前言
置身于 2026 年的计算机行业,不管是哪个方向,都不可避免地要主动拥抱 ai 带给整个行业的变化。最初我自己在尝试接触如何将 ai 应用到实际的工作流程中时,被铺面而来的新概念英文词,比如 llm、prompt 等汇绕得手足无措,但实际去了解过后才发现,作为 ai 原住民的我们,往往已经习惯的操作就是这些概念的学术表达,理解起来非常容易,并不是一个高深莫测的领域。故有此总结性质的文章。
这篇文章并不会从人工智能专业的角度出发,深入了解许多专业的概念,而是作为安全方向的学习者角度,在解决我实际的工程性问题时,常用到的 ai 概念以及操作到底是什么,打通底层逻辑。如有不全与理解误差,欢迎积极交流纠正,不胜感激。
LLM 全称Large Language Model,大语言模型,简称大模型或模型。我们平时刷到的 “xx 公司推出新模型”,在网页端与 ai 进行对话时进行模型的选择,以及使用 ai 编程软件中选择的模型,全部都是在聊 LLM 这个概念。
先用最好理解的方式讲讲大模型的工作原理是什么样的。我们日常在 ai 窗口与他进行对话时,可以注意到他常常是一段一段文字形式输出的答案,很像我们打字输出文本的状态。但 ai 的思考方式与我们的大脑是截然不同的,ai 回答的本质是一个“文字接龙”游戏,他的答案是基于“最初的问题”+“输出答案”来进行下一个词的预测,以此类推输出一段完整的回复。具体的例子可以观看参考视频的讲解从 LLM 到 Agent Skill,一期视频带你打通底层逻辑!
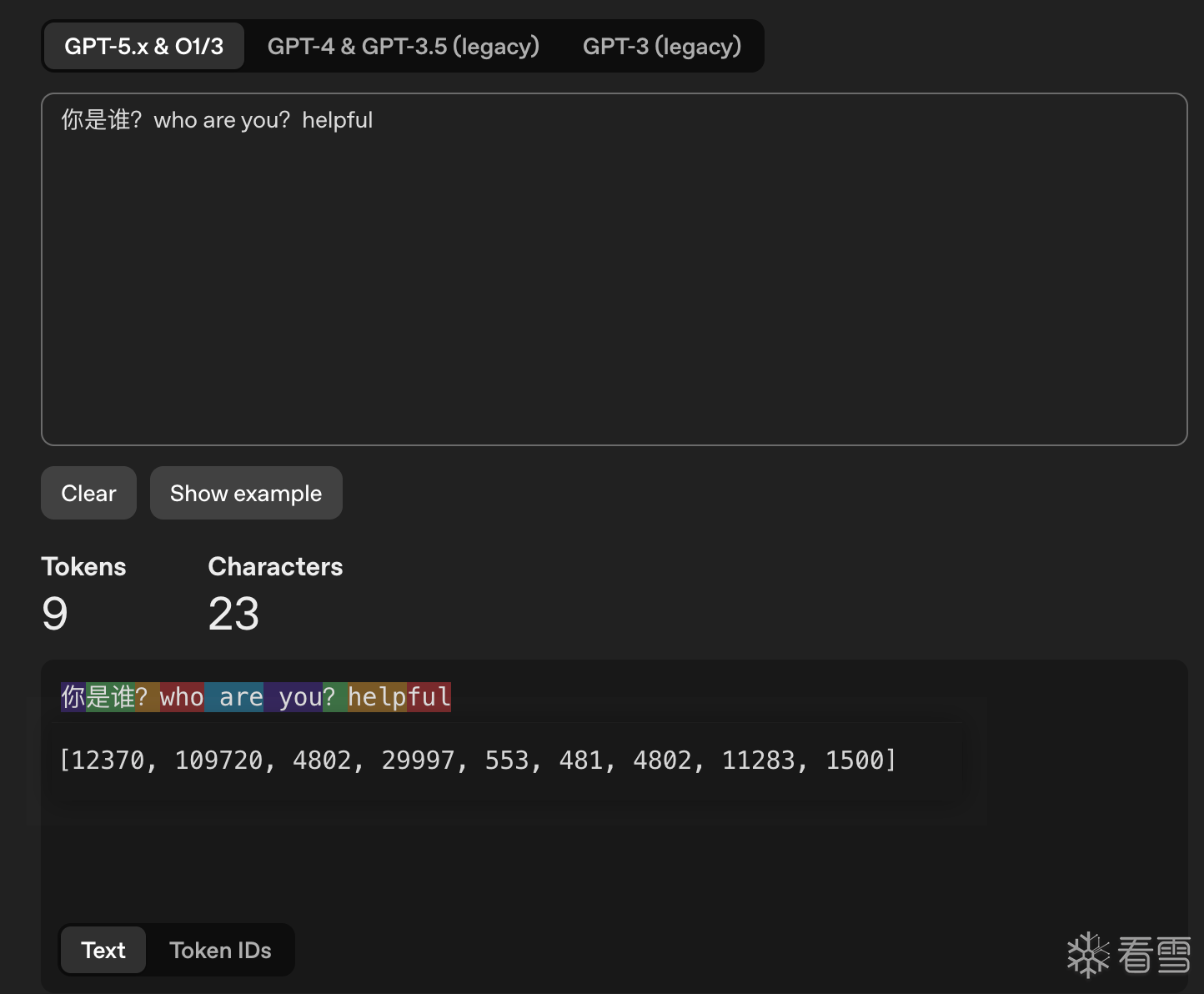
