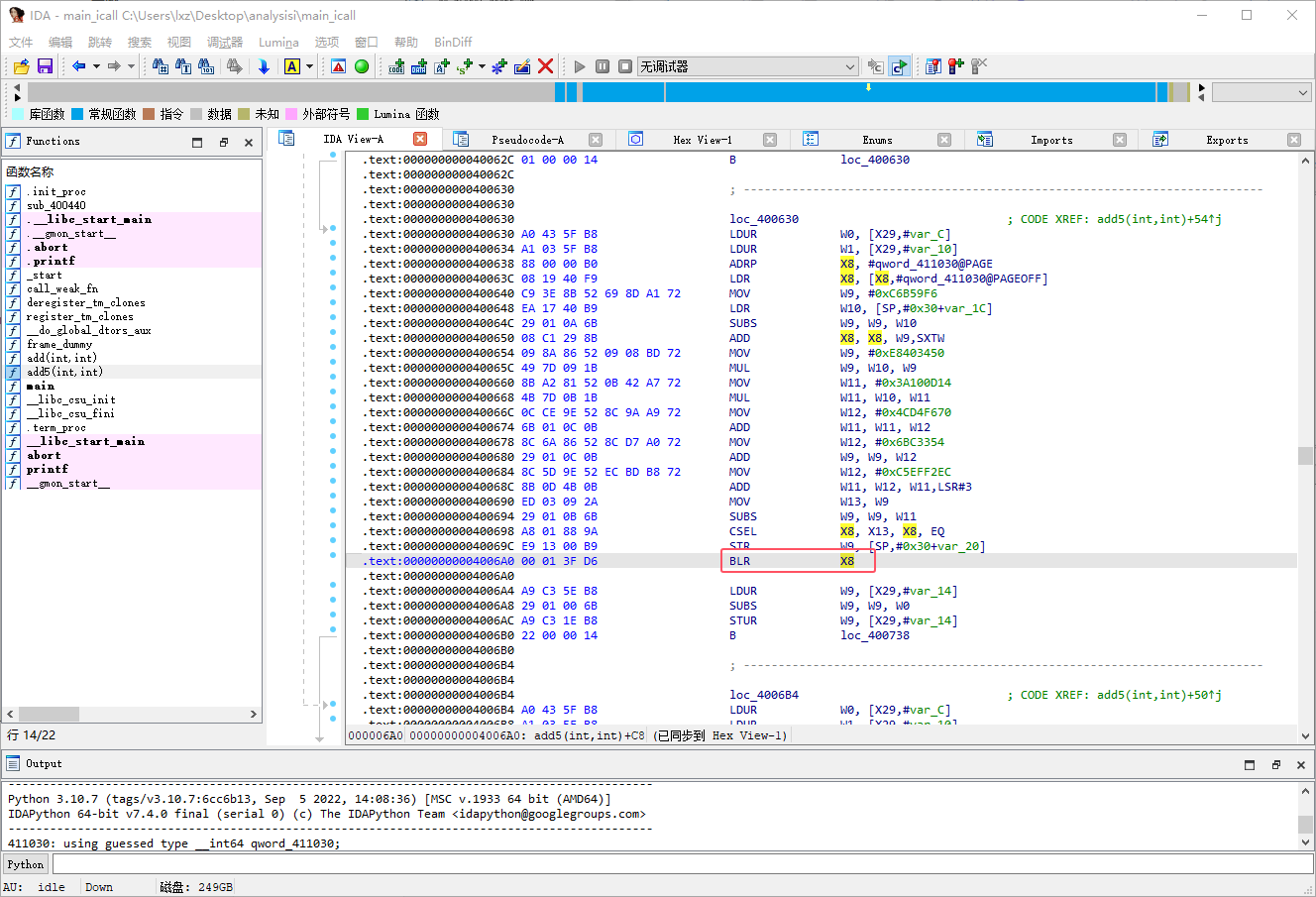
IDA 打开 main_icall 中的 main 函数可以发现函数 add5 的跳转已经被加密
这里我们可以发现原本的 BL 指令被替换成了 BLR 指令,这里我们只需要利用 flare_emu模拟执行一下函数,利用 iterate 方法强行执行到目标地址就可以获取目标寄存器的值了,在最后将 BLR 指令改回 BL 指令就可以了
根据观察,函数跳转的地址通过模拟执行还是比较好计算出来的,这里我的思路如下:
使用 flare_emu 的 iterate 方法,从指定的地址范围开始模拟执行
targetCallBack 回调中记录每个间接调用指令的目标地址
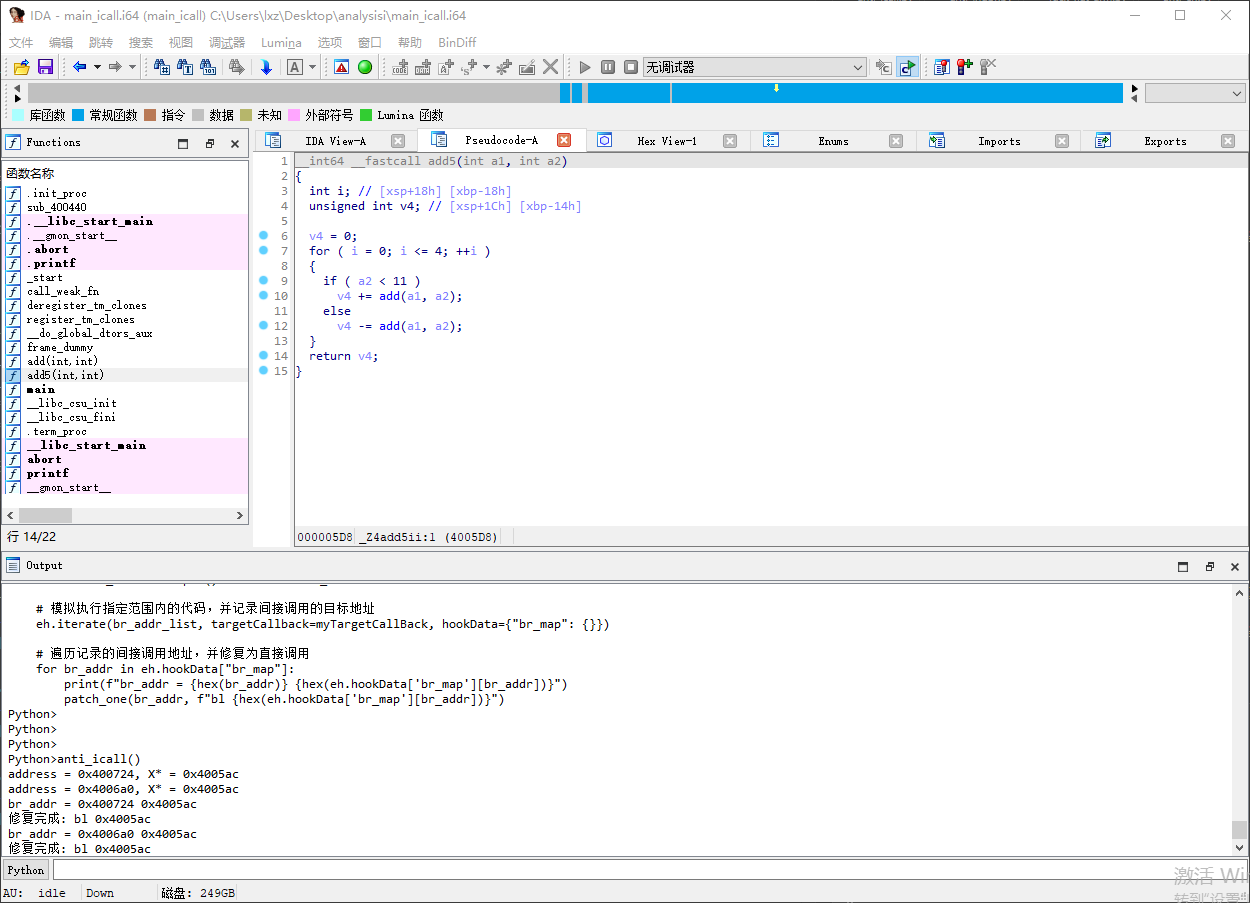
修复间接调用
IDA 已经可以解析出函数 add 的地址
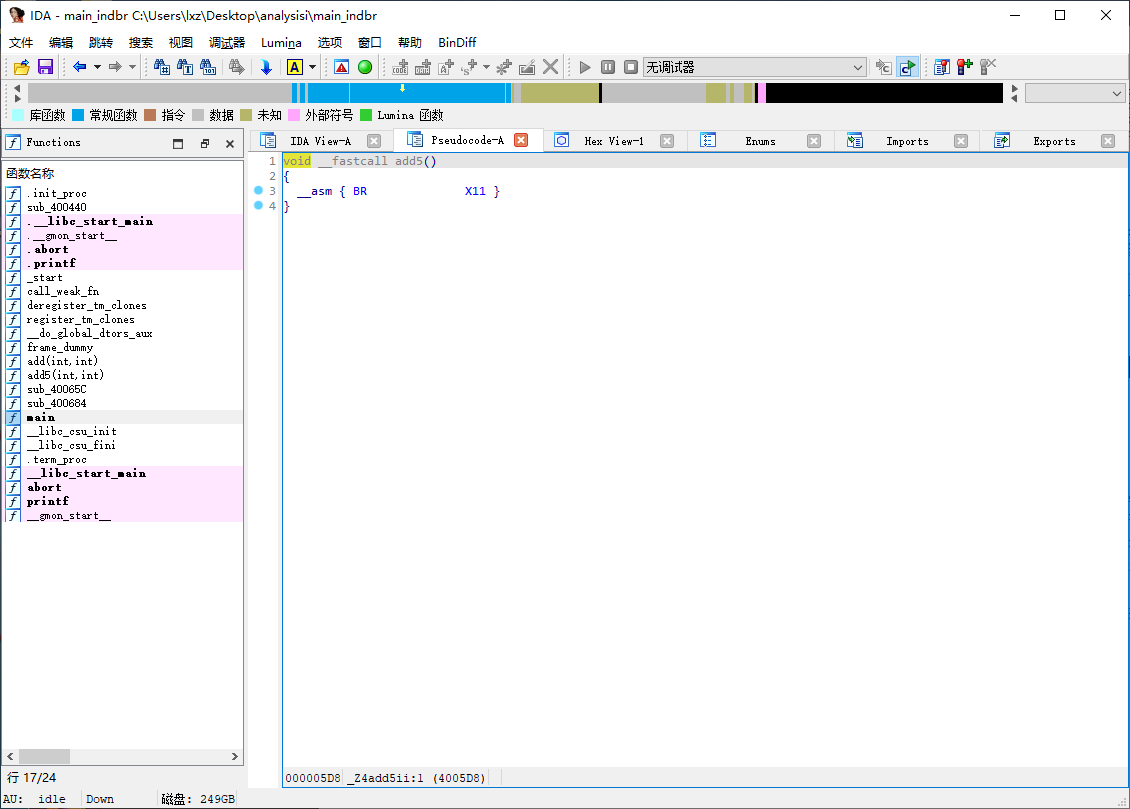
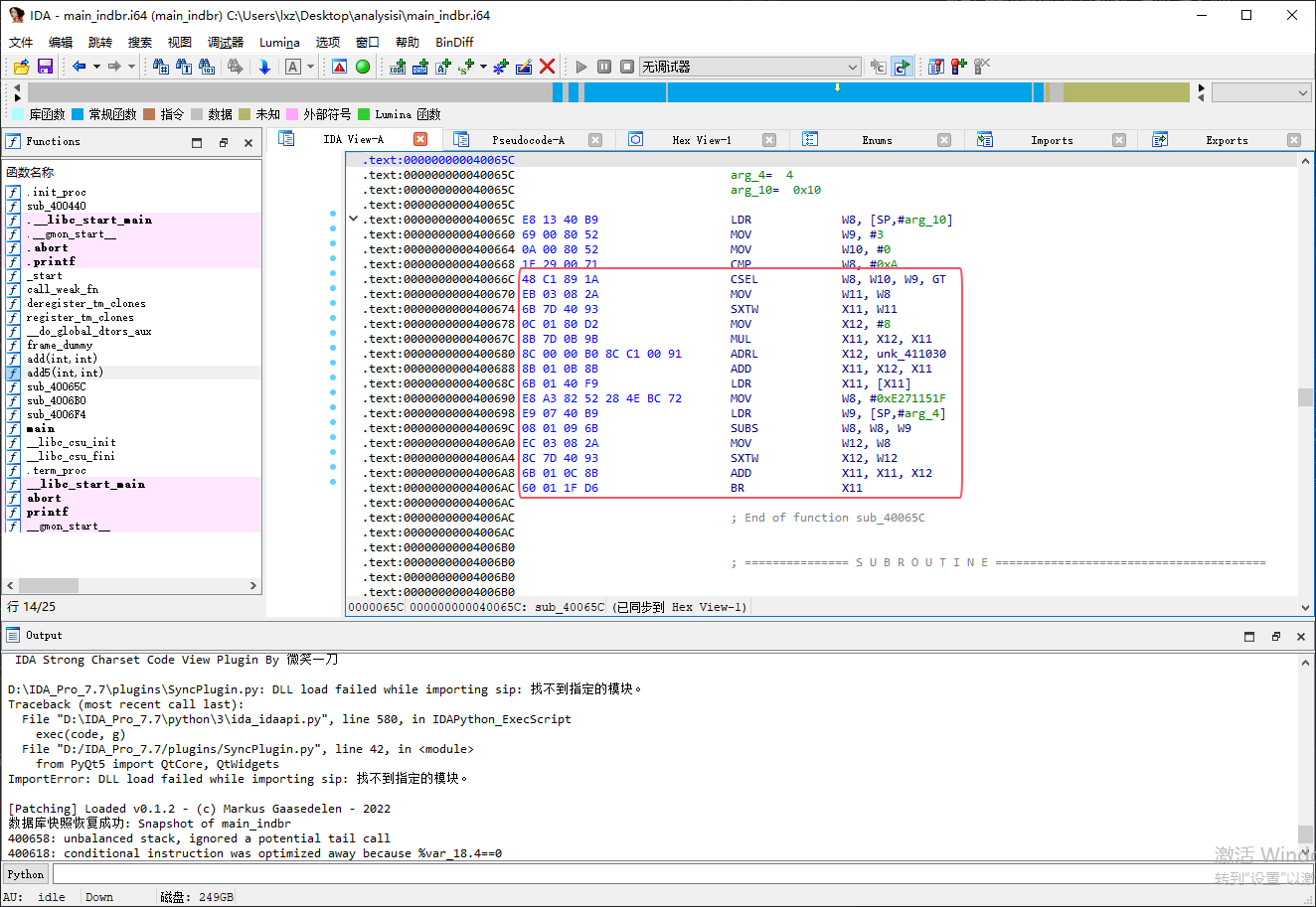
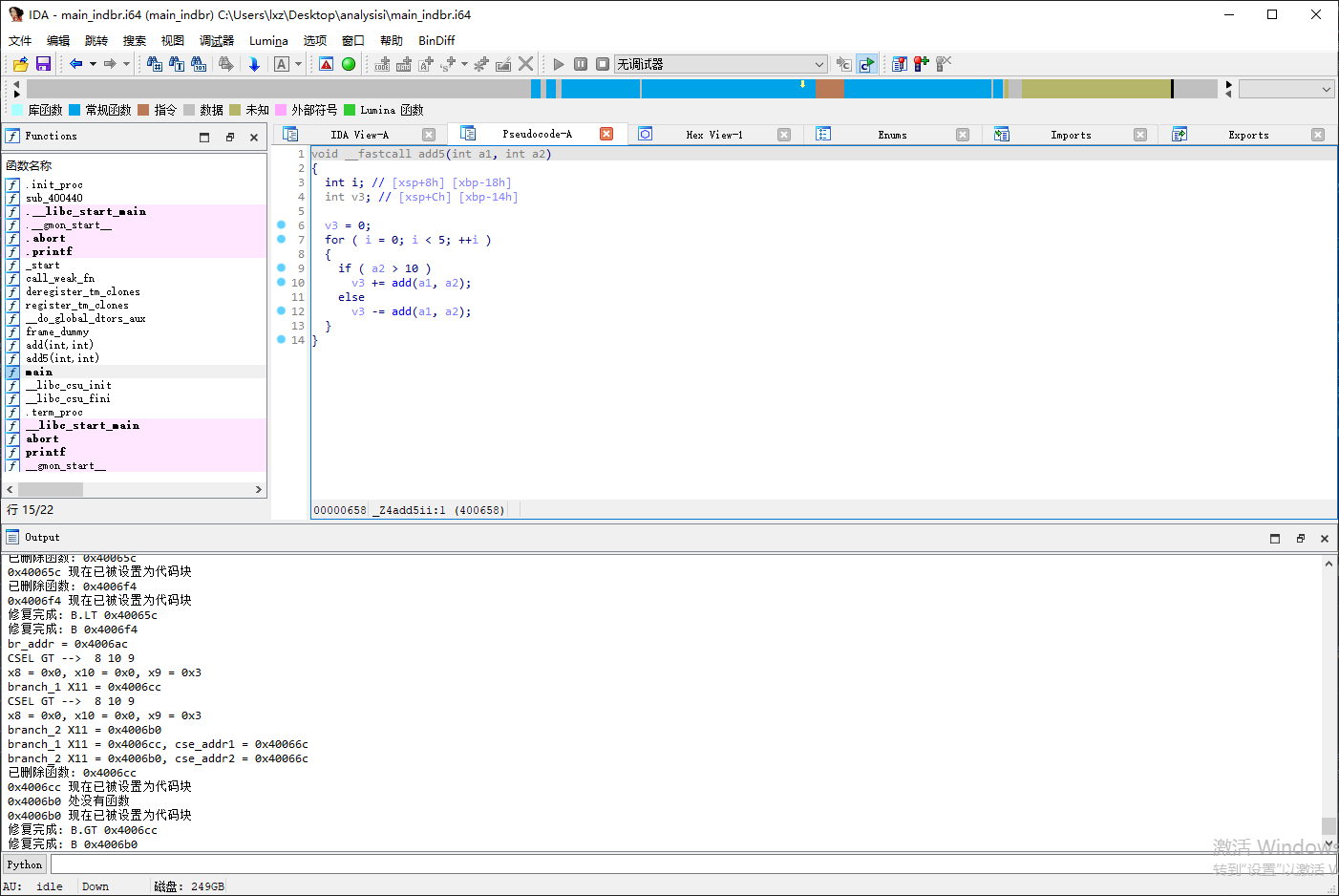
IDA 打开 main_indbr 中的 add5 函数可以发现函数主体无法被解析
这里我们可以发现原本的 BL 指令被替换成了 BLR 指令,不过这里就不能像 icall 那样粗暴的直接计算地址了,因为这里可能会涉及到多个分支的问题。
通过观察我发现一般只有两个分支,所以我这里的还原思路如下:
使用 flare_emu 的 emulateFrom 方法,从函数起始地址模拟执行到 BR 指令:
在模拟过程中,通过 my_instruction_hook 拦截指令,记录 CSEL 或 CSET 指令的地址,需要注意有两个分支。
根据 CSEL 或 CSET 指令的类型,修复为条件跳转指令
IDA 已经可以解析出函数 add5 的函数主体
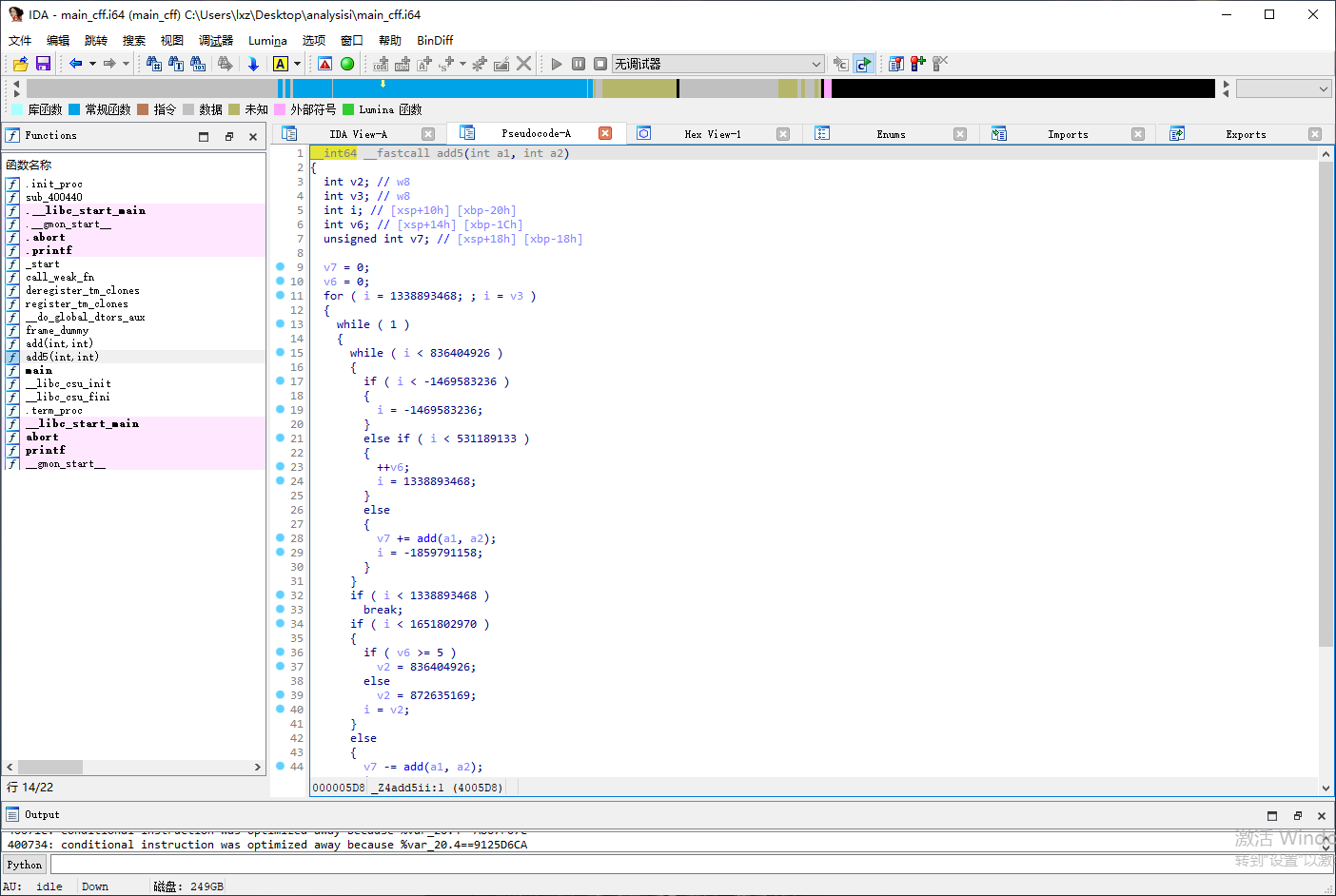
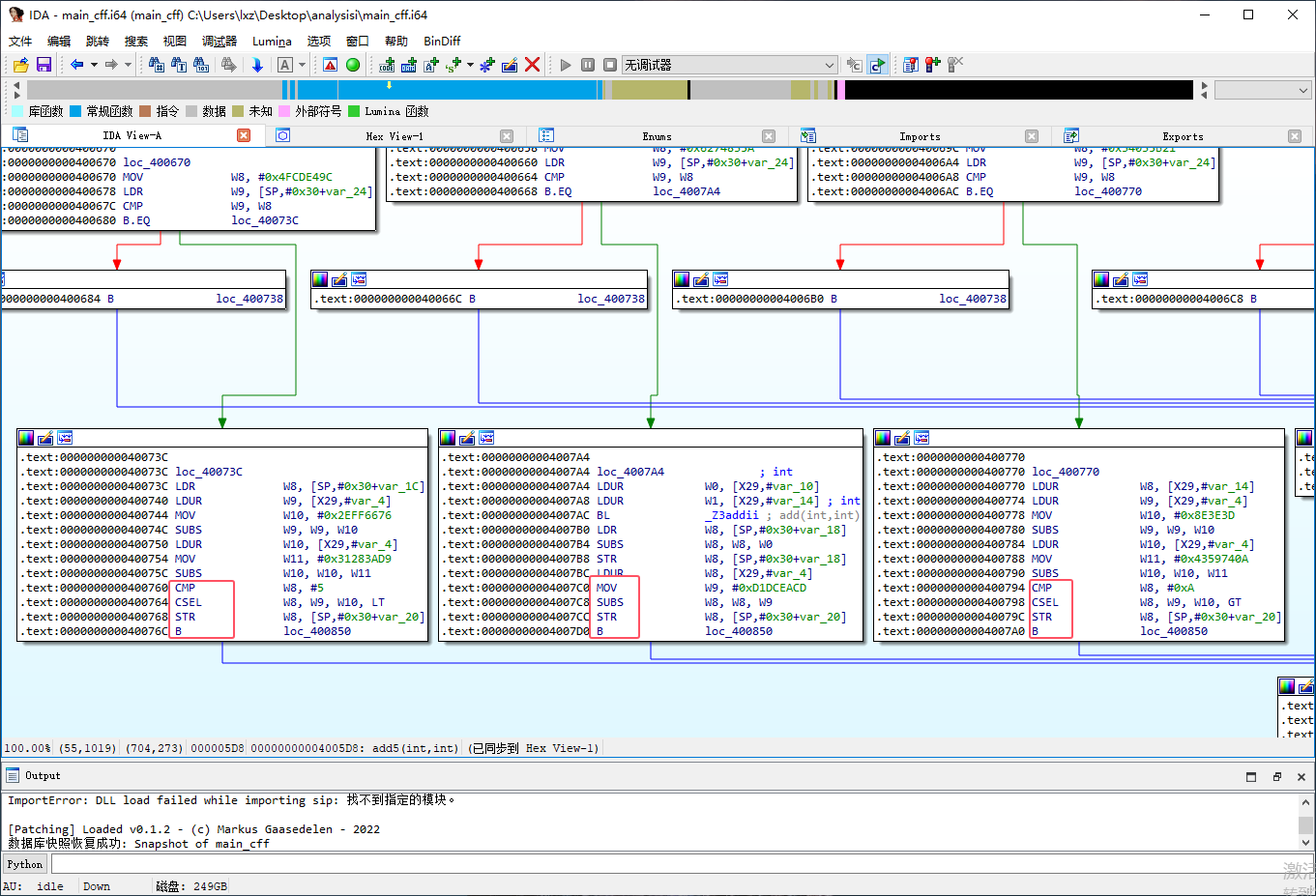
IDA 打开 main_indbr 中的 add5 函数可以发现函数逻辑难以理解
控制流平坦化作为 ollvm 中最重要的 Pass,也是最难以还原的,我这里的还原思路如下:
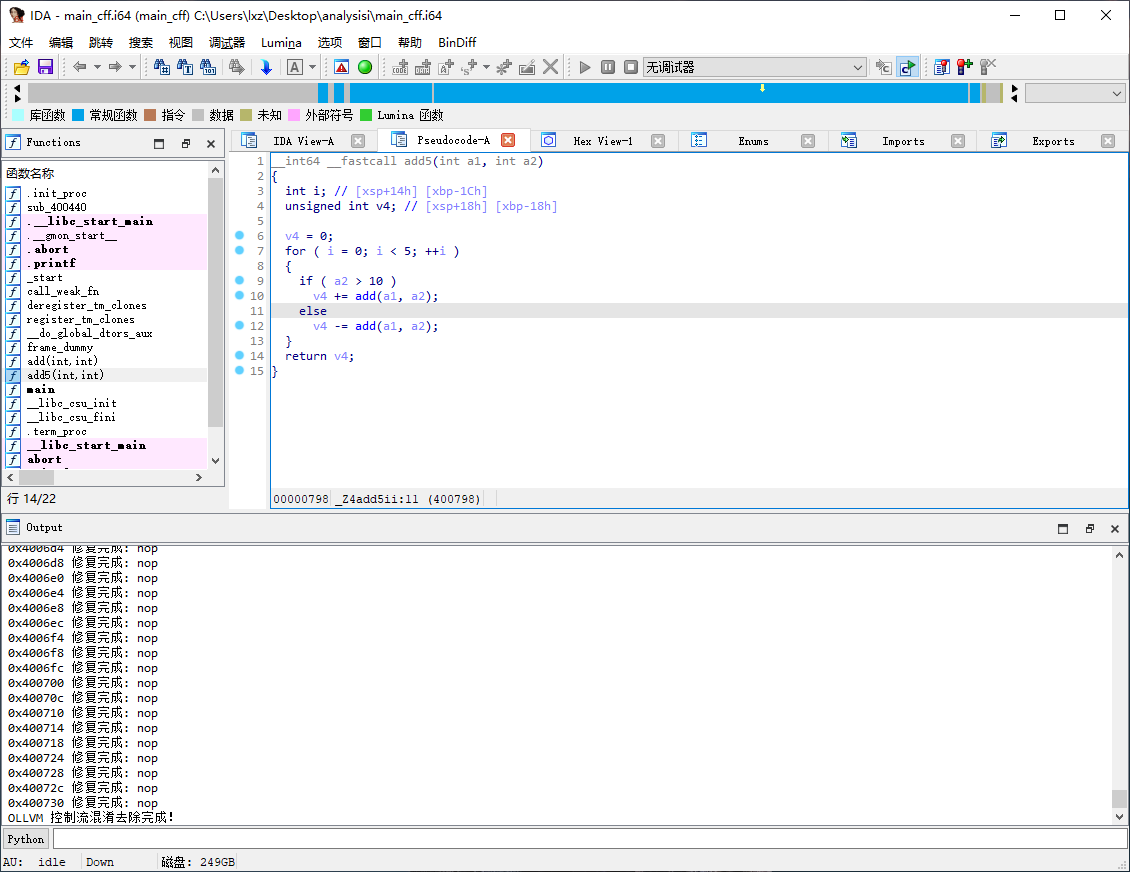
IDA 已经可以解析出函数 add5 的函数逻辑
通过本次学习和实践,笔者对 OLLVM 的编译、使用以及其混淆技术有了更深入的理解。具体来说:
这次学习让笔者认识到,面对复杂的混淆技术,工具的选择和分析思路的清晰性至关重要。同时也证明了混淆技术虽然强大,但并非不可破解。希望本篇笔记能够为其他研究 OLLVM 的同学提供一些参考和帮助。
细品sec2023安卓赛题
llvm学习笔记——llvm基础
初窺ARM平坦化還原
自实现一个LLVM Pass以及OLLVM简单的魔改
从源码视角分析Arkari间接跳转混淆
OLLVM控制流平坦化混淆还原
