以前做过pc端逆向,一直没有学过android,4月的时候,读了一下 my1988 对混淆壳的分析,很感兴趣,决定深入研究。
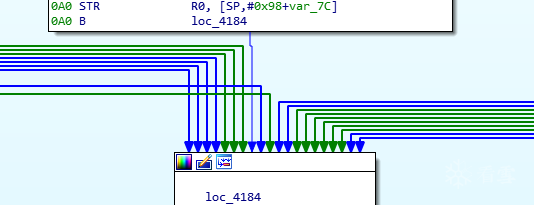
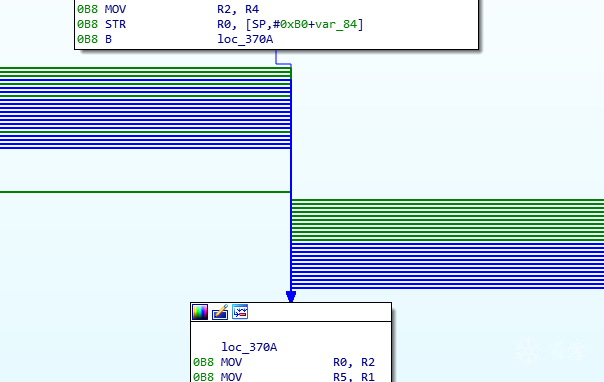
花了大约3个月的时间基本理清了混淆壳的原理,简单写了一个app,fastvm, 针对libmakeurl2.4.9.so 可以生成原始的cfg流图,和优化过的cfg流图, 以下是函数sub_342d的 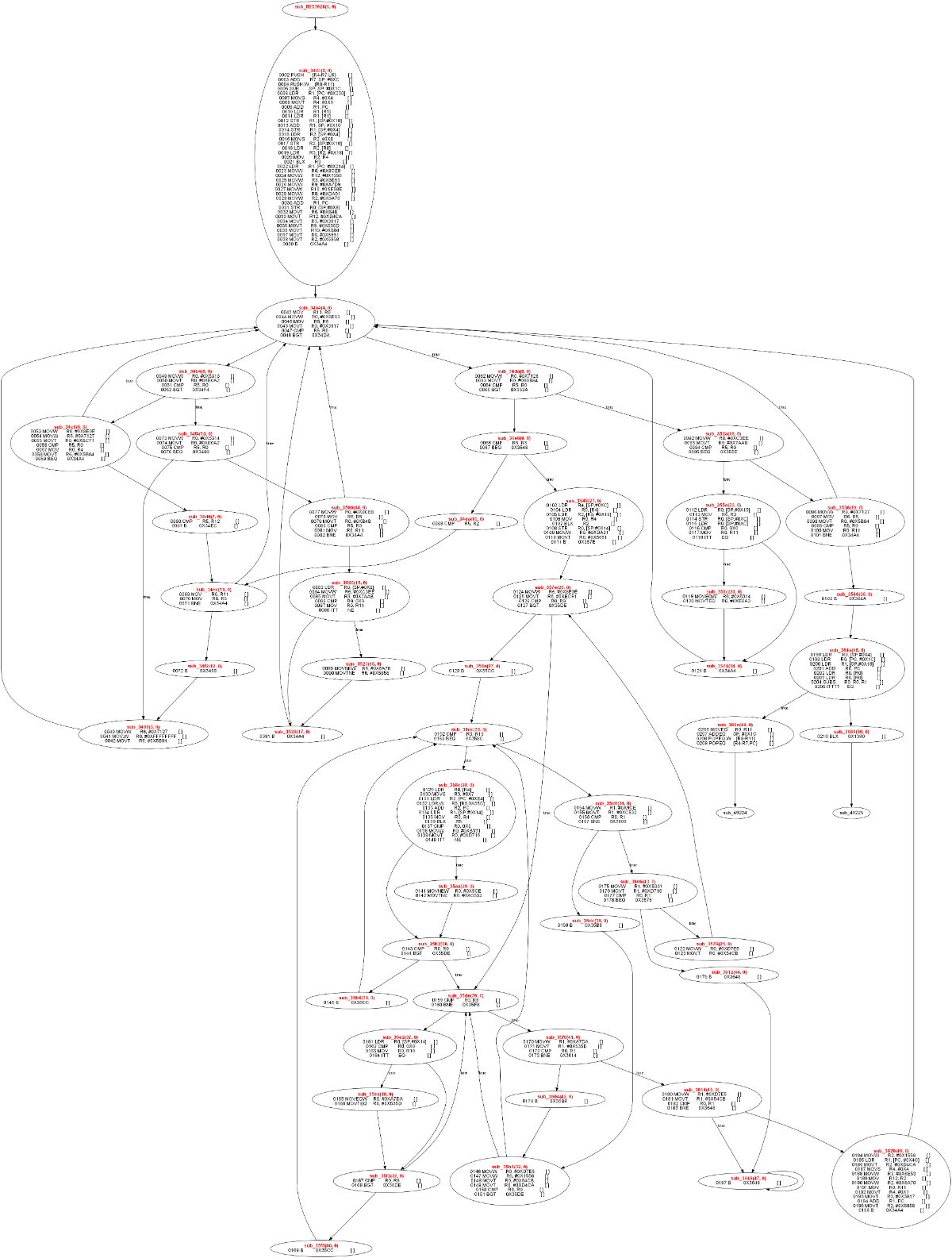 ]
]
优化过的如下:

#预备知识
写这个app的时候主要参考了3本书
代码里很多注释会有 P245,这样的写法,一般是代表1, 2中的某一本的第245页,
@aar 指的1
@MCIC 指的3
这个分析的很多了,我就不赘述了
因为我们要通过编译后端优化彻底干掉混淆,必须得自己实现数据流,所以无法使用别人的反汇编引擎,我们通过实现一个简单的正则表达式引擎来对elf的代码进行反汇编
我们重新实现一个正则表达式引擎,并增加自己的命名变量,举例:

我们定义一个正则表达式如下:
支持重复

先不管o的定义,我们看thumb_inst_cmp里面支持了 lm3和ln3,这句表达式的意义是:
我们在读取一个二进制串时,他以 0100 0010 0开始,接下去的三位提取到lm变量中,后面的3位提取到 ln变量中,这条指令用thumb_inst_cmp进行深度解析。这些变量都存放在一个arm_inst_ctx的结构中,
我们基于这个规则,完整的定义出整个arm thumb的指令集(暂时只定义了需要的部分)
然后基于此,按 nfs -> dfs -> 2d-trans的方式来生成整个状态机图
nfa的如下:
