用的 Ubuntu 编译的 Linux 版本, android 版本也编译了, 不过为了方便调试还是用的 Linux, 两者编译有些许不同, 原理和代码一样.
长文预警! 长文预警! 长文预警!
感觉前后文联系很强, 写的比较细, 几乎是每个地方都刨根问底, 如果跳着看, 注意回看前文, 有些前面写了, 我就没在后面重复.
建议一个屏幕打开源码, 一个屏幕读文章. 这样可以自己亲身体会一下.
作者也是小白, 难免疏忽, 如有错误还请您指出.
c69K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6c8b7V1c8u0i4K6u0r3f1f1u0p5d9b7`.`.
QBDI 实现了一个自己的 ir, 然后将要插桩的二进制指令与插桩代码统一翻译成自己的 ir, 然后借助 llvm 的组件转成对应架构二进制指令, 天才的构思. 接下来让我们一点点揭开它神秘的面纱.
跑一下 build/examples/ 中的可执行程序, 看看效果
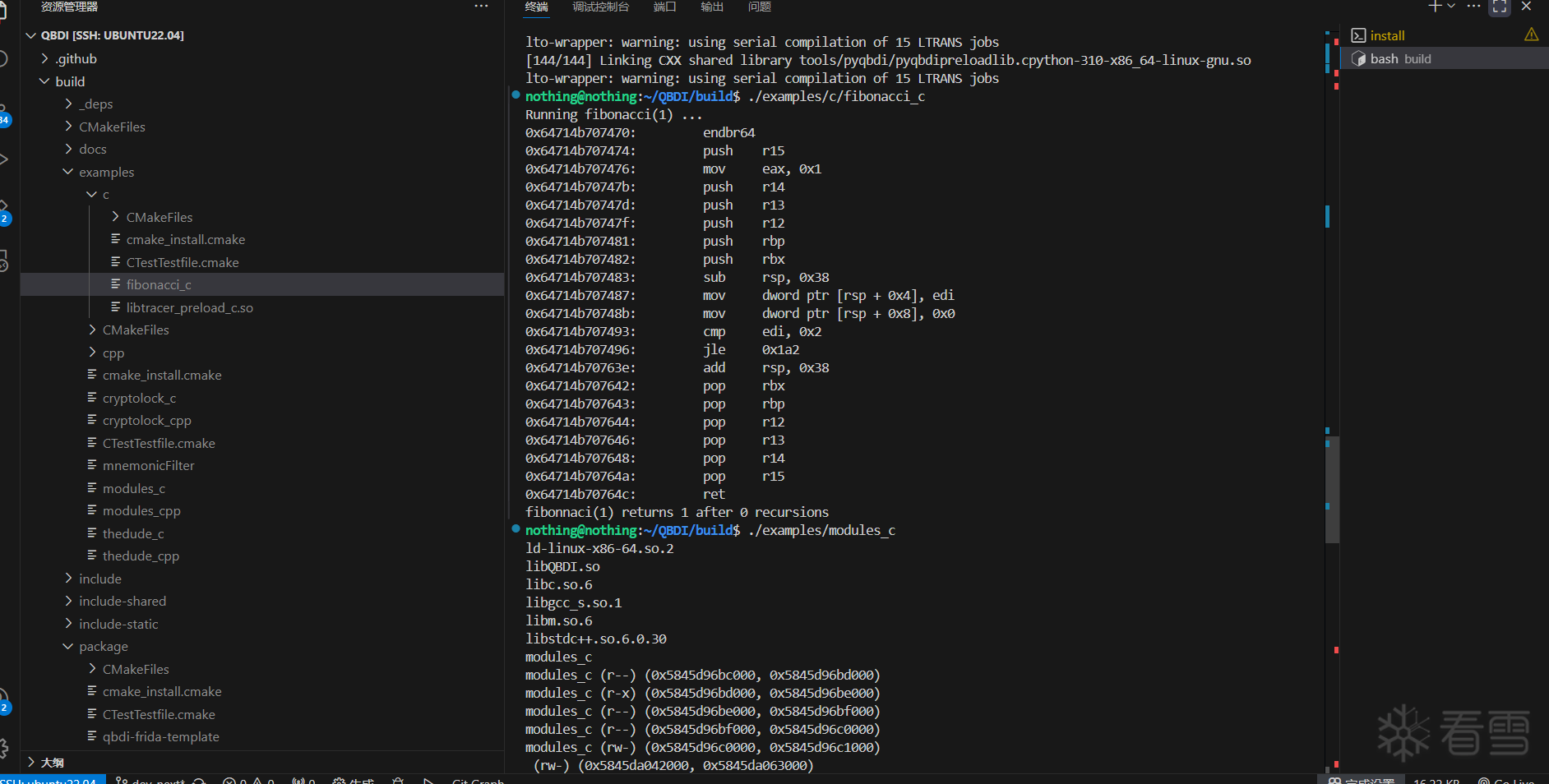
可以正常跑, 好了现在开始阅读 example 目录下的代码, 首先看下 CMakeLists.txt, examples/CMakeLists.txt:
添加了 mnemonicFilter modules_c modules_cpp thedude_c thedude_cpp cryptolock_cpp cryptolock_c 可执行文件, 然后再看 examples/c/CMakeLists.txt:
创建 fibonacci_c 可执行文件和 tracer_preload_c 共享库. 斐波那契数列真是老演员了, 我们从这里开始看起, 上边的 c 语言示例同样讲解的这个代码, 我觉得官方文档写的真好, 我无论怎么讲都显得冗余, 但为了完整性, 我还是简单概括下:
进入 src/Engine/VM_C.cpp 中查看代码:
可以看到代码很简单, 就是处理参数, 返回了一个 VM 类的实例, 跟进去 VM 类看一下, 来到了 include/QBDI/VM.h 下, 整个文件都是这个类的定义, 支持了很多的方法, 因为太长所以只截了几张图:
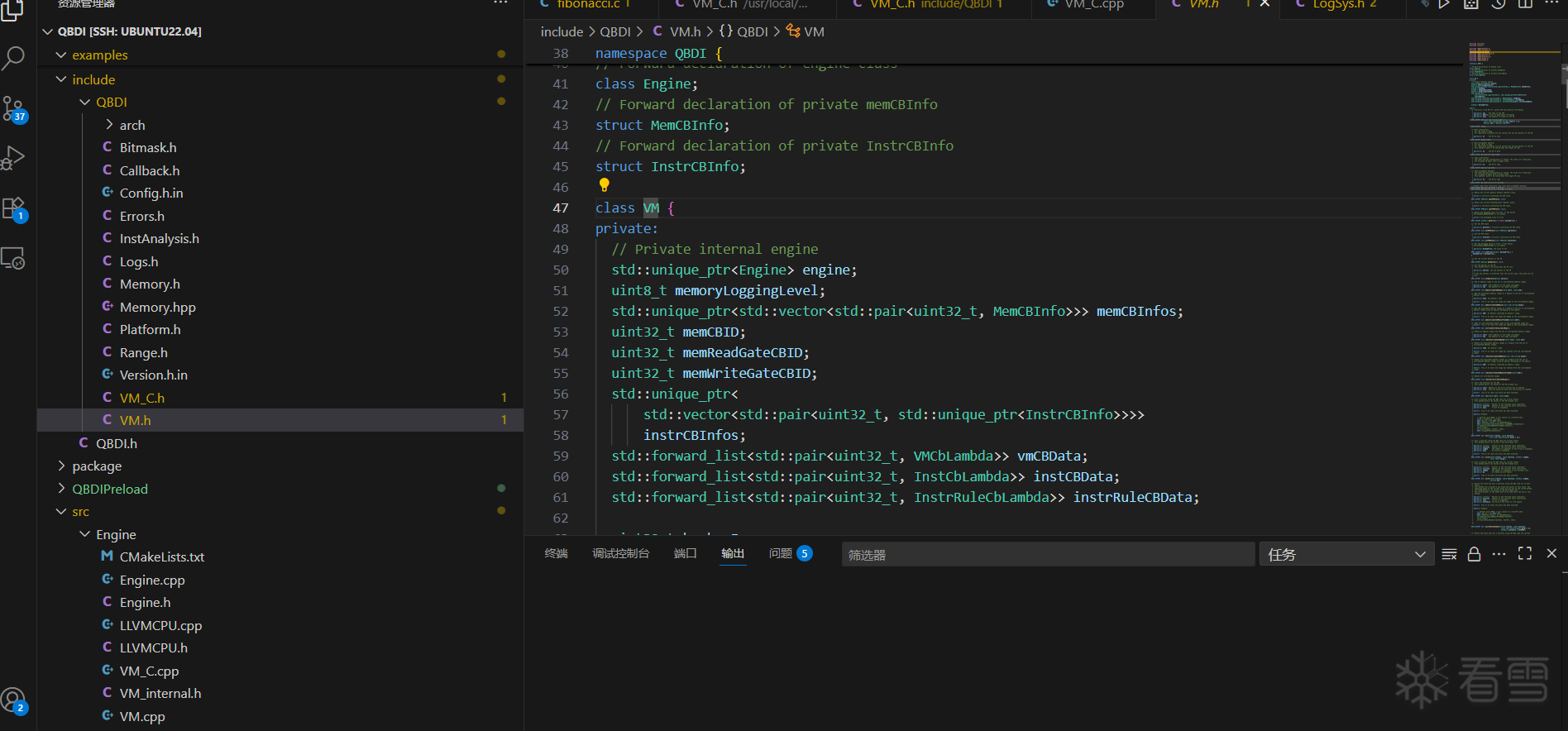
我们看一下它的构造函数:
将参数传入到了 Engine 类中, 我们同样找一下 Engine 类初始化函数:
可以看到, 很复杂, 初始化了很多类, 我们暂时不分析, 继续往下看.
可以看到是在调用 VM 类中的 getGPRState 方法, 再跟入 engine->getGPRState 来到 src/Engine/Engine.cpp 中:
返回了 Engine 类 中的 curGPRState 属性, 让我们跟踪一下 curGPRState:
在 include/QBDI/arch/X86_64/State.h 中找到了 GPRState 结构体的定义:
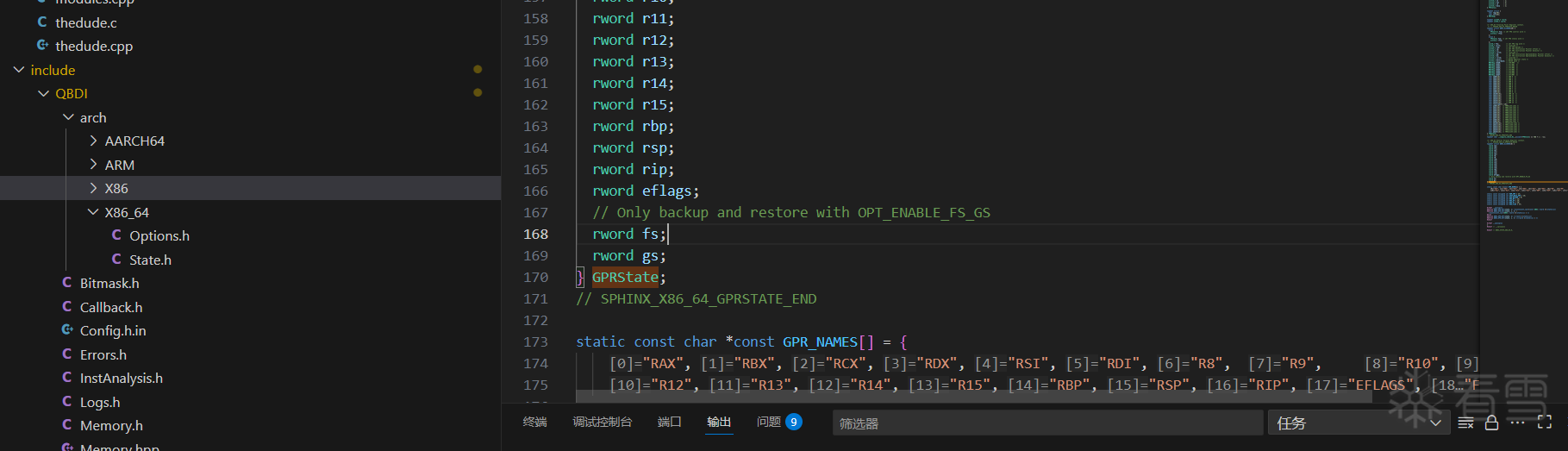
可以看到在 include/QBDI/arch/ 下同样有其他架构的一些支持, 根据我们编译时运行的脚本 GPRState 等有不同的实现.
在 src/Engine/Engine.cpp 与 src/Engine/Engine.h 中实现了 Engine 类, 而 VM 类中的 engine 属性就是 Engine 类的实例. 我们不着急分析这些类, 而是分析这个斐波那契示例实现的过程, 慢慢的就明白这些类扮演了什么样的角色.
我按执行顺序从上往下贴的, 可以看到这段是为虚拟栈分配了内存空间, 并且再内存大小上做了对齐处理, 然后将虚拟寄存器中的栈指针, 帧指针赋值. (虚拟栈存在堆上, 虚拟寄存器存在寄存器中)
然后来到 src/Engine/VM_C.cpp 文件来看实现:
与上边的 qbdi_getGPRState 类似, 还是调用 VM 类中的方法, 我们接着往下看, 跟入 addCodeCB 方法:
一点点看, 首先是 True::unique(), 跟进去:
发现就是一个模板工具类, 用来快速创建 unique_ptr 只能指针(这个指针的使用与 rust 中的所有权转移类似, 一个 std::unique_ptr 对象在任何时刻只能拥有一个指向动态分配对象的指针. 它不允许拷贝构造或赋值, 但可以通过 std::move 将所有权从一个 std::unique_ptr 转移到另一个), 现在我们疑惑的是 AutoUnique 这个模板类在 True::unique 调用时 typename T, typename U 是什么, 为此我们还要跟入 True 类一探究竟:
在跟入 AutoClone<PatchCondition, True>:
看到这, 我们可以知道 T 类型是 PatchCondition, U 类型是 True, 而 AutoClone AutoUnique 模板类相当于插入继承链, 本来是 True 类继承 PatchCondition 类变为了 True 继承 AutoClone 继承 AutoUnique 继承 PatchCondition. 而 True::unique(address) 创建的也就是一个类型为 True 的智能指针, 而翻回头来 InstrRuleBasicCBK::unique 也是类似的实现:
好了现在我们可以回过头来跟入 engine->addInstrRule 函数了:
把插桩规则的个数 instrRulesCounter 作为 id 返回, 并规定了最大个数 id < EVENTID_VM_MASK, 再看 this->clearCache(rule->affectedRange()), 先跟入 rule->affectedRange(如果跳转错误, 也可以搜索 InstrRuleBasicCBK::affectedRange):
InstrRuleBasicCBK 的 condition 属性就是 True::unique(), 而 True 类继承自 PatchCondition, 在跟入 condition->affectedRange, 就到了 PatchCondition 类中:
Range 与 RangeSet 太长了, 说下作用, 不在贴出代码, 感兴趣可以到 include/QBDI/Range.h 中自行查看:
回到 Engine::addInstrRule 函数中来看剩余这部分:
std::make_pair 创建了一个 std::pair 对象, 将 id 和 rule 组合在一起. std::upper_bound 是一个标准库函数, 用于在有序范围内找到第一个不满足给定条件的元素. 而 instrRules 是std::vector<std::pair<uint32_t, std::unique_ptr<InstrRule>>> 类型, 所以这段代码就是将 rule 插入到 instrRules 中第一个优先级小于或等于 rule 的优先级的位置. 使得 instrRules 中的规则始终按照优先级从高到低.
总结一下 qbdi_addCodeCB 函数就是创建插桩规则然后按输入的优先级存起来. 其中插桩规则保存了回调函数, 插桩位置, 用户参数...具体可以看 InstrRuleBasicCBK 类的构造函数.
二话不说跟进 addMnemonicCB:
可以看到和 qbdi_addCodeCB 函数实现唯一的差别就是 True::unique() 变为了 MnemonicIs::unique(mnemonic). mnemonic 就是咱们传进来的出发回调的特定指令, 在斐波那契这个示例中就是 "CALL*". 而 MnemonicIs 类与 True 类似:
看到这结合上面不难猜测 True 和 MnemonicIs 类都是用来判断回调条件的, 而这个 test 虚函数就是判断的统一调用. 所以我们在来看看 MnemonicIs::test:
我们先来看看第一个参数的类型 Patch 类, 跟入来到了 src/Patch/Patch.h 中, 代码不长, 将头文件注释:
在跟进 llvmcpu.getInstOpcodeName 看一眼:
看样子是在返回反汇编指令, 行, 这里先打住, 乱猜也是浪费时间, 接下往下看.
从上到下一步步跟入, execBroker 是 Engine 类的一个属性 ExecBroker *execBroker, 也是 ExecBroker 类的实例, 我们继续跟入 execBroker->addInstrumentedModuleFromAddr 函数:
看函数的名字就很容易知道在做什么, 写出注释. 首先先看看 getCurrentProcessMaps 函数, 来到了 src/Utility/Memory_linux.cpp 中, 还是会根据你编译的架构确定函数实现, 在同级目录下同样有其他架构的实现:
闲话少说来看看 getCurrentProcessMaps 函数的实现:
也就是通过 Linux 系统调用 getpid() 获取当前进程的 pid, 然后通过读取 /proc/[pid]/maps 文件获取内存映射, 然后将每条映射存进 std::vector<MemoryMap> maps 中.
在来看 addInstrumentedModule(回看一下上面的 ExecBroker::addInstrumentedModuleFromAddr 函数):
代码很简单就是将找到 name 对应的内存映射, 然后将映射的地址 保存到 ExecBroker 类的 instrumented 属性中. (我真要控制你了, 又调用 getCurrentProcessMaps() 遍历一遍)
好了, 现在再看这个函数感觉一切都明了了(再自己回顾一遍):
头文件的注释:
再来看具体实现:
用 va_start(ap, argNum) 处理可变参数, 参数存在 ap 中(随机提问, 在汇编层是如何实现可变参数的? 事实上只要知道可变参数的起始地址, 知道参数个数, 调用约定就可以顺藤摸瓜一点点找过去), 跟进 callV 函数:
将可变参数传入列表中在调用 callA, 继续跟入 callA:
首先检测栈指针, 然后调用 simulateCallA(看注释的意思是处理参数, QBDI_GPR_GET 在上边贴过源码, 忘记的话可以自己看一下), 跟进去:
根据目标架构的调用约定, 将参数加载到寄存器或栈中, 不同的架构有不同的处理方式, FRAME_LENGTH 决定了栈帧可以容纳的最大参数数量(一般来说, 在各个架构的调用约定中, 参数先通过寄存器传参, 然后再通过栈传参). 回过头再来看看 run:
首先看看设置的回调函数 stopCallback:
再跟入 addCodeAddrCB 中:
似曾相识的感觉有没有, 注册回调函数?!(忘记的朋友可以翻一翻上边). 有了上边的经验, 我们直接看 AddressIs:
如果我没记错的话 AddressIs::unique(address) 中的 address 应该是 42, 上边 #define FAKE_RET_ADDR 42 定义的. 带着疑问, 我们回到 VM::run, 跟入 bool ret = engine->run(start, stop)(等下, 我要再帮你回忆一下, start 是我们要插桩的函数的地址, stop 是注册回调返回的回调 id):
一个很长的函数, 让我们一点点看吧, 首先是 QBDI_REQUIRE_ABORT(not running, "Cannot run an already running Engine") 确保引擎当前没有在运行. 然后是 rword currentPC = start, 将 PC 指向了目标函数地址. 然后 curGPRState = gprState.get() 获取当前通用寄存器, curFPRState = fprState.get() 获取当前浮点寄存器, gprState 与 fprState 都是 Engine 类的属性:
GPRState 结构体的定义可以在前面找到, FPRState 与 GPRState 类似, 同样在 include/QBDI/arch/X86_64/State.h 中, 每个架构有不同的实现:
接着往下看:
还记得 execBroker, Engine 中存的 ExecBroker 实例, 我们用这个 ExecBroker 类记录了插桩的作用范围, 这里就是在检查目标函数地址是否在指定范围中, 不在的话直接返回. 再接着:
将 running 属性设置 true, 表示正在运行, 然后进入一个 do-while 大循环, 直到当前 PC 指针 currentPC 为 传进来的回调函数 id stop. 好了, 是时候进入主逻辑, 也就是这个 do-while 大循环, 先是 VMAction action = CONTINUE, 哦, 状态机? 我们跟进这个枚举看一看:
接着往下看, 一个大的 if-else:
看注释很容易理解, if 中处理了 currentPC 不在插桩范围内的情况, else 是执行, 我们先看 else 掌握执行的主要逻辑, 再来看 if 中的逻辑. 首先是 VMEvent event = VMEvent::SEQUENCE_ENTRY, 还是跟入枚举对象:
再回过头来看这段:
在 ARM 架构时, 区分 ARM 模式(32 位指令集)和 Thumb 模式(16 位指令集). 在往下看:
检查是否有待处理的缓存刷新操作, 更新缓存的 gprState 与 fprState 为当前值. 首先明确 blockManager 属性是 std::unique_ptr<ExecBlockManager> 类型, 也就是 ExecBlockManager 类的智能指针. 再看一下 isFlushPending:
没什么好说的, 再看一下 flushCommit:
我们需要关注两个属性 regions 与 codeBlockMap, 首先是 std::vector<ExecRegion> regions, 看 ExecRegion 类(比较短就贴出了):
再来看 std::map<rword, ExecBlock *> codeBlockMap, 也就是 ExecBlock 类, 非常的长, 在 src/ExecBlock/ExecBlock.h 文件中, 可以自行查看完整的实现:
它通过两块连续内存(代码块 codeBlock + 数据块 dataBlock)存储和运行插桩后的基本块, 同时提供执行控制、内存管理、记录等功能.
我们同样再找一下 ExecBlockManager 类的构造:
有个印象就行, 直到大概初始化了什么.
在回过来往下看:
看注释像是在检查能不能用缓存, 我们第一次执行到这, 肯定没有, 不过我们还是分析一下, 首先让我们先看看参数 currentPC 现在的值是 strat 也就是目标函数的地址, 然后 curCPUMode 是 Engine 类的 CPUMode curCPUMode 属性, 让我们看一下 CPUMode 是什么:
还是在 include/QBDI/arch/X86_64/State.h 中的一个枚举, 代表了 cpu 状态
在看看 currentSequence 的类型 SeqLoc:
看样子是一个表示位置的结构体, 好了现在跟入 blockManager->getProgrammedExecBlock:
又是一个很长的函数, 先跟入 searchRegion:
一个二分查找, 找到 address 所在的块的下标返回(regions 类型上面有讲过, 可以回看), 这样的话 regions 这个 vector 中存储的块的执行地址就是按循序排列的.
再回到 getProgrammedExecBlock, 往下看, 如果找到了就进入 if 逻辑, 否则返回一个 nullptr, 我们看一下 if 逻辑:
根据注释, 我们大概知道它的逻辑, 但是为了弄清楚还是关注几个点. 首先跟入 getExecRegionKey:
将地址在 arm 结构时做特殊处理, 不再赘述. 再看一眼 region.sequenceCache 的类型: std::map<rword, SeqLoc> sequenceCache, 一个地址与 SeqLoc 结构体(前面贴出过代码)的映射.
往下看, 看到 region.blocks[seqLoc->second.blockIdx]->selectSeq(seqLoc->second.seqID) 我们就大概明白 SeqLoc 结构体了, 它记录了指令序列的起始 seqStart 与结束 seqEnd 的地址, 以及所在 blocks 的索引 blockIdx, 自身的 id seqID, 所在块结束的地址 bbEnd. (还是贴出来, 方便你看):
可以再看下 selectSeq 函数:
看一下 seqRegistry 的类型: std::vector<SeqInfo> seqRegistry, 也就是说 seqID 实际上是 seqRegistry 中的下标, 看一下 SeqInfo:
再看一下 instRegistry 的类型: std::vector<InstInfo>, 还是一个 vector, 看 InstInfo:
好了, 现在可以理一理了, SeqLoc 记录了指令序列的位置以及 seqID, 根据 seqID 可以作为 seqRegistry 的下标找到 SeqInfo, 姑且称之为序列详情(根据这句代码 currentInst = seqRegistry[currentSeq].startInstID), 而用 SeqInfo 中的 startInstID 与 endInstID, 可以作为 instRegistry 属性的下标找到 InstInfo, 姑且称之为指令详情(根据这句代码 static_cast<rword>(instRegistry[currentInst].offset). 每个结构体还额外记录了很多信息. 而 ExecBlock::selectSeq 函数就是将当前块(ExecBlock 的实例)的一些属性设置成 seqID 对应的, 包括 currentSeq 当前序列, currentInst 当前指令, context->hostState.selector 上下文中的选择子, context->hostState.executeFlags 上下文中的执行标志.
回到 if 逻辑, 继续看 const auto instLoc = region.instCache.find(target), 找到 instCache 属性的类型 std::map<rword, InstLoc>, 看 InstLoc:
简直就是 sequenceCache 的翻版, 不在多说, 来看 block->getSeqID 函数:
多少有点循环链表的意思了, block->getSeqStart 也是类似:
再看 block->getInstMetadata:
使用了 instMetadata 属性, 我们来看看它的类型 std::vector<InstMetadata> instMetadata, 跟入 InstMetadata 类:
InstMetadata 存储了指令的很多信息.
再来看看 block->splitSequence:
构造 SeqInfo 实例, 存入 seqRegistry 中. 到此我们弄清楚了 getProgrammedExecBlock 的全部流程, 在回看一遍, 自己理一理.
回到 Engine::run 接着往下看:
这里就是处理缓存中没有时的逻辑, 整体看一下, 从名字也大概知道, handleNewBasicBlock(currentPC) 是生成新块, event |= BASIC_BLOCK_NEW 记录事件, blockManager->getProgrammedExecBlock 是刚刚看过的读取当前块. 所以我们重点看 handleNewBasicBlock:
先进入 patch:
通读一遍后, 我们可能已经知道它在做什么了, 还是补充说明几个点. llvm 部分我们不在刨根问底, 因为这篇写的已经够多了, llvm 的源码阅读放在别的文章.
先从 execBroker->getInstrumentedRange().getElementRange(start) 开始, execBroker 是我们的老朋友了(在上面获取内存 map, 设置插桩范围时就是它), execBroker->getInstrumentedRange:
instrumented 这个属性就存储了插桩的范围, 不记得的回看一下之前的分析, 在看 getElementRange:
返回了当前的 Range 用于计算块大小等, 再来看 llvmcpu.getInstruction:
LLVMCPU 这个类对 QBDI 需要的 llvm 中的功能做了封装, 在 src/Engine/LLVMCPU.h 中:
disassembler 属性类型为 std::unique_ptr<llvm::MCDisassembler>, 让我介绍一下:
而 disassembler->getInstruction 是 llvm api, 我们简单看一下头文件的注释:
再来看看 showInst:
asmPrinter 属性的类型是 std::unique_ptr<llvm::MCInstPrinter>, 让我介绍一下:
MSTI 属性类型是 std::unique_ptr<llvm::MCSubtargetInfo>, 让我介绍一下:
看看 asmPrinter->printInst 的注释:
回到 Engine::patch 我们接着看, patchRuleAssembly 是 Engine 类的属性, 是 PatchRuleAssembly 类的实例, 在上面 Engine 类构造函数中有: patchRuleAssembly = std::make_unique<PatchRuleAssembly>(options), 再来看 patchRuleAssembly->generate:
还记得这个函数的参数是什么吗? inst 是 llvm::MCInst 的实例, 存储解析出的机械指令, address 是指令地址, instSize 指令大小, llvmcpu llvm 方法封装, patchList 储存返回的地址.
看上去逻辑很明了. 用传进来的参数构建 Patch 实例, 然后用已有的 patch 规则处理这个实例, 然后处理可以合并的 patch. 但是已有的补丁规则 patchRules 是哪来的, 顶着头顶上的问号, 我们找一找, patchRules 是 PatchRuleAssembly 的属性, 我们找到 PatchRuleAssembly 的构造函数:
跟入 getDefaultPatchRules, 一个巨无霸函数:
这个函数位于 src/Patch/X86_64/PatchRuleAssembly_X86_64.cpp 中, 对于不同的架构有不同的实现:
这个函数我们要仔细分析一下, 先来看 PatchRule 类, 在 src/Patch/PatchRule.h 中:
我们看看 canBeApplied 方法实现:
和前面对上了, 还记得前面的注册回调函数的 True 和 MnemonicIs 类吗, 由各种子类实现 test 虚函数, 然后由 canBeApplied 调用.
apply 有些复杂, 留在后再调用时在分析. 回到 getDefaultPatchRules, 再来看 conv_unique 方法:
模板处理可变参数, 这个应该很经典, 那么 conv_unique 函数就是将传入的未知格式参数压入 vector, 然后返回 vector(随机提问: 模板处理可变参数在汇编层的实现?)
再往下看, 我们看到了各种 GetPCOffset::unique SubstituteWithTemp::unique ModifyInstruction::unique SetOpcode::unique.......他们就是 QBDI 的 ir. 我们随便找一个规则解读一下:
这是对 JMP *[RIP + IMM] 的转换, 用 QBDI 的 ir 去实现. rules 是 std::vector<PatchRule> 类型, 也就是说 emplace_back 进去的会被用来构造 PatchRule, 还记 PatchRule 的构造吗:
第一个是判断知否执行的条件, 第二个是执行的 ir. 先看条件:
从名字上也很容易看出来: 指令是 llvm::X86::JMP64m 并且使用 PC 寄存器. 我们直接看 OpIs 类:
patch.metadata.inst.getOpcode() 是 llvm 的 api, 一看就懂, 不在赘述. OpIs 类就是用来判断汇编指令的, 也就是操作码. 再看 UseReg:
UseReg 类检查指令是否使用了指定的寄存器. 再看 And 类:
就是将传入的条件们包装起来, 然后在 test 实现中, 使用 std::all_of 要所有的条件都返回 true 才是 true,
条件实现都在 src/Patch/PatchCondition.h src/Patch/PatchCondition.cpp 中. 条件判断的类都继承了 PatchCondition 类, 包括上面回调函数的也是, PatchCondition 类在上面贴出了, 不在重复, 子类都要实现 test 这个核心的虚函数.
然后是生成 QBDI 的 ir, 围绕着这个注释讲:
首先是 Temp(0) := RIP + Constant(0) 对应 GetPCOffset::unique(Temp(0), Constant(0)), 先看看 Temp:
可以看到就是包装了一层, 像 Constant, Operand 等也是类似, 都是包装一层赋予一定含义, 我们不在意义查看, Reg 类略有不同, 贴出注释:
再跟进 GetPCOffset:
首先我们关注的是它的父类 PatchGenerator 类:
不出意外, 应该是每个 QBDI ir 生成类都是 PatchGenerator 的子类, 并且都位于 src/Patch/PatchGenerator.h src/Patch/PatchGenerator.cpp 中, generate 应该是生成 ir 的核心虚方法.
接下来看一下 GetPCOffset::generate 的实现:
根据是传入的是常量还是操作数, 由不一样的调用:
可以看到最终都是调用 LoadImm::unique, 我们先不着急跟进去, 先看看 patch.metadata.endAddress:
获取指令结束地址, patch.metadata.inst 是 llvm::MCInst 的实例, 还记得吗, 咱们之前调用 llvm api 解析出来的. op 是操作数索引, patch.metadata.inst.getOperand(op).getImm() 就是调用 llvm api 获取索引对应的 操作数.
现在跟进 LoadImm, 来到 src/Patch/RelocatableInst.h 中:
同样先看看父类 RelocatableInst:
看名字是用来构建重定位指令.
现在看看 LoadImm 的两个虚方法, 在 src/Patch/X86_64/RelocatableInst_X86_64.cpp 文件中, 同样是根据架构改变:
看到着我们大概就知道了, 这个就是用来赋值的, mov 指令, 也就是组成了 Temp(0) := RIP + Constant(0), 即如下伪代码:
我们跟入 mov64ri, mov64ri32, mov32ri:
可以看到是在构造对应的 llvm::MCInst 实例返回. 好了这里我们全部理清了.
接下来看看下一条的实现 JMP *[RIP + IMM] --> MOV Temp(1), [Temp(0) + IMM]:
首先是 ModifyInstruction:
来看看 generate 方法:
与 And 类似, 调用传入的 transforms 中每个实例的 transform 方法, 将当前汇编指令的信息传入.
然后看看传入的 transforms 从 SubstituteWithTemp开始, 在 src/Patch/InstTransform.h中:
它的父类 InstTransform:
与之前的类似. 让我们来看看 SubstituteWithTemp::transform
放到我们这个例子中, 也就是将 JMP *[RIP + IMM] 中的 RIP 换成 Temp(0) 成了 JMP *[Temp(0) + IMM].
也就是说为之前这个 Temp(0) 临时对象分配一个真实的寄存器, TempManager 类也就是用来管理临时寄存器的以及这种映射关系的, 篇幅原因, 我们不在细看, 并不复杂, 感兴趣的朋友可以自行查看.
再回头看:
跟入 SetOpcode 类:
这个简单粗暴, 直接将汇编指令种类替换, 即由 JMP *[Temp(0) + IMM] 变为 MOV *[Temp(0) + IMM].
再来看:
跟进 AddOperand:
猜也猜到它的作用了, 向指令中插入新的操作数, 来看 transform 的实现:
即将 MOV *[Temp(0) + IMM] 变为 MOV Temp(1), [Temp(0) + IMM].
最后是 DataBlock[Offset(RIP)] := Temp(1):
我们跟进 WriteTemp:
查看 generate 方法的实现:
生成可重定位指令, 将临时值写入指定位置, 因为我们是 OffsetType, 所以跟进 StoreDataBlock, 其他的感兴趣可以自行查看:
来看看 reloc 方法, 来到了 src/Patch/X86_64/RelocatableInst_X86_64.cpp 中, 不同的架构实现不同:
mov64mr 与 mov32mr 位于 src/Patch/X86_64/Layer2_X86_64.cpp, 同样因架构而异:
这个 StoreDataBlock 类的作用是: 生成将寄存器值存储到数据块的 llvm::MCInst 指令. 这里就是将 Temp(1) 寄存器的值覆盖原 PC 值.
ok, 回到 getDefaultPatchRules 函数, 其他的规则也是类似, 不在一一分析. 我们走了太远, 已经快要忘记来时的路, 现在让我们回到 Engine::patch 方法. 在它的 do-while 循环中, 不断调用 patchRuleAssembly->generate, 用的规则将汇编指令转成 QBDI 自己的 ir, 然后, QBDI 的 ir 再到 llvm::MCInst. 在根据是否改变 PC 分割出基本块, 如果改变了那就是一个基本块, 这样我们将结果存入 basicBlock 中返回, 反之继续. 回到了 Engine::handleNewBasicBlock 方法(再贴一遍):
然后进入 blockManager->preWriteBasicBlock:
就是在找一个大小合适缓冲区位置, 然后返回要存的 patch 数量. 进入 instrument 方法:
代码也很好懂, 就是从刚刚生成好的基本块中取出每个指令 patch, 然后调用我们设置的插桩规则 instrRules (在设置回调函数那里写入的, 可以搜索 InstrRuleBasicCBK::unique). 在我们这个例子中 rule 的类型为 InstrRuleBasicCBK, 取出每条插桩规则看看能不能插桩 rule->tryInstrument. 我们看一下 InstrRuleBasicCBK 类中的 tryInstrument 方法:
先调用 canBeApplied 判断是否可以插桩:
调用 condition->test. 上面已经讲过不在赘述. 然后看 instrument(patch, patchGen, breakToHost, position, priority, tag) 的参数, patch 是汇编指令对应的 ir, patchGen, breakToHost, position, priority, tag 都是 InstrRuleBasicCBK 类属性, InstrRuleBasicCBK 类在上面贴出来过, 不在重复, 让我们去看看 InstrRuleBasicCBK 的构造函数:
patchGen 看样子是将我们传入的回调函数和自定义参数的 patch, position 是插桩位置(指令前或者指令后), breakToHost 传入的固定值 true, priority 传入的优先级, tag 与 position 相关.
看看 getCallbackGenerator 方法的实现:
看一眼 GetConstant:
好吧, 这些代码应该比较熟悉了, 概括一下就是 MOV REG64 temp, IMM64 cst, 这个注释.
再看 GetInstId:
再来看看 InstId:
也就是将执行块的 id execBlock->getNextInstID() 当作立即数, 用 mov 放入 Temp(0) 寄存器中.
回来再来看 instrument 函数:
还是整体浏览一遍, 然后找不懂得点查看实现, 首先是 RelocatableInst::UniquePtrVec instru, 这个是最终插桩代码, 我们看看它的属性 using UniquePtrVec = std::vector<std::unique_ptr<RelocatableInst>> 可重定位的指令集合, 将 patchGen 中的先放进来:
看看 append 函数:
让我们理一理: generate 方法会对应一条或者多条指令, 以 RelocatableInst 数组的形式返回, RelocatableInst 类的 reloc 会返回 llvm::MCInst 实例.
然后看这里:
根据 position 处理插桩位置, 是在指令前还是指令后.
然后是这里:
GetConstant(Temp(0), Constant(address)).generate(patch, tempManager) 在前面讲过, mov Temp(0), address, 将插桩地址赋给 Temp(0) 寄存器, 再看后面这个 append: tempManager.getRegForTemp(0) 前面讲过, 为临时寄存器配分一个实际寄存器. 看看 SaveReg:
这个 StoreDataBlock 咱们再前面也讲过, 概括就是这个注释 MOV MEM64 DataBlock[offset], REG64 reg, 看完这段咱们应该懂了 SaveReg(tempManager.getRegForTemp(0), Offset(Reg(REG_PC))) 就是将 MOV MEM64 DataBlock[PC], Temp(0), 将寄存器 Temp(0) 中的值写入数据块偏移为 Reg(REG_PC) 的值. 也就是将寄存器 Temp(0) 中的值写入 PC.
再回到 InstrRule::instrument, 往下看 tempManager.generateSaveRestoreInstructions:
LoadReg 与 SaveReg 相反, 代码非常相似, 从数据块加载值到对应寄存器, 而这个函数是用来生成寄存器的保存和恢复的指令, 它根据指定的数量 unrestoredRegNum, 决定哪些寄存器需要保存但不需要恢复, 哪些寄存器需要保存和恢复. 生成的指令分别存储在 saveInst 和 restoreInst 列表中, 未恢复的寄存器存储在 unrestoredReg 列表中.
再看 prepend 函数:
没什么好说的, 最后看 patch.addInstsPatch 函数:
按优先级存入 instsPatchs 属性中. 好了 InstrRule::instrument 函数就是将我回调函数与自定义参数处理好, 记录到 patch 的属性中.
现在回到 Engine::instrument 函数(在贴一次):
看最后的 patch.finalizeInstsPatch:
看一下 RelocTag 类:
在看一下 TargetPrologue 类:
RelocTag 与 TargetPrologue 类不在多说.
Patch::finalizeInstsPatch 方法是将插桩代码的指令从 instsPatchs 属性中读取真的插入到 patch 中, patch 对应了一条汇编指令, 由多指令实现.
回到 Engine::handleNewBasicBlock(再贴一次):
看最后的 blockManager->writeBasicBlock(std::move(basicBlock), patchEnd) 将指令写入缓存(这里我们插入到指令是插到 patch, 而 blockManager->preWriteBasicBlock 预分配的空间是按 patch 个数, 所以预分配的空间不会因为插入插桩代码和不足):
浏览器一遍函数. 这里构建了指令序列 SeqLoc, 对应了一条 patch 中包含的一条或者多条指令的范围. 存入 sequenceCache instCache 缓存, 和前面串起来了. 我们也理一理, region 中包含很多 block, 然后 block 包含很多 seq, seq 中包含很多 inst.
然后看这里:
跟入 writeSequence:
代码也很读, 根据注释, 我们大体懂了做什么, 我们跟入 writePatch
先判断是否已经填满一个块, 然后调用 applyRelocatedInst:
读完后, 让我们关注 llvmcpu.writeInstruction(inst->reloc(this, llvmcpu), stream, getCurrentPC()), 这里调用了 reloc 返回 llvm::MCInst 实例, 跟入 writeInstruction:
这里调用了 llvm 的 api assembler->getEmitter().encodeInstruction 将 llvm::MCValue 转为机器码, 存入 CB. 回头看一下 writeCodeByte:
将机器码写如 codeBlock 中.
好了, 终于读完了 Engine::handleNewBasicBlock 方法, 我们回到 Engine::run 方法, 走了太远了, 我们再贴一下它的代码, 并且注释一下, 帮你恢复死去的记忆:
有没有感觉已经很明了了, 我们再看几个函数 signalEvent:
再来看 curExecBlock->execute 执行函数:
先看 run 函数中的 qbdi_runCodeBlock 如何执行的:
找到 src/ExecBlock/X86_64/linux_X86_64.s 中的 __qbdi_runCodeBlock, 还是不同架构实现不同:
这里调用汇编进入我们之前用 llvm 写的机器码.
还记得上边我们如何插入插桩指令的吗? 我们有三条步, 回调函数地址赋值给 hostState.callback, 将用户自定义参数赋值给 hostState.data, 将执行块 id 赋值给 hostState.origin. 然后执行完一段后, 会跳回来检查是不是填好了回调 hostState.callback, 如果有就执行:
好了, 差不多就写到这, 自己再回顾一遍 Engine::run 函数. 想一想都做了什么...
整体看下来, QBDI 的代码写的非常好, 规范, 工整, 像一个艺术品.
我们的 QBDI 之旅告一段落, 等等, 我们是不是还忘了什么: 收尾, 某个被跳过的 if...好吧, 已经写了足够多了, 大行不顾细谨, 不在纠结了.
mkdir build
cd build
../cmake/config/config-linux-X86_64.sh
sudo ninja install
mkdir build
cd build
../cmake/config/config-linux-X86_64.sh
sudo ninja install
cd build
cmake -DQBDI_EXAMPLES=ON -DCMAKE_BUILD_TYPE=Debug -DQBDI_LOG_DEBUG=ON ..
ninja
cd build
cmake -DQBDI_EXAMPLES=ON -DCMAKE_BUILD_TYPE=Debug -DQBDI_LOG_DEBUG=ON ..
ninja
mkdir QBDIPreload && cd QBDIPreload
cp /usr/local/share/qbdipreloadX86_64/qbdi_preload_template/* .
mkdir build && cd build
cmake ..
make
mkdir QBDIPreload && cd QBDIPreload
cp /usr/local/share/qbdipreloadX86_64/qbdi_preload_template/* .
mkdir build && cd build
cmake ..
make
int fibonacci(int n) {
if(n <= 2)
return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
int fibonacci(int n) {
if(n <= 2)
return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
#include "QBDI.h"
VMInstanceRef vm;
qbdi_initVM(&vm, NULL, NULL, 0);
GPRState *state;
state = qbdi_getGPRState(vm);
assert(state != NULL);
uint8_t *fakestack;
static const uint32_t STACK_SIZE = 0x100000;
bool res = qbdi_allocateVirtualStack(state, STACK_SIZE, &fakestack);
assert(res == true);
#include "QBDI.h"
VMInstanceRef vm;
qbdi_initVM(&vm, NULL, NULL, 0);
GPRState *state;
state = qbdi_getGPRState(vm);
assert(state != NULL);
uint8_t *fakestack;
static const uint32_t STACK_SIZE = 0x100000;
bool res = qbdi_allocateVirtualStack(state, STACK_SIZE, &fakestack);
assert(res == true);
VMAction showInstruction(VMInstanceRef vm, GPRState *gprState,
FPRState *fprState, void *data) {
const InstAnalysis *instAnalysis = qbdi_getInstAnalysis(
vm, QBDI_ANALYSIS_INSTRUCTION | QBDI_ANALYSIS_DISASSEMBLY);
printf("0x%" PRIRWORD ": %s\n", instAnalysis->address,
instAnalysis->disassembly);
return QBDI_CONTINUE;
}
uint32_t cid = qbdi_addCodeCB(vm, QBDI_PREINST, showInstruction, NULL, 0);
assert(cid != QBDI_INVALID_EVENTID);
VMAction countIteration(VMInstanceRef vm, GPRState *gprState,
FPRState *fprState, void *data) {
(*((int *)data))++;
return QBDI_CONTINUE;
}
int iterationCount = 0;
qbdi_addMnemonicCB(vm, "CALL*", QBDI_PREINST, countIteration, &iterationCount, 0);
VMAction showInstruction(VMInstanceRef vm, GPRState *gprState,
FPRState *fprState, void *data) {
const InstAnalysis *instAnalysis = qbdi_getInstAnalysis(
vm, QBDI_ANALYSIS_INSTRUCTION | QBDI_ANALYSIS_DISASSEMBLY);
printf("0x%" PRIRWORD ": %s\n", instAnalysis->address,
instAnalysis->disassembly);
return QBDI_CONTINUE;
}
uint32_t cid = qbdi_addCodeCB(vm, QBDI_PREINST, showInstruction, NULL, 0);
assert(cid != QBDI_INVALID_EVENTID);
VMAction countIteration(VMInstanceRef vm, GPRState *gprState,
FPRState *fprState, void *data) {
(*((int *)data))++;
return QBDI_CONTINUE;
}
int iterationCount = 0;
qbdi_addMnemonicCB(vm, "CALL*", QBDI_PREINST, countIteration, &iterationCount, 0);
bool res = qbdi_addInstrumentedModuleFromAddr(vm, (rword)&fibonacci);
assert(res == true);
rword retvalue;
res = qbdi_call(vm, &retvalue, (rword)fibonacci, 1, n);
assert(res == true);
bool res = qbdi_addInstrumentedModuleFromAddr(vm, (rword)&fibonacci);
assert(res == true);
rword retvalue;
res = qbdi_call(vm, &retvalue, (rword)fibonacci, 1, n);
assert(res == true);
QBDI_EXPORT void qbdi_initVM(VMInstanceRef *instance, const char *cpu,
const char **mattrs, Options opts);
QBDI_EXPORT void qbdi_initVM(VMInstanceRef *instance, const char *cpu,
const char **mattrs, Options opts);
#define QBDI_REQUIRE_ACTION(req, ac) \
if (!(req)) { \
QBDI_ERROR("Assertion Failed : {}", #req); \
ac; \
}
void qbdi_initVM(VMInstanceRef *instance, const char *cpu, const char **mattrs,
Options opts) {
QBDI_REQUIRE_ACTION(instance, return);
*instance = nullptr;
std::string cpuStr = "";
std::vector<std::string> mattrsStr;
if (cpu != nullptr) {
cpuStr += cpu;
}
if (mattrs != nullptr) {
for (unsigned i = 0; mattrs[i] != nullptr; i++) {
mattrsStr.emplace_back(mattrs[i]);
}
}
*instance = static_cast<VMInstanceRef>(new VM(cpuStr, mattrsStr, opts));
}
#define QBDI_REQUIRE_ACTION(req, ac) \
if (!(req)) { \
QBDI_ERROR("Assertion Failed : {}", #req); \
ac; \
}
void qbdi_initVM(VMInstanceRef *instance, const char *cpu, const char **mattrs,
Options opts) {
QBDI_REQUIRE_ACTION(instance, return);
*instance = nullptr;
std::string cpuStr = "";
std::vector<std::string> mattrsStr;
if (cpu != nullptr) {
cpuStr += cpu;
}
if (mattrs != nullptr) {
for (unsigned i = 0; mattrs[i] != nullptr; i++) {
mattrsStr.emplace_back(mattrs[i]);
}
}
*instance = static_cast<VMInstanceRef>(new VM(cpuStr, mattrsStr, opts));
}
VM::VM(const std::string &cpu, const std::vector<std::string> &mattrs,
Options opts)
: memoryLoggingLevel(0), memCBID(0),
memReadGateCBID(VMError::INVALID_EVENTID),
memWriteGateCBID(VMError::INVALID_EVENTID) {
#if defined(_QBDI_ASAN_ENABLED_)
opts |= Options::OPT_DISABLE_FPR;
#endif
engine = std::make_unique<Engine>(cpu, mattrs, opts, this);
memCBInfos = std::make_unique<std::vector<std::pair<uint32_t, MemCBInfo>>>();
instrCBInfos = std::make_unique<
std::vector<std::pair<uint32_t, std::unique_ptr<InstrCBInfo>>>>();
}
VM::VM(const std::string &cpu, const std::vector<std::string> &mattrs,
Options opts)
: memoryLoggingLevel(0), memCBID(0),
memReadGateCBID(VMError::INVALID_EVENTID),
memWriteGateCBID(VMError::INVALID_EVENTID) {
#if defined(_QBDI_ASAN_ENABLED_)
opts |= Options::OPT_DISABLE_FPR;
#endif
engine = std::make_unique<Engine>(cpu, mattrs, opts, this);
memCBInfos = std::make_unique<std::vector<std::pair<uint32_t, MemCBInfo>>>();
instrCBInfos = std::make_unique<
std::vector<std::pair<uint32_t, std::unique_ptr<InstrCBInfo>>>>();
}
Engine::Engine(const std::string &_cpu, const std::vector<std::string> &_mattrs,
Options opts, VMInstanceRef vminstance)
: vminstance(vminstance), instrRulesCounter(0), vmCallbacksCounter(0),
curCPUMode(CPUMode::DEFAULT), options(opts), eventMask(VMEvent::NO_EVENT),
running(false) {
llvmCPUs = std::make_unique<LLVMCPUs>(_cpu, _mattrs, opts);
blockManager = std::make_unique<ExecBlockManager>(*llvmCPUs, vminstance);
execBroker = blockManager->getExecBroker();
patchRuleAssembly = std::make_unique<PatchRuleAssembly>(options);
gprState = std::make_unique<GPRState>();
fprState = std::make_unique<FPRState>();
curGPRState = gprState.get();
curFPRState = fprState.get();
initGPRState();
initFPRState();
curExecBlock = nullptr;
}
Engine::Engine(const std::string &_cpu, const std::vector<std::string> &_mattrs,
Options opts, VMInstanceRef vminstance)
: vminstance(vminstance), instrRulesCounter(0), vmCallbacksCounter(0),
curCPUMode(CPUMode::DEFAULT), options(opts), eventMask(VMEvent::NO_EVENT),
running(false) {
llvmCPUs = std::make_unique<LLVMCPUs>(_cpu, _mattrs, opts);
blockManager = std::make_unique<ExecBlockManager>(*llvmCPUs, vminstance);
execBroker = blockManager->getExecBroker();
patchRuleAssembly = std::make_unique<PatchRuleAssembly>(options);
gprState = std::make_unique<GPRState>();
fprState = std::make_unique<FPRState>();
curGPRState = gprState.get();
curFPRState = fprState.get();
initGPRState();
initFPRState();
curExecBlock = nullptr;
}
GPRState *qbdi_getGPRState(VMInstanceRef instance) {
QBDI_REQUIRE_ACTION(instance, return nullptr);
return static_cast<VM *>(instance)->getGPRState();
}
GPRState *VM::getGPRState() const { return engine->getGPRState(); }
GPRState *qbdi_getGPRState(VMInstanceRef instance) {
QBDI_REQUIRE_ACTION(instance, return nullptr);
return static_cast<VM *>(instance)->getGPRState();
}
GPRState *VM::getGPRState() const { return engine->getGPRState(); }
GPRState *Engine::getGPRState() const { return curGPRState; }
GPRState *Engine::getGPRState() const { return curGPRState; }
GPRState *curGPRState;
typedef struct QBDI_ALIGNED(8) {
rword rax;
rword rbx;
rword rcx;
rword rdx;
rword rsi;
rword rdi;
rword r8;
rword r9;
rword r10;
rword r11;
rword r12;
rword r13;
rword r14;
rword r15;
rword rbp;
rword rsp;
rword rip;
rword eflags;
rword fs;
rword gs;
} GPRState;
GPRState *curGPRState;
typedef struct QBDI_ALIGNED(8) {
rword rax;
rword rbx;
rword rcx;
rword rdx;
rword rsi;
rword rdi;
rword r8;
rword r9;
rword r10;
rword r11;
rword r12;
rword r13;
rword r14;
rword r15;
rword rbp;
rword rsp;
rword rip;
rword eflags;
rword fs;
rword gs;
} GPRState;
bool qbdi_allocateVirtualStack(GPRState *ctx, uint32_t stackSize,
uint8_t **stack) {
return allocateVirtualStack(ctx, stackSize, stack);
}
bool allocateVirtualStack(GPRState *ctx, uint32_t stackSize, uint8_t **stack) {
(*stack) = static_cast<uint8_t *>(alignedAlloc(stackSize, 16));
if (*stack == nullptr) {
return false;
}
QBDI_GPR_SET(ctx, REG_SP, reinterpret_cast<QBDI::rword>(*stack) + stackSize);
QBDI_GPR_SET(ctx, REG_BP, QBDI_GPR_GET(ctx, REG_SP));
return true;
}
void *alignedAlloc(size_t size, size_t align) {
void *allocated = nullptr;
if ((align == 0) || ((align & (align - 1)) != 0)) {
return nullptr;
}
#if defined(QBDI_PLATFORM_LINUX) || defined(QBDI_PLATFORM_ANDROID) || \
defined(QBDI_PLATFORM_OSX)
int ret = posix_memalign(&allocated, align, size);
if (ret != 0) {
return nullptr;
}
#elif defined(QBDI_PLATFORM_WINDOWS)
allocated = _aligned_malloc(size, align);
#endif
return allocated;
}
#ifdef __cplusplus
#define QBDI_GPR_GET(state, i) (reinterpret_cast<const QBDI::rword *>(state)[i])
#define QBDI_GPR_SET(state, i, v) \
(reinterpret_cast<QBDI::rword *>(state)[i] = v)
#else
#define QBDI_GPR_GET(state, i) (((rword *)state)[i])
#define QBDI_GPR_SET(state, i, v) (((rword *)state)[i] = v)
#endif
bool qbdi_allocateVirtualStack(GPRState *ctx, uint32_t stackSize,
uint8_t **stack) {
return allocateVirtualStack(ctx, stackSize, stack);
}
bool allocateVirtualStack(GPRState *ctx, uint32_t stackSize, uint8_t **stack) {
(*stack) = static_cast<uint8_t *>(alignedAlloc(stackSize, 16));
if (*stack == nullptr) {
return false;
}
QBDI_GPR_SET(ctx, REG_SP, reinterpret_cast<QBDI::rword>(*stack) + stackSize);
QBDI_GPR_SET(ctx, REG_BP, QBDI_GPR_GET(ctx, REG_SP));
return true;
}
void *alignedAlloc(size_t size, size_t align) {
void *allocated = nullptr;
if ((align == 0) || ((align & (align - 1)) != 0)) {
return nullptr;
}
#if defined(QBDI_PLATFORM_LINUX) || defined(QBDI_PLATFORM_ANDROID) || \
defined(QBDI_PLATFORM_OSX)
int ret = posix_memalign(&allocated, align, size);
if (ret != 0) {
return nullptr;
}
#elif defined(QBDI_PLATFORM_WINDOWS)
allocated = _aligned_malloc(size, align);
#endif
return allocated;
}
#ifdef __cplusplus
#define QBDI_GPR_GET(state, i) (reinterpret_cast<const QBDI::rword *>(state)[i])
#define QBDI_GPR_SET(state, i, v) \
(reinterpret_cast<QBDI::rword *>(state)[i] = v)
#else
#define QBDI_GPR_GET(state, i) (((rword *)state)[i])
#define QBDI_GPR_SET(state, i, v) (((rword *)state)[i] = v)
#endif
QBDI_EXPORT uint32_t qbdi_addCodeCB(VMInstanceRef instance, InstPosition pos,
InstCallback cbk, void *data, int priority);
QBDI_EXPORT uint32_t qbdi_addCodeCB(VMInstanceRef instance, InstPosition pos,
InstCallback cbk, void *data, int priority);
uint32_t qbdi_addCodeCB(VMInstanceRef instance, InstPosition pos,
InstCallback cbk, void *data, int priority) {
QBDI_REQUIRE_ACTION(instance, return VMError::INVALID_EVENTID);
return static_cast<VM *>(instance)->addCodeCB(pos, cbk, data, priority);
}
uint32_t qbdi_addCodeCB(VMInstanceRef instance, InstPosition pos,
InstCallback cbk, void *data, int priority) {
QBDI_REQUIRE_ACTION(instance, return VMError::INVALID_EVENTID);
return static_cast<VM *>(instance)->addCodeCB(pos, cbk, data, priority);
}
uint32_t VM::addCodeCB(InstPosition pos, InstCallback cbk, void *data,
int priority) {
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
True::unique(), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
uint32_t VM::addCodeCB(InstPosition pos, InstCallback cbk, void *data,
int priority) {
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
True::unique(), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
template <typename T, typename U>
class AutoUnique : public T {
public:
template <typename... Args>
AutoUnique(Args &&...args) : T(std::forward<Args>(args)...) {}
template <typename... Args>
inline static std::unique_ptr<T> unique(Args &&...args) {
return std::make_unique<U>(std::forward<Args>(args)...);
};
};
template <typename T, typename U>
class AutoUnique : public T {
public:
template <typename... Args>
AutoUnique(Args &&...args) : T(std::forward<Args>(args)...) {}
template <typename... Args>
inline static std::unique_ptr<T> unique(Args &&...args) {
return std::make_unique<U>(std::forward<Args>(args)...);
};
};
class True : public AutoClone<PatchCondition, True> {
public:
True() {}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override {
return true;
}
};
class True : public AutoClone<PatchCondition, True> {
public:
True() {}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override {
return true;
}
};
template <typename T, typename U>
class AutoClone : public AutoUnique<T, U> {
public:
template <typename... Args>
AutoClone(Args &&...args) : AutoUnique<T, U>(std::forward<Args>(args)...) {}
inline std::unique_ptr<T> clone() const override {
return std::make_unique<U>(*static_cast<const U *>(this));
};
};
template <typename T, typename U>
class AutoClone : public AutoUnique<T, U> {
public:
template <typename... Args>
AutoClone(Args &&...args) : AutoUnique<T, U>(std::forward<Args>(args)...) {}
inline std::unique_ptr<T> clone() const override {
return std::make_unique<U>(*static_cast<const U *>(this));
};
};
class InstrRuleBasicCBK : public AutoUnique<InstrRule, InstrRuleBasicCBK> {
PatchConditionUniquePtr condition;
PatchGeneratorUniquePtrVec patchGen;
InstPosition position;
bool breakToHost;
RelocatableInstTag tag;
InstCallback cbk;
void *data;
public:
InstrRuleBasicCBK(PatchConditionUniquePtr &&condition, InstCallback cbk,
void *data, InstPosition position, bool breakToHost,
int priority = PRIORITY_DEFAULT,
RelocatableInstTag tag = RelocTagInvalid);
~InstrRuleBasicCBK() override;
std::unique_ptr<InstrRule> clone() const override;
inline InstPosition getPosition() const { return position; }
RangeSet<rword> affectedRange() const override;
bool canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const;
bool changeDataPtr(void *data) override;
inline bool tryInstrument(Patch &patch,
const LLVMCPU &llvmcpu) const override {
if (canBeApplied(patch, llvmcpu)) {
instrument(patch, patchGen, breakToHost, position, priority, tag);
return true;
}
return false;
}
};
class InstrRuleBasicCBK : public AutoUnique<InstrRule, InstrRuleBasicCBK> {
PatchConditionUniquePtr condition;
PatchGeneratorUniquePtrVec patchGen;
InstPosition position;
bool breakToHost;
RelocatableInstTag tag;
InstCallback cbk;
void *data;
public:
InstrRuleBasicCBK(PatchConditionUniquePtr &&condition, InstCallback cbk,
void *data, InstPosition position, bool breakToHost,
int priority = PRIORITY_DEFAULT,
RelocatableInstTag tag = RelocTagInvalid);
~InstrRuleBasicCBK() override;
std::unique_ptr<InstrRule> clone() const override;
inline InstPosition getPosition() const { return position; }
RangeSet<rword> affectedRange() const override;
bool canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const;
bool changeDataPtr(void *data) override;
inline bool tryInstrument(Patch &patch,
const LLVMCPU &llvmcpu) const override {
if (canBeApplied(patch, llvmcpu)) {
instrument(patch, patchGen, breakToHost, position, priority, tag);
return true;
}
return false;
}
};
uint32_t Engine::addInstrRule(std::unique_ptr<InstrRule> &&rule) {
uint32_t id = instrRulesCounter++;
QBDI_REQUIRE_ACTION(id < EVENTID_VM_MASK, return VMError::INVALID_EVENTID);
this->clearCache(rule->affectedRange());
auto v = std::make_pair(id, std::move(rule));
auto it = std::upper_bound(instrRules.begin(), instrRules.end(), v,
[](const decltype(instrRules)::value_type &a,
const decltype(instrRules)::value_type &b) {
return a.second->getPriority() >
b.second->getPriority();
});
instrRules.insert(it, std::move(v));
return id;
}
uint32_t Engine::addInstrRule(std::unique_ptr<InstrRule> &&rule) {
uint32_t id = instrRulesCounter++;
QBDI_REQUIRE_ACTION(id < EVENTID_VM_MASK, return VMError::INVALID_EVENTID);
this->clearCache(rule->affectedRange());
auto v = std::make_pair(id, std::move(rule));
auto it = std::upper_bound(instrRules.begin(), instrRules.end(), v,
[](const decltype(instrRules)::value_type &a,
const decltype(instrRules)::value_type &b) {
return a.second->getPriority() >
b.second->getPriority();
});
instrRules.insert(it, std::move(v));
return id;
}
RangeSet<rword> InstrRuleBasicCBK::affectedRange() const {
return condition->affectedRange();
}
RangeSet<rword> InstrRuleBasicCBK::affectedRange() const {
return condition->affectedRange();
}
class PatchCondition {
public:
using UniquePtr = std::unique_ptr<PatchCondition>;
using UniquePtrVec = std::vector<std::unique_ptr<PatchCondition>>;
virtual UniquePtr clone() const = 0;
virtual bool test(const Patch &patch, const LLVMCPU &llvmcpu) const = 0;
virtual RangeSet<rword> affectedRange() const {
RangeSet<rword> r;
r.add(Range<rword>(0, (rword)-1));
return r;
}
virtual ~PatchCondition() = default;
};
class PatchCondition {
public:
using UniquePtr = std::unique_ptr<PatchCondition>;
using UniquePtrVec = std::vector<std::unique_ptr<PatchCondition>>;
virtual UniquePtr clone() const = 0;
virtual bool test(const Patch &patch, const LLVMCPU &llvmcpu) const = 0;
virtual RangeSet<rword> affectedRange() const {
RangeSet<rword> r;
r.add(Range<rword>(0, (rword)-1));
return r;
}
virtual ~PatchCondition() = default;
};
auto v = std::make_pair(id, std::move(rule));
auto it = std::upper_bound(instrRules.begin(), instrRules.end(), v,
[](const decltype(instrRules)::value_type &a,
const decltype(instrRules)::value_type &b) {
return a.second->getPriority() >
b.second->getPriority();
});
instrRules.insert(it, std::move(v));
auto v = std::make_pair(id, std::move(rule));
auto it = std::upper_bound(instrRules.begin(), instrRules.end(), v,
[](const decltype(instrRules)::value_type &a,
const decltype(instrRules)::value_type &b) {
return a.second->getPriority() >
b.second->getPriority();
});
instrRules.insert(it, std::move(v));
uint32_t qbdi_addMnemonicCB(VMInstanceRef instance, const char *mnemonic,
InstPosition pos, InstCallback cbk, void *data,
int priority) {
QBDI_REQUIRE_ACTION(instance, return VMError::INVALID_EVENTID);
return static_cast<VM *>(instance)->addMnemonicCB(mnemonic, pos, cbk, data,
priority);
}
uint32_t qbdi_addMnemonicCB(VMInstanceRef instance, const char *mnemonic,
InstPosition pos, InstCallback cbk, void *data,
int priority) {
QBDI_REQUIRE_ACTION(instance, return VMError::INVALID_EVENTID);
return static_cast<VM *>(instance)->addMnemonicCB(mnemonic, pos, cbk, data,
priority);
}
uint32_t VM::addMnemonicCB(const char *mnemonic, InstPosition pos,
InstCallback cbk, void *data, int priority) {
QBDI_REQUIRE_ACTION(mnemonic != nullptr, return VMError::INVALID_EVENTID);
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
MnemonicIs::unique(mnemonic), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
uint32_t VM::addMnemonicCB(const char *mnemonic, InstPosition pos,
InstCallback cbk, void *data, int priority) {
QBDI_REQUIRE_ACTION(mnemonic != nullptr, return VMError::INVALID_EVENTID);
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
MnemonicIs::unique(mnemonic), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
class MnemonicIs : public AutoClone<PatchCondition, MnemonicIs> {
std::string mnemonic;
public:
MnemonicIs(const char *mnemonic) : mnemonic(mnemonic) {}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override;
};
class MnemonicIs : public AutoClone<PatchCondition, MnemonicIs> {
std::string mnemonic;
public:
MnemonicIs(const char *mnemonic) : mnemonic(mnemonic) {}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override;
};
bool MnemonicIs::test(const Patch &patch, const LLVMCPU &llvmcpu) const {
return QBDI::String::startsWith(
mnemonic.c_str(), llvmcpu.getInstOpcodeName(patch.metadata.inst));
}
bool startsWith(const char *prefix, const char *str) {
QBDI_REQUIRE_ACTION(prefix != nullptr, return false);
QBDI_REQUIRE_ACTION(str != nullptr, return false);
while (*prefix && *str) {
if (*prefix == '*') {
if (toupper(*(prefix + 1)) == toupper(*str++)) {
prefix++;
}
continue;
}
if (toupper(*prefix++) != toupper(*str++)) {
return false;
}
}
if (*prefix && *(prefix + 1)) {
return false;
}
if (!((*str >= '0' && *str <= '9') || *str == '_' || !*str)) {
return false;
}
return true;
}
bool MnemonicIs::test(const Patch &patch, const LLVMCPU &llvmcpu) const {
return QBDI::String::startsWith(
mnemonic.c_str(), llvmcpu.getInstOpcodeName(patch.metadata.inst));
}
bool startsWith(const char *prefix, const char *str) {
QBDI_REQUIRE_ACTION(prefix != nullptr, return false);
QBDI_REQUIRE_ACTION(str != nullptr, return false);
while (*prefix && *str) {
if (*prefix == '*') {
if (toupper(*(prefix + 1)) == toupper(*str++)) {
prefix++;
}
continue;
}
if (toupper(*prefix++) != toupper(*str++)) {
return false;
}
}
if (*prefix && *(prefix + 1)) {
return false;
}
if (!((*str >= '0' && *str <= '9') || *str == '_' || !*str)) {
return false;
}
return true;
}
namespace llvm {
class MCInst;
}
namespace QBDI {
class LLVMCPU;
class RelocatableInst;
struct InstrPatch {
InstPosition position;
int priority;
std::vector<std::unique_ptr<RelocatableInst>> insts;
};
class Patch {
private:
std::vector<InstrPatch> instsPatchs;
public:
InstMetadata metadata;
std::vector<std::unique_ptr<RelocatableInst>> insts;
std::vector<std::pair<unsigned int, int>> patchGenFlags;
int patchGenFlagsOffset = 0;
std::vector<std::unique_ptr<InstCbLambda>> userInstCB;
std::array<RegisterUsage, NUM_GPR> regUsage;
std::map<RegLLVM, RegisterUsage> regUsageExtra;
std::set<RegLLVM> tempReg;
const LLVMCPU *llvmcpu;
bool finalize = false;
using Vec = std::vector<Patch>;
Patch(const llvm::MCInst &inst, rword address, uint32_t instSize,
const LLVMCPU &llvmcpu);
Patch(Patch &&);
Patch &operator=(Patch &&);
~Patch();
void setModifyPC(bool modifyPC);
void append(std::unique_ptr<RelocatableInst> &&r);
void append(std::vector<std::unique_ptr<RelocatableInst>> v);
void prepend(std::unique_ptr<RelocatableInst> &&r);
void prepend(std::vector<std::unique_ptr<RelocatableInst>> v);
void insertAt(unsigned position,
std::vector<std::unique_ptr<RelocatableInst>> v);
void addInstsPatch(InstPosition position, int priority,
std::vector<std::unique_ptr<RelocatableInst>> v);
void finalizeInstsPatch();
};
}
namespace llvm {
class MCInst;
}
namespace QBDI {
class LLVMCPU;
class RelocatableInst;
struct InstrPatch {
InstPosition position;
int priority;
std::vector<std::unique_ptr<RelocatableInst>> insts;
};
class Patch {
private:
std::vector<InstrPatch> instsPatchs;
public:
InstMetadata metadata;
std::vector<std::unique_ptr<RelocatableInst>> insts;
std::vector<std::pair<unsigned int, int>> patchGenFlags;
int patchGenFlagsOffset = 0;
std::vector<std::unique_ptr<InstCbLambda>> userInstCB;
std::array<RegisterUsage, NUM_GPR> regUsage;
std::map<RegLLVM, RegisterUsage> regUsageExtra;
std::set<RegLLVM> tempReg;
const LLVMCPU *llvmcpu;
bool finalize = false;
using Vec = std::vector<Patch>;
Patch(const llvm::MCInst &inst, rword address, uint32_t instSize,
const LLVMCPU &llvmcpu);
Patch(Patch &&);
Patch &operator=(Patch &&);
~Patch();
void setModifyPC(bool modifyPC);
void append(std::unique_ptr<RelocatableInst> &&r);
void append(std::vector<std::unique_ptr<RelocatableInst>> v);
void prepend(std::unique_ptr<RelocatableInst> &&r);
void prepend(std::vector<std::unique_ptr<RelocatableInst>> v);
void insertAt(unsigned position,
std::vector<std::unique_ptr<RelocatableInst>> v);
void addInstsPatch(InstPosition position, int priority,
std::vector<std::unique_ptr<RelocatableInst>> v);
void finalizeInstsPatch();
};
}
const char *LLVMCPU::getInstOpcodeName(const llvm::MCInst &inst) const {
return getInstOpcodeName(inst.getOpcode());
}
const char *LLVMCPU::getInstOpcodeName(unsigned opcode) const {
return MCII->getName(opcode).data();
}
const char *LLVMCPU::getInstOpcodeName(const llvm::MCInst &inst) const {
return getInstOpcodeName(inst.getOpcode());
}
const char *LLVMCPU::getInstOpcodeName(unsigned opcode) const {
return MCII->getName(opcode).data();
}
bool qbdi_addInstrumentedModuleFromAddr(VMInstanceRef instance, rword addr) {
QBDI_REQUIRE_ACTION(instance, return false);
return static_cast<VM *>(instance)->addInstrumentedModuleFromAddr(addr);
}
bool VM::addInstrumentedModuleFromAddr(rword addr) {
return engine->addInstrumentedModuleFromAddr(addr);
}
bool Engine::addInstrumentedModuleFromAddr(rword addr) {
return execBroker->addInstrumentedModuleFromAddr(addr);
}
bool qbdi_addInstrumentedModuleFromAddr(VMInstanceRef instance, rword addr) {
QBDI_REQUIRE_ACTION(instance, return false);
return static_cast<VM *>(instance)->addInstrumentedModuleFromAddr(addr);
}
bool VM::addInstrumentedModuleFromAddr(rword addr) {
return engine->addInstrumentedModuleFromAddr(addr);
}
bool Engine::addInstrumentedModuleFromAddr(rword addr) {
return execBroker->addInstrumentedModuleFromAddr(addr);
}
bool ExecBroker::addInstrumentedModuleFromAddr(rword addr) {
for (const MemoryMap &m : getCurrentProcessMaps()) {
if (m.range.contains(addr)) {
if (not m.name.empty()) {
return addInstrumentedModule(m.name);
} else if (m.permission & QBDI::PF_EXEC) {
addInstrumentedRange(m.range);
return true;
} else {
return false;
}
}
}
return false;
}
bool ExecBroker::addInstrumentedModuleFromAddr(rword addr) {
for (const MemoryMap &m : getCurrentProcessMaps()) {
if (m.range.contains(addr)) {
if (not m.name.empty()) {
return addInstrumentedModule(m.name);
} else if (m.permission & QBDI::PF_EXEC) {
addInstrumentedRange(m.range);
return true;
} else {
return false;
}
}
}
return false;
}
QBDI_EXPORT std::vector<MemoryMap>
getCurrentProcessMaps(bool full_path = false);
std::vector<MemoryMap> getCurrentProcessMaps(bool full_path) {
return getRemoteProcessMaps(getpid(), full_path);
}
std::vector<MemoryMap> getRemoteProcessMaps(QBDI::rword pid, bool full_path) {
static const int BUFFER_SIZE = 256;
char line[BUFFER_SIZE] = {0};
FILE *mapfile = nullptr;
std::vector<MemoryMap> maps;
snprintf(line, BUFFER_SIZE, "/proc/%llu/maps", (unsigned long long)pid);
mapfile = fopen(line, "r");
QBDI_DEBUG("Querying memory maps from {}", line);
QBDI_REQUIRE_ACTION(mapfile != nullptr, return maps);
while (fgets(line, BUFFER_SIZE, mapfile) != nullptr) {
char *ptr = nullptr;
MemoryMap m;
if ((ptr = strchr(line, '\n')) != nullptr) {
*ptr = '\0';
}
ptr = line;
QBDI_DEBUG("Parsing line: {}", line);
m.range.setStart(strtoul(ptr, &ptr, 16));
ptr++;
m.range.setEnd(strtoul(ptr, &ptr, 16));
while (isspace(*ptr))
ptr++;
m.permission = QBDI::PF_NONE;
if (*ptr == 'r')
m.permission |= QBDI::PF_READ;
ptr++;
if (*ptr == 'w')
m.permission |= QBDI::PF_WRITE;
ptr++;
if (*ptr == 'x')
m.permission |= QBDI::PF_EXEC;
ptr++;
ptr++;
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 16);
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 16);
ptr++;
strtoul(ptr, &ptr, 16);
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 10);
while (isspace(*ptr))
ptr++;
if (full_path) {
m.name = ptr;
} else {
if ((ptr = strrchr(ptr, '/')) != nullptr) {
m.name = ptr + 1;
} else {
m.name.clear();
}
}
QBDI_DEBUG("Read new map [0x{:x}, 0x{:x}] {} {}{}{}", m.range.start(),
m.range.end(), m.name.c_str(),
(m.permission & QBDI::PF_READ) ? "r" : "-",
(m.permission & QBDI::PF_WRITE) ? "w" : "-",
(m.permission & QBDI::PF_EXEC) ? "x" : "-");
maps.push_back(m);
}
fclose(mapfile);
return maps;
}
QBDI_EXPORT std::vector<MemoryMap>
getCurrentProcessMaps(bool full_path = false);
std::vector<MemoryMap> getCurrentProcessMaps(bool full_path) {
return getRemoteProcessMaps(getpid(), full_path);
}
std::vector<MemoryMap> getRemoteProcessMaps(QBDI::rword pid, bool full_path) {
static const int BUFFER_SIZE = 256;
char line[BUFFER_SIZE] = {0};
FILE *mapfile = nullptr;
std::vector<MemoryMap> maps;
snprintf(line, BUFFER_SIZE, "/proc/%llu/maps", (unsigned long long)pid);
mapfile = fopen(line, "r");
QBDI_DEBUG("Querying memory maps from {}", line);
QBDI_REQUIRE_ACTION(mapfile != nullptr, return maps);
while (fgets(line, BUFFER_SIZE, mapfile) != nullptr) {
char *ptr = nullptr;
MemoryMap m;
if ((ptr = strchr(line, '\n')) != nullptr) {
*ptr = '\0';
}
ptr = line;
QBDI_DEBUG("Parsing line: {}", line);
m.range.setStart(strtoul(ptr, &ptr, 16));
ptr++;
m.range.setEnd(strtoul(ptr, &ptr, 16));
while (isspace(*ptr))
ptr++;
m.permission = QBDI::PF_NONE;
if (*ptr == 'r')
m.permission |= QBDI::PF_READ;
ptr++;
if (*ptr == 'w')
m.permission |= QBDI::PF_WRITE;
ptr++;
if (*ptr == 'x')
m.permission |= QBDI::PF_EXEC;
ptr++;
ptr++;
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 16);
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 16);
ptr++;
strtoul(ptr, &ptr, 16);
while (isspace(*ptr))
ptr++;
strtoul(ptr, &ptr, 10);
while (isspace(*ptr))
ptr++;
if (full_path) {
m.name = ptr;
} else {
if ((ptr = strrchr(ptr, '/')) != nullptr) {
m.name = ptr + 1;
} else {
m.name.clear();
}
}
QBDI_DEBUG("Read new map [0x{:x}, 0x{:x}] {} {}{}{}", m.range.start(),
m.range.end(), m.name.c_str(),
(m.permission & QBDI::PF_READ) ? "r" : "-",
(m.permission & QBDI::PF_WRITE) ? "w" : "-",
(m.permission & QBDI::PF_EXEC) ? "x" : "-");
maps.push_back(m);
}
fclose(mapfile);
return maps;
}
bool ExecBroker::addInstrumentedModule(const std::string &name) {
bool instrumented = false;
if (name.empty()) {
return false;
}
for (const MemoryMap &m : getCurrentProcessMaps()) {
if ((m.name == name) && (m.permission & QBDI::PF_EXEC)) {
addInstrumentedRange(m.range);
instrumented = true;
}
}
return instrumented;
}
void ExecBroker::addInstrumentedRange(const Range<rword> &r) {
QBDI_DEBUG("Adding instrumented range [0x{:x}, 0x{:x}]", r.start(), r.end());
instrumented.add(r);
}
bool ExecBroker::addInstrumentedModule(const std::string &name) {
bool instrumented = false;
if (name.empty()) {
return false;
}
for (const MemoryMap &m : getCurrentProcessMaps()) {
if ((m.name == name) && (m.permission & QBDI::PF_EXEC)) {
addInstrumentedRange(m.range);
instrumented = true;
}
}
return instrumented;
}
void ExecBroker::addInstrumentedRange(const Range<rword> &r) {
QBDI_DEBUG("Adding instrumented range [0x{:x}, 0x{:x}]", r.start(), r.end());
instrumented.add(r);
}
bool ExecBroker::addInstrumentedModuleFromAddr(rword addr) {
for (const MemoryMap &m : getCurrentProcessMaps()) {
if (m.range.contains(addr)) {
if (not m.name.empty()) {
return addInstrumentedModule(m.name);
} else if (m.permission & QBDI::PF_EXEC) {
addInstrumentedRange(m.range);
return true;
} else {
return false;
}
}
}
return false;
}
bool ExecBroker::addInstrumentedModuleFromAddr(rword addr) {
for (const MemoryMap &m : getCurrentProcessMaps()) {
if (m.range.contains(addr)) {
if (not m.name.empty()) {
return addInstrumentedModule(m.name);
} else if (m.permission & QBDI::PF_EXEC) {
addInstrumentedRange(m.range);
return true;
} else {
return false;
}
}
}
return false;
}
QBDI_EXPORT bool qbdi_call(VMInstanceRef instance, rword *retval,
rword function, uint32_t argNum, ...);
QBDI_EXPORT bool qbdi_call(VMInstanceRef instance, rword *retval,
rword function, uint32_t argNum, ...);
bool qbdi_call(VMInstanceRef instance, rword *retval, rword function,
uint32_t argNum, ...) {
QBDI_REQUIRE_ACTION(instance, return false);
va_list ap;
va_start(ap, argNum);
bool res = static_cast<VM *>(instance)->callV(retval, function, argNum, ap);
va_end(ap);
return res;
}
bool qbdi_call(VMInstanceRef instance, rword *retval, rword function,
uint32_t argNum, ...) {
QBDI_REQUIRE_ACTION(instance, return false);
va_list ap;
va_start(ap, argNum);
bool res = static_cast<VM *>(instance)->callV(retval, function, argNum, ap);
va_end(ap);
return res;
}
bool VM::callV(rword *retval, rword function, uint32_t argNum, va_list ap) {
std::vector<rword> args(argNum);
for (uint32_t i = 0; i < argNum; i++) {
args[i] = va_arg(ap, rword);
}
bool res = this->callA(retval, function, argNum, args.data());
return res;
}
bool VM::callV(rword *retval, rword function, uint32_t argNum, va_list ap) {
std::vector<rword> args(argNum);
for (uint32_t i = 0; i < argNum; i++) {
args[i] = va_arg(ap, rword);
}
bool res = this->callA(retval, function, argNum, args.data());
return res;
}
#define FAKE_RET_ADDR 42
bool VM::callA(rword *retval, rword function, uint32_t argNum,
const rword *args) {
GPRState *state = getGPRState();
QBDI_REQUIRE_ABORT(state != nullptr, "Fail to get VM GPRState");
if (QBDI_GPR_GET(state, REG_SP) == 0) {
return false;
}
simulateCallA(state, FAKE_RET_ADDR, argNum, args);
bool res = run(function, FAKE_RET_ADDR);
if (retval != nullptr) {
*retval = QBDI_GPR_GET(state, REG_RETURN);
}
return res;
}
#define FAKE_RET_ADDR 42
bool VM::callA(rword *retval, rword function, uint32_t argNum,
const rword *args) {
GPRState *state = getGPRState();
QBDI_REQUIRE_ABORT(state != nullptr, "Fail to get VM GPRState");
if (QBDI_GPR_GET(state, REG_SP) == 0) {
return false;
}
simulateCallA(state, FAKE_RET_ADDR, argNum, args);
bool res = run(function, FAKE_RET_ADDR);
if (retval != nullptr) {
*retval = QBDI_GPR_GET(state, REG_RETURN);
}
return res;
}
#define FRAME_LENGTH 16
void simulateCallA(GPRState *ctx, rword returnAddress, uint32_t argNum,
const rword *args) {
uint32_t i = 0;
uint32_t argsoff = 0;
uint32_t limit = FRAME_LENGTH;
QBDI_GPR_SET(ctx, REG_SP,
QBDI_GPR_GET(ctx, REG_SP) - FRAME_LENGTH * sizeof(rword));
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
QBDI_GPR_SET(ctx, REG_SP, QBDI_GPR_GET(ctx, REG_SP) - sizeof(rword));
*(rword *)(QBDI_GPR_GET(ctx, REG_SP)) = returnAddress;
argsoff++;
#elif defined(QBDI_ARCH_ARM) || defined(QBDI_ARCH_AARCH64)
QBDI_DEBUG("Set LR to: 0x{:x}", returnAddress);
ctx->lr = returnAddress;
#endif
#define UNSTACK_ARG(REG) \
if (i < argNum) { \
ctx->REG = args[i++]; \
}
#if defined(QBDI_ARCH_X86_64)
#if defined(QBDI_PLATFORM_WINDOWS)
argsoff += 4;
UNSTACK_ARG(rcx);
UNSTACK_ARG(rdx);
UNSTACK_ARG(r8);
UNSTACK_ARG(r9);
#else
UNSTACK_ARG(rdi);
UNSTACK_ARG(rsi);
UNSTACK_ARG(rdx);
UNSTACK_ARG(rcx);
UNSTACK_ARG(r8);
UNSTACK_ARG(r9);
#endif // OS
#elif defined(QBDI_ARCH_X86)
#elif defined(QBDI_ARCH_ARM)
UNSTACK_ARG(r0);
UNSTACK_ARG(r1);
UNSTACK_ARG(r2);
UNSTACK_ARG(r3);
#elif defined(QBDI_ARCH_AARCH64)
UNSTACK_ARG(x0);
UNSTACK_ARG(x1);
UNSTACK_ARG(x2);
UNSTACK_ARG(x3);
UNSTACK_ARG(x4);
UNSTACK_ARG(x5);
UNSTACK_ARG(x6);
UNSTACK_ARG(x7);
#endif // ARCH
#undef UNSTACK_ARG
limit -= argsoff;
rword *frame = (rword *)QBDI_GPR_GET(ctx, REG_SP);
for (uint32_t j = 0; (i + j) < argNum && j < limit; j++) {
frame[argsoff + j] = args[i + j];
}
}
#define FRAME_LENGTH 16
void simulateCallA(GPRState *ctx, rword returnAddress, uint32_t argNum,
const rword *args) {
uint32_t i = 0;
uint32_t argsoff = 0;
uint32_t limit = FRAME_LENGTH;
QBDI_GPR_SET(ctx, REG_SP,
QBDI_GPR_GET(ctx, REG_SP) - FRAME_LENGTH * sizeof(rword));
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
QBDI_GPR_SET(ctx, REG_SP, QBDI_GPR_GET(ctx, REG_SP) - sizeof(rword));
*(rword *)(QBDI_GPR_GET(ctx, REG_SP)) = returnAddress;
argsoff++;
#elif defined(QBDI_ARCH_ARM) || defined(QBDI_ARCH_AARCH64)
QBDI_DEBUG("Set LR to: 0x{:x}", returnAddress);
ctx->lr = returnAddress;
#endif
#define UNSTACK_ARG(REG) \
if (i < argNum) { \
ctx->REG = args[i++]; \
}
#if defined(QBDI_ARCH_X86_64)
#if defined(QBDI_PLATFORM_WINDOWS)
argsoff += 4;
UNSTACK_ARG(rcx);
UNSTACK_ARG(rdx);
UNSTACK_ARG(r8);
UNSTACK_ARG(r9);
#else
UNSTACK_ARG(rdi);
UNSTACK_ARG(rsi);
UNSTACK_ARG(rdx);
UNSTACK_ARG(rcx);
UNSTACK_ARG(r8);
UNSTACK_ARG(r9);
#endif // OS
#elif defined(QBDI_ARCH_X86)
#elif defined(QBDI_ARCH_ARM)
UNSTACK_ARG(r0);
UNSTACK_ARG(r1);
UNSTACK_ARG(r2);
UNSTACK_ARG(r3);
#elif defined(QBDI_ARCH_AARCH64)
UNSTACK_ARG(x0);
UNSTACK_ARG(x1);
UNSTACK_ARG(x2);
UNSTACK_ARG(x3);
UNSTACK_ARG(x4);
UNSTACK_ARG(x5);
UNSTACK_ARG(x6);
UNSTACK_ARG(x7);
#endif // ARCH
#undef UNSTACK_ARG
limit -= argsoff;
rword *frame = (rword *)QBDI_GPR_GET(ctx, REG_SP);
for (uint32_t j = 0; (i + j) < argNum && j < limit; j++) {
frame[argsoff + j] = args[i + j];
}
}
bool VM::run(rword start, rword stop) {
uint32_t stopCB =
addCodeAddrCB(stop, InstPosition::PREINST, stopCallback, nullptr);
bool ret = engine->run(start, stop);
deleteInstrumentation(stopCB);
return ret;
}
bool VM::run(rword start, rword stop) {
uint32_t stopCB =
addCodeAddrCB(stop, InstPosition::PREINST, stopCallback, nullptr);
bool ret = engine->run(start, stop);
deleteInstrumentation(stopCB);
return ret;
}
VMAction stopCallback(VMInstanceRef vm, GPRState *gprState, FPRState *fprState,
void *data) {
return VMAction::STOP;
}
VMAction stopCallback(VMInstanceRef vm, GPRState *gprState, FPRState *fprState,
void *data) {
return VMAction::STOP;
}
uint32_t VM::addCodeAddrCB(rword address, InstPosition pos, InstCallback cbk,
void *data, int priority) {
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
AddressIs::unique(address), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
uint32_t VM::addCodeAddrCB(rword address, InstPosition pos, InstCallback cbk,
void *data, int priority) {
QBDI_REQUIRE_ACTION(cbk != nullptr, return VMError::INVALID_EVENTID);
return engine->addInstrRule(InstrRuleBasicCBK::unique(
AddressIs::unique(address), cbk, data, pos, true, priority,
(pos == PREINST) ? RelocTagPreInstStdCBK : RelocTagPostInstStdCBK));
}
class AddressIs : public AutoClone<PatchCondition, AddressIs> {
rword breakpoint;
public:
AddressIs(rword breakpoint_) : breakpoint(breakpoint_) {
if constexpr (is_arm) {
breakpoint &= (~1);
}
}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override {
return patch.metadata.address == breakpoint;
}
RangeSet<rword> affectedRange() const override {
RangeSet<rword> r;
r.add(Range<rword>(breakpoint, breakpoint + 1));
return r;
}
};
class AddressIs : public AutoClone<PatchCondition, AddressIs> {
rword breakpoint;
public:
AddressIs(rword breakpoint_) : breakpoint(breakpoint_) {
if constexpr (is_arm) {
breakpoint &= (~1);
}
}
bool test(const Patch &patch, const LLVMCPU &llvmcpu) const override {
return patch.metadata.address == breakpoint;
}
RangeSet<rword> affectedRange() const override {
RangeSet<rword> r;
r.add(Range<rword>(breakpoint, breakpoint + 1));
return r;
}
};
bool Engine::run(rword start, rword stop) {
QBDI_REQUIRE_ABORT(not running, "Cannot run an already running Engine");
rword currentPC = start;
bool hasRan = false;
curGPRState = gprState.get();
curFPRState = fprState.get();
rword basicBlockBeginAddr = 0;
rword basicBlockEndAddr = 0;
if (!execBroker->isInstrumented(start)) {
return false;
}
running = true;
do {
VMAction action = CONTINUE;
if (execBroker->isInstrumented(currentPC) == false and
execBroker->canTransferExecution(curGPRState)) {
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (not changeCPUMode) {
if (curCPUMode == CPUMode::Thumb) {
currentPC = currentPC | 1;
} else {
currentPC = currentPC & (~1);
}
}
#endif
curExecBlock = nullptr;
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
QBDI_DEBUG("Executing 0x{:x} through execBroker", currentPC);
action = signalEvent(EXEC_TRANSFER_CALL, currentPC, nullptr, 0,
curGPRState, curFPRState);
if (action == CONTINUE) {
execBroker->transferExecution(currentPC, curGPRState, curFPRState);
action = signalEvent(EXEC_TRANSFER_RETURN, currentPC, nullptr, 0,
curGPRState, curFPRState);
}
}
else {
VMEvent event = VMEvent::SEQUENCE_ENTRY;
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (changeCPUMode) {
curCPUMode = currentPC & 1 ? CPUMode::Thumb : CPUMode::ARM;
QBDI_DEBUG("CPUMode set to {}",
curCPUMode == CPUMode::ARM ? "ARM" : "Thumb");
} else if (curCPUMode == CPUMode::ARM) {
QBDI_REQUIRE_ABORT((currentPC & 1) == 0,
"Unexpected address in ARM mode");
} else {
QBDI_REQUIRE_ABORT((currentPC & 1) == 1,
"Unexpected address in Thumb mode");
}
currentPC = currentPC & (~1);
#endif
QBDI_DEBUG("Executing 0x{:x} through DBI in mode {}", currentPC,
curCPUMode);
if (blockManager->isFlushPending()) {
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
blockManager->flushCommit();
}
SeqLoc currentSequence;
curExecBlock = blockManager->getProgrammedExecBlock(currentPC, curCPUMode,
¤tSequence);
if (curExecBlock == nullptr) {
QBDI_DEBUG(
"Cache miss for 0x{:x}, patching & instrumenting new basic block",
currentPC);
handleNewBasicBlock(currentPC);
event |= BASIC_BLOCK_NEW;
curExecBlock = blockManager->getProgrammedExecBlock(
currentPC, curCPUMode, ¤tSequence);
QBDI_REQUIRE_ABORT(curExecBlock != nullptr,
"Fail to instrument the next basic block");
}
if (basicBlockEndAddr == 0) {
event |= BASIC_BLOCK_ENTRY;
basicBlockEndAddr = currentSequence.bbEnd;
basicBlockBeginAddr = currentPC;
}
if (&(curExecBlock->getContext()->gprState) != curGPRState ||
&(curExecBlock->getContext()->fprState) != curFPRState) {
curExecBlock->getContext()->gprState = *curGPRState;
curExecBlock->getContext()->fprState = *curFPRState;
}
curGPRState = &(curExecBlock->getContext()->gprState);
curFPRState = &(curExecBlock->getContext()->fprState);
action = signalEvent(event, currentPC, ¤tSequence,
basicBlockBeginAddr, curGPRState, curFPRState);
if (action == CONTINUE) {
hasRan = true;
action = curExecBlock->execute();
if (action == CONTINUE) {
if (basicBlockEndAddr == currentSequence.seqEnd) {
action = signalEvent(SEQUENCE_EXIT | BASIC_BLOCK_EXIT, currentPC,
¤tSequence, basicBlockBeginAddr,
curGPRState, curFPRState);
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
} else {
action = signalEvent(SEQUENCE_EXIT, currentPC, ¤tSequence,
basicBlockBeginAddr, curGPRState, curFPRState);
}
}
}
}
if (action == STOP) {
QBDI_DEBUG("Receive STOP Action");
break;
}
if (action != CONTINUE) {
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
curExecBlock = nullptr;
}
currentPC = QBDI_GPR_GET(curGPRState, REG_PC);
QBDI_DEBUG("Next address to execute is 0x{:x}", currentPC);
} while (currentPC != stop);
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
curExecBlock = nullptr;
running = false;
if (blockManager->isFlushPending()) {
blockManager->flushCommit();
}
return hasRan;
}
bool Engine::run(rword start, rword stop) {
QBDI_REQUIRE_ABORT(not running, "Cannot run an already running Engine");
rword currentPC = start;
bool hasRan = false;
curGPRState = gprState.get();
curFPRState = fprState.get();
rword basicBlockBeginAddr = 0;
rword basicBlockEndAddr = 0;
if (!execBroker->isInstrumented(start)) {
return false;
}
running = true;
do {
VMAction action = CONTINUE;
if (execBroker->isInstrumented(currentPC) == false and
execBroker->canTransferExecution(curGPRState)) {
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (not changeCPUMode) {
if (curCPUMode == CPUMode::Thumb) {
currentPC = currentPC | 1;
} else {
currentPC = currentPC & (~1);
}
}
#endif
curExecBlock = nullptr;
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
QBDI_DEBUG("Executing 0x{:x} through execBroker", currentPC);
action = signalEvent(EXEC_TRANSFER_CALL, currentPC, nullptr, 0,
curGPRState, curFPRState);
if (action == CONTINUE) {
execBroker->transferExecution(currentPC, curGPRState, curFPRState);
action = signalEvent(EXEC_TRANSFER_RETURN, currentPC, nullptr, 0,
curGPRState, curFPRState);
}
}
else {
VMEvent event = VMEvent::SEQUENCE_ENTRY;
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (changeCPUMode) {
curCPUMode = currentPC & 1 ? CPUMode::Thumb : CPUMode::ARM;
QBDI_DEBUG("CPUMode set to {}",
curCPUMode == CPUMode::ARM ? "ARM" : "Thumb");
} else if (curCPUMode == CPUMode::ARM) {
QBDI_REQUIRE_ABORT((currentPC & 1) == 0,
"Unexpected address in ARM mode");
} else {
QBDI_REQUIRE_ABORT((currentPC & 1) == 1,
"Unexpected address in Thumb mode");
}
currentPC = currentPC & (~1);
#endif
QBDI_DEBUG("Executing 0x{:x} through DBI in mode {}", currentPC,
curCPUMode);
if (blockManager->isFlushPending()) {
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
blockManager->flushCommit();
}
SeqLoc currentSequence;
curExecBlock = blockManager->getProgrammedExecBlock(currentPC, curCPUMode,
¤tSequence);
if (curExecBlock == nullptr) {
QBDI_DEBUG(
"Cache miss for 0x{:x}, patching & instrumenting new basic block",
currentPC);
handleNewBasicBlock(currentPC);
event |= BASIC_BLOCK_NEW;
curExecBlock = blockManager->getProgrammedExecBlock(
currentPC, curCPUMode, ¤tSequence);
QBDI_REQUIRE_ABORT(curExecBlock != nullptr,
"Fail to instrument the next basic block");
}
if (basicBlockEndAddr == 0) {
event |= BASIC_BLOCK_ENTRY;
basicBlockEndAddr = currentSequence.bbEnd;
basicBlockBeginAddr = currentPC;
}
if (&(curExecBlock->getContext()->gprState) != curGPRState ||
&(curExecBlock->getContext()->fprState) != curFPRState) {
curExecBlock->getContext()->gprState = *curGPRState;
curExecBlock->getContext()->fprState = *curFPRState;
}
curGPRState = &(curExecBlock->getContext()->gprState);
curFPRState = &(curExecBlock->getContext()->fprState);
action = signalEvent(event, currentPC, ¤tSequence,
basicBlockBeginAddr, curGPRState, curFPRState);
if (action == CONTINUE) {
hasRan = true;
action = curExecBlock->execute();
if (action == CONTINUE) {
if (basicBlockEndAddr == currentSequence.seqEnd) {
action = signalEvent(SEQUENCE_EXIT | BASIC_BLOCK_EXIT, currentPC,
¤tSequence, basicBlockBeginAddr,
curGPRState, curFPRState);
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
} else {
action = signalEvent(SEQUENCE_EXIT, currentPC, ¤tSequence,
basicBlockBeginAddr, curGPRState, curFPRState);
}
}
}
}
if (action == STOP) {
QBDI_DEBUG("Receive STOP Action");
break;
}
if (action != CONTINUE) {
basicBlockBeginAddr = 0;
basicBlockEndAddr = 0;
curExecBlock = nullptr;
}
currentPC = QBDI_GPR_GET(curGPRState, REG_PC);
QBDI_DEBUG("Next address to execute is 0x{:x}", currentPC);
} while (currentPC != stop);
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
curExecBlock = nullptr;
running = false;
if (blockManager->isFlushPending()) {
blockManager->flushCommit();
}
return hasRan;
}
std::unique_ptr<GPRState> gprState;
std::unique_ptr<FPRState> fprState;
std::unique_ptr<GPRState> gprState;
std::unique_ptr<FPRState> fprState;
typedef struct QBDI_ALIGNED(16) {
union {
FPControl fcw;
uint16_t rfcw;
};
union {
FPStatus fsw;
uint16_t rfsw;
};
uint8_t ftw;
uint8_t rsrv1;
uint16_t fop;
uint32_t ip;
uint16_t cs;
uint16_t rsrv2;
uint32_t dp;
uint16_t ds;
uint16_t rsrv3;
uint32_t mxcsr;
uint32_t mxcsrmask;
MMSTReg stmm0;
MMSTReg stmm1;
MMSTReg stmm2;
MMSTReg stmm3;
MMSTReg stmm4;
MMSTReg stmm5;
MMSTReg stmm6;
MMSTReg stmm7;
char xmm0[16];
char xmm1[16];
char xmm2[16];
char xmm3[16];
char xmm4[16];
char xmm5[16];
char xmm6[16];
char xmm7[16];
char xmm8[16];
char xmm9[16];
char xmm10[16];
char xmm11[16];
char xmm12[16];
char xmm13[16];
char xmm14[16];
char xmm15[16];
char reserved[6 * 16];
char ymm0[16];
char ymm1[16];
char ymm2[16];
char ymm3[16];
char ymm4[16];
char ymm5[16];
char ymm6[16];
char ymm7[16];
char ymm8[16];
char ymm9[16];
char ymm10[16];
char ymm11[16];
char ymm12[16];
char ymm13[16];
char ymm14[16];
char ymm15[16];
} FPRState;
typedef struct QBDI_ALIGNED(16) {
union {
FPControl fcw;
uint16_t rfcw;
};
union {
FPStatus fsw;
uint16_t rfsw;
};
uint8_t ftw;
uint8_t rsrv1;
uint16_t fop;
uint32_t ip;
uint16_t cs;
uint16_t rsrv2;
uint32_t dp;
uint16_t ds;
uint16_t rsrv3;
uint32_t mxcsr;
uint32_t mxcsrmask;
MMSTReg stmm0;
MMSTReg stmm1;
MMSTReg stmm2;
MMSTReg stmm3;
MMSTReg stmm4;
MMSTReg stmm5;
MMSTReg stmm6;
MMSTReg stmm7;
char xmm0[16];
char xmm1[16];
char xmm2[16];
char xmm3[16];
char xmm4[16];
char xmm5[16];
char xmm6[16];
char xmm7[16];
char xmm8[16];
char xmm9[16];
char xmm10[16];
char xmm11[16];
char xmm12[16];
char xmm13[16];
char xmm14[16];
char xmm15[16];
char reserved[6 * 16];
char ymm0[16];
char ymm1[16];
char ymm2[16];
char ymm3[16];
char ymm4[16];
char ymm5[16];
char ymm6[16];
char ymm7[16];
char ymm8[16];
char ymm9[16];
char ymm10[16];
char ymm11[16];
char ymm12[16];
char ymm13[16];
char ymm14[16];
char ymm15[16];
} FPRState;
if (!execBroker->isInstrumented(start)) {
return false;
}
if (!execBroker->isInstrumented(start)) {
return false;
}
running = true;
do {
} while (currentPC != stop);
running = true;
do {
} while (currentPC != stop);
typedef enum {
_QBDI_EI(CONTINUE) = 0,
_QBDI_EI(SKIP_INST) = 1,
_QBDI_EI(SKIP_PATCH) = 2,
_QBDI_EI(BREAK_TO_VM) = 3,
_QBDI_EI(STOP) = 4,
} VMAction;
typedef enum {
_QBDI_EI(CONTINUE) = 0,
_QBDI_EI(SKIP_INST) = 1,
_QBDI_EI(SKIP_PATCH) = 2,
_QBDI_EI(BREAK_TO_VM) = 3,
_QBDI_EI(STOP) = 4,
} VMAction;
if (execBroker->isInstrumented(currentPC) == false and
execBroker->canTransferExecution(curGPRState)){
}
else {
}
if (execBroker->isInstrumented(currentPC) == false and
execBroker->canTransferExecution(curGPRState)){
}
else {
}
typedef enum {
_QBDI_EI(NO_EVENT) = 0,
_QBDI_EI(SEQUENCE_ENTRY) = 1,
_QBDI_EI(SEQUENCE_EXIT) = 1 << 1,
_QBDI_EI(BASIC_BLOCK_ENTRY) = 1 << 2,
_QBDI_EI(BASIC_BLOCK_EXIT) = 1 << 3,
_QBDI_EI(BASIC_BLOCK_NEW) = 1 << 4,
_QBDI_EI(EXEC_TRANSFER_CALL) = 1 << 5,
_QBDI_EI(EXEC_TRANSFER_RETURN) = 1 << 6,
_QBDI_EI(SYSCALL_ENTRY) = 1 << 7,
_QBDI_EI(SYSCALL_EXIT) = 1 << 8,
_QBDI_EI(SIGNAL) = 1 << 9,
} VMEvent;
typedef enum {
_QBDI_EI(NO_EVENT) = 0,
_QBDI_EI(SEQUENCE_ENTRY) = 1,
_QBDI_EI(SEQUENCE_EXIT) = 1 << 1,
_QBDI_EI(BASIC_BLOCK_ENTRY) = 1 << 2,
_QBDI_EI(BASIC_BLOCK_EXIT) = 1 << 3,
_QBDI_EI(BASIC_BLOCK_NEW) = 1 << 4,
_QBDI_EI(EXEC_TRANSFER_CALL) = 1 << 5,
_QBDI_EI(EXEC_TRANSFER_RETURN) = 1 << 6,
_QBDI_EI(SYSCALL_ENTRY) = 1 << 7,
_QBDI_EI(SYSCALL_EXIT) = 1 << 8,
_QBDI_EI(SIGNAL) = 1 << 9,
} VMEvent;
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (changeCPUMode) {
curCPUMode = currentPC & 1 ? CPUMode::Thumb : CPUMode::ARM;
QBDI_DEBUG("CPUMode set to {}",
curCPUMode == CPUMode::ARM ? "ARM" : "Thumb");
} else if (curCPUMode == CPUMode::ARM) {
QBDI_REQUIRE_ABORT((currentPC & 1) == 0,
"Unexpected address in ARM mode");
} else {
QBDI_REQUIRE_ABORT((currentPC & 1) == 1,
"Unexpected address in Thumb mode");
}
currentPC = currentPC & (~1);
#endif
#if defined(QBDI_ARCH_ARM)
bool changeCPUMode = curExecBlock == nullptr ||
curExecBlock->getContext()->hostState.exchange == 1;
if (changeCPUMode) {
curCPUMode = currentPC & 1 ? CPUMode::Thumb : CPUMode::ARM;
QBDI_DEBUG("CPUMode set to {}",
curCPUMode == CPUMode::ARM ? "ARM" : "Thumb");
} else if (curCPUMode == CPUMode::ARM) {
QBDI_REQUIRE_ABORT((currentPC & 1) == 0,
"Unexpected address in ARM mode");
} else {
QBDI_REQUIRE_ABORT((currentPC & 1) == 1,
"Unexpected address in Thumb mode");
}
currentPC = currentPC & (~1);
#endif
if (blockManager->isFlushPending()) {
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
blockManager->flushCommit();
}
if (blockManager->isFlushPending()) {
*gprState = *curGPRState;
*fprState = *curFPRState;
curGPRState = gprState.get();
curFPRState = fprState.get();
blockManager->flushCommit();
}
bool isFlushPending() { return needFlush; }
bool isFlushPending() { return needFlush; }
void ExecBlockManager::flushCommit() {
if (needFlush) {
QBDI_DEBUG("Flushing analysis caches");
auto delFunc = [&](const ExecRegion &r) -> bool {
if (r.toFlush) {
QBDI_DEBUG("Erasing region [0x{:x}, 0x{:x}]", r.covered.start(),
r.covered.end());
for (const auto &block : r.blocks) {
codeBlockMap.erase(block->getBaseCodeBlock());
}
}
return r.toFlush;
};
regions.erase(std::remove_if(regions.begin(), regions.end(), delFunc),
regions.end());
needFlush = false;
}
}
void ExecBlockManager::flushCommit() {
if (needFlush) {
QBDI_DEBUG("Flushing analysis caches");
auto delFunc = [&](const ExecRegion &r) -> bool {
if (r.toFlush) {
QBDI_DEBUG("Erasing region [0x{:x}, 0x{:x}]", r.covered.start(),
r.covered.end());
for (const auto &block : r.blocks) {
codeBlockMap.erase(block->getBaseCodeBlock());
}
}
return r.toFlush;
};
regions.erase(std::remove_if(regions.begin(), regions.end(), delFunc),
regions.end());
needFlush = false;
}
}
class ExecRegion : public MovableDoubleLinkedListElement<ExecRegion> {
public:
Range<rword> covered;
unsigned translated = 0;
unsigned available = 0;
std::vector<std::unique_ptr<ExecBlock>> blocks;
std::map<rword, SeqLoc> sequenceCache;
std::map<rword, InstLoc> instCache;
bool toFlush = false;
std::vector<std::unique_ptr<InstCbLambda>> userInstCB;
ExecRegion(const Range<rword> &c)
: MovableDoubleLinkedListElement<ExecRegion>(), covered(c) {}
};
class ExecRegion : public MovableDoubleLinkedListElement<ExecRegion> {
public:
Range<rword> covered;
unsigned translated = 0;
unsigned available = 0;
std::vector<std::unique_ptr<ExecBlock>> blocks;
std::map<rword, SeqLoc> sequenceCache;
std::map<rword, InstLoc> instCache;
bool toFlush = false;
std::vector<std::unique_ptr<InstCbLambda>> userInstCB;
ExecRegion(const Range<rword> &c)
: MovableDoubleLinkedListElement<ExecRegion>(), covered(c) {}
};
class ExecBlock {
private:
using PF = llvm::sys::Memory::ProtectionFlags;
enum PageState { RX, RW };
VMInstanceRef vminstance;
llvm::sys::MemoryBlock codeBlock;
llvm::sys::MemoryBlock dataBlock;
unsigned codeBlockPosition;
unsigned codeBlockMaxSize;
const LLVMCPUs &llvmCPUs;
Context *context;
rword *shadows;
std::vector<ShadowInfo> shadowRegistry;
std::vector<TagInfo> tagRegistry;
uint16_t shadowIdx;
std::vector<InstMetadata> instMetadata;
std::vector<InstInfo> instRegistry;
std::vector<SeqInfo> seqRegistry;
PageState pageState;
uint16_t currentSeq;
uint16_t currentInst;
uint32_t epilogueSize;
bool isFull;
ScratchRegisterInfo srInfo;
inline bool isRX() const { return pageState == RX; }
inline bool isRW() const { return pageState == RW; }
void makeRX();
void makeRW();
void initScratchRegisterForPatch(std::vector<Patch>::const_iterator seqStart,
std::vector<Patch>::const_iterator seqEnd);
bool writePatch(std::vector<Patch>::const_iterator seqCurrent,
std::vector<Patch>::const_iterator seqEnd,
const LLVMCPU &llvmcpu);
bool writeCodeByte(const llvm::ArrayRef<char> &);
}
class ExecBlock {
private:
using PF = llvm::sys::Memory::ProtectionFlags;
enum PageState { RX, RW };
VMInstanceRef vminstance;
llvm::sys::MemoryBlock codeBlock;
llvm::sys::MemoryBlock dataBlock;
unsigned codeBlockPosition;
unsigned codeBlockMaxSize;
const LLVMCPUs &llvmCPUs;
Context *context;
rword *shadows;
std::vector<ShadowInfo> shadowRegistry;
std::vector<TagInfo> tagRegistry;
uint16_t shadowIdx;
std::vector<InstMetadata> instMetadata;
std::vector<InstInfo> instRegistry;
std::vector<SeqInfo> seqRegistry;
PageState pageState;
uint16_t currentSeq;
uint16_t currentInst;
uint32_t epilogueSize;
bool isFull;
ScratchRegisterInfo srInfo;
inline bool isRX() const { return pageState == RX; }
inline bool isRW() const { return pageState == RW; }
void makeRX();
void makeRW();
void initScratchRegisterForPatch(std::vector<Patch>::const_iterator seqStart,
std::vector<Patch>::const_iterator seqEnd);
bool writePatch(std::vector<Patch>::const_iterator seqCurrent,
std::vector<Patch>::const_iterator seqEnd,
const LLVMCPU &llvmcpu);
bool writeCodeByte(const llvm::ArrayRef<char> &);
}
ExecBlockManager::ExecBlockManager(const LLVMCPUs &llvmCPUs,
VMInstanceRef vminstance)
: total_translated_size(1), total_translation_size(1),
vminstance(vminstance), llvmCPUs(llvmCPUs),
execBlockPrologue(
getExecBlockPrologue(llvmCPUs.getCPU(CPUMode::DEFAULT))),
execBlockEpilogue(
getExecBlockEpilogue(llvmCPUs.getCPU(CPUMode::DEFAULT))) {
auto execBrokerBlock = std::make_unique<ExecBlock>(
llvmCPUs, vminstance, &execBlockPrologue, &execBlockEpilogue, 0);
epilogueSize = execBrokerBlock->getEpilogueSize();
execBroker = std::make_unique<ExecBroker>(std::move(execBrokerBlock),
llvmCPUs, vminstance);
}
ExecBlockManager::ExecBlockManager(const LLVMCPUs &llvmCPUs,
VMInstanceRef vminstance)
: total_translated_size(1), total_translation_size(1),
vminstance(vminstance), llvmCPUs(llvmCPUs),
execBlockPrologue(
getExecBlockPrologue(llvmCPUs.getCPU(CPUMode::DEFAULT))),
execBlockEpilogue(
getExecBlockEpilogue(llvmCPUs.getCPU(CPUMode::DEFAULT))) {
auto execBrokerBlock = std::make_unique<ExecBlock>(
llvmCPUs, vminstance, &execBlockPrologue, &execBlockEpilogue, 0);
epilogueSize = execBrokerBlock->getEpilogueSize();
execBroker = std::make_unique<ExecBroker>(std::move(execBrokerBlock),
llvmCPUs, vminstance);
}
SeqLoc currentSequence;
curExecBlock = blockManager->getProgrammedExecBlock(currentPC, curCPUMode,
¤tSequence);
SeqLoc currentSequence;
curExecBlock = blockManager->getProgrammedExecBlock(currentPC, curCPUMode,
¤tSequence);
typedef enum { X86_64 = 0, DEFAULT = 0, COUNT } CPUMode;
typedef enum { X86_64 = 0, DEFAULT = 0, COUNT } CPUMode;
struct SeqLoc {
uint16_t blockIdx;
uint16_t seqID;
rword bbEnd;
rword seqStart;
rword seqEnd;
};
struct SeqLoc {
uint16_t blockIdx;
uint16_t seqID;
rword bbEnd;
rword seqStart;
rword seqEnd;
};
ExecBlock *ExecBlockManager::getProgrammedExecBlock(rword address,
CPUMode cpumode,
SeqLoc *programmedSeqLock) {
QBDI_DEBUG("Looking up sequence at address {:x} mode {}", address, cpumode);
size_t r = searchRegion(address);
if (r < regions.size() && regions[r].covered.contains(address)) {
ExecRegion ®ion = regions[r];
const auto target = getExecRegionKey(address, cpumode);
const auto seqLoc = region.sequenceCache.find(target);
if (seqLoc != region.sequenceCache.end()) {
QBDI_DEBUG("Found sequence 0x{:x} ({}) in ExecBlock 0x{:x} as seqID {:x}",
address, cpumode,
reinterpret_cast<uintptr_t>(
region.blocks[seqLoc->second.blockIdx].get()),
seqLoc->second.seqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = seqLoc->second;
}
region.blocks[seqLoc->second.blockIdx]->selectSeq(seqLoc->second.seqID);
return region.blocks[seqLoc->second.blockIdx].get();
}
const auto instLoc = region.instCache.find(target);
if (instLoc != region.instCache.end()) {
ExecBlock *block = region.blocks[instLoc->second.blockIdx].get();
uint16_t existingSeqId = block->getSeqID(instLoc->second.instID);
const SeqLoc &existingSeqLoc = region.sequenceCache[getExecRegionKey(
block->getInstMetadata(block->getSeqStart(existingSeqId)).address,
cpumode)];
uint16_t newSeqID = block->splitSequence(instLoc->second.instID);
region.sequenceCache[target] = SeqLoc{
instLoc->second.blockIdx, newSeqID, existingSeqLoc.bbEnd, address,
existingSeqLoc.seqEnd,
};
QBDI_DEBUG(
"Splitted seqID {:x} at instID {:x} in ExecBlock 0x{:x} as new "
"sequence with seqID {:x}",
existingSeqId, instLoc->second.instID,
reinterpret_cast<uintptr_t>(block), newSeqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = regions[r].sequenceCache[target];
}
block->selectSeq(newSeqID);
return block;
}
}
QBDI_DEBUG("Cache miss for sequence 0x{:x} ({})", address, cpumode);
return nullptr;
}
ExecBlock *ExecBlockManager::getProgrammedExecBlock(rword address,
CPUMode cpumode,
SeqLoc *programmedSeqLock) {
QBDI_DEBUG("Looking up sequence at address {:x} mode {}", address, cpumode);
size_t r = searchRegion(address);
if (r < regions.size() && regions[r].covered.contains(address)) {
ExecRegion ®ion = regions[r];
const auto target = getExecRegionKey(address, cpumode);
const auto seqLoc = region.sequenceCache.find(target);
if (seqLoc != region.sequenceCache.end()) {
QBDI_DEBUG("Found sequence 0x{:x} ({}) in ExecBlock 0x{:x} as seqID {:x}",
address, cpumode,
reinterpret_cast<uintptr_t>(
region.blocks[seqLoc->second.blockIdx].get()),
seqLoc->second.seqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = seqLoc->second;
}
region.blocks[seqLoc->second.blockIdx]->selectSeq(seqLoc->second.seqID);
return region.blocks[seqLoc->second.blockIdx].get();
}
const auto instLoc = region.instCache.find(target);
if (instLoc != region.instCache.end()) {
ExecBlock *block = region.blocks[instLoc->second.blockIdx].get();
uint16_t existingSeqId = block->getSeqID(instLoc->second.instID);
const SeqLoc &existingSeqLoc = region.sequenceCache[getExecRegionKey(
block->getInstMetadata(block->getSeqStart(existingSeqId)).address,
cpumode)];
uint16_t newSeqID = block->splitSequence(instLoc->second.instID);
region.sequenceCache[target] = SeqLoc{
instLoc->second.blockIdx, newSeqID, existingSeqLoc.bbEnd, address,
existingSeqLoc.seqEnd,
};
QBDI_DEBUG(
"Splitted seqID {:x} at instID {:x} in ExecBlock 0x{:x} as new "
"sequence with seqID {:x}",
existingSeqId, instLoc->second.instID,
reinterpret_cast<uintptr_t>(block), newSeqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = regions[r].sequenceCache[target];
}
block->selectSeq(newSeqID);
return block;
}
}
QBDI_DEBUG("Cache miss for sequence 0x{:x} ({})", address, cpumode);
return nullptr;
}
size_t ExecBlockManager::searchRegion(rword address) const {
size_t low = 0;
size_t high = regions.size();
if (regions.size() == 0) {
return 0;
}
QBDI_DEBUG("Searching for address 0x{:x}", address);
while (low + 1 != high) {
size_t idx = (low + high) / 2;
if (regions[idx].covered.start() > address) {
high = idx;
} else if (regions[idx].covered.end() <= address) {
low = idx;
} else {
QBDI_DEBUG("Exact match for region {} [0x{:x}, 0x{:x}]", idx,
regions[idx].covered.start(), regions[idx].covered.end());
return idx;
}
}
QBDI_DEBUG("Low match for region {} [0x{:x}, 0x{:x}]", low,
regions[low].covered.start(), regions[low].covered.end());
return low;
}
size_t ExecBlockManager::searchRegion(rword address) const {
size_t low = 0;
size_t high = regions.size();
if (regions.size() == 0) {
return 0;
}
QBDI_DEBUG("Searching for address 0x{:x}", address);
while (low + 1 != high) {
size_t idx = (low + high) / 2;
if (regions[idx].covered.start() > address) {
high = idx;
} else if (regions[idx].covered.end() <= address) {
low = idx;
} else {
QBDI_DEBUG("Exact match for region {} [0x{:x}, 0x{:x}]", idx,
regions[idx].covered.start(), regions[idx].covered.end());
return idx;
}
}
QBDI_DEBUG("Low match for region {} [0x{:x}, 0x{:x}]", low,
regions[low].covered.start(), regions[low].covered.end());
return low;
}
if (r < regions.size() && regions[r].covered.contains(address)) {
ExecRegion ®ion = regions[r];
const auto target = getExecRegionKey(address, cpumode);
const auto seqLoc = region.sequenceCache.find(target);
if (seqLoc != region.sequenceCache.end()) {
QBDI_DEBUG("Found sequence 0x{:x} ({}) in ExecBlock 0x{:x} as seqID {:x}",
address, cpumode,
reinterpret_cast<uintptr_t>(region.blocks[seqLoc->second.blockIdx].get()),
seqLoc->second.seqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = seqLoc->second;
}
region.blocks[seqLoc->second.blockIdx]->selectSeq(seqLoc->second.seqID);
return region.blocks[seqLoc->second.blockIdx].get();
}
const auto instLoc = region.instCache.find(target);
if (instLoc != region.instCache.end()) {
ExecBlock *block = region.blocks[instLoc->second.blockIdx].get();
uint16_t existingSeqId = block->getSeqID(instLoc->second.instID);
const SeqLoc &existingSeqLoc = region.sequenceCache[getExecRegionKey(
block->getInstMetadata(block->getSeqStart(existingSeqId)).address,
cpumode)];
uint16_t newSeqID = block->splitSequence(instLoc->second.instID);
region.sequenceCache[target] = SeqLoc{
instLoc->second.blockIdx, newSeqID, existingSeqLoc.bbEnd, address,
existingSeqLoc.seqEnd,
};
QBDI_DEBUG(
"Splitted seqID {:x} at instID {:x} in ExecBlock 0x{:x} as new "
"sequence with seqID {:x}",
existingSeqId, instLoc->second.instID,
reinterpret_cast<uintptr_t>(block), newSeqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = regions[r].sequenceCache[target];
}
block->selectSeq(newSeqID);
return block;
}
}
if (r < regions.size() && regions[r].covered.contains(address)) {
ExecRegion ®ion = regions[r];
const auto target = getExecRegionKey(address, cpumode);
const auto seqLoc = region.sequenceCache.find(target);
if (seqLoc != region.sequenceCache.end()) {
QBDI_DEBUG("Found sequence 0x{:x} ({}) in ExecBlock 0x{:x} as seqID {:x}",
address, cpumode,
reinterpret_cast<uintptr_t>(region.blocks[seqLoc->second.blockIdx].get()),
seqLoc->second.seqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = seqLoc->second;
}
region.blocks[seqLoc->second.blockIdx]->selectSeq(seqLoc->second.seqID);
return region.blocks[seqLoc->second.blockIdx].get();
}
const auto instLoc = region.instCache.find(target);
if (instLoc != region.instCache.end()) {
ExecBlock *block = region.blocks[instLoc->second.blockIdx].get();
uint16_t existingSeqId = block->getSeqID(instLoc->second.instID);
const SeqLoc &existingSeqLoc = region.sequenceCache[getExecRegionKey(
block->getInstMetadata(block->getSeqStart(existingSeqId)).address,
cpumode)];
uint16_t newSeqID = block->splitSequence(instLoc->second.instID);
region.sequenceCache[target] = SeqLoc{
instLoc->second.blockIdx, newSeqID, existingSeqLoc.bbEnd, address,
existingSeqLoc.seqEnd,
};
QBDI_DEBUG(
"Splitted seqID {:x} at instID {:x} in ExecBlock 0x{:x} as new "
"sequence with seqID {:x}",
existingSeqId, instLoc->second.instID,
reinterpret_cast<uintptr_t>(block), newSeqID);
if (programmedSeqLock != nullptr) {
*programmedSeqLock = regions[r].sequenceCache[target];
}
block->selectSeq(newSeqID);
return block;
}
}
inline rword getExecRegionKey(rword address, CPUMode cpumode) {
if constexpr (is_arm) {
if (cpumode != CPUMode::DEFAULT) {
address |= 1;
} else {
address &= (~1);
}
}
return address;
}
inline rword getExecRegionKey(rword address, CPUMode cpumode) {
if constexpr (is_arm) {
if (cpumode != CPUMode::DEFAULT) {
address |= 1;
} else {
address &= (~1);
}
}
return address;
}
struct SeqLoc {
uint16_t blockIdx;
uint16_t seqID;
rword bbEnd;
rword seqStart;
rword seqEnd;
};
struct SeqLoc {
uint16_t blockIdx;
uint16_t seqID;
rword bbEnd;
rword seqStart;
rword seqEnd;
};
void ExecBlock::selectSeq(uint16_t seqID) {
QBDI_REQUIRE(seqID < seqRegistry.size());
currentSeq = seqID;
currentInst = seqRegistry[currentSeq].startInstID;
context->hostState.selector =
reinterpret_cast<rword>(codeBlock.base()) +
static_cast<rword>(instRegistry[currentInst].offset);
context->hostState.executeFlags = seqRegistry[currentSeq].executeFlags;
}
void ExecBlock::selectSeq(uint16_t seqID) {
QBDI_REQUIRE(seqID < seqRegistry.size());
currentSeq = seqID;
currentInst = seqRegistry[currentSeq].startInstID;
context->hostState.selector =
reinterpret_cast<rword>(codeBlock.base()) +
static_cast<rword>(instRegistry[currentInst].offset);
context->hostState.executeFlags = seqRegistry[currentSeq].executeFlags;
}
struct SeqInfo {
uint16_t startInstID;
uint16_t endInstID;
uint8_t executeFlags;
CPUMode cpuMode;
ScratchRegisterSeqInfo sr;
};
struct SeqInfo {
uint16_t startInstID;
uint16_t endInstID;
uint8_t executeFlags;
CPUMode cpuMode;
ScratchRegisterSeqInfo sr;
};
struct InstInfo {
uint16_t seqID;
uint16_t offset;
uint16_t offsetSkip;
uint16_t shadowOffset;
uint16_t shadowSize;
uint16_t tagOffset;
uint16_t tagSize;
ScratchRegisterSeqInfo sr;
};
struct InstInfo {
uint16_t seqID;
uint16_t offset;
uint16_t offsetSkip;
uint16_t shadowOffset;
uint16_t shadowSize;
uint16_t tagOffset;
uint16_t tagSize;
ScratchRegisterSeqInfo sr;
};
struct InstLoc {
uint16_t blockIdx;
uint16_t instID;
};
struct InstLoc {
uint16_t blockIdx;
uint16_t instID;
};
uint16_t ExecBlock::getSeqID(uint16_t instID) const {
QBDI_REQUIRE(instID < instRegistry.size());
return instRegistry[instID].seqID;
}
uint16_t ExecBlock::getSeqID(uint16_t instID) const {
QBDI_REQUIRE(instID < instRegistry.size());
return instRegistry[instID].seqID;
}
uint16_t ExecBlock::getSeqStart(uint16_t seqID) const {
QBDI_REQUIRE(seqID < seqRegistry.size());
return seqRegistry[seqID].startInstID;
}
uint16_t ExecBlock::getSeqStart(uint16_t seqID) const {
QBDI_REQUIRE(seqID < seqRegistry.size());
return seqRegistry[seqID].startInstID;
}
const InstMetadata &ExecBlock::getInstMetadata(uint16_t instID) const {
QBDI_REQUIRE(instID < instMetadata.size());
return instMetadata[instID];
}
const InstMetadata &ExecBlock::getInstMetadata(uint16_t instID) const {
QBDI_REQUIRE(instID < instMetadata.size());
return instMetadata[instID];
}
class InstMetadata {
public:
llvm::MCInst inst;
rword address;
uint32_t instSize;
uint32_t patchSize;
CPUMode cpuMode;
bool modifyPC;
uint8_t execblockFlags;
mutable InstAnalysisPtr analysis;
InstMetadataArch archMetadata;
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
std::vector<llvm::MCInst> prefix;
#endif
InstMetadata(const llvm::MCInst &inst, rword address, uint32_t instSize,
uint32_t patchSize, CPUMode cpuMode, bool modifyPC,
uint8_t execblockFlags, InstAnalysisPtr analysis)
: inst(inst), address(address), instSize(instSize), patchSize(patchSize),
cpuMode(cpuMode), modifyPC(modifyPC), execblockFlags(execblockFlags),
analysis(std::move(analysis)) {}
InstMetadata(const llvm::MCInst &inst, rword address, uint32_t instSize,
CPUMode cpuMode, uint8_t execblockFlags)
: inst(inst), address(address), instSize(instSize), patchSize(0),
cpuMode(cpuMode), modifyPC(false), execblockFlags(execblockFlags),
analysis(nullptr) {}
inline rword endAddress() const { return address + instSize; }
inline InstMetadata lightCopy() const {
InstMetadata cpy{inst, address, instSize, patchSize,
cpuMode, modifyPC, execblockFlags, nullptr};
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
cpy.prefix = prefix;
#endif
cpy.archMetadata = archMetadata;
return cpy;
}
};
class InstMetadata {
public:
llvm::MCInst inst;
rword address;
uint32_t instSize;
uint32_t patchSize;
CPUMode cpuMode;
bool modifyPC;
uint8_t execblockFlags;
mutable InstAnalysisPtr analysis;
InstMetadataArch archMetadata;
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
std::vector<llvm::MCInst> prefix;
#endif
InstMetadata(const llvm::MCInst &inst, rword address, uint32_t instSize,
uint32_t patchSize, CPUMode cpuMode, bool modifyPC,
uint8_t execblockFlags, InstAnalysisPtr analysis)
: inst(inst), address(address), instSize(instSize), patchSize(patchSize),
cpuMode(cpuMode), modifyPC(modifyPC), execblockFlags(execblockFlags),
analysis(std::move(analysis)) {}
InstMetadata(const llvm::MCInst &inst, rword address, uint32_t instSize,
CPUMode cpuMode, uint8_t execblockFlags)
: inst(inst), address(address), instSize(instSize), patchSize(0),
cpuMode(cpuMode), modifyPC(false), execblockFlags(execblockFlags),
analysis(nullptr) {}
inline rword endAddress() const { return address + instSize; }
inline InstMetadata lightCopy() const {
InstMetadata cpy{inst, address, instSize, patchSize,
cpuMode, modifyPC, execblockFlags, nullptr};
#if defined(QBDI_ARCH_X86_64) || defined(QBDI_ARCH_X86)
cpy.prefix = prefix;
#endif
cpy.archMetadata = archMetadata;
return cpy;
}
};
uint16_t ExecBlock::splitSequence(uint16_t instID) {
QBDI_REQUIRE(instID < instRegistry.size());
uint16_t seqID = instRegistry[instID].seqID;
seqRegistry.push_back(SeqInfo{
instID, seqRegistry[seqID].endInstID, seqRegistry[seqID].executeFlags,
seqRegistry[seqID].cpuMode, instRegistry[instID].sr});
return getNextSeqID() - 1;
}
uint16_t ExecBlock::splitSequence(uint16_t instID) {
QBDI_REQUIRE(instID < instRegistry.size());
uint16_t seqID = instRegistry[instID].seqID;
seqRegistry.push_back(SeqInfo{
instID, seqRegistry[seqID].endInstID, seqRegistry[seqID].executeFlags,
seqRegistry[seqID].cpuMode, instRegistry[instID].sr});
return getNextSeqID() - 1;
}
if (curExecBlock == nullptr) {
QBDI_DEBUG(
"Cache miss for 0x{:x}, patching & instrumenting new basic block",
currentPC);
handleNewBasicBlock(currentPC);
event |= BASIC_BLOCK_NEW;
curExecBlock = blockManager->getProgrammedExecBlock(
currentPC, curCPUMode, ¤tSequence);
QBDI_REQUIRE_ABORT(curExecBlock != nullptr,
"Fail to instrument the next basic block");
}
if (curExecBlock == nullptr) {
QBDI_DEBUG(
"Cache miss for 0x{:x}, patching & instrumenting new basic block",
currentPC);
handleNewBasicBlock(currentPC);
event |= BASIC_BLOCK_NEW;
curExecBlock = blockManager->getProgrammedExecBlock(
currentPC, curCPUMode, ¤tSequence);
QBDI_REQUIRE_ABORT(curExecBlock != nullptr,
"Fail to instrument the next basic block");
}
void Engine::handleNewBasicBlock(rword pc) {
Patch::Vec basicBlock = patch(pc);
size_t patchEnd = blockManager->preWriteBasicBlock(basicBlock);
instrument(basicBlock, patchEnd);
blockManager->writeBasicBlock(std::move(basicBlock), patchEnd);
}
void Engine::handleNewBasicBlock(rword pc) {
Patch::Vec basicBlock = patch(pc);
size_t patchEnd = blockManager->preWriteBasicBlock(basicBlock);
instrument(basicBlock, patchEnd);
blockManager->writeBasicBlock(std::move(basicBlock), patchEnd);
}
std::vector<Patch> Engine::patch(rword start) {
std::vector<Patch> basicBlock;
const LLVMCPU &llvmcpu = llvmCPUs->getCPU(curCPUMode);
size_t sizeCode = (size_t)-1;
const Range<rword> *curRange =
execBroker->getInstrumentedRange().getElementRange(start);
if (curRange != nullptr) {
sizeCode = curRange->end() - start;
}
const llvm::ArrayRef<uint8_t> code((uint8_t *)start, sizeCode);
rword address = start;
QBDI_DEBUG("Patching basic block at address 0x{:x}", start);
bool endLoop = false;
do {
llvm::MCInst inst;
uint64_t instSize;
bool dstatus = llvmcpu.getInstruction(inst, instSize,
code.slice(address - start), address);
if (not dstatus) {
QBDI_DEBUG("Bump into invalid instruction at address {:x}", address);
bool rollbackOK = patchRuleAssembly->earlyEnd(llvmcpu, basicBlock);
if ((not rollbackOK) or (basicBlock.size() == 0)) {
size_t sizeDump = start + sizeCode - address;
if (sizeDump > 16) {
sizeDump = 16;
}
QBDI_ABORT(
"Disassembly error : fail to parse address 0x{:x} (CPUMode {}) "
"({:n})",
address, curCPUMode,
spdlog::to_hex(reinterpret_cast<uint8_t *>(address),
reinterpret_cast<uint8_t *>(address + sizeDump)));
} else {
endLoop = true;
break;
}
}
QBDI_DEBUG("Disassembly address 0x{:x} ({:n})", address,
spdlog::to_hex(reinterpret_cast<uint8_t *>(address),
reinterpret_cast<uint8_t *>(address + instSize)));
QBDI_REQUIRE_ABORT(dstatus, "Unexpected disassembly status");
QBDI_DEBUG_BLOCK({
std::string disass = llvmcpu.showInst(inst, address);
QBDI_DEBUG("Patching 0x{:x} {}", address, disass.c_str());
});
endLoop = not patchRuleAssembly->generate(inst, address, instSize, llvmcpu,
basicBlock);
address += instSize;
} while (endLoop);
QBDI_REQUIRE_ABORT(basicBlock.size() > 0,
"No instruction to disassemble found");
QBDI_DEBUG("Basic block starting at address 0x{:x} ended at address 0x{:x}",
start, basicBlock.back().metadata.endAddress());
return basicBlock;
}
std::vector<Patch> Engine::patch(rword start) {
std::vector<Patch> basicBlock;
const LLVMCPU &llvmcpu = llvmCPUs->getCPU(curCPUMode);
size_t sizeCode = (size_t)-1;
const Range<rword> *curRange =
execBroker->getInstrumentedRange().getElementRange(start);
if (curRange != nullptr) {
sizeCode = curRange->end() - start;
}
const llvm::ArrayRef<uint8_t> code((uint8_t *)start, sizeCode);
rword address = start;
QBDI_DEBUG("Patching basic block at address 0x{:x}", start);
bool endLoop = false;
do {
llvm::MCInst inst;
uint64_t instSize;
bool dstatus = llvmcpu.getInstruction(inst, instSize,
code.slice(address - start), address);
if (not dstatus) {
QBDI_DEBUG("Bump into invalid instruction at address {:x}", address);
bool rollbackOK = patchRuleAssembly->earlyEnd(llvmcpu, basicBlock);
if ((not rollbackOK) or (basicBlock.size() == 0)) {
size_t sizeDump = start + sizeCode - address;
if (sizeDump > 16) {
sizeDump = 16;
}
QBDI_ABORT(
"Disassembly error : fail to parse address 0x{:x} (CPUMode {}) "
"({:n})",
address, curCPUMode,
spdlog::to_hex(reinterpret_cast<uint8_t *>(address),
reinterpret_cast<uint8_t *>(address + sizeDump)));
} else {
endLoop = true;
break;
}
}
QBDI_DEBUG("Disassembly address 0x{:x} ({:n})", address,
spdlog::to_hex(reinterpret_cast<uint8_t *>(address),
reinterpret_cast<uint8_t *>(address + instSize)));
QBDI_REQUIRE_ABORT(dstatus, "Unexpected disassembly status");
QBDI_DEBUG_BLOCK({
std::string disass = llvmcpu.showInst(inst, address);
QBDI_DEBUG("Patching 0x{:x} {}", address, disass.c_str());
});
endLoop = not patchRuleAssembly->generate(inst, address, instSize, llvmcpu,
basicBlock);
address += instSize;
} while (endLoop);
QBDI_REQUIRE_ABORT(basicBlock.size() > 0,
"No instruction to disassemble found");
QBDI_DEBUG("Basic block starting at address 0x{:x} ended at address 0x{:x}",
start, basicBlock.back().metadata.endAddress());
return basicBlock;
}
const RangeSet<rword> &getInstrumentedRange() const { return instrumented; }
const RangeSet<rword> &getInstrumentedRange() const { return instrumented; }
const Range<T> *getElementRange(const T &t) const {
auto lower = std::lower_bound(
ranges.cbegin(), ranges.cend(), t,
[](const Range<T> &r, const T &value) { return r.end() <= value; });
if (lower == ranges.cend() || (!lower->contains(t))) {
return nullptr;
} else {
return &*lower;
}
}
const Range<T> *getElementRange(const T &t) const {
auto lower = std::lower_bound(
ranges.cbegin(), ranges.cend(), t,
[](const Range<T> &r, const T &value) { return r.end() <= value; });
if (lower == ranges.cend() || (!lower->contains(t))) {
return nullptr;
} else {
return &*lower;
}
}
bool LLVMCPU::getInstruction(llvm::MCInst &instr, uint64_t &size,
llvm::ArrayRef<uint8_t> bytes,
uint64_t address) const {
auto status =
disassembler->getInstruction(instr, size, bytes, address, llvm::nulls());
if (status == llvm::MCDisassembler::SoftFail) {
std::string dissas = showInst(instr, address);
QBDI_WARN("Disassembly softfail on 0x{:x} : {} (CPUMode {}) ({:n})",
address, dissas, getCPUMode(),
spdlog::to_hex(bytes.data(), bytes.data() + size));
}
return status != llvm::MCDisassembler::Fail;
}
bool LLVMCPU::getInstruction(llvm::MCInst &instr, uint64_t &size,
llvm::ArrayRef<uint8_t> bytes,
uint64_t address) const {
auto status =
disassembler->getInstruction(instr, size, bytes, address, llvm::nulls());
if (status == llvm::MCDisassembler::SoftFail) {
std::string dissas = showInst(instr, address);
QBDI_WARN("Disassembly softfail on 0x{:x} : {} (CPUMode {}) ({:n})",
address, dissas, getCPUMode(),
spdlog::to_hex(bytes.data(), bytes.data() + size));
}
return status != llvm::MCDisassembler::Fail;
}
class LLVMCPU {
private:
std::string tripleName;
std::string cpu;
std::string arch;
std::vector<std::string> mattrs;
const llvm::Target *target;
Options options;
CPUMode cpumode;
std::unique_ptr<llvm::MCAsmInfo> MAI;
std::unique_ptr<llvm::MCContext> MCTX;
std::unique_ptr<llvm::MCInstrInfo> MCII;
std::unique_ptr<llvm::MCObjectFileInfo> MOFI;
std::unique_ptr<llvm::MCRegisterInfo> MRI;
std::unique_ptr<llvm::MCSubtargetInfo> MSTI;
std::unique_ptr<llvm::MCAssembler> assembler;
std::unique_ptr<llvm::MCDisassembler> disassembler;
std::unique_ptr<llvm::MCInstPrinter> asmPrinter;
std::unique_ptr<llvm::raw_pwrite_stream> null_ostream;
}
class LLVMCPU {
private:
std::string tripleName;
std::string cpu;
std::string arch;
std::vector<std::string> mattrs;
const llvm::Target *target;
Options options;
CPUMode cpumode;
std::unique_ptr<llvm::MCAsmInfo> MAI;
std::unique_ptr<llvm::MCContext> MCTX;
std::unique_ptr<llvm::MCInstrInfo> MCII;
std::unique_ptr<llvm::MCObjectFileInfo> MOFI;
std::unique_ptr<llvm::MCRegisterInfo> MRI;
std::unique_ptr<llvm::MCSubtargetInfo> MSTI;
std::unique_ptr<llvm::MCAssembler> assembler;
std::unique_ptr<llvm::MCDisassembler> disassembler;
std::unique_ptr<llvm::MCInstPrinter> asmPrinter;
std::unique_ptr<llvm::raw_pwrite_stream> null_ostream;
}
virtual DecodeStatus getInstruction(MCInst &Instr, uint64_t &Size,
ArrayRef<uint8_t> Bytes, uint64_t Address,
raw_ostream &CStream) const = 0;
virtual DecodeStatus getInstruction(MCInst &Instr, uint64_t &Size,
ArrayRef<uint8_t> Bytes, uint64_t Address,
raw_ostream &CStream) const = 0;
std::string LLVMCPU::showInst(const llvm::MCInst &inst, rword address) const {
std::string out;
llvm::raw_string_ostream rso(out);
llvm::StringRef unusedAnnotations;
asmPrinter->printInst(&inst, address, unusedAnnotations, *MSTI, rso);
rso.flush();
return out;
}
std::string LLVMCPU::showInst(const llvm::MCInst &inst, rword address) const {
std::string out;
llvm::raw_string_ostream rso(out);
llvm::StringRef unusedAnnotations;
asmPrinter->printInst(&inst, address, unusedAnnotations, *MSTI, rso);
rso.flush();
return out;
}
virtual void printInst(const MCInst *MI, uint64_t Address, StringRef Annot,
const MCSubtargetInfo &STI, raw_ostream &OS) = 0;
virtual void printInst(const MCInst *MI, uint64_t Address, StringRef Annot,
const MCSubtargetInfo &STI, raw_ostream &OS) = 0;
bool PatchRuleAssembly::generate(const llvm::MCInst &inst, rword address,
uint32_t instSize, const LLVMCPU &llvmcpu,
std::vector<Patch> &patchList) {
Patch instPatch{inst, address, instSize, llvmcpu};
setRegisterSaved(instPatch);
for (uint32_t j = 0; j < patchRules.size(); j++) {
if (patchRules[j].canBeApplied(instPatch, llvmcpu)) {
QBDI_DEBUG("Patch rule {} applied", j);
if (mergePending) {
QBDI_REQUIRE_ABORT(patchList.size() > 0, "No previous patch to merge");
QBDI_DEBUG("Previous instruction merged");
patchRules[j].apply(instPatch, llvmcpu);
int position = -1;
for (auto &p : instPatch.patchGenFlags) {
if (p.second == PatchGeneratorFlags::ModifyInstructionBeginFlags) {
position = p.first;
break;
}
}
QBDI_REQUIRE_ABORT(
position != -1,
"Fail to get the position to insert the new patch {}", instPatch);
Patch &mergePatch = patchList.back();
instPatch.insertAt(position, std::move(mergePatch.insts));
instPatch.metadata.address = mergePatch.metadata.address;
instPatch.metadata.instSize += mergePatch.metadata.instSize;
instPatch.metadata.execblockFlags |= mergePatch.metadata.execblockFlags;
instPatch.metadata.prefix = mergePatch.metadata.prefix;
instPatch.metadata.prefix.push_back(mergePatch.metadata.inst);
mergePatch = std::move(instPatch);
} else {
patchRules[j].apply(instPatch, llvmcpu);
patchList.push_back(std::move(instPatch));
}
Patch &patch = patchList.back();
mergePending = false;
for (auto &p : patch.patchGenFlags) {
mergePending |= (p.second == PatchGeneratorFlagsX86_64::MergeFlag);
}
if (mergePending) {
return false;
} else if (patch.metadata.modifyPC) {
reset();
return true;
} else {
return false;
}
}
}
QBDI_ABORT("Not PatchRule found for: {}", instPatch);
}
static void setRegisterSaved(Patch &patch) {
if constexpr (is_x86) {
switch (patch.metadata.inst.getOpcode()) {
case llvm::X86::PUSHA16:
case llvm::X86::PUSHA32:
case llvm::X86::POPA16:
case llvm::X86::POPA32:
for (unsigned i = 0; i < AVAILABLE_GPR; i++) {
patch.regUsage[i] |= RegisterUsage::RegisterSaved;
}
break;
default:
break;
}
}
return;
}
bool PatchRuleAssembly::generate(const llvm::MCInst &inst, rword address,
uint32_t instSize, const LLVMCPU &llvmcpu,
std::vector<Patch> &patchList) {
Patch instPatch{inst, address, instSize, llvmcpu};
setRegisterSaved(instPatch);
for (uint32_t j = 0; j < patchRules.size(); j++) {
if (patchRules[j].canBeApplied(instPatch, llvmcpu)) {
QBDI_DEBUG("Patch rule {} applied", j);
if (mergePending) {
QBDI_REQUIRE_ABORT(patchList.size() > 0, "No previous patch to merge");
QBDI_DEBUG("Previous instruction merged");
patchRules[j].apply(instPatch, llvmcpu);
int position = -1;
for (auto &p : instPatch.patchGenFlags) {
if (p.second == PatchGeneratorFlags::ModifyInstructionBeginFlags) {
position = p.first;
break;
}
}
QBDI_REQUIRE_ABORT(
position != -1,
"Fail to get the position to insert the new patch {}", instPatch);
Patch &mergePatch = patchList.back();
instPatch.insertAt(position, std::move(mergePatch.insts));
instPatch.metadata.address = mergePatch.metadata.address;
instPatch.metadata.instSize += mergePatch.metadata.instSize;
instPatch.metadata.execblockFlags |= mergePatch.metadata.execblockFlags;
instPatch.metadata.prefix = mergePatch.metadata.prefix;
instPatch.metadata.prefix.push_back(mergePatch.metadata.inst);
mergePatch = std::move(instPatch);
} else {
patchRules[j].apply(instPatch, llvmcpu);
patchList.push_back(std::move(instPatch));
}
Patch &patch = patchList.back();
mergePending = false;
for (auto &p : patch.patchGenFlags) {
mergePending |= (p.second == PatchGeneratorFlagsX86_64::MergeFlag);
}
if (mergePending) {
return false;
} else if (patch.metadata.modifyPC) {
reset();
return true;
} else {
return false;
}
}
}
QBDI_ABORT("Not PatchRule found for: {}", instPatch);
}
static void setRegisterSaved(Patch &patch) {
if constexpr (is_x86) {
switch (patch.metadata.inst.getOpcode()) {
case llvm::X86::PUSHA16:
case llvm::X86::PUSHA32:
case llvm::X86::POPA16:
case llvm::X86::POPA32:
for (unsigned i = 0; i < AVAILABLE_GPR; i++) {
patch.regUsage[i] |= RegisterUsage::RegisterSaved;
}
break;
default:
break;
}
}
return;
}
PatchRuleAssembly::PatchRuleAssembly(Options opts)
: patchRules(getDefaultPatchRules(opts)), options(opts),
mergePending(false) {}
PatchRuleAssembly::PatchRuleAssembly(Options opts)
: patchRules(getDefaultPatchRules(opts)), options(opts),
mergePending(false) {}
std::vector<PatchRule> getDefaultPatchRules(Options opts) {
std::vector<PatchRule> rules;
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::LOCK_PREFIX),
OpIs::unique(llvm::X86::REX64_PREFIX),
OpIs::unique(llvm::X86::REP_PREFIX),
OpIs::unique(llvm::X86::REPNE_PREFIX),
OpIs::unique(llvm::X86::DATA16_PREFIX),
OpIs::unique(llvm::X86::CS_PREFIX),
OpIs::unique(llvm::X86::SS_PREFIX),
OpIs::unique(llvm::X86::DS_PREFIX),
OpIs::unique(llvm::X86::ES_PREFIX),
OpIs::unique(llvm::X86::FS_PREFIX),
OpIs::unique(llvm::X86::GS_PREFIX),
OpIs::unique(llvm::X86::XACQUIRE_PREFIX),
OpIs::unique(llvm::X86::XRELEASE_PREFIX))),
conv_unique<PatchGenerator>(
PatchGenFlags::unique(PatchGeneratorFlagsX86_64::MergeFlag),
ModifyInstruction::unique(InstTransform::UniquePtrVec())));
rules.emplace_back(
And::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP64m),
UseReg::unique(Reg(REG_PC)))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0)),
SetOpcode::unique(llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(1)))),
WriteTemp::unique(Temp(1), Offset(Reg(REG_PC)))));
rules.emplace_back(
And::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL64m),
UseReg::unique(Reg(REG_PC)))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0)),
SetOpcode::unique(llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(1)))),
SimulateCall::unique(Temp(1))));
rules.emplace_back(
UseReg::unique(Reg(REG_PC)),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0))))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP32m),
OpIs::unique(llvm::X86::JMP64m))),
conv_unique<PatchGenerator>(
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOpcode::unique(is_x86 ? llvm::X86::MOV32rm
: llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(0)))),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL32m),
OpIs::unique(llvm::X86::CALL64m))),
conv_unique<PatchGenerator>(
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOpcode::unique(is_x86 ? llvm::X86::MOV32rm
: llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(0)))),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP_1),
OpIs::unique(llvm::X86::JMP_2),
OpIs::unique(llvm::X86::JMP_4))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP32r),
OpIs::unique(llvm::X86::JMP64r))),
conv_unique<PatchGenerator>(
GetOperand::unique(Temp(0), Operand(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL32r),
OpIs::unique(llvm::X86::CALL64r))),
conv_unique<PatchGenerator>(GetOperand::unique(Temp(0), Operand(0)),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::JCC_1), OpIs::unique(llvm::X86::LOOP),
OpIs::unique(llvm::X86::LOOPE), OpIs::unique(llvm::X86::LOOPNE),
OpIs::unique(llvm::X86::JRCXZ), OpIs::unique(llvm::X86::JECXZ),
OpIs::unique(llvm::X86::JCXZ))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(
conv_unique<InstTransform>(SetOperand::unique(
Operand(0),
Constant(is_x86 ? 6 : 11))
)),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
OpIs::unique(llvm::X86::JCC_2),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOperand::unique(Operand(0), Constant(is_x86 ? 7 : 12)))),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
OpIs::unique(llvm::X86::JCC_4),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOperand::unique(Operand(0), Constant(is_x86 ? 9 : 14)))),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(
conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL64pcrel32),
OpIs::unique(llvm::X86::CALLpcrel16),
OpIs::unique(llvm::X86::CALLpcrel32))),
conv_unique<PatchGenerator>(GetPCOffset::unique(Temp(0), Operand(0)),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::RET32), OpIs::unique(llvm::X86::RET64),
OpIs::unique(llvm::X86::RET16), OpIs::unique(llvm::X86::RETI32),
OpIs::unique(llvm::X86::RETI64), OpIs::unique(llvm::X86::RETI16))),
conv_unique<PatchGenerator>(SimulateRet::unique(Temp(0))));
rules.emplace_back(True::unique(),
conv_unique<PatchGenerator>(ModifyInstruction::unique(
InstTransform::UniquePtrVec())));
return rules;
}
std::vector<PatchRule> getDefaultPatchRules(Options opts) {
std::vector<PatchRule> rules;
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::LOCK_PREFIX),
OpIs::unique(llvm::X86::REX64_PREFIX),
OpIs::unique(llvm::X86::REP_PREFIX),
OpIs::unique(llvm::X86::REPNE_PREFIX),
OpIs::unique(llvm::X86::DATA16_PREFIX),
OpIs::unique(llvm::X86::CS_PREFIX),
OpIs::unique(llvm::X86::SS_PREFIX),
OpIs::unique(llvm::X86::DS_PREFIX),
OpIs::unique(llvm::X86::ES_PREFIX),
OpIs::unique(llvm::X86::FS_PREFIX),
OpIs::unique(llvm::X86::GS_PREFIX),
OpIs::unique(llvm::X86::XACQUIRE_PREFIX),
OpIs::unique(llvm::X86::XRELEASE_PREFIX))),
conv_unique<PatchGenerator>(
PatchGenFlags::unique(PatchGeneratorFlagsX86_64::MergeFlag),
ModifyInstruction::unique(InstTransform::UniquePtrVec())));
rules.emplace_back(
And::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP64m),
UseReg::unique(Reg(REG_PC)))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0)),
SetOpcode::unique(llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(1)))),
WriteTemp::unique(Temp(1), Offset(Reg(REG_PC)))));
rules.emplace_back(
And::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL64m),
UseReg::unique(Reg(REG_PC)))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0)),
SetOpcode::unique(llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(1)))),
SimulateCall::unique(Temp(1))));
rules.emplace_back(
UseReg::unique(Reg(REG_PC)),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Constant(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SubstituteWithTemp::unique(Reg(REG_PC), Temp(0))))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP32m),
OpIs::unique(llvm::X86::JMP64m))),
conv_unique<PatchGenerator>(
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOpcode::unique(is_x86 ? llvm::X86::MOV32rm
: llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(0)))),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL32m),
OpIs::unique(llvm::X86::CALL64m))),
conv_unique<PatchGenerator>(
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOpcode::unique(is_x86 ? llvm::X86::MOV32rm
: llvm::X86::MOV64rm),
AddOperand::unique(Operand(0), Temp(0)))),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP_1),
OpIs::unique(llvm::X86::JMP_2),
OpIs::unique(llvm::X86::JMP_4))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::JMP32r),
OpIs::unique(llvm::X86::JMP64r))),
conv_unique<PatchGenerator>(
GetOperand::unique(Temp(0), Operand(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL32r),
OpIs::unique(llvm::X86::CALL64r))),
conv_unique<PatchGenerator>(GetOperand::unique(Temp(0), Operand(0)),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::JCC_1), OpIs::unique(llvm::X86::LOOP),
OpIs::unique(llvm::X86::LOOPE), OpIs::unique(llvm::X86::LOOPNE),
OpIs::unique(llvm::X86::JRCXZ), OpIs::unique(llvm::X86::JECXZ),
OpIs::unique(llvm::X86::JCXZ))),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(
conv_unique<InstTransform>(SetOperand::unique(
Operand(0),
Constant(is_x86 ? 6 : 11))
)),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
OpIs::unique(llvm::X86::JCC_2),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOperand::unique(Operand(0), Constant(is_x86 ? 7 : 12)))),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
OpIs::unique(llvm::X86::JCC_4),
conv_unique<PatchGenerator>(
GetPCOffset::unique(Temp(0), Operand(0)),
ModifyInstruction::unique(conv_unique<InstTransform>(
SetOperand::unique(Operand(0), Constant(is_x86 ? 9 : 14)))),
GetPCOffset::unique(Temp(0), Constant(0)),
WriteTemp::unique(Temp(0), Offset(Reg(REG_PC)))));
rules.emplace_back(
Or::unique(
conv_unique<PatchCondition>(OpIs::unique(llvm::X86::CALL64pcrel32),
OpIs::unique(llvm::X86::CALLpcrel16),
OpIs::unique(llvm::X86::CALLpcrel32))),
conv_unique<PatchGenerator>(GetPCOffset::unique(Temp(0), Operand(0)),
SimulateCall::unique(Temp(0))));
rules.emplace_back(
Or::unique(conv_unique<PatchCondition>(
OpIs::unique(llvm::X86::RET32), OpIs::unique(llvm::X86::RET64),
OpIs::unique(llvm::X86::RET16), OpIs::unique(llvm::X86::RETI32),
OpIs::unique(llvm::X86::RETI64), OpIs::unique(llvm::X86::RETI16))),
conv_unique<PatchGenerator>(SimulateRet::unique(Temp(0))));
rules.emplace_back(True::unique(),
conv_unique<PatchGenerator>(ModifyInstruction::unique(
InstTransform::UniquePtrVec())));
return rules;
}
class PatchRule {
std::unique_ptr<PatchCondition> condition;
std::vector<std::unique_ptr<PatchGenerator>> generators;
public:
PatchRule(std::unique_ptr<PatchCondition> &&condition,
std::vector<std::unique_ptr<PatchGenerator>> &&generators);
PatchRule(PatchRule &&);
~PatchRule();
bool canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const;
void apply(Patch &patch, const LLVMCPU &llvmcpu) const;
};
class PatchRule {
std::unique_ptr<PatchCondition> condition;
std::vector<std::unique_ptr<PatchGenerator>> generators;
public:
PatchRule(std::unique_ptr<PatchCondition> &&condition,
std::vector<std::unique_ptr<PatchGenerator>> &&generators);
PatchRule(PatchRule &&);
~PatchRule();
bool canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const;
void apply(Patch &patch, const LLVMCPU &llvmcpu) const;
};
bool PatchRule::canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const {
return condition->test(patch, llvmcpu);
}
bool PatchRule::canBeApplied(const Patch &patch, const LLVMCPU &llvmcpu) const {
return condition->test(patch, llvmcpu);
}
template <class T, class... Args>
inline std::vector<std::unique_ptr<T>> conv_unique(Args... args) {
std::vector<std::unique_ptr<T>> vec;
_conv_unique<T>(vec, std::forward<Args>(args)...);
return vec;
}
template <class T>
inline void _conv_unique(std::vector<std::unique_ptr<T>> &vec,
std::unique_ptr<T> &&u) {
vec.push_back(std::forward<std::unique_ptr<T>>(u));
}
template <class T, class... Args>
inline void _conv_unique(std::vector<std::unique_ptr<T>> &vec,
std::unique_ptr<T> &&u, Args... args) {
vec.push_back(std::forward<std::unique_ptr<T>>(u));
_conv_unique<T>(vec, std::forward<Args>(args)...);
}
template <class T, class... Args>
inline std::vector<std::unique_ptr<T>> conv_unique(Args... args) {
std::vector<std::unique_ptr<T>> vec;
_conv_unique<T>(vec, std::forward<Args>(args)...);
return vec;
}
template <class T>
inline void _conv_unique(std::vector<std::unique_ptr<T>> &vec,
std::unique_ptr<T> &&u) {
vec.push_back(std::forward<std::unique_ptr<T>>(u));
}
template <class T, class... Args>
inline void _conv_unique(std::vector<std::unique_ptr<T>> &vec,
std::unique_ptr<T> &&u, Args... args) {
vec.push_back(std::forward<std::unique_ptr<T>>(u));
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2025-7-22 09:48
被nothing233编辑
,原因:









