DodgeBox | ThreatLabz
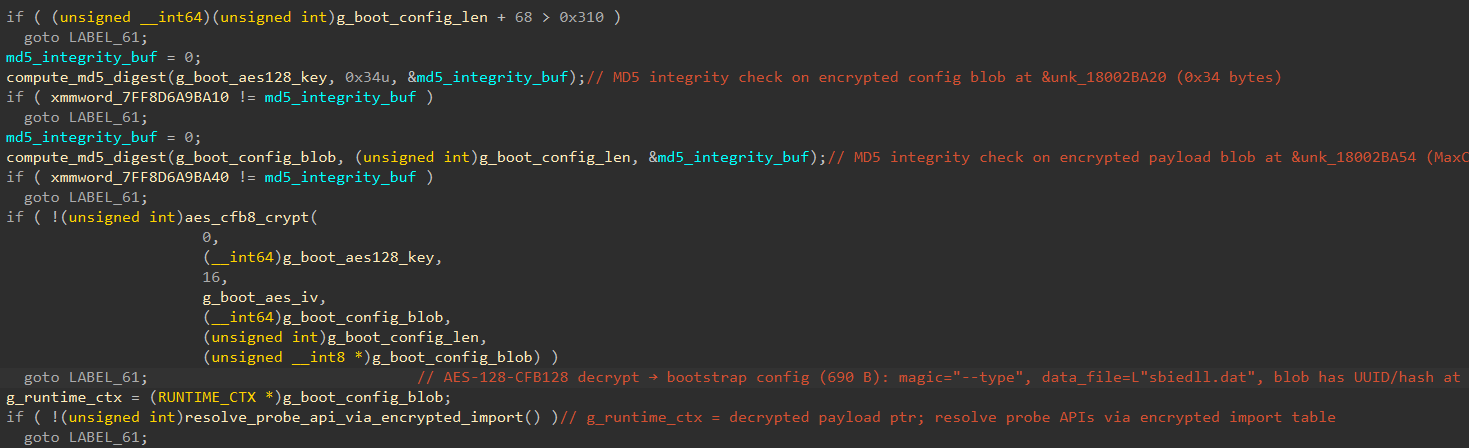
在bootstrap_runtime_and_scan_modules函数中,首先使用MD5算法对其config blob和payload 进行校验。MD5应该是加载器生成器在二进制中预置的。接下来,以config头16Bytes为IV,以一个内置key对整个payload blob进行流式解密。
然后进行了一次参数验证。其首先通过AES-CFB算法对内置数据进行解密,获取一个模块名称msvcrt.dll和函数名称__getmainargs,并分别用loadlibraryw和getprocessaddr进行加载,然后运行获得当前进程的命令行参数,然后检查命令行参数中是否包含--type字符串,并对其之后的字符串进行MD5检查。根据分析,其所验证的参数为--type driver。
接下来样本通过一个自定义的函数位置解析器init_hashed_api_dispatch_table从给定的系统dll中查找特定的导出函数地址。特别之处在于这里使用了FNV-1a哈希算法。FNV-1a(Fowler-Noll-Vo)是一种非加密型哈希算法,以其极高的计算速度和极低的碰撞率而闻名。它非常适合处理字符串、文件名、IP 地址等短数据的哈希化。这个也是常规流程了,能够以不错的效果规避一些静态扫描。不过现在一些安全方案里面不仅会存储这些常见的api名称,还可能存储一些常见的api的哈希。这里使用的相对小众的算法可能能够规避。
样本需要首先获取需要脱钩的模块。遍历PEBInMemoryOrderModuleList,对于每个模块,读取LDR_DATA_TABLE_ENTRY中的Flags字段。检查 Flags & 0x60000000 是否为 0x20000000。如果是,表示该模块已被此 Loader 处理过,直接跳过。读取模块 PE 头的 Characteristics。必须包含 IMAGE_FILE_DLL (0x2000),即只处理 DLL,不处理 EXE。接下来解析 FullDllName,提取其父目录名。只有父目录名为 system32 的模块(如 ntdll.dll, kernel32.dll, user32.dll)才进入后续模块脱钩。
样本通过pNtReadFile函数从System32目录下读取 被标记为需要处理的DLL,然后进行内存映射和重定位。在这里,加载器按照预定义的规则进行脱钩:
PROCESS_MITIGATION_CONTROL_FLOW_GUARD_POLICY (winnt.h) - Win32 apps | Microsoft Learn 为什么这个样本要进行CFG ?实际上是在为之后的DLL Hollowing进程注入进行准备,其会读写非CFG位图中所允许的位置。
样本先调用RtlGetVersion函数检查系统版本是否大于0x602(NT 6.2 = Windows 8,即须为 Windows 8.1 及以上),然后检查CFG是否开启:调用 probe_cfg_policy通过GetProcessMitigationPolicy(-1,ProcessControlFlowGuardPolicy,0,4)调用检查PROCESS_MITIGATION_CONTROL_FLOW_GUARD_POLICY结构体中EnableControlFlowGuard值是否为1。如果通过门控检查,则开始进行CFG Bypass。