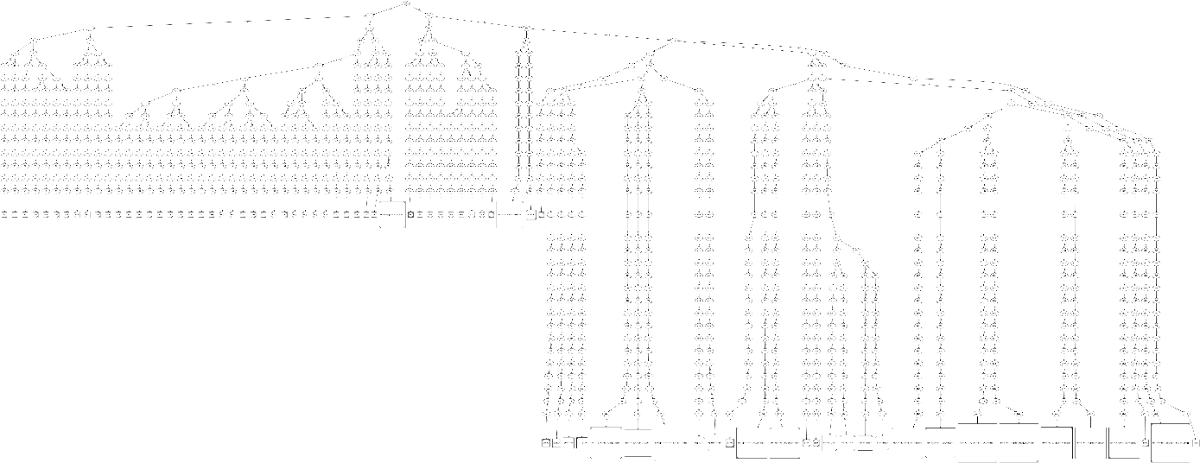
nfa在归纳同字符集可到达的边,生成dfa, 
PS. 不知道为什么,看雪把我图片压缩了,想看具体大图,可以看着 状态机大图
详细分析可以参考任意一本形式语言与自动机理论,或者 龙书, 《parsing techniques》都可。
语法分析反而比较简单,因为汇编语言不存在特殊的语法,唯一特殊的指令是it指令,在ida中arm的it指令是不会做切分,和上下的代码完整的放到一个block中,比如
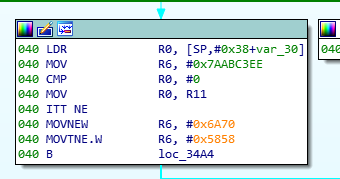
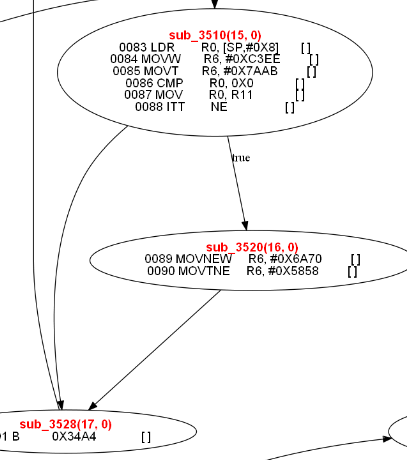
但是假如我们需要用编译优化去掉混淆,必须得把it指令做为一个单独的bcond指令来处理,比如上图中的代码,转换成c语言后如下:
基于此,上图中的指令,被我们转换成如下格式:
b<cond>指令没啥太多需要注意的,他末尾跟着的指令指向他的false_label分支,它的跳转指向它的true_label分支,这一点上和it是相反的
因为要做后端的数据流分析,必须给出所有指令的def和use关系, 举几个例子说明需要注意的地方,因为是直接在arm的汇编上做的def和use,所以实际的代码写起来很多的corner case非常难处理,举一些典型的例子说明下
进入函数前,需要定义r0-r3, sp, pc寄存器
出函数前,需要使用r0-r1, sp, pc寄存器
生成了def和use数据以后,就可以方便的做活跃性分析了,活跃性分析本身的算法很简单,伪代码如下, @MCIC.P232:

对照代码,参考fastvm中的minst.c:minst_blk_liveness_calc
和上面的代码差不多是一一对应的
