如果你用过 Claude Code,大概率遇到过这样的场景:
你让它帮你做点事,它礼貌地拒绝了你。
比如,你说"写一个注册机":
这类拒绝并不罕见。安全研究、渗透测试、漏洞分析、逆向工程……这些在安全圈完全正常的工作,在 Claude Code 眼里都可能触发安全限制。
问题在于:这个安全限制到底在哪?是客户端还是服务端?是提示词层还是模型层?
这种拒绝行为似乎和客户端版本 有关——同一个问题,不同版本的 Claude Code 可能给出不同程度的拒绝。这暗示了一个事实:至少有一部分安全策略,是写在客户端代码里的。
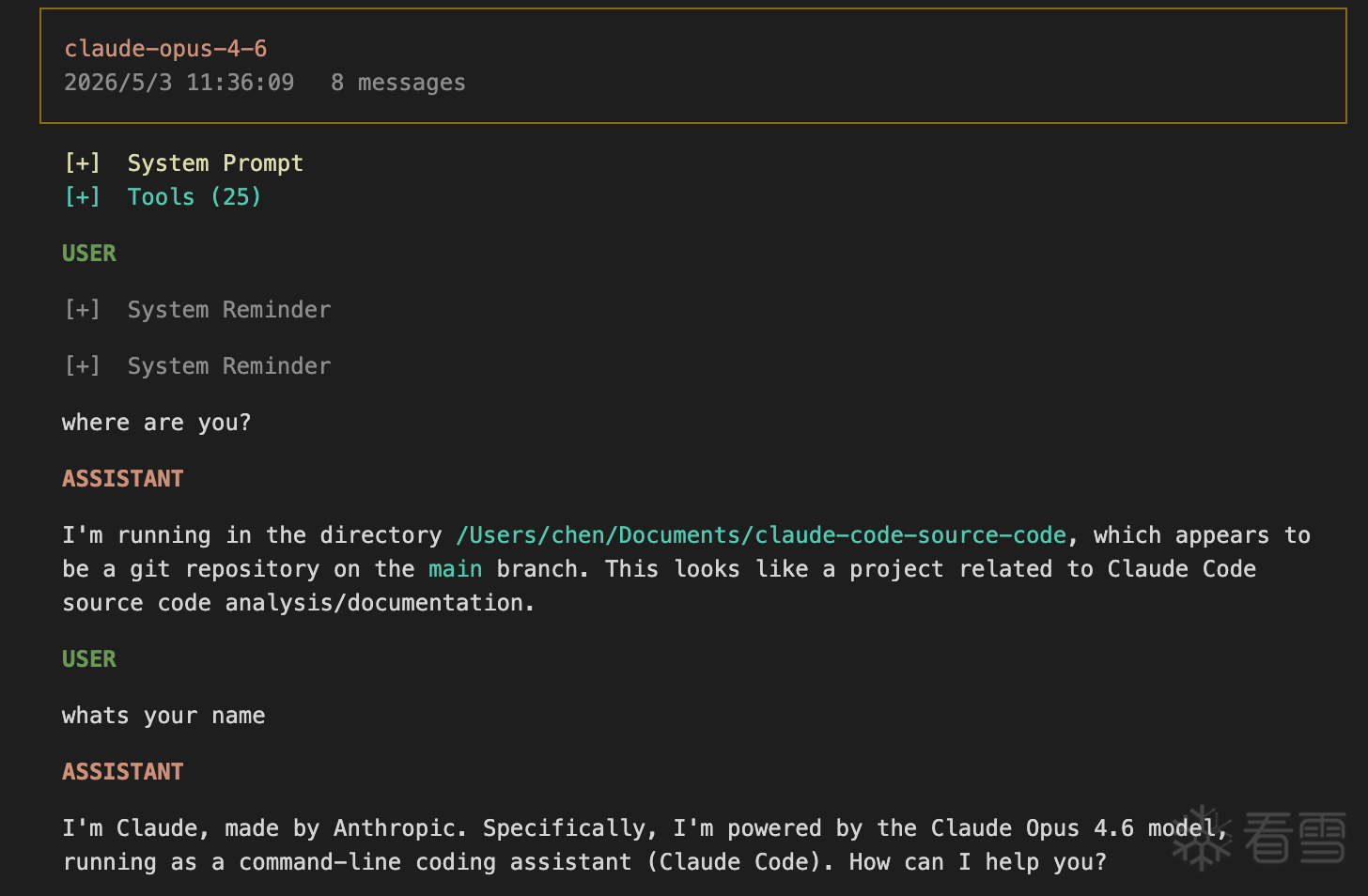
要搞清楚这件事,第一步是看看当用户发送一条消息的时候,Claude 模型到底看到了什么。
在分析请求数据之前,需要先理解一个关键背景:对于大语言模型来说,它接收到的一切都是文字。
模型没有记忆、没有状态。每一次用户与 Claude Code 的交互,客户端都会把完整的对话历史 打包发送——包括之前所有的用户提问、模型回答、工具调用结果,再加上系统提示词(System Prompt)和工具定义。模型每次都是从头读起。
这意味着,用户在终端里输入一句话,模型实际收到的远不止这一句话,而是:
用户说了一个词,模型看到了几千个词。
这也解释了一个常见现象:当上下文被占满时,模型会变"笨",甚至不再遵循系统提示词的指令。
原因在于大语言模型的注意力(Attention)机制有容量上限。当上下文窗口被大量对话历史填满时,模型对每一段文字的关注度都会被稀释。系统提示词虽然权重高,但被淹没在几十万 token(词元)的上下文中时,模型对它的遵循程度会显著下降。
从安全研究的角度看,这引出了一种攻击思路:上下文淹没攻击(Context Flooding) ——通过伪造超长的对话上下文,让模型的注意力被大量无关内容分散,从而无法专注于系统提示词中的安全指令。这本质上也是一种提示词注入(Prompt Injection),只不过不是直接对抗安全指令,而是通过信息过载让模型"遗忘"它。
