-
-
[原创]入门实战-某居客nsign参数分析
-
发表于: 2025-11-11 14:39 1680
-

某居客nsign参数分析
版本:17.15.8
java层分析
算法定位
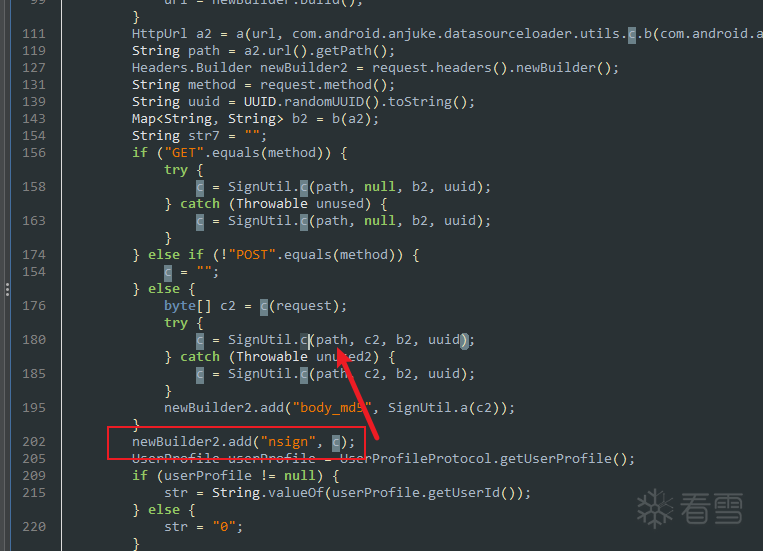
nsign参数很好寻找,jadx中可以直接搜索到

发现他是走了一个getSign0的native函数
定位so
通过frida进行定位一下这个native函数具体在哪个so中,frida代码方式不少,我是通过枚举模块的导出表实现定位

so层分析
简单概览参数和返回值分析
getSign0中可以看到,主要是get_sign函数,和一些写入字节操作
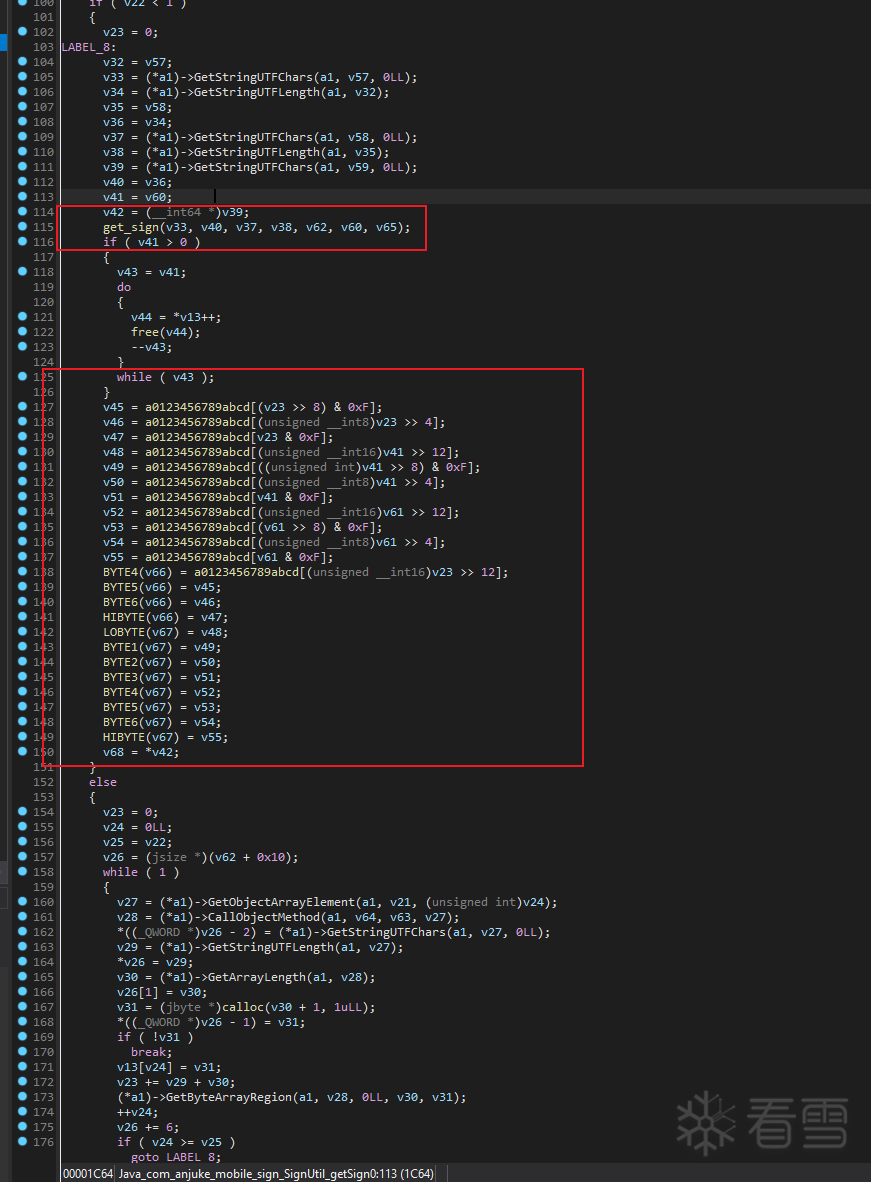
get_sign中可以看到,应该就是md5,然后可能做了一些额外处理
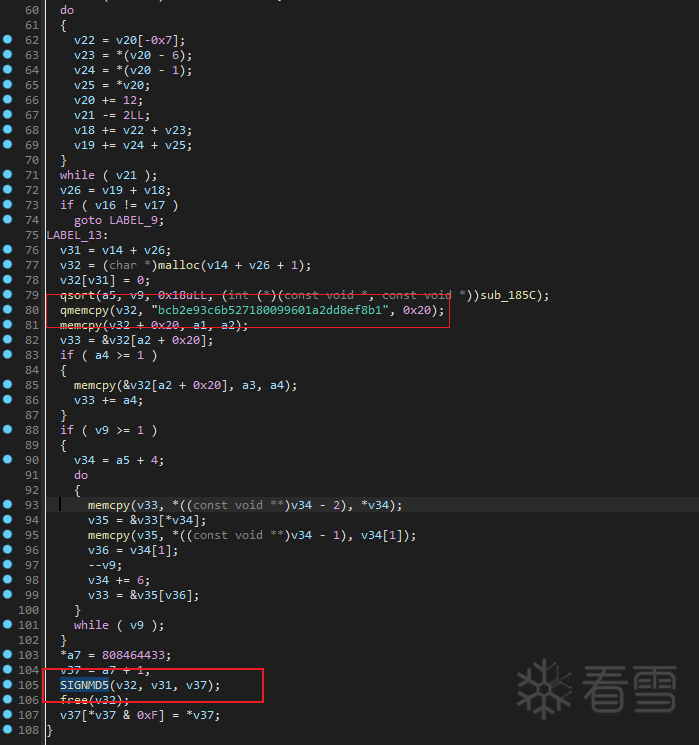
frida 打印get_sign函数,还有SIGNMD5函数的参数和返回值,观察一下,发现具体如下:
- 通过
get_sign生成了前面的加密值 - 通过自定义逻辑,生成后面
20位加密值
get_sign函数分析
SIGNMD5函数返回值 : a402a74775c3b95f14e7dc4468eb8d25
SignUtil.getSign0 返回值: 1000 aa02a74775c3b95f14e7dc4468eb8d25 01b20014000087d34a82
看的出来,md5就是第二段,但是第二个字节存在区别,这里我们直接分析一下反编译的c代码
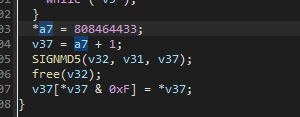
get_sign函数是通过a7这个指针进行返回数据SIGNMD5函数是通过v37指针进行返回数据
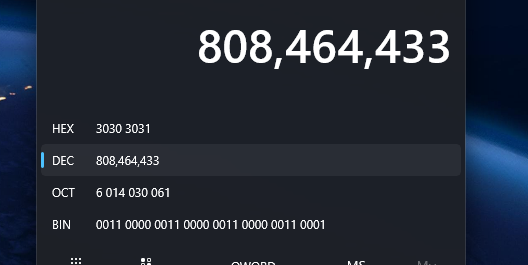
*a7 = 808464433;
表示修改a7指针指向的数据为固定值808464433
这个值转成二进制是 如图
v37 = a7 + 1;
v37 和a7都是指针,+1 表示指向位置加上一个int类型大小,而64位系统中,一个int表示4个字节
所以上述这里,其实是两个指针指向类似同一块数据地址,前面是固定值,后面是SIGNMD5函数返回值的拼接,
固定值: 就是从低到高数的字节, 31 30 30 30, 观察一下hexump内容和计算器内容,二者是一致的
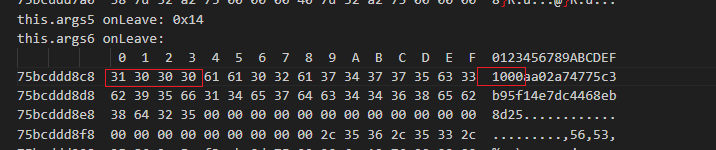
v37[*v37 & 0xF] = *v37;
v37是_BYTE指针, 它指向md5返回的数据
所以*v37就是表示取出指向的地址的第一个字节
所以就很清楚了 : 第一个字节的低 4 位当作索引,把该字节复制到 MD5 结果中的某个位置

所以原本md5 = a402a74775c3b95f14e7dc4468eb8d25
转换后 = aa02a74775c3b95f14e7dc4468eb8d25
生成后20位加密值分析
一个个参数进行分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | v45 = a0123456789abcd[(v23 >> 8) & 0xF];v46 = a0123456789abcd[(unsigned __int8)v23 >> 4];v47 = a0123456789abcd[v23 & 0xF];v48 = a0123456789abcd[(unsigned __int16)v41 >> 12];v49 = a0123456789abcd[((unsigned int)v41 >> 8) & 0xF];v50 = a0123456789abcd[(unsigned __int8)v41 >> 4];v51 = a0123456789abcd[v41 & 0xF];v52 = a0123456789abcd[(unsigned __int16)v61 >> 12];v53 = a0123456789abcd[(v61 >> 8) & 0xF];v54 = a0123456789abcd[(unsigned __int8)v61 >> 4];v55 = a0123456789abcd[v61 & 0xF];BYTE4(v66) = a0123456789abcd[(unsigned __int16)v23 >> 12];BYTE5(v66) = v45;BYTE6(v66) = v46;HIBYTE(v66) = v47;LOBYTE(v67) = v48;BYTE1(v67) = v49;BYTE2(v67) = v50;BYTE3(v67) = v51;BYTE4(v67) = v52;BYTE5(v67) = v53;BYTE6(v67) = v54;HIBYTE(v67) = v55;v68 = *v42; |
a0123456789abcd 函数简单看了一下,其实就是将内容转化为十六进制字符
而内部的(v23 >> 8) & 0xF这种位移操作,本质上就是通过位移,将数据存储到不同的位上,而且观察代码可以知道,他还是一个数据,切成了4位
最后20个字符,0123456789abcdef,所以分析代码得知如下:
01b200140000=> 12个字节:01b2= 434 : map循环 len(key) + len(value)0014= 20 : map.size()0000= 0 : 最后一个参数i值
89abcdef
可以看到v68直接赋值了*v42,

也就是说,89abcdef就是取的str3参数的前64位,也就是8个字节
总结
自此nsign所有分析都完成了,没有什么加固混淆,整体分析流程都是最基本的frida+ida,适合新手入门
后续还可以借助unidbg进行算法还原学习
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
赞赏
|
|
|---|---|
|
|
|

- [原创]编译和链接、装载过程 1988
- [原创]入门实战-知乎x-zse-96参数分析 22445
- [原创]入门实战-Rui幸app白盒aes 19720
- [原创]入门实战-某居客nsign参数分析 1681