衔接刚才对大模型回答方式的案例,当我们提问“你是谁?”的时候,ai 作出回答“我是人工智能”。对于他的回答方式我们大概了解了他是一段一段输出的答案。那么这个提到的一段一段就是这里要介绍的概念“token”。
token 是 LLM 中最小的处理单位,但 1 token 并不是一个英文字母,也不是一个中文汉字,而是按照特定的规则,将这些可能出现的词对应为具体的数字。
我们在对大模型进行提问时,首先会通过使用Tokenizer分词器的组件,将一段话分为碎片化的 token。比如刚才提到的“你是谁?” 我们在 openai 官网的Tokenizer 换算网站中就可以查看这些词他对应的 token 是什么。Tokenizer
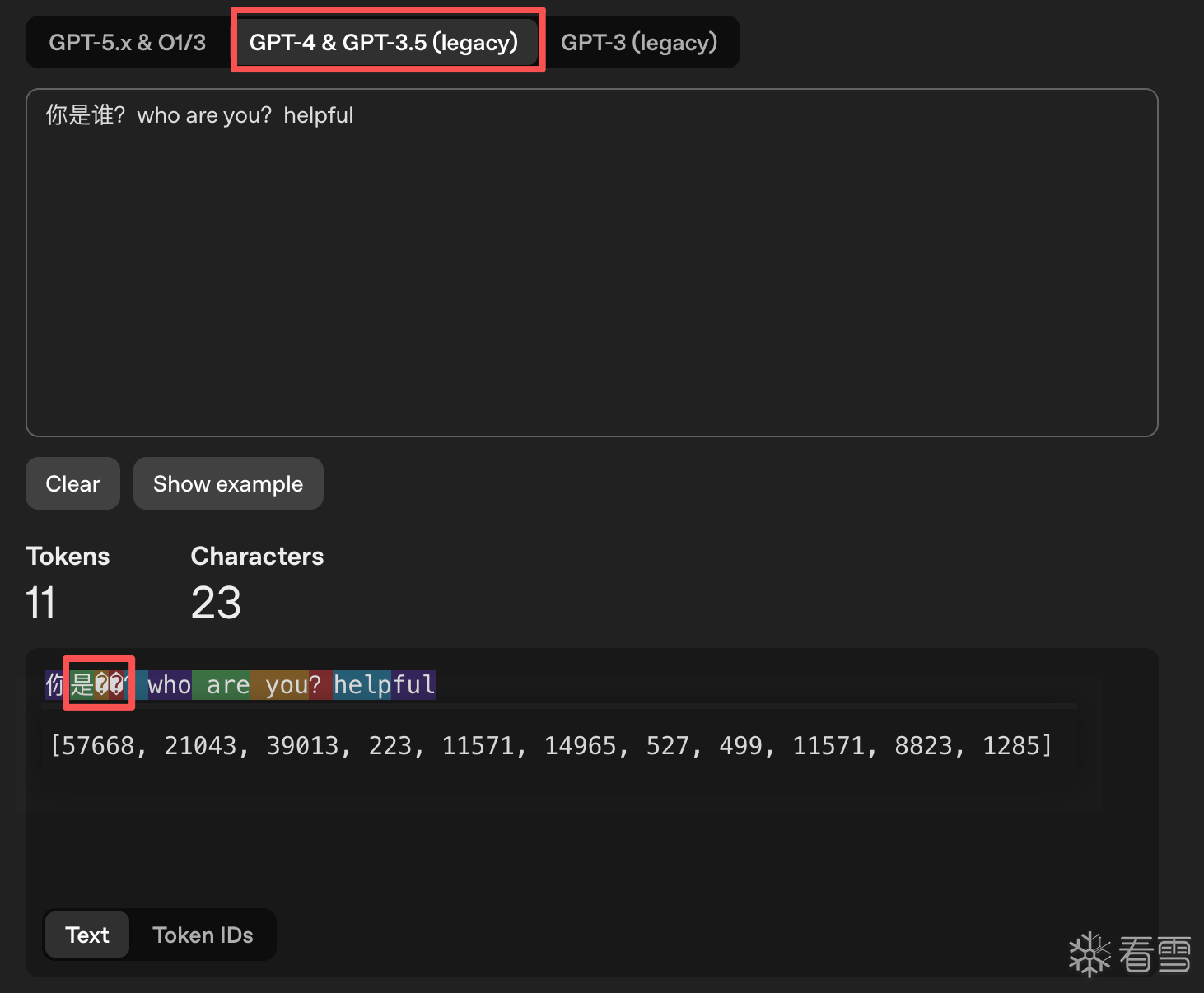
可以看到分词器并没有把一个汉字或者一个单词作为 1 token,上面的图片中,我们可以看到两个汉字对应 1 token,以及一个英文单词helpful对应 2 token 的情况出现。除此之外,不同模型的 token 也是不同的,他们往往对应一套不同的规则,就算是同一家的模型迭代,可以看到“是谁”从 4 代的 3 token 优化为了 1 token。往往随着模型的升级,对 token 的理解能力也有进一步的增强与节约。
最近一段时间,token 也是正式被官方命名为“词元”,可以说在人工智能领域,不亚于计算机中“字节”概念的基本单元概念了。我们常听到“我使用的模型又消耗了多少 token”,每次提到 token 就和消耗离不开关系,几乎所有 API 都按 token 算钱,输入 token 和输出 token 单价还不一样。你贴一个 10 万行的反编译结果进去,可能就是几美金出去了。