在locate_hook_target_pattern函数中,程序会尝试通过特定的二进制序列匹配到LdrpHandleInvalidUserCallTarget函数的入口点。这个函数是当CFG检查失败的时候会调用的函数。这里还会对windows版本进行检查,以windows 10 14393版本为分界线,使用两套不同的特征码进行定位。定位到的函数头内存指针会返回到主函数中。主函数会先将该函数头size为5的部分设置为PAGE_EXECUTE_READWRITE,然后在这个函数头改写为JMP RAX; INT 3; NOP。CFG Bypass相关资料 MOV EBX,EDX; MOV RDI,RCX; CALL rel32并且尝试解析rel32的绝对目标longjmp_dispatch_fn,然后校验 longjmp_dispatch_fn 以 48 8B 05(MOV RAX,[RIP+disp32]) + magic DWORD 0x48D18B48 开头。这一系列的魔法操作是怎么回事呢?查看msvcrt发现:
跳转到__except_validate_jump_buffer:
别的不说我们先来看一下这段函数逻辑。这里是 __except_validate_jump_buffer 函数,它是 longjmp 调用的一部分。由于 longjmp 会通过非正常的堆栈回溯改变控制流,它是黑客最喜欢利用的攻击点之一,因此 Windows 必须在这里检查跳转的目标是否合法
可以发现这里是意图获取CFG机制的开关指针__guard_check_icall_fptr。首先获取*(__guard_check_icall_fptr),然后和下面的_CrtSetDbgBlockType逻辑对比。这个_CrtSetDbgBlockType在这里则是一个空容器,内容为retn 0。如果指针所指向的代码的位置和空容器相同,则说明CFG被短路,否则执行之后的CFG检查。
所以样本首先获取了__guard_check_icall_fptr,然后获取了_CrtSetDbgBlockType,最后使前者指向后者。如此则短路检查必定ok。最后样本再将刚才修改过的权限复原。
我个人用一些类似APC或VEH劫持的办法去劫持线程RIP寄存器也是一种不错的CFG Bypass办法。
接下来样本会验证机器的mac地址、机器名称以及当前登录的账户。对于当前登录的账户,OpenProcessToken打开进程令牌,GetTokenInformation(TokenUser)获取当前用户SID,LookupAccountSidW将SID解析为account_name+domain_name,然后AES-CFB8解密PE中嵌入的期望账户名/域名密文,使用_wcsicmp比较;匹配返回1,否则返回0。在我拿到的样本中,不存在内嵌的mac、机器名称配置。
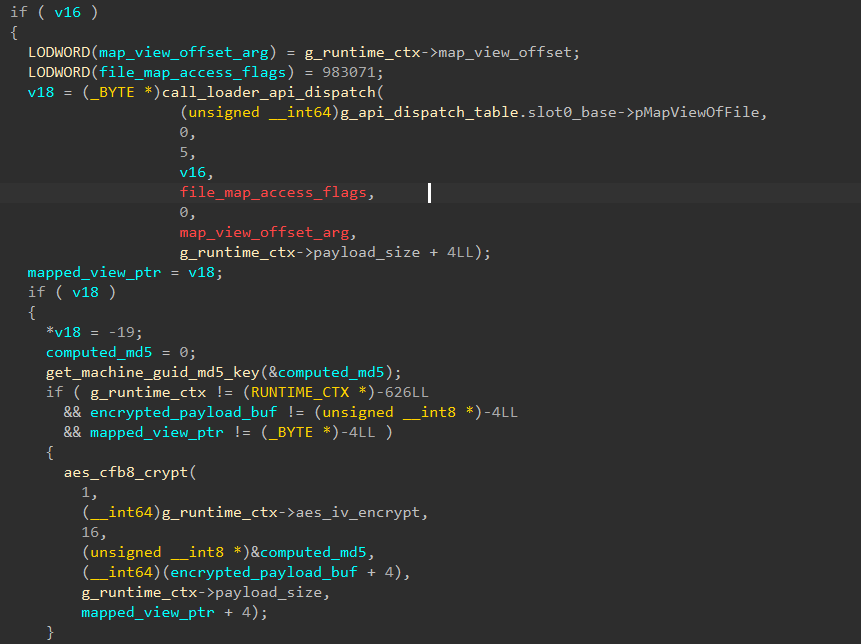
接下来开始执行载荷读取和加载功能。函数会通过一系列函数的调用生成载荷路径,并且对载荷进行校验和解密。在这里有一个很有意思的环境控制功能:最初始版本的载荷是通用的,但是一旦在某一台机器上执行了函数,则会被这台机器通过其注册表中的MachineGUID得到的MD5进行加密,尽可能延缓被安全厂商通过匿名文件上报功能将载荷上传后被分析的速度,除非厂商得到了这台机器的机器ID。在每次加载loader的时候,样本会检查被加密的载荷的第一个字节,如果为零则说明是未被特质化处理的加密载荷,否则为已经被处理过的加密载荷。
我拿到的样本已经被其他机器加密了,GG。。 起码我们把整个流程分析完。样本通过一条完整的载荷验证流水线load_and_verify_runtime_payload(_QWORD *out_payload_ptr)来加载载荷:首先获取加密载荷文件(在这里是sbiedll.dat)并通过静态内置密钥或本机GUID衍生的AES密钥将载荷加载到本地堆,并原地解密,然后进行md5运算校验。在这条流水线中允许选择在加载后使用DeleteFileW函数删除原始加密文件。
DLL Hollowing资料 DLL Hollowing 的高级进程注入技术,将堆中的载荷加载到可执行内存。
核心思路是选择一个牺牲DLL,利用NtCreateSection创建SEC_IMAGE标志内核节对象,并使用NtMapViewOfSection映射至进程,然后触发写时复制机制以脱钩映射,达到使得内存区域有合法文件背书的效果。
首先样本需要选择一个用于牺牲的DLL宿主。在函数stage_and_inject_payload_pe(char *payload_pe_buf, unsigned int payload_pe_size)中,传入了指向载荷PE数据的堆缓冲区(带有4字节大小前缀)、载荷PE的总字节大小。接下来进行载荷PE的基本数据头校验和载荷代码节的准备和校验:这个PE载荷必须有且仅有一个RX节作为第一节,其它节都不包含MEM_EXECUTE标志。接下来样本构造sys_dir_path+\\*.dll的名称并且枚举system32中的所有DLL,并且排除排除列表中的DLL,将所有可用宿主的DLL名称复制到数组中。
在样本中列举了高达58个所需要排除的DLL,包括我们熟悉的kernel32、ntdll.dll等。可能是因为这些dll过于常用,可能安全软件容易直接监控之,也可能会因为重复加载模块引发安全软件不必要的警觉。我观察了一下我的电脑system32中的dll,除了这58个dll之外仍有上千个候选宿主。在可用的宿主列表构建完成之后,样本随机(RtlGenRandom,通过advapi32.dll中的SystemFunction036提供)选择一个合格的DLL。
接下来样本会尝试生成一个用来暂存刚才选中的宿主的目录。有两种生成模式:首先尝试在C:\Windows\Microsoft.NET\assembly\GAC_MSIL\System.Data.Trace\<timestamp>.log获取一个特有的LUID,并生成C:\Windows\Microsoft.NET\assembly\GAC_MSIL\System.Data.Trace\v4.0_4.0.0.0__<rand_part_LUID>\<candidate_dll>冒充dotnet全局程序集缓存。如果之前这个log不存在,则改为生成C:\ProgramData\Microsoft.NET\System.Data.Trace\xxxx这个目录。样本会使用FILE_GENERIC_WRITE权限以FILE_CREATE方式创建这个暂存文件并获取句柄。
完成了宿主选择、暂存文件的创建之后,样本进入一条综合流水线。样本会尝试利用VirtualQuery查找kernel32模块正下方的空闲(状态为MEM_FREE)虚拟地址区域,利用1MB的步长进行扫描来确保加载地址和系统DLL在同一高地址范围。接下来分配一块堆空间,拷贝载荷PE, 然后对此进行处理:
在样本完成了制作代码节被载荷代码节替换的DLL文件 这一任务之后,接下来开始进行磁盘文件映射。使用NtCreateSection以PAGE_READONLY和SEC_IMAGE的内存保护标志创建内存切片,接下来使用NtMapViewOfSection将内存切片映射到所选中的位置。
在样本进行映射之后,将这个DLL链接到PEB中去以消除该IOC,接着将页面权限修改为RWX,并且使用堆中的载荷拷贝到刚才映射的位置。这里有一个问题:我们之前已经用载荷的text覆盖了暂存DLL的text,为什么现在要再复制一次呢?
