近期学习DEX文件结构为学习APP加壳脱壳打基础,自实现了一个简易的DEX解析器加深理解
DEX文件结构整体看不复杂,深究时发现DexCLassDef结构非常复杂,编码的数据结构,嵌套和指向关系
本文作为近期学习的一个阶段总结以及知识分享,后期再完善Todo部分
由于本人水平有限,文章错漏之处还望大佬批评指正
环境&工具:
010editor 15.0.1 (13.0.1有bug,打开大文件分析时容易崩溃)
Clion 2024.2.3
JDK 11.0.23
MinGW 14.2.0
Android Studio
自行编译dex文件供后续分析
可能遇到报错如下,这是因为d8需要java11+的环境,不支持java8
Android源码 b27K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3q4F1k6s2u0G2K9h3c8^5M7X3g2X3i4K6u0W2j5$3!0E0i4K6u0r3x3W2)9J5k6e0y4Q4x3X3f1%4i4K6u0r3P5s2u0W2k6W2)9J5c8X3c8S2L8s2k6A6K9#2)9J5c8X3I4A6j5X3c8W2P5q4)9J5c8V1c8W2P5p5k6A6L8r3g2Q4x3X3g2Z5
sleb128、uleb128、uleb128p1是Dex文件中特有的LEB128类型.在下述Android源码位置可以找到LEB128的实现.009K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3q4F1k6s2u0G2K9h3c8^5M7X3g2X3i4K6u0W2j5$3!0E0i4K6u0r3x3W2)9J5k6e0y4Q4x3X3f1%4i4K6u0r3P5s2u0W2k6W2)9J5c8X3c8S2L8s2k6A6K9#2)9J5c8X3I4A6j5X3c8W2P5q4)9J5c8V1I4W2j5U0p5J5z5q4)9J5k6h3R3`.
每个LEB128由1-5字节组成,所有字节组合在一起表示一个32位的数据, 每个字节只有低7位为有效位,最高位标识是否需要使用额外字节
如果第1个字节的最高位为1,表示LEB128需要使用第2个字节,如果第2个字节的最高位为1,表示会使用第3个字节,依次类推,直到最后一个字节的最高位为0
uleb128读取代码如下
值得注意的是参数为二级指针,也就是说,调用该函数时会移动一级指针,一级指针的偏移量即为读取到的uleb128的大小
为方便使用自定义了myReadUnsignedLeb128函数,参数为一级指针,返回读取的数据及其大小
参考Android官方文档f04K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6K6L8%4g2J5j5$3g2Q4x3X3g2S2L8X3c8J5L8$3W2V1i4K6u0W2j5$3!0E0i4K6u0r3k6r3!0U0M7#2)9J5c8X3y4G2M7X3g2Q4x3V1k6V1j5h3I4$3K9h3E0Q4x3V1k6V1k6i4S2Q4x3X3c8X3L8%4u0E0j5i4c8Q4x3@1k6Z5L8q4)9K6c8s2A6Z5i4K6u0V1j5$3&6Q4x3U0y4W2L8X3y4G2k6r3W2F1k6H3`.`.