衔接刚才提到的 token 概念,我们在对大模型提问的过程中,为什么我们前几轮提示他的内容,在后续的提问中他还是能记住呢?这就是 context 在发力。中文翻译“上下文”很容易理解他的作用,就是为了让只有短期记忆的大模型可以知道前面的内容在聊什么,方便后续的沟通进一步回答。
但是 context 并不是一个无限制的上下文,每个模型都有自己的“上下文窗口”Context Window,单位是 token。超过这个数,要么报错、要么被静默截断、要么触发某种压缩机制。对话越久,上下文越长,越贵、越慢、越容易"忘事"。
除了提到的对话历史, context 的内容主要还有用户问题、当前输出、工具列表和 System prompt 等概念。
prompt 并没有非常高深难理解,Prompt 就是你给 LLM 的输入指令。最常见的提示词就是你对 ai 的提问。直观理解,提示词越精致、越详细,输出答案也就一定更精准优质。之前还有像"提示词工程(Prompt Engineering)"这个方向,本质上就是学会怎么把话给 ai 讲清楚。
对 prompt 的具体分类大致如下:user prompt(用户提示词)、system prompt(系统提示词)。前者就是我们对 ai 的每一轮提问,后者就是提前在系统中给 ai 设定的身份,比如“你是一位资深的安卓逆向工程师,你熟悉···”等等,我们往往可以套用一些优质的提示词,来提高输出的质量,下面两个网站就收录了一些优质的提示词。
