动态二进制插桩(Dynamic Binary Instrumentation)简称 DBI,其根本原理可以简单概括为:
在每条汇编指令的前后插入额外的指令,实现控制程序的执行流与读取程序的数据流。
我们要想在一条指令的前后插入指令,首当其冲面临的问题便是:内存空间不足。因为,ELF 文件在被加载进内存时,已经按照编译时所确定的固定内存大小被加载到进程。几乎没有多余的空间供我们使用。因此,我们必须申请与管理一段新内存,让原本的代码段运行在我们新申请的内存中。所以在 DBI 中必须有一个内存管理模块。
我们在拥有了足够的内存之后,便能够写入指令了。而想要写入指令,我们必须能够先生成指令,因此我们也需要一个汇编器模块。 而在 DBI 中由于内存地址的改变,部分 ARM64 的指令已经不能简单的复制过去就能与原程序逻辑一样运行了。因为,ARM64 的部分指令是与 PC 相关的指令。比如:B.cond、ADRP、TBNZ……等指令,这些指令的寻址能力各不相同,我们将代码段复制到新开辟的内存空间运行后,运行的 PC 基址已经改变,此时如果寻址能力不足以跳转到目标地址的话,那么将引发错误。拿 B.EQ 指令来举例:

插桩后的 B.EQ 指令将跳转不到 0x7100 地址执行,因为 B.EG 指令的寻址能力只有相对 PC 1MB 的范围,而 0x7000000 - 0x7100 = 0x6FF8F00,已经远远超过 B.EQ 指令的寻址范围了,因此将引发错误。那么这种指令我们该如何处理,让其能按照原有的逻辑运行呢?我们可以将其翻译为这样:

这样就能利用 B 指令的 128MB 寻址能力为我们跳转到指定的地址。所以,为了完成这样的指令转变,我们还需要一个翻译器模块。
我们观察转换后的指令可以发现,原来的一条指令膨胀成了两条指令。如此我们便引申出了 DBI 的一个重大弊端:几何级的指令膨胀。在实际的插桩过程中,我们为了完成对每条指令监控的同时保证程序按照原逻辑运行,需要在每条指令的前后插入保存与恢复寄存器状态指令。拿监控 MOV X0, #1 这条指令来举例,通常我们插桩后的指令视图是这样的:
仅仅看这段指令明面上就由单条指令膨胀成了 27 条指令,而事实上 monitor 函数为了实现监控打印指令信息,可能还会有上百条的指令不止。因此,DBI 后的单条指令时间复杂度由原来的 O(1) 上升到了 O(n) 。我们将保存恢复寄存器状态的指令集记为 A,monitor 函数记为 B。
N = A + B + 1
假设:A = 26,B = 200。那么原来的单条指令就转变为了 267 条指令,这还是保守假设。