ARM64 目前主流的反混淆技术的初窥
ollvm_assets.zip
环境
配置
VMware
16.1.1 build-17801498
Ubuntu
Ubuntu 20.04.2 LTS
物理机内存
32G
虚拟机内存
16G
物理机储存
2T
虚拟机内存
1T
目标版本
llvm-project-9.0
sudo apt-get install git-core gnupg flex bison build-essential zip curl zlib1g-dev gcc-multilib g++-multilib libc6-dev-i386 libncurses5 lib32ncurses5-dev x11proto-core-dev libx11-dev lib32z1-dev libgl1-mesa-dev libxml2-utils xsltproc unzip fontconfig libncurses5 cmake ninja-build
sudo apt-get install git-core gnupg flex bison build-essential zip curl zlib1g-dev gcc-multilib g++-multilib libc6-dev-i386 libncurses5 lib32ncurses5-dev x11proto-core-dev libx11-dev lib32z1-dev libgl1-mesa-dev libxml2-utils xsltproc unzip fontconfig libncurses5 cmake ninja-build
git clone https://github.com/amimo/goron.git
git checkout e943a8a78325632df64988e05d66ad5fa0e0c6f6
git clone https://github.com/amimo/goron.git
git checkout e943a8a78325632df64988e05d66ad5fa0e0c6f6
cd llvm-project-9.0.1
mkdir build_release
cd build_release
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang" ../llvm
cd llvm-project-9.0.1
mkdir build_release
cd build_release
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang" ../llvm
ninja -j16
export PATH=/home/lxz/ollvm/llvm-project/build_release/bin:$PATH
export PATH=/home/lxz/ollvm/llvm-project/build_release/bin:$PATH
-G Ninja -DLLVM_ENABLE_PROJECTS="clang"