1e1K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3M7X3!0E0M7s2b7I4x3U0y4Q4x3X3g2U0L8W2)9J5c8R3`.`. 88fK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2S2K9i4y4Z5L8%4u0@1i4K6u0W2N6r3!0H3
此外在提示词方面,如果你提前告诉了大模型几个 "输入-输出" 示例,他们的答案就会输出相似的内容,这个叫Few-shot;相对没有这样的示例叫做Zero-shot。让模型"一步一步想"。加一句"请先分析步骤,再给出结论",复杂推理准确率会明显提升,这个叫做Chain-of-Thought(CoT,思维链)
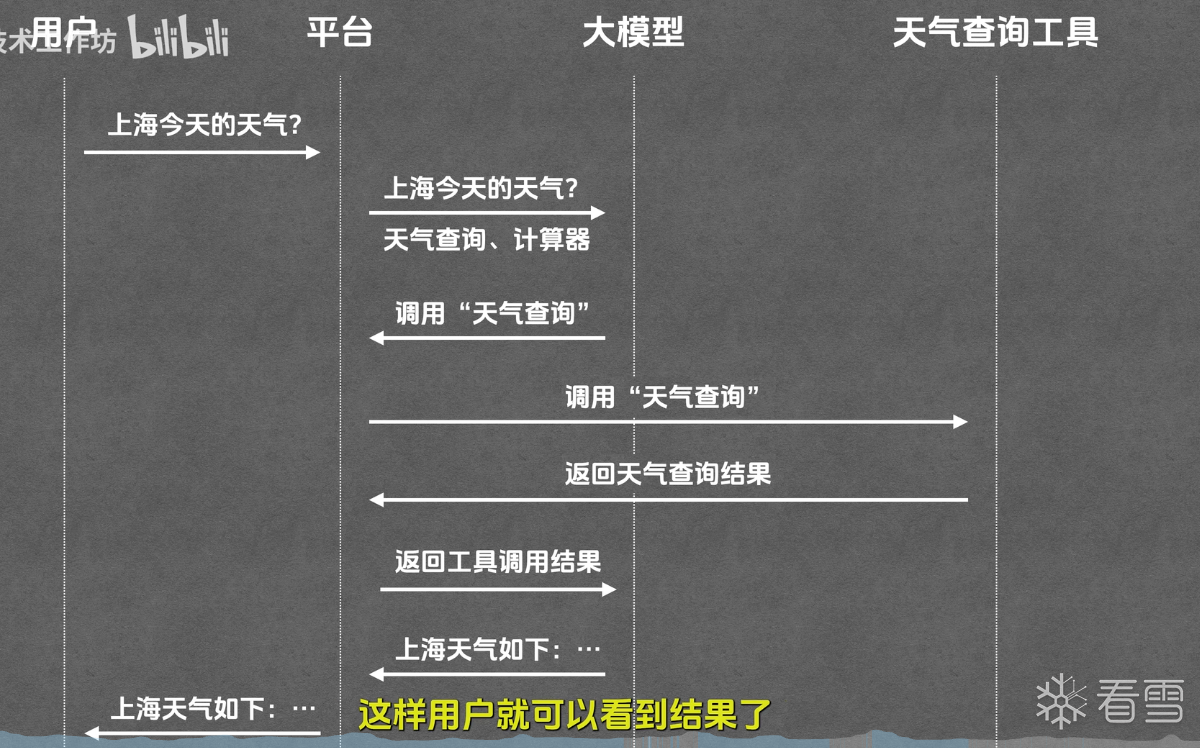
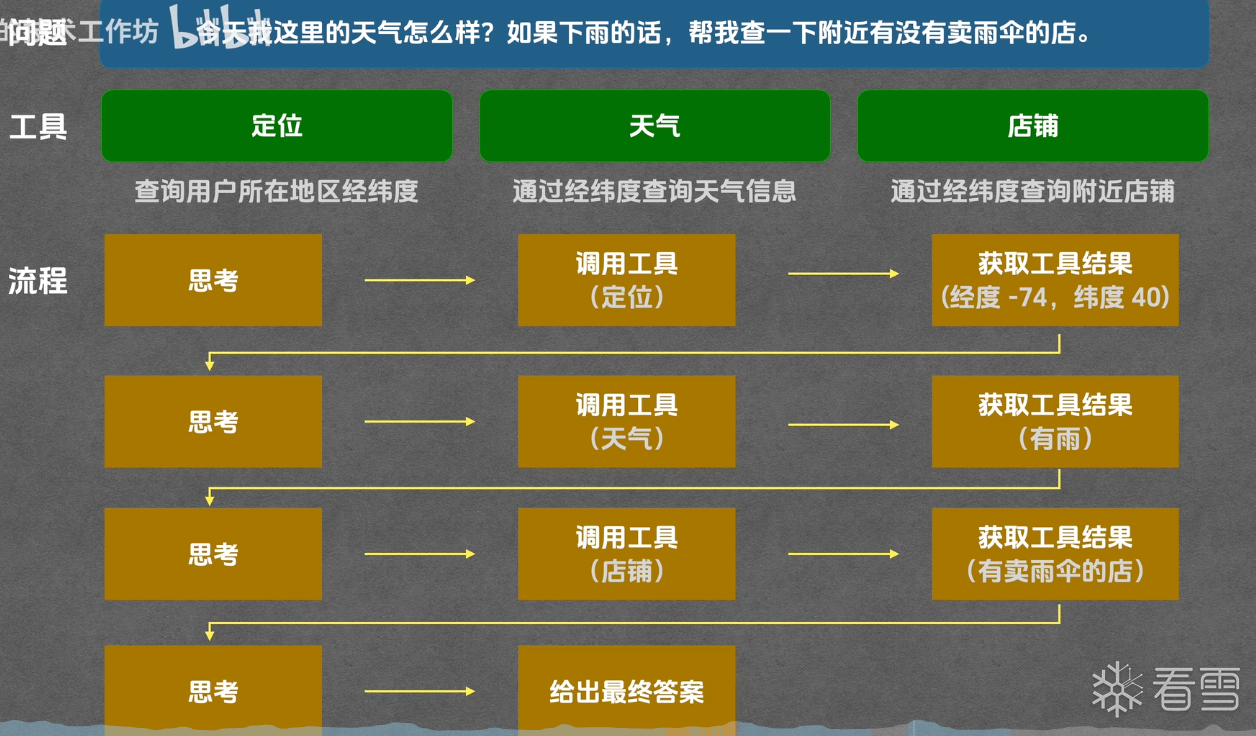
思考这样的场景,我们像 ai 提问,今天上海的天气是什么样的。基于推测回答问题的大模型,他的知识库只局限于训练时的某个固定时间点,并不能做这样事实的回答。Tool(工具)就是给 LLM 装上的"手脚",让它能主动调用外部能力。
技术上这个机制通常叫 Function Calling 或 Tool Use:你提前告诉 LLM "我这里有这些工具、每个工具需要什么参数",LLM 在回答时如果判断需要用某个工具,就输出一个结构化的"工具调用请求",由外部程序执行并把结果返回给它,然后它基于结果继续回答。