解析代码参考以下文档,只找到了java代码
cdaK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3q4F1k6s2u0G2K9h3c8^5M7X3g2X3i4K6u0W2j5$3!0E0i4K6u0r3x3W2)9J5k6e0y4Q4x3X3f1%4i4K6u0r3P5s2u0W2k6W2)9J5c8X3y4@1M7#2)9J5c8Y4c8G2L8$3I4K6i4K6u0r3k6r3g2^5i4K6u0V1N6r3!0G2L8s2y4Q4x3V1k6K6M7X3y4Q4x3V1k6V1k6i4S2Q4x3V1k6J5k6h3q4V1k6i4u0Q4x3V1k6p5k6i4S2q4L8X3y4G2k6r3g2V1g2X3q4D9N6h3g2u0L8i4m8D9i4K6u0W2K9X3q4$3j5b7`.`.
a7dK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3q4F1k6s2u0G2K9h3c8^5M7X3g2X3i4K6u0W2j5$3!0E0i4K6u0r3x3W2)9J5k6e0y4Q4x3X3f1%4i4K6u0r3P5s2u0W2k6W2)9J5c8X3c8S2L8s2k6A6K9#2)9J5c8X3c8^5i4K6u0r3M7%4u0U0i4K6u0r3j5$3!0E0i4K6u0r3j5h3&6V1M7X3!0A6k6q4)9J5c8X3c8^5i4K6u0r3k6r3g2^5i4K6u0r3k6X3W2D9k6g2)9J5c8W2k6S2L8s2g2W2c8h3&6U0L8$3c8W2M7W2)9J5k6h3A6S2N6X3p5`.
解析DexClassDef结构时,Annotation的annotation_element和encoded_array_item会使用该编码
编码格式如下,1字节的头用于指定value格式和大小,后续紧跟数据,需要根据类型解析
value_type枚举定义如下
解析代码如下(该函数在解析DexClassDef的Annotation时才会使用,可先忽略 )
parseEncodedValue函数会自动读取单个encoded_value并返回解析后的字符串(类型:值 的键值对形式)以及value占用的真实字节数
由于encoded_array.values数组元素为encoded_value,所以每个元素的大小不固定,不能当作一般的数组解析
该类型主要在DexClassDef的Annotations部分使用,此处仅做介绍
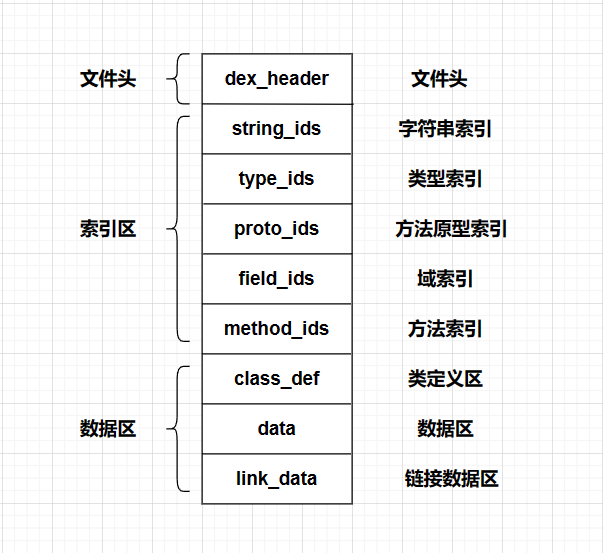
dex文件整体结构分为: dex文件头, 索引结构区, data数据区, 示意图如下:
dex文件头