-G Ninja -DLLVM_ENABLE_PROJECTS="clang"
export PATH=/home/lxz/ollvm/llvm-project/cmake-build-release/bin::$PATH
export PATH=/home/lxz/ollvm/llvm-project/cmake-build-release/bin::$PATH
clang hello.c -o hello
sudo apt install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
sudo apt install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
clang hello.c -o hello -target aarch64-linux-gnu
clang hello.c -o hello -target aarch64-linux-gnu
clang hello.c -o hello -mllvm -sub -mllvm -bcf -mllvm -fla
clang hello.c -o hello -mllvm -sub -mllvm -bcf -mllvm -fla
clang hello.c -o hello -mllvm -sub -mllvm -bcf -mllvm -fla -target aarch64-linux-gnu
clang hello.c -o hello -mllvm -sub -mllvm -bcf -mllvm -fla -target aarch64-linux-gnu
wget https://dl.google.com/android/repository/android-ndk-r21e-linux-x86_64.zip
unzip android-ndk-r21e-linux-x86_64.zip
wget https://dl.google.com/android/repository/android-ndk-r21e-linux-x86_64.zip
unzip android-ndk-r21e-linux-x86_64.zip
cp /home/lxz/ollvm/llvm-project/build_debug/lib /home/lxz/ollvm/android-ndk-r21e/toolchains/llvm/prebuilt/linux-x86_64/lib
cp /home/lxz/ollvm/llvm-project/build_debug/bin /home/lxz/ollvm/android-ndk-r21e/toolchains/llvm/prebuilt/linux-x86_64/bin
cp /home/lxz/ollvm/llvm-project/build_debug/lib /home/lxz/ollvm/android-ndk-r21e/toolchains/llvm/prebuilt/linux-x86_64/lib