因为,通常我们会把指令信息输出到文件,那么这时 monitor 函数在运行时还会和内核交互,如此算来的时间复杂度就不可预估了。正是因为运行时间的大幅增加,检测 DBI 的方法之一便是记录开始与结束时间,如果时间相差过于悬殊,则就证明程序的运行环境异常。此时不管是风控上报异常还是自毁,都是合理的选择。当然,我们想要绕过检测也不难。不过,这不是本文的重点就不展开了。
现在我们知道想要实现 DBI 最重要的有三大模块:内存管理、汇编器、翻译器。那么我们只要实现这几个模块,就能实现一个完备的 DBI 了吗?并不是。在 ARM64 中有些指令的跳转地址是在运行时才确定的,比如:BLR, X8。这个 X8 可能是运行时动态计算的函数地址,而我们在运行到这条指令之前是不知道 X8 的值的。所以我们必须在运行时拿到 X8 的跳转地址,才能完成这类动态指令的插桩。但是接下来又引申了另外两个问题:我们怎么保证跳转过去的地址是被我们插过桩的呢?又为什么需要保证跳转地址是被我们插过桩的呢?因为,我们需要监控程序。如果运行没被插过桩的代码段,我们是无法调用 monitor 函数监控程序执行状态的。那我们怎么保证跳转的目标地址始终是被插过桩的呢?我们可以构建一个二级跳转路径,让所有的跳转指令首先跳转到我们的路由函数,将要跳转的目标地址作为参数传给路由函数,这样所有的跳转指令我们就都能拦截了。然后,我们可以在路由函数中判断目标地址是不是被插过桩,如果没有就先将目标地址的指令插桩一遍,再跳转。
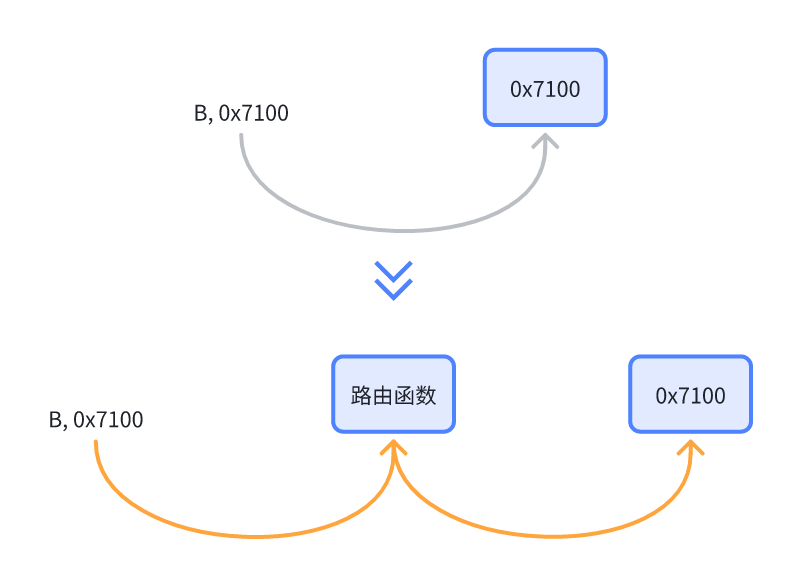
而这也是为什么 DBI 需要以基本块为单位插桩的原因,因为前一基本块无法预测下一基本块的落点。所以,干脆设计个二级跳转路径,一旦遇上带有跳转语义的指令标记基本块结束,并把原跳转指令替换为跳转到路由函数的指令。再在路由函数中实现对下一基本块的插桩。
至此,我们就可以勾勒出一幅 DBI 的架构图:
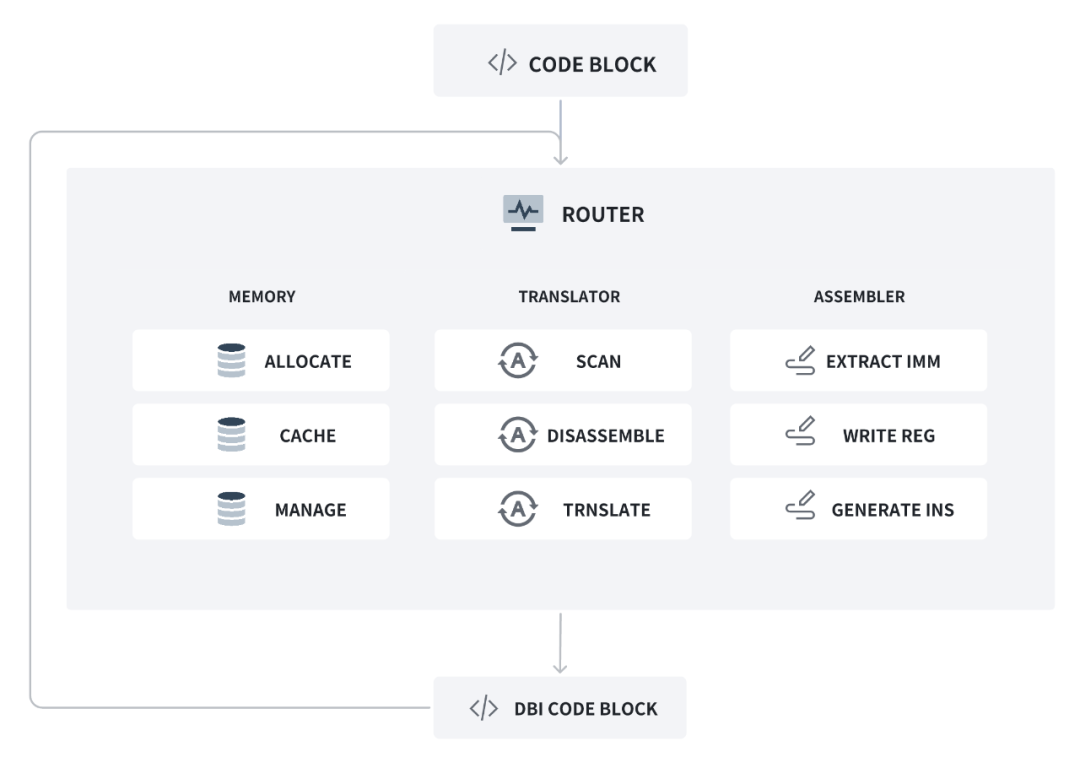
以基本块为单位插桩,基本块结束时翻译跳转指令首先跳转到路由函数。再在路由函数中使用内存管理、翻译器、汇编器三大模块对下一基本块实现插桩。
我们以插桩一个快排算法为目标,实现一个简单的 DBI 框架。
可以看到,这个函数里包含了条件判断、循环、递归函数调用等语句,是一个极佳的插桩学习样本。函数编译后的汇编为:
我们整理出所有带有跳转语义的指令,共有 4 类:
事实上由于 BL 指令跳转的目标地址是一段间接跳转代码段,所以还会有如下一段指令:
会有这段指令原因是:我们在函数中调用了函数。而由于我们的函数在被加载到进程之前是不知道确切的函数地址的,所以编译器生成了一个间接跳转的代码段,等待运行时由 Linker 来重定位函数地址,从而完成跳转。并且我们可以看到,最后的跳转是由 BR 指令来完成的,而不是 BL 指令。那为什么要换一个指令呢?因为 BR 指令的寻址能力只有相对 PC 128MB 的距离,而 BR 使用寄存器跳转,拥有 64bit 全范围的寻址能力。如果调用的目标函数是一个三方库函数,BR 仍然能够寻址到,而 BL 则不一定。编译器为确保万无一失,所以换成 BR 指令来完成跳转。所以实际上我们还要加上 BR 这条跳转指令,加起来共有 5 类带有跳转语义的指令。另外,我们还有一条 ADRP 指令是与 PC 相关的指令。因此,我们一共有 6 条指令需要翻译。接下来,我们开始实现 DBI 框架。
所有带有跳转语义的指令都将先跳转到我们的路由函数,以避免跳转到没被插桩的基本块。比如一条 b.cond 指令,将被翻译为:
可以看到,不管跳转条件怎样都会先跳转到我们的路由函数,并且将跳转地址做为第一个参数传入 router。
可以看到,有一个 ROUTER_TYPE 参数,这个参数的作用是识别指令类型。以便在下一个基本块的开头恢复我们在跳转路由函数过程中所破坏的寄存器。
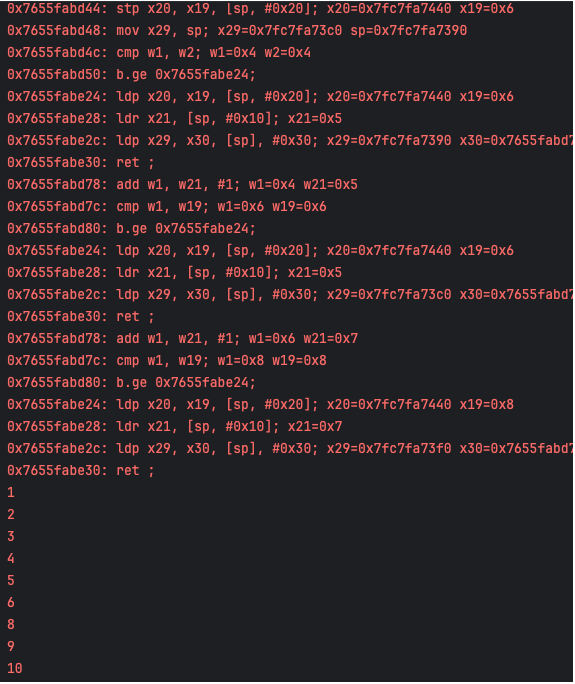
可以看到,最后完美的将数组从小到大排序了,并且输出了每一条指令的状态信息。至此,一个简易的 DBI 框架就完成了。
本文的实现源代码已上传到:740K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9K9h3c8G2L8X3N6&6L8$3!0G2i4K6u0r3b7g2u0y4y4U0c8p5b7V1W2Q4c8f1k6Q4b7V1y4Q4z5p5y4Q4c8e0k6Q4z5o6c8Q4z5f1k6Q4c8e0g2Q4z5o6g2Q4b7U0c8Q4c8e0S2Q4b7U0k6Q4b7e0y4Q4c8e0N6Q4z5f1q4Q4z5o6c8Q4c8e0k6Q4z5f1y4Q4z5p5u0Q4c8e0g2Q4z5p5k6Q4z5p5u0Q4c8e0g2Q4z5p5k6Q4b7f1k6Q4c8e0S2Q4z5o6N6Q4b7f1q4Q4c8e0S2Q4b7e0q4Q4z5p5y4Q4c8e0W2Q4z5e0S2Q4z5o6g2Q4c8e0S2Q4b7f1k6Q4b7V1u0Q4c8e0y4Q4z5o6m8Q4z5o6t1`.
建了个交流群,感兴趣的朋友可以加我,拉你入群。vx:lidongyooo
STP X29, X30, [SP,
ADD X29, SP,
STP X0, X1, [SP,
STP X2, X3, [SP,
STP X4, X5, [SP,
STP X6, X7, [SP,
STP X8, X9, [SP,
STP X10, X11, [SP,
STP X12, X13, [SP,
STP X14, X15, [SP,
STP X16, X17, [SP,
STR X18, [SP,
MOV X0, SP
LDR X16, monitor
BLR X16 // 调用监控程序
LDR X18, [SP,
LDP X16, X17, [SP,
LDP X14, X15, [SP,
LDP X12, X13, [SP,
LDP X10, X11, [SP,
LDP X8, X9, [SP,
LDP X6, X7, [SP,
LDP X4, X5, [SP,
LDP X2, X3, [SP,
LDP X0, X1, [SP,
LDP X29, X30, [SP],
MOV X0,
STP X29, X30, [SP,
ADD X29, SP,
STP X0, X1, [SP,
STP X2, X3, [SP,
STP X4, X5, [SP,
STP X6, X7, [SP,
STP X8, X9, [SP,
STP X10, X11, [SP,
STP X12, X13, [SP,
STP X14, X15, [SP,
STP X16, X17, [SP,
STR X18, [SP,
MOV X0, SP
LDR X16, monitor
BLR X16 // 调用监控程序
LDR X18, [SP,
LDP X16, X17, [SP,
LDP X14, X15, [SP,
LDP X12, X13, [SP,
LDP X10, X11, [SP,
LDP X8, X9, [SP,
LDP X6, X7, [SP,
LDP X4, X5, [SP,
LDP X2, X3, [SP,
LDP X0, X1, [SP,
LDP X29, X30, [SP],
MOV X0,
void quick_sort(int arr[], int left, int right) {
if (left >= right) return;
int i = left, j = right;
int pivot = arr[left];
while (i < j) {
while (i < j && arr[j] >= pivot) j--;
if (i < j) arr[i++] = arr[j];
while (i < j && arr[i] <= pivot) i++;
if (i < j) arr[j--] = arr[i];
}
arr[i] = pivot;
quick_sort(arr, left, i - 1);
quick_sort(arr, i + 1, right);
}
void quick_sort(int arr[], int left, int right) {
if (left >= right) return;
int i = left, j = right;
int pivot = arr[left];
while (i < j) {
while (i < j && arr[j] >= pivot) j--;
if (i < j) arr[i++] = arr[j];
while (i < j && arr[i] <= pivot) i++;
if (i < j) arr[j--] = arr[i];
}
arr[i] = pivot;
quick_sort(arr, left, i - 1);
quick_sort(arr, i + 1, right);
}
#define BLOCK_NUMBER 4096
#define BLOCK_SIZE 1024
struct BlockMeta {
int index;
void* code_start;
int code_size;
void* block_start;
int block_size;
BlockMeta* slice_block_meta;
uint32_t code[BLOCK_SIZE];
};
class Memory {
private:
static Memory* instance;
Memory() {
size_t blocks_meta_size = ALIGN_PAGE_UP(sizeof(BlockMeta) * BLOCK_NUMBER);
first_block_meta = (BlockMeta*)mmap(nullptr, blocks_meta_size, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
}
public:
std::unordered_map<uint64_t, int> cache_block_meta;
int curr_block_index = 0;
BlockMeta* first_block_meta;
BlockMeta* block_meta_arr[BLOCK_NUMBER] = {nullptr};
static BlockMeta* get_or_new_block_meta(int index = 99999999);
static BlockMeta* new_block_meta();
static bool set_cache_block_meta(uint64_t key, int value);
static BlockMeta* get_cache_block_meta(uint64_t key);
};
#define BLOCK_NUMBER 4096
#define BLOCK_SIZE 1024
struct BlockMeta {
int index;
void* code_start;
int code_size;
void* block_start;
int block_size;
BlockMeta* slice_block_meta;
uint32_t code[BLOCK_SIZE];
};
class Memory {
private:
static Memory* instance;
Memory() {
size_t blocks_meta_size = ALIGN_PAGE_UP(sizeof(BlockMeta) * BLOCK_NUMBER);
first_block_meta = (BlockMeta*)mmap(nullptr, blocks_meta_size, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
