首次遇到OLLVM时是校队转正比赛的压轴题, 当初不懂这是什么骚操作, 侥幸因为题目使用RC4加密, 通过侧信道方式爆破出了flag
后来了解到D810等去混淆脚本, 针对OLLVM中较为基础的指令替换, 虚假控制流和平坦化没有问题, 久而久之顶着混淆硬看也不是不行
再后来遇到了BR混淆即间接跳转(Indirect Branch)混淆, 学了一阵子大佬思路和脚本云里雾里, 始终不明白其原理, 到底有哪些特例
直到决心沉住气阅读源码, 调试几遍, 似乎也没有当初想的那么难
闲话少说, 希望本文能抛砖引玉, 对入门OLLVM的师傅有所帮助
本文按顺序阅读即可, 实践体会从LLVM到OLLVM的流程并解决问题非常重要, 一定要多动手和调试
环境:
本文主要包括以下部分:
其中1-5为基础部分, 6为重点部分
文章附件 ollvm-study-attachments.zip :
注意:
本文最初基于llvm-18.1.8, 使用fla混淆时遇到无法修复的bug, 遂改用llvm19
如遇文中涉及llvm18的文字或图片请默认替换为llvm19
不同机器和平台上可能遇到不同问题, 本文以Windows 10平台为主
使用LLVM和OLLVM仅需要Release模式编译clang即可(占用空间小)
调试时需要Debug模式编译llvm,clang,lld(占用空间大,约100G)
LLVM 官网下载 04eK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6J5k6h3I4W2j5i4y4W2M7#2)9J5k6h3I4D9N6X3#2Q4x3X3g2G2M7X3M7`. github链接 29dK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9L8s2k6E0i4K6u0r3L8r3I4$3L8g2)9J5k6s2m8J5L8$3A6W2j5%4c8Q4x3X3g2Y4K9i4b7`.
NDK 28.2.13676358 对应 clang 19.0.1
NDK 27.3.13750724 对应 clang 18.0.4 (本文后续涉及到该版本NDK请替换为上述版本)
可以到 878K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9L8s2k6E0i4K6u0r3L8r3I4$3L8g2)9J5k6s2m8J5L8$3A6W2j5%4c8Q4x3V1k6J5k6h3I4W2j5i4y4W2M7H3`.`. 查看是否有一致的版本,如果没有可以拉取最近的版本
拉取距离最近的19.1.7版本 (--depth 1 指定浅克隆, 不保存历史更改记录)
编译LLVM参考 243K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2L8%4u0Y4i4K6u0r3k6r3!0U0M7#2)9J5c8V1N6W2N6s2c8A6L8X3N6e0N6r3q4J5N6r3g2V1i4K6u0W2K9s2c8E0L8l9`.`.
主要分为2步:
windows平台编译clang有2种方案: 使用msvc或mingw 不同方案编译得到的clang行为会略有不同
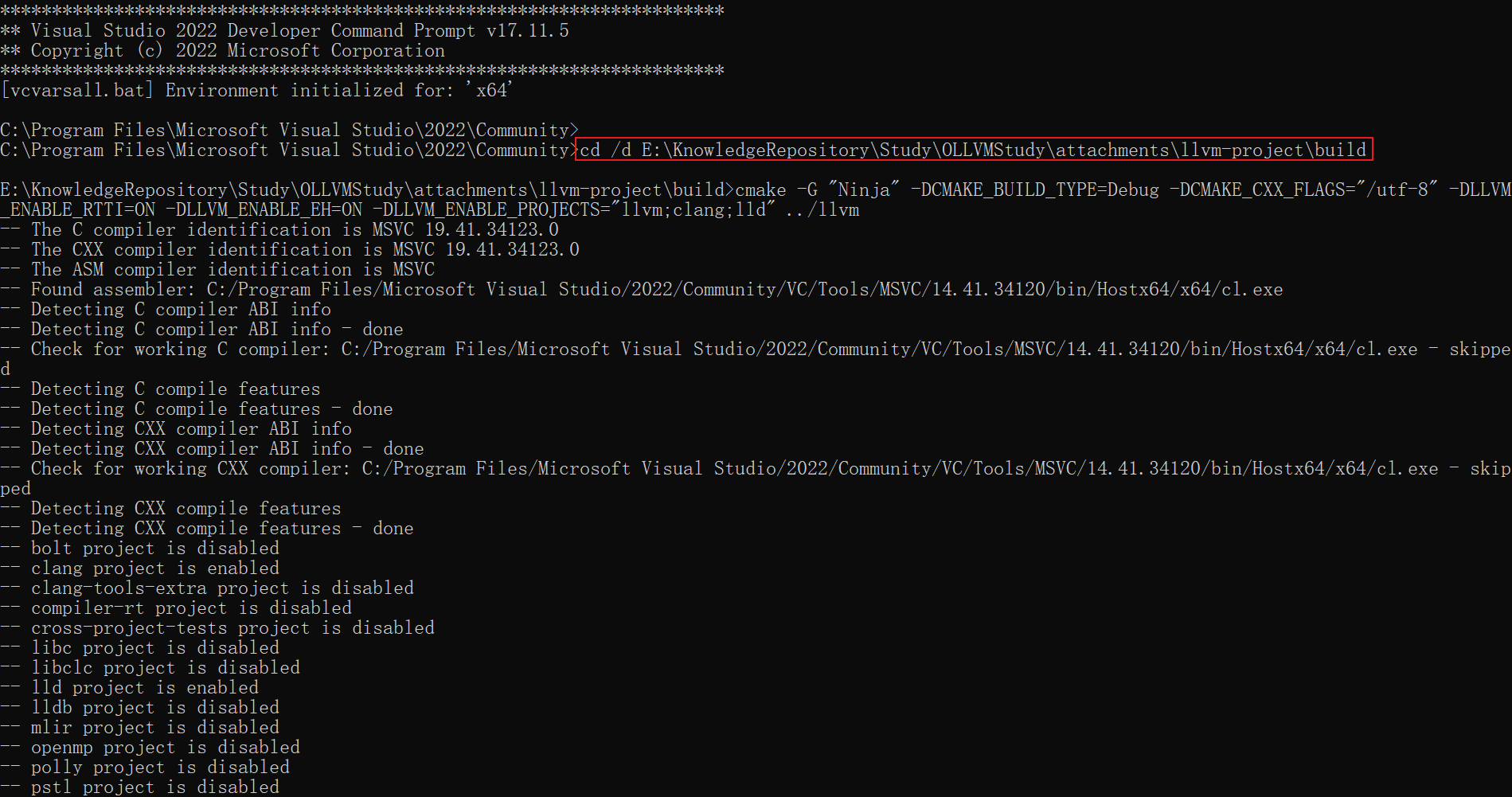
本文以msvc为例, 安装Visual Studio 2022后, 搜索MSVC命令行工具并打开
进入llvm/build目录, 注意cd命令需添加/d参数进行跨分区跳转
参考windows下命令行模式中cd命令无效的原因
之后使用cmake初始化ninja构建配置
参数的具体作用如下:
-G "Ninja" 指定构建系统Build工具
-DCMAKE_BUILD_TYPE=Debug
指定构建类型为 Debug 模式,包含调试信息,不启用优化,便于开发和调试
-DCMAKE_CXX_FLAGS="/utf-8"
-DLLVM_ENABLE_RTTI=ON
-DLLVM_ENABLE_EH=ON
-DLLVM_ENABLE_PROJECTS="llvm;clang;lld"
../llvm
执行这条命令后,会在当前目录(build)生成 Ninja 构建文件,之后可以使用ninja命令进行编译构建
Debug模式编译完成后有100G+,需预留足够空间
编译完成后进入bin目录验证是否正常运行
安装cmake和ninja用于构建llvm项目
拉取llvm源码项目
cmake配置构建设置 (release版)
如果配置debug版
构建项目
将clang所在bin目录临时添加到PATH
注意: 使用clang时需要指定系统sdk路径, 否则clang会报 "can't find "<stdio.h>" 等错误, 例如
大部分文章基于linux编译llvm, 先安装依赖后拉取llvm源码编译即可, 此处不多赘述
可参考 从llvm到ollvm学习笔记 和 [原创]llvm学习笔记——llvm基础
使用前可将编译好的clang所在bin目录添加到环境变量
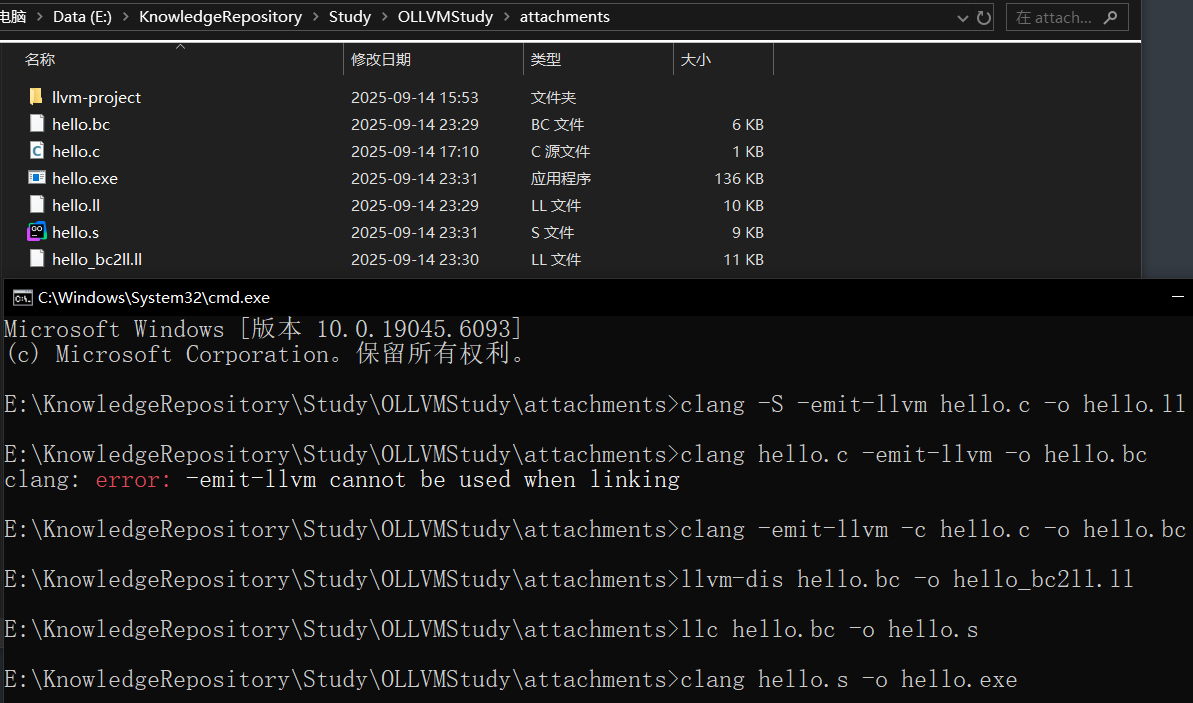
hello.c代码如下
编译
运行
使用CLion打开clang/CMakeLists.txt, 并选择作为项目打开
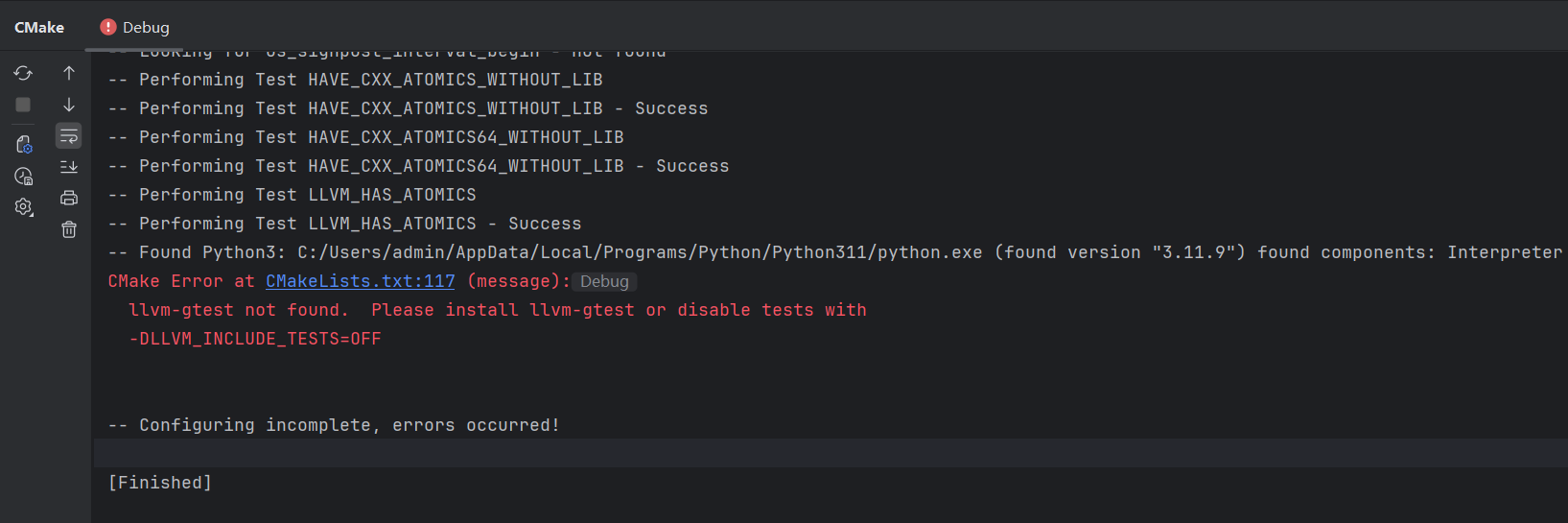
此时发现报错如下,这个错误表明 CMake 在配置 LLVM 项目时找不到 llvm-gtest,因此无法继续
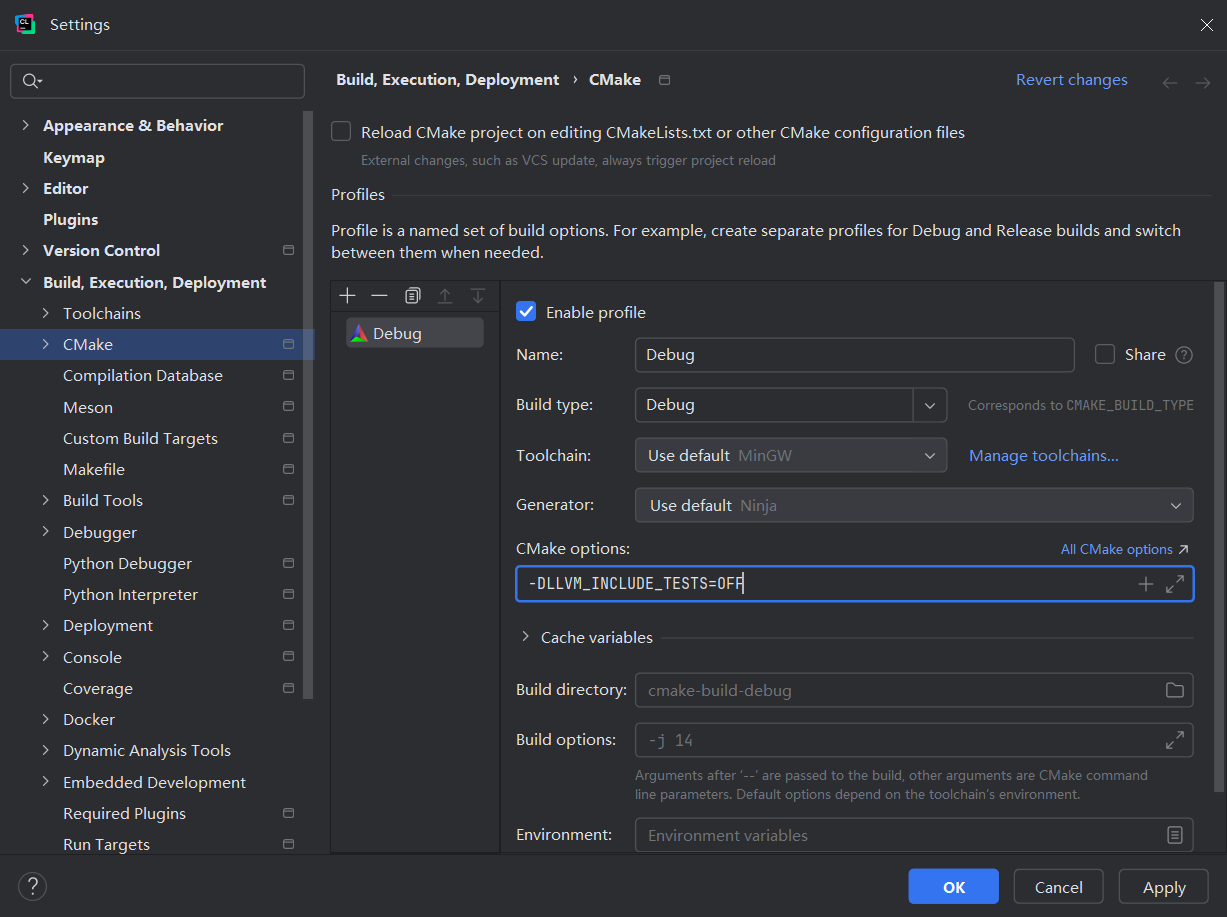
由于不需要运行测试,可通过添加CMake配置参数 "-DLLVM_INCLUDE_TESTS=OFF" 跳过测试模块
另外在Windows平台建议将默认的编译工具链Toolchain由MinGW替换为Visual Studio, 保证兼容性防止出现bug
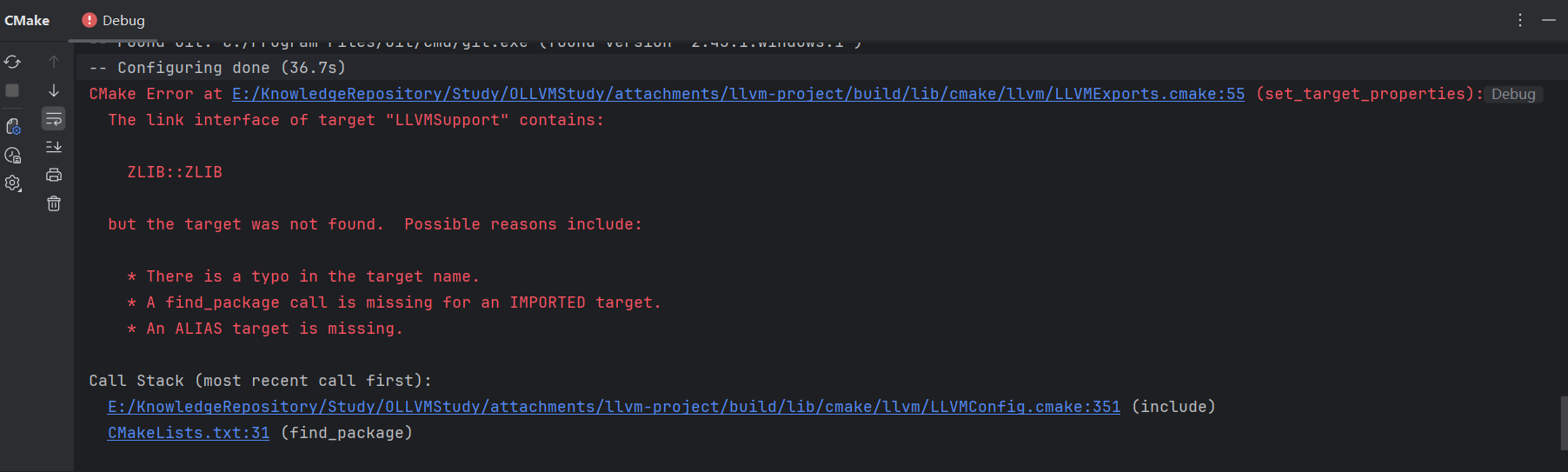
之后遇到第2个报错,原因是缺少zlib库
参考文章Windows中zlib的安装与配置
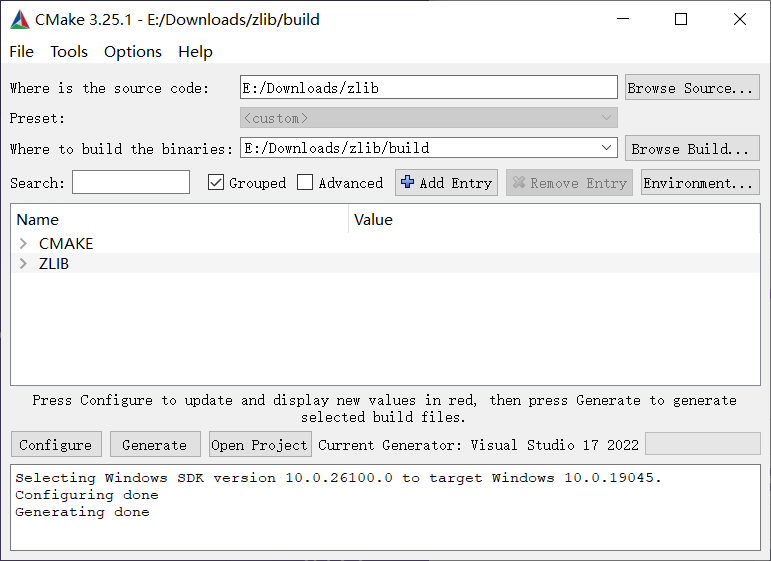
首先拉取zlib源码
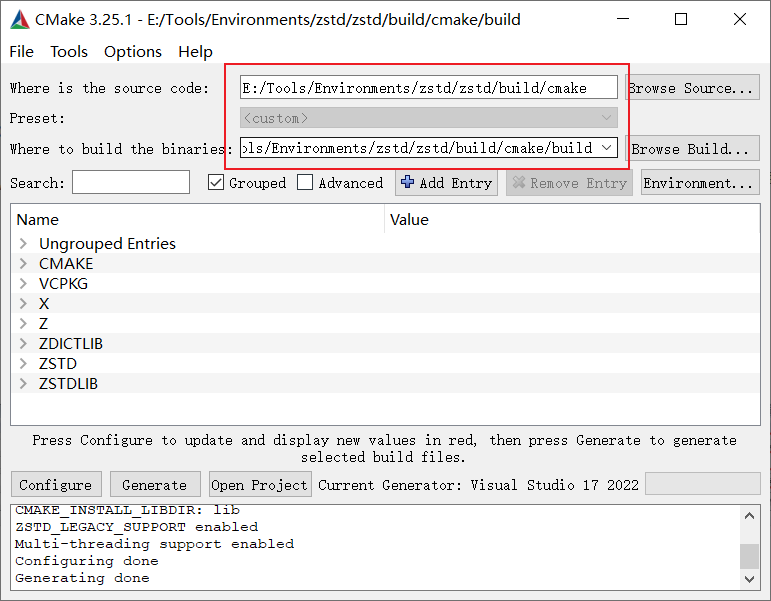
再打开CMake-gui
分别输入zlib的源码路径和build路径, 之后依次点击左下方Configure,Generate
中间文本框可能出现红色,此时再次点击Configure和Generate消除红色即可
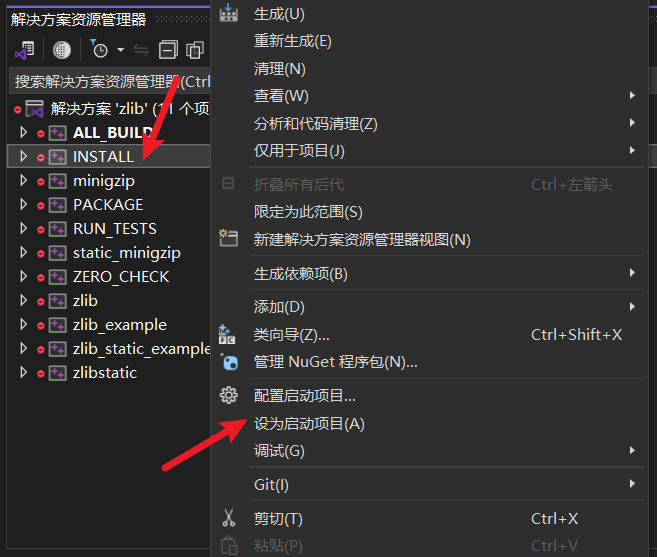
最后点击Open Project,使用VS打开项目
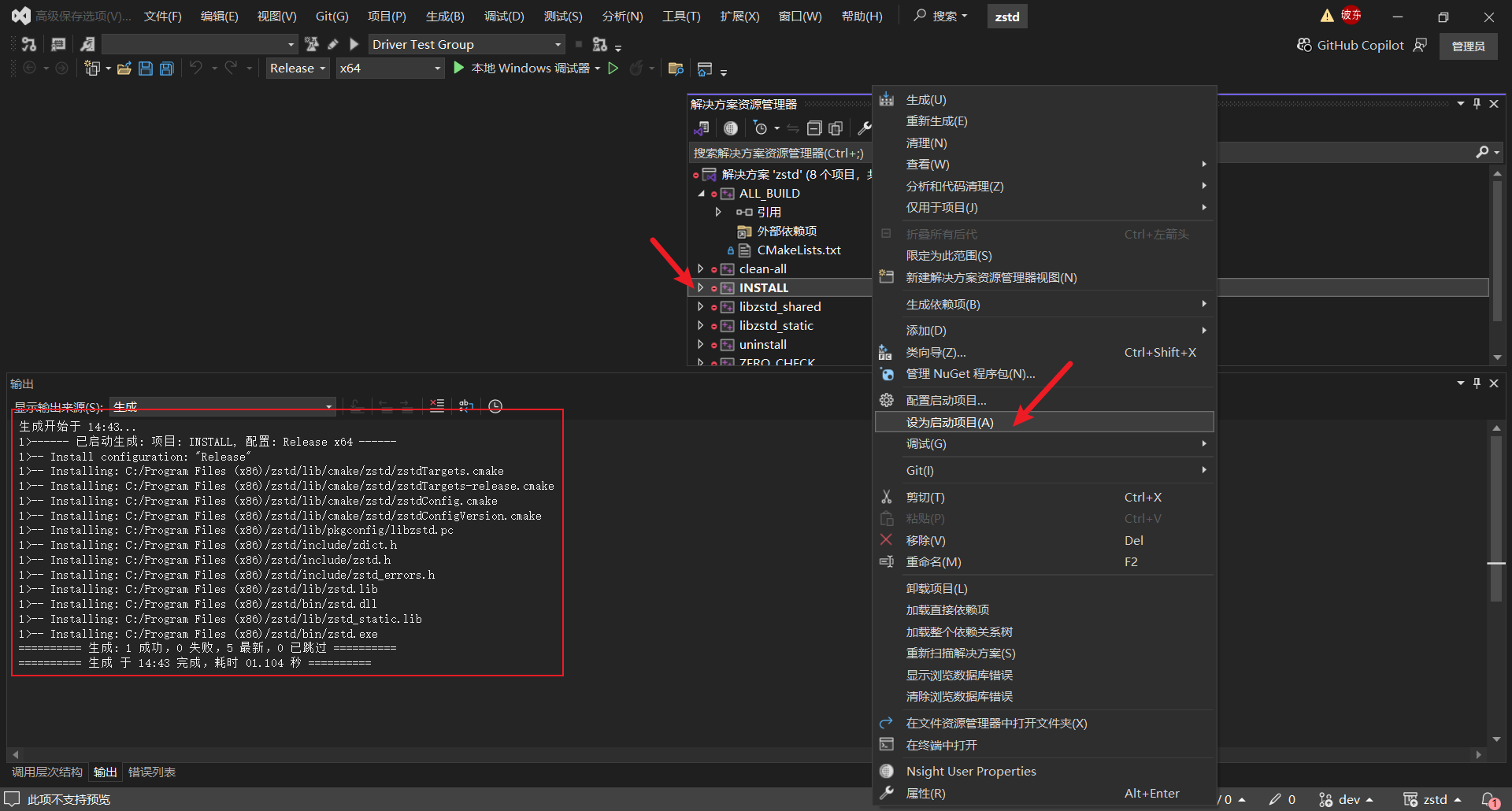
首先右键INSTALL项目并设为启动项目
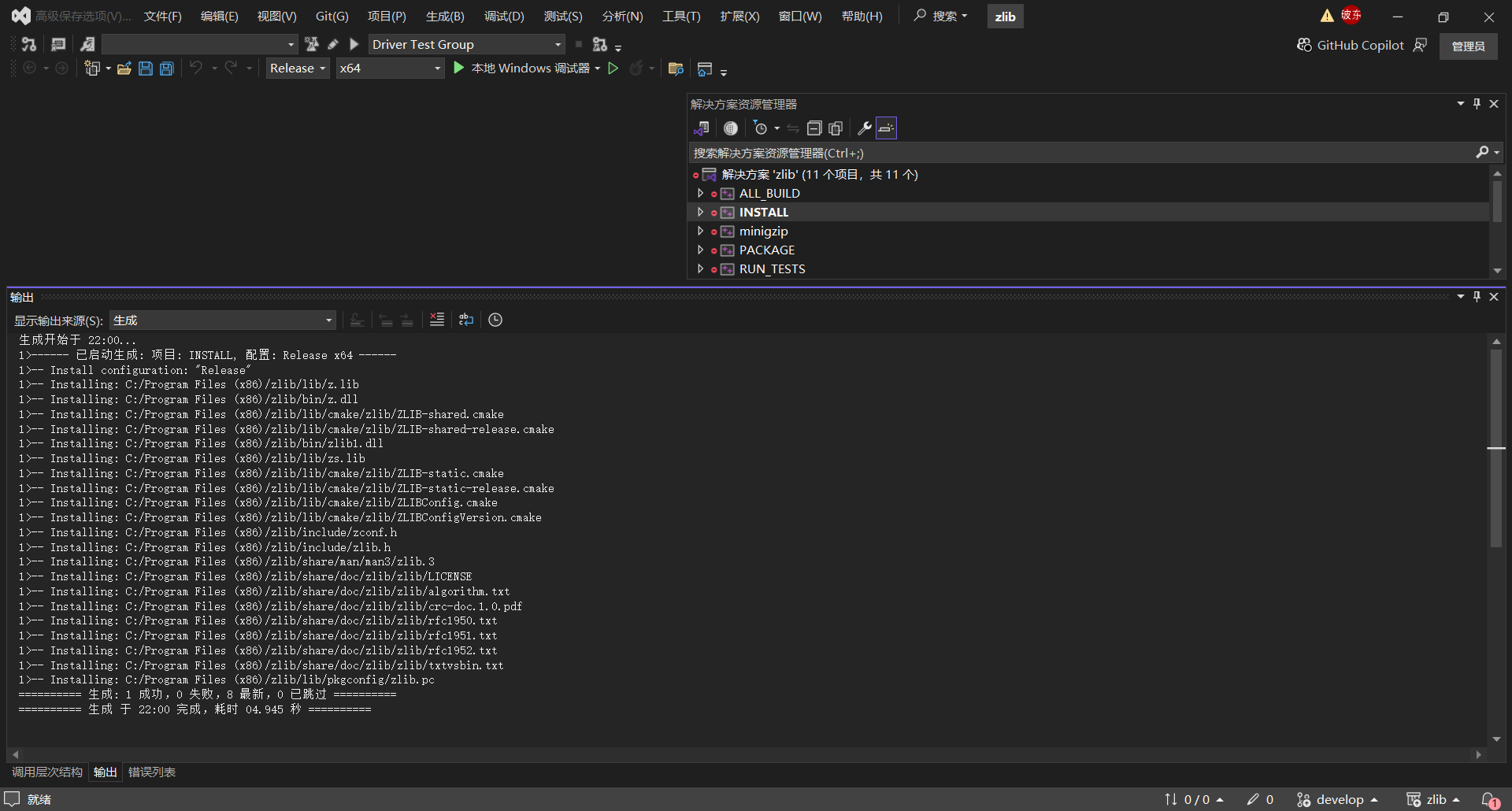
再选择Release模式Build INSTALL项目,成功后显示如下:
注意: 此处由于需要将编译后的zlib库写入系统核心区,可能会报错如下
这个问题是由于权限不足,只需要手动用管理员权限打开VS并重新Build即可解决
解决zlib后紧接着又出现了zstd库的问题
参考windows环境下zstd编译 , 编译流程类似zlib
zstd源码项目解压后,在build/cmake中有CMakeLists.txt
编译完成后以管理员权限运行VisualStudio, 打开~zstd\build\cmake\build\zstd.sln
同安装zlib时类似,先生成再设置INSTALL项目为启动项目进行安装便可以解决问题
std库安装成功后输出如下
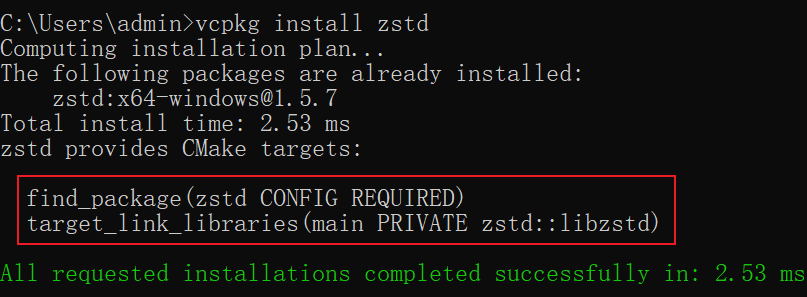
然而此时仍会报错,CMake没有找到zstd,需要手动添加find_package指明zstd
大功告成之后,可以看到LLVM的项目
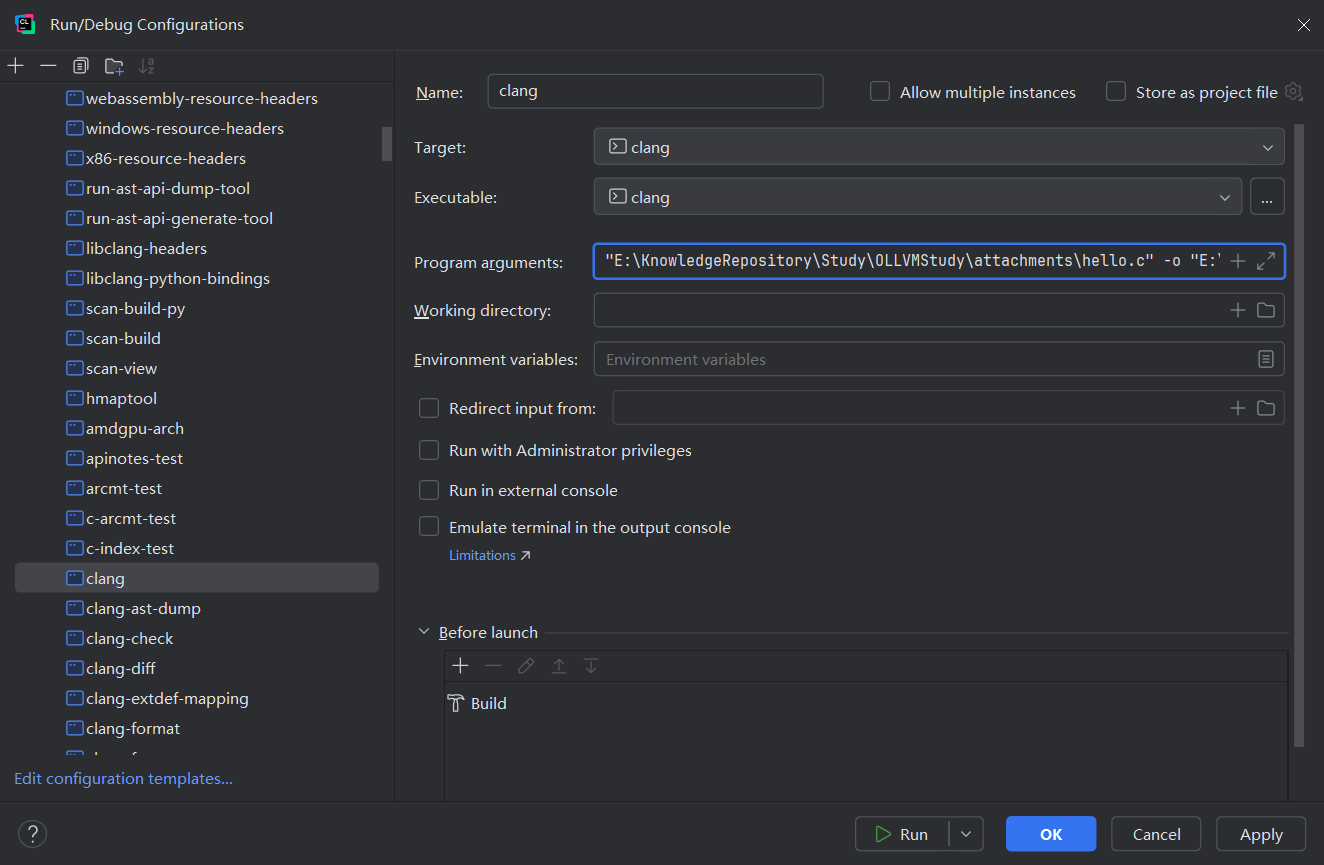
debug前先设置clang的debug配置,添加启动参数,实际上就是保证启动时执行以下编译命令(参数输入clang后面的部分即可,CLion调试时自动拼接):
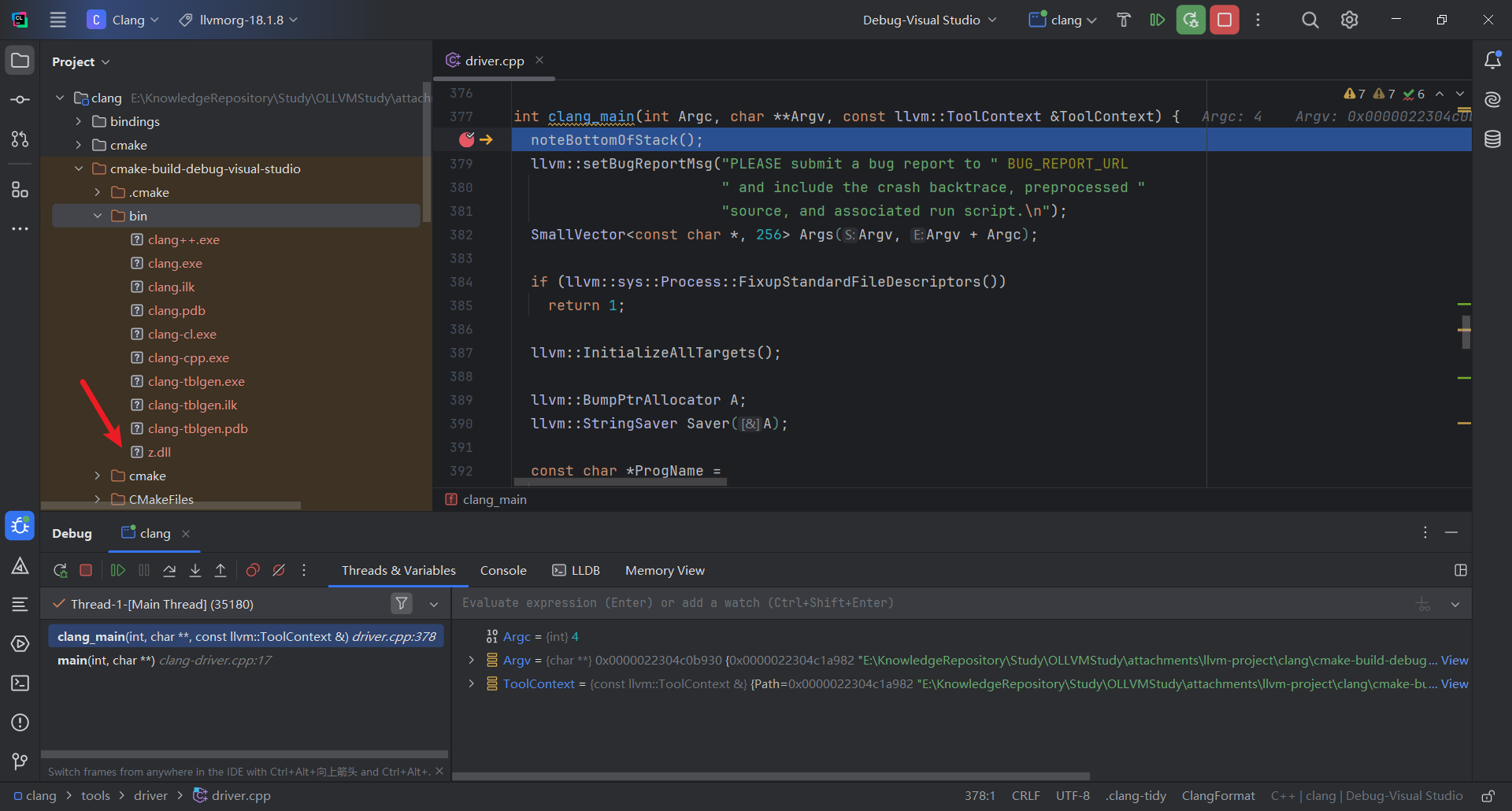
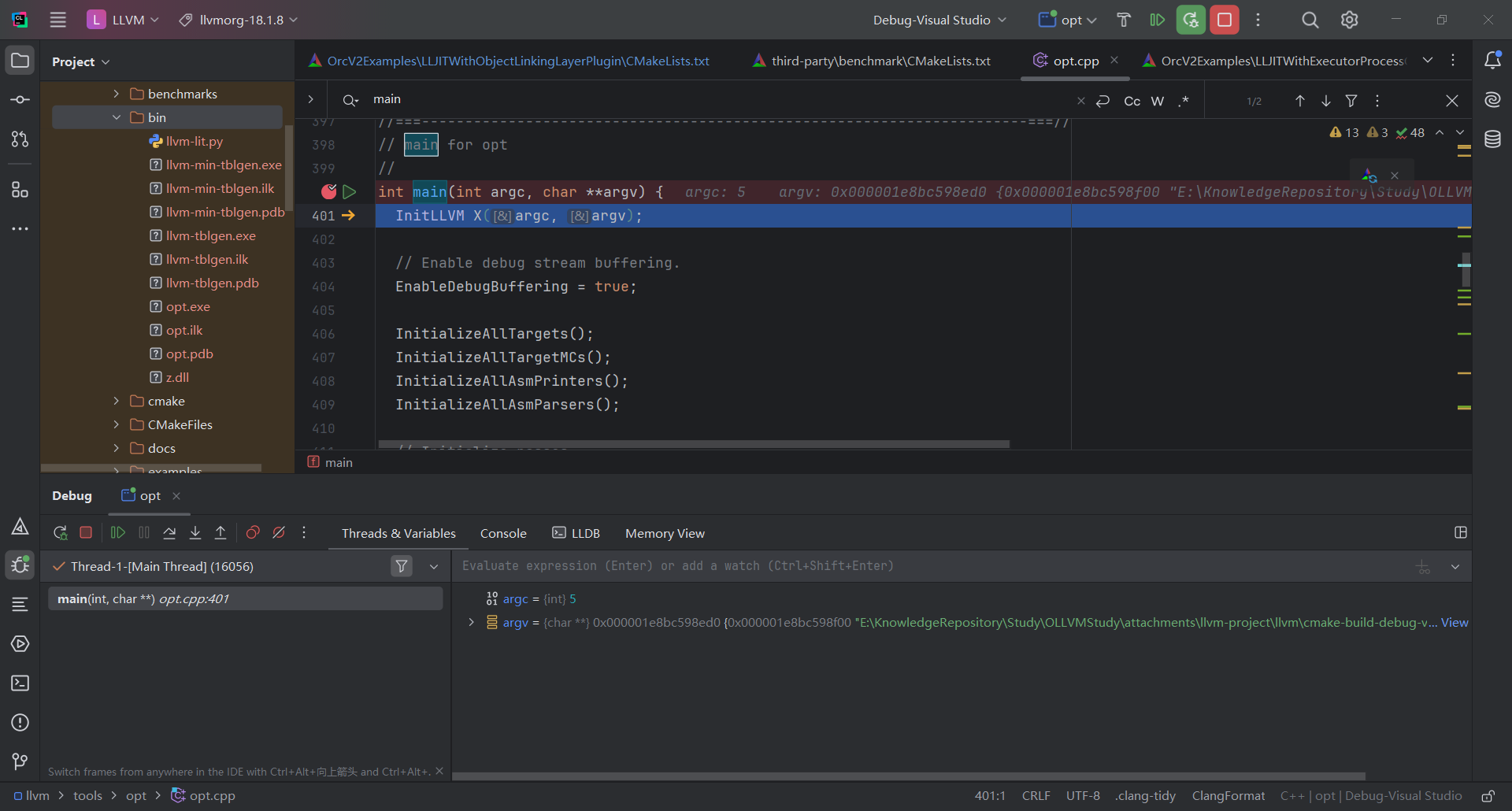
之后找到clang_main并下断点调试 (clang/tools/driver/driver.cpp)
注意: 调试时CLion会重新编译一次clang,需要花费一定时间和空间
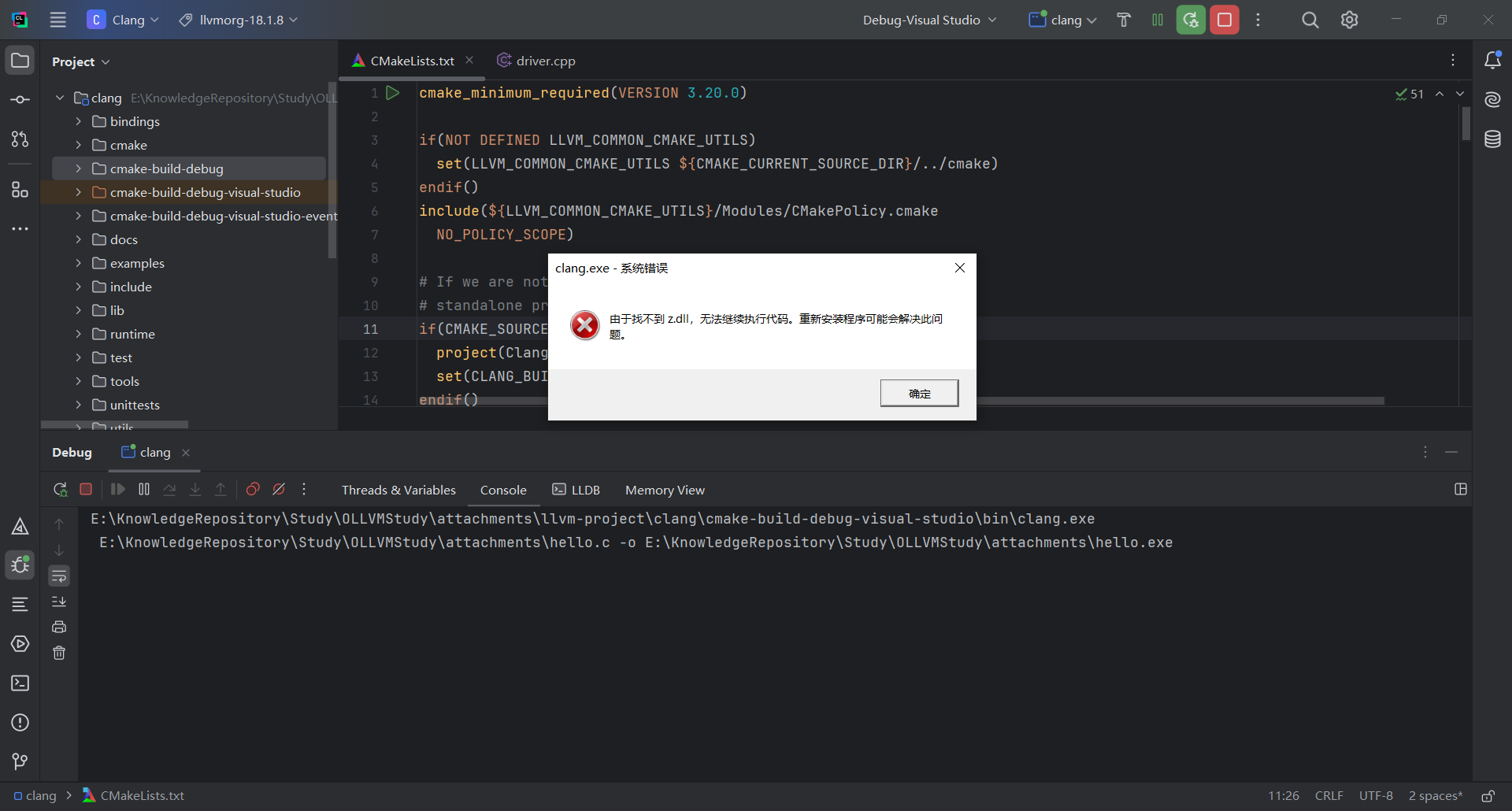
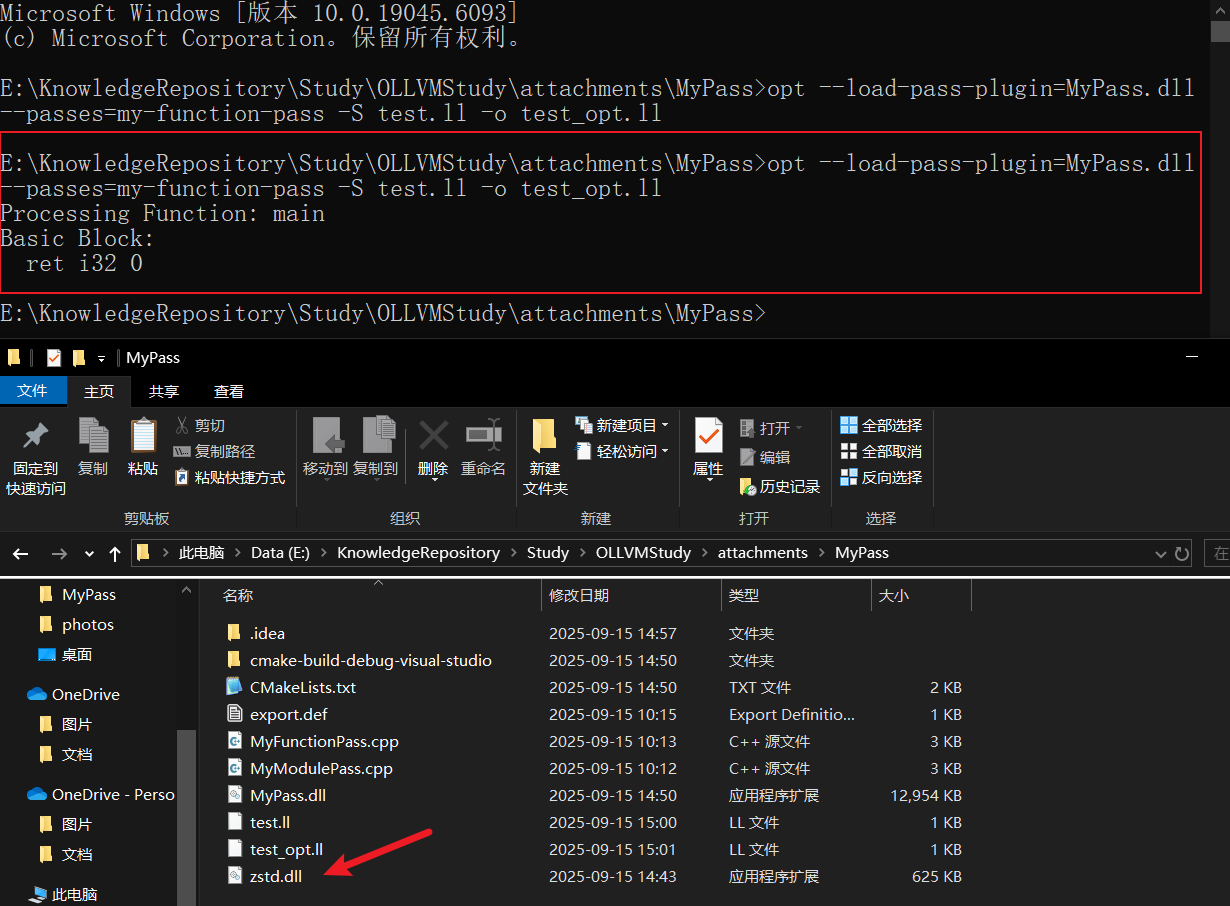
然而运行后找不到z.dll,明明前面安装zlib时已经安装了z.dll,为什么这里找不到呢?
仔细一看VS的输出,发现z.dll是安装到了C:\Program Files (x86)\zlib\bin目录内,并非是直接安装为系统dll
于是复制一份z.dll到CLion的debug输出目录下,成功解决问题
后记: 似乎重新编译后能识别到系统的z.dll, 无需手动复制, 可能由于先前编译时没有安装zlib
官方手册 465K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2L8%4u0Y4i4K6u0r3k6r3!0U0M7#2)9J5c8V1I4S2L8X3N6d9k6h3k6Q4x3X3g2Z5N6r3#2D9 和 ac2K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2k6$3&6#2i4K6u0W2j5h3y4Q4x3X3g2U0L8W2)9J5c8X3c8G2j5%4y4Q4x3V1k6x3j5h3&6Y4f1X3g2X3i4K6u0W2K9s2c8E0L8l9`.`.
[原创]llvm学习笔记——llvm基础
LLVM IR(Intermediate Representation,中间表示)是 LLVM 编译框架的核心。它是一种 介于高级语言(如 C/C++)与底层机器码之间的中间语言 ,既能表达高级语言的语义,又足够接近机器指令,便于优化和生成目标代码。
LLVM IR 的两种存储形式:
LLVM IR 与具体 CPU 架构解耦,可以跨平台复用优化逻辑。LLVM IR 参考手册f17K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2L8%4u0Y4i4K6u0r3k6r3!0U0M7#2)9J5c8V1I4S2L8X3N6d9k6h3k6Q4x3X3g2Z5N6r3#2D9
例如一段C代码
对应的LLVM IR (.II)如下
在这个例子中:
通过 LLVM IR,编译器就能在架构无关的层面做优化,然后再交由 LLVM 后端翻译成目标平台的机器码。
将C文件转换为LLVM IR (.ll)
生成二进制LLVM IR (.bc)
使用llvm-dis将.bc转换为.ll形式
使用llvm-as将.ll转换为.bc
将LLVM bitcode转换为汇编
将汇编转换成可执行程序
结果如下
其中.ll的文件内容如下(省略部分)
.s汇编文件的main函数如下,可以发现默认使用AT&T汇编语法
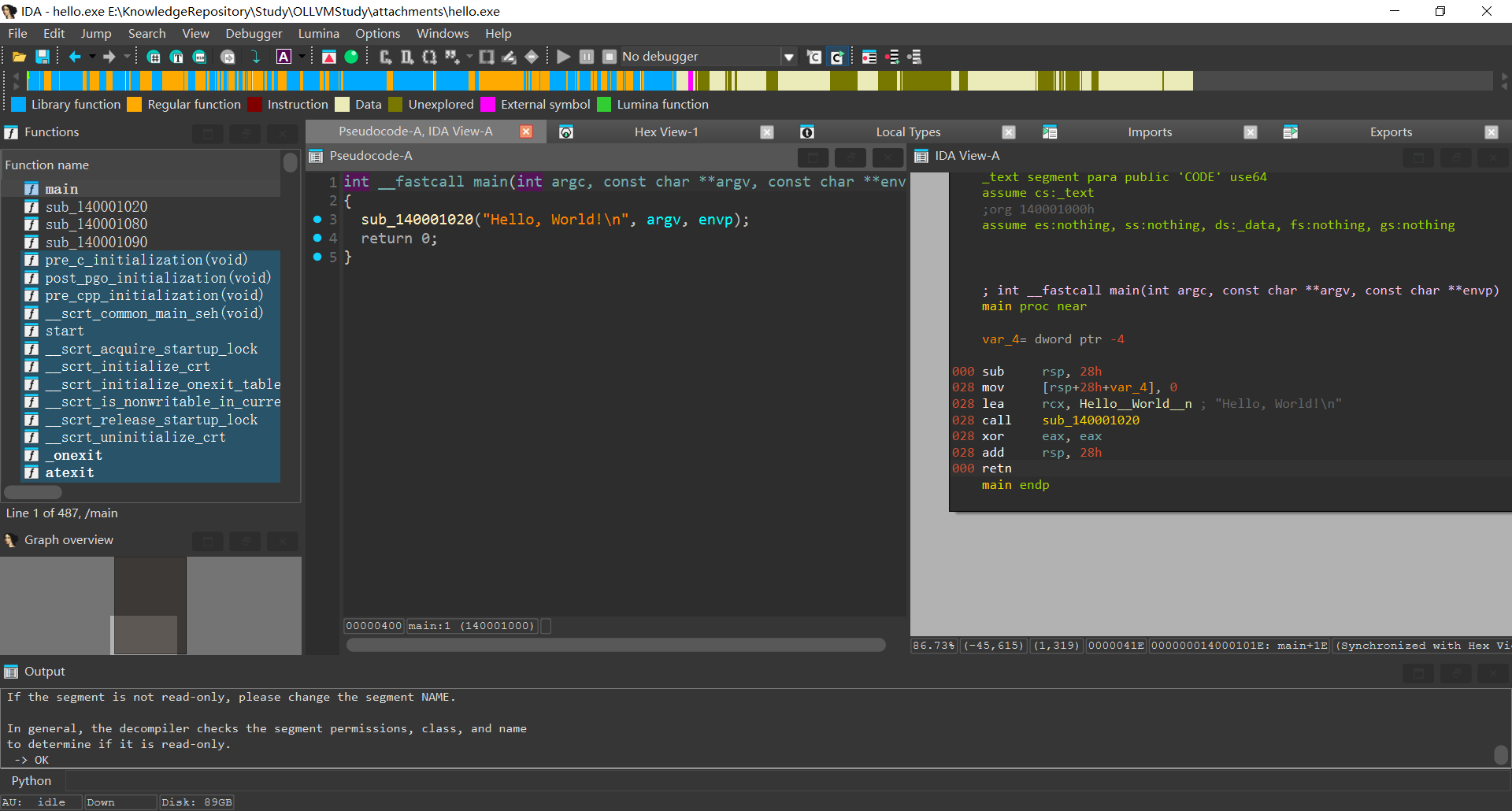
反汇编hello.exe结果如下
两种语法的主要不同:
操作数顺序
AT&T的源操作数在前,目的操作数在后,与Intel语法相反
例如:movl %eax, %ebx(ebx=eax)
操作数大小指定方式
AT&T通过指令后缀显式指定操作数位数
b8位, w16位, l32位, q64位
例如:movb %al, %bl(8 位移动)、movq %rax, %rbx(64 位移动)
而Intel语法由寄存器隐含操作数大小,如al,ax,eax,rax
寄存器和立即数前缀
AT&T的寄存器加前缀'%', 立即数加前缀'$', Intel则无需前缀
内存寻址方式
jmp和call的目标表示
opt 是 LLVM 提供的一个命令行工具,主要用于 对 LLVM IR 进行分析和优化 。
它不会直接生成目标机器码,而是专注于 IR 层面的处理 ,通常在编译流程中作为“优化器”环节出现。
opt 工具通过应用各种优化 Pass,可以实现 **“优化/分析” ** 的目的。
opt O3优化.ll文件生成.bc文件
opt O3优化.bc文件生成.ll文件, -S表示输出可读的文本格式
应用单个pass优化, 参数说明:
函数内联优化,将函数调用替换为函数体减少调用开销
应用多个pass
生成函数的控制流图(Control Flow Graph), 输出.dot文件
CLion 打开 llvm-project\llvm\CMakeLists.txt 并作为项目打开
打开CMake设置, 设置默认工具链Toolchain为Visual Studio
遇到第一种报错,提示路径字符过长,直接在LLVM项目的CMakeLists.txt中设置最大值, set(CMAKE_OBJECT_PATH_MAX 512) , 不需要每个子项目单独设置
之后出现第二个警告,选择直接忽略
设置参数
在llvm/tools/opt/opt.cpp中给main函数下断点调试, 同调试clang类似,需要手动添加z.dll保证正常运行
LLVM Pass 是 LLVM 的扩展机制,Pass 是一种对程序中间表示(IR)进行分析或转换的模块,由 Pass Manager 统一调度。
通过编写自定义 Pass,开发者可以插入自己的逻辑来优化代码、分析性能或插入调试信息等。
Pass的分类
老版本 bbeK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2L8%4u0Y4i4K6u0r3k6r3!0U0M7#2)9J5c8W2N6J5K9i4c8A6L8X3N6m8L8V1I4x3g2V1#2b7j5i4y4K6i4K6u0W2K9s2c8E0L8l9`.`.
新版本 daaK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9L8s2k6E0i4K6u0W2L8%4u0Y4i4K6u0r3k6r3!0U0M7#2)9J5c8W2N6J5K9i4c8A6L8X3N6m8L8V1I4x3g2V1#2z5k6i4N6b7e0g2m8S2M7%4y4Q4x3X3g2Z5N6r3#2D9
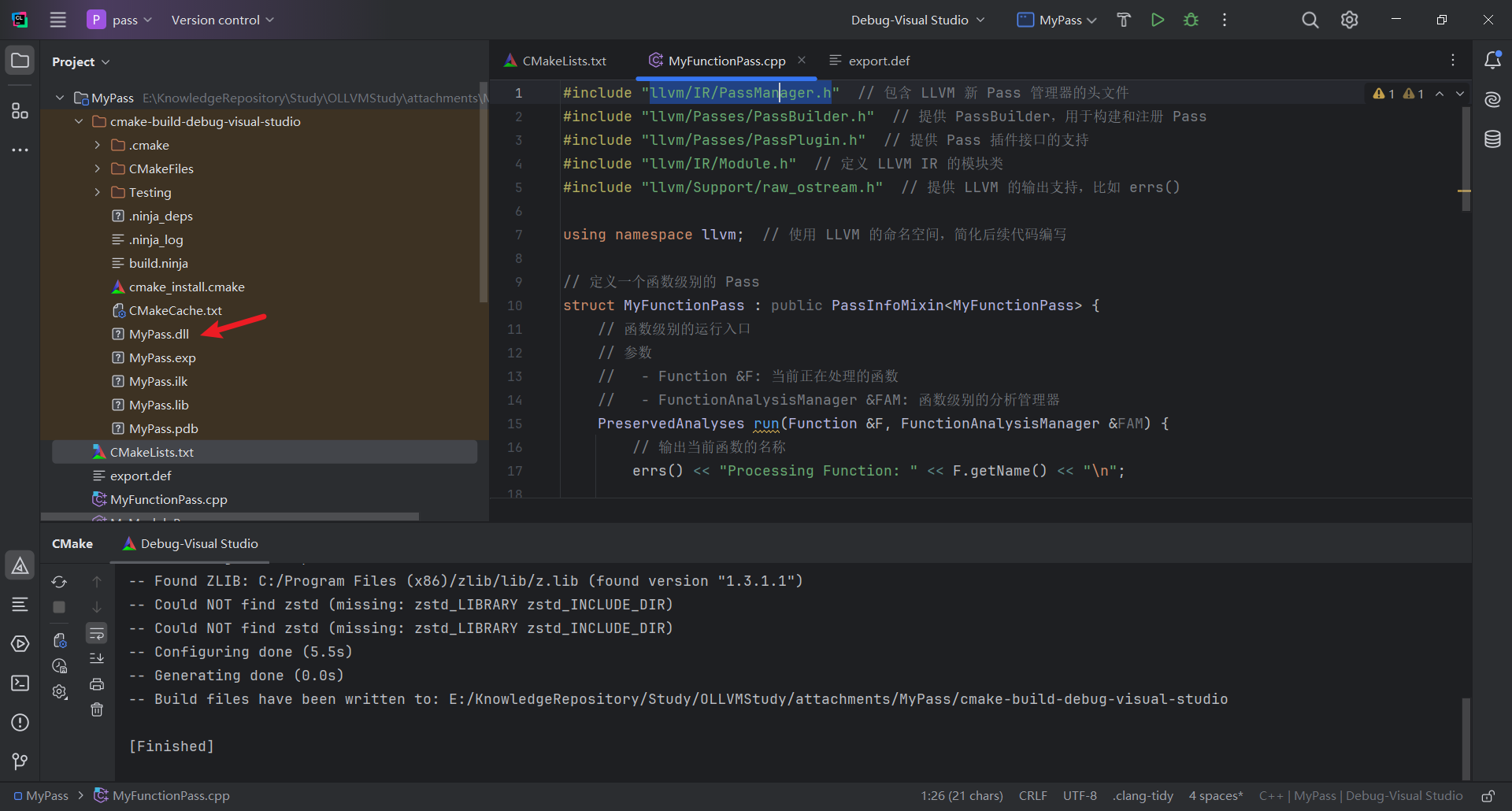
创建 MyModulePass.cpp,定义一个模块级别的 Pass,run 函数实现了对模块的遍历,并输出每个函数的名称
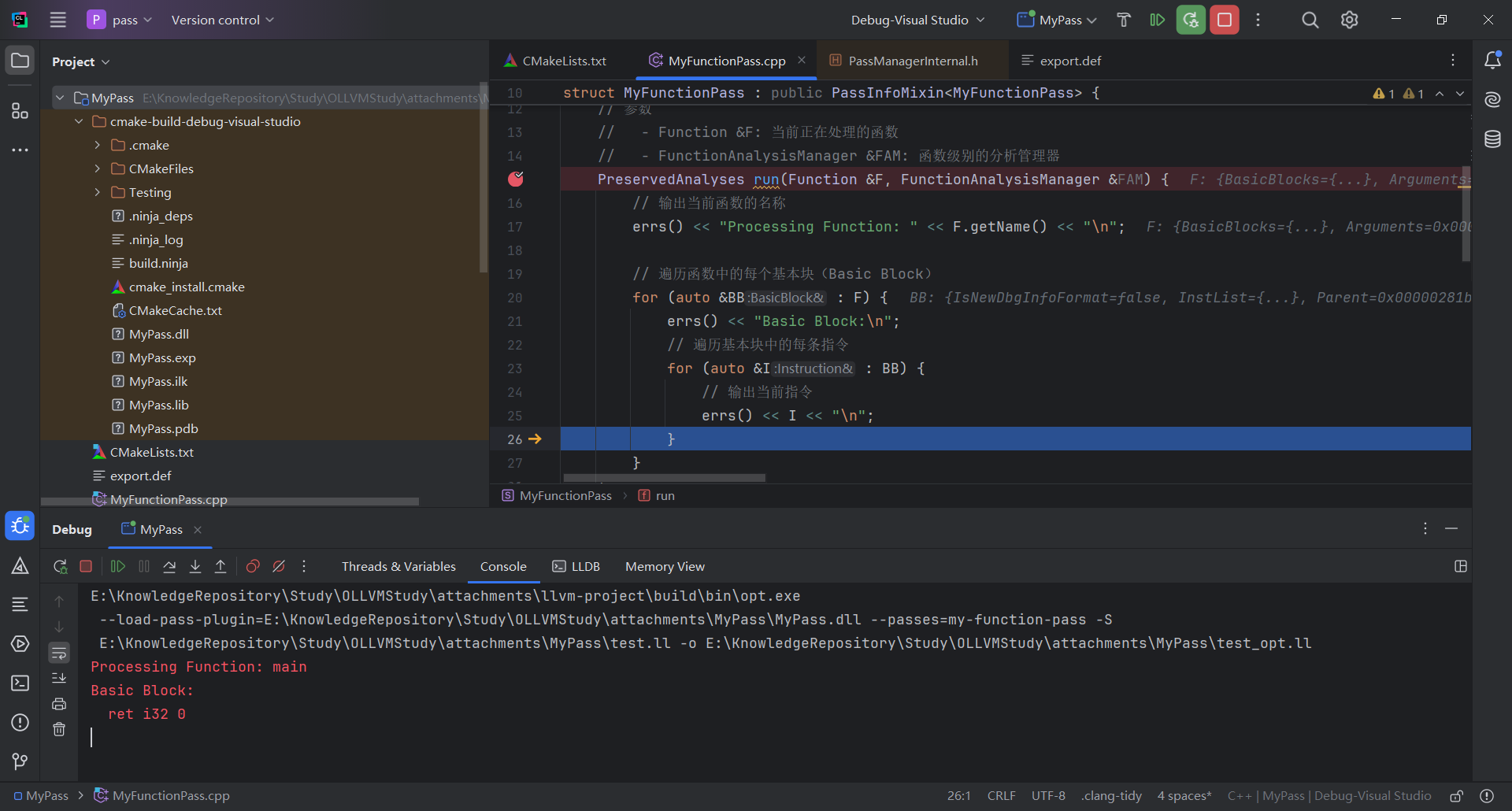
创建 MyFunctionPass.cpp,定义一个函数级别的 Pass,run 遍历函数中的基本块以及基本块中的每条指令,并将其输出
创建 CMake 项目配置文件 CMakeLists.txt
在 Windows 上,动态链接库(DLL)的符号导出通常需要显式指定。否则,运行时的链接器(linker)无法正确找到并加载这些符号。
创建一个 export.def 文件,用于显式导出 llvmGetPassPluginInfo
参数说明:
执行命令编译pass
编译成功
编译后可通过 opt 命令运行 Pass
其中:
创建test.ll文件
使用 opt 工具加载 MyPass.dll 插件,运行自定义的 my-function-pass ,对 test.ll 进行优化处理,并将结果输出到 test_opt.ll
同上类似,需要将zstd.dll和MyPass.dll放到同一路径,否则会报错
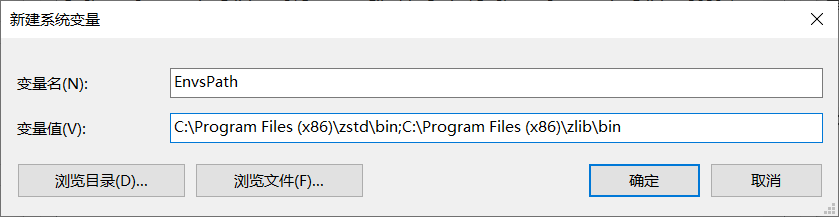
为根绝该问题,选择创建环境变量EnvsPath, 保存zstd和zlib的bin目录路径
之后将"%EnvsPath%"添加到环境变量Path中即可让所有程序都能找到对应dll
新版脱离源码开发Pass Developing LLVM passes out of source
新版Pass编写教程 WritingAnLLVMNewPMPass
旧版脱离源码开发Pass 8.0.1 developing-llvm-passes-out-of-source
旧版Pass编写教程 8.0.1 WritingAnLLVMPass.html
主要步骤:
CMakeLists.txt
MyFunctionPass.cpp
CMakeLists.txt
MyModulePass.cpp
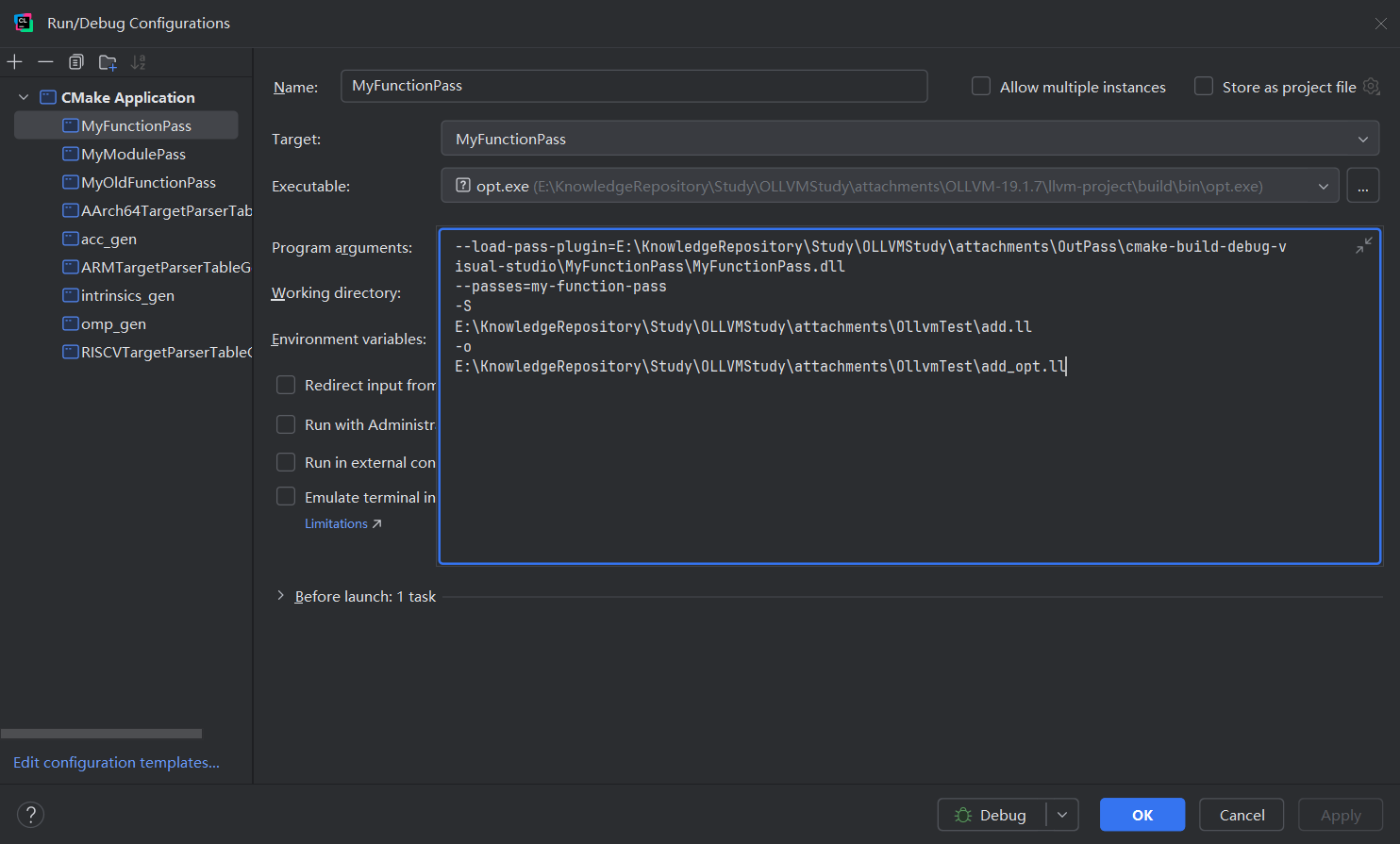
以MyFunctionPass为例, 编译出MyFunctionPass.dll后, 指定opt加载pass并执行
效果如下, 由于脱离llvm源码树,所以修改和编译起来更快,不需要每次debug重新编译clang和opt
clang默认情况或O0优化下会为函数生成optnone属性, 并且添加到attributes属性集
由于该属性禁止opt对函数进行任何优化, function pass受此影响失效, 但module pass作用于整个模块, 因此不会失效
解决办法:
clang编译时通过-Xclang指定-disable-O0-optnone (推荐)
手动去除ir中的optnone属性
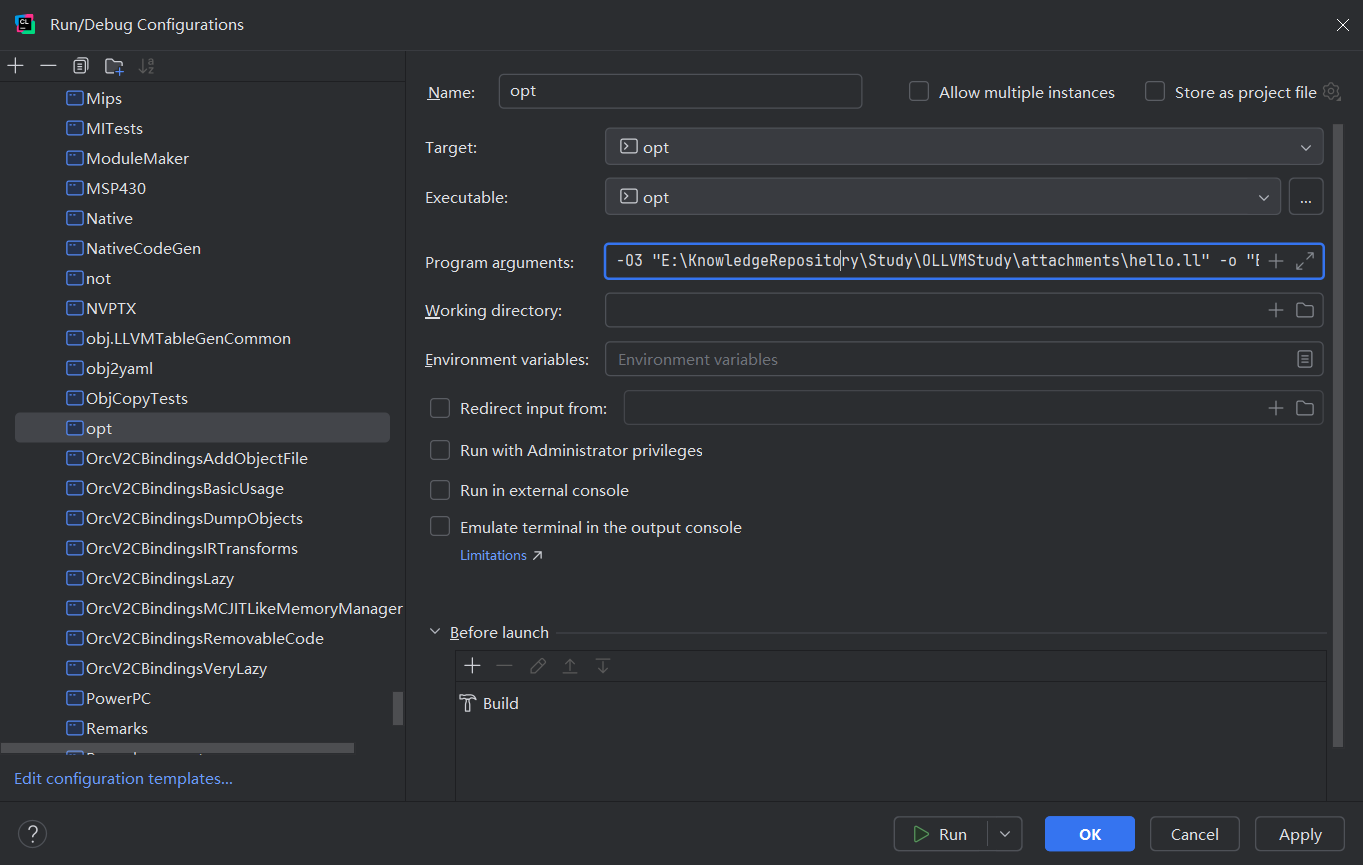
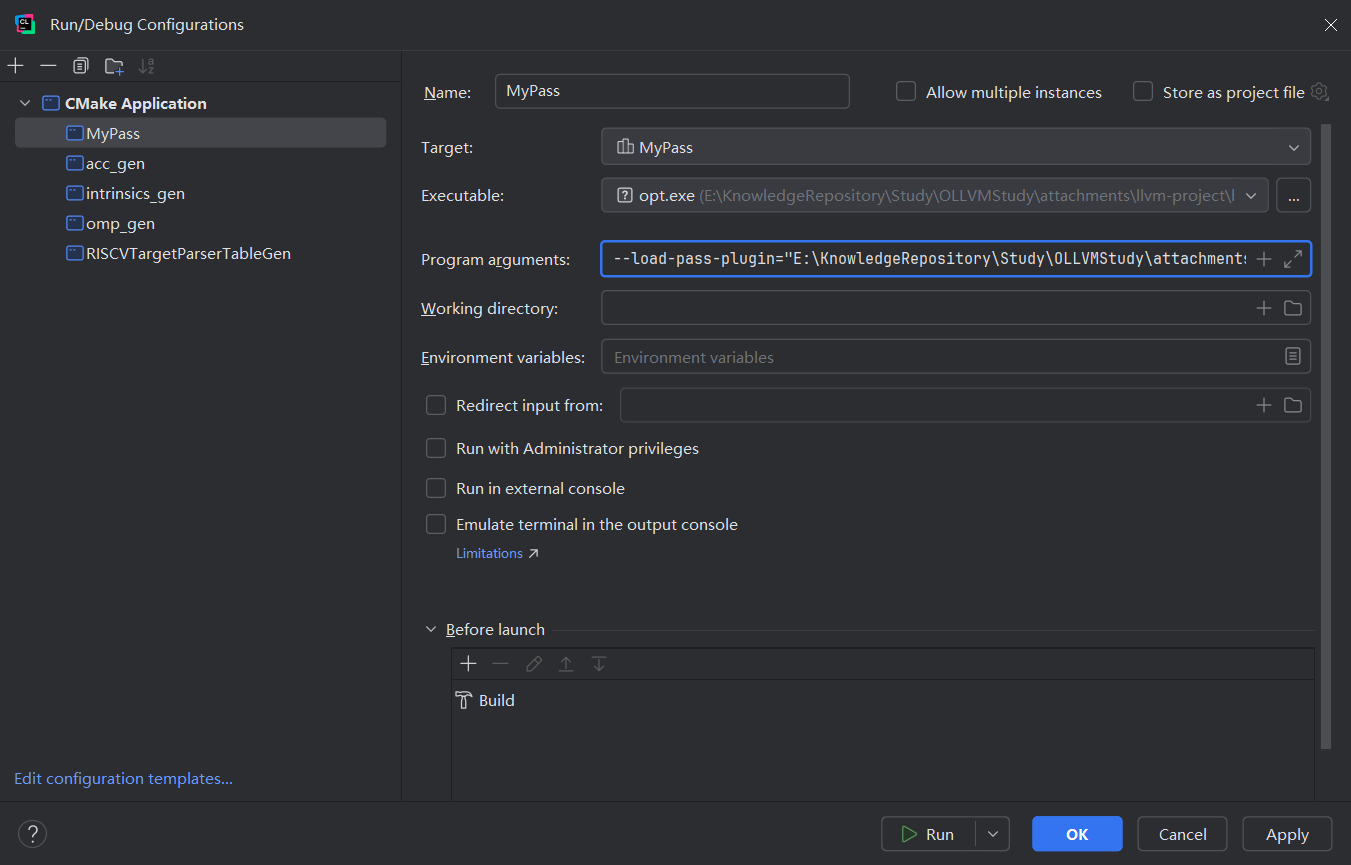
首先设置MyPass的debug设置, 启动程序选择之前编译好的opt,参数输入如下
在MyFunctionPass.cpp的run方法下断点即可调试
新建hello_test.c
生成LLVM IR(.ll)
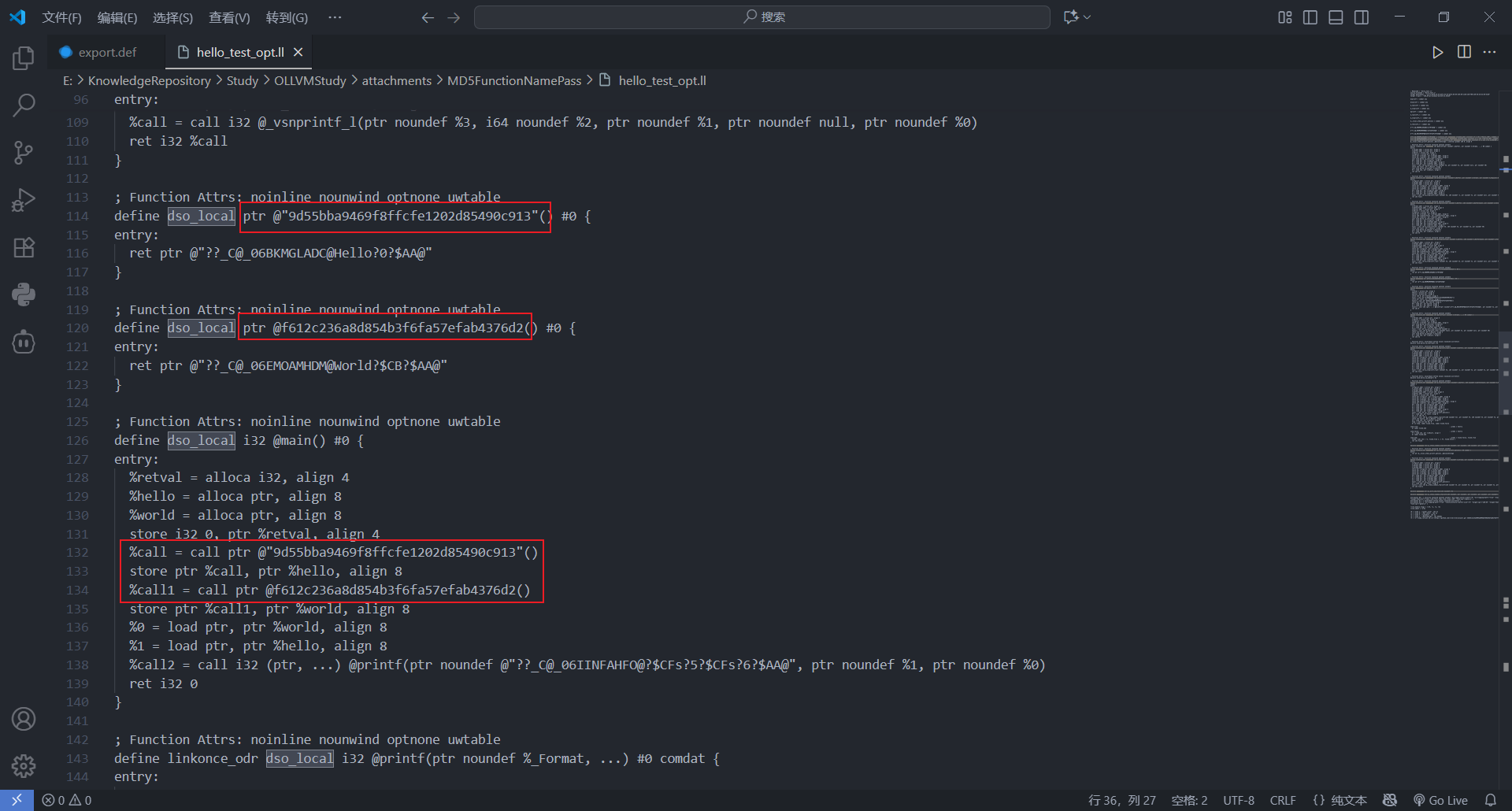
opt使用md5-function-name-pass 优化 并导出优化后的ll文件
打开hello_test_opt.ll,发现函数名均被替换为md5值
运行以下命令直接加载插件并应用于编译流程
这是老版本的传统方式,通过load加载任意llvm插件(包括pass,分析器等)
或者使用新版方式, 专门用于加载函数优化阶段的pass插件(FunctionPass)
OLLVM(Obfuscator-LLVM)是基于 LLVM 编译器框架 的一个开源扩展项目,主要用于程序代码混淆与保护。
OLLVM 基于 LLVM 的 Pass 插件机制 ,在优化环节增加 代码混淆功能 ,从而增加二进制程序的逆向难度。
常见的混淆手段包括:
OLLVM 项目地址:facK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6G2j5X3k6#2M7$3y4S2N6r3!0J5i4K6u0V1L8r3I4$3L8g2)9J5c8X3!0T1k6Y4g2K6j5$3q4@1L8%4t1`.
目前最新版本的是分支名为 llvm-4.0,基于 LLVM 团队发布的版本 4.0.1
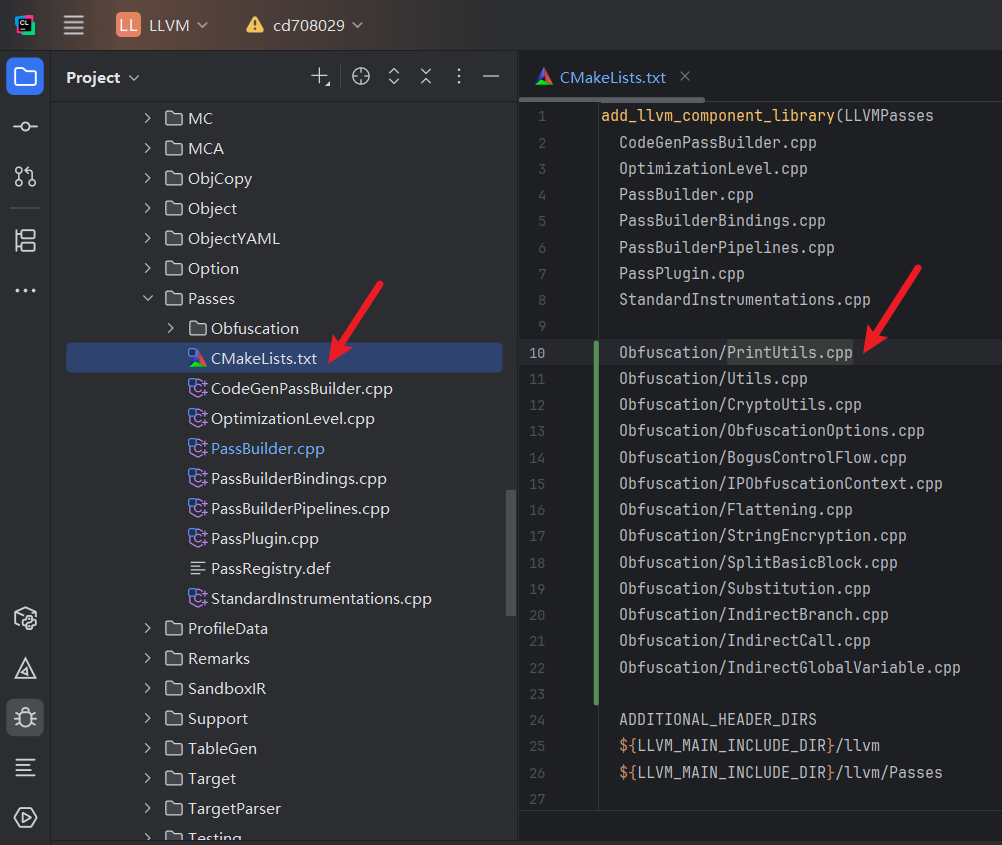
OLLVM 的核心代码在:lib/Transforms/Obfuscation 或 lib/Passes/Obfuscation 内
Initial LLVM and Clang 4.0 之外的都是基于 LLVM 4.0 改动过的代码
由于 obfuscator 中的代码已经 7 年多没有维护更新了,移植到 llvm19 变动太大, 故采用以下项目中的Obfuscation
参考 移植到19.1.0所需要的diff文件 末尾提供的Passes.zip, 其中包含了Obfuscation Pass文件
如果仅为使用OLLVM可参考以下项目:
b30K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6t1j5h3g2V1N6i4y4Q4x3X3c8u0L8X3c8#2M7%4c8J5K9h3g2K6i4K6u0r3L8$3I4D9N6X3#2Q4x3X3b7I4z5b7`.`. 工具链和库文件更全面
1e0K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6v1K9h3q4b7j5h3V1I4x3U0p5K6z5q4)9J5c8V1!0x3e0q4k6y4i4K6u0V1x3e0V1`. 只有二进制文件
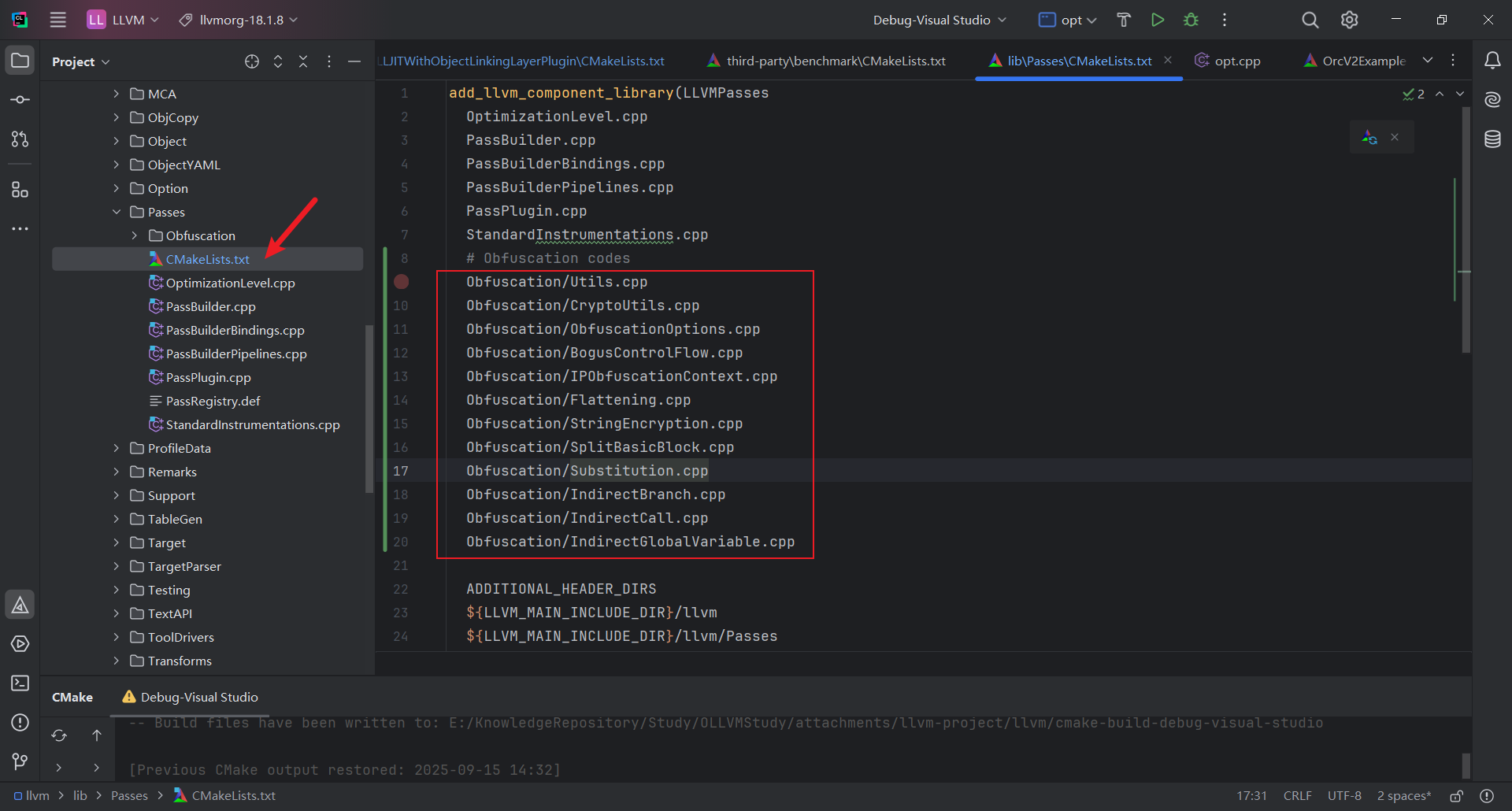
首先复制Obfuscation文件夹到 LLVM 工程 llvm/lib/Passes/Obfuscation
再修改llvm/lib/Passes/CMakeLists.txt, 添加Obfuscation相关的源文件
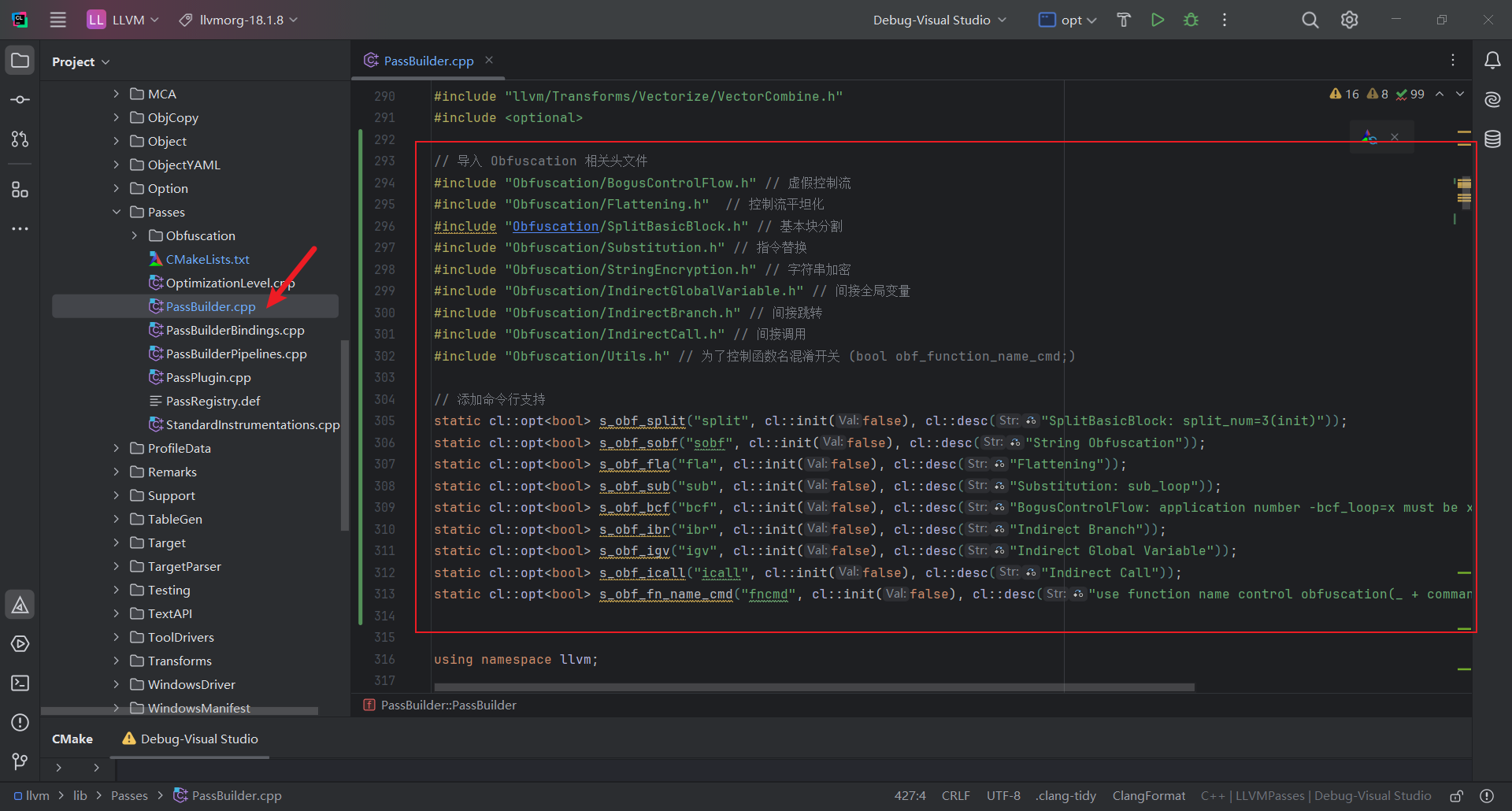
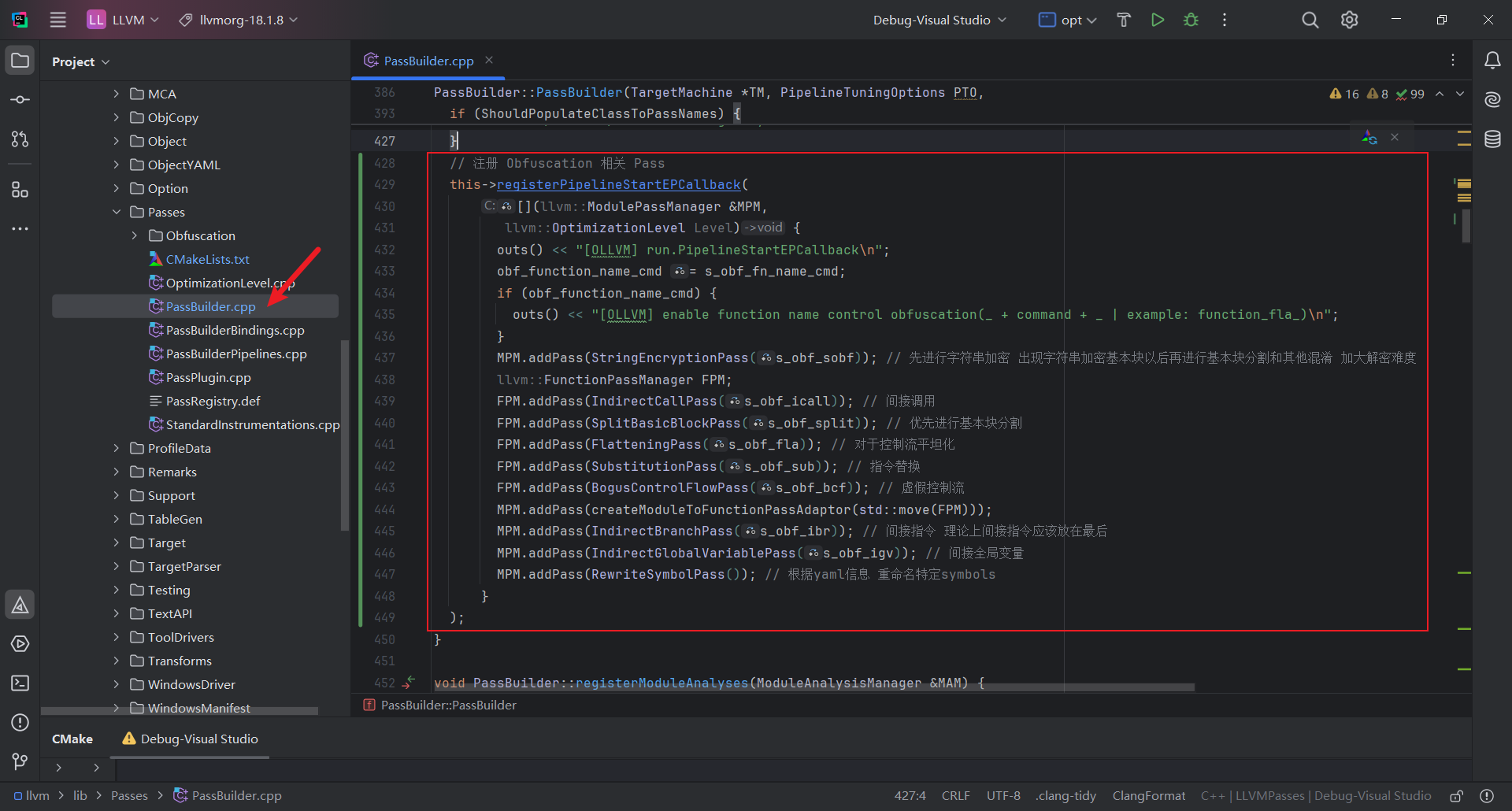
之后编辑 llvm/lib/Passes/PassBuilder.cpp
先添加Obfuscation相关头文件和命令行支持
再注册obfuscation相关pass
进入build目录,重新配置cmake,主要是将构建类型设置为Release以节省空间
注: 使用OLLVM只需要Release模式编译即可, 移植OLLVM到NDK时也使用Release版clang
但后续调试obfuscation pass时仍需使用Debug模式编译
ninja构建项目
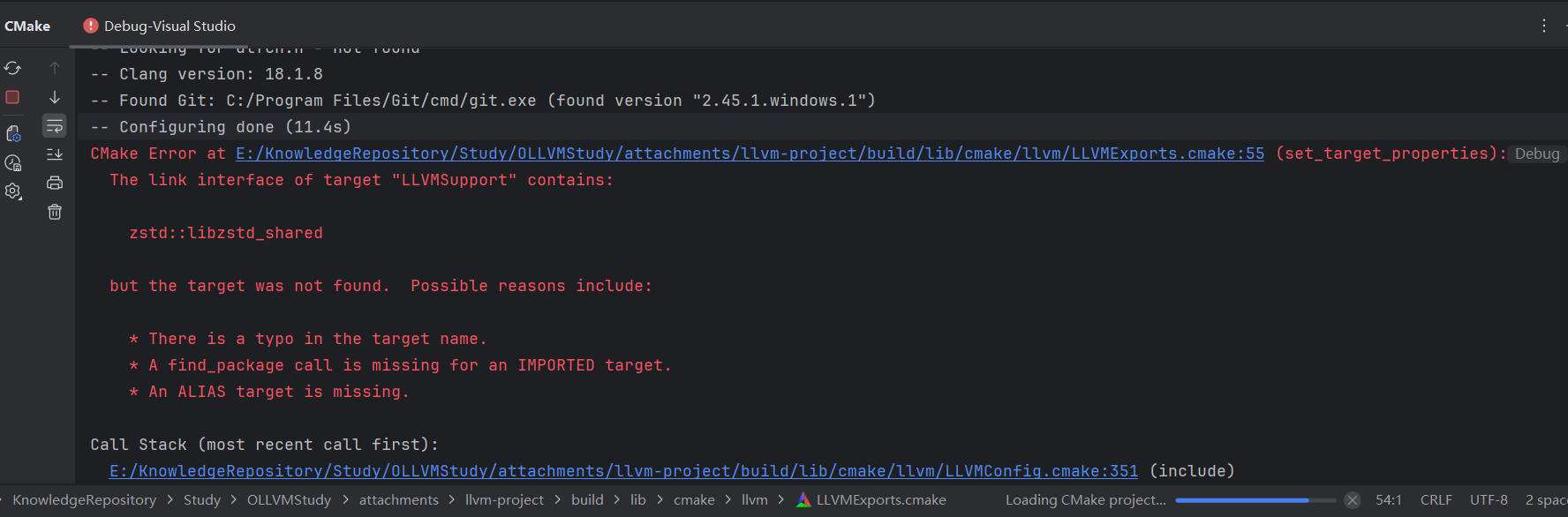
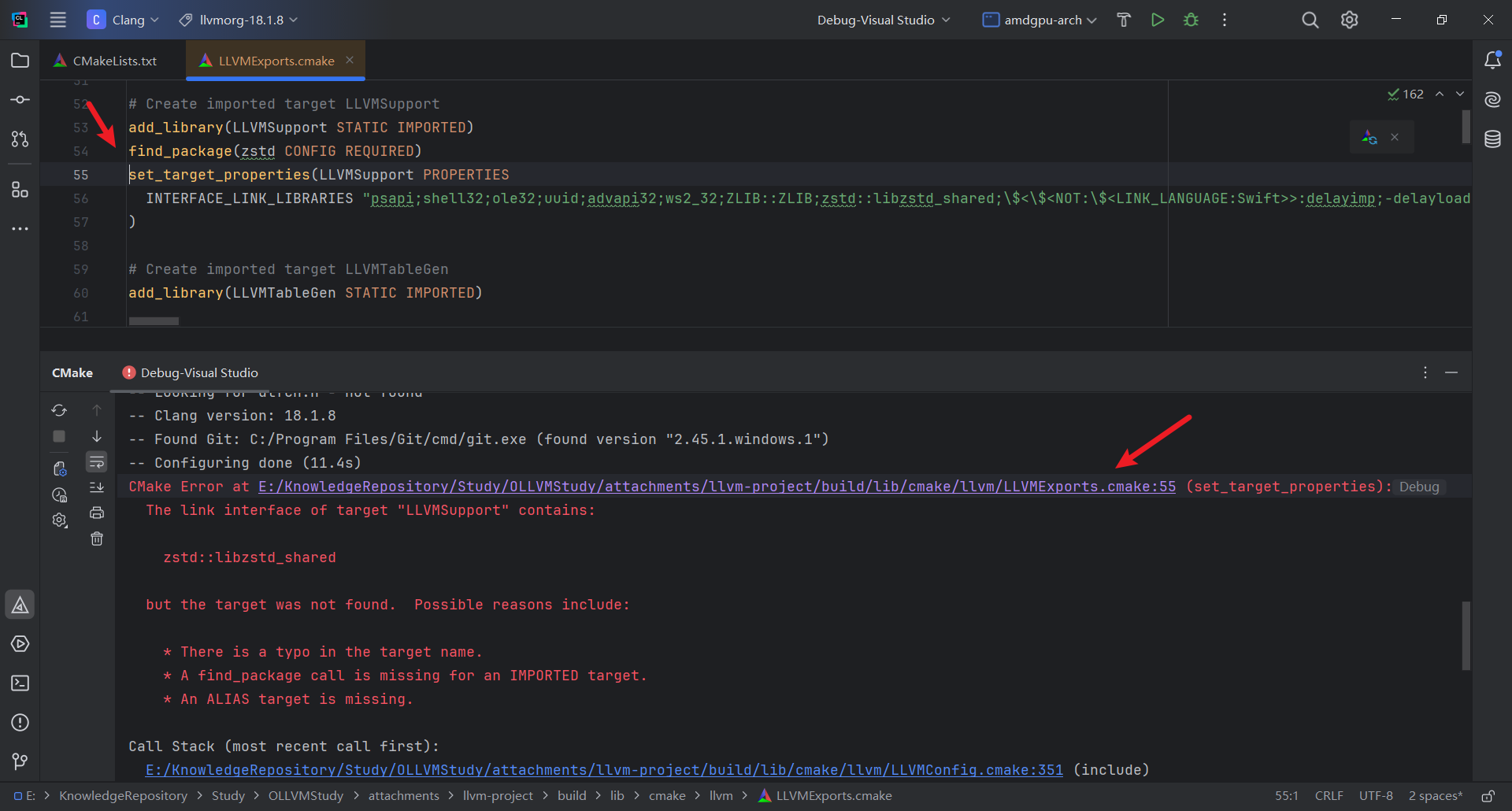
注意Debug模式编译可能遇到如下报错
参考 OLLVM19搭建
原因: API不兼容, 从 LLVM17 开始,引入了 强制启用不透明指针(opaque pointer)模型,并彻底移除了 PointerType 中对 pointee type 的直接访问接口,包括:getElementType()(17 中废弃) isOpaqueOrPointeeTypeMatches()(已移除)
手动修改源码,位置:~/llvm/lib/Passes/Obfuscation/compat/CallSite.h:137:18
替换成如下代码即可解决:
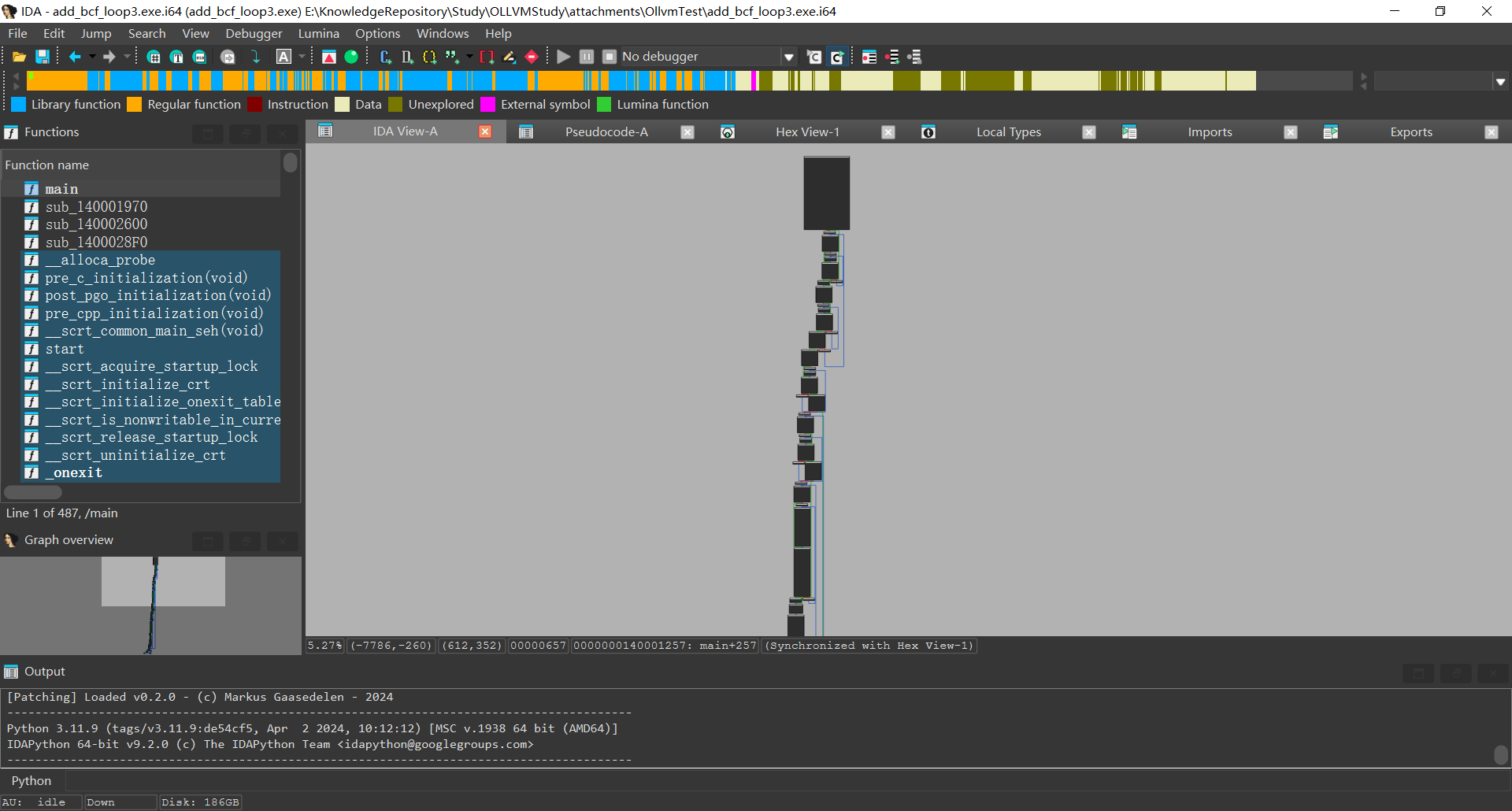
编写一个add.c的测试程序
不使用ollvm编译的结果,结构较为简单清晰
使用ollvm 的sub即指令替换,并且loop=3
可以发现汇编的运算指令膨胀了很多,不过ida的伪C代码仍然给出了优化后的结果
Instruction Substitution 是将一些常用的简单指令替换为具有等效逻辑但更加复杂的指令序列,从而提高代码逆向分析的难度。
使用 clang 编译时通过添加 -sub 参数启用指令替换功能, 通过-sub_loop参数指定替换次数
实现原理:
目前已实现加、减、与、或、异或指令的替换。比如加法运算 a + b:
替换为:a - (-b)
等价 LLVM IR 为:
参考:Instructions Substitution
Bogus Control Flow(BCF) 是 OLLVM(Obfuscation LLVM)的一种控制流混淆技术。
BCF 的核心思想是通过增加虚假的分支语句 ,构造看似复杂的控制流图(CFG),让逆向分析者难以理解程序的真实逻辑。这些分支通常通过难以猜测的条件判断来决定执行路径,但无论选择哪条路径,最终的逻辑都保持正确。
比如,未混淆的代码示例:
经过BCF混淆后可能有如下结构
启用虚假控制流,并对一个函数应用 3 次虚假控制流转换,默认为1
启用虚假控制流,并以 40% 的概率对基本块进行混淆。默认值为 30%
控制流程图膨胀很多
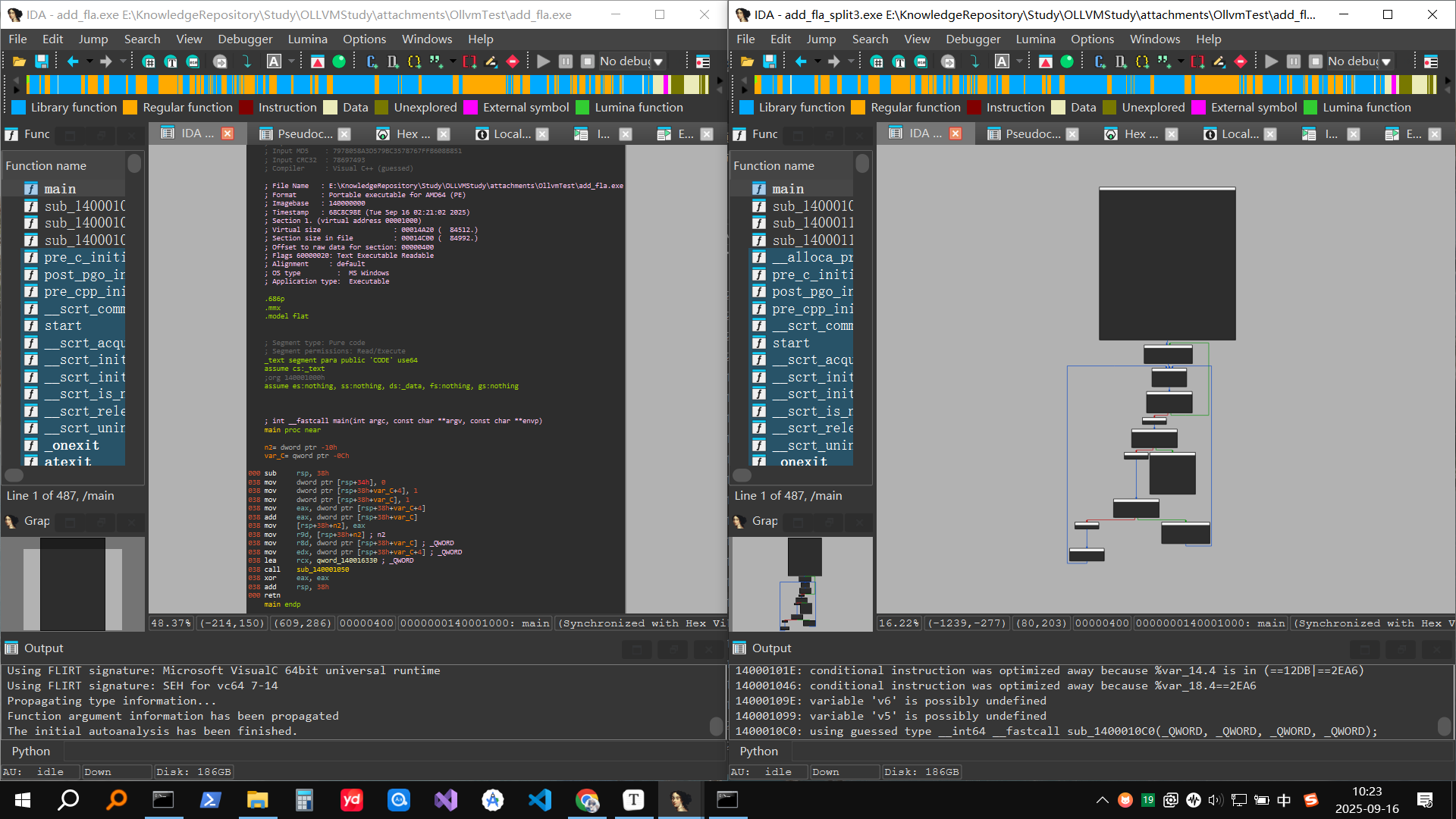
Control Flow Flattening(控制流平坦化)通过引入一个调度变量和统一的调度循环,将程序的所有基本块按编号管理,使用条件跳转动态调度执行顺序,从而隐藏原始控制流结构。
例如,原始代码如下
平坦化后的代码
命令如下
分别只使用fla和split_num=3配合fla,结果如下
可以发现左边只使用fla的变化不大,因为没有分支语句,而右边使用split配合的流程图显然更复杂
所以一般使用split配合fla加强混淆效果
在 Android 应用安全中,Native 层 so 库往往是最容易被逆向分析的目标 。无论是游戏的核心逻辑,还是 App 的关键算法,一旦 so 被反编译,核心代码就可能暴露无遗。
传统的 Java 层混淆工具(如 ProGuard、R8)对 C/C++ 代码无能为力,因此 NDK 层代码的保护 成了安全加固中的难点。解决思路:在编译阶段对 so 进行混淆处理 ,让逆向难度大幅提升。
在 Android 平台上,自 NDK r18 开始,Google 就全面弃用了 GCC,转而采用 LLVM/Clang 作为官方工具链。也就是说,所有的 C/C++ 代码编译、优化、生成 so 库的过程,底层都是由 LLVM 驱动完成的。
集成OLLVM到NDK后最终实现编译流程大概如下:
对比 Android NDK 目录 toolchains\llvm\prebuilt\windows-x86_64 和 OLLVM的目录
其中主要几个文件夹:
粗略移植(不推荐)
只需要将OLLVM的bin, include, lib目录复制并替换NDK的对应目录即可移植
精细移植(推荐)
参考Android逆向-ollvm-使用
将以下文件: clang, clang++, clang-format 移植到NDK的 "~\toolchains\llvm\prebuilt\windows-x86_64\bin" 目录内即可
如果编译时Android Studio提示找不到头文件,则从 "~\lib\clang\
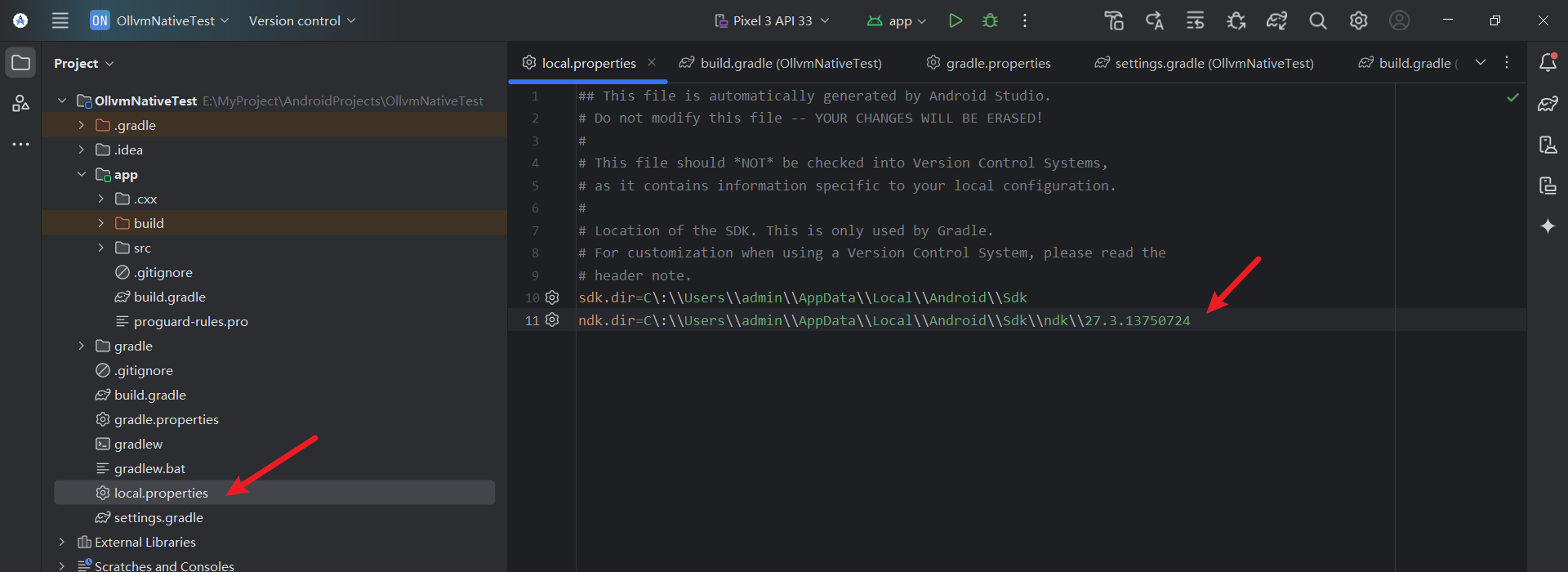
创建一个Android Native工程 OllvmNativeTest
编辑 local.properties 添加 ndk.dir 配置为 移植了ollvm的ndk 路径
MainActivity.java
ollvm-lib.cpp
全局混淆
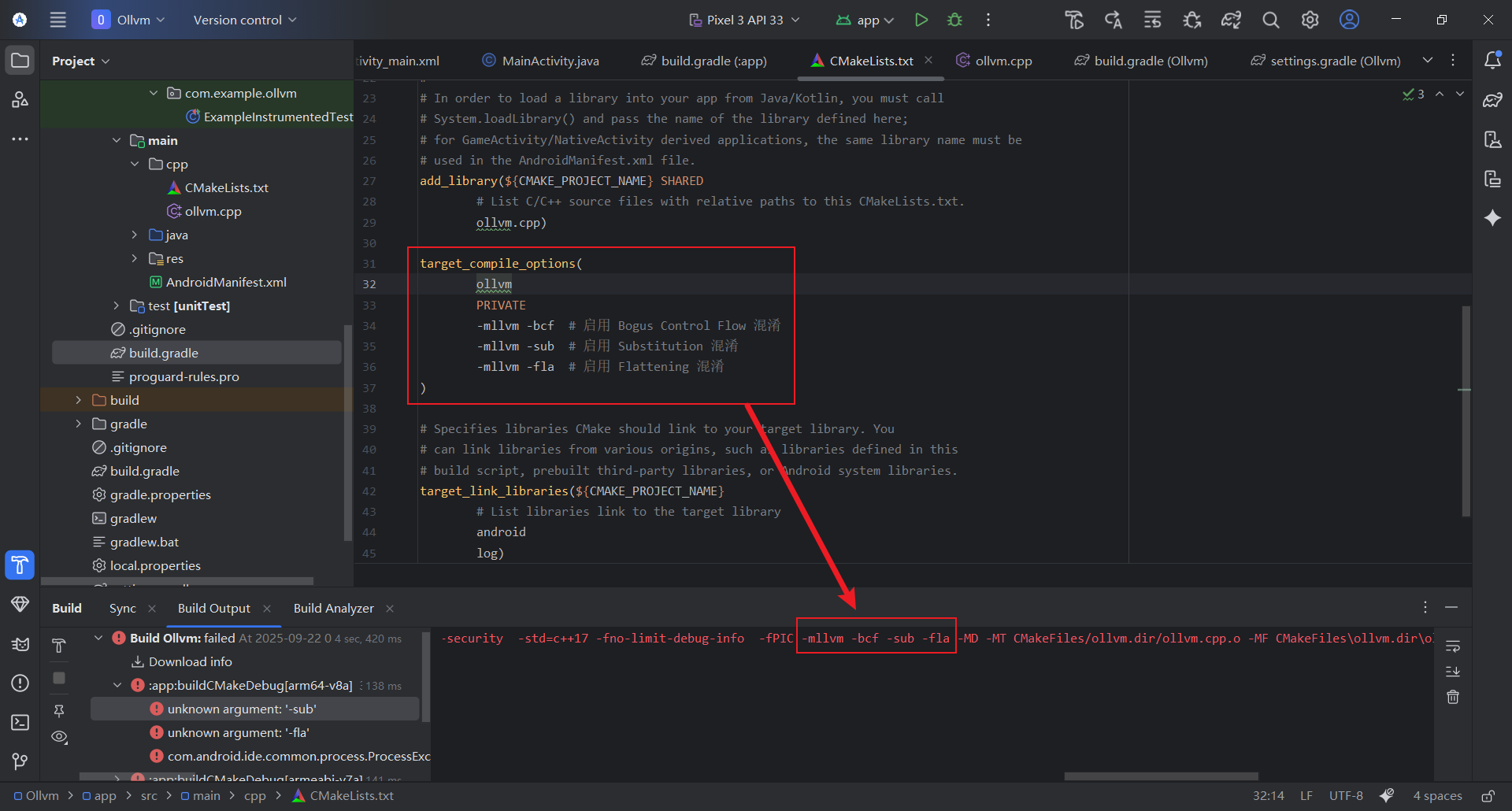
编辑 CMakeLists.txt,添加如下配置启用 OLLVM 混淆
针对单个动态库混淆(无效)
可以发现多个-mllvm被合并成一个
在CMakeLists.txt中, 通过CMAKE_FLAGS设置参数
在build.gradle中
严格按照android\defaultConfig\externalNativeBuild\cmake的层级目录
设置cppFlags传递ollvm参数
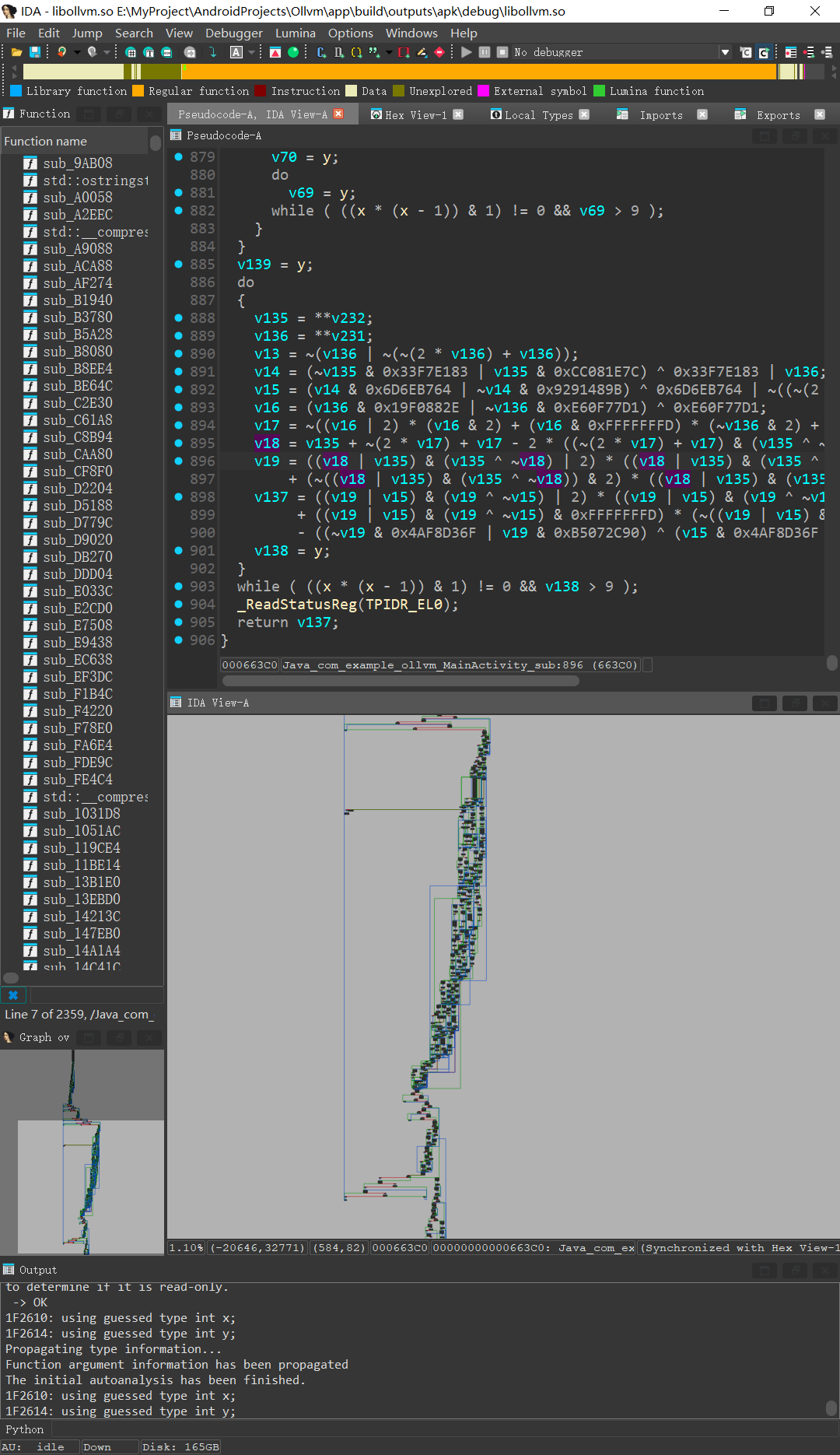
测试参数为混淆全开 (不包括indirect branch/call)
效果如下,简单的减法函数膨胀成900行伪代码以及复杂的流程图
经过以上基础学习, 我们了解了LLVM和Pass相关概念, LLVM工具的使用, 移植编译OLLVM 以及集成到 NDK
接下来阅读各混淆Pass的源码深入理解其原理, 同时分析测试代码混淆前后的IR变化加强理解
注意:
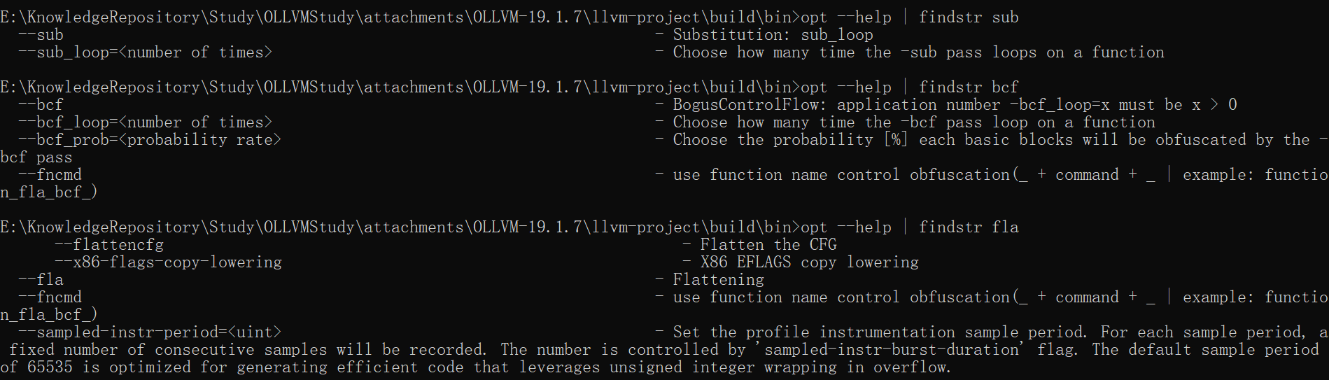
编译clang后,实际上opt用于调用pass处理IR,所以obfuscation pass被集成在opt中
通过opt --help可以查询支持哪些obfuscation pass参数
调试方法:
先修改obfuscation, 为pass添加打印语句
再调试opt并通过参数调用指定pass
PrintUtils.h
PrintUtils.cpp
修改llvm/lib/Passes/CMakeLists.txt, 添加PrintUtils.cpp到项目中
之后在需要调试的pass中添加代码即可, 以Substitution.cpp为例:
由于pass不能单独执行, 且pass被集成到opt中, 所以需要使用CLion调试opt从而调试pass
注意: opt优化的是IR文件, 所以要先生成IR文件才能调试, 参考前文脱离LLVM源码编译Pass中提到的optnone问题
使用以下命令编译源文件得到的IR文件才能正常用于opt优化调试
之后在obfuscation对应pass源码中断点, 设置参数优化IR文件以调试opt
注意参数中一定要传递"-On" 其中n=0~3, 优化力度依次增加, 如果不传递该参数则不会调用pass优化
例如使用以下参数进行优化
实际调试时修改opt参数参考如下:
例如调试bcf时指定bcf_loop=1时的调试参数
功能: 将单个二进制运算指令(加减乘除,位运算等)替换为等价指令序列
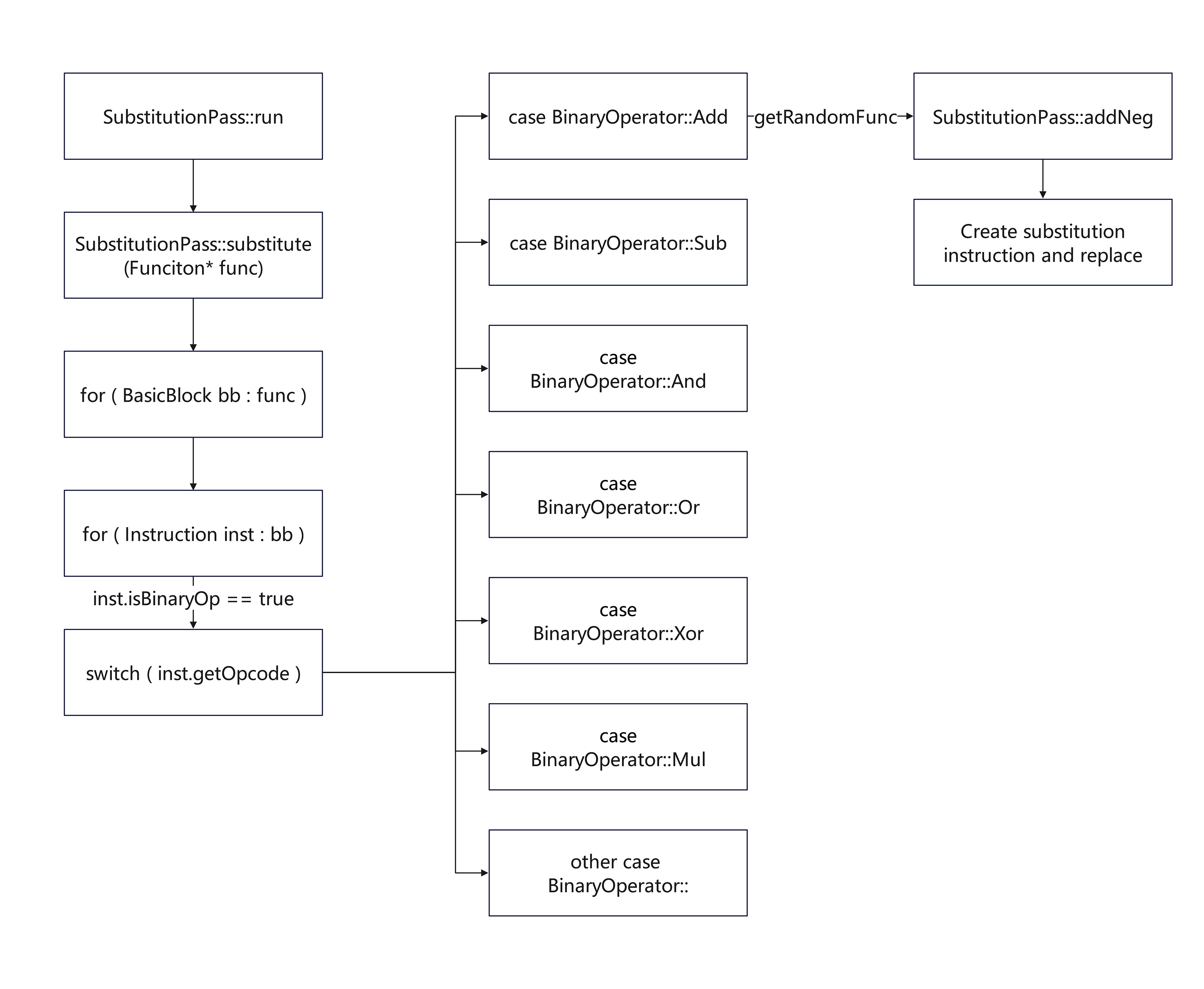
SubstitutionPass::run
pass的入口函数,检查剩余混淆次数以及是否需要进行混淆
调用SubstitutionPass::substitute执行具体混淆操作
SubstitutionPass::substitute
对传入的函数循环进行ObfTimes次混淆操作
第一层for循环遍历Funciton的每个BasicBlock
第二层for循环遍历BasicBlock的每个Instruction
当指令为BinaryOperator时, switch判断指令具体类型并调用随机混淆函数
混淆函数 如SubstitutionPass::addNeg
生成等价指令序列并替换原始指令
pass的入口函数, 检查剩余混淆次数后调用substitute函数执行sub混淆
该类定义在Substitution.h中, 可以发现Add指令有7种混淆函数
以addNeg为例, 其将 a=b+c 替换为 a = b - (-c)
测试代码add.c
对应add.ll main (未调用sub)
不难看出 %0=a, %1=b, %sum=%add=%0+%1
混淆后add_opt_sub.ll
%0=a, %1=b,
%2=%0+730782619
%3=%2+%1
%4=%3-730782619
%sum=%4
即%sum=%4=%3-730782619=%2+%1-730782619=%0+730782619+%1-730782619=%0+%1=a+b
其中指令 %add = add nsw i32 %0, %1 不影响后续结果, 故没有作用从而成为了死代码
显然插入了以下3条指令
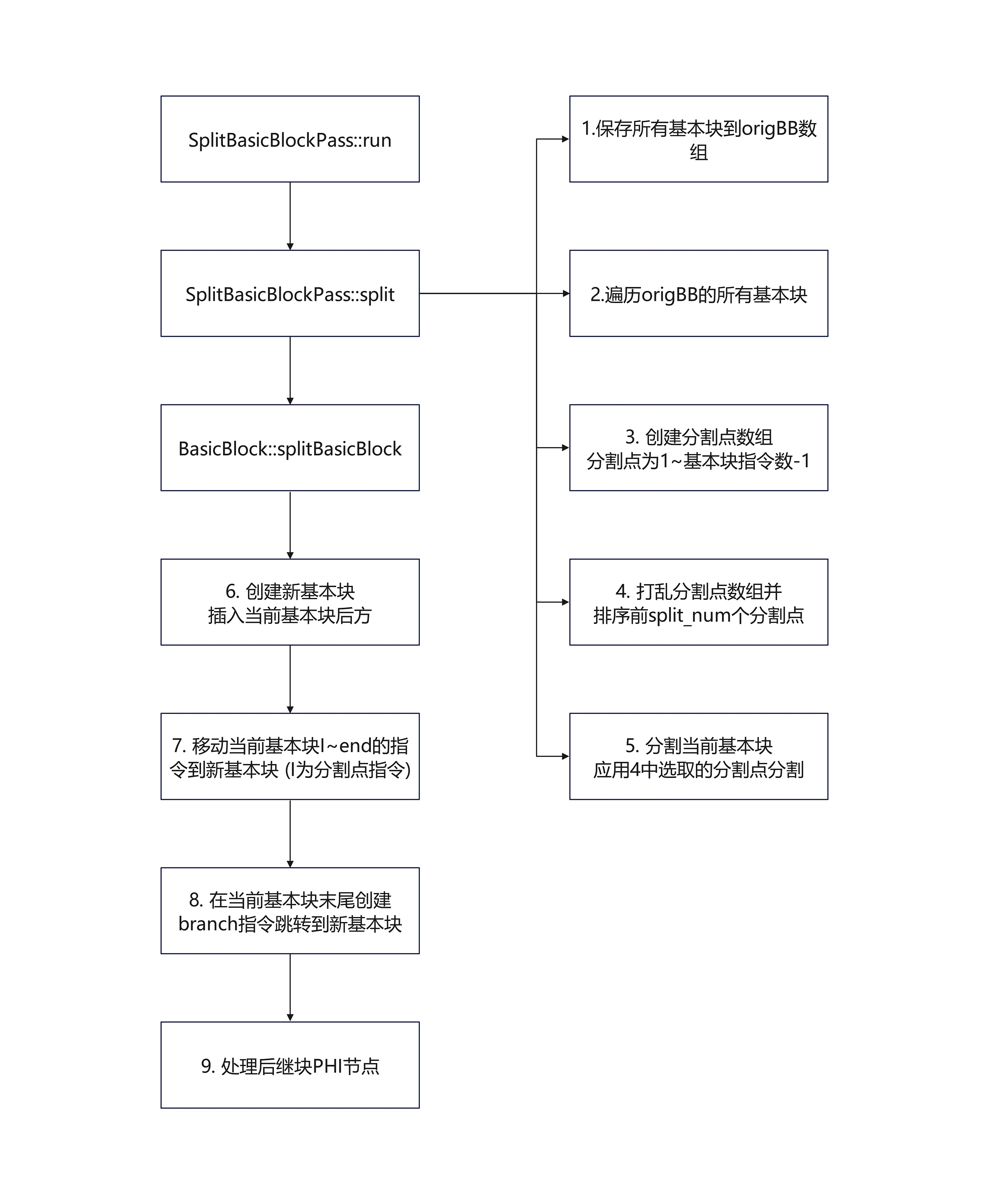
功能: 随机选取分割点,将函数的每个基本块分割为多个小基本块, 小基本块间用分支指令br连接
Split Basic Blocks 的流程比较简单,实际上只需要重点关注SplitBasicBlockPass::split即可
分割基本块最终通过调用API函数BasicBlock::splitBasicBlock实现
通过随机数作为索引,交换元素顺序打乱数组
上述代码中调用了SplitBasicBlockPass::containsPHI判断基本块中是否包含PHI指令
参考 SSA Form and PHI Nodes
所有 LLVM 指令以静态单一赋值形式(SSA)表示 。本质上,这意味着任何变量只能被赋值一次。
单次赋值的结果就是 PHI (Φ) 节点。当变量可以根据控制流路径被赋值时,这些节点则是必需的。
例如有下列代码:
假设v<10, a会被再次赋值为2, 由于SSA性质, a已经被赋值一次, 所以不能继续赋值
LLVM中通过PHI Node解决该问题, 用于基本块之间的分支和合并 , 当一个基本块有多个前驱基本块时, PHI Node可用于表示从不同前驱基本块中接收的值
以上代码会被转换为如下形式:
PHI 节点根据控制流到达 PHI 节点的位置选择 a1 或 a2 。
PHI 节点的参数 a1 与块 “a1 = 1;” 相关联,而 a2 与块 “a2 = 2;” 相关联。
PHI 节点必须在 LLVM IR 中显式创建, 因此, LLVM 指令集有一条名为 phi 的指令
关于如何处理后继基本块,感兴趣的师傅可以深入了解
总的操作是将后继基本块中PHI Nodes的前驱基本块由当前基本块转换为新基本块, 调用链如下:
混淆前
混淆后
经过SplitBasicBlocks后, 原来1个基本块被分割为4个基本块
基本块名称依次添加.split后缀, 它们之间通过br指令连接, 指令流原始执行顺序并未改变
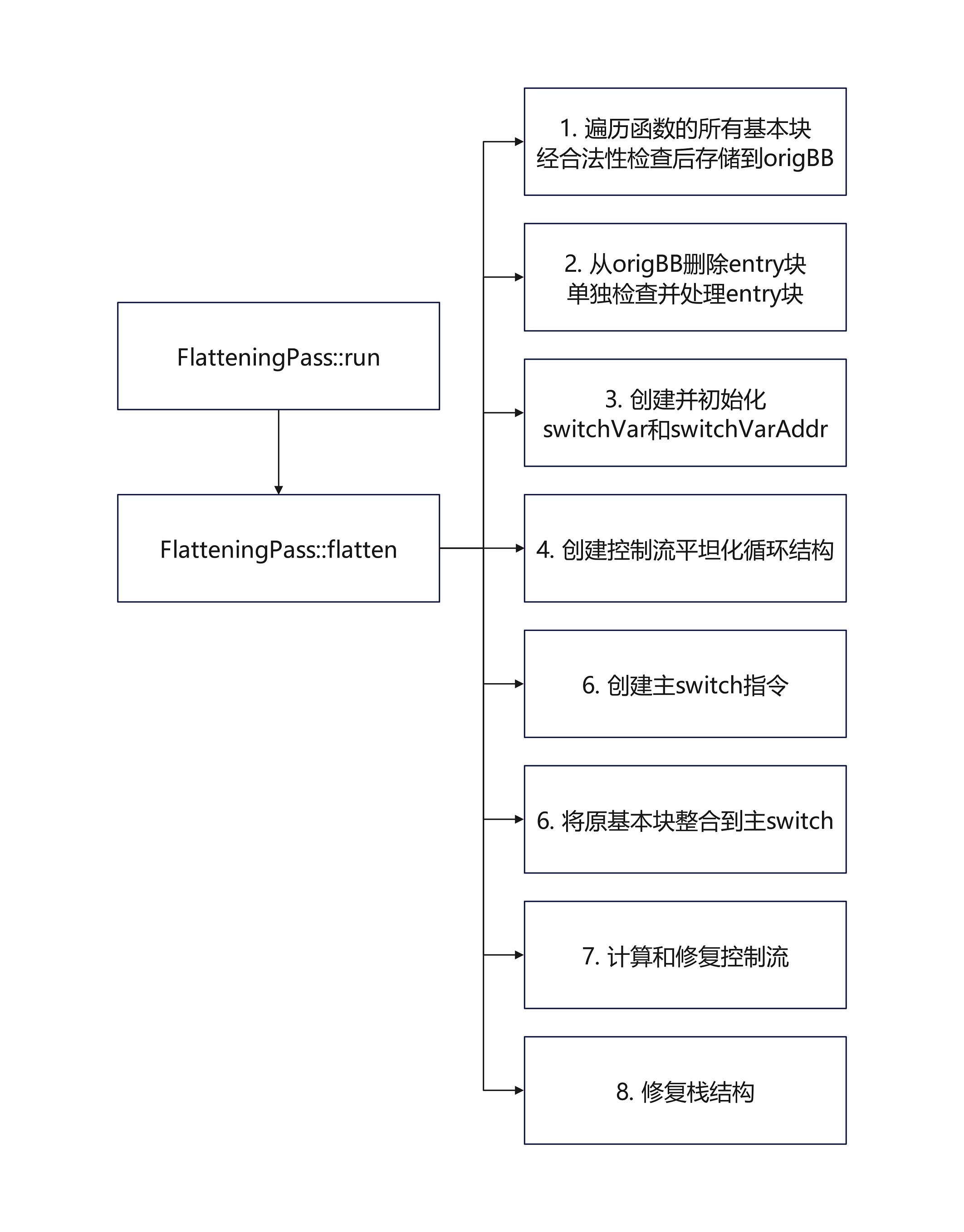
功能: 重整基本块关系, 将控制流由垂直转为平坦化
先学习简单的旧版flatten函数
参考[原创] OLLVM 攻略笔记 中00cK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6S2L8h3W2E0L8#2)9J5c8X3N6G2M7X3!0F1i4@1f1%4i4K6W2m8i4K6R3@1k6X3I4S2N6s2c8W2L8R3`.`.
关键步骤:
将函数中的switch结构转换为if-else结构简化控制流,保证平坦化后只有一个主switch结构
存储所有基本块到oriBB, 若遇到异常处理调用指令invoke则终止平坦化
从oriBB中删除entry块, 并单独处理entry块
如果entry块以条件分支结束且有多个后继块则进行分割
无论如何都去除entry块的终止指令
创建并初始化switchVar变量, 该变量用于存储switch的条件值
创建控制流平坦化的循环结构
创建主switch指令
将所有原始基本块整合到主switch中
修复栈结构,优化switch结构
新版flatten函数和旧版在整体结构上基本一致, 细节略有区别, 代码量加倍
其中有一个非常关键的概念: 降级到栈上
首先了解一下LLVM中数据的存储方式:
需要注意:
降级到栈上 ≠ 简单的将寄存器值保存到栈
而是将原本使用 SSA 寄存器形式的值,转换为通过栈内存分配和访问的形式
SSA虚拟寄存器 ≠ 物理寄存器
SSA寄存器是LLVM中的中间表示, 是否使用物理寄存器需通过映射算法确定
对于普通指令的降级 (DemoteRegToStack):
降级前: 原始代码使用SSA寄存器存储add结果
降级后:
对于 PHI 节点的降级 (DemotePHIToStack):
降级前: 使用SSA虚拟寄存器向PHI Node传递值
降级后: 分支将具体值存入栈中供PHI Node选取使用
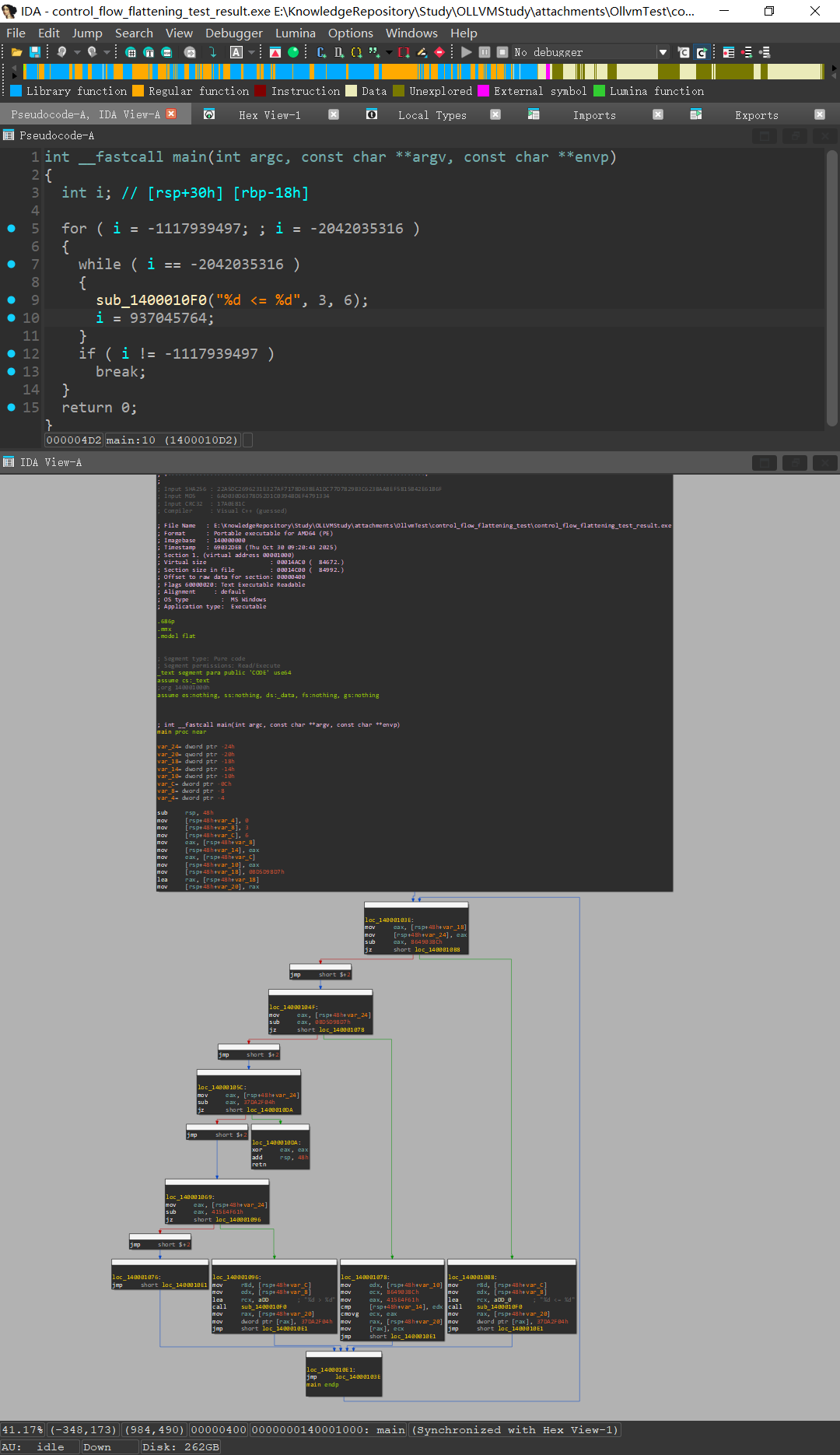
混淆前: 包含entry, if.then, if.else, if.end 共4个基本块
混淆后: 包含entry, if.then, if.else, if.end, first, loopEntry, loopEnd, switchDefault 共8个基本块
逐步解析相关变化, 首先从entry块切入
有3处改动
%x和%y声明后插入降级声明代码
%x和%y赋值后reg2mem降级操作
替换icmp和br指令
entry块设置 %switchVar = -1117939497 后跳转到loopEntry块, 不难发现实际是跳转到first块
回顾flatten中第2步处理entry块:
如果entry的终止指令是branch则获取
如果该branch指令是条件分支指令或者有多个后继块则分割entry
entry块指令数=1时迭代器从end前移1单位,否则前移2单位
利用迭代器分割entry后,新块命名为first并添加到origBB头部
所以icmp和br指令实际上被分配给了first块:
loopEnd块只会跳转回loopEntry
而first块中的case值分别对应if-else结构的两个分支块
if.then和if.else代码类似
先加载x和y值后调用printf函数打印, 之后获取switchVar指针并设置case值, 跳转到loopEnd
此处case值固定为937045764, 对应if.end块
执行到if.end块后运行ret指令退出main函数, 至此通过entry切入, 混淆后的main函数分析完毕
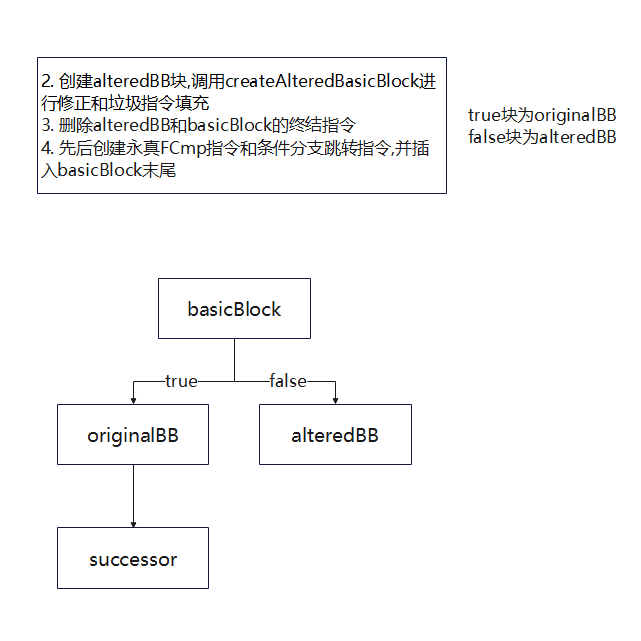
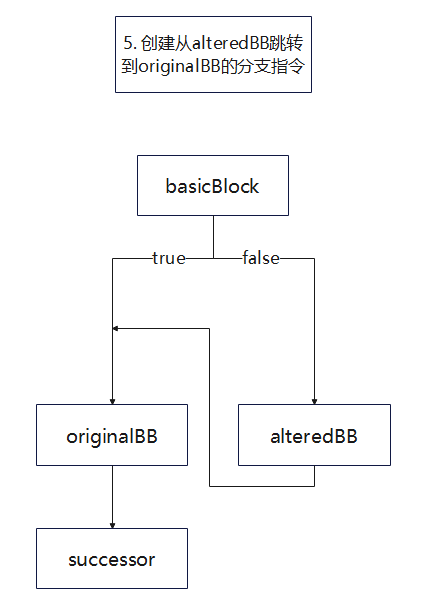
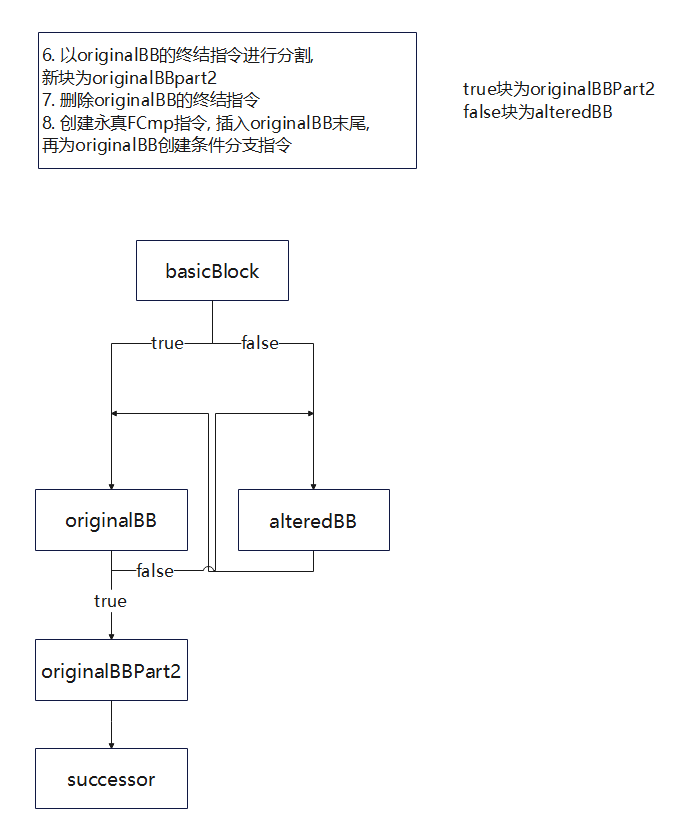
功能: 创建虚假分支块从而混淆原程序控制流
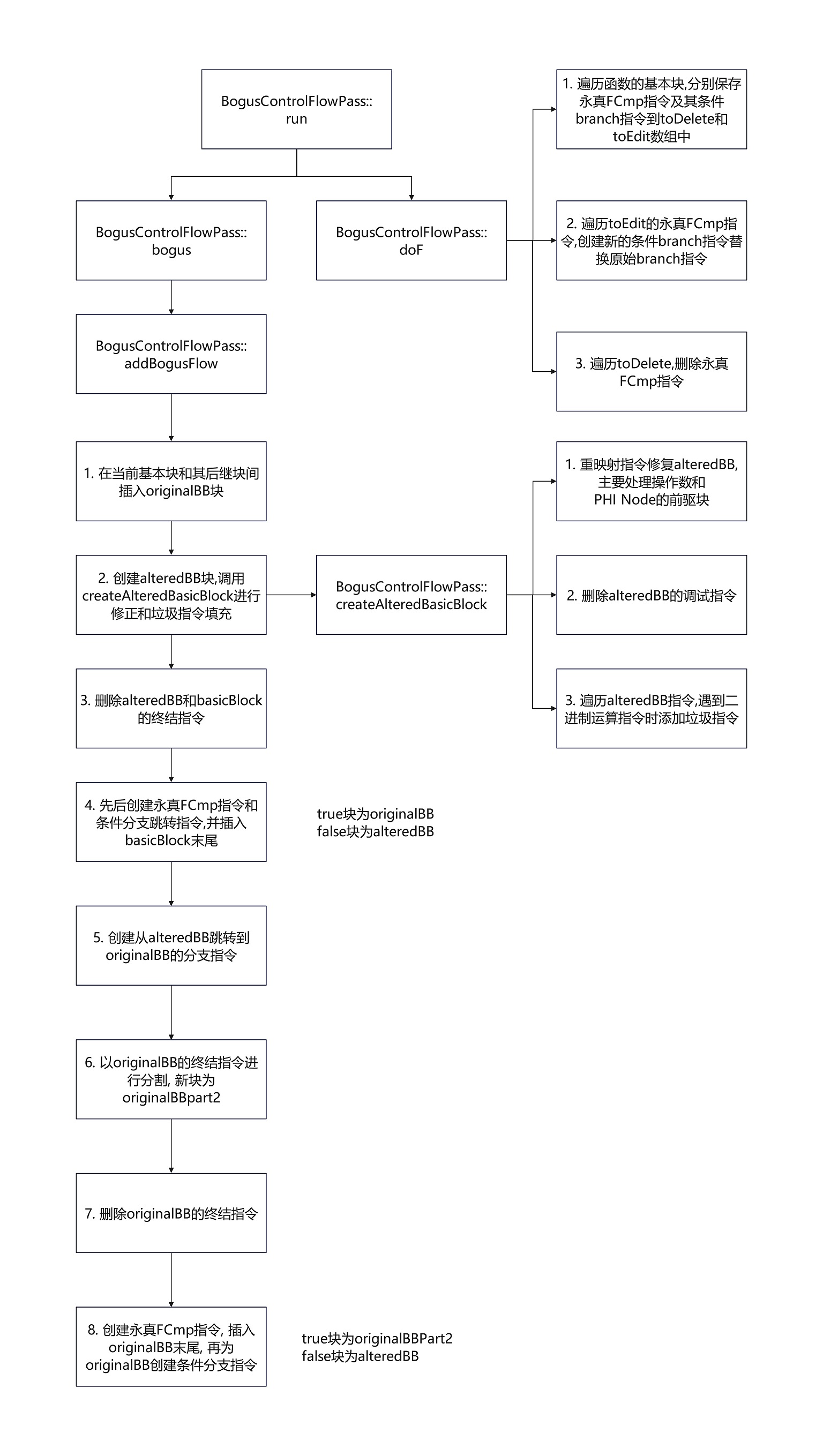
BogusControlFlow的关键流程如下,先调用bogus后调用doF
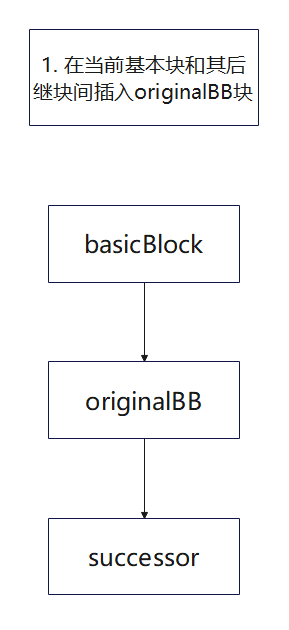
由于代码比较绕, 为了清晰展示流程额外绘制几张混淆过程中的基本块变化图
假设需要混淆的基本块名为basicBlock
可以发现,原本basicBlock->successor的控制流经过一次bogus混淆后额外添加了3个干扰基本块
bcf中主要执行bogus和doF
bogus添加虚假控制流
doF创建并替换bogus中创建的永真条件跳转指令为一般条件跳转指令
该函数用于fork虚假块, 并填充垃圾指令
注意: pass默认的bcf_loop=2, 调试时通过--bcf_loop=1参数限制只做一次bogus保证易于分析
混淆前
混淆后
混淆后的结果和开头流程分析时给定的流程类似,此处不过多赘述
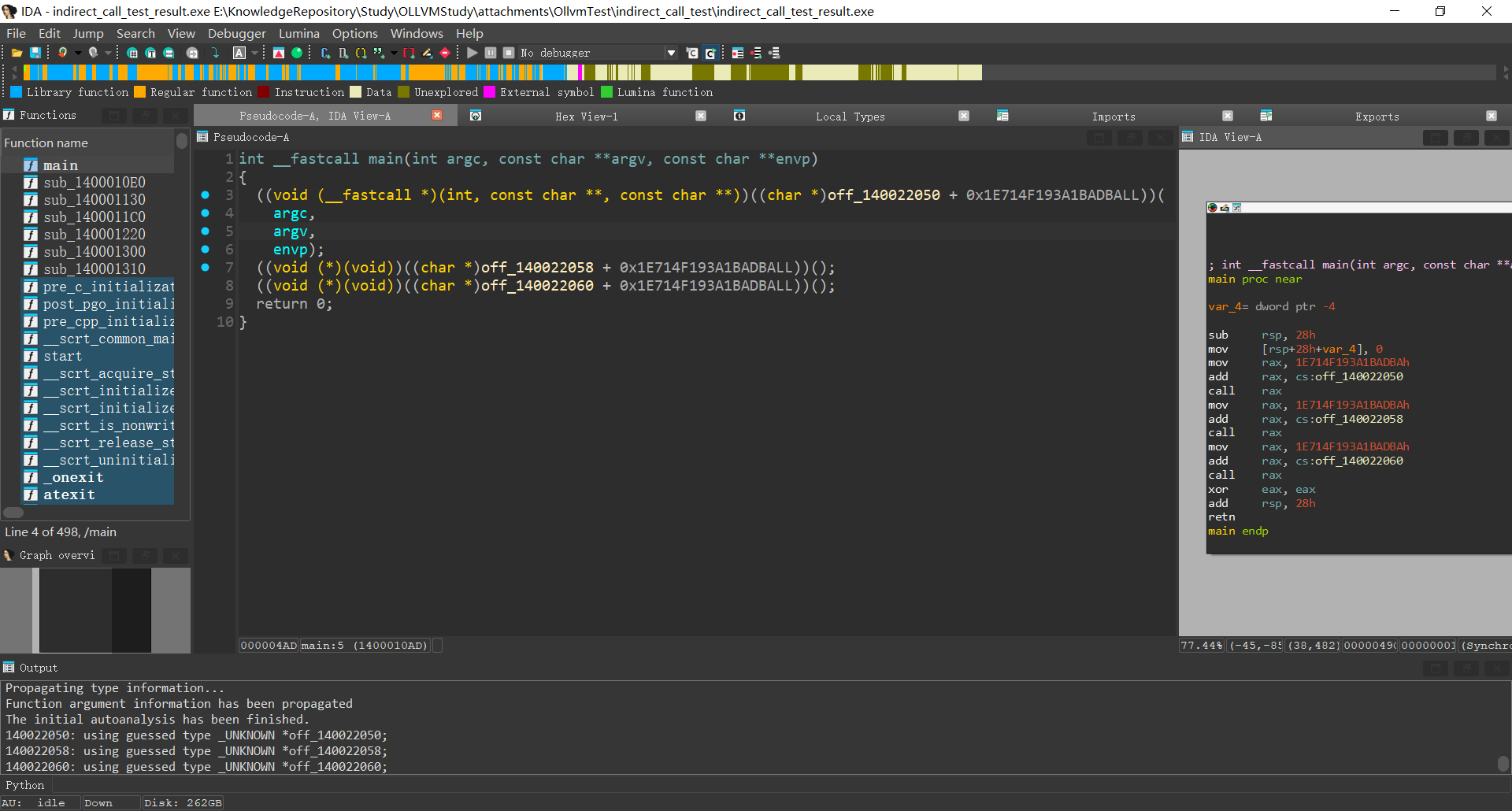
功能:将基本块间的条件跳转替换为间接条件跳转
例如if和if-else结构, 无论哪种情况都存在条件真分支和条件假分支
没有封装到函数中,直接于run方法内实现混淆逻辑
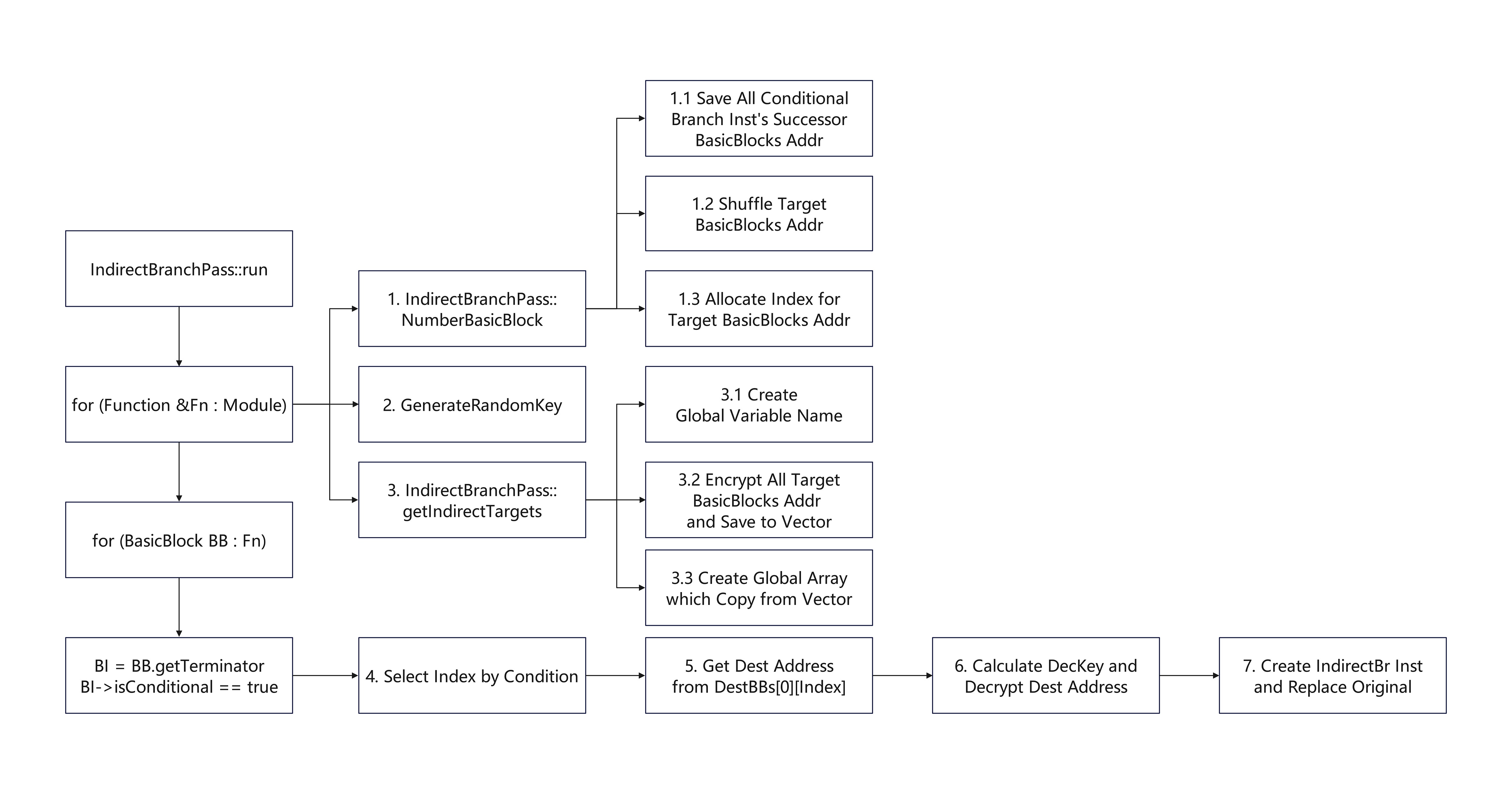
功能: 收集函数中所有条件分支指令的目标基本块并分配随机索引
功能: 创建全局间接分支目标基本块地址数组,加密并保存间接分支目标基本块地址
这是llvm的一个工具类方法, 定义于: ~\llvm\lib\Transforms\Utils\BasicBlockUtils.cpp
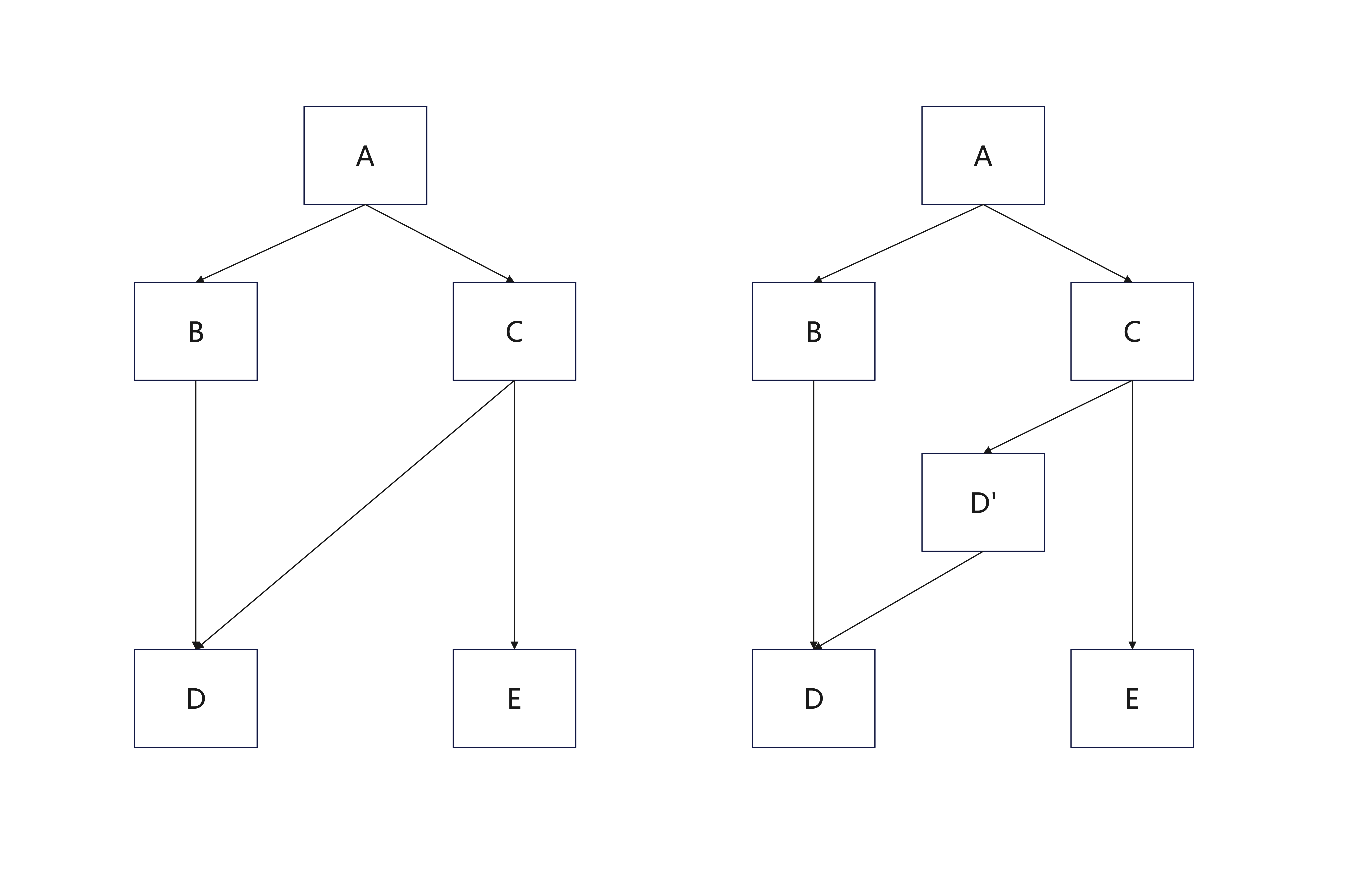
该函数用于分离临界边,那么什么是临界边,为什么要分离临界边?
临界边: 从一个具有多个后继的块(即分支块), 到一个具有多个前驱的块(即汇聚块)的边
一条边 BB → Succ 是临界边,当且仅当:
临界边在进行某些变换时(比如插入新块、拆分控制流、混淆等)会带来困难
拆分临界边的操作及其作用:
例如C有多个后继,D有多个前驱, 所以C->D是临界边
假设修改C块末尾的br指令为indirectbr, 很显然会影响C->E, 破坏原有语义
假设修改D的入口指令, 显然会影响B->D, 破坏原有语义
所以解决方法是拆分临界边,在C->D之间插入新块D', 即C->D'->D
之后的操作可基于D'进行, 无论修改D'的入口还是出口代码均不会影响其他边
参考llvm进阶(1)SplitAllCriticalEdges(关键边切割的艺术)
混淆前的main函数
混淆后的main函数
关于entry块
不难发现关键点为 entry块末尾的br条件分支指令
被替换成
逐步解析以上代码:
" %cmp = icmp eq i32 %0, %1 "
对应测试代码中的 if(a==b){...}
" %2 = select i1 %cmp, i64 0, i64 1 "
对应Pass中如下代码
先从原始的br指令中获取后继的条件真和条件假对应的基本块地址
再根据地址从BBNumbering中获取对应基本块索引
最后根据原始br指令的跳转条件, 创建select指令, 根据结果选择不同索引赋给Idx
" %3 = getelementptr [4 x ptr], ptr @main_IndirectBrTargets, i64 0, i64 %2 "
对应Pass中如下代码
先使用IRB.CreateGEP从目标基本块地址表DestBBs中获取Idx对应的元素地址
再通过IRB.CreateLoad从GEP指针中加载得到目标基本块地址 (加密状态)
等价于访问数组和解引用指针
" %4 = getelementptr i8, ptr %EncDestAddr, i64 -8909362643113078243 "
对应Pass的如下代码
先计算解密密钥, 后解密目标地址
注意此处的EncKey实际上是解密密钥
Pass中使用EncKey的相反数EncKey1作为加密秘钥生成间接分支目标地址全局表
" indirectbr ptr %4, [label %if.then, label %if.else] "
对应Pass代码如下
注意点:
IRB.CreateGEP
该函数用于计算元素指针, 本质是根据首地址+偏移计算目标地址
函数原形:
值得一提的是通过参数1数据类型和参数3索引列表, 可实现多级数组或结构体访问
例如第一次调用时传入"DestBBs->getValueType()" 和 "{Zero, Idx}" 对应 "&DestBBs[0][Idx]"
而第二次调用时传入"Type::getInt8Ty(Ctx)" 和 "DecKey" 对应 "EncDestAddr+DecKey"
IndirectBrInst
indirectbr指令可以有多个合法目标地址, 但具体时刻的真实目标地址只有一个
if.else块,同上类似
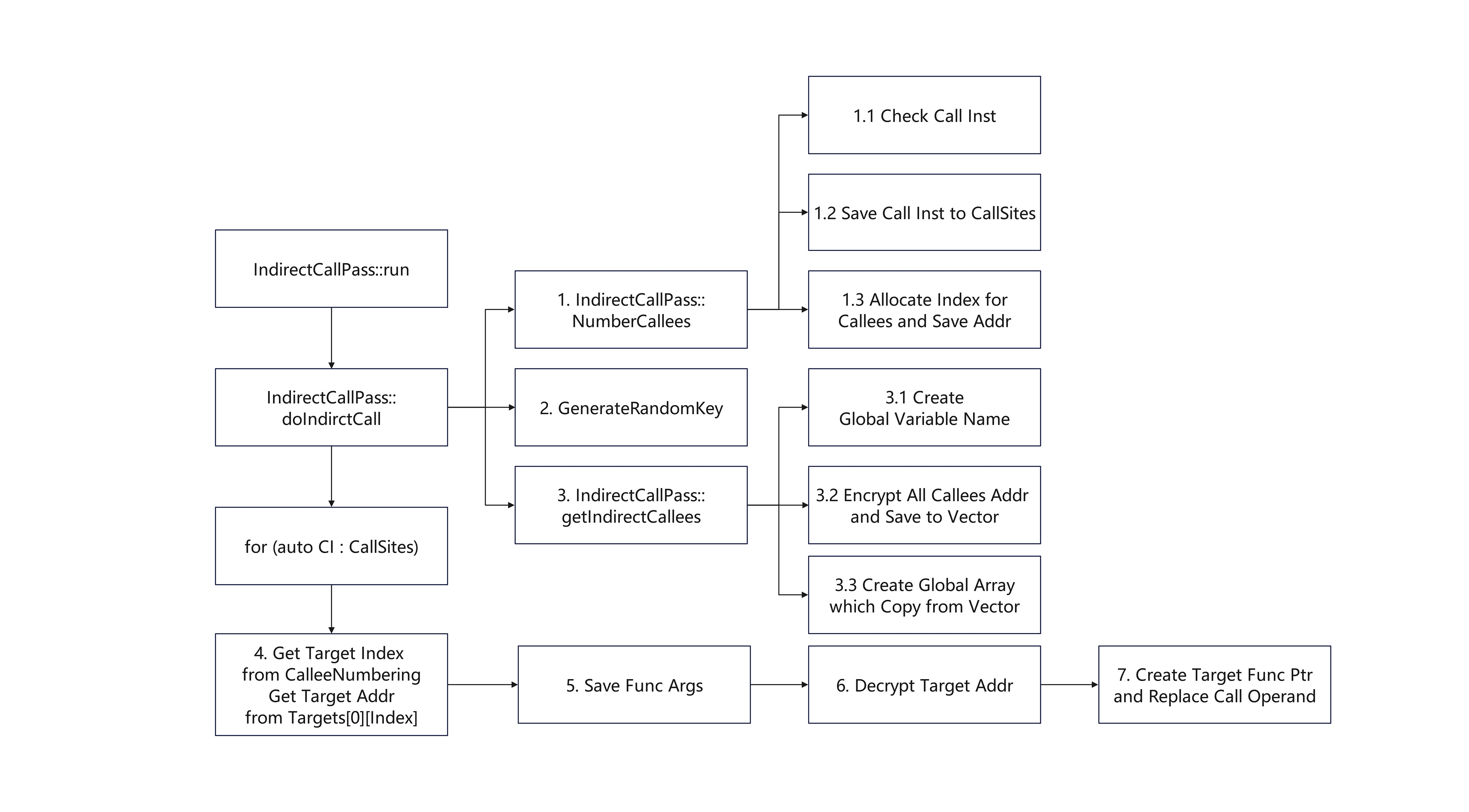
功能: 加密函数调用地址, 将bl指令替换为blr指令
和Indirect Branch基本结构类似, 更加简单
功能: 收集函数中的直接调用点, 并为被调函数编号
功能: 创建/获取用于存储加密函数地址的全局变量指针
混淆前
混淆后
不难看出结构基本类似, 以func1为例:
被替换为
以上代码逻辑非常简单:
从LLVM再到OLLVM, 混淆的核心基于LLVM的Pass机制, 想深入OLLVM则需要学习LLVM, 从而实现自定义的混淆pass
在此推荐 Getting Started with LLVM Core Libraries(中文版) 和《LLVM编译器原理与实践》作者: 吴建明 吴一昊
本文的不足之处:
LLVM基础部分没有系统性深入讲解, 仅介绍了基本的编译和使用
以Windows平台为主, 相较其他平台更容易踩坑
未实现脱离LLVM源码编译Obfuscation Pass
大部分文章基于老版本Pass管理器脱离llvm项目源码, 暂时没看到涉及新版Pass管理器的脱离案例
每次调试都会重新编译项目, 虽然调试时改动不大, 但总觉得不够优雅
使用时如果添加其他Pass也会影响整个项目, 有待改进
由于本文知识水平有限, 如有其他不足或补充之处望师傅们及时指出
下篇文章将基于本文, 总结OLLVM去混淆的各种方案并实战具体样本 (立个新坑flag)
相关资料:
[原创]llvm学习笔记——llvm基础
OLLVM混淆源码解读
[原创] OLLVM 攻略笔记
LLVM 全面解析:NDK 为什么离不开它?如何亲手编译调试 clang
LLVM 不止能编译!自定义 Pass + 定制 clang 实现函数名加密
OLLVM 移植 LLVM 18 实战,轻松实现 C&C++ 代码混淆
别让 so 裸奔!移植 OLLVM 到 NDK 并集成到 Android Studio
OLLVM相关项目:
注: 旧版Pass管理器的Pass文件位于 "llvm/lib/Transforms"; 新版Pass管理器的Pass位于 "llvm/lib/Passes"
ninja -j16
brew install cmake ninja
git clone --depth 1 --branch llvmorg-19.1.7 https://github.com/llvm/llvm-project.git
git clone --depth 1 --branch llvmorg-19.1.7 https://github.com/llvm/llvm-project.git
cd llvm-project-19.1.7
mkdir build
cd build
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_RTTI=ON -DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_PROJECTS="clang" ../llvm
cd llvm-project-19.1.7
mkdir build
cd build
cmake -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_RTTI=ON -DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_PROJECTS="clang" ../llvm
cmake -G Ninja -DCMAKE_BUILD_TYPE=Debug -DLLVM_ENABLE_RTTI=ON -DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_PROJECTS="llvm;clang;lld" ../llvm
cmake -G Ninja -DCMAKE_BUILD_TYPE=Debug -DLLVM_ENABLE_RTTI=ON -DLLVM_ENABLE_EH=ON -DLLVM_ENABLE_PROJECTS="llvm;clang;lld" ../llvm
ninja -j16
export PATH="/Users/orientalglass/Study/OLLVMStudy/attachents/llvm-project/build/bin:$PATH"
export PATH="/Users/orientalglass/Study/OLLVMStudy/attachents/llvm-project/build/bin:$PATH"
clang -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk /Users/orientalglass/Study/OLLVMStudy/attachents/Test/test.c -o /Users/orientalglass/Study/OLLVMStudy/attachents/Test/test
clang -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk /Users/orientalglass/Study/OLLVMStudy/attachents/Test/test.c -o /Users/orientalglass/Study/OLLVMStudy/attachents/Test/test
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
clang hello.c -o hello.exe
clang hello.c -o hello.exe
错误 MSB3073 命令“setlocal
"C:\Program Files\CMake\bin\cmake.exe" -DBUILD_TYPE=Release -P cmake_install.cmake
if %errorlevel% neq 0 goto :cmEnd
:cmEnd
endlocal & call :cmErrorLevel %errorlevel% & goto :cmDone
:cmErrorLevel
exit /b %1
:cmDone
if %errorlevel% neq 0 goto :VCEnd
:VCEnd”已退出,代码为 1。
INSTALL C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\Microsoft.CppCommon.targets 166
错误 MSB3073 命令“setlocal
"C:\Program Files\CMake\bin\cmake.exe" -DBUILD_TYPE=Release -P cmake_install.cmake
if %errorlevel% neq 0 goto :cmEnd
:cmEnd
endlocal & call :cmErrorLevel %errorlevel% & goto :cmDone
:cmErrorLevel
exit /b %1
:cmDone
if %errorlevel% neq 0 goto :VCEnd
:VCEnd”已退出,代码为 1。
INSTALL C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\Microsoft.CppCommon.targets 166
clang "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.c" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.exe"
clang "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.c" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.exe"
int add(int a, int b) {
return a + b;
}
int add(int a, int b) {
return a + b;
}
define i32 @add(i32 %a, i32 %b) {
entry:
%0 = add i32 %a, %b
ret i32 %0
}
define i32 @add(i32 %a, i32 %b) {
entry:
%0 = add i32 %a, %b
ret i32 %0
}
clang -emit-llvm -S hello.c -o hello.ll
clang -emit-llvm -S hello.c -o hello.ll
clang -emit-llvm -c hello.c -o hello.bc
clang -emit-llvm -c hello.c -o hello.bc
llvm-dis hello.bc -o hello_bc2ll.ll
llvm-dis hello.bc -o hello_bc2ll.ll
llvm-as hello.ll -o hello_ll2bc.bc
llvm-as hello.ll -o hello_ll2bc.bc
llc hello.bc -o hello.s
clang hello.s -o hello.exe
clang hello.s -o hello.exe
; ModuleID = 'hello.c'
source_filename = "hello.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-windows-msvc19.41.34123"
$sprintf = comdat any
$vsprintf = comdat any
$_snprintf = comdat any
$_vsnprintf = comdat any
$printf = comdat any
$_vsprintf_l = comdat any
$_vsnprintf_l = comdat any
$__local_stdio_printf_options = comdat any
$_vfprintf_l = comdat any
$"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@" = comdat any
@"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@" = linkonce_odr dso_local unnamed_addr constant [15 x i8] c"Hello, World!\0A\00", comdat, align 1
@__local_stdio_printf_options._OptionsStorage = internal global i64 0, align 8
......
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
store i32 0, ptr %retval, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@")
ret i32 0
}
......
entry:
%_ArgList.addr = alloca ptr, align 8
%_Locale.addr = alloca ptr, align 8
%_Format.addr = alloca ptr, align 8
%_Stream.addr = alloca ptr, align 8
store ptr %_ArgList, ptr %_ArgList.addr, align 8
store ptr %_Locale, ptr %_Locale.addr, align 8
store ptr %_Format, ptr %_Format.addr, align 8
store ptr %_Stream, ptr %_Stream.addr, align 8
%0 = load ptr, ptr %_ArgList.addr, align 8
%1 = load ptr, ptr %_Locale.addr, align 8
%2 = load ptr, ptr %_Format.addr, align 8
%3 = load ptr, ptr %_Stream.addr, align 8
%call = call ptr @__local_stdio_printf_options()
%4 = load i64, ptr %call, align 8
%call1 = call i32 @__stdio_common_vfprintf(i64 noundef %4, ptr noundef %3, ptr noundef %2, ptr noundef %1, ptr noundef %0)
ret i32 %call1
}
declare dso_local ptr @__acrt_iob_func(i32 noundef)
declare dso_local i32 @__stdio_common_vfprintf(i64 noundef, ptr noundef, ptr noundef, ptr noundef, ptr noundef)
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 2}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"uwtable", i32 2}
!3 = !{i32 1, !"MaxTLSAlign", i32 65536}
!4 = !{!"clang version 18.1.8 (f0eK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9L8s2k6E0i4K6u0r3L8r3I4$3L8g2)9J5k6s2m8J5L8$3A6W2j5%4c8Q4x3X3g2Y4K9i4b7`. 3b5b5c1ec4a3095ab096dd780e84d7ab81f3d7ff)"}
; ModuleID = 'hello.c'
source_filename = "hello.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-windows-msvc19.41.34123"
$sprintf = comdat any
$vsprintf = comdat any
$_snprintf = comdat any
$_vsnprintf = comdat any
$printf = comdat any
$_vsprintf_l = comdat any
$_vsnprintf_l = comdat any
$__local_stdio_printf_options = comdat any
$_vfprintf_l = comdat any
$"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@" = comdat any
@"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@" = linkonce_odr dso_local unnamed_addr constant [15 x i8] c"Hello, World!\0A\00", comdat, align 1
@__local_stdio_printf_options._OptionsStorage = internal global i64 0, align 8
......
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
store i32 0, ptr %retval, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0P@MHJMLPNF@Hello?0?5World?$CB?6?$AA@")
ret i32 0
}
......
entry:
%_ArgList.addr = alloca ptr, align 8
%_Locale.addr = alloca ptr, align 8
%_Format.addr = alloca ptr, align 8
%_Stream.addr = alloca ptr, align 8
store ptr %_ArgList, ptr %_ArgList.addr, align 8
store ptr %_Locale, ptr %_Locale.addr, align 8
store ptr %_Format, ptr %_Format.addr, align 8
store ptr %_Stream, ptr %_Stream.addr, align 8
%0 = load ptr, ptr %_ArgList.addr, align 8
%1 = load ptr, ptr %_Locale.addr, align 8
%2 = load ptr, ptr %_Format.addr, align 8
%3 = load ptr, ptr %_Stream.addr, align 8
%call = call ptr @__local_stdio_printf_options()
%4 = load i64, ptr %call, align 8
%call1 = call i32 @__stdio_common_vfprintf(i64 noundef %4, ptr noundef %3, ptr noundef %2, ptr noundef %1, ptr noundef %0)
ret i32 %call1
}
declare dso_local ptr @__acrt_iob_func(i32 noundef)
declare dso_local i32 @__stdio_common_vfprintf(i64 noundef, ptr noundef, ptr noundef, ptr noundef, ptr noundef)
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 2}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"uwtable", i32 2}
!3 = !{i32 1, !"MaxTLSAlign", i32 65536}
!4 = !{!"clang version 18.1.8 (f92K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6D9L8s2k6E0i4K6u0r3L8r3I4$3L8g2)9J5k6s2m8J5L8$3A6W2j5%4c8Q4x3X3g2Y4K9i4b7`. 3b5b5c1ec4a3095ab096dd780e84d7ab81f3d7ff)"}
LLVM IR (.ll / .bc)
↓
opt 工具
↓ (加载并执行多个 Pass)
┌───────────────┐
│ Pass A (分析) │
│ Pass B (优化) │
│ Pass C (混淆) │
└───────────────┘
↓
优化/变换后的 LLVM IR
LLVM IR (.ll / .bc)
↓
opt 工具
↓ (加载并执行多个 Pass)
┌───────────────┐
│ Pass A (分析) │
│ Pass B (优化) │
│ Pass C (混淆) │
└───────────────┘
↓
优化/变换后的 LLVM IR
opt -O3 hello.ll -o hello_optll.bc
opt -O3 hello.ll -o hello_optll.bc
opt -O3 hello.bc -S -o hello_optbc.ll
opt -O3 hello.bc -S -o hello_optbc.ll
opt -passes=mem2reg hello.ll -S -o hello_opt_mem2reg.ll
opt -passes=mem2reg hello.ll -S -o hello_opt_mem2reg.ll
opt -passes=inline hello.ll -S -o hello_opt_inline.ll
opt -passes=inline hello.ll -S -o hello_opt_inline.ll
opt -passes="mem2reg,inline,constprop" hello.ll -S -o hello_opt_passes.ll
opt -passes="mem2reg,inline,constprop" hello.ll -S -o hello_opt_passes.ll
opt -passes=dot-cfg hello.ll
opt -passes=dot-cfg hello.ll
-O3 "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.ll" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello_opt.bc"
-O3 "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello.ll" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\hello_opt.bc"
Pass
作用范围
适用场合
Module Pass
作用于整个llvm::Module
适用于需要全局视角的操作,例如链接优化或全局变量分析
Function Pass
针对每个函数 llvm::Function
适用于优化单个函数内的代码,例如循环优化、死代码删除等
Basic Block Pass
针对函数内的每个基本块(Basic Block)
通常用于优化基本块内部,例如指令合并、无用指令消除等
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass Manager 的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于注册和管理 Pass
#include "llvm/Passes/PassPlugin.h" // 用于实现动态插件的接口
#include "llvm/IR/Module.h" // 定义了 Module 类,用于表示 LLVM IR 的顶层结构
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,如 errs() 输出到标准错误流
using namespace llvm;
struct MyModulePass : PassInfoMixin<MyModulePass> {
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM) {
errs() << "Processing Module: " << M.getName() << "\n";
for (auto &F: M) {
errs() << "Function: " << F.getName() << "\n";
}
return PreservedAnalyses::all();
}
};
extern "C" PassPluginLibraryInfo llvmGetPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, ModulePassManager &MPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-module-pass") {
MPM.addPass(MyModulePass());
return true;
}
return false;
});
}};
}
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass Manager 的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于注册和管理 Pass
#include "llvm/Passes/PassPlugin.h" // 用于实现动态插件的接口
#include "llvm/IR/Module.h" // 定义了 Module 类,用于表示 LLVM IR 的顶层结构
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,如 errs() 输出到标准错误流
using namespace llvm;
struct MyModulePass : PassInfoMixin<MyModulePass> {
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM) {
errs() << "Processing Module: " << M.getName() << "\n";
for (auto &F: M) {
errs() << "Function: " << F.getName() << "\n";
}
return PreservedAnalyses::all();
}
};
extern "C" PassPluginLibraryInfo llvmGetPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, ModulePassManager &MPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-module-pass") {
MPM.addPass(MyModulePass());
return true;
}
return false;
});
}};
}
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
struct MyFunctionPass : public PassInfoMixin<MyFunctionPass> {
PreservedAnalyses run(Function &F, FunctionAnalysisManager &FAM) {
errs() << "Processing Function: " << F.getName() << "\n";
for (auto &BB : F) {
errs() << "Basic Block:\n";
for (auto &I : BB) {
errs() << I << "\n";
}
}
return PreservedAnalyses::all();
}
};
llvm::PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, FunctionPassManager &FPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-function-pass") {
FPM.addPass(MyFunctionPass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
struct MyFunctionPass : public PassInfoMixin<MyFunctionPass> {
PreservedAnalyses run(Function &F, FunctionAnalysisManager &FAM) {
errs() << "Processing Function: " << F.getName() << "\n";
for (auto &BB : F) {
errs() << "Basic Block:\n";
for (auto &I : BB) {
errs() << I << "\n";
}
}
return PreservedAnalyses::all();
}
};
llvm::PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, FunctionPassManager &FPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-function-pass") {
FPM.addPass(MyFunctionPass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
LIBRARY MyPass
EXPORTS
llvmGetPassPluginInfo
LIBRARY MyPass
EXPORTS
llvmGetPassPluginInfo
mkdir build && cd build
cmake -G "Ninja" -DCMAKE_BUILD_TYPE=Release ..
cmake --build .
mkdir build && cd build
cmake -G "Ninja" -DCMAKE_BUILD_TYPE=Release ..
cmake --build .
define i32 @main() {
ret i32 0
}
define i32 @main() {
ret i32 0
}
opt --load-pass-plugin=MyPass.dll --passes=my-function-pass -S test.ll -o test_opt.ll
Processing Function: main
Basic Block:
ret i32 0
opt --load-pass-plugin=MyPass.dll --passes=my-function-pass -S test.ll -o test_opt.ll
Processing Function: main
Basic Block:
ret i32 0
#include "llvm/IR/Function.h"
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
class MyFunctionPass : public PassInfoMixin<MyFunctionPass> {
public:
PreservedAnalyses run(Function &F, FunctionAnalysisManager &FAM) {
errs() << "Function: " << F.getName() << " (isDeclaration: " << F.isDeclaration() << ")\n";
if(F.getName().compare("main") !=0 ) {
for (auto &BB : F) {
errs() << "Basic Block:\n";
for (auto &I : BB) {
errs() << I << "\n";
}
}
}
return PreservedAnalyses::all();
}
};
PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyFunctionPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, FunctionPassManager &FPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-function-pass") {
FPM.addPass(MyFunctionPass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
#include "llvm/IR/Function.h"
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
class MyFunctionPass : public PassInfoMixin<MyFunctionPass> {
public:
PreservedAnalyses run(Function &F, FunctionAnalysisManager &FAM) {
errs() << "Function: " << F.getName() << " (isDeclaration: " << F.isDeclaration() << ")\n";
if(F.getName().compare("main") !=0 ) {
for (auto &BB : F) {
errs() << "Basic Block:\n";
for (auto &I : BB) {
errs() << I << "\n";
}
}
}
return PreservedAnalyses::all();
}
};
PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyFunctionPass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, FunctionPassManager &FPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-function-pass") {
FPM.addPass(MyFunctionPass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
#include "llvm/IR/Function.h"
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
class MyModulePass : public PassInfoMixin<MyModulePass> {
public:
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM) {
errs() << "Processing Module: " << M.getName() << "\n";
for (auto &F: M) {
errs() << "Function: " << F.getName() << "\n";
for(auto &BB: F) {
errs() << "Basic Block: " << BB.getName() << "\n";
for(auto &I: BB) {
errs() << I << "\n";
}
}
}
return PreservedAnalyses::all();
}
};
PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyModulePass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, ModulePassManager &MPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-module-pass") {
MPM.addPass(MyModulePass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
#include "llvm/IR/Function.h"
#include "llvm/IR/PassManager.h" // 包含 LLVM 新 Pass 管理器的头文件
#include "llvm/Passes/PassBuilder.h" // 提供 PassBuilder,用于构建和注册 Pass
#include "llvm/Passes/PassPlugin.h" // 提供 Pass 插件接口的支持
#include "llvm/IR/Module.h" // 定义 LLVM IR 的模块类
#include "llvm/Support/raw_ostream.h" // 提供 LLVM 的输出支持,比如 errs()
using namespace llvm;
class MyModulePass : public PassInfoMixin<MyModulePass> {
public:
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM) {
errs() << "Processing Module: " << M.getName() << "\n";
for (auto &F: M) {
errs() << "Function: " << F.getName() << "\n";
for(auto &BB: F) {
errs() << "Basic Block: " << BB.getName() << "\n";
for(auto &I: BB) {
errs() << I << "\n";
}
}
}
return PreservedAnalyses::all();
}
};
PassPluginLibraryInfo getPassPluginInfo() {
return {
LLVM_PLUGIN_API_VERSION,
"MyModulePass",
LLVM_VERSION_STRING,
[](PassBuilder &PB) {
PB.registerPipelineParsingCallback(
[](StringRef Name, ModulePassManager &MPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "my-module-pass") {
MPM.addPass(MyModulePass());
return true;
}
return false;
});
}};
}
extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo llvmGetPassPluginInfo() {
return getPassPluginInfo();
}
attributes
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main()
attributes
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main()
clang.exe -Xclang -disable-O0-optnone -emit-llvm -S main.c -o main.ll
clang.exe -Xclang -disable-O0-optnone -emit-llvm -S main.c -o main.ll
--load-pass-plugin="E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\MyPass.dll" --passes=my-function-pass -S "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\test.ll" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\test_opt.ll"
--load-pass-plugin="E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\MyPass.dll" --passes=my-function-pass -S "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\test.ll" -o "E:\KnowledgeRepository\Study\OLLVMStudy\attachments\MyPass\test_opt.ll"
#include <stdio.h>
const char *getHello() {
return "Hello,";
}
const char *getWorld() {
return "World!";
}
int main() {
const char *hello = getHello();
const char *world = getWorld();
printf("%s %s\n", hello, world);
return 0;
}
#include <stdio.h>
const char *getHello() {
return "Hello,";
}
const char *getWorld() {
return "World!";
}
int main() {
const char *hello = getHello();
const char *world = getWorld();
printf("%s %s\n", hello, world);
return 0;
}
clang -emit-llvm -S hello_test.c -o hello_test.ll
clang -emit-llvm -S hello_test.c -o hello_test.ll
opt --load-pass-plugin=./cmake-build-debug-visual-studio/MD5FunctionNamePass.dll --passes=md5-function-name-pass -S hello_test.ll -o hello_test_opt.ll
MD5FunctionNamePass Plugin Loaded Successfully.
Skipping standard library function: sprintf
Skipping standard library function: vsprintf
Skipping comdat function: _snprintf
Skipping comdat function: _vsnprintf
Original Function Name: getHello
MD5 Hash: 9d55bba9469f8ffcfe1202d85490c913
Original Function Name: getWorld
MD5 Hash: f612c236a8d854b3f6fa57efab4376d2
Skipping encryption for function: main
Skipping standard library function: printf
Skipping comdat function: _vsprintf_l
Skipping comdat function: _vsnprintf_l
Skipping comdat function: __local_stdio_printf_options
Skipping comdat function: _vfprintf_l
opt --load-pass-plugin=./cmake-build-debug-visual-studio/MD5FunctionNamePass.dll --passes=md5-function-name-pass -S hello_test.ll -o hello_test_opt.ll
MD5FunctionNamePass Plugin Loaded Successfully.
Skipping standard library function: sprintf
Skipping standard library function: vsprintf
Skipping comdat function: _snprintf
Skipping comdat function: _vsnprintf
Original Function Name: getHello
MD5 Hash: 9d55bba9469f8ffcfe1202d85490c913
Original Function Name: getWorld
MD5 Hash: f612c236a8d854b3f6fa57efab4376d2
Skipping encryption for function: main
Skipping standard library function: printf
Skipping comdat function: _vsprintf_l
Skipping comdat function: _vsnprintf_l
Skipping comdat function: __local_stdio_printf_options
Skipping comdat function: _vfprintf_l
clang -Xclang -load -Xclang MD5FunctionNamePass.dll hello.c -o hello.exe
clang -Xclang -load -Xclang MD5FunctionNamePass.dll hello.c -o hello.exe
clang -Xclang -fpass-plugin=MD5FunctionNamePass.dll hello.c -o hello.exe
clang -Xclang -fpass-plugin=MD5FunctionNamePass.dll hello.c -o hello.exe
#include "Obfuscation/BogusControlFlow.h" // 虚假控制流
#include "Obfuscation/Flattening.h" // 控制流平坦化
#include "Obfuscation/SplitBasicBlock.h" // 基本块分割
#include "Obfuscation/Substitution.h" // 指令替换
#include "Obfuscation/StringEncryption.h" // 字符串加密
#include "Obfuscation/IndirectGlobalVariable.h" // 间接全局变量
#include "Obfuscation/IndirectBranch.h" // 间接跳转
#include "Obfuscation/IndirectCall.h" // 间接调用
#include "Obfuscation/Utils.h" // 为了控制函数名混淆开关 (bool obf_function_name_cmd;)
static cl::opt<bool> s_obf_split("split", cl::init(false), cl::desc("SplitBasicBlock: split_num=3(init)"));
static cl::opt<bool> s_obf_sobf("sobf", cl::init(false), cl::desc("String Obfuscation"));
static cl::opt<bool> s_obf_fla("fla", cl::init(false), cl::desc("Flattening"));
static cl::opt<bool> s_obf_sub("sub", cl::init(false), cl::desc("Substitution: sub_loop"));
static cl::opt<bool> s_obf_bcf("bcf", cl::init(false), cl::desc("BogusControlFlow: application number -bcf_loop=x must be x > 0"));
static cl::opt<bool> s_obf_ibr("ibr", cl::init(false), cl::desc("Indirect Branch"));
static cl::opt<bool> s_obf_igv("igv", cl::init(false), cl::desc("Indirect Global Variable"));
static cl::opt<bool> s_obf_icall("icall", cl::init(false), cl::desc("Indirect Call"));
static cl::opt<bool> s_obf_fn_name_cmd("fncmd", cl::init(false), cl::desc("use function name control obfuscation(_ + command + _ | example: function_fla_bcf_)"));
#include "Obfuscation/BogusControlFlow.h" // 虚假控制流
#include "Obfuscation/Flattening.h" // 控制流平坦化
#include "Obfuscation/SplitBasicBlock.h" // 基本块分割
#include "Obfuscation/Substitution.h" // 指令替换
#include "Obfuscation/StringEncryption.h" // 字符串加密
#include "Obfuscation/IndirectGlobalVariable.h" // 间接全局变量
#include "Obfuscation/IndirectBranch.h" // 间接跳转
#include "Obfuscation/IndirectCall.h" // 间接调用
#include "Obfuscation/Utils.h" // 为了控制函数名混淆开关 (bool obf_function_name_cmd;)
static cl::opt<bool> s_obf_split("split", cl::init(false), cl::desc("SplitBasicBlock: split_num=3(init)"));
static cl::opt<bool> s_obf_sobf("sobf", cl::init(false), cl::desc("String Obfuscation"));
static cl::opt<bool> s_obf_fla("fla", cl::init(false), cl::desc("Flattening"));
static cl::opt<bool> s_obf_sub("sub", cl::init(false), cl::desc("Substitution: sub_loop"));
static cl::opt<bool> s_obf_bcf("bcf", cl::init(false), cl::desc("BogusControlFlow: application number -bcf_loop=x must be x > 0"));
static cl::opt<bool> s_obf_ibr("ibr", cl::init(false), cl::desc("Indirect Branch"));
static cl::opt<bool> s_obf_igv("igv", cl::init(false), cl::desc("Indirect Global Variable"));
static cl::opt<bool> s_obf_icall("icall", cl::init(false), cl::desc("Indirect Call"));
static cl::opt<bool> s_obf_fn_name_cmd("fncmd", cl::init(false), cl::desc("use function name control obfuscation(_ + command + _ | example: function_fla_bcf_)"));
PassBuilder::PassBuilder( ... ) : ... {
...
this->registerPipelineStartEPCallback(
[](llvm::ModulePassManager &MPM,
llvm::OptimizationLevel Level) {
outs() << "[OLLVM] run.PipelineStartEPCallback\n";
obf_function_name_cmd = s_obf_fn_name_cmd;
if (obf_function_name_cmd) {
outs() << "[OLLVM] enable function name control obfuscation(_ + command + _ | example: function_fla_)\n";
}
MPM.addPass(StringEncryptionPass(s_obf_sobf));
llvm::FunctionPassManager FPM;
FPM.addPass(IndirectCallPass(s_obf_icall));
FPM.addPass(SplitBasicBlockPass(s_obf_split));
FPM.addPass(FlatteningPass(s_obf_fla));
FPM.addPass(SubstitutionPass(s_obf_sub));
FPM.addPass(BogusControlFlowPass(s_obf_bcf));
MPM.addPass(createModuleToFunctionPassAdaptor(std::move(FPM)));
MPM.addPass(IndirectBranchPass(s_obf_ibr));
MPM.addPass(IndirectGlobalVariablePass(s_obf_igv));
MPM.addPass(RewriteSymbolPass());
}
);
}
PassBuilder::PassBuilder( ... ) : ... {
...
this->registerPipelineStartEPCallback(
[](llvm::ModulePassManager &MPM,
llvm::OptimizationLevel Level) {
outs() << "[OLLVM] run.PipelineStartEPCallback\n";
obf_function_name_cmd = s_obf_fn_name_cmd;
if (obf_function_name_cmd) {
outs() << "[OLLVM] enable function name control obfuscation(_ + command + _ | example: function_fla_)\n";
}
MPM.addPass(StringEncryptionPass(s_obf_sobf));
llvm::FunctionPassManager FPM;
FPM.addPass(IndirectCallPass(s_obf_icall));
FPM.addPass(SplitBasicBlockPass(s_obf_split));
FPM.addPass(FlatteningPass(s_obf_fla));
FPM.addPass(SubstitutionPass(s_obf_sub));
FPM.addPass(BogusControlFlowPass(s_obf_bcf));
MPM.addPass(createModuleToFunctionPassAdaptor(std::move(FPM)));
MPM.addPass(IndirectBranchPass(s_obf_ibr));
MPM.addPass(IndirectGlobalVariablePass(s_obf_igv));
MPM.addPass(RewriteSymbolPass());
}
);
}
ninja -j16
/Users/orientalglass/Study/OLLVMStudy/attachents/llvm-project/llvm/lib/Passes/Obfuscation/compat/CallSite.h:137:18: error: no member named 'isOpaqueOrPointeeTypeMatches' in 'llvm::PointerType'
136 | assert(cast<PointerType>(V->getType())
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
137 | ->isOpaqueOrPointeeTypeMatches(
|
/Users/orientalglass/Study/OLLVMStudy/attachents/llvm-project/llvm/lib/Passes/Obfuscation/compat/CallSite.h:137:18: error: no member named 'isOpaqueOrPointeeTypeMatches' in 'llvm::PointerType'
136 | assert(cast<PointerType>(V->getType())
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
137 | ->isOpaqueOrPointeeTypeMatches(
|
#if LLVM_VERSION_MAJOR >= 15
assert(cast<PointerType>(V->getType())
->isOpaqueOrPointeeTypeMatches(
cast<CallBase>(getInstruction())->getFunctionType()) &&
"New callee type does not match FunctionType on call");
#else
assert(cast<PointerType>(V->getType())->getElementType() ==
cast<CallBase>(getInstruction())->getFunctionType() &&
"New callee type does not match FunctionType on call");
#endif
*getCallee() = V;
#if LLVM_VERSION_MAJOR >= 15
assert(cast<PointerType>(V->getType())
->isOpaqueOrPointeeTypeMatches(
cast<CallBase>(getInstruction())->getFunctionType()) &&
"New callee type does not match FunctionType on call");
#else
assert(cast<PointerType>(V->getType())->getElementType() ==
cast<CallBase>(getInstruction())->getFunctionType() &&
"New callee type does not match FunctionType on call");
#endif
*getCallee() = V;
#if LLVM_VERSION_MAJOR < 17
auto *PtrTy = cast<PointerType>(V->getType());
auto *FuncTy = cast<CallBase>(getInstruction())->getFunctionType();
assert(PtrTy->getElementType() == FuncTy &&
"New callee type does not match FunctionType on call");
#endif
*getCallee() = V;
#if LLVM_VERSION_MAJOR < 17
auto *PtrTy = cast<PointerType>(V->getType());
auto *FuncTy = cast<CallBase>(getInstruction())->getFunctionType();
assert(PtrTy->getElementType() == FuncTy &&
"New callee type does not match FunctionType on call");
#endif
*getCallee() = V;
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int sum;
sum = a + b;
printf("结果是: %d + %d = %d\n", a, b, sum);
return 0;
}
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int sum;
sum = a + b;
printf("结果是: %d + %d = %d\n", a, b, sum);
return 0;
}
clang add.c -o add.exe
clang -mllvm -sub -mllvm -sub_loop=3 add.c -o add_sub_loop3.exe
clang -mllvm -sub -mllvm -sub_loop=3 add.c -o add_sub_loop3.exe
-mllvm -sub
-mllvm -sub -mllvm -sub_loop=3 启用指令替换功能,并对每个指令应用3次替换操作(默认为1次)
-mllvm -sub
-mllvm -sub -mllvm -sub_loop=3 启用指令替换功能,并对每个指令应用3次替换操作(默认为1次)
%0 = load i32* %a, align 4 ; 从指针 %a 加载一个 32 位整数到 %0,%a 是一个 4 字节对齐的内存地址
%1 = load i32* %b, align 4 ; 从指针 %b 加载一个 32 位整数到 %1,%b 是一个 4 字节对齐的内存地址
%2 = sub i32 0, %1 ; 计算 0 - %1,结果存储到 %2,相当于取 %1 的相反数(-b)
%3 = sub nsw i32 %0, %2 ; 计算 %0 - %2,结果存储到 %3,其中 nsw(No Signed Wrap)指示结果不会发生有符号溢出
%0 = load i32* %a, align 4 ; 从指针 %a 加载一个 32 位整数到 %0,%a 是一个 4 字节对齐的内存地址
%1 = load i32* %b, align 4 ; 从指针 %b 加载一个 32 位整数到 %1,%b 是一个 4 字节对齐的内存地址
%2 = sub i32 0, %1 ; 计算 0 - %1,结果存储到 %2,相当于取 %1 的相反数(-b)
%3 = sub nsw i32 %0, %2 ; 计算 %0 - %2,结果存储到 %3,其中 nsw(No Signed Wrap)指示结果不会发生有符号溢出
int add(int a, int b) {
return a + b;
}
int add(int a, int b) {
return a + b;
}
int add(int a, int b) {
int bogus_condition = (a ^ b) & 0x1;
if (bogus_condition) {
for (int i = 0; i < 10; i++) {
a += i;
}
} else {
return a + b;
}
return a + b;
}
int add(int a, int b) {
int bogus_condition = (a ^ b) & 0x1;
if (bogus_condition) {
for (int i = 0; i < 10; i++) {
a += i;
}
} else {
return a + b;
}
return a + b;
}
clang -mllvm -bcf -mllvm -bcf_loop=3
clang -mllvm -bcf -mllvm -bcf_loop=3
clang -mllvm -bcf -mllvm -bcf_prob=40
clang -mllvm -bcf -mllvm -bcf_prob=40
int calculate(int x) {
if (x > 0) {
return x * 2;
} else {
return -x;
}
}
int calculate(int x) {
if (x > 0) {
return x * 2;
} else {
return -x;
}
}
int calculate(int x) {
int dispatcher = 0;
int result = 0;
while (1) {
switch (dispatcher) {
case 0:
if (x > 0) {
dispatcher = 1;
} else {
dispatcher = 2;
}
break;
case 1:
result = x * 2;
dispatcher = 3;
break;
case 2:
result = -x;
dispatcher = 3;
break;
case 3:
return result;
default:
return -1;
}
}
}
int calculate(int x) {
int dispatcher = 0;
int result = 0;
while (1) {
switch (dispatcher) {
case 0:
if (x > 0) {
dispatcher = 1;
} else {
dispatcher = 2;
}
break;
case 1:
result = x * 2;
dispatcher = 3;
break;
case 2:
result = -x;
dispatcher = 3;
break;
case 3:
return result;
default:
return -1;
}
}
}
clang -mllvm -fla
clang -mllvm -fla -mllvm -split
clang -mllvm -fla -mllvm -split -mllvm -split_num=3
clang -mllvm -fla
clang -mllvm -fla -mllvm -split
clang -mllvm -fla -mllvm -split -mllvm -split_num=3
┌──────────────────┐
│ C / C++ 源码 │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ LLVM (Clang) │ ← Android NDK 内置的官方编译器工具链
│ 前端:生成 IR │
└────────┬─────────┘
│ LLVM IR
▼
┌──────────────────┐
│ OLLVM Pass │ ← 基于 LLVM 的扩展:混淆(控制流平坦化、指令替换等)
│ (插入在中间) │
└────────┬─────────┘
│ 混淆后的 IR
▼
┌──────────────────┐
│ LLVM 后端优化 │
│ + 代码生成 │
└────────┬─────────┘
│ 汇编
▼
┌──────────────────┐
│ 链接生成 so │ ← 最终供 Android 应用调用的 native 库
└──────────────────┘
┌──────────────────┐
│ C / C++ 源码 │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ LLVM (Clang) │ ← Android NDK 内置的官方编译器工具链
│ 前端:生成 IR │
└────────┬─────────┘
│ LLVM IR
▼
┌──────────────────┐
│ OLLVM Pass │ ← 基于 LLVM 的扩展:混淆(控制流平坦化、指令替换等)
│ (插入在中间) │
└────────┬─────────┘
│ 混淆后的 IR
▼
┌──────────────────┐
│ LLVM 后端优化 │
│ + 代码生成 │
└────────┬─────────┘
│ 汇编
▼
┌──────────────────┐
│ 链接生成 so │ ← 最终供 Android 应用调用的 native 库
└──────────────────┘
package com.example.ollvm;
import androidx.appcompat.app.AppCompatActivity;
import android.os.Bundle;
import android.widget.TextView;
import com.example.ollvm.databinding.ActivityMainBinding;
public class MainActivity extends AppCompatActivity {
static {
System.loadLibrary("ollvm");
}
private ActivityMainBinding binding;
public native int sub(int a,int b);
public native String bcf(String str);
public native String fla(int x,int y);
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
binding = ActivityMainBinding.inflate(getLayoutInflater());
setContentView(binding.getRoot());
TextView tv = binding.sampleText;
String result=sub(9,3)+bcf("Hello, OLLVM!")+fla(1,2);
tv.setText(result);
}
}
package com.example.ollvm;
import androidx.appcompat.app.AppCompatActivity;
import android.os.Bundle;
import android.widget.TextView;
import com.example.ollvm.databinding.ActivityMainBinding;
public class MainActivity extends AppCompatActivity {
static {
System.loadLibrary("ollvm");
}
private ActivityMainBinding binding;
public native int sub(int a,int b);
public native String bcf(String str);
public native String fla(int x,int y);
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
binding = ActivityMainBinding.inflate(getLayoutInflater());
setContentView(binding.getRoot());
TextView tv = binding.sampleText;
String result=sub(9,3)+bcf("Hello, OLLVM!")+fla(1,2);
tv.setText(result);
}
}
#include <jni.h>
#include <string>
#include <sstream>
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_ollvm_MainActivity_sub(JNIEnv *env, jobject thiz, jint a, jint b) {
return a-b;
}
extern "C"
JNIEXPORT jstring JNICALL
Java_com_example_ollvm_MainActivity_bcf(JNIEnv *env, jobject thiz, jstring str) {
const char* input=env->GetStringUTFChars(str, nullptr);
std::string result=std::string("BCF: ")+input;
return env->NewStringUTF(result.c_str());
}
extern "C"
JNIEXPORT jstring JNICALL
Java_com_example_ollvm_MainActivity_fla(JNIEnv *env, jobject thiz, jint x, jint y) {
int sum = x + y;
std::ostringstream result;
if (sum < 5) {
result << "x = " << x << ", y = " << y << ", x + y " << "< 5";
} else if(sum == 5){
result << "x = " << x << ", y = " << y << ", x + y " << "= 5";
} else{
result << "x = " << x << ", y = " << y << ", x + y " << "> 5";
}
return env->NewStringUTF(result.str().c_str());
}
#include <jni.h>
#include <string>
#include <sstream>
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_ollvm_MainActivity_sub(JNIEnv *env, jobject thiz, jint a, jint b) {
return a-b;
}
extern "C"
JNIEXPORT jstring JNICALL
Java_com_example_ollvm_MainActivity_bcf(JNIEnv *env, jobject thiz, jstring str) {
const char* input=env->GetStringUTFChars(str, nullptr);
std::string result=std::string("BCF: ")+input;
return env->NewStringUTF(result.c_str());
}
extern "C"
JNIEXPORT jstring JNICALL
Java_com_example_ollvm_MainActivity_fla(JNIEnv *env, jobject thiz, jint x, jint y) {
int sum = x + y;
std::ostringstream result;
if (sum < 5) {
result << "x = " << x << ", y = " << y << ", x + y " << "< 5";
} else if(sum == 5){
result << "x = " << x << ", y = " << y << ", x + y " << "= 5";
} else{
result << "x = " << x << ", y = " << y << ", x + y " << "> 5";
}
return env->NewStringUTF(result.str().c_str());
}
-mllvm -sub -mllvm -sub_loop=3 -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -fla -mllvm -split -mllvm -split_num=3
-mllvm -sub -mllvm -sub_loop=3 -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -fla -mllvm -split -mllvm -split_num=3
#ifndef PRINT_UTILS_H
#define PRINT_UTILS_H
#include "llvm/IR/Function.h"
#include "llvm/IR/BasicBlock.h"
#include "llvm/IR/Instruction.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
void printInstruction(Instruction& inst);
void printBasicBlock(BasicBlock& BB);
void printFunction(Function& func);
#endif
#ifndef PRINT_UTILS_H
#define PRINT_UTILS_H
#include "llvm/IR/Function.h"
#include "llvm/IR/BasicBlock.h"
#include "llvm/IR/Instruction.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
void printInstruction(Instruction& inst);
void printBasicBlock(BasicBlock& BB);
void printFunction(Function& func);
#endif
#include "PrintUtils.h"
void printInstruction(Instruction& inst) {
inst.print(outs());
outs()<<"\n";
}
void printBasicBlock(BasicBlock& BB) {
BB.print(outs());
outs()<<"\n";
}
void printFunction(Function& func) {
func.print(outs());
outs()<<"\n";
}
#include "PrintUtils.h"
void printInstruction(Instruction& inst) {
inst.print(outs());
outs()<<"\n";
}
void printBasicBlock(BasicBlock& BB) {
BB.print(outs());
outs()<<"\n";
}
void printFunction(Function& func) {
func.print(outs());
outs()<<"\n";
}
clang -Xclang -disable-O0-optnone -emit-llvm -S main.c -o main.ll
clang -Xclang -disable-O0-optnone -emit-llvm -S main.c -o main.ll
opt -O0 --sub add.ll -S -o add_opt_test.ll
opt -O0 --sub add.ll -S -o add_opt_test.ll
-O0
-S
--bcf
--bcf_loop=1
E:\KnowledgeRepository\Study\OLLVMStudy\attachments\OllvmTest\bogus_control_flow_test\bogus_control_flow_test.ll
-o
E:\KnowledgeRepository\Study\OLLVMStudy\attachments\OllvmTest\bogus_control_flow_test\bogus_control_flow_test_result.ll
-O0
-S
--bcf
--bcf_loop=1
E:\KnowledgeRepository\Study\OLLVMStudy\attachments\OllvmTest\bogus_control_flow_test\bogus_control_flow_test.ll
-o
E:\KnowledgeRepository\Study\OLLVMStudy\attachments\OllvmTest\bogus_control_flow_test\bogus_control_flow_test_result.ll
PreservedAnalyses SubstitutionPass::run(Function &F, FunctionAnalysisManager &AM) {
if (ObfTimes <= 0) {
errs() << "Substitution application number -sub_loop=x must be x > 0";
return PreservedAnalyses::all();
}
Function *tmp = &F;
if (toObfuscate(flag, tmp, "sub")) {
substitute(tmp);
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
PreservedAnalyses SubstitutionPass::run(Function &F, FunctionAnalysisManager &AM) {
if (ObfTimes <= 0) {
errs() << "Substitution application number -sub_loop=x must be x > 0";
return PreservedAnalyses::all();
}
Function *tmp = &F;
if (toObfuscate(flag, tmp, "sub")) {
substitute(tmp);
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
bool SubstitutionPass::substitute(Function *f) {
Function *tmp = f;
int times = ObfTimes;
do {
for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) {
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) {
if (inst->isBinaryOp()) {
switch (inst->getOpcode()) {
case BinaryOperator::Add:
(this->*funcAdd[llvm::cryptoutils->get_range(NUMBER_ADD_SUBST)])(
cast<BinaryOperator>(inst));
++Add;
break;
case BinaryOperator::Sub:
(this->*funcSub[llvm::cryptoutils->get_range(NUMBER_SUB_SUBST)])(
cast<BinaryOperator>(inst));
++Sub;
break;
default:
break;
}
}
}
}
} while (--times > 0);
return false;
}
bool SubstitutionPass::substitute(Function *f) {
Function *tmp = f;
int times = ObfTimes;
do {
for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) {
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) {
if (inst->isBinaryOp()) {
switch (inst->getOpcode()) {
case BinaryOperator::Add:
(this->*funcAdd[llvm::cryptoutils->get_range(NUMBER_ADD_SUBST)])(
cast<BinaryOperator>(inst));
++Add;
break;
case BinaryOperator::Sub:
(this->*funcSub[llvm::cryptoutils->get_range(NUMBER_SUB_SUBST)])(
cast<BinaryOperator>(inst));
++Sub;
break;
default:
break;
}
}
}
}
} while (--times > 0);
return false;
}
#define NUMBER_ADD_SUBST 7
#define NUMBER_SUB_SUBST 6
#define NUMBER_AND_SUBST 6
#define NUMBER_OR_SUBST 6
#define NUMBER_XOR_SUBST 6
#define NUMBER_MUL_SUBST 2
namespace llvm {
class SubstitutionPass : public PassInfoMixin<SubstitutionPass> {
public:
bool flag;
void (SubstitutionPass::*funcAdd[NUMBER_ADD_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcSub[NUMBER_SUB_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcAnd[NUMBER_AND_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcOr[NUMBER_OR_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcXor[NUMBER_XOR_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcMul[NUMBER_MUL_SUBST])(BinaryOperator *bo);
SubstitutionPass(bool flag) {
this->flag = flag;
funcAdd[0] = &SubstitutionPass::addNeg;
funcAdd[1] = &SubstitutionPass::addDoubleNeg;
funcAdd[2] = &SubstitutionPass::addRand;
funcAdd[3] = &SubstitutionPass::addRand2;
funcAdd[4] = &SubstitutionPass::addSubstitution;
funcAdd[5] = &SubstitutionPass::addSubstitution2;
funcAdd[6] = &SubstitutionPass::addSubstitution3;
}
}
#define NUMBER_ADD_SUBST 7
#define NUMBER_SUB_SUBST 6
#define NUMBER_AND_SUBST 6
#define NUMBER_OR_SUBST 6
#define NUMBER_XOR_SUBST 6
#define NUMBER_MUL_SUBST 2
namespace llvm {
class SubstitutionPass : public PassInfoMixin<SubstitutionPass> {
public:
bool flag;
void (SubstitutionPass::*funcAdd[NUMBER_ADD_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcSub[NUMBER_SUB_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcAnd[NUMBER_AND_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcOr[NUMBER_OR_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcXor[NUMBER_XOR_SUBST])(BinaryOperator *bo);
void (SubstitutionPass::*funcMul[NUMBER_MUL_SUBST])(BinaryOperator *bo);
SubstitutionPass(bool flag) {
this->flag = flag;
funcAdd[0] = &SubstitutionPass::addNeg;
funcAdd[1] = &SubstitutionPass::addDoubleNeg;
funcAdd[2] = &SubstitutionPass::addRand;
funcAdd[3] = &SubstitutionPass::addRand2;
funcAdd[4] = &SubstitutionPass::addSubstitution;
funcAdd[5] = &SubstitutionPass::addSubstitution2;
funcAdd[6] = &SubstitutionPass::addSubstitution3;
}
}
void SubstitutionPass::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
if (bo->getOpcode() == Instruction::Add) {
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
bo->replaceAllUsesWith(op);
}
}
void SubstitutionPass::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
if (bo->getOpcode() == Instruction::Add) {
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
bo->replaceAllUsesWith(op);
}
}
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int sum;
sum = a + b;
printf("结果是: %d + %d = %d\n", a, b, sum);
return 0;
}
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int sum;
sum = a + b;
printf("结果是: %d + %d = %d\n", a, b, sum);
return 0;
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%sum = alloca i32, align 4
store i32 0, ptr %retval, align 4
store i32 1, ptr %a, align 4
store i32 1, ptr %b, align 4
%0 = load i32, ptr %a, align 4
%1 = load i32, ptr %b, align 4
%add = add nsw i32 %0, %1
store i32 %add, ptr %sum, align 4
%2 = load i32, ptr %sum, align 4
%3 = load i32, ptr %b, align 4
%4 = load i32, ptr %a, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BJ@JAMMOFDE@?g?$LL?$JD?f?$JO?$JM?f?$JI?$KP?3?5?$CFd?5?$CL?5?$CFd?5?$DN?5?$CFd?6?$AA@", i32 noundef %4, i32 noundef %3, i32 noundef %2)
ret i32 0
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%sum = alloca i32, align 4
store i32 0, ptr %retval, align 4
store i32 1, ptr %a, align 4
store i32 1, ptr %b, align 4
%0 = load i32, ptr %a, align 4
%1 = load i32, ptr %b, align 4
%add = add nsw i32 %0, %1
store i32 %add, ptr %sum, align 4
%2 = load i32, ptr %sum, align 4
%3 = load i32, ptr %b, align 4
%4 = load i32, ptr %a, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BJ@JAMMOFDE@?g?$LL?$JD?f?$JO?$JM?f?$JI?$KP?3?5?$CFd?5?$CL?5?$CFd?5?$DN?5?$CFd?6?$AA@", i32 noundef %4, i32 noundef %3, i32 noundef %2)
ret i32 0
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%sum = alloca i32, align 4
store i32 0, ptr %retval, align 4
store i32 1, ptr %a, align 4
store i32 1, ptr %b, align 4
%0 = load i32, ptr %a, align 4
%1 = load i32, ptr %b, align 4
%2 = add i32 %0, 730782619
%3 = add i32 %2, %1
%4 = sub i32 %3, 730782619
%add = add nsw i32 %0, %1
store i32 %4, ptr %sum, align 4
%5 = load i32, ptr %sum, align 4
%6 = load i32, ptr %b, align 4
%7 = load i32, ptr %a, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BJ@JAMMOFDE@?g?$LL?$JD?f?$JO?$JM?f?$JI?$KP?3?5?$CFd?5?$CL?5?$CFd?5?$DN?5?$CFd?6?$AA@", i32 noundef %7, i32 noundef %6, i32 noundef %5)
ret i32 0
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
%sum = alloca i32, align 4
store i32 0, ptr %retval, align 4
store i32 1, ptr %a, align 4
store i32 1, ptr %b, align 4
%0 = load i32, ptr %a, align 4
%1 = load i32, ptr %b, align 4
%2 = add i32 %0, 730782619
%3 = add i32 %2, %1
%4 = sub i32 %3, 730782619
%add = add nsw i32 %0, %1
store i32 %4, ptr %sum, align 4
%5 = load i32, ptr %sum, align 4
%6 = load i32, ptr %b, align 4
%7 = load i32, ptr %a, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BJ@JAMMOFDE@?g?$LL?$JD?f?$JO?$JM?f?$JI?$KP?3?5?$CFd?5?$CL?5?$CFd?5?$DN?5?$CFd?6?$AA@", i32 noundef %7, i32 noundef %6, i32 noundef %5)
ret i32 0
}
%2 = add i32 %0, 730782619
%3 = add i32 %2, %1
%4 = sub i32 %3, 730782619
%2 = add i32 %0, 730782619
%3 = add i32 %2, %1
%4 = sub i32 %3, 730782619
PreservedAnalyses SplitBasicBlockPass::run(Function& F, FunctionAnalysisManager& AM) {
Function *tmp = &F;
if (toObfuscate(flag, tmp, "split")){
errs() << "run split on function "<<F.getName() <<"\n";
split(tmp);
++Split;
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
PreservedAnalyses SplitBasicBlockPass::run(Function& F, FunctionAnalysisManager& AM) {
Function *tmp = &F;
if (toObfuscate(flag, tmp, "split")){
errs() << "run split on function "<<F.getName() <<"\n";
split(tmp);
++Split;
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
void SplitBasicBlockPass::split(Function *f){
std::vector<BasicBlock *> origBB;
for (Function::iterator I = f->begin(), IE = f->end(); I != IE; ++I){
origBB.push_back(&*I);
}
for (std::vector<BasicBlock *>::iterator I = origBB.begin(), IE = origBB.end();I != IE; ++I){
BasicBlock *curr = *I;
int splitN = SplitNum;
if (curr->size() < 2 || containsPHI(curr)){
continue;
}
if ((size_t)splitN >= curr->size()){
splitN = curr->size() - 1;
}
std::vector<int> test;
for (unsigned i = 1; i < curr->size(); ++i){
test.push_back(i);
}
if (test.size() != 1){
shuffle(test);
std::sort(test.begin(), test.begin() + splitN);
}
BasicBlock::iterator it = curr->begin();
BasicBlock *toSplit = curr;
int last = 0;
for (int i = 0; i < splitN; ++i){
if (toSplit->size() < 2){
continue;
}
for (int j = 0; j < test[i] - last; ++j){
++it;
}
last = test[i];
toSplit = toSplit->splitBasicBlock(it, toSplit->getName() + ".split");
}
++Split;
}
}
void SplitBasicBlockPass::split(Function *f){
std::vector<BasicBlock *> origBB;
for (Function::iterator I = f->begin(), IE = f->end(); I != IE; ++I){
origBB.push_back(&*I);
}
for (std::vector<BasicBlock *>::iterator I = origBB.begin(), IE = origBB.end();I != IE; ++I){
BasicBlock *curr = *I;
int splitN = SplitNum;
if (curr->size() < 2 || containsPHI(curr)){
continue;
}
if ((size_t)splitN >= curr->size()){
splitN = curr->size() - 1;
}
std::vector<int> test;
for (unsigned i = 1; i < curr->size(); ++i){
test.push_back(i);
}
if (test.size() != 1){
shuffle(test);
std::sort(test.begin(), test.begin() + splitN);
}
BasicBlock::iterator it = curr->begin();
BasicBlock *toSplit = curr;
int last = 0;
for (int i = 0; i < splitN; ++i){
if (toSplit->size() < 2){
continue;
}
for (int j = 0; j < test[i] - last; ++j){
++it;
}
last = test[i];
toSplit = toSplit->splitBasicBlock(it, toSplit->getName() + ".split");
}
++Split;
}
}
void SplitBasicBlockPass::shuffle(std::vector<int> &vec){
int n = vec.size();
for (int i = n - 1; i > 0; --i){
std::swap(vec[i], vec[cryptoutils->get_uint32_t() % (i + 1)]);
}
}
void SplitBasicBlockPass::shuffle(std::vector<int> &vec){
int n = vec.size();
for (int i = n - 1; i > 0; --i){
std::swap(vec[i], vec[cryptoutils->get_uint32_t() % (i + 1)]);
}
}
BasicBlock *BasicBlock::splitBasicBlock(iterator I, const Twine &BBName,
bool Before) {
if (Before)
return splitBasicBlockBefore(I, BBName);
assert(getTerminator() && "Can't use splitBasicBlock on degenerate BB!");
assert(I != InstList.end() &&
"Trying to get me to create degenerate basic block!");
BasicBlock *New = BasicBlock::Create(getContext(), BBName, getParent(),
this->getNextNode());
DebugLoc Loc = I->getStableDebugLoc();
New->splice(New->end(), this, I, end());
BranchInst *BI = BranchInst::Create(New, this);
BI->setDebugLoc(Loc);
New->replaceSuccessorsPhiUsesWith(this, New);
return New;
}
BasicBlock *BasicBlock::splitBasicBlock(iterator I, const Twine &BBName,
bool Before) {
if (Before)
return splitBasicBlockBefore(I, BBName);
assert(getTerminator() && "Can't use splitBasicBlock on degenerate BB!");
assert(I != InstList.end() &&
"Trying to get me to create degenerate basic block!");
BasicBlock *New = BasicBlock::Create(getContext(), BBName, getParent(),
this->getNextNode());
DebugLoc Loc = I->getStableDebugLoc();
New->splice(New->end(), this, I, end());
BranchInst *BI = BranchInst::Create(New, this);
BI->setDebugLoc(Loc);
New->replaceSuccessorsPhiUsesWith(this, New);
return New;
}
bool SplitBasicBlockPass::containsPHI(BasicBlock *BB){
for (Instruction &I : *BB){
if (isa<PHINode>(&I)){
return true;
}
}
return false;
}
bool SplitBasicBlockPass::containsPHI(BasicBlock *BB){
for (Instruction &I : *BB){
if (isa<PHINode>(&I)){
return true;
}
}
return false;
}
a = 1;
if (v < 10)
a = 2;
b = a;
a = 1;
if (v < 10)
a = 2;
b = a;
a1 = 1;
if (v < 10)
a2 = 2;
b = PHI(a1, a2);
a1 = 1;
if (v < 10)
a2 = 2;
b = PHI(a1, a2);
void BasicBlock::replaceSuccessorsPhiUsesWith(BasicBlock *Old,
BasicBlock *New) {
Instruction *TI = getTerminator();
if (!TI)
return;
for (BasicBlock *Succ : successors(TI))
Succ->replacePhiUsesWith(Old, New);
}
void BasicBlock::replaceSuccessorsPhiUsesWith(BasicBlock *Old,
BasicBlock *New) {
Instruction *TI = getTerminator();
if (!TI)
return;
for (BasicBlock *Succ : successors(TI))
Succ->replacePhiUsesWith(Old, New);
}
void BasicBlock::replacePhiUsesWith(BasicBlock *Old, BasicBlock *New) {
for (Instruction &I : *this) {
PHINode *PN = dyn_cast<PHINode>(&I);
if (!PN)
break;
PN->replaceIncomingBlockWith(Old, New);
}
}
void BasicBlock::replacePhiUsesWith(BasicBlock *Old, BasicBlock *New) {
for (Instruction &I : *this) {
PHINode *PN = dyn_cast<PHINode>(&I);
if (!PN)
break;
PN->replaceIncomingBlockWith(Old, New);
}
}
void replaceIncomingBlockWith(const BasicBlock *Old, BasicBlock *New) {
assert(New && Old && "PHI node got a null basic block!");
for (unsigned Op = 0, NumOps = getNumOperands(); Op != NumOps; ++Op)
if (getIncomingBlock(Op) == Old)
setIncomingBlock(Op, New);
}
void setIncomingBlock(unsigned i, BasicBlock *BB) {
const_cast<block_iterator>(block_begin())[i] = BB;
}
void replaceIncomingBlockWith(const BasicBlock *Old, BasicBlock *New) {
assert(New && Old && "PHI node got a null basic block!");
for (unsigned Op = 0, NumOps = getNumOperands(); Op != NumOps; ++Op)
if (getIncomingBlock(Op) == Old)
setIncomingBlock(Op, New);
}
void setIncomingBlock(unsigned i, BasicBlock *BB) {
const_cast<block_iterator>(block_begin())[i] = BB;
}
#include<stdio.h>
int main(){
printf("Hello, Split Basic Block!\n");
return 0;
}
#include<stdio.h>
int main(){
printf("Hello, Split Basic Block!\n");
return 0;
}
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
store i32 0, ptr %retval, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BL@MDKBAEJA@Hello?0?5Split?5Basic?5Block?$CB?6?$AA@")
ret i32 0
}
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
store i32 0, ptr %retval, align 4
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BL@MDKBAEJA@Hello?0?5Split?5Basic?5Block?$CB?6?$AA@")
ret i32 0
}
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
br label %entry.split
entry.split: ; preds = %entry
store i32 0, ptr %retval, align 4
br label %entry.split.split
entry.split.split: ; preds = %entry.split
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BL@MDKBAEJA@Hello?0?5Split?5Basic?5Block?$CB?6?$AA@")
br label %entry.split.split.split
entry.split.split.split: ; preds = %entry.split.split
ret i32 0
}
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main()
entry:
%retval = alloca i32, align 4
br label %entry.split
entry.split: ; preds = %entry
store i32 0, ptr %retval, align 4
br label %entry.split.split
entry.split.split: ; preds = %entry.split
%call = call i32 (ptr, ...) @printf(ptr noundef @"??_C@_0BL@MDKBAEJA@Hello?0?5Split?5Basic?5Block?$CB?6?$AA@")
br label %entry.split.split.split
entry.split.split.split: ; preds = %entry.split.split
ret i32 0
}
bool Flattening::flatten(Function *f) {
vector<BasicBlock *> origBB;
BasicBlock *loopEntry;
BasicBlock *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar;
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
#if LLVM_VERSION_MAJOR * 10 + LLVM_VERSION_MINOR >= 90
FunctionPass *lower = createLegacyLowerSwitchPass();
#else
FunctionPass *lower = createLowerSwitchPass();
#endif
lower->runOnFunction(*f);
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
if (isa<InvokeInst>(tmp->getTerminator())) {
return false;
}
}
if (origBB.size() <= 1) {
return false;
}
LLVMContext &Ctx = f->getContext();
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(f);
}
Value *MySecret = SecretInfo ? SecretInfo->SecretLI : ConstantInt::get(Type::getInt32Ty(Ctx), 0);
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
if (isa<BranchInst>(insert->getTerminator()) && insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
insert->getTerminator()->eraseFromParent();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(load, swDefault, 0, loopEntry);
for (BasicBlock *bb : origBB) {
bb->moveBefore(loopEnd);
ConstantInt *numCase = ConstantInt::get(switchI->getCondition()->getType(), llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key));
switchI->addCase(numCase, bb);
}
fixStack(f);
lower->runOnFunction(*f);
delete lower;
return true;
}
bool Flattening::flatten(Function *f) {
vector<BasicBlock *> origBB;
BasicBlock *loopEntry;
BasicBlock *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar;
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
#if LLVM_VERSION_MAJOR * 10 + LLVM_VERSION_MINOR >= 90
FunctionPass *lower = createLegacyLowerSwitchPass();
#else
FunctionPass *lower = createLowerSwitchPass();
#endif
lower->runOnFunction(*f);
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
if (isa<InvokeInst>(tmp->getTerminator())) {
return false;
}
}
if (origBB.size() <= 1) {
return false;
}
LLVMContext &Ctx = f->getContext();
const IPObfuscationContext::IPOInfo *SecretInfo = nullptr;
if (IPO) {
SecretInfo = IPO->getIPOInfo(f);
}
Value *MySecret = SecretInfo ? SecretInfo->SecretLI : ConstantInt::get(Type::getInt32Ty(Ctx), 0);
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
if (isa<BranchInst>(insert->getTerminator()) && insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
insert->getTerminator()->eraseFromParent();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(load, swDefault, 0, loopEntry);
for (BasicBlock *bb : origBB) {
bb->moveBefore(loopEnd);
ConstantInt *numCase = ConstantInt::get(switchI->getCondition()->getType(), llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key));
switchI->addCase(numCase, bb);
}
fixStack(f);
lower->runOnFunction(*f);
delete lower;
return true;
}
PreservedAnalyses FlatteningPass::run(Function& F, FunctionAnalysisManager& AM) {
Function *tmp = &F;
if (toObfuscate(flag, tmp, "fla")) {
INIT_CONTEXT(F);
if (flatten(tmp)) {
++Flattened;
}
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
PreservedAnalyses FlatteningPass::run(Function& F, FunctionAnalysisManager& AM) {
Function *tmp = &F;
if (toObfuscate(flag, tmp, "fla")) {
INIT_CONTEXT(F);
if (flatten(tmp)) {
++Flattened;
}
return PreservedAnalyses::none();
}
return PreservedAnalyses::all();
}
bool FlatteningPass::flatten(Function *f) {
SmallVector<BasicBlock *, 8> origBB;
BasicBlock *loopEntry, *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar, *switchVarAddr;
const DataLayout &DL = f->getParent()->getDataLayout();
std::unordered_map<uint32_t, uint32_t> scrambling_key;
PassBuilder PB;
FunctionAnalysisManager FAM;
FunctionPassManager FPM;
PB.registerFunctionAnalyses(FAM);
FPM.addPass(LowerSwitchPass());
FPM.run(*f, FAM);
for (BasicBlock &BB : *f) {
if (BB.isEHPad() || BB.isLandingPad()) {
errs() << f->getName()
<< " Contains Exception Handing Instructions and is unsupported "
"for flattening in the open-source version of Hikari.\n";
return false;
}
if (!isa<BranchInst>(BB.getTerminator()) &&
!isa<ReturnInst>(BB.getTerminator()))
return false;
origBB.emplace_back(&BB);
}
if (origBB.size() <= 1)
return false;
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
BranchInst *br = nullptr;
if (isa<BranchInst>(insert->getTerminator()))
br = cast<BranchInst>(insert->getTerminator());
if ((br && br->isConditional()) ||
insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
Instruction *oldTerm = insert->getTerminator();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()),
DL.getAllocaAddrSpace(), "switchVar", oldTerm);
switchVarAddr =
new AllocaInst(Type::getInt32Ty(f->getContext())->getPointerTo(),
DL.getAllocaAddrSpace(), "", oldTerm);
oldTerm->eraseFromParent();
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()),
cryptoutils->scramble32(0, scrambling_key)),
switchVar, insert);
new StoreInst(switchVar, switchVarAddr, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar->getAllocatedType(), switchVar, "switchVar",
loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault =
BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);
switchI->setCondition(load);
f->begin()->getTerminator()->eraseFromParent();
BranchInst::Create(loopEntry, &*f->begin());
for (BasicBlock *i : origBB) {
ConstantInt *numCase = nullptr;
i->moveBefore(loopEnd);
numCase = cast<ConstantInt>(ConstantInt::get(
switchI->getCondition()->getType(),
cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)));
switchI->addCase(numCase, i);
}
for (BasicBlock *i : origBB) {
ConstantInt *numCase = nullptr;
if (i->getTerminator()->getNumSuccessors() == 1) {
BasicBlock *succ = i->getTerminator()->getSuccessor(0);
i->getTerminator()->eraseFromParent();
numCase = switchI->findCaseDest(succ);
if (!numCase) {
numCase = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
cryptoutils->scramble32(switchI->getNumCases() - 1,
scrambling_key)));
}
new StoreInst(
numCase,
new LoadInst(switchVarAddr->getAllocatedType(), switchVarAddr, "", i),
i);
BranchInst::Create(loopEnd, i);
continue;
}
if (i->getTerminator()->getNumSuccessors() == 2) {
ConstantInt *numCaseTrue =
switchI->findCaseDest(i->getTerminator()->getSuccessor(0));
ConstantInt *numCaseFalse =
switchI->findCaseDest(i->getTerminator()->getSuccessor(1));
if (!numCaseTrue) {
numCaseTrue = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
cryptoutils->scramble32(switchI->getNumCases() - 1,
scrambling_key)));
}
if (!numCaseFalse) {
numCaseFalse = cast<ConstantInt>(
ConstantInt::get(switchI->getCondition()->getType(),
cryptoutils->scramble32(switchI->getNumCases() - 1,
scrambling_key)));
}
BranchInst *br = cast<BranchInst>(i->getTerminator());
SelectInst *sel =
SelectInst::Create(br->getCondition(), numCaseTrue, numCaseFalse, "",
i->getTerminator());
i->getTerminator()->eraseFromParent();
new StoreInst(
sel,
new LoadInst(switchVarAddr->getAllocatedType(), switchVarAddr, "", i),
i);
BranchInst::Create(loopEnd, i);
continue;
}
}
errs() << "Fixing Stack\n";
fixStack(*f);
errs() << "Fixed Stack\n";
return true;
}
bool FlatteningPass::flatten(Function *f) {
SmallVector<BasicBlock *, 8> origBB;
BasicBlock *loopEntry, *loopEnd;
LoadInst *load;
SwitchInst *switchI;
AllocaInst *switchVar, *switchVarAddr;
const DataLayout &DL = f->getParent()->getDataLayout();
std::unordered_map<uint32_t, uint32_t> scrambling_key;
PassBuilder PB;
FunctionAnalysisManager FAM;
FunctionPassManager FPM;
PB.registerFunctionAnalyses(FAM);
FPM.addPass(LowerSwitchPass());
FPM.run(*f, FAM);
for (BasicBlock &BB : *f) {
if (BB.isEHPad() || BB.isLandingPad()) {
errs() << f->getName()
<< " Contains Exception Handing Instructions and is unsupported "
"for flattening in the open-source version of Hikari.\n";
return false;
}
if (!isa<BranchInst>(BB.getTerminator()) &&
!isa<ReturnInst>(BB.getTerminator()))
return false;
origBB.emplace_back(&BB);
}
if (origBB.size() <= 1)
return false;
origBB.erase(origBB.begin());
Function::iterator tmp = f->begin();
BasicBlock *insert = &*tmp;
BranchInst *br = nullptr;
if (isa<BranchInst>(insert->getTerminator()))
br = cast<BranchInst>(insert->getTerminator());
if ((br && br->isConditional()) ||
insert->getTerminator()->getNumSuccessors() > 1) {
BasicBlock::iterator i = insert->end();
--i;
if (insert->size() > 1) {
--i;
}
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
Instruction *oldTerm = insert->getTerminator();
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()),
DL.getAllocaAddrSpace(), "switchVar", oldTerm);
switchVarAddr =
new AllocaInst(Type::getInt32Ty(f->getContext())->getPointerTo(),
DL.getAllocaAddrSpace(), "", oldTerm);
oldTerm->eraseFromParent();
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()),
cryptoutils->scramble32(0, scrambling_key)),
switchVar, insert);
new StoreInst(switchVar, switchVarAddr, insert);
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar->getAllocatedType(), switchVar, "switchVar",
loopEntry);
insert->moveBefore(loopEntry);
BranchInst::Create(loopEntry, insert);
BranchInst::Create(loopEntry, loopEnd);
BasicBlock *swDefault =
BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
BranchInst::Create(loopEnd, swDefault);
switchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);
switchI->setCondition(load);
f->begin()->getTerminator()->eraseFromParent();
BranchInst::Create(loopEntry, &*f->begin());
for (BasicBlock *i : origBB) {
ConstantInt *numCase = nullptr;
i->moveBefore(loopEnd);
numCase = cast<ConstantInt>(ConstantInt::get(
switchI->getCondition()->getType(),
cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)));
switchI->addCase(numCase, i);
}
for (BasicBlock *i : origBB) {
ConstantInt *numCase = nullptr;
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。