保存了dex文件的基本信息, 例如文件大小,dex头大小,大小端序,索引表的起始地址和大小等
索引结构区
这部分保存了字符串表,类型表,方法原型表,域表,方法表等结构
根据这些表和索引可以访问到对应数据
data数据区
所有的代码和数据存放在该区域
dex文件结构体的定义在Android源码目录/dalvik/libdex/DexFile.h中可以找到,其中定义的dex文件结构体如下:
为方便使用仅保留部分字段,编写相关函数如下
通过字节buffer或文件路径创建DexFile类并初始化各个字段
DexHeader定义如下
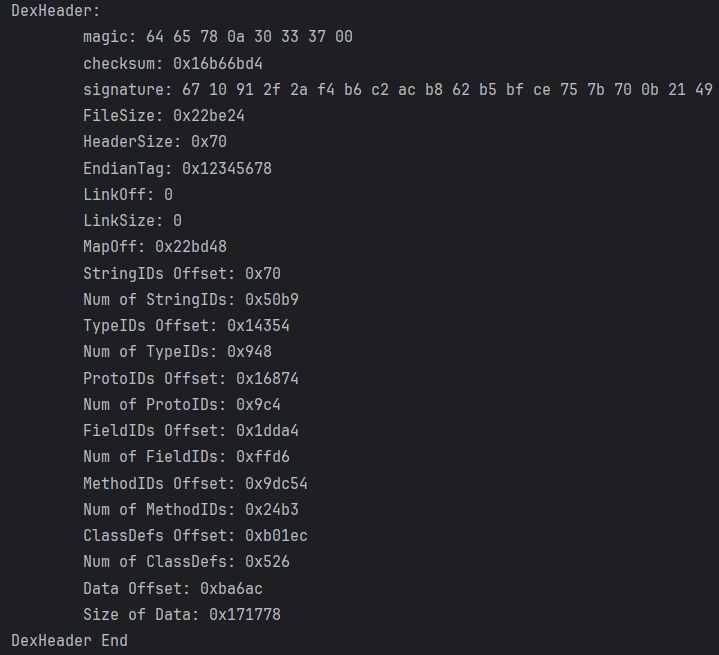
打印DexHeader
效果如下
定义如下
注意dex文件的字符串采用MUTF-8编码,与UTF-8区别如下:
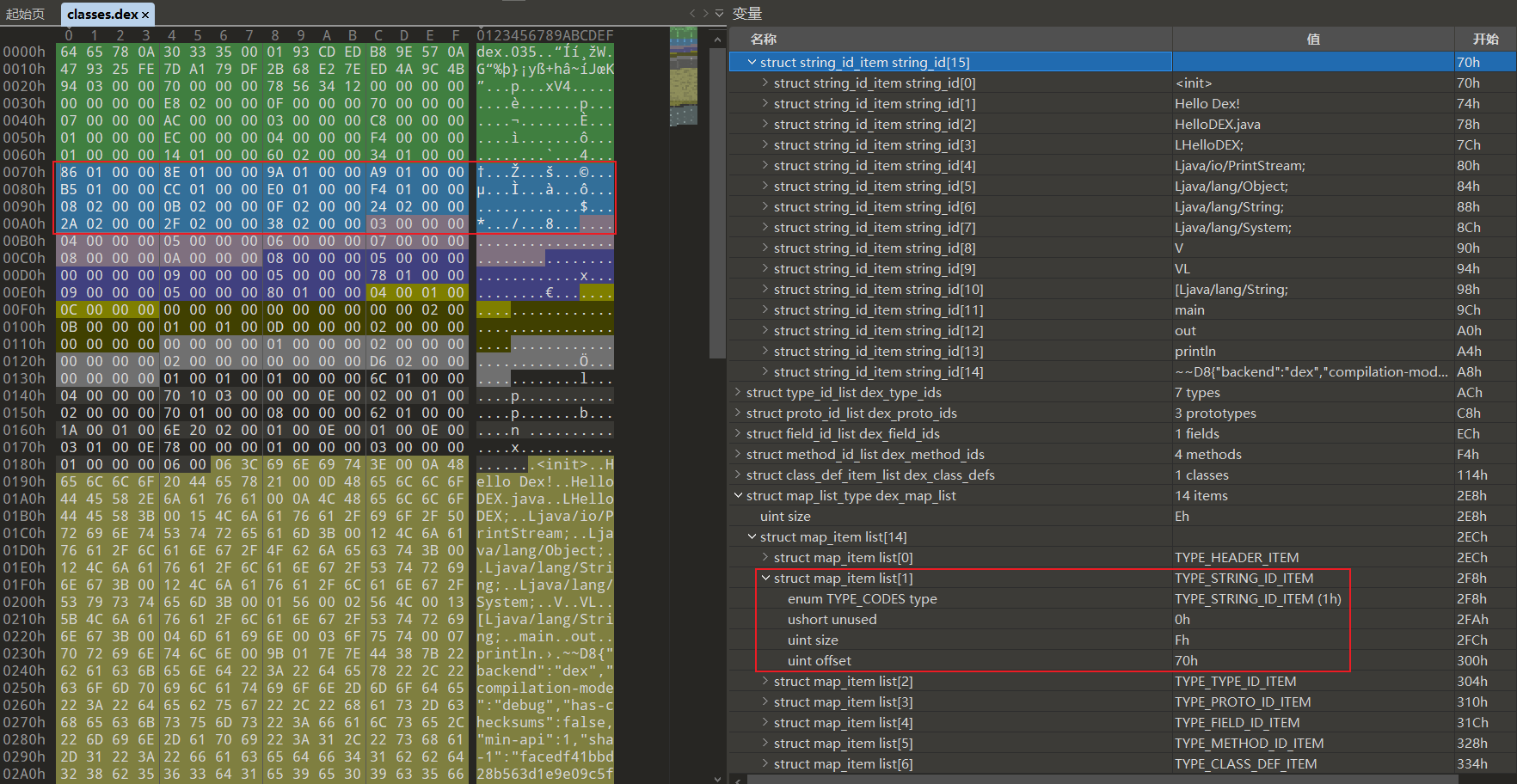
MUTF-8字符串头部保存的是字符串长度,是uleb128类型
相关函数定义如下,解析StringId
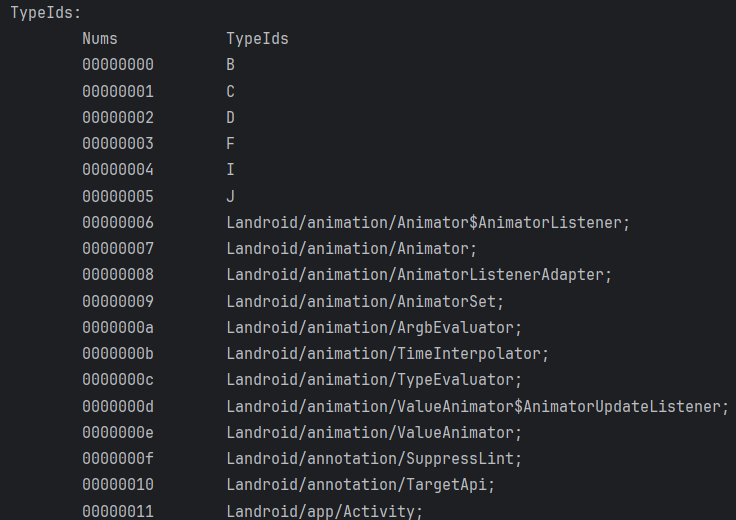
打印所有StringId,没有做MUTF编码处理,直接打印ASCII字符串
效果如下,没有做编码处理故可能出现乱码
定义如下
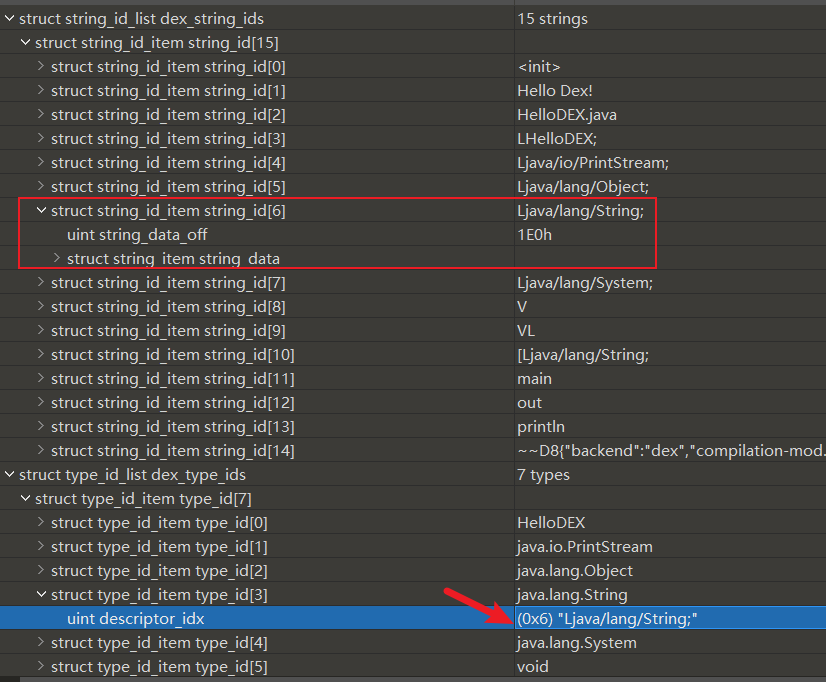
descriptorIdx为DexStringID表的索引,对应字符串表示类的类型
例如此处DexTypeID[3].descriptorIdx=6, 而DexStringID[6]对应的字符串为"Ljava/lang/String;"
和StringId类似,TypeId的解析代码如下,通过索引获取StringId及其对应的字符串
打印所有TypeId
效果如下
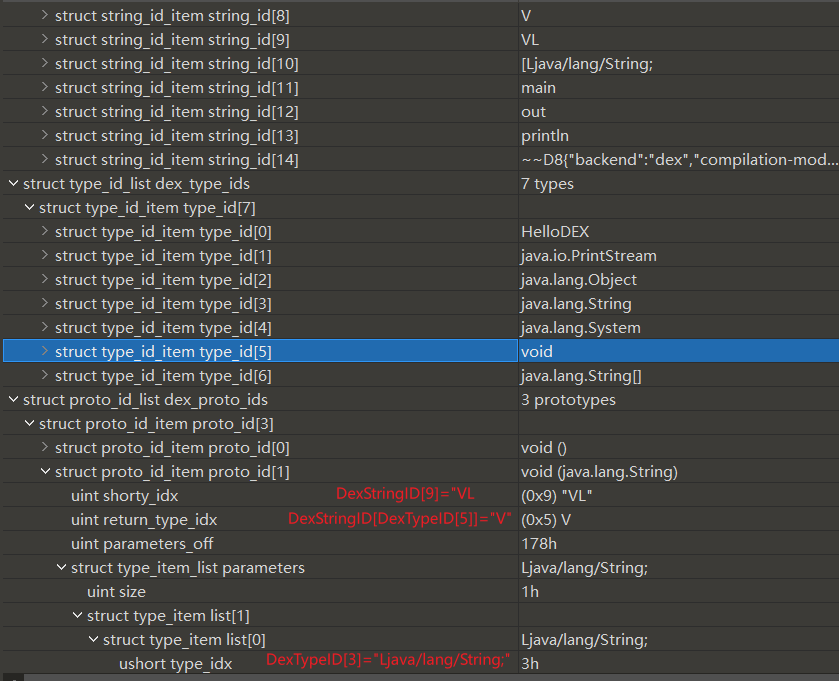
DexProtoId是**方法声明(方法签名)**的结构体,保存方法(函数)的返回值类型和参数类型列表,没有函数名,定义如下
parametersOff是DexTypeList的文件偏移
结构定义如下
例如此处DexProtoID[1]
方法声明 DexStringID[shortyIdx]="VL"
返回类型 DexStringID[DexTypeID[returnTypeIdx]]="V"
参数列表 DexStringID[DexTypeID[typeIdx]]="Ljava/lang/String;"
解析代码如下
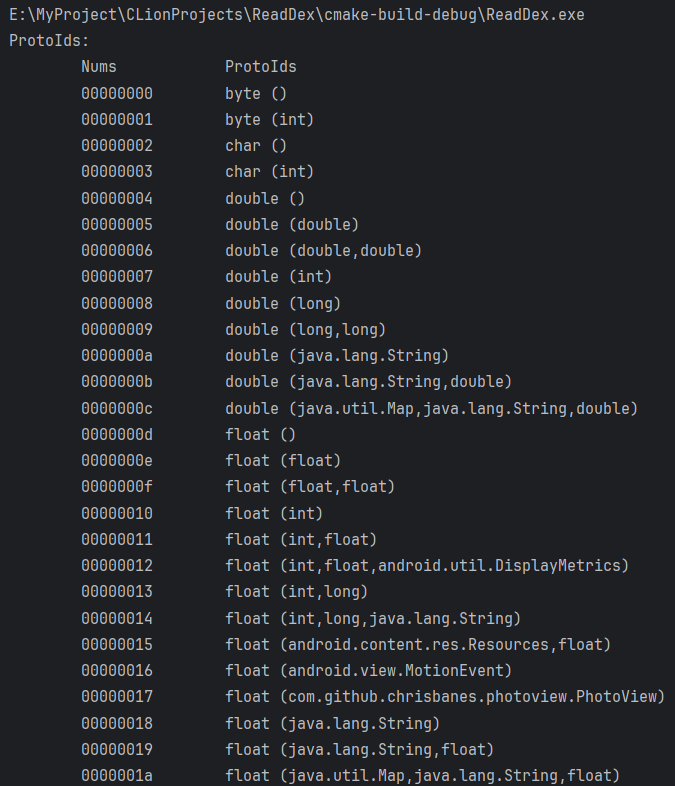
打印所有ProtoId
效果如下
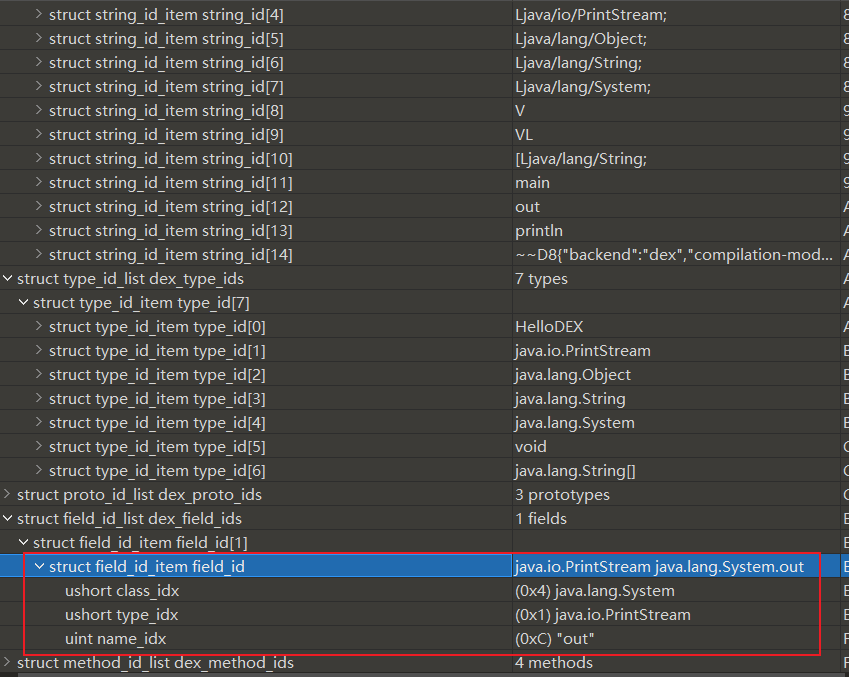
DexFieldID结构体指明了成员变量所在的类,类型以及变量名
寻找方法类似,out是java.lang.System类的成员,类型为java.io.PrintStream
解析代码如下
打印所有ProtoId
效果如下
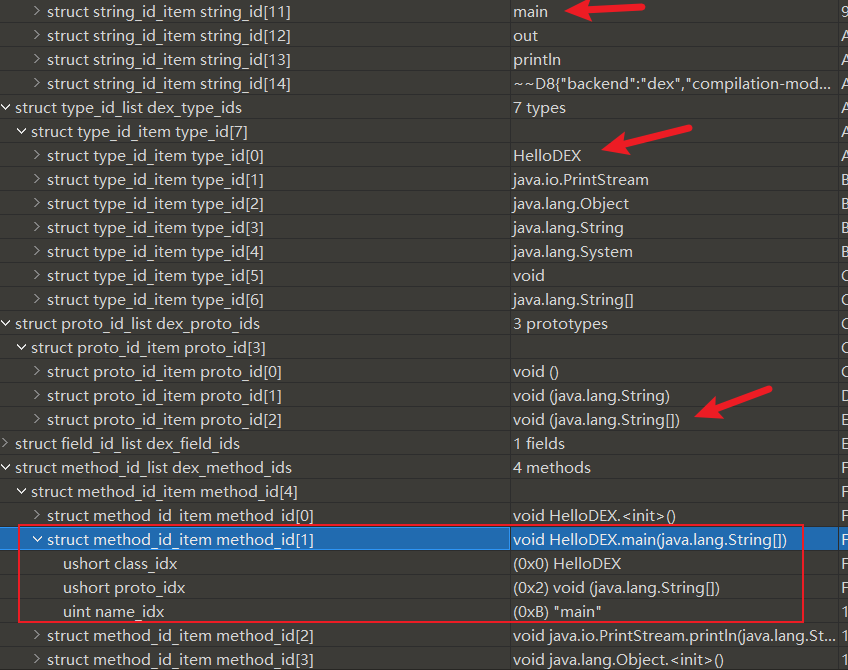
