-
-
[推荐]700K参数-未知文件子结构识别模型
-
发表于:
2026-3-21 19:15
3679
-
当下业界多在追逐更大的模型、更多的参数、更强的算力。
但我们始终相信:真正的技术实力,不在于做得多大,而在于做得极致。
今天,我们带来一款真正意义上的微模型:大辣椒V2.
免费使用,下载地址:5b6K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6h3q4K6L8e0j5@1i4K6u0W2j5$3!0E0i4K6u0r3j5$3S2A6L8r3W2Q4x3V1k6A6L8X3c8W2P5q4)9J5k6h3S2@1L8h3H3`.
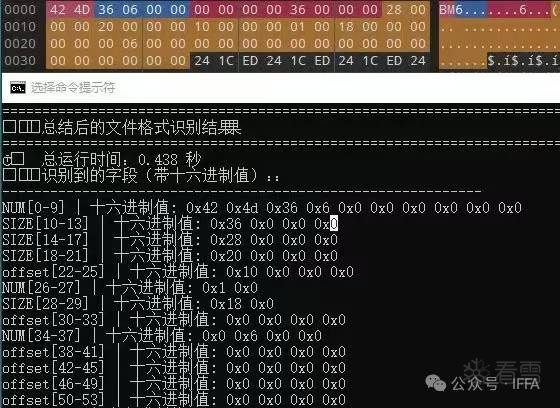
(注:图片为V1版本图片,和V2有细微区别)
参数量仅 700K,INT4量化后不到200KB。不足业内同赛道产品的万分之一。纯 CPU 即可毫秒级运行。256字节的未知文件格式结构,识别率高达88.77%。
很多人会问:这么小,真的能用吗?
因为它不是简单压缩,不是盲目剪枝,而是在极致精简的结构上,做到了最平衡的取舍。
他的背后是:
• 三百万级规模样本训练
• 20 轮完整迭代与严格测试
• 几百亿 Token 深度精调
• 无数次结构优化、冗余剔除、效率压榨
我们把所有不必要的全部去掉,
只保留最核心、最高效、最稳定的表达。
大就是小.小就是大.
就像数学考试,同样的分数,用0张草稿纸的和用100张草稿纸的,是一个级别的吗?
轻到可以嵌入任何工具,
快到可以毫秒级响应,
稳到可以支撑实际场景,
小到颠覆你对模型体积的认知。
只需读取文件前 256 字节,
即可完成结构化解析:
MAGIC、SIZE、OFFSET、STR、NUM、DATA、校验……
在人人都追求更大、更强、更重的时代,
我们选择走向另一个方向:
更小,更精,更快,更稳。
这,就是我们微模型。
—— 大蒜 & 大辣椒 · 7884数学工作室 · c43K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6h3q4K6L8e0j5@1i4K6u0W2j5$3!0E0
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!