在进行了活跃性分析以后,死代码删除就非常简单了,对应的c代码在minst.c:minst_blk_dead_code_elim中,原理就是:
某条指令被def,但是不在它的出口活跃列表中,则可以删除,举例
因为r0被定义了二次,导致了指令1中的r0,在到达2的时候已经死了。也就是不在它的出口活跃列表中了。
到达主要是研究,某条指令最远到达过什么地方,它在常量传播的分析中非常有用
假如你也打算深入分析混淆壳,建议认真读下 @MCIC的17章,Dataflow Analysis。
在上图中b就可以被优化为2,同时cmp的结果也是为1,按算法上的描述就是
假如某条指令被常量定值以后,后续所有使用过此条指令的代码都要根据自己的语义进行跟新
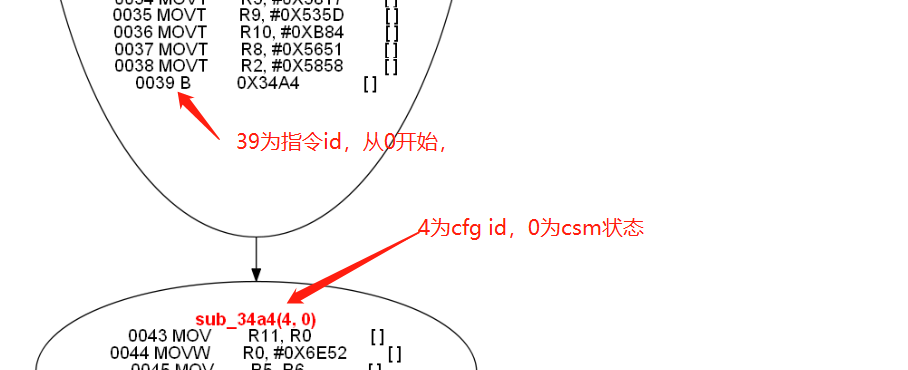
判断是否有混淆,我们需要遍历所有cfg节点,然后判断其cmp指令的左右2个参数,是否大部分都是常数,假如是的话,则认为其处在混淆cfg的某一个节点中,那么直接找到其支配节点即可。
ps. 这里为了方便,我直接偷懒把一个函数中前缀最多而且大于7的节点,当作了混淆状态机的支配节点了。
这里有个简单的办法,就是先过滤所有前缀节点小于7的可以直接抛弃,因为混淆函数的支配节点前驱节点都特别多,比如:

支配节点的算法,我没实现,但是原理上比较简单,可以参考@MCIC.C18(Loop Optimization)
这里简单介绍下什么是支配节点
有些书籍上可能也翻译为必经节点,也就是从外部节点进入到内层循环时必须经历的节点,这个节点非常有用
先看如下代码:
这个代码,我们手工尝试对他做混淆
我们简单审读下这个代码,把a定义为状态寄存器,只要你跟着状态寄存器走,整个循环自然会被全部展开。
上面的例子只是演示了简单的statment该如何混淆,那么如何实现循环,判断呢?
判断和循环从原理上来说都是一样的,只是判断以后,跳转点,跳到前面的某点上。从头开始,在来个例子,我们对上面的例子进行拓展:
混淆过后
大家简单肉眼跟读下这个代码,发现整个混淆壳其实就是一个稍微复杂的常量状态机。只要你顺着状态寄存器走,很容易就能跟踪出整个脉络
my1988在他的帖子my1988算法里面提到过一个简单的算法,把混淆过的代码的cfg分为2部分,一部分为 控制节点 一部分为 状态节点,然后连接 状态节点,删除 控制节点,这个算法是有问题的,因为假如原代码里面,散落了一,二条代码在 控制节点内,就会丢代码了。
不过我们只需要简单改造即可。
代码: minst_dob_analyze
参考代码 minst_csm_expand
为什么要拓展说一下,参考以下的代码:
混淆过后
我们看一下,到了cfg2的时候,a被b定值了,但是b实际上有2个值的,假如你要进行反混淆,必须得跟踪出唯一的定值路径才行,但是从cfg2开始已经不可分析了,那如何处理呢?
把cfg2改为如何形式:
有人看到这里,可能感觉很奇怪,为什么不直接改成如下形式呢
这是和编译优化的到达定值的生成有关,到达定值分析很蠢的,他只有对明确的定值语句,才能给出数据流分析。他无法识别
在某种程度上是等价的。
参考: minst_blk_classify
我们把cfg节点分为3类:
分类算法非常简单,用dfs即可:
循环遍历所有不为csm_out的bcond节点,也就是有条件跳转的节点
然后分析其跳转指令参考的cmp指令的,2个寄存器的值,分析其是否为常数,是的话,进入步骤5,定值点跟踪
在进入定值点跟踪时,我们先简单说一下一些术语
以下的示例代码来自于 libmakeurl2.4.9.so的jni_OnLoad,ida f5以后,代码如下:

v2是混淆的状态寄存器
这个是IDA F5后的分析结果,我们在做实际的编译优化时,是在cfg流图上做的,我们用上面语法分析优化后得到的cfg流图操作一遍:
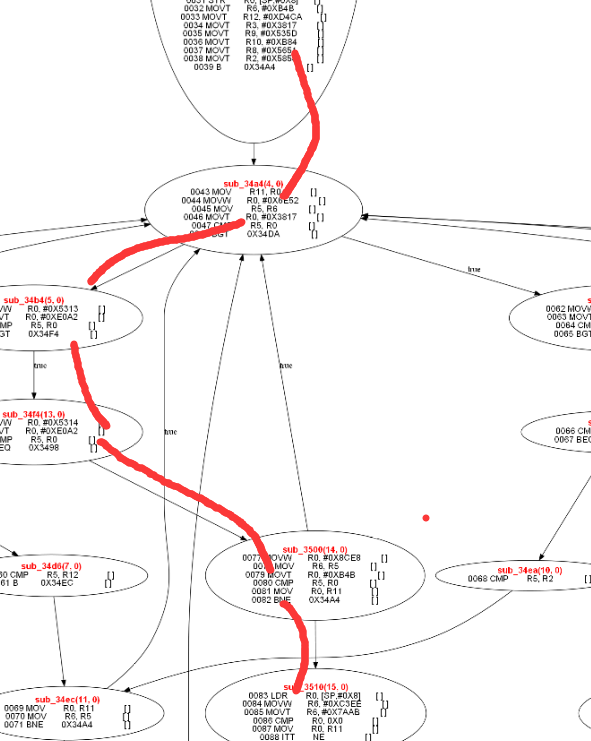
连接新的cfg和cfg15,最后得到的图如下
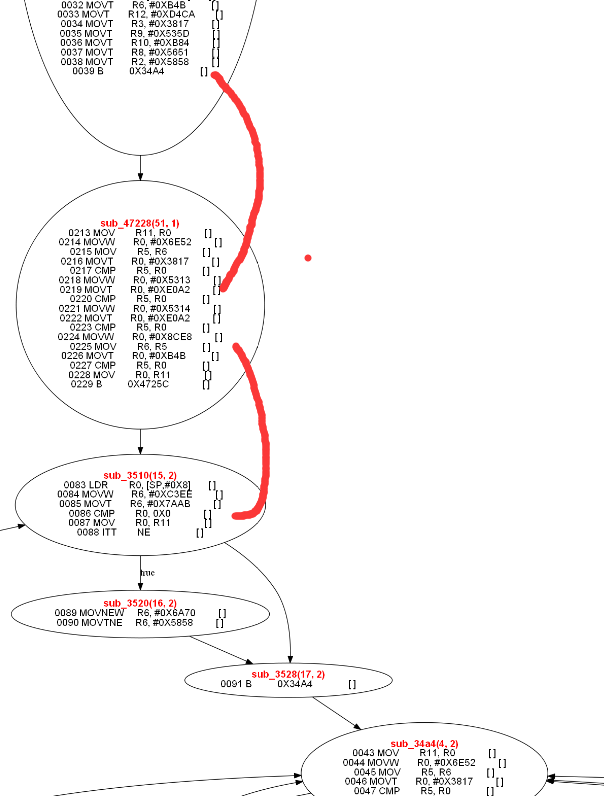
cfg51就是新生成的节点,里面有大量的指令是死的,比如 216, 219, 222都是重复定义的,后面的编译优化分析都可以彻底干掉,上图中的cfg51被编译优化后变成了,如下形式:
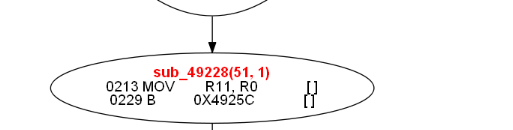
然后我们在找v2的另外的定值点,重复这个过程
遍历所有的cfg,一直到找不到找不到可以跟踪的定值点结束,也就是最开始的那副优化过的图像。
一般优化到最后以后,大量的节点都找不到前驱节点都可以删除,后面优化的就是最终的图像了。
这里是一个更复杂的例子,因为图像太大了,我直接放在github上。
sub_367c optimization
我对ssa不怎么熟悉,感觉表达能力和普通的数据流分析差不多,所以没上
我对android下调试还不熟悉,小米的手机root需要申请权限,很久都没发权限邀请给我
很困难,一开始用了别名分析,结果错误的优化了某些变量,想用别名分析,可能需要深入的分析每个函数之间的调用关系才行
[培训]《冰与火的战歌:Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2020-7-13 09:48
被baikaishiu编辑
,原因:






 万抽抽
万抽抽  赞, 我每次自己写 IR 到最后都会发现 “写得什么玩意,还不如直接用现成的”
赞, 我每次自己写 IR 到最后都会发现 “写得什么玩意,还不如直接用现成的”