DexMethodId结构体指明了方法所在的类、方法声明(签名)以及方法名, 即完整的方法声明
寻找方法
对应解析代码如下
打印所有MethodId
效果如下
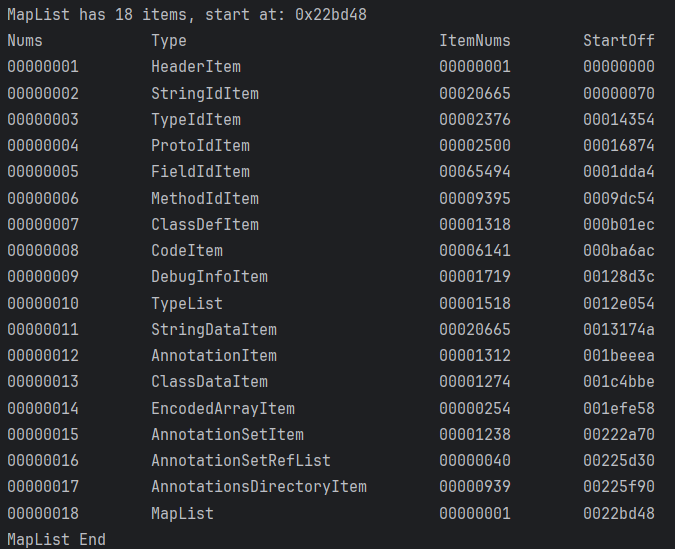
Dalvik虚拟机解析dex文件后,映射为DexMapList的数据结构, 该结构由DexHeader.mapOff指明位置
type是枚举常量,用于判断类型
size指定了类型个数,在dex文件中连续存放, offset是起始地址文件偏移
例如DexMapList[1] type=string_id_item, size=0xF, offset=0x70
和DexStringID表正好对应,起始地址,表项数
解析代码如下
打印效果如下
该结构较为复杂(这部分相关代码比前文所有结构代码之和都大)
有了对Dex文件的基本了解和上面各个结构的基础,才能解析该结构
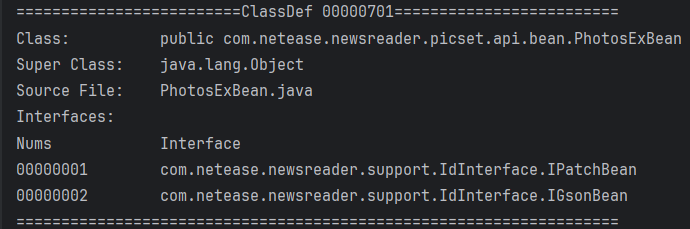
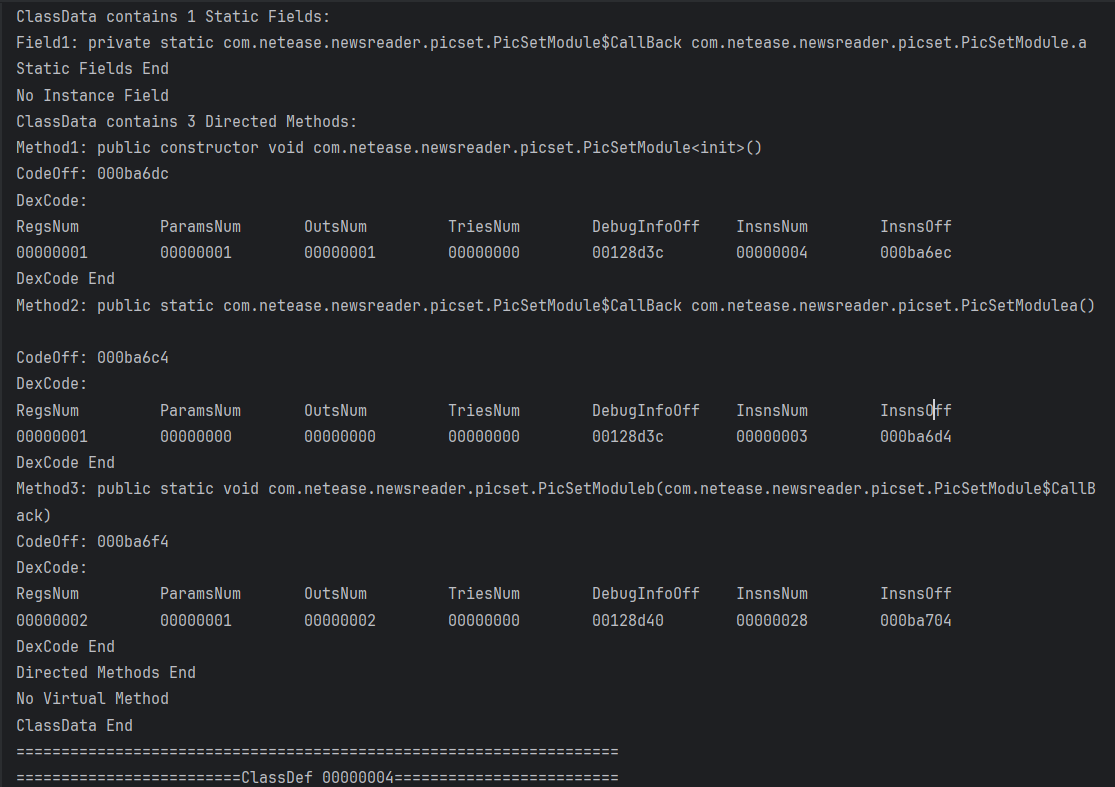
DexClassDef保存了类的相关信息,定义如下
解析代码如下
将ClassDef结构划分为4部分解析: BasicInfo, Annotations, ClassData, StaticValues, 从classIdx到sourceFileIx属于BasicInfo
每部分使用单独的打印函数进行处理
代码如下
效果如下
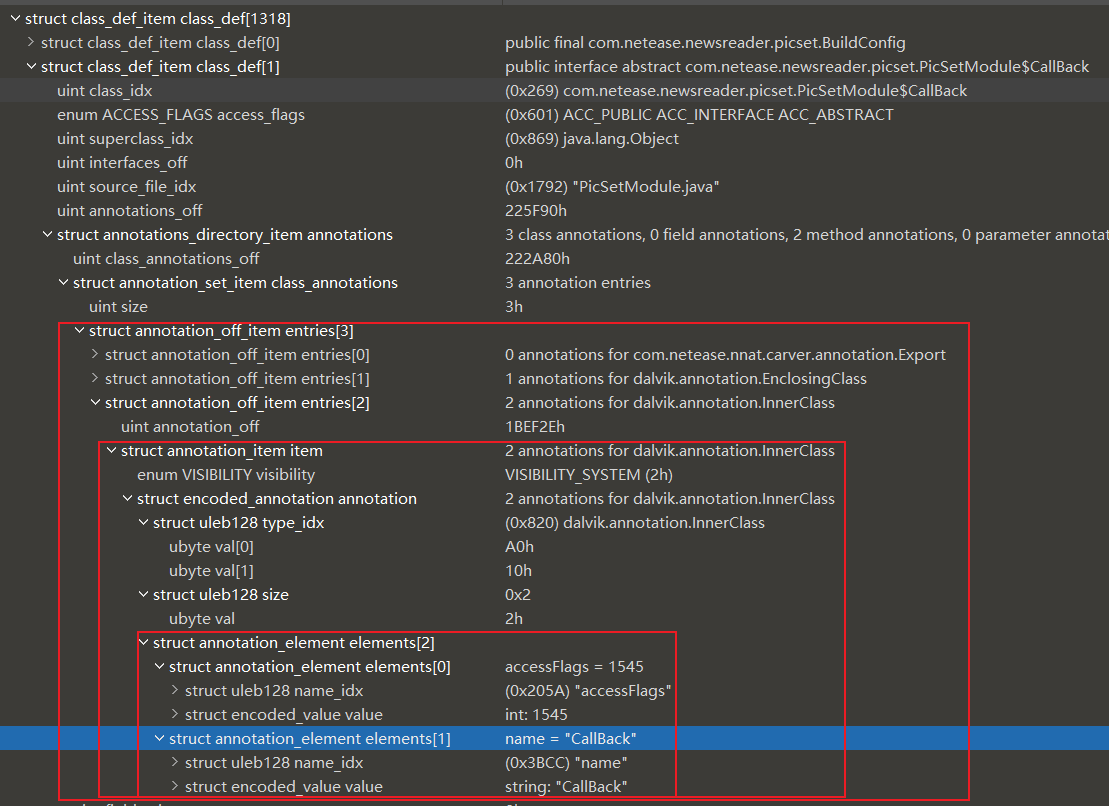
annotationsOff指向该结构,用于指向类的所有注解,定义如下
printClassDefAnnotations函数用于打印该结构,根据不同注解类型调用不同函数解析
visibility表示注释的可见性,主要有以下几种情况:
annotation是采用encoded_annotation格式的注释内容, encoded_annotation格式 如下:
annotation_element元素格式 如下:
解析代码如下
效果如下, 打印类注解及其包含的encoded_element内容
定义如下
由于指向DexAnnotationSetItem结构,故解析方式和类注解类似
效果如下
定义如下
解析方法类似
效果如下
定义如下
DexAnotationSetRefList结构体定义如下
解析方法略有不同,代码如下
效果如下
定义在fbaK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3q4F1k6s2u0G2K9h3c8^5M7X3g2X3i4K6u0W2j5$3!0E0i4K6u0r3x3W2)9J5k6e0y4Q4x3X3f1%4i4K6u0r3P5s2u0W2k6W2)9J5c8X3c8S2L8s2k6A6K9#2)9J5c8X3I4A6j5X3c8W2P5q4)9J5c8V1c8W2P5p5y4D9j5i4y4K6i4K6u0W2K9q4!0q4y4q4!0n7z5q4!0m8c8l9`.`.