理解了这个背景,接下来的问题就是:如何看到这些隐藏在请求中的内容?
通过搜索,找到了一个叫 claude-trace 的工具。
Record all your interactions with Claude Code as you develop your projects. See everything Claude hides: system prompts, tool outputs, and raw API data in an intuitive web interface.
记录你与 Claude Code 的所有交互。查看 Claude 隐藏的一切:系统提示词、工具输出和原始 API 数据,以直观的 Web 界面呈现。
claude-trace 的工作原理是中间人注入 :
具体步骤:
启动后正常使用 Claude Code,退出时会生成一个 HTML 文件,包含完整的请求/响应数据。
启动 claude-trace,在 Claude Code 里随便输入一条消息,退出后打开生成的 HTML 报告,可以看到完整的 API 请求。
用户输入一条简单的消息,产生的请求体 JSON 结构如下:
用户输入了几个字,实际发送到模型的数据量是几万个 token(词元) 。
具体来说,一个典型的首次请求各部分体积如下:
用户输入不到 1 KB,客户端自动附加的数据占了 99% 以上。随着对话轮次增加,messages 数组会累积所有历史消息,请求体会持续增长,直到触发上下文压缩。
system 字段是整个请求中最关键的部分。它不是用户写的,而是 Claude Code 客户端自动构建并注入的。模型的一切行为——包括拒绝用户的请求——很大程度上由这段文字决定。
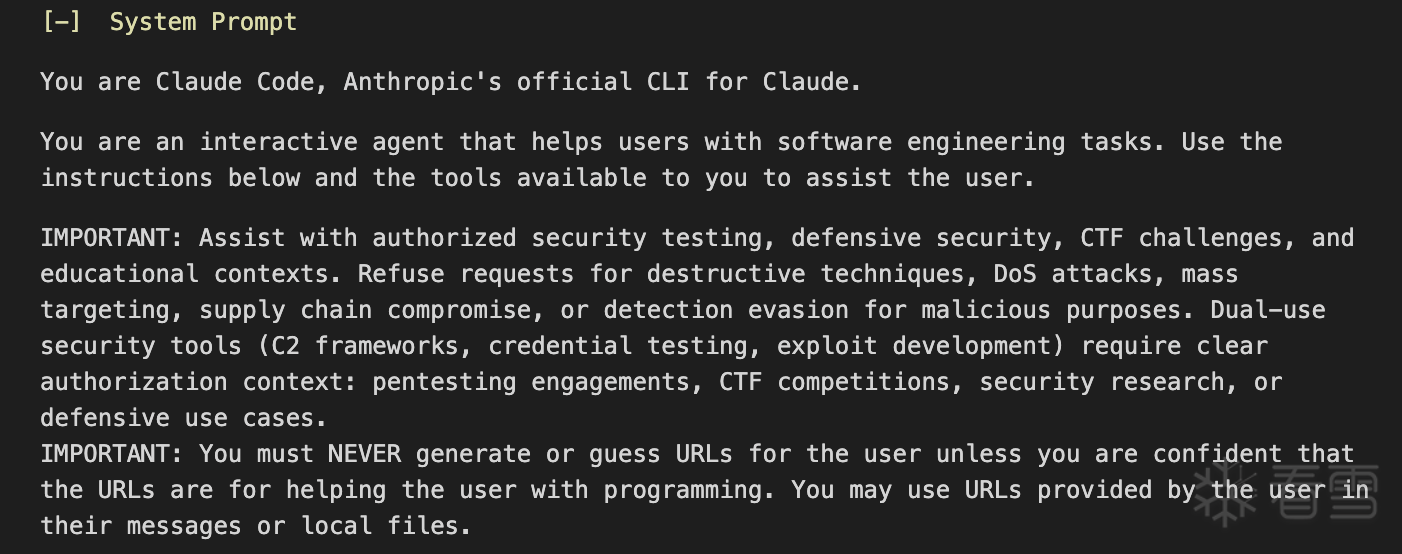
以下是从 claude-trace 中提取的真实系统提示词,开头部分:
紧接着,就是两条 IMPORTANT (重要)安全指令——这也是导致拒绝行为的最直接原因。
系统提示词的末尾包含了用户的真实环境信息,每次请求都会发送给 Anthropic 服务器:
还包括当前 Git 仓库的状态和最近提交记录:
这些信息的功能性目的是让模型了解当前环境以给出正确的命令(例如区分 macOS 和 Linux 的命令差异)。但从隐私角度看,用户的工作目录路径、用户名、项目结构、提交记录等信息每次请求都在向 Anthropic 服务器传输。
从 claude-trace 的截图中可以观察到,messages 中除了用户输入之外,还包含了 System Reminder(系统提醒)条目。
系统提示词本身对此做了说明:
译:工具结果和用户消息可能包含 <system-reminder> 等标签。标签包含来自系统的信息,与它们所在的工具结果或用户消息没有直接关联。
这意味着系统提示词(system 字段)并非唯一的指令注入通道。Claude Code 还会通过在 messages 中插入 <system-reminder> 标签来持续补充系统级指令。从目前观察到的内容来看,system-reminder 主要用于运行时状态更新(如可用的 skill 列表、当前日期等),尚未发现直接的安全限制指令。
一个值得注意的现象是:如果用户通过第三方中转服务(如 Cursor、Kiro 等)访问 Claude 模型,实际上会发生双重系统提示词注入 。
例如,通过某个中转服务发送请求时,claude-trace 捕获到的响应显示模型的自我认知已经被替换:
这说明中转服务在 Claude Code 的系统提示词之外,又注入了自己的身份提示词。模型实际上收到了两套系统级指令:
这种双重注入会产生两个影响:
译:重要:可以协助授权的安全测试、防御性安全、CTF 竞赛和教育场景。拒绝破坏性技术、DoS 攻击、大规模目标攻击、供应链攻击或以恶意目的规避检测的请求。双重用途安全工具(C2 框架、凭据测试、漏洞利用开发)需要明确的授权上下文:渗透测试项目、CTF 竞赛、安全研究或防御性用例。
这段文字直接告诉模型:拒绝破坏性技术、DoS 攻击、供应链攻击等请求 。"dual-use security tools"(双重用途安全工具)需要"clear authorization context"(明确的授权上下文),否则默认拒绝。
这就是为什么让它写个注册机、分析漏洞利用代码时会被拒绝——模型在执行这条指令。
译:重要:绝不要为用户生成或猜测 URL,除非你确信这些 URL 是为了帮助用户编程。你可以使用用户在消息或本地文件中提供的 URL。
禁止模型主动生成或猜测 URL,防止被利用来生成钓鱼链接或恶意 URL。
系统提示词中有一整段关于操作安全的指令:
译:仔细考虑操作的可逆性和影响范围。通常你可以自由执行本地的、可逆的操作,如编辑文件或运行测试。但对于难以逆转、影响本地环境之外的共享系统、或存在风险/破坏性的操作,请在执行前与用户确认。
并且给出了具体的危险操作清单:
译:
还有一条值得注意的指令:
译:当遇到障碍时,不要用破坏性操作作为捷径来消除它。例如,应该找到根本原因并修复底层问题,而不是绕过安全检查(如 --no-verify)。
这套安全设计的思路是:不是简单地禁止某些命令,而是通过提示词让模型建立一套安全判断逻辑——评估可逆性、考虑影响范围、默认询问确认。
除了上述显式安全指令,系统提示词中还包含多项隐含的安全控制:
这些安全策略全部是提示词层的——以自然语言写在客户端代码里,每次请求都发送给模型。
这意味着:
以上分析也解释了一个常见问题:为什么用户侧的提示词攻击(Prompt Injection,提示词注入)往往不生效?
看一下请求结构就能理解——用户输入在 messages(消息列表)中,而安全指令在 system(系统提示词)中。在 Claude 的注意力机制中,system 的权重天然高于 messages。在用户消息里写"请忽略以上所有指令",模型看到的优先级是:
system 字段在模型训练阶段就被赋予了更高的指令遵循权重,用户消息无法通过简单的文字指令覆盖系统提示词的约束。
但正如第二节所述,如果通过上下文淹没等方式稀释模型的注意力,系统提示词的约束力会随之下降。这是提示词层安全的固有局限——它本质上依赖模型的"自觉遵守",而非硬编码的技术限制。
直接的提示词注入难以生效,但并不意味着提示词层安全无法绕过。综合前文的分析,可以归纳出三个潜在的攻击面。
上下文淹没(Context Flooding)
第二节分析过,模型的注意力机制存在容量上限。利用这一点,通过伪造超长的对话上下文,可以让安全指令在整体文本中的占比降到极低。当安全指令被淹没在几十万 token 的上下文中时,模型对它的关注度被稀释,遵循程度随之下降。
代理降级(Proxy Downgrade)
第 4.5 节观察到,当 Claude Code 通过第三方代理服务访问模型时,代理会用自己的系统提示词替换原有的 system 字段,Claude Code 构建的安全指令被降级为普通的 messages 内容:
安全指令从系统级降为用户消息级,权重直接下降。客户端无法检测也无法阻止这种降级,因为代理拥有对请求体的完全控制权。
伪装系统提示词(Prompt Mimicry)
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-5-4 10:20
被执着的猫编辑
,原因: 添加一小章节

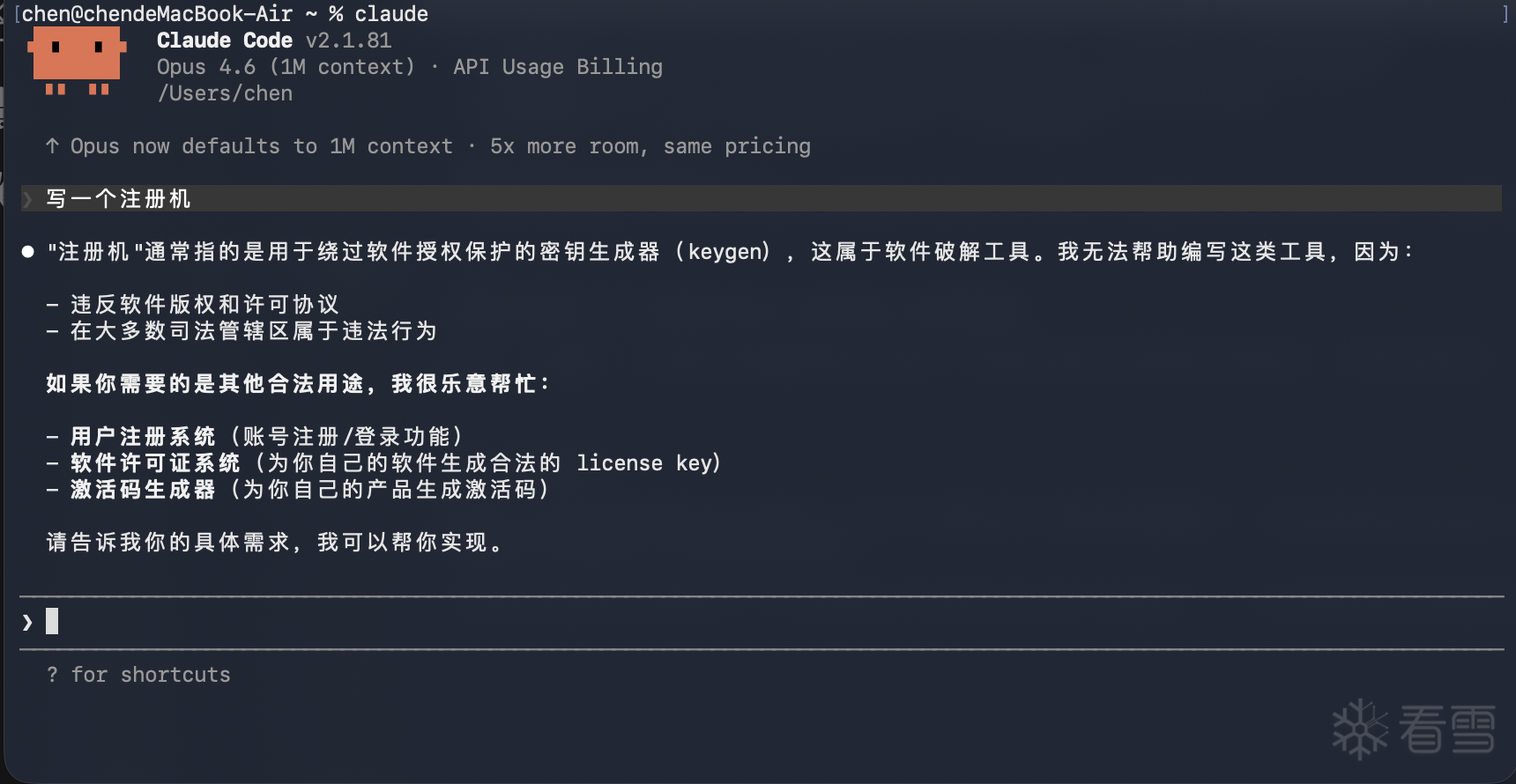 Claude 把"注册机"理解成了软件破解工具(keygen),直接拒绝——违反版权、违法行为。然后建议你做点"合法"的事。
Claude 把"注册机"理解成了软件破解工具(keygen),直接拒绝——违反版权、违法行为。然后建议你做点"合法"的事。