windows写时复制处理流程 - 怎么可以吃突突 - 博客园 NtCreateSection 以 SEC_IMAGE 的标志创建切片的时候,Windows 并不会将实际的内存页复制到内存中,而是创建一个内核 SECTION 对象,其中记录了 PE 各节的文件位置和对应的内存保护属性,并持有对暂存文件的引用——此刻没有任何物理内存被分配,只是纯粹的元数据。
然后在 NtMapViewOfSection 函数被触发的时候,内核在进程 VAD 树中插入一个节点,其中记录了映射的虚拟地址范围、VadType = VadImageMap 以及指向暂存文件的路径引用,同时在进程PTE页表中为这段地址填入占位符,Present = 0,物理内存依然为零。外部工具此刻查询这段地址,会得到 MEM_IMAGE 类型和 GAC 伪装文件路径——这份"合法身份"由 Windows 内核自己填写,与物理内存中实际存放什么完全无关。真正的物理页要等到 CPU 第一次访问时才会按需从文件读入,而 memmove 的写操作会在此过程中触发 COW,将页面转为进程私有(Present=1, PageFrame=私有物理页, Prototype=0),永久脱离文件。
在完成memmove的循环拷贝之后,每个代码页都已经是进程私有,与文件本身脱钩,但是却拥有SEC_IMAGE标志。现在样本再次将候选DLL从原位置拷贝到暂存区,则现在暂存区的DLL也是干净的DLL。如果从安全软件的视角去看,这个内存区域有映射标志,有硬盘文件背书,文件本身为有签名的干净文件,这个区域看上去完全没有可疑之处。最后触发载荷DLLMain入口点。
如果我们硬要分析,那么就是其实际硬盘文件与内存中的映射块不同,并且内存中为MEM_IMAGE,作为工具就可以认定这是一个IOC。hasherezade/hollows_hunter: Scans all running processes. Recognizes and dumps a variety of potentially malicious implants (replaced/implanted PEs, shellcodes, hooks, in-memory patches). 有一个叫hollows_hunter的开源项目检测这类镂空。但是这可能提高检测成本。
如果DLL镂空模式未能成功加载,则样本回落至传统的反射式加载模式。在此样本中,反射时加载的行为和标准的反射加载行为没有太大区别,不再赘述。
接下来来看这个样本的堆栈欺骗技术。在样本开始加载的时候,是通过init_hashed_api_dispatch_table()来获得需要的api的指针,然后通过一个带有堆栈欺骗功能的api调用器call_loader_api_dispatch()进行api调用。
这个分发器支持大量的函数。分发器函数签名为call_loader_api_dispatch(__int64 api_fn_ptr, int fnv1a_obfs_enabler, __int64 arg_count, ...),其中第一个参数为所需要调用的api的虚拟地址。第二个参数为堆栈混淆开关,第三个参数为传递参数数量。使用了参数传递数量,分发器就可以在API调用时传递栈上无限的参数。
可以看见arg_count(即R8)被放置在[rsp+18h]的位置,[rsp+20h]为要传递的第一个参数。这样便允许分发器将全部参数视为一个(R11+20h)[arg_count]的数组。实际上样本中也是这么做的,在开辟了一个16x8Bytes的内存空间之后,从*(arg_count)+8h的位置开始将所有的参数(共arg_count个)复制进去。所以这里最多支持16个参数。样本中没有对输入的arg_count进行判断,应该判断一下。
接下来是样本尝试从TEB中尝试获得线程栈基址。正常情况下,我们总是可以从gs:[0x30]中获取当前TEB的指向,然后在TEB中:
可以看到在TEB64 + 0x08的地方可以获取到线程栈基址。Vergilius Project | _TEB64 但是调取gs寄存器容易在内存中留下比较显眼的痕迹,可能被进行特征码扫描。也许是出于这个原因,样本没有这样使用,而是调用了NtQueryInformationThread(NtCurrentThread(),ThreadBasicInformation,thread_basic_info,48,nt_query_ret_buf)。根据文档,这里thread_basic_info中结构如下
而在TEB中,栈基址的位置同样是在0x08,所以在thread_basic_info+0x10的地方可以寻到栈基址。
而在样本中,对基址的获取则添加了利用动态TLS的缓存机制。当线程执行到这里的时候,会尝试从全局变量(进程空间中的地址)中查找已经分配的TLS索引和线程基址。若不存在,则通过TlsAlloc分配索引,并且通过上述NtQueryInformationThread()函数获得当前线程的栈基址。TLS是对于每个线程独立的存储空间。我们简单地把TLS理解成写字楼(即进程)楼下的公共储物柜,每个公司(线程)拥有一排,而公司的员工(即线程中不同的业务实体,如不同的模块)可以向物业申请数个公司所拥有的储物柜。不同公司的员工即使拿着相同的编号,打开的也是不同的柜子。而通过业务申请,你也不会打开已经被公司内他人占用的柜子。在同一线程中,因为样本会多次利用分发器调用API,所以这个函数不止会调用一次。这时利用缓存的TLS能够大幅减少对NtQueryInformationThread()的调用次数,降低被检测的可能。
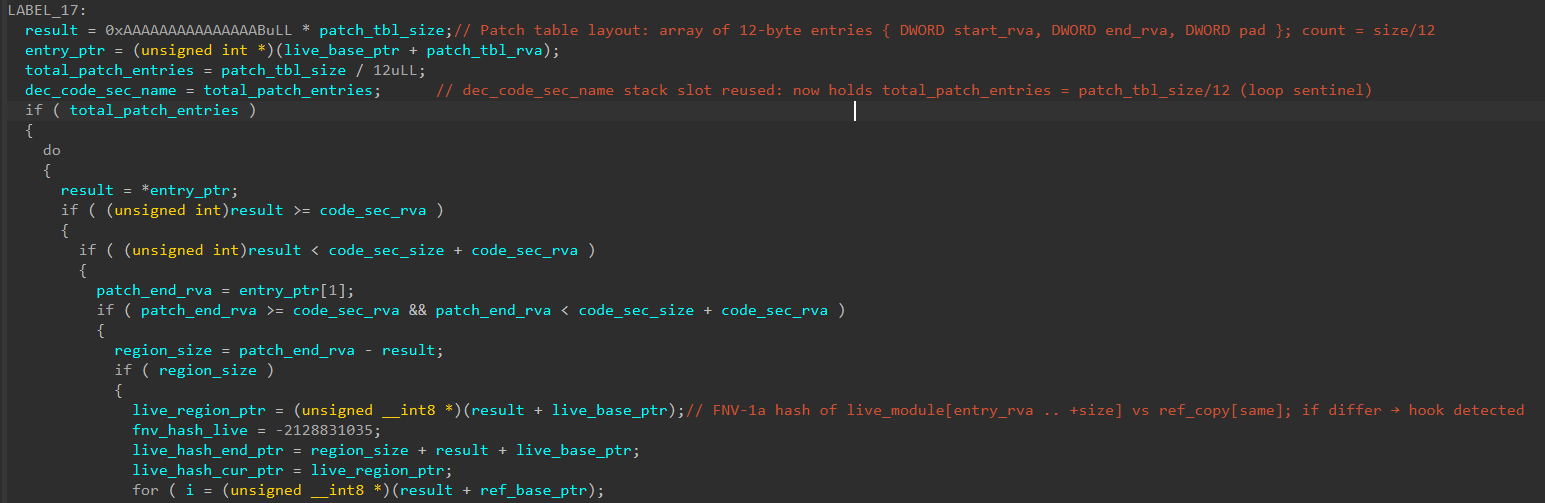
接下来回到样本。在分发器函数中进入函数find_hook_candidate_in_dll(_QWORD *out_hook_candidate_va, _DWORD *out_frame_size)。这个函数首先进行一些字符串解密,然后尝试定位kernelbase中的.text段。接下来在该段中搜寻jmp qword ptr [rbp + 0x48]指令。对于搜索到的这些指令,进入get_pdata_frame_size(__int64 module_base, int target_func_va, _DWORD *out_frame_size)函数进行UNWIND_CODE检查。
而在get_pdata_frame_size中,先是进行对模块的pdata节定位,然后因为RUNTIME_FUNCTION每一条大小为12,所以pdata的virtualsize/12等于条目数量。对于RUNTIME_FUNCTION,其第九个到第十二个字节指向UNWIND_INFO。一个函数的UNWIND_INFO由一些flags和UNWIND_CODE组成。对于UNWIND_INFO,这个样本中仅关注UNWIND_CODE中的opcode部分。相较于经典堆栈欺骗项目 SilentMoonwalk 而言,少了一些在多个dll中进行筛选的环节。也体现出本次攻击为鱼叉攻击。有关x64栈回溯的相关内容,在查漏补缺中有。
样本中的opcode和栈计数操作对应:
一个跳板函数所对应的栈回溯大小会被累计,并返回到上级函数。样本会检测这个跳板函数的有效帧大小,有效范围在[0x88, 0x1000)之间。不合法的跳板函数会被丢弃。样本会收集最多一百个候选跳板函数,避免进行过多的遍历。最终样本会在这些候选项中,通过GetTickCount64 % 候选者数目作为候选者名单数组的索引随机选择一个候选的跳板函数。最后再次调用一次get_pdata_frame_size获取被选上的函数的栈回溯值。
现在我们已经拿到了这个重要的jmp qword ptr [rbp + 0x48]跳板。接下来就是栈构造的时间。样本会获取ntdll!RtlUserThreadStart+0x21、kernel32!BaseThreadInitThunk + 0x14这两个地址并通过刚才的函数获取函数栈大小,这是一般的线程起点栈。接下来按照如下规则布置栈:
接下来将指向null哨兵的指针再次返回上级call_loader_api_dispatch。
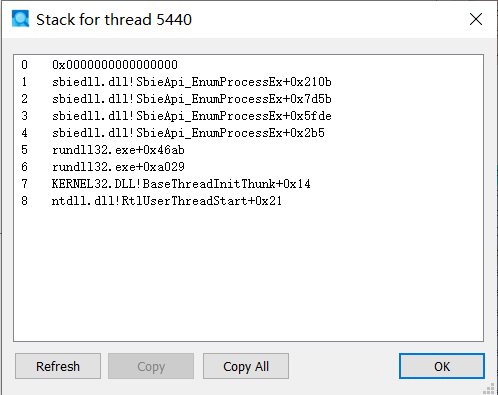
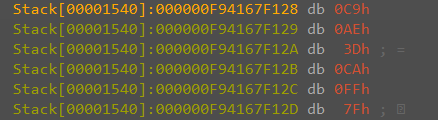
现在我们来进入最后,也是真正的栈伪造环节。在dispatch_via_hook_trampoline中,首先压栈保存了所有7个非易失性寄存器,然后通过hook_ctx中的frame_high和frame_low获得新栈的大小,再加上200h的距离避免新老栈交错。接下来进行栈上参数的复制。然后在将RBP指向栈底+50h的地方。如果检测对原栈的加密flag存在,则还会进行fnv1a加密,加密的;但是无论是否存在,都会将函数跳板尾声hook_trampoline_epilog的指针放在RBP+48h,也就是栈底+8h的位置。最后再完成对几个寄存器的参数赋值,然后通过jmp r12命令跳转到打算跳转的地方。这时,我们再通过processExplorer查看,则会发现当前的线程栈中完全不存在sbiedll.dll的偏移。jmp_gadget_va,也就是在kernelbase之前选出的jmp qword ptr [rbp + 0x48]。这时会将控制流劫持到刚才放置的跳板尾声函数指针hook_trampoline_epilog。在跳板尾声中,如果加密flag存在的时候则会进行fnv1a解密,因为fnv1a是加密自反算法,加密两次等于自身。最后在跳板尾声函数中恢复非易失性寄存器值,最后返回真正的调用者。
SilentMoonwalk: Implementing a dynamic Call Stack Spoofer | CyberSecurity Blog
在这个样本中,回溯器和执行流之间确实被分离了,执行流被jmp rbp+48h所劫持到跳板函数,而回溯器则顺着回溯到预置的假线程入口。而在SilentMoonwalk中,通过第一和第二栈帧,允许将回溯器通过RBP诱导到任意入口点 ,比如真正的线程入口,caller's caller(如被植入shellcode的有漏洞线程的线程入口)。在本项目中没有使用这两个栈帧,说明样本不需要对抗学术级别的精确定位追溯,这个样本本身是利用了开源软件sandboxie的hook_layer中的dll侧载漏洞,并且在宿主进程中作为独立线程被调用,也不必要为了过于严谨的回溯增加投放成本。
复杂的检测手段有很多,比如追溯栈帧入口点的上一条指令是否为常见call、或者直接调用intel pt引擎进行PIP追溯。但是在成本有限的情况下可能造成大量安全运维噪音,导致很多时候并没有被工程化地部署(如对于采用了JIt的语言线程来说往往是致命的)。
RUNTIME_FUNCTION (winnt.h) - Win32 应用 | Microsoft Learn --- RUNTIME_FUNCTION (winnt.h) - Win32 apps | Microsoft Learn x64 异常处理 | 微软学习 --- x64 exception handling | Microsoft Learn
为什么在x64中,RBP可以被用来被用作栈指针?在 x64 汇编中,RBP(Base Pointer)是一个非常特殊的寄存器,它有两种截然不同的用法:
用法 A:作为通用寄存器(General Purpose Register)
Windows x64 不再通过简单的扫描栈来回溯(像 x86 那样),而是依赖 PE 文件中必须存在的 .pdata (Runtime Function Table) 和 Unwind Info。这相当于一本“说明书”,告诉系统如何回溯每一行代码。
当系统(或 EDR)进行栈回溯时,如果它在“说明书”里读到了 UWOP_SET_FPREG,它会收到一条强制指令:
异常目录 位于该数组的第 4 个索引位(索引值为 3),宏定义为 IMAGE_DIRECTORY_ENTRY_EXCEPTION。DataDirectory[IMAGE_DIRECTORY_ENTRY_EXCEPTION] 包含两个关键字段:VirtualAddress : 异常表相对于 ImageBase 的偏移(RVA)。Size : 异常表的总字节大小。
也就是说在第9-12个字节处是存放unwindinfo的位置。这是个RVA。
跳转过去之后是一个UNWIND_INFO结构体。
低四位为2,表示实际的FP寄存器为RSP + 16 * 2,即32字节。为什么这里是32字节?这个问题我没有搞明白。根据X64 ABI的规定,caller必须在调用任何函数之前,在栈上留下32字节的空间。这块空间被称作为影子空间,无论参数有多少都必须存在。
RBP指向了影子空间的顶端,然后可以用正负偏移量分别访问函数自身的局部变量和影子空间中保存的输入参数。但是其又提出,这个设计有代码密度优化的功能,允许使用8位有符号位移,能比32位位移的指令更短,比如说一个函数使用了相当大的栈空间,就可以让FP在栈的正中央,能够允许更多的访存指令使用8位而不是32位。但是到底是为了哪种目的,这里也没有一个专门的flags指示,所以感觉不太明白。根据AI的描述,这二者本身并不冲突,是同一个设计目标在不同规模函数下的体现。
因为之前说有三个unwind code,所以后面跟了三个WORD unwind code。0b23 06b2 0250,剩下一些全零。首先对于第一个,0b23,prolog偏移量为0b,代表在函数序言执行到11字节的时候发生的动作。opcode为3UWOP_SET_FPREG,opinfo为2,对应UNWIND_INFO头部中设置的帧寄存器偏移量(缩放值)。这个是什么东西?根据AI解释,在这个栈描述结构中,有一些opcode是需要额外参数的,放在opinfo中;当操作码为UWOP_SET_FPREG的时候,opinfo的含义为Frame Register Offset。X64 ABI规定,FP = RSP+16*FrameRegisterOffset;也就是说:
在0x0B之前,回溯器认为这个栈是无框的,可以通过RSP+增量回溯。在0x0B之后,执行器看到这个code触发,立刻去header中读出RBP和0x20。从此以后,RSP的基准值永远等于RBP-0x20。
现在我们再从这三个code开始模拟一次栈回溯。动态栈 操作(如alloca)。
下一步阅读到06B2。偏移06,动作为UWOP_ALLOC_SMALL分配小栈空间;info B=11,分配公式为(INFO * 8) + 8。所以这里就是分配96(0x60)字节。那么对于回溯器来说就是回溯96字节。
下一步阅读到0250。偏移02,动作为UWOP_PUSH_NONVOL(压栈非易失存储器);info 5为寄存器RBP。也就是说,这个code描绘了将RBP入栈的动作。那么作为回溯器,就应该RSP再+8。到此位置,就完成了对一个栈的回溯。
样本宿主sbiedll.dll来自沙箱软件sandboxie-plus。这是一个注入型 Hook DLL——Sandboxie 驱动通过 SbieApi_DeviceHandle 将它强制加载进每一个沙箱内的进程。被注入的进程可以是 Chrome(200+ 线程)、Firefox、Office,也可以是任意第三方程序。沙箱必须在这些进程的所有线程上正确拦截 ntdll/kernel32 系统调用,并做路径虚拟化、IPC 转发等工作。任何并发问题都会变成数据损坏或权限绕过。因此样本中含有大量的并发休眠,TLS缓存等机制避免直接崩溃或重复注入载荷的风险。
我会在之后完成对这个加载器的复现,届时会上传到Github中。感谢阅读。
typedef struct _RUNTIME_FUNCTION {
DWORD BeginAddress;
DWORD EndAddress;
DWORD UnwindData;
} RUNTIME_FUNCTION;
typedef struct _RUNTIME_FUNCTION {
DWORD BeginAddress;
DWORD EndAddress;
DWORD UnwindData;
} RUNTIME_FUNCTION;
.text:000000011012F840 ; void __cdecl __noreturn longjmp(jmp_buf Buf, int Value)
……
mov ebx, edx
mov rdi, rcx
call __except_validate_jump_buffer
.text:000000011012F840 ; void __cdecl __noreturn longjmp(jmp_buf Buf, int Value)
……
mov ebx, edx
mov rdi, rcx
call __except_validate_jump_buffer
__except_validate_jump_buffer proc near ; CODE XREF: longjmp+F↑p
mov rax, cs:__guard_check_icall_fptr
mov rdx, rcx
lea rcx, _CrtSetDbgBlockType
cmp rax, rcx
jz short locret_110130A72
mov rax, gs:30h
mov ecx, 0Dh
mov r8, [rdx+10h]
cmp r8, [rax+10h]
jb short loc_110130A68
cmp r8, [rax+8]
jbe short loc_110130A6A
__except_validate_jump_buffer proc near ; CODE XREF: longjmp+F↑p
mov rax, cs:__guard_check_icall_fptr
mov rdx, rcx
lea rcx, _CrtSetDbgBlockType
cmp rax, rcx
jz short locret_110130A72
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。