cp /home/lxz/ollvm/llvm-project/build_debug/bin /home/lxz/ollvm/android-ndk-r21e/toolchains/llvm/prebuilt/linux-x86_64/bin
ndk.dir =/home/lxz/ollvm/android-ndk-r21e
ndk.dir =/home/lxz/ollvm/android-ndk-r21e
add_definitions(-mllvm -fla)
add_definitions(-mllvm -sub -mllvm -bcf -mllvm -fla)
add_definitions(-mllvm -sub -mllvm -sub_loop=3 -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -fla -mllvm -split_num=3)
add_definitions(-mllvm -fla)
add_definitions(-mllvm -sub -mllvm -bcf -mllvm -fla)
add_definitions(-mllvm -sub -mllvm -sub_loop=3 -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -fla -mllvm -split_num=3)
export PATH=~/ollvm/llvm-project-9.0.1/llvm/cmake-build-release/bin::$PATH
clang -emit-llvm -S hello.c -o hello.ll
export PATH=~/ollvm/llvm-project-9.0.1/llvm/cmake-build-release/bin::$PATH
clang -emit-llvm -S hello.c -o hello.ll
lli hello.ll
llvm-as hello.ll -o hello.bc
llvm-as hello.ll -o hello.bc
llc hello.bc -o hello.s
clang hello.s -o hello_s
clang hello.bc -o hello_bc
clang hello.bc -o hello_bc
clang hello.ll -o hello_ll
clang hello.ll -o hello_ll
int fun1(int a, int b){
return a+b;
}
int fun1(int a, int b){
return a+b;
}
; dso_local:这是一个链接属性,表示该函数是局部的,仅在当前模块中可见。
; i32:表示函数的返回类型是 32 位整数。
;@_Z4fun1ii(i32, i32):这是函数的名称和参数列表,@ 是函数名的标识符。
;
; 参数优先分配 %0、%1、%2、%3 ...
