class Tencent():
def __init__(self):
server = Server('browsermob-proxy-2.1.4/bin/browsermob-proxy')
server.start()
self.proxy = server.create_proxy(params={'trustAllServers':'true'})
self.url = 'aHR0cHM6Ly93d3cudXJidGl4LmhrL2xvZ2lu'
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument('--proxy-server={0}'.format(self.proxy.proxy))
self.proxy.new_har(options={'captureContent': True,'captureHeaders': True})
self.driver = webdriver.Chrome(options=option)
self.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator,"webdriver",{get: () => undefined})'
})
with open('stealth.min.js') as f:
js = f.read()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js})
self.driver.maximize_window()
self.det = ddddocr.DdddOcr(det=False, ocr=False, show_ad=False)
self.headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
def index(self):
self.driver.get(self.url)
time.sleep(5)
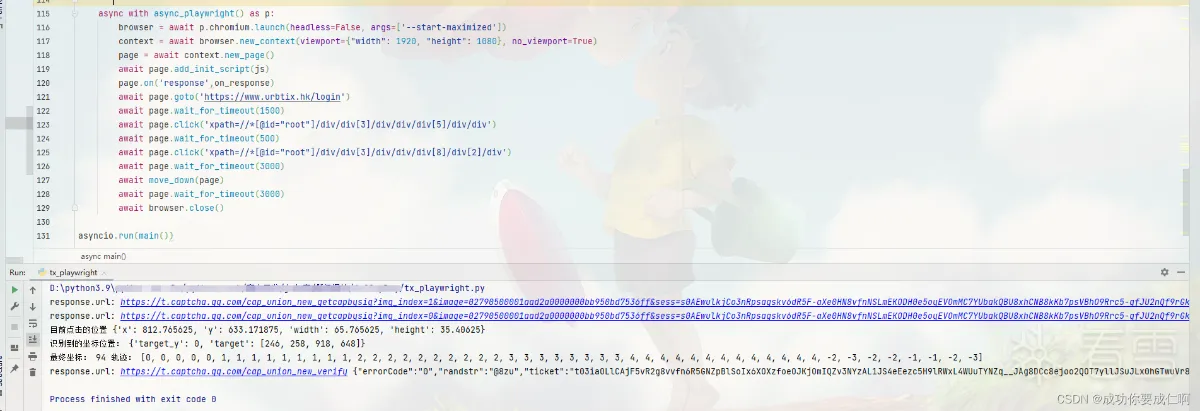
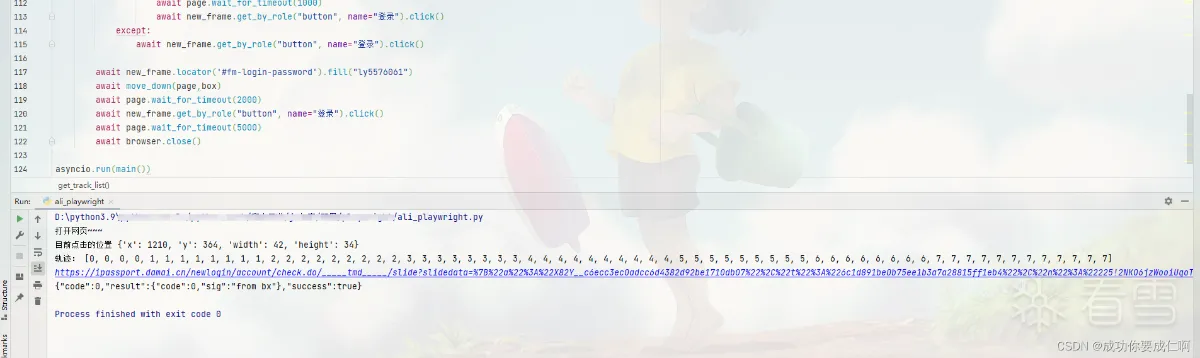
print("正在打开网页~~~")
self.driver.find_element(by=By.XPATH, value=f'//*[@id="root"]/div/div[3]/div/div/div[5]/div/div').click()
time.sleep(1)
self.driver.find_element(by=By.XPATH, value=f'//*[@id="root"]/div/div[3]/div/div/div[8]/div[2]/div').click()
time.sleep(5)
self.driver.switch_to.frame('tcaptcha_iframe_dy')
bg_style = self.driver.find_element('id','slideBg').get_attribute("style")
cut_style = self.driver.find_element(by=By.XPATH, value=f'//*[@id="tcOperation"]/div[8]').get_attribute("style")
bg_url = re.findall('url\("(.*?)"\)',str(bg_style))[0]
cut_url = re.findall('url\("(.*?)"\)', str(cut_style))[0]
print("获取到背景图片url:",bg_url)
print("获取到滑块图片url:",cut_url)
with open("bg_picture.jpg", "wb") as f:
f.write(requests.get(bg_url).content)
with open("cut_picture.png", "wb") as f:
f.write(requests.get(cut_url).content)
def get_gap_offset(self):
img = Image.open('cut_picture.png')
region = img.crop((160, 508, 243, 595))
region.save(f'cut_picture.png')
with open('bg_picture.jpg', 'rb') as f:
target_bytes = f.read()
with open('cut_picture.png', 'rb') as f:
background_bytes = f.read()
res = self.det.slide_match(target_bytes, background_bytes, simple_target=True)
print("识别到的坐标位置:",res)
distance = int(res['target'][0])
return distance
def get_track(self, offset):
offset -= 30
a = offset / 4
track = [a, a, a, a]
return track
def shake_mouse(self):
ActionChains(self.driver).move_by_offset(xoffset=-2, yoffset=0).perform()
ActionChains(self.driver).move_by_offset(xoffset=2, yoffset=0).perform()
def operate_slider(self, track):
slider_bt = self.driver.find_element(by=By.XPATH,value ='//*[@id="tcOperation"]/div[6]')
ActionChains(self.driver).click_and_hold(slider_bt).perform()
for i in track:
ActionChains(self.driver).move_by_offset(xoffset=i, yoffset=0).perform()
time.sleep(random.random() / 100)
time.sleep(random.random())
back_tracks = [-1, -0.5, -1]
for i in back_tracks:
time.sleep(random.random() / 100)
ActionChains(self.driver).move_by_offset(xoffset=i, yoffset=0).perform()
self.shake_mouse()
time.sleep(random.random())
ActionChains(self.driver).release().perform()
time.sleep(2)
def login(self):
self.index()
distance = self.get_gap_offset()
distance = int(distance/1.97)
track = self.get_track(distance)
self.operate_slider(track)
result = self.proxy.har
for entry in result['log']['entries']:
if entry['request']['url'] == 'b6aK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6@1i4K6u0W2j5$3q4H3N6r3y4Z5j5g2)9J5k6i4q4I4i4K6u0W2j5$3!0E0i4K6u0r3j5$3q4H3i4K6g2X3N6h3&6A6L8$3&6Q4y4h3k6F1k6i4N6Q4y4h3k6$3k6i4u0A6k6Y4W2Q4x3U0M7`.:
print(entry['request']['url'],entry['response']['content'])
print(entry['response']['content']['text'])