}
public:
std::unordered_map<uint64_t, int> cache_block_meta;
int curr_block_index = 0;
BlockMeta* first_block_meta;
BlockMeta* block_meta_arr[BLOCK_NUMBER] = {nullptr};
static BlockMeta* get_or_new_block_meta(int index = 99999999);
static BlockMeta* new_block_meta();
static bool set_cache_block_meta(uint64_t key, int value);
static BlockMeta* get_cache_block_meta(uint64_t key);
};
class Assembler {
public:
static void prolog(uint32_t *&writer);
static void epilog(uint32_t *&writer);
static void movz(uint32_t &instr, ARM64_REGISTER reg, uint16_t immediate, uint8_t shift);
static void movk(uint32_t &instr, ARM64_REGISTER reg, uint16_t immediate, uint8_t shift);
static void str(uint32_t &instr, ARM64_REGISTER src_reg, ARM64_REGISTER dst_reg, int dst_offset);
static void blr(uint32_t &instr, ARM64_REGISTER reg);
static void ret(uint32_t &instr, ARM64_REGISTER reg);
static void b(uint32_t &instr, uint64_t pc, uint64_t target);
static void mov_sp_to_x(uint32_t &instr, ARM64_REGISTER rd);
static void mov_x_to_x(uint32_t &instr, uint8_t dest_reg, uint8_t src_reg);
static void write_value_to_reg(uint32_t *&writer, ARM64_REGISTER reg, uint64_t value);
static void write_pc_to_cpu(uint32_t *&writer, uint64_t pc);
static void call_dbi_callback(uint32_t *&writer);
static void get_b_addr(uint64_t &addr, uint64_t pc, uint32_t machine_code);
static void get_bl_addr(uint64_t &addr, uint64_t pc, uint32_t machine_code);
static void get_adrp_addr(uint64_t &addr, uint64_t pc, uint32_t machine_code);
static ARM64_REGISTER get_adrp_reg(uint32_t machine_code);
static ARM64_REGISTER get_br_reg(uint32_t machine_code);
static bool b_is_cond(uint32_t machine_code);
static void modify_b_cond_addr(uint32_t &instr, uint32_t machine_code, uint64_t current_pc, uint64_t new_address);
static void br(uint32_t &instr, ARM64_REGISTER reg);
static void br_x16_jump(uint32_t *&writer, uint64_t target_addr);
static void blr_x16_jump(uint32_t *&writer, uint64_t target_addr);
};
class Assembler {
public:
static void prolog(uint32_t *&writer);
static void epilog(uint32_t *&writer);
static void movz(uint32_t &instr, ARM64_REGISTER reg, uint16_t immediate, uint8_t shift);
static void movk(uint32_t &instr, ARM64_REGISTER reg, uint16_t immediate, uint8_t shift);
static void str(uint32_t &instr, ARM64_REGISTER src_reg, ARM64_REGISTER dst_reg, int dst_offset);
static void blr(uint32_t &instr, ARM64_REGISTER reg);
static void ret(uint32_t &instr, ARM64_REGISTER reg);
static void b(uint32_t &instr, uint64_t pc, uint64_t target);
static void mov_sp_to_x(uint32_t &instr, ARM64_REGISTER rd);
static void mov_x_to_x(uint32_t &instr, uint8_t dest_reg, uint8_t src_reg);
static void write_value_to_reg(uint32_t *&writer, ARM64_REGISTER reg, uint64_t value);
static void write_pc_to_cpu(uint32_t *&writer, uint64_t pc);
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!