注意: DexClass.h定义的结构体中,u4类型实际类型为uleb128
内部的结构体定义如下:
注意u4均为uleb128,所以这些结构大小不固定,无法通过sizeof计算,需要手动计算
其中codeOff指向DexCode结构,定义如下
解析代码如下,
效果如下
定义如下
encoded_array格式定义如下:
解析代码如下
效果如下
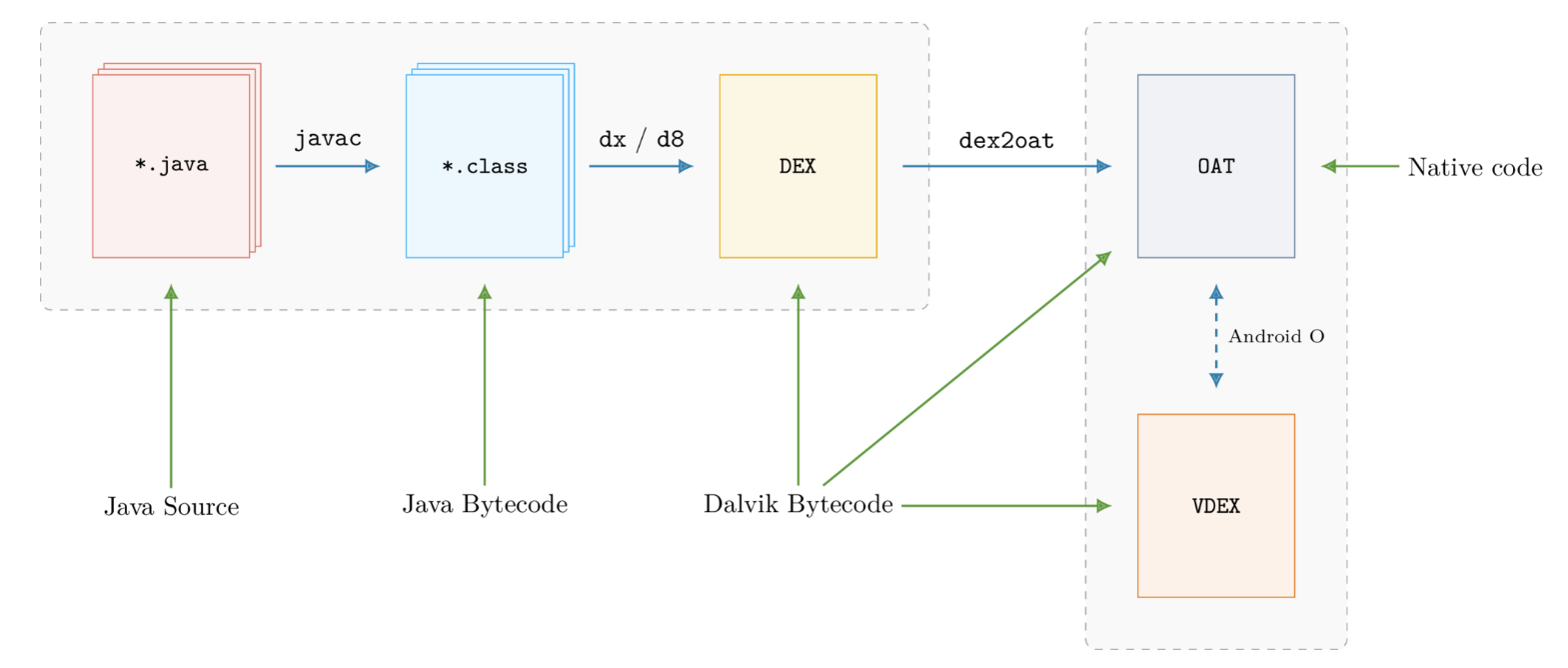
JVM是java语言的虚拟机,运行.class文件
Dalvik是google设计的用于Android平台的虚拟机,运行.dex文件
JVM基于栈,DVM基于寄存器,可以做到更好的提前优化,并且运行速度更快
Android 4.4首次提出ART虚拟机,在Android 5.0后弃用Dalvik,默认使用ART,运行oat文件
DVM应用运行时,字节码需要通过即时编译器JIT转换为机器码运行
ART则在应用第一次安装时,预先将字节码编译为机器码,该过程称之为预编译(AOT Ahead of time)
.java文件 经javac编译后生成 .class 文件 再通过dx/d8生成.dex文件
Dalvik虚拟机运行.dex文件,一个apk包内可能含有多个dex文件
Android5.0前,使用Dalvik虚拟机,ODEX是Dalvik对Dex文件优化后的产物, 通常存放在/data/dalvik-cache目录下
运行程序时直接加载odex文件,避免重复验证和优化
Android 5.0后,使用ART虚拟机, .odex实际上是OAT文件(ART定制的ELF文件)
OAT文件是Android4.4中引入的, Android5.0后,系统默认虚拟机为ART
OAT文件即是ART虚拟机对Dex优化后的产物,是Android定制的ELF文件
OAT文件结构随Android版本变化而变化,没有向后兼容性
VDEX文件在Android 8.0后引入, 不是Android系统的可执行文件,
Android 8.0后, dex2oat将class.dex优化生成2个文件: OAT文件(.odex)和VDEX文件(.vdex)
.art文件是一种ELF可执行文件 借助odex文件优化生成, 记录应用启动的热点函数相关地址,便于寻址加速
art文件结构随android版本变化,无向后兼容性
Dalvik 可执行文件格式 Android官方文档
Dex文件格式
dex文件格式解析
从JVM到Dalivk再到ART(class,dex,odex,vdex,ELF)
android的dex,odex,oat,vdex,art文件格式
一图全览DEX文件格式
附件: ReadDex.zip 工程项目压缩包
public class HelloDEX{
public static void main(String[] args){
System.out.println("Hello Dex!");
}
}
public class HelloDEX{
public static void main(String[] args){
System.out.println("Hello Dex!");
}
}
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/android/tools/r8/D8 has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/android/tools/r8/D8 has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0
自定义类型
原类型
含义
s1
int8_t
有符号单字节
u1
uint8_t
无符号单字节
s2
int16_t
u2
uint16_t
s4
int32_t
u4
uint32_t
s8
int64_t
u8
uint64_t
sleb128
无
有符号LEB128,可变长度
uleb128
无
无符号LEB128,可变长度
uleb128p1
无
等于ULEB128加1,可变长度
int readUnsignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result > 0x7f) {
int cur = *(ptr++);
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 14;
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 21;
if (cur > 0x7f) {
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
int readUnsignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result > 0x7f) {
int cur = *(ptr++);
result = (result & 0x7f) | ((cur & 0x7f) << 7);
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 14;
if (cur > 0x7f) {
cur = *(ptr++);
result |= (cur & 0x7f) << 21;
if (cur > 0x7f) {
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
int myReadUnsignedLeb128(const u1* pData,size_t* readSize) {
const u1** pStream = &pData;
u4 result=readUnsignedLeb128(pStream);
if(readSize)
*readSize=unsignedLeb128Size(result);
return result;
}
int myReadUnsignedLeb128(const u1* pData,size_t* readSize) {
const u1** pStream = &pData;
u4 result=readUnsignedLeb128(pStream);
if(readSize)
*readSize=unsignedLeb128Size(result);
return result;
}
名称
格式
说明
(value_arg << 5) | value_type
ubyte
高3位为value_arg的值,低5位为value_type的值,value_type指定value的格式。
value
ubyte[]
用于表示值的字节,不同 value_type 字节的长度不同且采用不同的解译方式;不过一律采用小端字节序。
类型名称
value_type
value_arg
value格式
说明
VALUE_BYTE
0x00
(无;必须为 0)
ubyte[1]
有符号的单字节整数值
VALUE_SHORT
0x02
size - 1 (0…1)
ubyte[size]
有符号的双字节整数值,符号扩展
VALUE_CHAR
0x03
size - 1 (0…1)
ubyte[size]
无符号的双字节整数值,零扩展
VALUE_INT
0x04
size - 1 (0…3)
ubyte[size]
有符号的四字节整数值,符号扩展
VALUE_LONG
0x06
size - 1 (0…7)
ubyte[size]
有符号的八字节整数值,符号扩展
VALUE_FLOAT
0x10
size - 1 (0…3)
ubyte[size]
四字节位模式,向右零扩展,系统会将其解译为 IEEE754 32 位浮点值
VALUE_DOUBLE
0x11
size - 1 (0…7)
ubyte[size]
八字节位模式,向右零扩展,系统会将其解译为 IEEE754 64 位浮点值
VALUE_METHOD_TYPE
0x15
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 proto_ids 区段的索引;表示方法类型值
VALUE_METHOD_HANDLE
0x16
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 method_handles 区段的索引;表示方法句柄值
VALUE_STRING
0x17
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 string_ids 区段的索引;表示字符串值
VALUE_TYPE
0x18
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 type_ids 区段的索引;表示反射类型/类值
VALUE_FIELD
0x19
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 field_ids 区段的索引;表示反射字段值
VALUE_METHOD
0x1a
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 method_ids 区段的索引;表示反射方法值
VALUE_ENUM
0x1b
size - 1 (0…3)
ubyte[size]
无符号(零扩展)四字节整数值,会被解译为要编入 field_ids 区段的索引;表示枚举类型常量的值
VALUE_ARRAY
0x1c
(无;必须为 0)
encoded_array
值的数组,采用下文“encoded_array 格式”所指定的格式。value 的大小隐含在编码中。
VALUE_ANNOTATION
0x1d
(无;必须为 0)
encoded_annotation
子注解,采用下文“encoded_annotation 格式”所指定的格式。value 的大小隐含在编码中。
VALUE_NULL
0x1e
(无;必须为 0)
(无)
null 引用值
VALUE_BOOLEAN
0x1f
布尔值 (0…1)
(无)
一位值;0 表示 false,1 表示 true。该位在 value_arg 中表示。
void DexFile::getEncodedValue(ubyte* pDest,const ubyte* pValue,int size) {
for(int i=0;i<size;i++) {
pDest[i]=pValue[i];
}
}
std::string DexFile::parseEncodedValue(ubyte* pEncodedValue,size_t& valueRealSize) {
ubyte valueArg = GetValueArg(pEncodedValue[0]);
ubyte valueType = GetValueType(pEncodedValue[0]);
if(valueArg==0) {
bool isSpecialType=false;
switch (valueType) {
case VALUE_BYTE:
case VALUE_ARRAY:
case VALUE_ANNOTATION:
case VALUE_NULL:
case VALUE_BOOLEAN:
isSpecialType=true;
break;
}
if(isSpecialType)
valueRealSize=1;
else
valueRealSize=2;
}
else
valueRealSize=valueArg+2;
int readValueSize=valueArg+1;
ubyte* pValue=&pEncodedValue[1];
std::string result;
unsigned int index=0;
switch(valueType) {
case VALUE_BYTE: {
char byte=0;
getEncodedValue((ubyte*)&byte,pValue,readValueSize);
result="byte:"+std::format("0x{:x}",byte);
break;
}
case VALUE_SHORT: {
short value_short=0;
getEncodedValue((ubyte*)&value_short,pValue,readValueSize);
result="short:"+std::format("0x{:x}",value_short);
break;
}
case VALUE_CHAR: {
unsigned short value_char=0;
getEncodedValue((ubyte*)&value_char,pValue,readValueSize);
result="char:"+std::format("0x{:x}",value_char);
break;
}
case VALUE_INT: {
int value_int=0;
getEncodedValue((ubyte*)&value_int,pValue,readValueSize);
result="int:"+std::format("0x{:x}",value_int);
break;
}
case VALUE_LONG: {
long long value_long=0;
getEncodedValue((ubyte*)&value_long,pValue,readValueSize);
result="long:"+std::format("0x{:x}",value_long);
break;
}
case VALUE_FLOAT: {
float value_float=0;
getEncodedValue((ubyte*)&value_float,pValue,readValueSize);
result="float:"+std::format("{:f}",value_float);
break;
}
case VALUE_DOUBLE: {
double value_double=0;
getEncodedValue((ubyte*)&value_double,pValue,readValueSize);
result="double:"+std::format("{:f}",value_double);
break;
}
case VALUE_METHOD_TYPE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="MethodType:"+std::format("0x{:x}",index)+" "+getProtoIdDataByIndex(index);
break;
}
case VALUE_METHOD_HANDLE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="MethodHandle Index:"+std::format("0x{:x}",index);
break;
}
case VALUE_STRING: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="String:"+getStringIdDataByIndex(index);
break;
}
case VALUE_TYPE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Type:"+parseString(getTypeIdDataByIndex(index));
break;
}
case VALUE_FIELD: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Field:"+parseString(getFieldIdDataByIndex(index));
break;
}