define dso_local i32 @_Z4fun1ii(i32, i32)
; 在栈上分配一个 i32 类型的内存空间,对齐到 4 字节边界,标记为 %3
%3 = alloca i32, align 4
; 在栈上分配一个 i32 类型的内存空间,对齐到 4 字节边界,标记为 %4
%4 = alloca i32, align 4
; 将 %0 的值存储到 %3 指向的内存中,4 字节对齐
store i32 %0, i32* %3, align 4
; 将 %1 的值存储到 %4 指向的内存中, 4 字节对齐
store i32 %1, i32* %4, align 4
; 从 %3 指向的内存中加载一个 i32 类型的值,存储到临时变量 %5 中,4 字节对齐
%5 = load i32, i32* %3, align 4
; 从 %4 指向的内存中加载一个 i32 类型的值,存储到临时变量 %6 中,4 字节对齐
%6 = load i32, i32* %4, align 4
; 将 %5 和 %6 中的值相加,结果存储到临时变量 %7 中,加法操作不会检查有符号溢出
%7 = add nsw i32 %5, %6
; 返回函数的结果,即 %7 中存储的加法结果
ret i32 %7
}
; dso_local:这是一个链接属性,表示该函数是局部的,仅在当前模块中可见。
; i32:表示函数的返回类型是 32 位整数。
;@_Z4fun1ii(i32, i32):这是函数的名称和参数列表,@ 是函数名的标识符。
;
; 参数优先分配 %0、%1、%2、%3 ...
define dso_local i32 @_Z4fun1ii(i32, i32)
; 在栈上分配一个 i32 类型的内存空间,对齐到 4 字节边界,标记为 %3
%3 = alloca i32, align 4
; 在栈上分配一个 i32 类型的内存空间,对齐到 4 字节边界,标记为 %4
%4 = alloca i32, align 4
; 将 %0 的值存储到 %3 指向的内存中,4 字节对齐
store i32 %0, i32* %3, align 4
; 将 %1 的值存储到 %4 指向的内存中, 4 字节对齐
store i32 %1, i32* %4, align 4
; 从 %3 指向的内存中加载一个 i32 类型的值,存储到临时变量 %5 中,4 字节对齐
%5 = load i32, i32* %3, align 4
; 从 %4 指向的内存中加载一个 i32 类型的值,存储到临时变量 %6 中,4 字节对齐
%6 = load i32, i32* %4, align 4
; 将 %5 和 %6 中的值相加,结果存储到临时变量 %7 中,加法操作不会检查有符号溢出
%7 = add nsw i32 %5, %6
; 返回函数的结果,即 %7 中存储的加法结果
ret i32 %7
}
int fun2(int a, int b){
int ret = 0;
for(int i = 0; i < 5; i++){
ret += a;
}
return ret+b;
}
int fun2(int a, int b){
int ret = 0;
for(int i = 0; i < 5; i++){
ret += a;
}
return ret+b;
}
define dso_local i32 @_Z4fun2ii(i32, i32)
%3 = alloca i32, align 4 (参数1)
%4 = alloca i32, align 4 (参数2)
%5 = alloca i32, align 4 (中间计算结果)
%6 = alloca i32, align 4 (循环计数器)
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
store i32 0, i32* %5, align 4
store i32 0, i32* %6, align 4
; 无条件跳转到标签 %7,开始循环
br label %7
;这部分对应 i < 5
7: ; preds = %14, %2
%8 = load i32, i32* %6, align 4
; 比较 %8 是否小于 5,结果存放到 %9,%9 为布尔值
; %9 = (bool)(%8 < 5)
%9 = icmp slt i32 %8, 5
; 根据比较结果布尔类型的 %9 跳转到标签 %10 或 %17
; if(%9){
; br label %10
; }else{
; br label %17
; }
br i1 %9, label %10, label %17
; 这部分对应 ret += a
10: ; preds = %7
; 从 %3 指向的内存中加载第一个参数的值
%11 = load i32, i32* %3, align 4
; 从 %5 指向的内存中加载中间计算结果的值
%12 = load i32, i32* %5, align 4
; 将中间计算结果 %12 和第一个参数 %11 相加,结果存储到 %13
%13 = add nsw i32 %12, %11
; 将新的中间计算结果 %13 存储到 %5 指向的内存中
store i32 %13, i32* %5, align 4
; 跳转到标签 %14,继续循环
br label %14
; 这部分对应 i++
14: ; preds = %10
; 从 %6 指向的内存中加载循环计数器的值
%15 = load i32, i32* %6, align 4
; 将循环计数器 %15 加 1,结果存储到 %16
%16 = add nsw i32 %15, 1
; 将新的循环计数器值 %16 存储到 %6 指向的内存中
store i32 %16, i32* %6, align 4
; 跳转回标签 %7,继续循环
br label %7
;这部分对应 return ret+b;
17: ; preds = %7
; 从 %5 指向的内存中加载最终的中间计算结果
%18 = load i32, i32* %5, align 4
; 从 %4 指向的内存中加载第二个参数的值
%19 = load i32, i32* %4, align 4
; 将中间计算结果 %18 和第二个参数 %19 相加,结果存储到 %20
%20 = add nsw i32 %18, %19
; 返回函数的结果,即 %20 中存储的值
ret i32 %20
}
define dso_local i32 @_Z4fun2ii(i32, i32)
%3 = alloca i32, align 4 (参数1)
%4 = alloca i32, align 4 (参数2)
%5 = alloca i32, align 4 (中间计算结果)
%6 = alloca i32, align 4 (循环计数器)
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
store i32 0, i32* %5, align 4
store i32 0, i32* %6, align 4
; 无条件跳转到标签 %7,开始循环
br label %7
;这部分对应 i < 5
7: ; preds = %14, %2
%8 = load i32, i32* %6, align 4
; 比较 %8 是否小于 5,结果存放到 %9,%9 为布尔值
; %9 = (bool)(%8 < 5)
%9 = icmp slt i32 %8, 5
; 根据比较结果布尔类型的 %9 跳转到标签 %10 或 %17
; if(%9){
; br label %10
; }else{
; br label %17
; }
br i1 %9, label %10, label %17
; 这部分对应 ret += a
10: ; preds = %7
; 从 %3 指向的内存中加载第一个参数的值
%11 = load i32, i32* %3, align 4
; 从 %5 指向的内存中加载中间计算结果的值
%12 = load i32, i32* %5, align 4
; 将中间计算结果 %12 和第一个参数 %11 相加,结果存储到 %13
%13 = add nsw i32 %12, %11
; 将新的中间计算结果 %13 存储到 %5 指向的内存中
store i32 %13, i32* %5, align 4
; 跳转到标签 %14,继续循环
br label %14
; 这部分对应 i++
14: ; preds = %10
; 从 %6 指向的内存中加载循环计数器的值
%15 = load i32, i32* %6, align 4
; 将循环计数器 %15 加 1,结果存储到 %16
%16 = add nsw i32 %15, 1
; 将新的循环计数器值 %16 存储到 %6 指向的内存中
store i32 %16, i32* %6, align 4
; 跳转回标签 %7,继续循环
br label %7
;这部分对应 return ret+b;
17: ; preds = %7
; 从 %5 指向的内存中加载最终的中间计算结果
%18 = load i32, i32* %5, align 4
; 从 %4 指向的内存中加载第二个参数的值
%19 = load i32, i32* %4, align 4
; 将中间计算结果 %18 和第二个参数 %19 相加,结果存储到 %20
%20 = add nsw i32 %18, %19
; 返回函数的结果,即 %20 中存储的值
ret i32 %20
}
int fun3(int a, int b){
return fun2(a, b);
}
int fun3(int a, int b){
return fun2(a, b);
}
define dso_local i32 @_Z4fun3ii(i32, i32)
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
; 调用函数 _Z4fun2ii,将 %5 和 %6 作为参数传递,返回值存储到临时变量 %7 中
%7 = call i32 @_Z4fun2ii(i32 %5, i32 %6)
ret i32 %7
}
define dso_local i32 @_Z4fun3ii(i32, i32)
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
; 调用函数 _Z4fun2ii,将 %5 和 %6 作为参数传递,返回值存储到临时变量 %7 中
%7 = call i32 @_Z4fun2ii(i32 %5, i32 %6)
ret i32 %7
}
int fun4(int a, int b){
if(a > 5){
return fun2(a, b);
}else{
return fun3(a, b);
}
}
int fun4(int a, int b){
if(a > 5){
return fun2(a, b);
}else{
return fun3(a, b);
}
}
define dso_local i32 @_Z4fun4ii(i32, i32)
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %4, align 4
store i32 %1, i32* %5, align 4
%6 = load i32, i32* %4, align 4
%7 = icmp sgt i32 %6, 5
br i1 %7, label %8, label %12
8: ; preds = %2
%9 = load i32, i32* %4, align 4
%10 = load i32, i32* %5, align 4
%11 = call i32 @_Z4fun2ii(i32 %9, i32 %10)
store i32 %11, i32* %3, align 4
br label %16
12: ; preds = %2
%13 = load i32, i32* %4, align 4
%14 = load i32, i32* %5, align 4
%15 = call i32 @_Z4fun3ii(i32 %13, i32 %14)
store i32 %15, i32* %3, align 4
br label %16
16: ; preds = %12, %8
%17 = load i32, i32* %3, align 4
ret i32 %17
}
define dso_local i32 @_Z4fun4ii(i32, i32)
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %4, align 4
store i32 %1, i32* %5, align 4
%6 = load i32, i32* %4, align 4
%7 = icmp sgt i32 %6, 5
br i1 %7, label %8, label %12
8: ; preds = %2
%9 = load i32, i32* %4, align 4
%10 = load i32, i32* %5, align 4
%11 = call i32 @_Z4fun2ii(i32 %9, i32 %10)
store i32 %11, i32* %3, align 4
br label %16
12: ; preds = %2
%13 = load i32, i32* %4, align 4
%14 = load i32, i32* %5, align 4
%15 = call i32 @_Z4fun3ii(i32 %13, i32 %14)
store i32 %15, i32* %3, align 4
br label %16
16: ; preds = %12, %8
%17 = load i32, i32* %3, align 4
ret i32 %17
}
bool runOnFunction(Function &Fn) override {
if (!toObfuscate(flag, &Fn, "icall")) {
return false;
}
if (Options && Options->skipFunction(Fn.getName())) {
return false;
}
LLVMContext &Ctx = Fn.getContext();
CalleeNumbering.clear();
Callees.clear();
CallSites.clear();
NumberCallees(Fn);
if (Callees.empty()) {
return false;
}
uint32_t V = RandomEngine.get_uint32_t() & ~3;
ConstantInt *EncKey = ConstantInt::get(Type::getInt32Ty(Ctx), V, false);
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(&Fn);
}
Value *MySecret;
if (SecretInfo) {
MySecret = SecretInfo->SecretLI;
} else {
MySecret = ConstantInt::get(Type::getInt32Ty(Ctx), 0, true);
}
ConstantInt *Zero = ConstantInt::get(Type::getInt32Ty(Ctx), 0);
GlobalVariable *Targets = getIndirectCallees(Fn, EncKey);
for (auto CI : CallSites) {
SmallVector<Value *, 8> Args;
SmallVector<AttributeSet, 8> ArgAttrVec;
CallSite CS(CI);
Instruction *Call = CS.getInstruction();
Function *Callee = CS.getCalledFunction();
FunctionType *FTy = CS.getFunctionType();
IRBuilder<> IRB(Call);
Args.clear();
ArgAttrVec.clear();
Value *Idx = ConstantInt::get(Type::getInt32Ty(Ctx), CalleeNumbering[CS.getCalledFunction()]);
Value *GEP = IRB.CreateGEP(Targets, {Zero, Idx});
LoadInst *EncDestAddr = IRB.CreateLoad(GEP, CI->getName());
Constant *X;
if (SecretInfo) {
X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey);
} else {
X = ConstantExpr::getSub(Zero, EncKey);
}
const AttributeList &CallPAL = CS.getAttributes();
CallSite::arg_iterator I = CS.arg_begin();
unsigned i = 0;
for (unsigned e = FTy->getNumParams(); i != e; ++I, ++i) {
Args.push_back(*I);
AttributeSet Attrs = CallPAL.getParamAttributes(i);
ArgAttrVec.push_back(Attrs);
}
for (CallSite::arg_iterator E = CS.arg_end(); I != E; ++I, ++i) {
Args.push_back(*I);
ArgAttrVec.push_back(CallPAL.getParamAttributes(i));
}
AttributeList NewCallPAL = AttributeList::get(
IRB.getContext(), CallPAL.getFnAttributes(), CallPAL.getRetAttributes(), ArgAttrVec);
Value *Secret = IRB.CreateSub(X, MySecret);
Value *DestAddr = IRB.CreateGEP(EncDestAddr, Secret);
Value *Value1 = IRB.CreateAdd(MySecret, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value2 = IRB.CreateSub(MySecret, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value3 = IRB.CreateMul(Value1, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value4 = IRB.CreateMul(Value2, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value5 = IRB.CreateShl(Value3, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), 2));
Value *Value6 = IRB.CreateLShr(Value4, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), 3));
Value *FinalValue1 = IRB.CreateAdd(Value5, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *FinalValue2 = IRB.CreateSub(Value6, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *CmpResult = IRB.CreateICmpEQ(FinalValue1, FinalValue2);
Value *FinalValue1AsPtr = IRB.CreateIntToPtr(FinalValue1, Type::getInt8PtrTy(Fn.getContext()));
Value *Result = IRB.CreateSelect(CmpResult, FinalValue1AsPtr, DestAddr);
DestAddr = Result;
Value *FnPtr = IRB.CreateBitCast(DestAddr, FTy->getPointerTo());
FnPtr->setName("Call_" + Callee->getName());
CallInst *NewCall = IRB.CreateCall(FTy, FnPtr, Args, Call->getName());
NewCall->setAttributes(NewCallPAL);
Call->replaceAllUsesWith(NewCall);
Call->eraseFromParent();
}
return true;
}
bool runOnFunction(Function &Fn) override {
if (!toObfuscate(flag, &Fn, "icall")) {
return false;
}
if (Options && Options->skipFunction(Fn.getName())) {
return false;
}
LLVMContext &Ctx = Fn.getContext();
CalleeNumbering.clear();
Callees.clear();
CallSites.clear();
NumberCallees(Fn);
if (Callees.empty()) {
return false;
}
uint32_t V = RandomEngine.get_uint32_t() & ~3;
ConstantInt *EncKey = ConstantInt::get(Type::getInt32Ty(Ctx), V, false);
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(&Fn);
}
Value *MySecret;
if (SecretInfo) {
MySecret = SecretInfo->SecretLI;
} else {
MySecret = ConstantInt::get(Type::getInt32Ty(Ctx), 0, true);
}
ConstantInt *Zero = ConstantInt::get(Type::getInt32Ty(Ctx), 0);
GlobalVariable *Targets = getIndirectCallees(Fn, EncKey);
for (auto CI : CallSites) {
SmallVector<Value *, 8> Args;
SmallVector<AttributeSet, 8> ArgAttrVec;
CallSite CS(CI);
Instruction *Call = CS.getInstruction();
Function *Callee = CS.getCalledFunction();
FunctionType *FTy = CS.getFunctionType();
IRBuilder<> IRB(Call);
Args.clear();
ArgAttrVec.clear();
Value *Idx = ConstantInt::get(Type::getInt32Ty(Ctx), CalleeNumbering[CS.getCalledFunction()]);
Value *GEP = IRB.CreateGEP(Targets, {Zero, Idx});
LoadInst *EncDestAddr = IRB.CreateLoad(GEP, CI->getName());
Constant *X;
if (SecretInfo) {
X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey);
} else {
X = ConstantExpr::getSub(Zero, EncKey);
}
const AttributeList &CallPAL = CS.getAttributes();
CallSite::arg_iterator I = CS.arg_begin();
unsigned i = 0;
for (unsigned e = FTy->getNumParams(); i != e; ++I, ++i) {
Args.push_back(*I);
AttributeSet Attrs = CallPAL.getParamAttributes(i);
ArgAttrVec.push_back(Attrs);
}
for (CallSite::arg_iterator E = CS.arg_end(); I != E; ++I, ++i) {
Args.push_back(*I);
ArgAttrVec.push_back(CallPAL.getParamAttributes(i));
}
AttributeList NewCallPAL = AttributeList::get(
IRB.getContext(), CallPAL.getFnAttributes(), CallPAL.getRetAttributes(), ArgAttrVec);
Value *Secret = IRB.CreateSub(X, MySecret);
Value *DestAddr = IRB.CreateGEP(EncDestAddr, Secret);
Value *Value1 = IRB.CreateAdd(MySecret, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value2 = IRB.CreateSub(MySecret, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value3 = IRB.CreateMul(Value1, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value4 = IRB.CreateMul(Value2, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *Value5 = IRB.CreateShl(Value3, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), 2));
Value *Value6 = IRB.CreateLShr(Value4, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), 3));
Value *FinalValue1 = IRB.CreateAdd(Value5, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *FinalValue2 = IRB.CreateSub(Value6, ConstantInt::get(Type::getInt32Ty(Fn.getContext()), V));
Value *CmpResult = IRB.CreateICmpEQ(FinalValue1, FinalValue2);
Value *FinalValue1AsPtr = IRB.CreateIntToPtr(FinalValue1, Type::getInt8PtrTy(Fn.getContext()));
Value *Result = IRB.CreateSelect(CmpResult, FinalValue1AsPtr, DestAddr);
DestAddr = Result;
Value *FnPtr = IRB.CreateBitCast(DestAddr, FTy->getPointerTo());