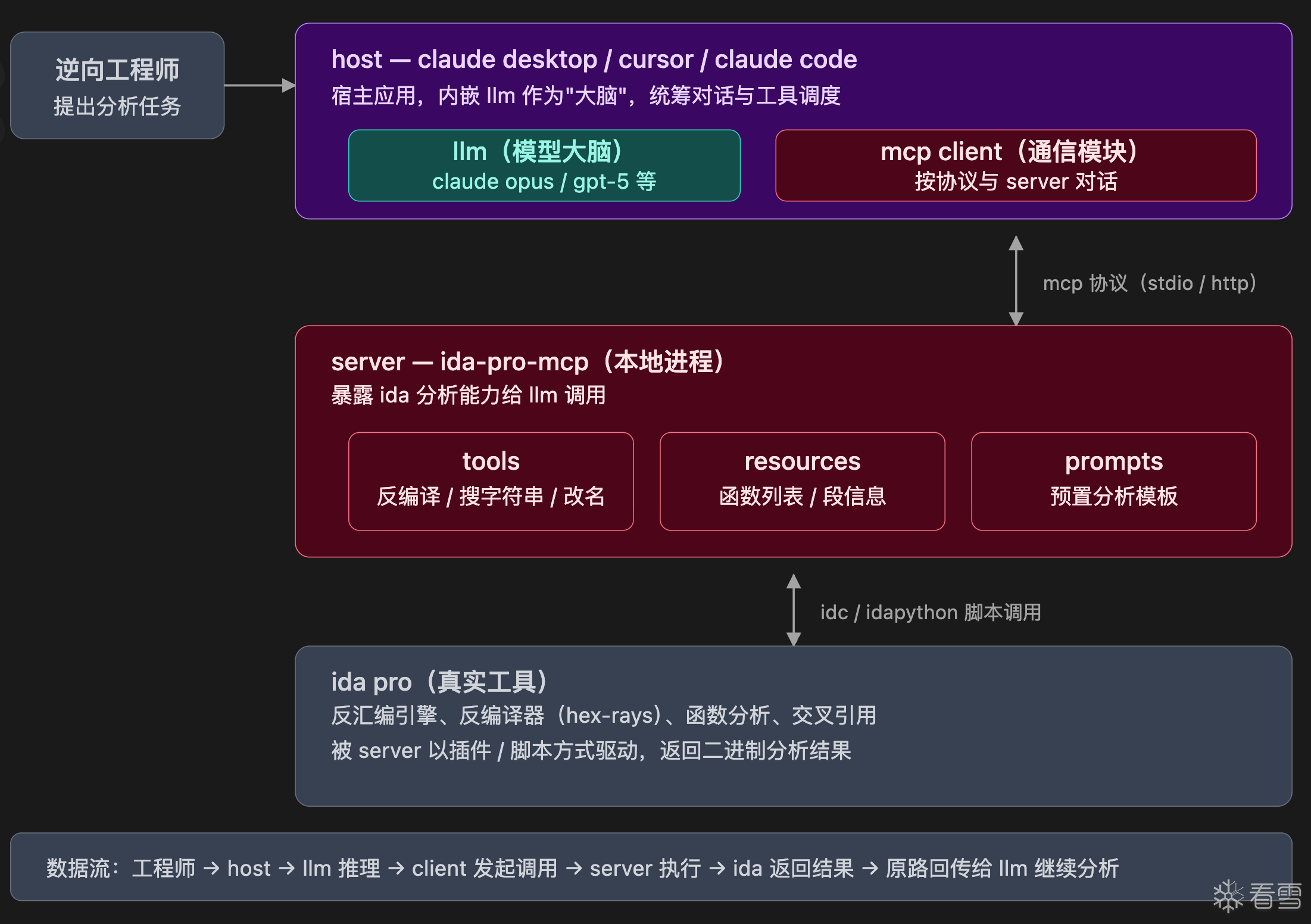
2024 年 Anthropic 推出的 Model Context Protocol(MCP) 在这两年已经成了事实标准。你可以把它理解成 LLM 领域的 USB-C:不管什么工具、什么模型,大家都按同一套协议对接,就不用每个模型每个工具都重新写一遍适配。
在逆向工程方向,常用的 mcp 就是 ida-pro-mcp 以及 jadx-mcp 这样的反编译工具的 mcp,结合我们本地的 agent 可以很好的做到逆向分析工作。
MCP 的主要结构有:Host、Client、Server
你真正在用的那个应用程序,比如 Claude Desktop、Cursor、Claude Code、VS Code 的某个 AI 插件。Host 是用户直接打交道的界面,负责 orchestrate 整个流程。
Host 内部负责与 MCP Server 通信的组件。一个 Host 可以同时连接多个 Server,每个连接对应一个 Client 实例。用户一般意识不到 Client 的存在,它是 Host 里的"通信模块"。
真正暴露能力的一方——提供工具、数据、提示词模板。MCP Server 可以跑在你本地(比如一个读本地文件系统的 Server),也可以跑在远程(比如 GitHub 官方提供的 MCP Server)。
如果想对 mcp 有切实的了解,自己去找一下自己常用的工具中有没有开源的 mcp 协议,亲身体验一下让大模型接手你的工作,会对 mcp 协议有更深的了解。
