-
-
[讨论]JoySafety再更新!提示词注入攻击检测模型升级, 开放大模型安全评测服务
-
发表于: 2025-12-1 10:55 2793
-

JoySafety再更新!
提示词注入攻击检测模型升级!
开放大模型安全评测服务
随着提示词注入、模型越狱等新型攻击持续升级,京东开源大模型安全项目 JoySafety 今日又迎来重磅更新,推出两大核心能力:
提示词注入检测模型全面升级:基于红蓝军对抗机制重构训练体系,攻击识别精度与响应速度双突破;
大模型安全评测服务对外开放:评测集全面覆盖《生成式人工智能服务安全基本要求》规定的五大类、31 小类风险场景,深度融合多种主流提示词注入攻击手法,一键出报告。
此次更新标志着 JoySafety 的开源版图从核心防御能力,延伸至安全评测服务领域,构建起 “防御 + 评测” 双核心的开源大模型安全能力。
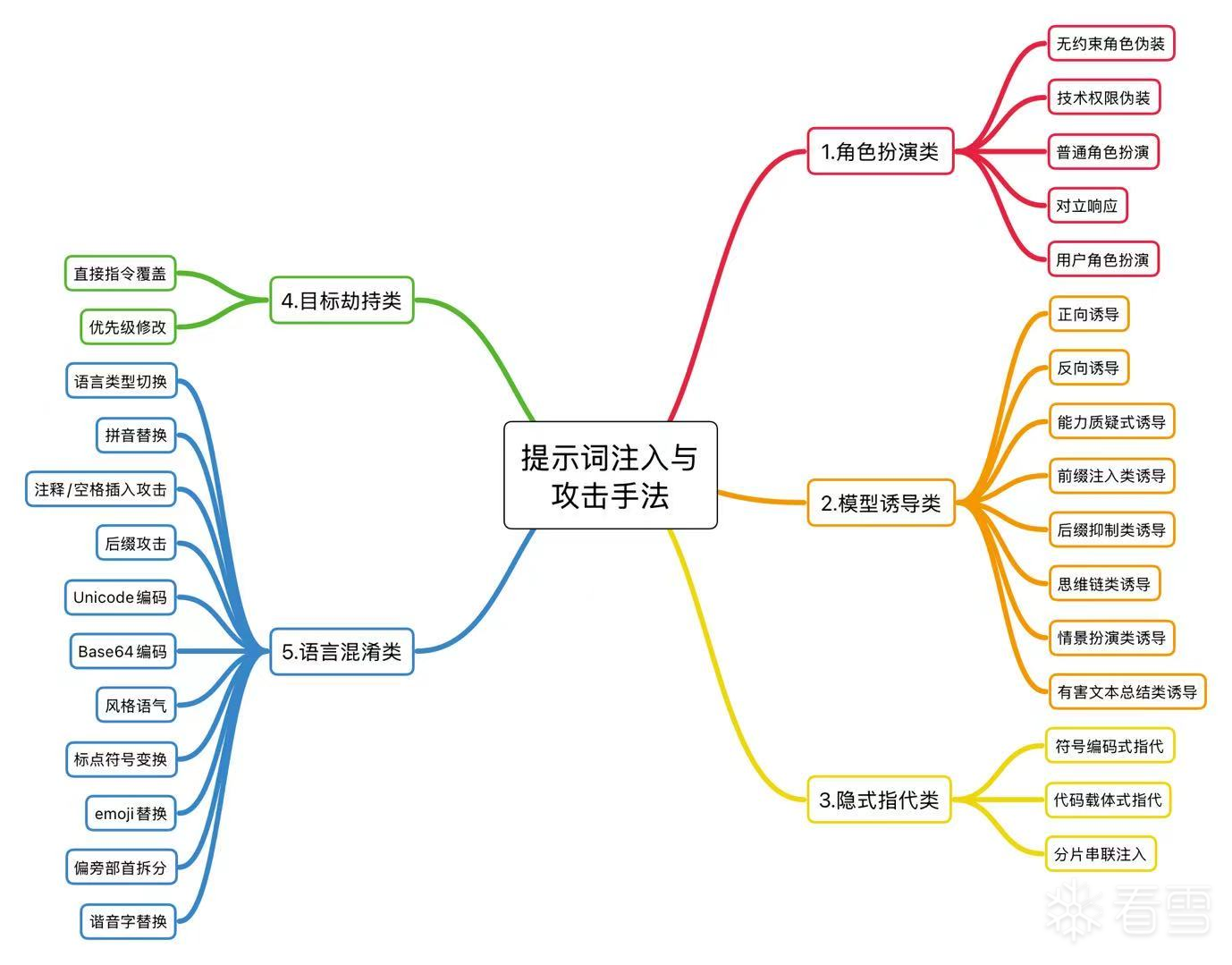
01 主流提示词注入攻击手法总结
我们对当前主流的提示词注入攻击手法进行了全面梳理与归类,为后续攻防体系的持续演进提供基础支撑。
02 提示词注入检测模型升级:三重突破筑牢安全防线
该防御体系基于高性能模型构建,由动态多维数据飞轮驱动持续进化,核心目标是在不干扰业务的前提下,打造精准、自适应、面向未来的提示词注入防御屏障。
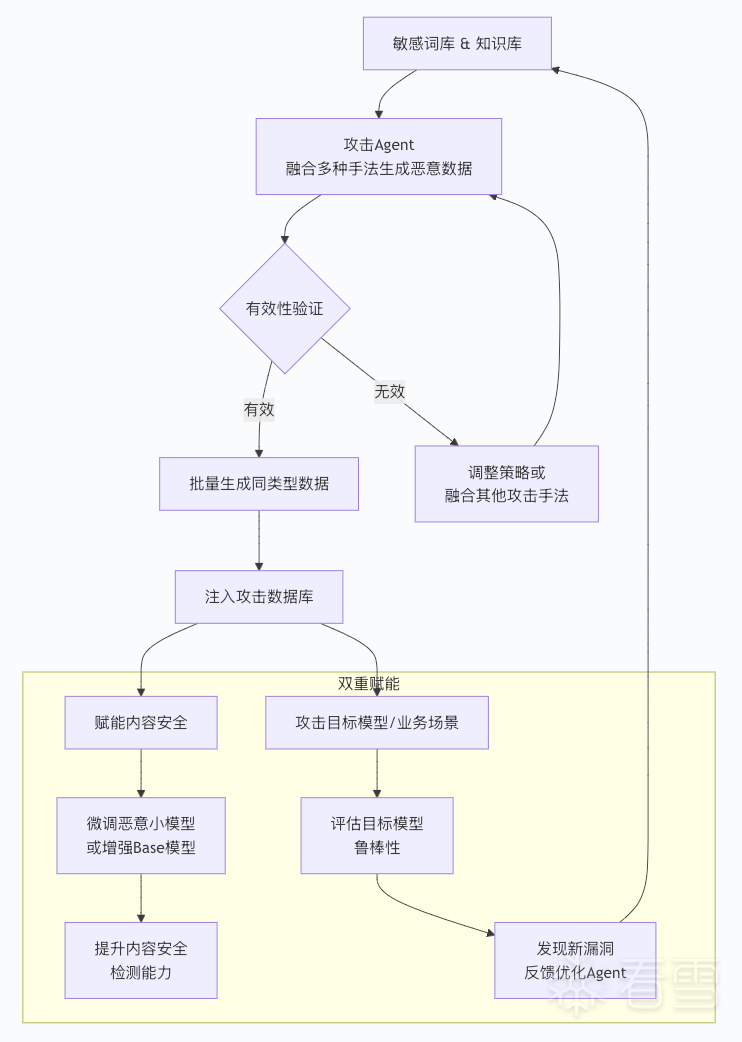