FnPtr->setName("Call_" + Callee->getName());
CallInst *NewCall = IRB.CreateCall(FTy, FnPtr, Args, Call->getName());
NewCall->setAttributes(NewCallPAL);
Call->replaceAllUsesWith(NewCall);
Call->eraseFromParent();
}
return true;
}
bool runOnFunction(Function &Fn) override {
if (!toObfuscate(flag, &Fn, "indbr")) {
return false;
}
if (Options && Options->skipFunction(Fn.getName())) {
return false;
}
if (Fn.getBasicBlockList().empty() || Fn.hasLinkOnceLinkage() || Fn.getSection() == ".text.startup") {
return false;
}
LLVMContext &Ctx = Fn.getContext();
BBNumbering.clear();
BBTargets.clear();
SplitAllCriticalEdges(Fn, CriticalEdgeSplittingOptions(nullptr, nullptr));
NumberBasicBlock(Fn);
if (BBNumbering.empty()) {
return false;
}
uint32_t V = RandomEngine.get_uint32_t() & ~3;
ConstantInt *EncKey = ConstantInt::get(Type::getInt32Ty(Ctx), V, false);
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(&Fn);
}
Value *MySecret;
if (SecretInfo) {
MySecret = SecretInfo->SecretLI;
} else {
MySecret = ConstantInt::get(Type::getInt32Ty(Ctx), 0, true);
}
ConstantInt *Zero = ConstantInt::get(Type::getInt32Ty(Ctx), 0);
GlobalVariable *DestBBs = getIndirectTargets(Fn, EncKey);
for (auto &BB : Fn) {
auto *BI = dyn_cast<BranchInst>(BB.getTerminator());
if (BI && BI->isConditional()) {
IRBuilder<> IRB(BI);
Value *Cond = BI->getCondition();
Value *Idx;
Value *TIdx, *FIdx;
TIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(0)]);
FIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(1)]);
Idx = IRB.CreateSelect(Cond, TIdx, FIdx);
Value *GEP = IRB.CreateGEP(DestBBs, {Zero, Idx});
LoadInst *EncDestAddr = IRB.CreateLoad(GEP, "EncDestAddr");
Constant *X;
if (SecretInfo) {
X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey);
} else {
X = ConstantExpr::getSub(Zero, EncKey);
}
Value *DecKey = IRB.CreateSub(X, MySecret);
Value *DestAddr = IRB.CreateGEP(EncDestAddr, DecKey);
IndirectBrInst *IBI = IndirectBrInst::Create(DestAddr, 2);
IBI->addDestination(BI->getSuccessor(0));
IBI->addDestination(BI->getSuccessor(1));
ReplaceInstWithInst(BI, IBI);
}
}
return true;
}
bool runOnFunction(Function &Fn) override {
if (!toObfuscate(flag, &Fn, "indbr")) {
return false;
}
if (Options && Options->skipFunction(Fn.getName())) {
return false;
}
if (Fn.getBasicBlockList().empty() || Fn.hasLinkOnceLinkage() || Fn.getSection() == ".text.startup") {
return false;
}
LLVMContext &Ctx = Fn.getContext();
BBNumbering.clear();
BBTargets.clear();
SplitAllCriticalEdges(Fn, CriticalEdgeSplittingOptions(nullptr, nullptr));
NumberBasicBlock(Fn);
if (BBNumbering.empty()) {
return false;
}
uint32_t V = RandomEngine.get_uint32_t() & ~3;
ConstantInt *EncKey = ConstantInt::get(Type::getInt32Ty(Ctx), V, false);
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(&Fn);
}
Value *MySecret;
if (SecretInfo) {
MySecret = SecretInfo->SecretLI;
} else {
MySecret = ConstantInt::get(Type::getInt32Ty(Ctx), 0, true);
}
ConstantInt *Zero = ConstantInt::get(Type::getInt32Ty(Ctx), 0);
GlobalVariable *DestBBs = getIndirectTargets(Fn, EncKey);
for (auto &BB : Fn) {
auto *BI = dyn_cast<BranchInst>(BB.getTerminator());
if (BI && BI->isConditional()) {
IRBuilder<> IRB(BI);
Value *Cond = BI->getCondition();
Value *Idx;
Value *TIdx, *FIdx;
TIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(0)]);
FIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(1)]);
Idx = IRB.CreateSelect(Cond, TIdx, FIdx);
Value *GEP = IRB.CreateGEP(DestBBs, {Zero, Idx});
LoadInst *EncDestAddr = IRB.CreateLoad(GEP, "EncDestAddr");
Constant *X;
if (SecretInfo) {
X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey);
} else {
X = ConstantExpr::getSub(Zero, EncKey);
}
Value *DecKey = IRB.CreateSub(X, MySecret);
Value *DestAddr = IRB.CreateGEP(EncDestAddr, DecKey);
IndirectBrInst *IBI = IndirectBrInst::Create(DestAddr, 2);
IBI->addDestination(BI->getSuccessor(0));
IBI->addDestination(BI->getSuccessor(1));
ReplaceInstWithInst(BI, IBI);
}
}
return true;
}
bool Flattening::flatten(Function *f) {
vector<BasicBlock *> origBB;
BasicBlock *loopEntry;
BasicBlock *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar;
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
#if LLVM_VERSION_MAJOR * 10 + LLVM_VERSION_MINOR >= 90
FunctionPass *lower = createLegacyLowerSwitchPass();
#else
FunctionPass *lower = createLowerSwitchPass();
#endif
lower->runOnFunction(*f);
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
if (isa<InvokeInst>(tmp->getTerminator())) {
return false;
}
}
if (origBB.size() <= 1) {
return false;
}
LLVMContext &Ctx = f->getContext();
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(f);
}
Value *MySecret = SecretInfo ? SecretInfo->SecretLI : ConstantInt::get(Type::getInt32Ty(Ctx), 0);
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
if (isa<BranchInst>(insert->getTerminator()) && insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
insert->getTerminator()->eraseFromParent();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(load, swDefault, 0, loopEntry);
for (BasicBlock *bb : origBB) {
bb->moveBefore(loopEnd);
ConstantInt *numCase = ConstantInt::get(switchI->getCondition()->getType(), llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key));
switchI->addCase(numCase, bb);
}
fixStack(f);
lower->runOnFunction(*f);
delete lower;
return true;
}
bool Flattening::flatten(Function *f) {
vector<BasicBlock *> origBB;
BasicBlock *loopEntry;
BasicBlock *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar;
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
#if LLVM_VERSION_MAJOR * 10 + LLVM_VERSION_MINOR >= 90
FunctionPass *lower = createLegacyLowerSwitchPass();
#else
FunctionPass *lower = createLowerSwitchPass();
#endif
lower->runOnFunction(*f);
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
if (isa<InvokeInst>(tmp->getTerminator())) {
return false;
}
}
if (origBB.size() <= 1) {
return false;
}
LLVMContext &Ctx = f->getContext();
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(f);
}
Value *MySecret = SecretInfo ? SecretInfo->SecretLI : ConstantInt::get(Type::getInt32Ty(Ctx), 0);
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
if (isa<BranchInst>(insert->getTerminator()) && insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
insert->getTerminator()->eraseFromParent();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(load, swDefault, 0, loopEntry);
