-
-
[讨论]JoySafety安全审核大模型重磅更新!提示词注入、多语种、多轮对话检测能力全面加码
-
发表于: 2025-10-28 10:44 1836
-

为应对大模型安全威胁日益复杂的挑战,继 2025 年 9 月 25 日在京东 JDD 大会首次发布后,JoySafety项目迎来首次重大升级 ——安全审核大模型V2.0 版本正式上线!本次更新聚焦 “防御强化” 与 “场景适配”,全面提升提示词注入防御精度、多语种覆盖广度及多轮对话风险识别深度,为企业构建 “智能 + 全面 + 可靠” 的大模型安全护城河。
一、安全审核大模型介绍
京东安全审核大模型(JSL-joysafety)是基于Llama3.2 、GPT-OSS架构开发,在 140 万高质量审核样本上完成端到训练,提供 1B / 3B / 8B / 20B 四档参数规模,可灵活适配云-边-端全场景部署,核心特性聚焦五大维度:
1、业界最全风险识别链路
覆盖 “输入 - 输出 - 会话 - 格式” 全流程,无死角拦截风险:
- 输入侧:用户 Query 实时检测,秒级识别潜在恶意请求;
- 输出侧:模型生成内容实时校验,避免有害信息泄露;
- 会话侧:多轮上下文关联分析,捕捉跨轮次隐藏风险;
- 格式侧:原生兼容 OpenAI 对话协议,完整日志一键导出送审,降低业务对接成本
2、三级标签 + 处置建议 + 可解释链
- 三级风险标签:按 “类别 - 子类 - 细项” 划分,粒度为业界最细(如 “涉黄 - 色情出版物 - 色情网站”),精准定位风险类型;
- 配套决策支持:每条风险告警同步输出 “处置建议”(如 “拦截并提示合规话术”)与 “风险推理链”(如 “触发依据:含‘色情诱导’关键词”),业务方可一键溯源,可解释性极强。
3、系统化提示词注入防护从战术、路径、阶段、可见性、手法五大维度立体拆解注入攻击,覆盖 50 + 主流攻击方式:
- 战术识别(injection_tactic):精准判断 “越狱(jailbreak)、目标劫持(target-hijack)、内容注入(content-inject)、越权” 等攻击意图;
- 路径区分(injection_path):识别 “直接注入”“外部间接携带”(如通过链接、文件)等攻击路径;
- 阶段跟踪(injection_stage):支持 “单轮、多轮、跨会话” 全阶段攻击检测;
- 可见性还原(injection_visibility):破解 “明文、编码、混淆、分段隐藏” 等伪装手段;
- 手法覆盖(injection_methods):全量拦截 “忽略前置指令、系统伪装、间接诱导、重复扰动、格式隐藏” 等 50 + 攻击手法。
4、12 种主流语言原生支持:
无需外挂翻译工具,中、英、西、德、日、法、韩、俄、阿、葡、意、土 12 种语言同步对齐训练,确保多语种场景下风险检测效果无损。
5、11 大风险域全景覆盖:
一网打尽大模型核心安全风险,包括:涉政、涉黄、暴恐、涉毒、涉赌、违禁(如管制刀具)、辱骂、歧视(种族 / 性别 / 地域)、虚假消息(如谣言)、商业违规(如虚假宣传)、恶意代码执行(如注入恶意脚本)。
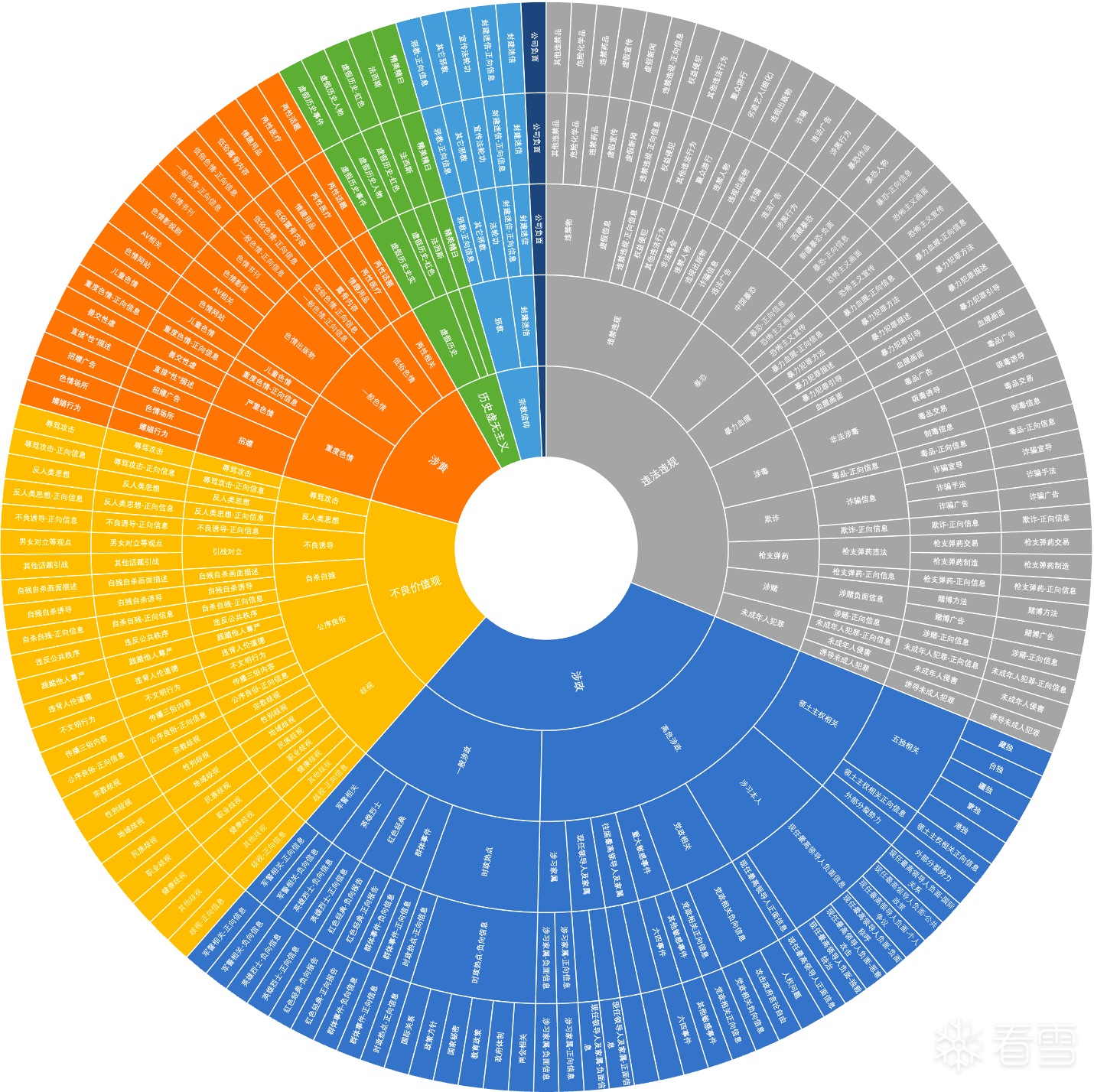
二、训练语料:140 万条高逼真、高对抗语料构建
JSL-joysafety V2.0 训练语料库共 140 万条,覆盖 “用户 Query、模型回复、单轮对话、完整多轮对话”4 类场景,Safe/Unsafe 样本按 7:3 比例混合,通过 “六维交叉矩阵”+“蓝军生成”+“三重校验” 确保多样性与可靠性。
1. 六维交叉矩阵:覆盖全场景风险
从 六个维度构建样本多样性,避免模型偏科:
维度 | 具体覆盖内容 |
领域标签 | 通用问答、法务、健康、政务、医疗、教育、电商、游戏、金融等 18 个垂直领域 |
风险类型 | 11 大类→130 细类(如 “涉赌 - 网络赌博 - 棋牌赌博推广”) |
注入手法 | 50 + 主流提示词注入手法,支持 “手法 - 风险” 二维联合采样(如 “间接诱导 + 涉黄”) |
语种 | 12 种主流语言,语料占比与全球互联网母语人口对齐 |
对话类型 | 单轮、多轮、角色扮演、任务型、开放式 5 类(后续将补充 Agent 任务场景) |
对话轮数 | 1-15 轮均匀分段,长对话(≥8 轮)采用滑动窗口采样,保证上下文连贯性 |
2. 蓝军 Agent 自动生成:逼近真实攻防前沿
Unsafe 样本中 90% 由 “数据合成蓝军 Agent” 生成,实现 “情报 - 变异 - 生成” 闭环:
- 核心引擎:基于蓝军大模型,实时调用 Deep Search 抓取公开威胁情报(如最新越狱手法、黑产话术);
- 生成能力:通过角色扮演(如 “黑客诱导模型输出恶意代码”)、场景模拟(如 “电商平台虚假宣传对话”)、风格克隆(模仿真实用户提问风格),批量生成高逼真恶意 Query;
- 变异增强:从 “危害程度”(递进式提升风险等级)和 “攻击手法”(注入最新越狱技巧)双维度强化,扩展攻击覆盖面与成功率。
3. 多轮对抗会话合成
以单轮 “恶意 Query - 有害 Response” 为基础,通过 “蓝军模型(攻击者)vs 靶场模型(受害者)” 自动扩展多轮对话,核心机制包括:
- 状态记忆:每轮保留角色立场(如 “攻击者坚持诱导越狱”)与攻击目标;
- 策略演进:根据上一轮回复动态切换注入手法(如 “首次 jailbreak 失败后,改用‘分段编码’逃逸”);
- 风险递进:若触发安全机制,自动启用 “混淆 + 分段 + 编码” 组合策略,压低触发率直至生成成功。
4. 三重校验:确保样本高质量
通过 “多维打标→蒸馏筛选→人工复核” 三重流程,沉淀高置信样本:
- 多维打标:标注 “对话类型、角色属性、风险领域、攻击手法”,并通过 Sentence-BERT 1024 维向量 + HDBSCAN 自动去重,优先保留 “高危罕见样本”(低密度区)与 “高争议样本”(模型置信度 40%-60%),确保分布覆盖长尾风险;
- 蒸馏筛选:以 “Prompt 工程 + 通用大模型 + 开源 Guard 模型” 为教师模型,生成 “风险标签 + 三级子类 + 处置建议 + 推理链”,通过 “一致性投票 + LLM as Judge” 筛选高可用结果;
- 人工复核:按 “标注员→质检员→安全专家” 三级校验,争议样本由安全专家委员会仲裁,通过率≥98% 方可入库,未通过样本回流至蒸馏环节迭代。
三、训练技巧:兼顾效果与效率的三大核心策略
1、“由易到难”课程学习(Curriculum Learning)
避免模型初期被复杂样本 “劝退”,分阶段提升训练难度:
- 难度量化:难度分 = 0.7× 标准化语义困惑度 + 0.3× 标准化攻击手法复杂度(攻击手法按 CVSS-style 评分,0-10 分),映射为 D1-D5 五级;
- 课程设计:按 D1→D2→D3→D4→D5 递进,每级训练 4k steps,共 20k steps;
- 防遗忘机制:进入新难度后,回放 10% 上一阶段最高困惑度样本,避免灾难性遗忘。
2、“由短到长”上下文拓展
适配长对话场景,分阶段扩展上下文长度:
- 样本分组:按 1K→4K→8K→16K→32K 上下文长度分组;
- 训练阶段:实际按 8K→16K→32K 三阶段训练;
- 记忆刷新:切换长度时,回放 10% 上一长度最难样本,巩固长程依赖识别能力。
3. 多语种混合训练
提升多语种场景鲁棒性:
- 语种配比:中文 36%、英文 28%、其余语种 4%-6%;
- 混合增强:随机在 15% 样本中插入跨语种提问(如 “用户先用中文问‘如何买刀’,再用英文补充‘where to buy a knife’”),模拟真实多语种对话场景。
四、行业 SOTA 对比:核心指标领先
对比维度 | JoySafety V2.0 | 行业同类模型 |
支持语种 | 12 种主流语言(原生支持) | 多为中 / 英双语,需外挂翻译 |
检查风险项目 | 11 大类→130 细类(全景覆盖) | 平均覆盖 6-8 大类,细类颗粒度粗 |
风险等级划分 | 三级(安全 / 有争议 / 不安全)+ 处置建议 | 仅区分 Safe/Unsafe,无决策支持 |
支持检测场景 | 用户输入、模型输出、多轮对话 | 多仅支持用户输入检测,单轮对话检测 |
最大模型规模 | 20B(适配云部署) | 多为 8B 及以下,大参数模型少 |
可解释性 | 提供风险推理链 + 溯源日志 | 多无明确可解释依据 |
五、欢迎关注与交流
欢迎扫码加入JoySafety官方微信交流群:

更多技术细节,欢迎10月29日18:00-19:00来线上直播间交流!

[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|