case VALUE_METHOD: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Method:"+parseString(getMethodIdDataByIndex(index));
break;
}
case VALUE_ENUM: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Enum:"+parseString(getFieldIdDataByIndex(index));
break;
}
case VALUE_ARRAY: {
break;
}
case VALUE_ANNOTATION:
result="Todo......";
break;
case VALUE_NULL:
result="null";
break;
case VALUE_BOOLEAN:
result="bool:";
if(valueArg)
result+="true";
else
result+="false";
break;
default:
result="Unknown value type";
}
return result;
}
void DexFile::getEncodedValue(ubyte* pDest,const ubyte* pValue,int size) {
for(int i=0;i<size;i++) {
pDest[i]=pValue[i];
}
}
std::string DexFile::parseEncodedValue(ubyte* pEncodedValue,size_t& valueRealSize) {
ubyte valueArg = GetValueArg(pEncodedValue[0]);
ubyte valueType = GetValueType(pEncodedValue[0]);
if(valueArg==0) {
bool isSpecialType=false;
switch (valueType) {
case VALUE_BYTE:
case VALUE_ARRAY:
case VALUE_ANNOTATION:
case VALUE_NULL:
case VALUE_BOOLEAN:
isSpecialType=true;
break;
}
if(isSpecialType)
valueRealSize=1;
else
valueRealSize=2;
}
else
valueRealSize=valueArg+2;
int readValueSize=valueArg+1;
ubyte* pValue=&pEncodedValue[1];
std::string result;
unsigned int index=0;
switch(valueType) {
case VALUE_BYTE: {
char byte=0;
getEncodedValue((ubyte*)&byte,pValue,readValueSize);
result="byte:"+std::format("0x{:x}",byte);
break;
}
case VALUE_SHORT: {
short value_short=0;
getEncodedValue((ubyte*)&value_short,pValue,readValueSize);
result="short:"+std::format("0x{:x}",value_short);
break;
}
case VALUE_CHAR: {
unsigned short value_char=0;
getEncodedValue((ubyte*)&value_char,pValue,readValueSize);
result="char:"+std::format("0x{:x}",value_char);
break;
}
case VALUE_INT: {
int value_int=0;
getEncodedValue((ubyte*)&value_int,pValue,readValueSize);
result="int:"+std::format("0x{:x}",value_int);
break;
}
case VALUE_LONG: {
long long value_long=0;
getEncodedValue((ubyte*)&value_long,pValue,readValueSize);
result="long:"+std::format("0x{:x}",value_long);
break;
}
case VALUE_FLOAT: {
float value_float=0;
getEncodedValue((ubyte*)&value_float,pValue,readValueSize);
result="float:"+std::format("{:f}",value_float);
break;
}
case VALUE_DOUBLE: {
double value_double=0;
getEncodedValue((ubyte*)&value_double,pValue,readValueSize);
result="double:"+std::format("{:f}",value_double);
break;
}
case VALUE_METHOD_TYPE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="MethodType:"+std::format("0x{:x}",index)+" "+getProtoIdDataByIndex(index);
break;
}
case VALUE_METHOD_HANDLE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="MethodHandle Index:"+std::format("0x{:x}",index);
break;
}
case VALUE_STRING: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="String:"+getStringIdDataByIndex(index);
break;
}
case VALUE_TYPE: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Type:"+parseString(getTypeIdDataByIndex(index));
break;
}
case VALUE_FIELD: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Field:"+parseString(getFieldIdDataByIndex(index));
break;
}
case VALUE_METHOD: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Method:"+parseString(getMethodIdDataByIndex(index));
break;
}
case VALUE_ENUM: {
getEncodedValue((ubyte*)&index,pValue,readValueSize);
result="Enum:"+parseString(getFieldIdDataByIndex(index));
break;
}
case VALUE_ARRAY: {
break;
}
case VALUE_ANNOTATION:
result="Todo......";
break;
case VALUE_NULL:
result="null";
break;
case VALUE_BOOLEAN:
result="bool:";
if(valueArg)
result+="true";
else
result+="false";
break;
default:
result="Unknown value type";
}
return result;
}
名称
格式
说明
size
uleb128
数组中的元素数量
values
encoded_value[size]
采用本部分所指定格式的一系列 size encoded_value 字节序列;依序串联。
名称
格式
说明
type_idx
uleb128
注释的类型。这种类型必须是“类”(而非“数组”或“基元”)。
size
uleb128
此注解中 name-value 映射的数量
elements
annotation_element[size]
注解的元素,直接以内嵌形式(不作为偏移量)表示。元素必须按 string_id 索引以升序进行排序。
名称
格式
说明
name_idx
uleb128
元素名称,表示为要编入 string_ids 区段的索引。该字符串必须符合上文定义的 MemberName 的语法。
value
encoded_value
元素值
struct DexFile {
const DexOptHeader* pOptHeader;
const DexHeader* pHeader;
const DexStringId* pStringIds;
const DexTypeId* pTypeIds;
const DexFieldId* pFieldIds;
const DexMethodId* pMethodIds;
const DexProtoId* pProtoIds;
const DexClassDef* pClassDefs;
const DexLink* pLinkData;
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool;
const u1* baseAddr;
int overhead;
};
struct DexFile {
const DexOptHeader* pOptHeader;
const DexHeader* pHeader;
const DexStringId* pStringIds;
const DexTypeId* pTypeIds;
const DexFieldId* pFieldIds;
const DexMethodId* pMethodIds;
const DexProtoId* pProtoIds;
const DexClassDef* pClassDefs;
const DexLink* pLinkData;
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool;
const u1* baseAddr;
int overhead;
};
class DexFile {
u1* baseAddr{nullptr};
DexHeader* pHeader{nullptr};
DexStringId* pStringIds{nullptr};
DexTypeId* pTypeIds{nullptr};
DexFieldId* pFieldIds{nullptr};
DexMethodId* pMethodIds{nullptr};
DexProtoId* pProtoIds{nullptr};
DexClassDef* pClassDefs{nullptr};
void initFields(unsigned char *buffer);
}
void DexFile::initFields(unsigned char* buffer) {
if(buffer==nullptr) {
printf("Null pointer provided!\n");
exit(0);
}
baseAddr=buffer;
pHeader=(DexHeader*)baseAddr;
pStringIds=(DexStringId*)(baseAddr+pHeader->stringIdsOff);
pTypeIds=(DexTypeId*)(baseAddr+pHeader->typeIdsOff);
pFieldIds=(DexFieldId*)(baseAddr+pHeader->fieldIdsOff);
pMethodIds=(DexMethodId*)(baseAddr+pHeader->methodIdsOff);
pProtoIds=(DexProtoId*)(baseAddr+pHeader->protoIdsOff);
pClassDefs=(DexClassDef*)(baseAddr+pHeader->classDefsOff);
}
DexFile::DexFile(unsigned char *buffer) {
initFields(buffer);
}
DexFile::DexFile(std::string filePath) {
size_t fileLength=0;
initFields(readFileToBytes(filePath, fileLength));
}
DexFile::~DexFile() {
delete baseAddr;
}
class DexFile {
u1* baseAddr{nullptr};
DexHeader* pHeader{nullptr};
DexStringId* pStringIds{nullptr};
DexTypeId* pTypeIds{nullptr};
DexFieldId* pFieldIds{nullptr};
DexMethodId* pMethodIds{nullptr};
DexProtoId* pProtoIds{nullptr};
DexClassDef* pClassDefs{nullptr};
void initFields(unsigned char *buffer);
}
void DexFile::initFields(unsigned char* buffer) {
if(buffer==nullptr) {
printf("Null pointer provided!\n");
exit(0);
}
baseAddr=buffer;
pHeader=(DexHeader*)baseAddr;
pStringIds=(DexStringId*)(baseAddr+pHeader->stringIdsOff);
pTypeIds=(DexTypeId*)(baseAddr+pHeader->typeIdsOff);
pFieldIds=(DexFieldId*)(baseAddr+pHeader->fieldIdsOff);
pMethodIds=(DexMethodId*)(baseAddr+pHeader->methodIdsOff);
pProtoIds=(DexProtoId*)(baseAddr+pHeader->protoIdsOff);
pClassDefs=(DexClassDef*)(baseAddr+pHeader->classDefsOff);
}
DexFile::DexFile(unsigned char *buffer) {
initFields(buffer);
}
DexFile::DexFile(std::string filePath) {
size_t fileLength=0;
initFields(readFileToBytes(filePath, fileLength));
}
DexFile::~DexFile() {
delete baseAddr;
}
typedef struct DexHeader {
u1 magic[8];
u4 checksum;
u1 signature[kSHA1DigestLen];
u4 fileSize;
u4 headerSize;
u4 endianTag;
u4 linkSize;
u4 linkOff;
u4 mapOff;
u4 stringIdsSize;
u4 stringIdsOff;
u4 typeIdsSize;
u4 typeIdsOff;
u4 protoIdsSize;
u4 protoIdsOff;
u4 fieldIdsSize;