for (BasicBlock *bb : origBB) {
bb->moveBefore(loopEnd);
ConstantInt *numCase = ConstantInt::get(switchI->getCondition()->getType(), llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key));
switchI->addCase(numCase, bb);
}
fixStack(f);
lower->runOnFunction(*f);
delete lower;
return true;
}
环境
配置
操作系统
Windows 10
IDA 版本
7.7
Python
3.10.7
unicorn
2.1.1
keystone-engine
0.9.2
import unicorn
import capstone
import binascii
def print_regs(mu):
for i in range(unicorn.arm64_const.UC_ARM64_REG_X0, unicorn.arm64_const.UC_ARM64_REG_X30 + 1):
print('X%d: 0x%x' % (i - unicorn.arm64_const.UC_ARM64_REG_X0, mu.reg_read(i)))
def hook_code(mu, addr, size, user_data):
print('-------hook code start-------')
code = mu.mem_read(addr, size)
cp = capstone.Cs(capstone.CS_ARCH_ARM64, capstone.CS_MODE_ARM)
for i in cp.disasm(code, addr):
print('[addr:0x%x]: %s %s' % (i.address, i.mnemonic, i.op_str))
print_regs(mu)
def hook_mem_write(mu, type, addr, size, value, user_data):
print('-------hook mem write-------')
if type == unicorn.UC_MEM_WRITE:
print('memory write addr:0x%x size:%x value:0x%x' % (addr, size, value))
def hook_intr(mu, intno, user_data):
print('-------hook intr start-------')
print_regs(mu)
def test_arm64():
code = b'\xe0\x03\x1f\xaa'
mu = unicorn.Uc(unicorn.UC_ARCH_ARM64, unicorn.UC_MODE_ARM)
addr = 0x1000
size = 0x1000
mu.mem_map(addr, size)
mu.mem_write(addr, code)
code_bytes = mu.mem_read(addr, len(code))
print('addr:0x%x, content:%s' % (addr, binascii.b2a_hex(code_bytes)))
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X0, 0x100)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X1, 0x200)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X2, 0x300)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X3, 0x400)
mu.hook_add(unicorn.UC_HOOK_CODE, hook_code)
mu.hook_add(unicorn.UC_HOOK_MEM_WRITE, hook_mem_write)
mu.hook_add(unicorn.UC_HOOK_INTR, hook_intr)
try:
mu.emu_start(addr, addr + len(code))
except unicorn.UcError as e:
print(e)
stack_bytes = mu.mem_read(addr, 4)
print("mem:0x%x, value:%s" % (addr, binascii.b2a_hex(stack_bytes)))
if __name__ == '__main__':
test_arm64()
import unicorn
import capstone
import binascii
def print_regs(mu):
for i in range(unicorn.arm64_const.UC_ARM64_REG_X0, unicorn.arm64_const.UC_ARM64_REG_X30 + 1):
print('X%d: 0x%x' % (i - unicorn.arm64_const.UC_ARM64_REG_X0, mu.reg_read(i)))
def hook_code(mu, addr, size, user_data):
print('-------hook code start-------')
code = mu.mem_read(addr, size)
cp = capstone.Cs(capstone.CS_ARCH_ARM64, capstone.CS_MODE_ARM)
for i in cp.disasm(code, addr):
print('[addr:0x%x]: %s %s' % (i.address, i.mnemonic, i.op_str))
print_regs(mu)
def hook_mem_write(mu, type, addr, size, value, user_data):
print('-------hook mem write-------')
if type == unicorn.UC_MEM_WRITE:
print('memory write addr:0x%x size:%x value:0x%x' % (addr, size, value))
def hook_intr(mu, intno, user_data):
print('-------hook intr start-------')
print_regs(mu)
def test_arm64():
code = b'\xe0\x03\x1f\xaa'
mu = unicorn.Uc(unicorn.UC_ARCH_ARM64, unicorn.UC_MODE_ARM)
addr = 0x1000
size = 0x1000
mu.mem_map(addr, size)
mu.mem_write(addr, code)
code_bytes = mu.mem_read(addr, len(code))
print('addr:0x%x, content:%s' % (addr, binascii.b2a_hex(code_bytes)))
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X0, 0x100)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X1, 0x200)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X2, 0x300)
mu.reg_write(unicorn.arm64_const.UC_ARM64_REG_X3, 0x400)
mu.hook_add(unicorn.UC_HOOK_CODE, hook_code)
mu.hook_add(unicorn.UC_HOOK_MEM_WRITE, hook_mem_write)
mu.hook_add(unicorn.UC_HOOK_INTR, hook_intr)
try:
mu.emu_start(addr, addr + len(code))
except unicorn.UcError as e:
print(e)
stack_bytes = mu.mem_read(addr, 4)
print("mem:0x%x, value:%s" % (addr, binascii.b2a_hex(stack_bytes)))
if __name__ == '__main__':
test_arm64()
#include <stdio.h>
int add(int a, int b){
return a + b;
}
int add5(int a, int b){
int ret = 0;
for (int i = 0; i < 5; i++){
if(b > 10){
ret -= add(a, b);
}else{
ret += add(a, b);
}
}
return ret;
}
int main() {
int ret = add5(1, 2);
printf("add5 ret %d", ret);
return 0;
}
#include <stdio.h>
int add(int a, int b){
return a + b;
}
int add5(int a, int b){
int ret = 0;
for (int i = 0; i < 5; i++){
if(b > 10){
ret -= add(a, b);
}else{
ret += add(a, b);
}
}
return ret;
}
int main() {
int ret = add5(1, 2);
printf("add5 ret %d", ret);
return 0;
}
clang main.cpp -o main_icall -target aarch64-linux-gnu -mllvm -irobf-icall
clang main.cpp -o main_indbr -target aarch64-linux-gnu -mllvm -irobf-indbr
clang main.cpp -o main_cff -target aarch64-linux-gnu -mllvm -irobf-cff
clang main.cpp -o main_icall -target aarch64-linux-gnu -mllvm -irobf-icall
clang main.cpp -o main_indbr -target aarch64-linux-gnu -mllvm -irobf-indbr
clang main.cpp -o main_cff -target aarch64-linux-gnu -mllvm -irobf-cff
import flare_emu
import idc
import idaapi
import keypatch
def patch_one(address: int, new_instruction: str):
kp_asm = keypatch.Keypatch_Asm()
if kp_asm.arch is None:
print("ERROR: Keypatch无法处理此架构")
return False
assembly = kp_asm.ida_resolve(new_instruction, address)
(encoding, count) = kp_asm.assemble(assembly, address)
if encoding is None:
print("Keypatch: 无需修复")
return False
patch_data = ''.join(chr(c) for c in encoding)
patch_len = len(patch_data)
kp_asm.patch(address, patch_data, patch_len)
print(f"修复完成: {assembly}")
def myTargetCallBack(emu, address, argv, userData):
code_str = idc.GetDisasm(address)
register_name = code_str.split(" ")[-1]
print(f"address = {hex(address)}, X* = {hex(emu.getRegVal(register_name))}")
userData["br_map"][address] = emu.getRegVal(register_name)
def anti_icall():
br_addr_list = [0x4006A0, 0x400724]
eh = flare_emu.EmuHelper()
eh.iterate(br_addr_list, targetCallback=myTargetCallBack, hookData={"br_map": {}})
for br_addr in eh.hookData["br_map"]:
print(f"br_addr = {hex(br_addr)} {hex(eh.hookData['br_map'][br_addr])}")
patch_one(br_addr, f"bl {hex(eh.hookData['br_map'][br_addr])}")
import flare_emu
import idc
import idaapi
import keypatch
def patch_one(address: int, new_instruction: str):
kp_asm = keypatch.Keypatch_Asm()
if kp_asm.arch is None:
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2025-4-5 01:18
被简单的简单编辑
,原因: 一些排版调整
上传的附件: