我平时的工作流就是在 Claude Code 和 OpenCode 里跟模型聊天、迭代、挖洞。这套流程我已经用了挺久,效果还不错,但问题是烧钱。正好 DeepSeek V4 出来了,通过架构创新把 1M 上下文的成本打了下来,缓存命中高的情况下成本极低,我就想知道它能不能替代我手头那些贵的模型,缩减 token 成本。需要注意的是本文的侧重点不在于发现了多少真实漏洞,而在于评估长任务下,模型的表现差异。
于是拉上郭小白师傅,自费跑了 6 组对比实验。这不是严谨测评,只是想在 DeepSeek V4 在自动化长任务上的效果。
先看关键指标速查,有个整体印象:

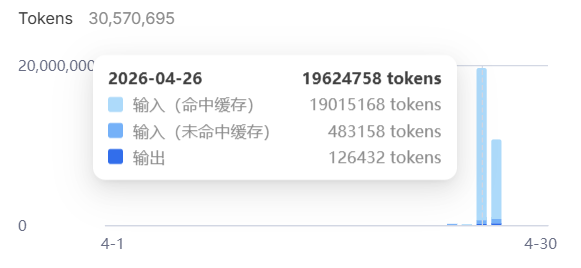
精度和发现数量基本是反着来的,最让我惊喜的是 DeepSeek 夸张的命中率和价格,这么多次实验加起来也就十几块钱,单次半小时左右的长任务在 2 块钱:
实验测试全部通过官方 API,DeepSeek V4 是核心目标,所以给它试了 OpenCode 和 Claude Code 上的四种组合,包括是否开启 plan 模式、subagent 是否使用 DeepSeek-V4-pro 模型,GPT-5.3 Codex 和 Kimi K2.6 当对比:

为什么不选 GLM-5.1 :限制 1 并发
为什么不选 GPT-5.5 :内容安全管控,懒得折腾
为什么不选 Claude :太贵
为什么不选 Qwen:没有自动调用Ghidra MCP,烧了两百多块钱(学生代金券),遂放弃
为什么...:
任务:拿一个 Tenda W30AP V1.0RE 路由器固件,扔给 AI 让它挖漏洞。
工具链:Ghidra MCP + Binwalk v3。初始提示词是从大可实验室简单魔改的:AI挖Java 0day不再靠运气!这套Skill让审计覆盖率100%、幻觉率趋近0
核心逻辑是敏感 API 扫描 + 多 Agent 并行审计,每条调用链必须标注文件:行号,不得编造代码片段,不确定的发现标记为 Hypothesis,宁可漏报不能误报。对于可利用漏洞按利用难度记性评估,最后还需要检查文件覆盖率,直到百分百。提示词放在了文章末尾。
先说各模型的表现。注:Hypothesis的全都没人工核验
Kimi 只报了 6 条,它是唯一一个完成了跨库调用链追踪的模型,其他模型在追到动态库边界的时候就放弃了,Kimi 硬是跨了 .so 追到了底。
DeepSeek 在 Claude Code 上用 Max Thinking 模式直接报了 27 条,量上碾压全场,但人工确认下来近半是误报。在 OpenCode 上 11 条发现 5 个正确,1个归因错误,算是均衡选手,不过没有 Claude Code 上的表现好。
GPT-5.3 最保守,3 条发现,其中 1 个归因需要进一步验证,关键漏洞比如认证绕过直接没看到。37 分钟跑完,输出结构最规整,但深度不够,而且不知道为什么opencode导出的思考过程完全是空的(
有个要吐槽的事:S4(DS-CC-Plan-Flash)最终输出报告时仅有几个漏洞,但从日志看它里面列的 30 多条其实挺靠谱的。我实在没精力一条条翻日志去验证,所以确认数打了个问号。模型干了 80 分的活,最后一步输出开始偷懒,功亏一篑——这类问题其实很普遍。
人工核验后,所有模型一致发现的真实漏洞:
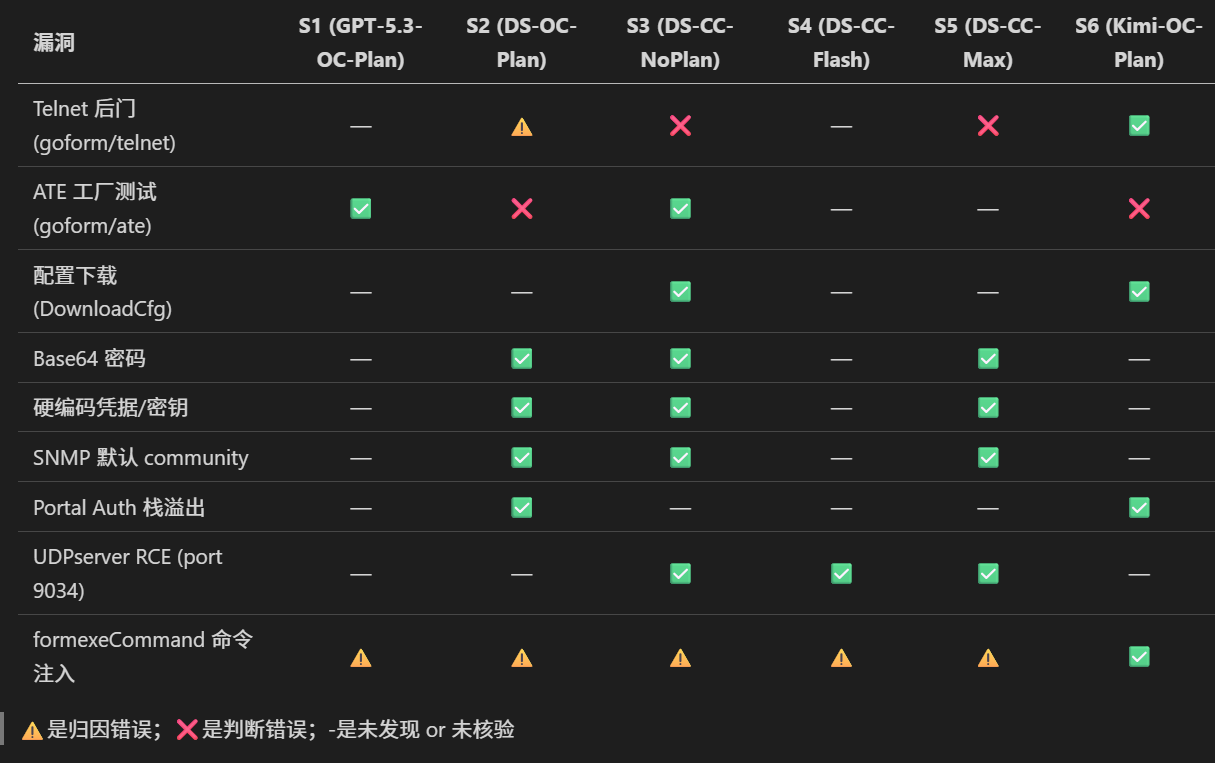
S4 表现看起来差是因为最终导出报告出了问题,日志里实际列了 30 多条,大部分长得挺靠谱的,但没精力逐一翻日志核验,所以大部分标了"—"。此外,由于精力有限,所有 Hypothesis 待确认的都没有经过人工确认,所以显得 no-plan 效果更好。

几个值得注意的点:
有用,而且比我想的明显。No-Plan 模式(S3)完全跳过了覆盖率门禁,Plan 模式(S4/S5)严格走完了"读取输出→交叉验证→启动补扫→重新验证"的流程。
不过别高兴太早。覆盖率门禁保证的是"看过了",不保证"看懂了"。S5 声称覆盖 243 个文件,但 High/Medium 发现也就两三句话,深度显然不够。
这部分说实话参考意义有限——不知道是不是我用的这个 Ghidra MCP 的问题,反编译出来的代码可读性极差,明显影响了大模型发挥。
但有些错误很值得玩味,因为它们不是个别模型的锅,而是三个模型在同一个位置犯了同样的错:
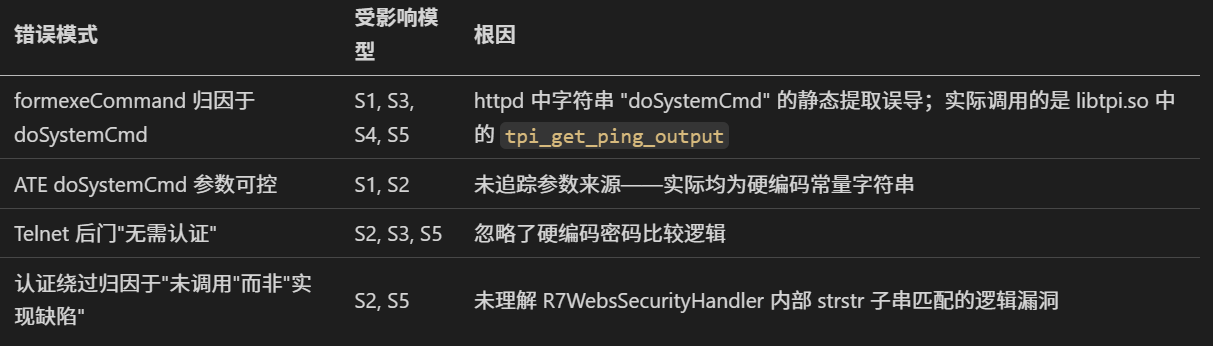
这些说明高质量的数据和输入,尤其是反编译代码的质量对任务影响极大。Ghidra 出来的东西可读性太差,模型再聪明也是 garbage in garbage out。工具链不升级,换个再聪明的脑子也白搭。
跑完这轮测试,我脑子里给三个模型画了像:
GPT-5.3 Codex 极度保守,严格按照指令格式来,输出结构最规整,Plan 阶段执行最严格。但深度不足,3 条发现 1 条明确误报,漏了关键漏洞也不会主动深挖。
DeepSeek V4 Pro 激进探索,高并行度。Claude Code 上展现了最强的系统协调能力——7 个 Agent 并行 + 覆盖率矩阵自动补扫。精度随发现数量上升而变化,而且会在同一个坑里反复摔跤。适合广度优先的大面积扫描,快速摸清攻击面。最重要的是——便宜,1M 上下文 + 高缓存命中,大规模跑起来不心疼。
Kimi K2.6 方法论驱动,谨慎验证,唯一完成跨库调用链追踪的模型,严格遵循 Hypothesis 标记。
Claude Code 的核心优势在于原生 Agent 并行机制和覆盖率门禁的严格实施。
1. DeepSeek V4 Pro + Claude Code + Plan + Max Thinking,是目前性价比最高的组合。 27 条发现、100% 文件覆盖、25 分钟跑完。适合广度优先的攻击面测绘。
2. Plan 模式一般优于直接开干,但不能强求 Plan 一定能解决问题。 S3 不开 Plan,直接跳过了覆盖率门禁;S4/S5 开了 Plan,流程走得规整。但 Plan 做到 100% 覆盖后,S5 的深度分析也不过两三句话——Plan 解决了"不遗漏",没解决"不理解"。对于真正困难的任务,不管是全自动 Agent 还是人机协作,本质上都是迭代完善的过程,别指望一步到位。
3. 精度的天花板不在模型,在 Ghidra 反编译出来的那坨代码。 三个模型在同一个位置犯同样的错,说明根因在工具链而非推理能力。工具链不升级,换再聪明的脑子也白搭。
4. 人机协作短期内不会被替代。 人类的经验可以帮助模型快速撕开问题核心的口子——模型在全自动模式下花了大量 Token 在低价值路径上试错,但如果人在关键节点看一眼、给一句话的判断,模型就能省下大量无意义的探索。反过来,模型能覆盖人懒得逐行审计的代码,把人的判断力放大到整个固件。模型负责广度,人负责方向和深度判断,这个配合模式在深入任务上远优于全自动。
5. 智能体框架拆解到最后,本质上就两个核心任务:上下文管理(含记忆)和任务编排逻辑。 其余的调度、工具调用、错误恢复,无非是这两个核心的外延。上下文管理决定了模型"知道什么",任务编排决定了模型"怎么干"。这两个做好了,框架就不会太差。Claude Code 和 OpenCode 毕竟是通用 CLI,它们的 Plan、Agent 并行、覆盖率门禁都是面向通用场景设计的,遇到困难任务时调度策略和上下文淘汰机制并不总能贴合安全审计的需求。如果要做自动化解决困难任务的智能体,只能自己搭,可以考虑基于 pi-agent这类框架来做深度的编排定制。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!