u4 fieldIdsOff;
u4 methodIdsSize;
u4 methodIdsOff;
u4 classDefsSize;
u4 classDefsOff;
u4 dataSize;
u4 dataOff;
} DexHeader;
typedef struct DexHeader {
u1 magic[8];
u4 checksum;
u1 signature[kSHA1DigestLen];
u4 fileSize;
u4 headerSize;
u4 endianTag;
u4 linkSize;
u4 linkOff;
u4 mapOff;
u4 stringIdsSize;
u4 stringIdsOff;
u4 typeIdsSize;
u4 typeIdsOff;
u4 protoIdsSize;
u4 protoIdsOff;
u4 fieldIdsSize;
u4 fieldIdsOff;
u4 methodIdsSize;
u4 methodIdsOff;
u4 classDefsSize;
u4 classDefsOff;
u4 dataSize;
u4 dataOff;
} DexHeader;
void DexFile::printDexHeader() {
printf("DexHeader:\n");
printf("\tmagic: ");printHexBytes(pHeader->magic,sizeof(pHeader->magic));printf("\n");
printf("\tchecksum: %#x\n",pHeader->checksum);
printf("\tsignature: ");printHexBytes(pHeader->signature,kSHA1DigestLen);printf("\n");
printf("\tFileSize: %#x\n",pHeader->fileSize);
printf("\tHeaderSize: %#x\n",pHeader->headerSize);
printf("\tEndianTag: %#x\n",pHeader->endianTag);
printf("\tLinkOff: %#x\n",pHeader->linkOff);
printf("\tLinkSize: %#x\n",pHeader->linkSize);
printf("\tMapOff: %#x\n",pHeader->mapOff);
printf("\tStringIDs Offset: %#x\n",pHeader->stringIdsOff);
printf("\tNum of StringIDs: %#x\n",pHeader->stringIdsSize);
printf("\tTypeIDs Offset: %#x\n",pHeader->typeIdsOff);
printf("\tNum of TypeIDs: %#x\n",pHeader->typeIdsSize);
printf("\tProtoIDs Offset: %#x\n",pHeader->protoIdsOff);
printf("\tNum of ProtoIDs: %#x\n",pHeader->protoIdsSize);
printf("\tFieldIDs Offset: %#x\n",pHeader->fieldIdsOff);
printf("\tNum of FieldIDs: %#x\n",pHeader->fieldIdsSize);
printf("\tMethodIDs Offset: %#x\n",pHeader->methodIdsOff);
printf("\tNum of MethodIDs: %#x\n",pHeader->methodIdsSize);
printf("\tClassDefs Offset: %#x\n",pHeader->classDefsOff);
printf("\tNum of ClassDefs: %#x\n",pHeader->classDefsSize);
printf("\tData Offset: %#x\n",pHeader->dataOff);
printf("\tSize of Data: %#x\n",pHeader->dataSize);
printf("DexHeader End\n");
}
void DexFile::printDexHeader() {
printf("DexHeader:\n");
printf("\tmagic: ");printHexBytes(pHeader->magic,sizeof(pHeader->magic));printf("\n");
printf("\tchecksum: %#x\n",pHeader->checksum);
printf("\tsignature: ");printHexBytes(pHeader->signature,kSHA1DigestLen);printf("\n");
printf("\tFileSize: %#x\n",pHeader->fileSize);
printf("\tHeaderSize: %#x\n",pHeader->headerSize);
printf("\tEndianTag: %#x\n",pHeader->endianTag);
printf("\tLinkOff: %#x\n",pHeader->linkOff);
printf("\tLinkSize: %#x\n",pHeader->linkSize);
printf("\tMapOff: %#x\n",pHeader->mapOff);
printf("\tStringIDs Offset: %#x\n",pHeader->stringIdsOff);
printf("\tNum of StringIDs: %#x\n",pHeader->stringIdsSize);
printf("\tTypeIDs Offset: %#x\n",pHeader->typeIdsOff);
printf("\tNum of TypeIDs: %#x\n",pHeader->typeIdsSize);
printf("\tProtoIDs Offset: %#x\n",pHeader->protoIdsOff);
printf("\tNum of ProtoIDs: %#x\n",pHeader->protoIdsSize);
printf("\tFieldIDs Offset: %#x\n",pHeader->fieldIdsOff);
printf("\tNum of FieldIDs: %#x\n",pHeader->fieldIdsSize);
printf("\tMethodIDs Offset: %#x\n",pHeader->methodIdsOff);
printf("\tNum of MethodIDs: %#x\n",pHeader->methodIdsSize);
printf("\tClassDefs Offset: %#x\n",pHeader->classDefsOff);
printf("\tNum of ClassDefs: %#x\n",pHeader->classDefsSize);
printf("\tData Offset: %#x\n",pHeader->dataOff);
printf("\tSize of Data: %#x\n",pHeader->dataSize);
printf("DexHeader End\n");
}
struct DexStringId {
u4 stringDataOff;
};
struct string_data_item {
uleb128 utf16_size;
ubyte[] data;
}
struct DexStringId {
u4 stringDataOff;
};
struct string_data_item {
uleb128 utf16_size;
ubyte[] data;
}
DexStringId DexFile::getStringIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->stringIdsSize-1)) {
return pStringIds[index];
}
printf("No such index: %x\n",index);
exit(0);
}
size_t DexFile::getStringDataLength(DexStringId& stringId) {
const u1* ptr = baseAddr + stringId.stringDataOff;
size_t size=0;
myReadUnsignedLeb128(ptr,&size);
return size;
}
std::string DexFile::getStringIdData(const DexStringId& stringId) {
const u1* ptr = baseAddr + stringId.stringDataOff;
while (*(ptr++) > 0x7f);
return (char*)ptr;
}
std::string DexFile::getStringIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->stringIdsSize-1)) {
return getStringIdData(pStringIds[index]);
}
return nullptr;
}
DexStringId DexFile::getStringIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->stringIdsSize-1)) {
return pStringIds[index];
}
printf("No such index: %x\n",index);
exit(0);
}
size_t DexFile::getStringDataLength(DexStringId& stringId) {
const u1* ptr = baseAddr + stringId.stringDataOff;
size_t size=0;
myReadUnsignedLeb128(ptr,&size);
return size;
}
std::string DexFile::getStringIdData(const DexStringId& stringId) {
const u1* ptr = baseAddr + stringId.stringDataOff;
while (*(ptr++) > 0x7f);
return (char*)ptr;
}
std::string DexFile::getStringIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->stringIdsSize-1)) {
return getStringIdData(pStringIds[index]);
}
return nullptr;
}
void DexFile::printStringIds() {
printf("StringIds:\n");
printf("\tNums\t\tStrings\n");
for(int i=0;i<pHeader->stringIdsSize;i++) {
printf("\t%08x\t%s\n",i,getStringIdDataByIndex(i).c_str());
}
printf("StringIds End\n");
}
void DexFile::printStringIds() {
printf("StringIds:\n");
printf("\tNums\t\tStrings\n");
for(int i=0;i<pHeader->stringIdsSize;i++) {
printf("\t%08x\t%s\n",i,getStringIdDataByIndex(i).c_str());
}
printf("StringIds End\n");
}
typedef struct DexTypeId {
u4 descriptorIdx;
} DexTypeId;
typedef struct DexTypeId {
u4 descriptorIdx;
} DexTypeId;
DexTypeId DexFile::getTypeIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->typeIdsSize-1)) {
return pTypeIds[index];
}
printf("No such index: %x\n",index);
exit(0);
}
std::string DexFile::getTypeIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->typeIdsSize-1)) {
return getStringIdDataByIndex(pTypeIds[index].descriptorIdx);
}
return nullptr;
}
DexTypeId DexFile::getTypeIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->typeIdsSize-1)) {
return pTypeIds[index];
}
printf("No such index: %x\n",index);
exit(0);
}
std::string DexFile::getTypeIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->typeIdsSize-1)) {
return getStringIdDataByIndex(pTypeIds[index].descriptorIdx);
}
return nullptr;
}
void DexFile::printTypeIds() {
printf("TypeIds:\n");
printf("\tNums\t\tTypeIds\n");
for(int i=0;i<pHeader->typeIdsSize;i++) {
printf("\t%08x\t%s\n",i,getTypeIdDataByIndex(i).c_str());
}
printf("TypeIds End\n");
}
void DexFile::printTypeIds() {
printf("TypeIds:\n");
printf("\tNums\t\tTypeIds\n");
for(int i=0;i<pHeader->typeIdsSize;i++) {
printf("\t%08x\t%s\n",i,getTypeIdDataByIndex(i).c_str());
}
printf("TypeIds End\n");
}
typedef struct DexProtoId {
u4 shortyIdx;
u4 returnTypeIdx;
u4 parametersOff;
} DexProtoId;
typedef struct DexProtoId {
u4 shortyIdx;
u4 returnTypeIdx;
u4 parametersOff;
} DexProtoId;
typedef struct DexTypeList {
u4 size;
DexTypeItem list[size];
} DexTypeList;
typedef struct DexTypeItem {
u2 typeIdx;
} DexTypeItem;
typedef struct DexTypeList {
u4 size;
DexTypeItem list[size];
} DexTypeList;
typedef struct DexTypeItem {
u2 typeIdx;
} DexTypeItem;
const DexProtoId DexFile::getProtoIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->protoIdsSize-1)) {
return pProtoIds[index];
}
illegalIndex(index);
}
std::string DexFile::getProtoIdShorty(const DexProtoId& protoId) {
return getStringIdDataByIndex(protoId.shortyIdx);
}
std::string DexFile::getProtoIdReturnType(const DexProtoId& protoId) {
return getTypeIdDataByIndex(protoId.returnTypeIdx);
}
std::vector<std::string> DexFile::getProtoIdParameters(const DexProtoId& protoId) {
std::vector<std::string> parameters;
if(protoId.parametersOff==0) {
return parameters;
}
DexTypeList* typeList=(DexTypeList*)(baseAddr+protoId.parametersOff);
for(int i=0;i<typeList->size;i++) {
parameters.push_back(getTypeIdDataByIndex(typeList->list[i].typeIdx));
}
return parameters;
}
std::string DexFile::parseProtoId(const DexProtoId& protoId) {
std::string shorty=getProtoIdShorty(protoId);
std::string return_type = getProtoIdReturnType(protoId);
std::vector<std::string> parameters=getProtoIdParameters(protoId);
std::string result;
result+=parseString(return_type)+" (";
for(int i=0;i<parameters.size();i++) {
result+=parseString(parameters[i]);
if(i!=parameters.size()-1)
result+=",";
}
result+=")";
return result;
}
std::string DexFile::getProtoIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->protoIdsSize-1)) {
return parseProtoId(getProtoIdByIndex(index));
}
return nullptr;
}
const DexProtoId DexFile::getProtoIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->protoIdsSize-1)) {
return pProtoIds[index];
}
illegalIndex(index);
}
std::string DexFile::getProtoIdShorty(const DexProtoId& protoId) {
return getStringIdDataByIndex(protoId.shortyIdx);
}
std::string DexFile::getProtoIdReturnType(const DexProtoId& protoId) {
return getTypeIdDataByIndex(protoId.returnTypeIdx);
}
std::vector<std::string> DexFile::getProtoIdParameters(const DexProtoId& protoId) {
std::vector<std::string> parameters;
if(protoId.parametersOff==0) {
return parameters;
}
DexTypeList* typeList=(DexTypeList*)(baseAddr+protoId.parametersOff);
for(int i=0;i<typeList->size;i++) {
parameters.push_back(getTypeIdDataByIndex(typeList->list[i].typeIdx));
}
return parameters;
}
std::string DexFile::parseProtoId(const DexProtoId& protoId) {
std::string shorty=getProtoIdShorty(protoId);
std::string return_type = getProtoIdReturnType(protoId);
std::vector<std::string> parameters=getProtoIdParameters(protoId);
std::string result;
result+=parseString(return_type)+" (";
for(int i=0;i<parameters.size();i++) {
result+=parseString(parameters[i]);
if(i!=parameters.size()-1)
result+=",";
}
result+=")";
return result;
}
std::string DexFile::getProtoIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->protoIdsSize-1)) {
return parseProtoId(getProtoIdByIndex(index));
}
return nullptr;
}
void DexFile::printProtoIds() {
printf("ProtoIds:\n");
printf("\tNums\t\tProtoIds\n");
for(int i=0;i<pHeader->protoIdsSize;i++) {
printf("\t%08x\t%s\n",i,getProtoIdDataByIndex(i).c_str());
}
printf("ProtoIds End\n");
}
void DexFile::printProtoIds() {
printf("ProtoIds:\n");
printf("\tNums\t\tProtoIds\n");
for(int i=0;i<pHeader->protoIdsSize;i++) {
printf("\t%08x\t%s\n",i,getProtoIdDataByIndex(i).c_str());
}
printf("ProtoIds End\n");
}
typedef struct DexFieldId {
u2 classIdx;
u2 typeIdx;
u4 nameIdx;
} DexFieldId;
typedef struct DexFieldId {
u2 classIdx;
u2 typeIdx;
u4 nameIdx;
} DexFieldId;
const DexFieldId DexFile::getFieldIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->fieldIdsSize-1)) {
return pFieldIds[index];
}
illegalIndex(index);
}
std::string DexFile::getFieldIdClass(const DexFieldId& fieldId) {
return getTypeIdDataByIndex(fieldId.classIdx);
}
std::string DexFile::getFieldIdType(const DexFieldId& fieldId) {
return getTypeIdDataByIndex(fieldId.typeIdx);
}
std::string DexFile::getFieldIdName(const DexFieldId& fieldId) {
return getStringIdDataByIndex(fieldId.nameIdx);
}
std::string DexFile::parseFieldId(const DexFieldId& fieldId) {
std::string fieldClass=getFieldIdClass(fieldId);
std::string fieldType=getFieldIdType(fieldId);
std::string fieldName=getFieldIdName(fieldId);
return parseString(fieldType)+" "+parseString(fieldClass)+"."+fieldName;
}
std::string DexFile::getFieldIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->fieldIdsSize-1)) {
return parseFieldId(getFieldIdByIndex(index));
}
return nullptr;
}
const DexFieldId DexFile::getFieldIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->fieldIdsSize-1)) {
return pFieldIds[index];
}
illegalIndex(index);
}
std::string DexFile::getFieldIdClass(const DexFieldId& fieldId) {
return getTypeIdDataByIndex(fieldId.classIdx);
}
std::string DexFile::getFieldIdType(const DexFieldId& fieldId) {
return getTypeIdDataByIndex(fieldId.typeIdx);
}
std::string DexFile::getFieldIdName(const DexFieldId& fieldId) {
return getStringIdDataByIndex(fieldId.nameIdx);
}
std::string DexFile::parseFieldId(const DexFieldId& fieldId) {
std::string fieldClass=getFieldIdClass(fieldId);
std::string fieldType=getFieldIdType(fieldId);
std::string fieldName=getFieldIdName(fieldId);
return parseString(fieldType)+" "+parseString(fieldClass)+"."+fieldName;
}
std::string DexFile::getFieldIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->fieldIdsSize-1)) {
return parseFieldId(getFieldIdByIndex(index));
}
return nullptr;
}
void DexFile::printFieldIds() {
printf("FieldIds:\n");
printf("\tNums\t\tFieldIds\n");
for(int i=0;i<pHeader->fieldIdsSize;i++) {
printf("\t%08x\t%s\n",i,getFieldIdDataByIndex(i).c_str());
}
printf("FieldId End\n");
}
void DexFile::printFieldIds() {
printf("FieldIds:\n");
printf("\tNums\t\tFieldIds\n");
for(int i=0;i<pHeader->fieldIdsSize;i++) {
printf("\t%08x\t%s\n",i,getFieldIdDataByIndex(i).c_str());
}
printf("FieldId End\n");
}
struct DexMethodId {
u2 classIdx;
u2 protoIdx;
u4 nameIdx;
};
struct DexMethodId {
u2 classIdx;
u2 protoIdx;
u4 nameIdx;
};
const DexMethodId DexFile::getMethodIdByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->methodIdsSize-1)) {
return pMethodIds[index];
}
illegalIndex(index);
}
std::string DexFile::getMethodIdClass(const DexMethodId& methodId) {
return getTypeIdDataByIndex(methodId.classIdx);
}
std::string DexFile::getMethodIdProto(const DexMethodId& methodId) {
return getProtoIdDataByIndex(methodId.protoIdx);
}
std::string DexFile::getMethodIdName(const DexMethodId& methodId) {
return getStringIdDataByIndex(methodId.nameIdx);
}
std::string DexFile::parseMethodId(const DexMethodId& methodId) {
std::string methodProto=getMethodIdProto(methodId);
std::string methodFullName=parseString(getMethodIdClass(methodId))+getMethodIdName(methodId);
return methodProto.insert(methodProto.find(' ')+1,methodFullName);
}
std::string DexFile::getMethodIdDataByIndex(u4 index) {
if(checkIndexIsLegal(index,pHeader->methodIdsSize-1)) {
return parseMethodId(getMethodIdByIndex(index));
}
return nullptr;
}
const DexMethodId DexFile::getMethodIdByIndex(u4 index) {
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
上传的附件: