-
-
[推荐]7884结构归纳推理模型训练框架
-
发表于: 2026-4-25 19:55 1660
-

7884-结构归纳推理赛道 · 开创者 · 独行者 · 十年唯一坚守者
一、系统概述
7884归纳推理系统是原创性归纳推理技术体系,核心区别于传统统计拟合与交叉熵损失导向的模型,以“挖掘深层结构、归纳客观规律、自我校验严谨性”为核心目标。系统通过5维加权评分体系定义归纳推理质量标准,依托11步标准化管线实现全流程推理,搭配双层循环迭代+早停机制保障推理精度与效率,最终输出稳定、深度、可信的归纳结论。
二、核心综合评分体系
采用5维加权求和计算OVERALL综合评分,作为归纳推理结果的核心质量判定依据,各维度权重、释义及核心价值如下:
评分维度 | 权重 | 中文释义 | 核心作用 |
Coverage(覆盖度) | 25% | 对目标数据、问题场景的信息覆盖全面性,无关键信息遗漏 | 保障归纳结论的完整性,覆盖全部核心字段、逻辑与场景,是评分核心基础 |
Structure Consistency(结构一致性) | 20% | 生成的结构、层级、格式的稳定性与自洽性,无逻辑矛盾 | 确保归纳推理结构统一、可复用,避免碎片化、矛盾化结论,保障结构严谨性 |
Refutation Confidence(自反驳置信度) | 20% | 系统自我质疑、校验、推翻错误结论的能力与可信度 | 原创核心维度,主动过滤逻辑谬误、无效推理,从源头提升结论可信度与严谨性 |
Cross Validation(交叉验证) | 20% | 多维度、多视角、多分支推理结果的相互验证,排除偶然误差 | 验证推理逻辑的普适性,避免过拟合,保障结论的稳定性与通用性 |
Relation Saturation(关系饱和度) | 15% | 实体、字段、数据间深层关联的挖掘充分度,覆盖表层至嵌套关系 | 凸显归纳推理的深度价值,区别于表层关联匹配,挖掘隐藏逻辑规律 |
评分公式
OVERALL = Coverage×0.25 + Structure Consistency×0.20 + Refutation Confidence×0.20 + Cross Validation×0.20 + Relation Saturation×0.15
三、全流程执行管线(11步标准化流程)
系统采用阶梯式、不可逆的标准化管线,覆盖从引擎初始化到最终结论输出的全链路归纳推理,各阶段核心逻辑如下:
执行阶段 | 流程名称 | 核心执行内容 |
0 | ML Engine Init | 引擎初始化,加载配置、环境、底层模型,完成系统启动就绪 |
1.1 | SSL Pretraining | 自监督预训练,基于无标注数据构建基础推理能力,打牢底层逻辑 |
1.5 | History Consultation | 历史信息调取,参考历史推理数据、结论,为当前流程提供参考 |
2 | Clustering | 数据聚类,对目标数据分类聚合,梳理基础分类逻辑 |
3 | Field Pattern Analysis | 字段模式分析,解析数据字段特征、格式与内在规律 |
4 | ML Field Type Prediction | 字段类型预测,精准判定数据字段属性与类型 |
5 | Relation Discovery | 基础关系发现,挖掘数据、字段、实体间的基础关联逻辑 |
6 | Deep Nested Structure Search | 深度嵌套结构搜索,挖掘深层、多层级嵌套结构与逻辑关系 |
7 | Cross-Validation | 交叉验证,多维度校验前期挖掘结果,排除偶然误差 |
8 | Self-Refutation | 自反驳校验,系统主动质疑、推翻错误推理,过滤无效结论 |
9 | Relation Induction Engine | 关系归纳整合,整合验证通过的关联,生成核心逻辑归纳结论 |
10 | Candidate Generation + Ensemble Fusion | 候选结论生成+集成融合,生成多套候选方案并完成优化融合 |
11 | Sorting & Finalization | 排序与定稿,依据OVERALL评分对候选排序,输出最终最优结论 |
四、双层循环迭代机制(核心训练逻辑)
系统采用大循环+小循环双层迭代,精准打磨推理细节、优化整体逻辑,同时配套早停机制避免无效迭代,提升效率:
1. 小循环(子模块训练)
•迭代次数:65536次/步
•核心目标:聚焦单一步骤、单一逻辑的精细化打磨,修正细节误差、完善局部结构与关系挖掘,确保每一步推理的精度与质量。
•执行场景:在11步管线的每一个独立步骤(如聚类、关系发现、自反驳)中,重复执行65536次训练,优化该步骤的模型参数、逻辑规则与挖掘精度。
2. 大循环(全流程迭代)
•迭代次数:64次
•核心目标:完成11步管线全流程闭环后,回溯核心推理环节,基于上一轮OVERALL评分结果,整体优化全链路逻辑、结构与关联,打磨全局归纳结论的深度与可信度。
•执行逻辑:每完成1次大循环,系统会整合小循环的训练成果,对管线各步骤的输出进行全局校验与优化,逐步逼近最优推理结果。
3. 早停机制(终止条件)
•触发阈值:连续8个大循环无显著效果提升
•核心逻辑:当连续8次大循环结束后,OVERALL综合评分的提升幅度低于预设阈值(或无实质提升),系统自动触发早停,终止迭代训练。
•价值:避免无效迭代消耗计算资源,同时防止过度迭代导致过拟合,平衡推理精度与效率,保障系统高效运行。
五、系统独创性与核心优势
1.原创评分体系,颠覆传统拟合评价
摒弃交叉熵损失、MSE等传统统计拟合评价标准,打造专属归纳推理的5维评分体系,聚焦“结构、关系、严谨性”而非单纯数值拟合,精准衡量归纳推理质量。
2.自反驳核心创新,行业独有校验逻辑
将“自反驳置信度”纳入核心评分与流程,强制系统主动自我质疑、纠错,从被动输出转向主动校验,大幅提升归纳结论的可信度与严谨性,为行业首创。
3.全链路闭环管线,深度归纳推理落地
11步标准化管线+双层循环迭代+早停机制,构成完整的归纳推理闭环,从预训练、关系挖掘到自我校验、融合输出,全程聚焦深层逻辑归纳,区别于传统模型的浅层模式匹配。
4.迭代机制高效适配,兼顾精度与效率
小循环打磨细节、大循环优化全局,搭配早停机制精准终止无效迭代,既保障了推理的深度与精度,又提升了系统运行效率,适配工业化落地需求。
六、IFFA先验介绍
iffa先验是利用IFFA大蒜的输出信息,理论上做到加速加分。
IFFA先验知识介绍
如果需要先验知识,需要存一对文件(一个要分析的样本和对于的XML脚本(脚本由IFFA大蒜生成). 有了先验知识,可以有效提高训练时间和训练成绩。
(记不住参数,可以用python生成参数)
使用先验知识测试:
B:\7884\code\x64\Release>7884_brain.exe --input B:/7884/code/samples
--output B:\7884\code\output --iffa-path B:/7884/code/IFFA
使用先验知识:2分钟 训练9轮 得分31.63%
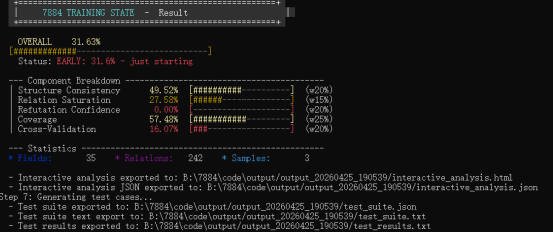
不用先验知识: 4分钟 训练9轮 得分31.59%
7884_brain.exe --input B:/7884/code/samples --output B:\7884\code\output
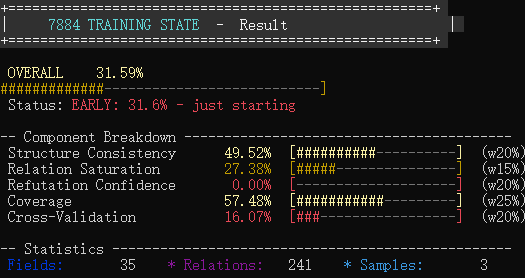
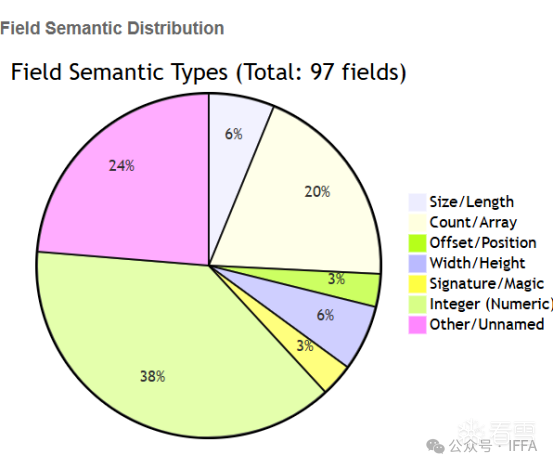
七、部分输出结构

八、反哺AI
当所有 AI 还在生成、拟合、模仿,我们早已向下扎根,向上定义。不做跟风的应用,只做支撑未来的底层骨架。真正的核心,从不是使用智能,而是孕育智能、强化智能、定义智能的边界。
社会主流 AI 代码辅助工具全品类覆盖 支持
- IDE 原生插件
GitHub Copilot、Amazon Q Developer、Tabnine、通义灵码、文心快码、JetBrains AI Assistant、腾讯云代码助手
- 独立编辑器形态
Cursor、Windsurf、Continue、Codeium
- 开源本地模型
CodeLlama、Magicoder、LLM4Decompile
- 厂商 / 云厂商体系
字节 Trae、Sourcegraph Cody、Google Gemini Code Assist、BinaryA
九、下载地址
1e5K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6h3q4K6L8e0j5@1i4K6u0W2j5$3!0E0i4K6u0r3y4K6R3^5y4q4)9J5k6h3S2@1L8h3H3`.
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
赞赏
|
|
|---|---|
|
|
|




