关于 Claude Code 封号,社区里已经有很多经验总结:固定 IP、避开机房段、对齐时区和语言、不要多设备同时活跃、不要长时间高并发请求。它们并非完全没有道理,但如果只盯着这些单点信号,很容易误判风险的来源。
本文不再给出另一份“防封清单”,而是换一个角度:回到 Claude Code 客户端本身,看看它在正常使用过程中会向服务端发送哪些信息。
这件事的意义在于,服务端看到的并不一定只是一条孤立的推理请求。围绕一次请求,客户端还会带上账号、设备、进程、工作目录、git 仓库和运行环境等上下文。理解这些上下文,比记住某几条经验规则更有助于判断风险。
先把边界说清楚:本文基于 Claude Code v2.1.88 反编译源码,以及对相关中转实现的代码分析。文中能够确认的是“客户端发送了什么、服务端因此理论上能拿到什么”。至于服务端实际如何判定风险、哪些字段权重更高,外部无法直接观测。下面所有推论,都会尽量停在这个边界之内。
常见防封经验通常围绕几个单点展开:IP 是否稳定、地区是否一致、系统时区是否匹配、请求频率是否过高、同一账号是否多地登录。这些因素当然可能影响风险,但它们解释不了一个现象:有些用户基本照做,仍然遇到封号;也有些用户并不严格遵守,却长期正常使用。
这说明问题不太可能只落在某一个字段上。
更合理的看法是:服务端面对的不是一条条互不相关的请求,而是一组围绕账号持续积累的上下文。一次请求可能看起来很正常,但如果这个账号长期只表现为“不断产生推理请求”,却缺少真实客户端通常会伴随产生的设备、进程、配置和遥测信息,它在数据形态上就会显得不完整。
所以,与其问“这个 IP 会不会封号”“这个时区要不要改”,不如先问一个更基础的问题:
这个账号的使用痕迹,是否像一个真实客户端在一台真实机器上持续运行?
这不是一个玄学问题。Claude Code 客户端确实会发送足够多的上下文信息,使服务端有条件从“单次请求”之外观察账号的使用形态。
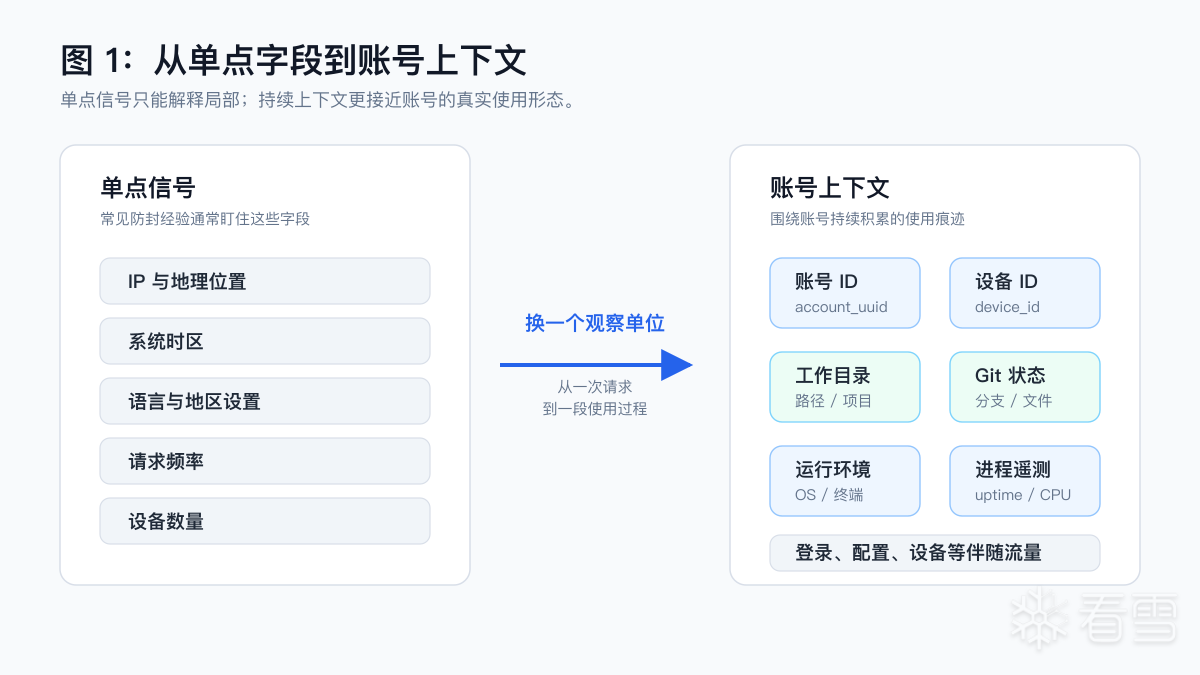 图 1:风险判断不只来自单个字段,而来自持续积累的账号上下文。
图 1:风险判断不只来自单个字段,而来自持续积累的账号上下文。
Claude Code 发起 /v1/messages 请求时,请求体里不只有用户输入的内容。它还会在 system 和 metadata 中加入一组本机环境与账号相关的信息。
先看 system。客户端会把当前工作目录、是否处在 git 仓库中、操作系统平台、shell 类型、系统版本等信息拼进系统提示里。也就是说,服务端看到的请求并不是一段完全脱离环境的文本,而是一段带着运行环境的文本。
其中最容易被忽略的是路径和 git 信息。
当前工作目录通常是绝对路径。在 macOS 上,它可能长这样:
这类路径里经常包含本机用户名、项目名、公司名或客户名。它未必是敏感内容,但它确实是一种稳定的身份和项目线索。
如果当前目录是 git 仓库,Claude Code 还会读取一部分 git 状态,包括当前分支、默认分支、最近提交、工作区状态,以及本地配置中的 git user.name。这里有两个细节值得单独说明。
第一,git user.name 很多人会填真实姓名或常用英文名。客户端会主动读取这个值,并把它作为 Git user 写进提示词。它不是网络层无意带出的信息,而是客户端在构造上下文时主动收集的内容。
第二,git status --short 会列出已修改和未跟踪的文件路径。文件内容不会因此直接上传,但文件名本身有时就包含项目代号、客户名、内部功能名,甚至 .env.production 这类不该轻易出现在上下文里的名称。换句话说,请求里可能不只有“你问了什么”,还会带上“你正在什么项目里、改哪些文件”。
顺手澄清一个常见说法:git log --oneline 本身只包含短 hash 和提交标题,不包含提交时间,也不包含时区。真正更值得注意的,反而是 Git user 和工作区文件路径。
除了 system,请求里的 metadata.user_id 也很关键。它大致由三部分组成:
其中 device_id 来自本地 ~/.claude/config.json 里的 userID。它是按本机配置保存的,不是每次登录都重新生成。只要这个配置文件还在,换一个 Claude 账号后,新账号仍可能带着同一个本地 device_id 发起请求。
这件事本身不等于“换号一定会被关联”,但它说明客户端具备把多个账号与同一台本机环境联系起来的基础条件。对于正常用户来说,这只是设备连续性的体现;对于频繁切换账号或批量使用账号的场景,它会成为更明显的上下文线索。
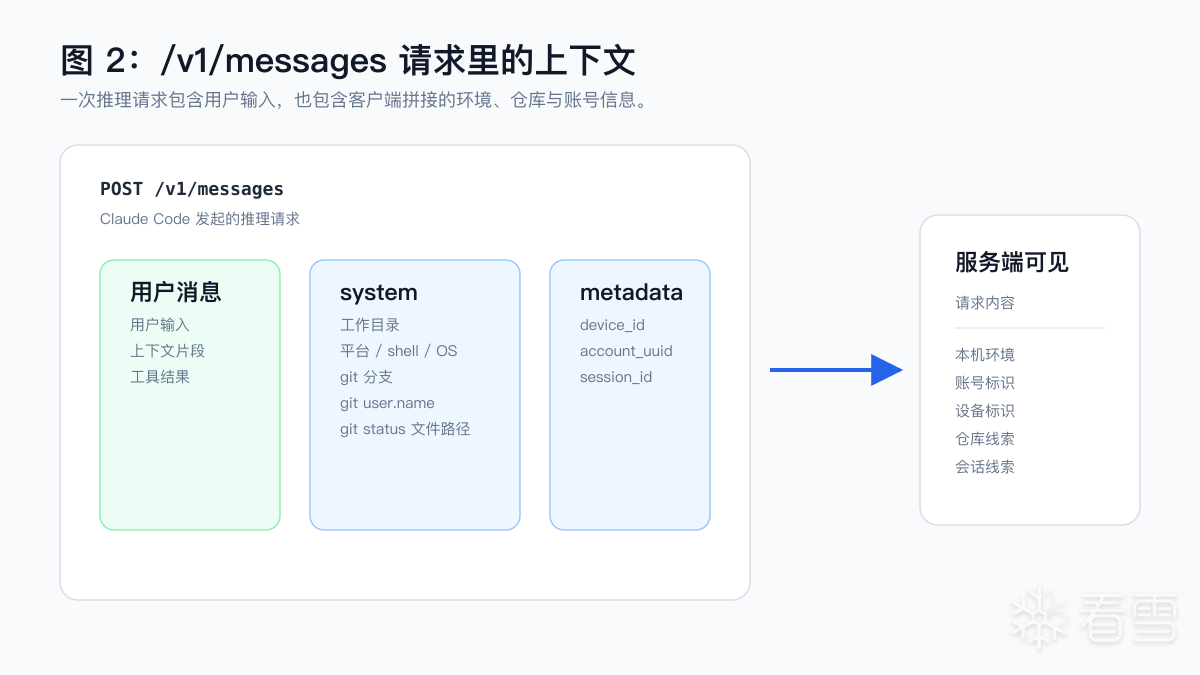 图 2:一次推理请求并不只有用户输入,也会带上本机与账号上下文。
图 2:一次推理请求并不只有用户输入,也会带上本机与账号上下文。
如果说 /v1/messages 里的信息回答的是“这次请求从哪里来”,那么遥测事件回答的就是“这个客户端进程正在怎样运行”。
Claude Code 有一条第一方事件上报通道,端点是 event_logging/batch。默认情况下,只要客户端在产生事件,就会按批次上报。源码里可以看到默认导出间隔是 10 秒,单批最多 200 条事件。
这类事件会附带一组 envContext。它包含的不是某个单一字段,而是一整组运行环境画像:
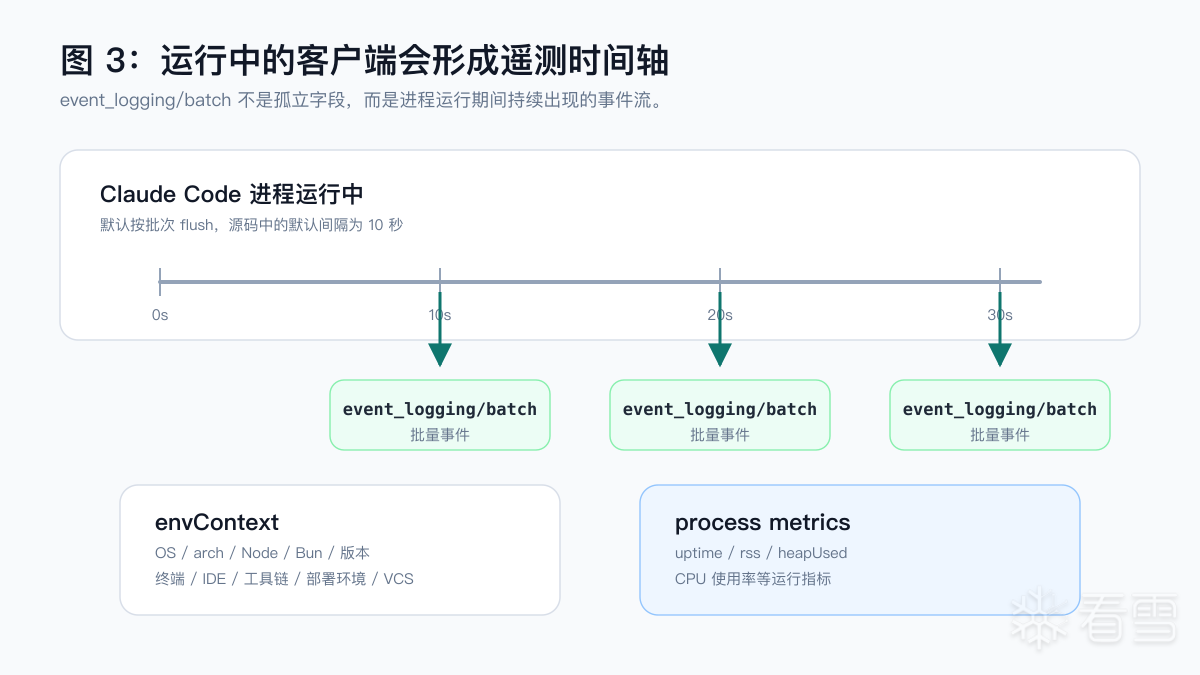 图 3:遥测事件让服务端看到一个持续运行的客户端进程。
图 3:遥测事件让服务端看到一个持续运行的客户端进程。
这里有几项尤其值得注意。
deploymentEnvironment 不只是读取环境变量。某些情况下,它还会通过文件系统特征识别运行位置,例如 Docker、云服务或特定 CI 环境。对真实开发者来说,这些信息通常只是环境描述;但如果一个账号长期表现为在云函数、容器或自动化环境中高频使用,它就会和普通本地使用产生差异。
terminal 也不只是粗略区分终端。它会识别一系列编辑器和 IDE,包括 Cursor、Windsurf、VS Code、VSCodium,以及 JetBrains 的多个产品。这类信息可以帮助服务端理解客户端运行在怎样的开发场景中。
更重要的是,遥测里还有进程指标,例如进程已运行时间、内存占用、堆内存使用量、CPU 使用率等。它们不像操作系统或 Node 版本那样是静态指纹,而更像一个正在运行的客户端进程的生命体征。
这就是单次请求和持续遥测之间的区别:请求头可以被精心还原,某些字段也可以被模拟;但一个真实进程在持续运行时自然产生的环境、时序和资源使用痕迹,更难被批量、长期、低成本地伪造。
还有一个细节是 rh。它是 git 远程仓库地址归一化后的 SHA256 前 16 位。它不暴露远程地址明文,但同一个仓库会稳定映射到同一个值。因此,服务端理论上可以用它识别“这些会话是否来自同一个仓库上下文”。
到这里,风险模型已经比较清楚了:Claude Code 的正常使用并不只是 /v1/messages。围绕推理请求,还会自然出现一组设备、进程、环境、仓库和会话上下文。
这也是为什么中转池账号的风险不能只从“单次请求是否伪装得像”来理解。
以 sub2api 这类中转网关为例,它的基本模式是:运营方维护一批 Claude 订阅账号的 OAuth token,对外发放自己的 sk-xxx;用户本地 Claude Code 把请求发到中转网关,中转网关再用池子里的某个账号 token 转发给 Anthropic。
从单次 /v1/messages 看,这类实现可以做得非常接近真实 Claude Code。它会复刻 Claude Code 的消息指纹算法,计算 x-anthropic-billing-header 里的 cc_version;也会根据抓包结果还原 cch 客户端证明;甚至连 HTTP 头大小写这种细节都可能按真实客户端格式处理。
也就是说,如果只看一条推理请求,它未必粗糙。
真正的问题在请求之外。
典型中转使用方式大致是这样的:
这个 sk-xxx 是中转服务发给用户的 key,不是 Anthropic 的 OAuth access token,也不是 Anthropic 官方 API key。池子账号真正的 OAuth token 留在中转服务器里,并没有进入用户本地的 Claude Code 进程。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-5-30 00:07
被执着的猫编辑
,原因: 编辑标题