如果说 LLM 是"大脑",Tool 是"手脚",那 Agent 就是装上了大脑和手脚之后、还会自己规划和反思的一个完整体。核心差异在那个 Loop(循环):普通的 LLM 是"一问一答",Agent 是"规划 → 执行 → 观察结果 → 反思 → 再规划 → 再执行……",直到完成任务或判断无法完成。学术上常把这个循环叫 ReAct(Reasoning + Acting) 模式:推理一步、行动一步、看结果再推理下一步。
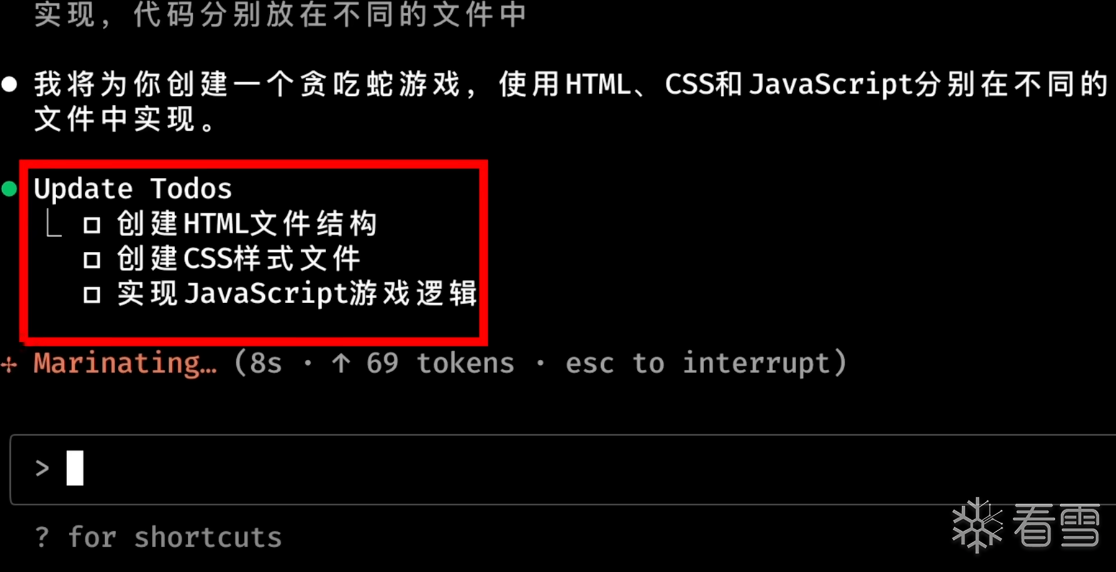
目前最常用的 agent 工具就是 Claude Code(cc)、Codex、Gemini CLI 等。除了刚才提到的ReAct构建模式,另一种构建模式叫做Plan-And-Execute先规划再运行模式。例如我们在使用 Claude Code 时就常常能看到这样的运行模式。
而在 agent 中还有许多其他比如 skills、memory 这些核心概念,这里就只做一些概念性的描述,后续有时间再可以结合 claude code 的源码,对 agent 中的机制进行详细分析。
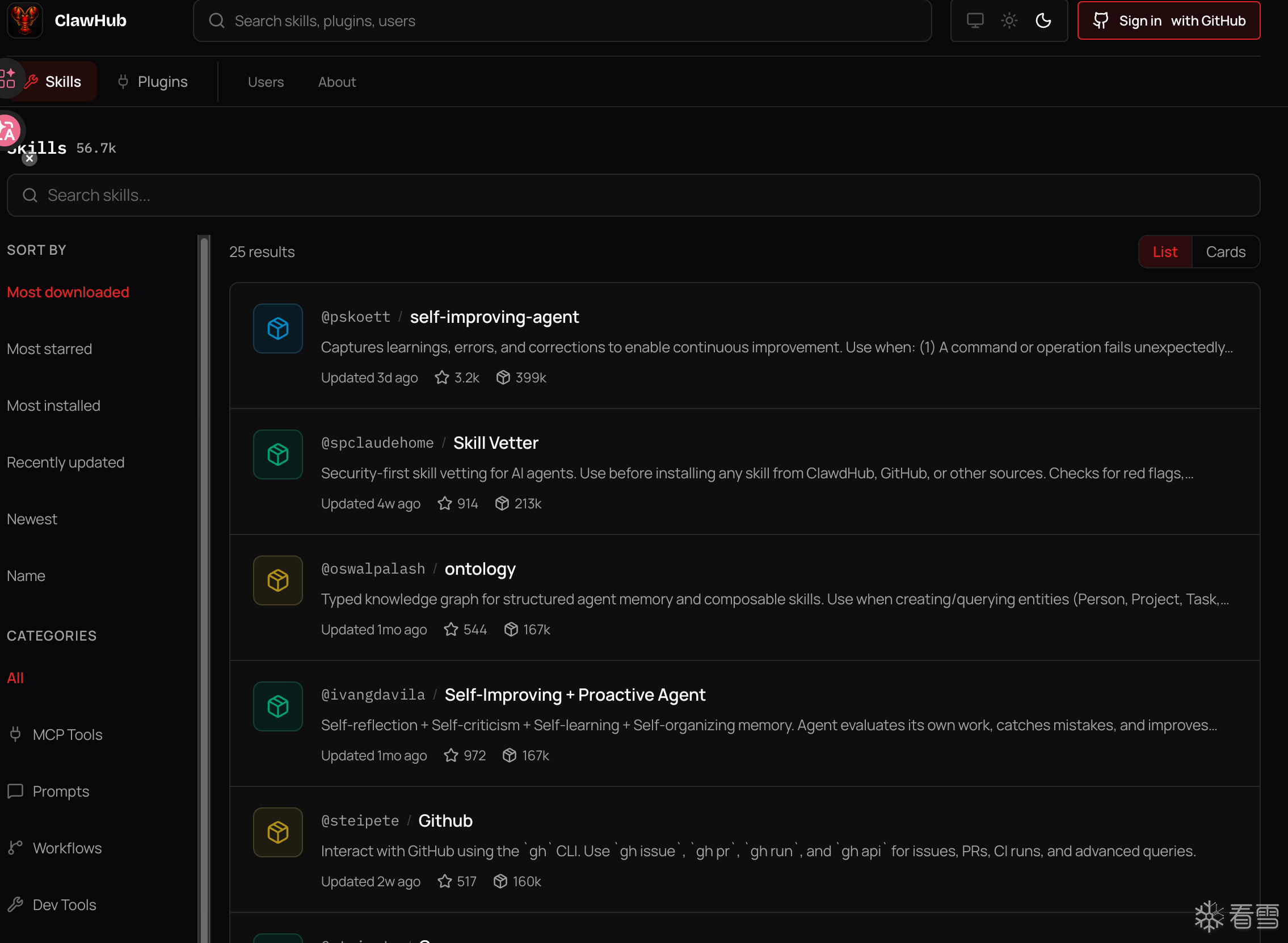
skills 就如他的含义一样,代表技能和能力,是给 agent 点技能点的一个功能选项。Skills 是 Anthropic 在 2025 年推出的一个概念,现在已经被广泛采纳。它的核心思路是:把一项专门技能封装成一个可复用的模块,Agent 需要的时候动态加载。
一个 Skill 通常是一个文件夹,里面包含:
当 Agent 判断当前任务匹配某个 Skill 时,它会读这个 Skill 的说明文档,获取相应的指令和资源,然后按照里面的最佳实践去完成任务。23bK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6U0L8r3q4%4K9s2g2T1i4K6u0W2j5h3W2Q4x3V1k6K6K9$3W2D9L8s2y4Q4x3@1k6K6L8%4u0@1i4K6y4p5k6r3!0%4L8X3I4G2j5h3c8K6
在我前段时间使用 openclaw 的时候,我自己也会在上面这个网站上去下载一些提升小龙虾能力的 Skills 文件。
比如我们下载一个天气的 Skills,本质上就是一个放在 skills 目录下的 md 文件,他有一定的格式规范
记忆实际上和我们前面提到的 context 上下文的概念高度绑定,在 agent 中一般分为长期记忆和短期记忆。短期记忆在上下文能接受的前提下,就可以实现记忆上文的功能,会话一结束就没了。它已经"天然存在",不需要额外设计。长期记忆则是跨会话持久化的记忆,存储在上下文之外——比如数据库、向量库、本地文件。每次需要时再"捞"相关片段进上下文。这是 Memory 系统真正要解决的问题。
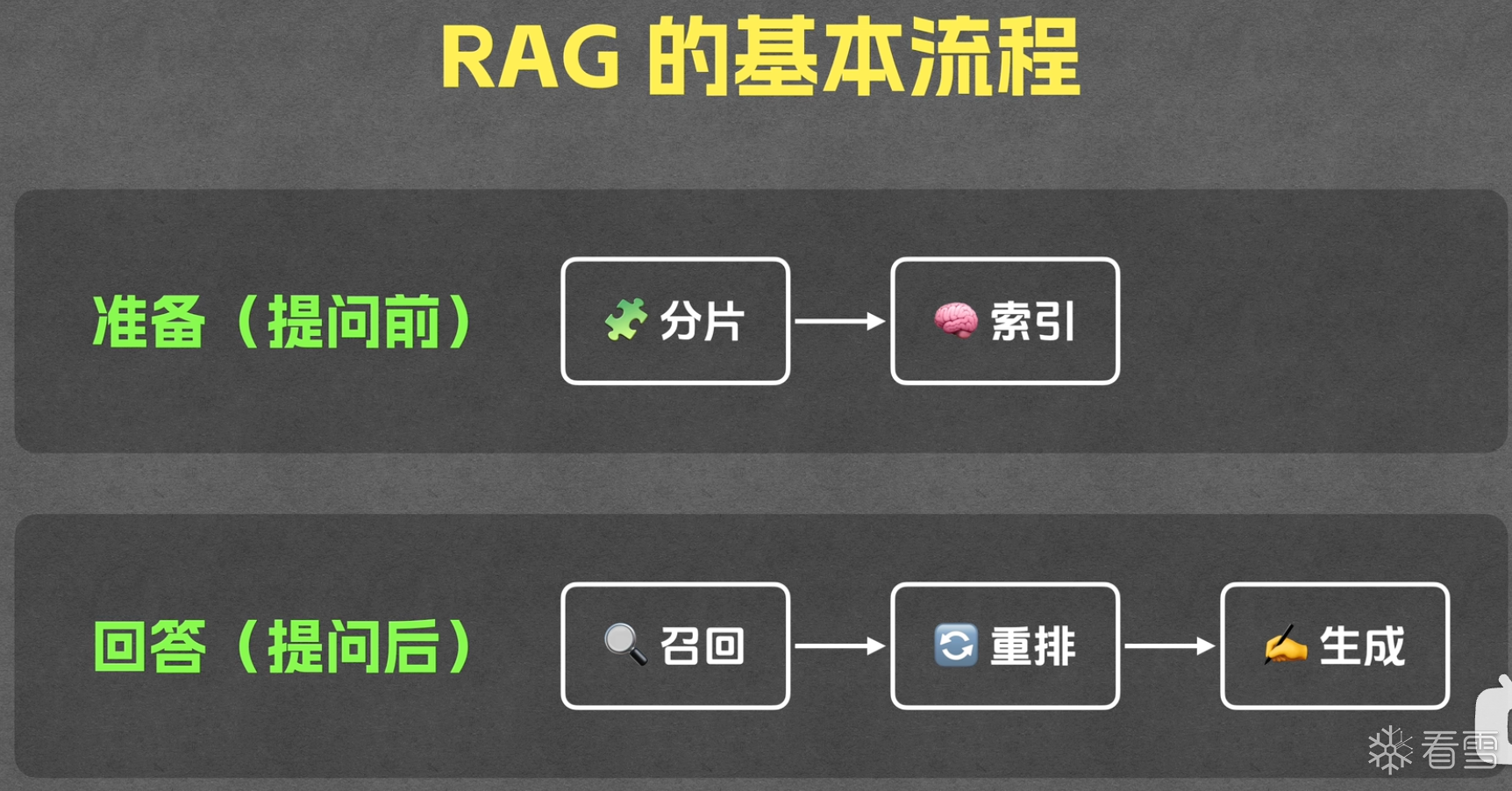
可以先简单介绍一下比较常见的 RAG,过多的内容可能会再出一篇文章详细探讨。
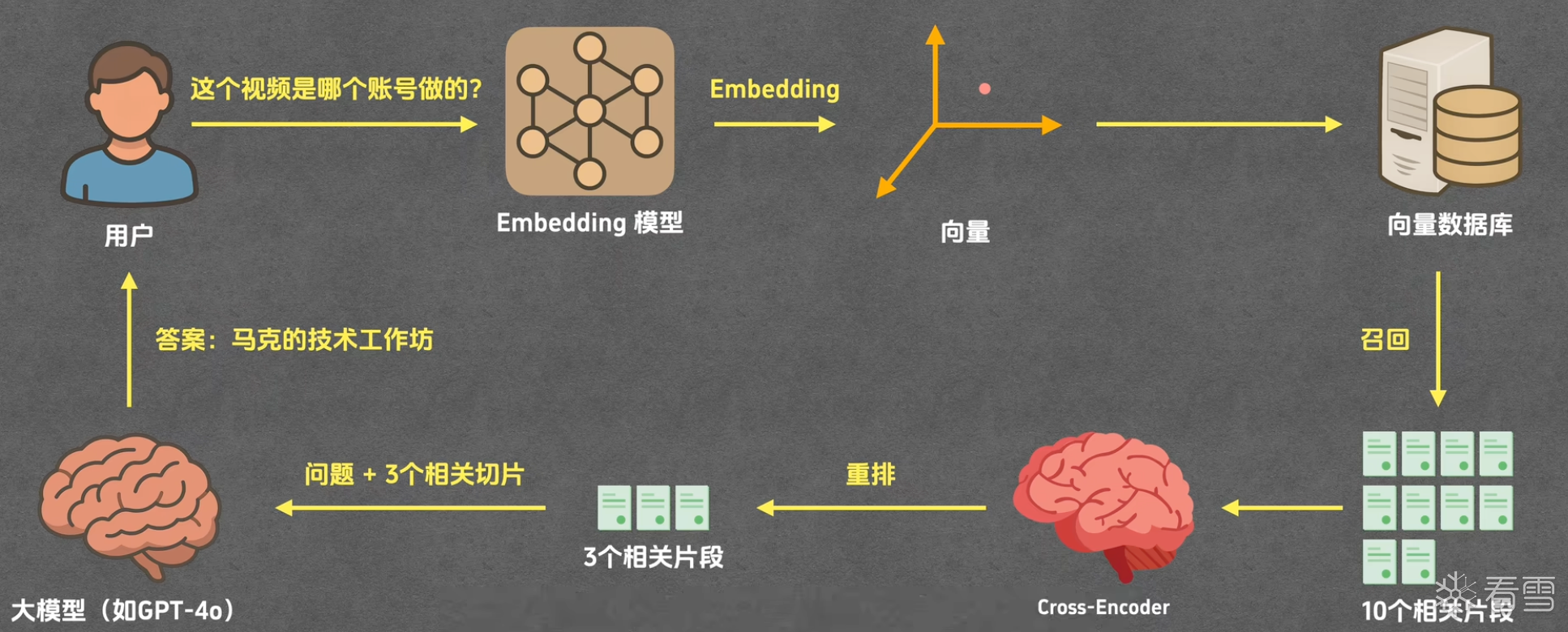
RAG(Retrieval-Augmented Generation)检索增强生成。这个有些像我们前文提到的 tool 章节时,怎么在训练截止日期之后、有限上下文的大模型面前,去提问一个比较新的问题。RAG 就是这样一个解决方式,类比成一个“外挂知识库”。具体的演示流程可以看这个视频RAG
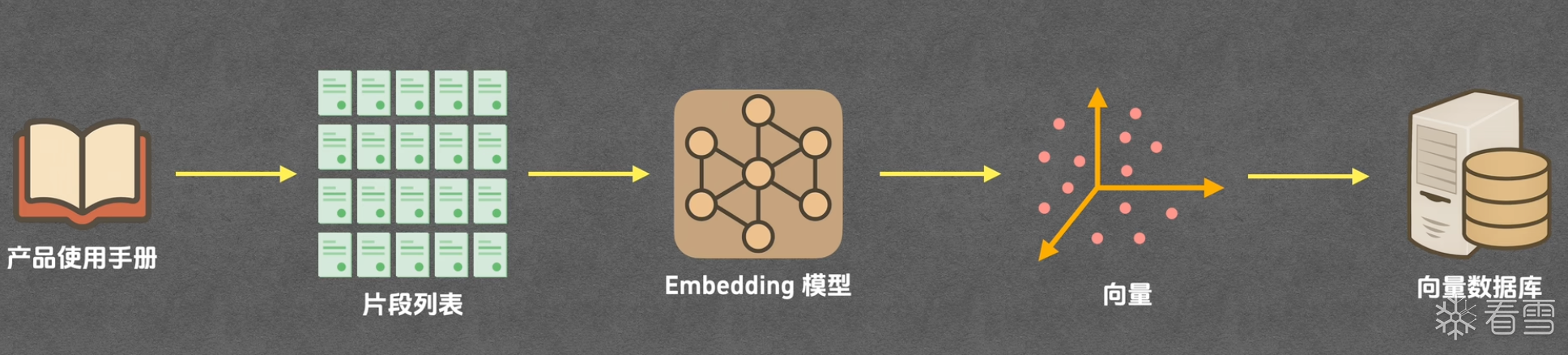
RAG 的构建一般分为两个流程:离线建索引(提问前)-在线查询(提问后)
这步做完,你就有了一个"能按语义查询"的知识库。
用户每次提问时:
上下文总归是有限的,为了能在有限的上下文中取得更好的效果,类似于千问提到的“提示词工程”的概念出现了。之前有看过 Cursor 的 Composer 模型是怎么优化上下文的文章,做了类似当上下文即将满时,就进行一个记忆的总结,保留会话(session)。具体的内容大家有了解的可以一起讨论。
Multi-agents就是多个 agent 一起协作完成一件事,适用于构建一个体系化的流程,是一个较为广义的概念。比如在安卓逆向中,我们希望完成下面的一个完整的流程,我们就可以通过使用多个 agent 去分别专项地完成不同的任务。
但是对这部分的内容还只是了解大致概念的阶段,后续如果有机会接触更多实战,也希望能深入了解这一体系。(如果大家对这部分内容有一定的见解,欢迎评论交流)
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-4-19 20:48
被xianyuuuan编辑
,原因: