上一篇文章我给大家讲述了通用哈希算法和aes加密算法的识别方式,本篇文章着重讲述一下base64和rc4算法的识别。
在数据保护和数据转换算法中,rc4和base64是使用频率最高的算法;rc4用于数据加密,base64用于数据转换。
本篇文章介绍的识别算法和上一篇稍有不同,本篇讲述的算法识别方法我把它称之为“结构和特征识别”的识别方法;该方法适用于算法简单,算法结构逻辑清晰,并且算法中包含或者算法输出包含明显的特征,把这些明显的固定的特征抽取加以整理就构成了识别这些算法的关键。
介绍识别方法之前我们先看一下base64原理。
1. 每 3 个字节 → 转成 4 个字符
2. Base64 使用的 64 个字符是:
A–Z(26个) a–z(26个) 0–9(10个) + 和 /(2个)
所以一共有 64 个字符,叫做 “Base64”。
3.补位(padding)
如果不是刚好 3 个字节,比如你只给了 "Ma"(2 个字符 = 16 位)怎么办?
→ Base64 会补零到 24 位,然后结果里加一个 = 做标志。
规则:
其他略
1. 把三个字节变成四个字符(后面我们着重讲一下)
2. Base64依赖一个64个字符的表
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
3. 输出可能会出现“=”作为补位,如”Hello, world!”的base64为SGVsbG8sIHdvcmxkIQ==
举个例子(超简单)
假设我们要编码文本:
"Man"
它的 ASCII 是:
拼在一起:
01001101 01100001 01101110 → 共24位
把这 24 位切成 4 组,每组 6 位:
010011 010110 000101 101110
从上面base64原理举例中我们抽取核心特征是三个字节变成四个字符,一个字节8位,共24位,在把24位切成4组,每组6位;这不是妥妥的位运算嘛,位运算就涉及左右移位、或与操作。
由以上分析得,base64算法具备如下直观的特征:
1、 取三个字符组成24位二进制数,在此基础上进行移位或与操作后得到每组6位的二进制数共4组
2、 有一个固定的字符表是(参与算法索引字符):
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
3、 输出字符串中可能包含”=”
对特征1有很多种实现,我贴图出来参考一下;
实现一:

实现二:
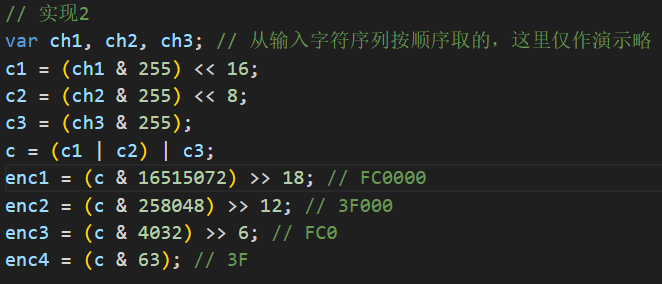
实现三(这种实现不多见, 它不把三个字节对应的二进制数组合成24位,而是独立看待每个字节的二进制数,组合拼接形成每组6位的4组二进制数):
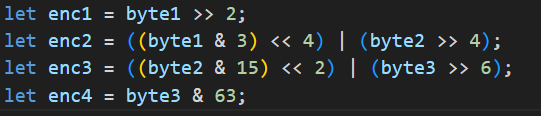
我们需要从前两种(第三种结合原理去分析)不同的实现中抽取相同的特征作为识别算法的特征,从输入字符(这里不是很准确,应该是任意二进制字节,有些二进制数不是可显示字符)序列连续取三个字节,左移8、16位或操作后形成一个24位的二进制数,先移位后与(右移6、12、18位,然后都与0x3f(十进制数63)); 先与后移位(分别与0xfc0(十进制数4032),0x3f00(十进制数258048), 0xfc000(十进制数16515072),在对应移位18、12、6。
最终我们得到快速定位base64算法的特征如下:
1、看输出结果是否包含”=”,算法中是否包含一个固定64个字符的表
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
2、由抽取实现方式简化得到;看左移8、16位,右移6、12、18位,&四个常数0xfc0、0x3f00、0xfc000、0x3f
我先以一段arm v7汇编举例,示例中通过base64固定的字符串替换表(64个)交叉引用找到了算法位置,然后通过base64原理看移位等推断它是base64算法。
定位字符串:


交叉引用:

定位函数:

伪代码(base64后两位可能涉及补码=的情况,这里忽略,不给出演示):

伪代码和我们上面介绍的实现三比较接近,我们来分析一下,v9是计数器从0开始,v4是输入的原始数据,(v4 + v9) >> 2等价于byte1 >> 2,整行是把计算的值直接作为base64表的索引查找出了替换的值即结果;v11是 (v4 + v9)即byte1, 16 * v11即v11(byte1) << 4 & 0x30 等价于(v11 & 3) << 4,作为第二个字符的高2位,v10是原始输入数据序列的下一个字节byte2,右移4位同刚刚计算得出的高2位与操作即第二个替换后的字符的索引即((byte1 << 4) & 0x30) | (byte2 >> 4),其他代码逻辑类似,这里就不在做分析了。
上面识别方法是通过特征base64固定的替换表,和简单的base64核心逻辑特征确定了上面算法是base64;基于算法的实现存在差异(逻辑相同),其他算法可能包含实现1和实现2的移位操作和特殊的常量数字(0x3f, 0x3f00,……),这些都是我们识别base64算法的核心;base64算法如此的简单以至于它太容易被识别,因此出现了vmp化的base64,被vmp化后我们无法直观识别,但当我们动态分析时,它的特征就会一一暴漏,这样我们就能快速识别它了,另外如果某个算法最终输出是一段长长的字符串且末尾中最多包含两个”=”,那我们首先假设它就是base64算法。
有了识别base64的基础识别rc4就更容易了,虽说这两个算法毫无关系,但因为rc4算法简单,因此结构和特征识别方式同样适用于rc4。同样我们看一下rc4的核心逻辑:
用密钥生成一个“伪随机序列”,然后和明文按位异或(XOR)得到密文。
你只要记住这句话,RC4的原理你已经掌握了一半。
RC4 工作流程分两步:
初始化 S 盒(S-box)
准备一个数组 S,包含从 0 到 255 的整数(共 256 个数):
S = [0, 1, 2, ..., 255]
再准备一个密钥数组 K,用密钥循环填充:
KSA(Key-Scheduling Algorithm)
我们开始打乱 S 数组:
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。