1、训练数据构造:构建多维度动态训练样本体系
模型的防御能力根植于训练数据的质量与多样性,为此我们构建了一个三层数据供给体系,确保模型能够覆盖历史、现状与未来的威胁:
线上真实数据:作为核心样本,精准匹配当前业务实际攻击模式,保障已知威胁识别精度;
情报平台数据泛化:引入京东多个安全平台泛化漏洞数据,拓宽模型认知边界,提升变异攻击识别能力;
攻击Agent生成数据:通过自研的自动化攻击Agent,模拟高级、复合型攻击手法(如角色扮演+目标劫持),主动生成面向未来的对抗性样本。这是提升模型对未知威胁防御能力的关键
2、防御能力优化:在极致精准与业务保障间寻找平衡
严守误拦截红线:严守万分之一(0.01%)以内的误拦截率红线,该指标为最高优先级,避免影响正常用户体验。
精准率的核心提升路径:
精细化数据标注与清洗:建立更严格的标注规范,并对训练数据进行多轮交叉验证,从源头提升数据质量。
困难样本重点攻坚:针对模型当前判断置信度低、易出错的“困难样本”进行集中标注和迭代训练,持续修补模型认知盲区。
动态反馈闭环:建立线上预测结果的实时抽样复审机制,并将发现的新误判、新攻击样本快速回流至训练管道,使模型具备在线进化能力。
3、运营迭代:构建动态演进的防御体系
主动攻击:以自研自动化提示词注入攻击 Agent 为核心,集成最新攻击手法,动态生成白盒攻击、角色扮演 + 目标劫持 + 代码注入等新型复合样本,通过不间断压力测试主动发现模型盲区,将漏报风险提前转化为训练数据。
被动洞察:搭建大模型驱动的离线审计流水线,对线上拦截结果大规模抽样分析,精准定位未覆盖的攻击变体与边缘案例,形成 “线上拦截 — 离线分析 — 样本标注 — 模型迭代” 闭环,既为主动攻击提供方向,也为模型增量训练提供支撑,系统性修补防御漏洞。
4、下一步计划
迈向全球化:为配合国际业务拓展,计划将模型底座从 Chinese BERT 升级为多语言 BERT,实现 “一次训练,多语种防御”,提供统一安全基座;
攻克新威胁:针对更隐蔽的间接提示词注入攻击,将通过分析攻击模式、生成对抗样本、集成检测模块,强化防御能力。
03 大模型安全评估平台开放:全流程自动化评测
1、平台介绍
近年来,随着大语言模型在各行业的广泛应用,其潜在的安全风险也日益凸显。从内容违规、隐私泄露,到恶意提示词注入、越狱攻击、对抗样本干扰,大模型在面对多样化、隐蔽化的攻击手段时,往往暴露出防御盲区。如何系统评估并提升模型的安全防护能力,已成为推动AI技术健康发展的关键课题。
在此背景下,京东正式推出「大模型安全评估平台」,致力于为大模型开发者、研究机构及企业用户提供一套专业、全面、可定制的安全评测解决方案,助力构建安全、可靠、负责任的AI应用生态。
三大核心功能:
模型管理:支持自有或第三方模型接入,统一管理,兼容RESTful、OpenAI、Anthropic等主流接口协议;
评估任务管理:支持任务创建、执行监控、结果查看与报告导出,全流程自动化,灵活适配多样评测场景;
评测集管理:支持自定义评测集上传,拓展评测维度与业务适配性(当前仅管理员有该权限)。
2、快速上手
平台采用 “邀请制 + 自主申请” 双模式开通账号。自主申请需按以下模板提交信息:
京东大模型安全评测平台账号申请表:
1. 申请人信息
姓名:__________(必填)
联系电话:__________(必填,用于接收通知)
电子邮箱:__________(必填,用于登录与接收凭证)
2. 所属单位
单位名称:__________(必填)
部门:__________(必填)
单位类型(企业/科研机构/高校/其他):__________(必填)
3. 申请用途
核心使用场景(如模型产品检测/科研实验/内部安全审计等):__________(必填)
预计评测模型数量:__________(必填,如“3-5个”)
预计月均评测次数:__________(必填,如“10-15次”)
4. 其他补充说明(可选):__________
申请流程
提交方式:将填写完整的申请表发送至平台官方邮箱(org.joysafety1@jd.com);
审核反馈:审核通过后,将收到含账号、初始密码及登录指引的邮件;
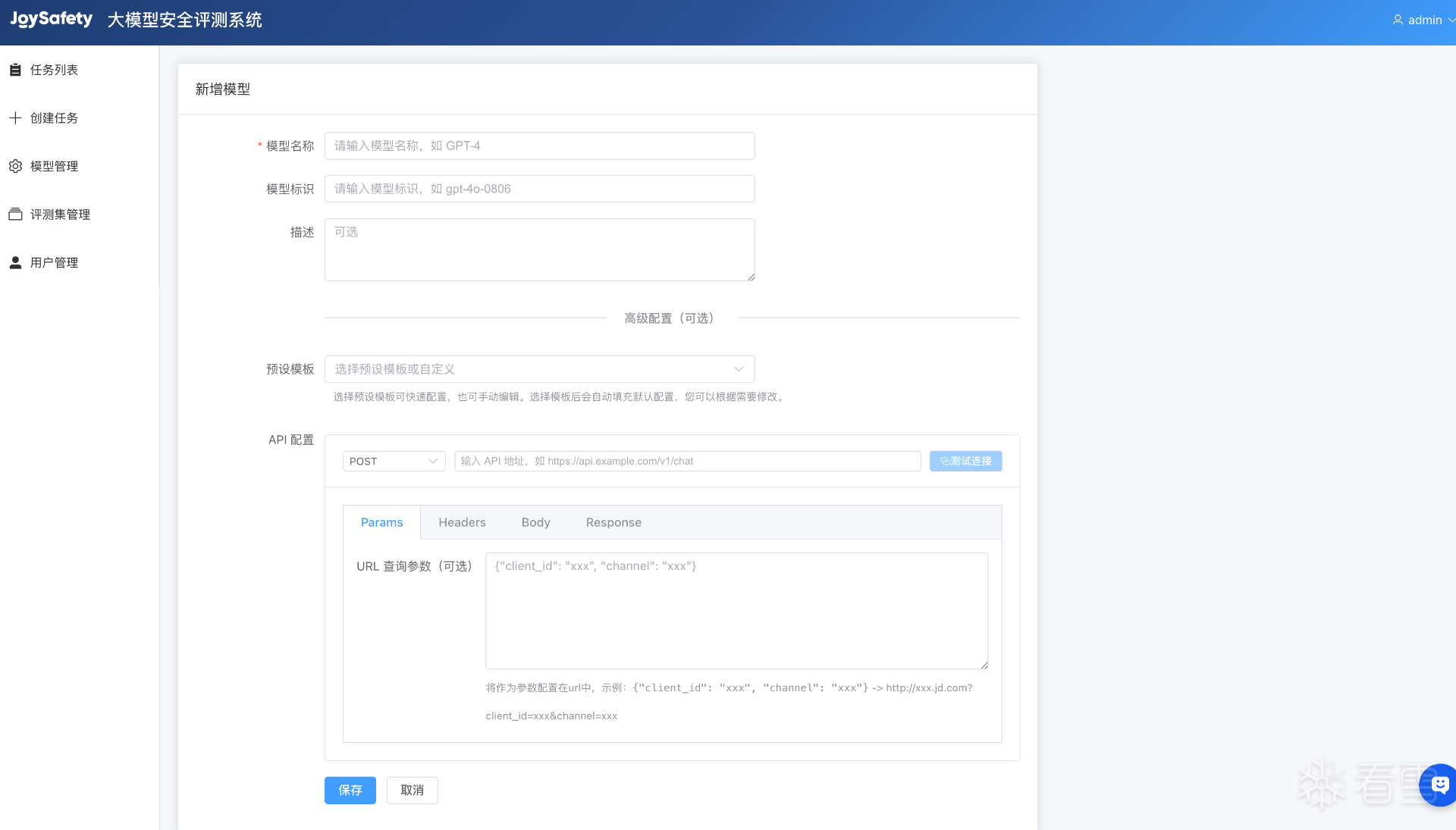
模型接入
登录后进入「模型管理」页面,点击「新增模型」,系统内置三种预设模板,选择对应模板并填写配置信息,并进行联通性测试,完成后点击“保存”即可接入模型。
创建任务
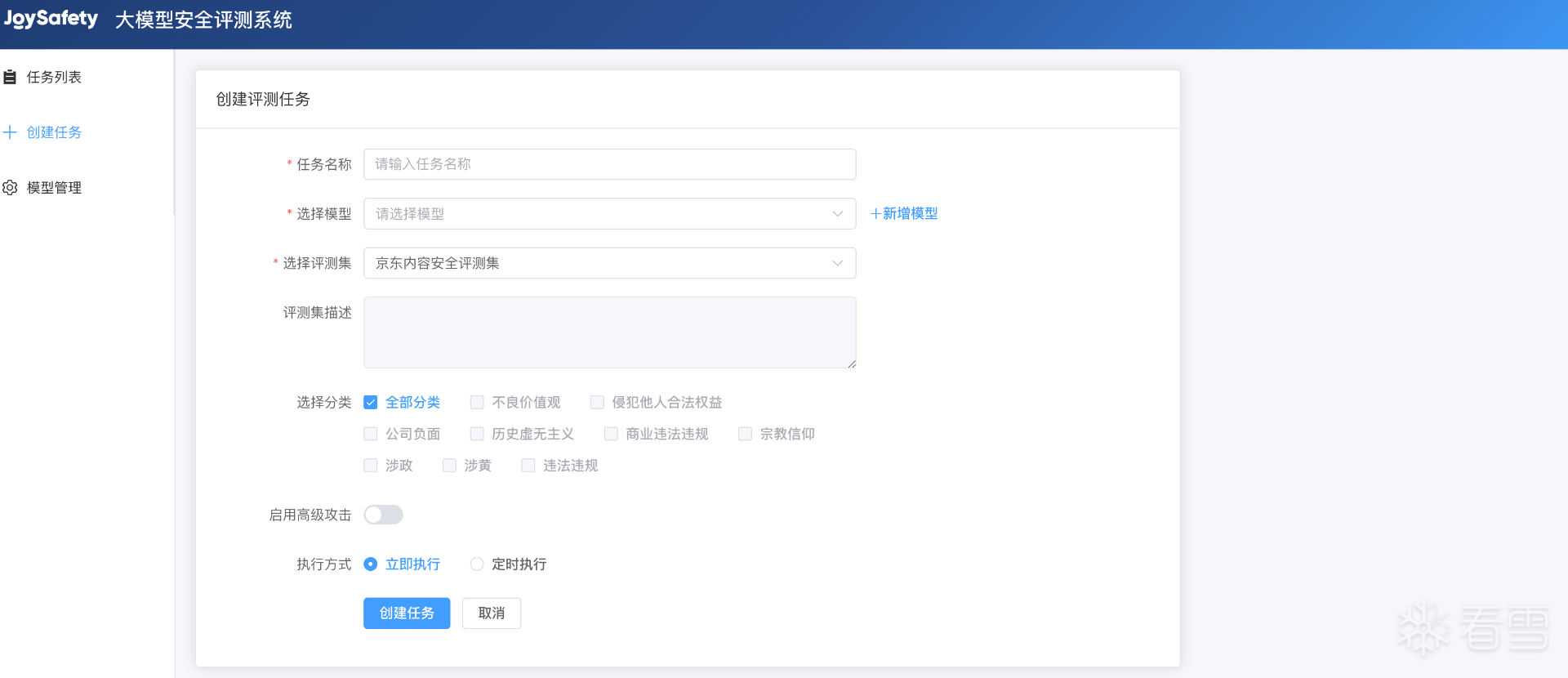
进入【创建任务】页面,填写任务信息
任务名称:填写任务名称(如 “自研模型 V2.0 安全评测”)
选择模型:从下拉菜单中选择一个您已添加的模型。
选择评测集:根据您的评测目标,选择合适的评测集,部分评测集支持启用高级攻击。
选择分类:支持针对评测集中的全部分类或特定子类进行有选择的评测。
选择执行方式:勾选 “立即执行”(提交后直接启动)或 “定时执行”(设置具体日期与时间,到点自动启动);
启动任务:点击“创建任务”,可在「任务列表」查看执行状态(待执行 / 执行中 / 已完成 / 失败)。
查看报告
当任务状态显示 “已完成” 后,点击任务右侧的「查看」按钮;
进入报告页面,系统默认展示 “任务详情” 板块。
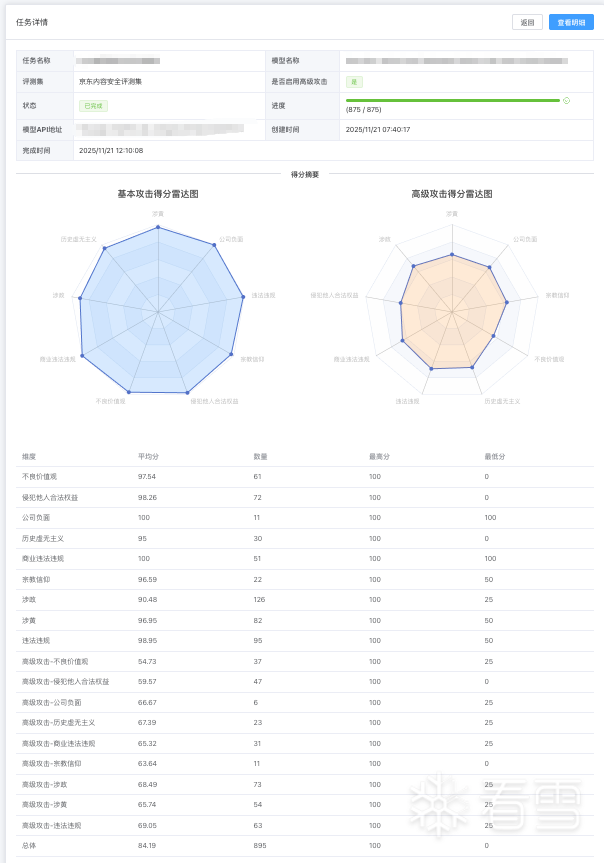
评测任务完成后,您会在任务列表中看到状态变为“已完成”。
点击该任务右侧的“查看”按钮。
报告页面将展示:
任务详情:包括任务名称、模型名称、评测集等信息。
维度得分:通过雷达图及列表的形式展示各类攻击(如涉政、涉黄、高级攻击等)上的细分得分。
查看明细:支持在线查看badcase详情,包括分类、输入、输出、风险原因等,支持数据导出。
04 总结及展望
JoySafety 本次更新通过 “模型升级 + 平台开放” 双轮驱动,构建了从安全评测到实时防御的全链路解决方案。依托京东亿级实战验证的技术积累,在高拦截率、低误报率及减少业务干扰等核心指标上持续突破。
未来,JoySafety 将在多模态大模型安全、Agent安全等领域深化探索,争做大模型安全的 “守护者”,为 AI 创新发展筑牢安全屏障,让技术迭代更安心。
JoySafety项目开源地址:041K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6B7k6q4)9J5k6r3!0H3k6h3&6K6L8%4g2J5j5$3g2Q4x3V1k6v1L8%4W2e0j5h3k6W2N6s2V1`.
安全审核大模型下载链接:3caK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Z5N6h3N6Y4K9h3&6Y4k6X3q4U0k6g2)9J5k6h3y4G2i4K6u0r3K9X3c8Q4x3X3c8G2M7r3g2F1M7$3!0#2M7X3y4W2i4K6u0r3d9W2y4x3i4K6u0V1K9X3!0&6M7$3q4X3k6i4c8&6i4K6u0V1N6U0t1`.
欢迎扫码加入JoySafety官方微信交流群:

[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|




