翻译:梦幻的彼岸
原文地址:b04K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Z5k6i4S2Q4x3X3c8J5j5i4W2K6i4K6u0W2j5$3!0E0i4K6u0r3j5X3I4G2k6#2)9J5c8X3W2Y4L8%4u0Q4x3X3c8@1K9i4m8Q4x3X3c8G2k6W2)9J5k6s2c8Z5k6g2)9J5k6s2N6W2k6h3E0Q4x3X3b7I4x3#2)9J5k6s2y4@1M7X3W2F1k6#2)9J5k6r3I4A6N6r3g2J5j5h3I4K6i4K6u0V1j5h3&6V1i4K6u0V1j5%4g2K6N6r3!0E0i4K6u0V1k6h3&6U0L8$3c8A6L8X3N6K6i4K6u0r3
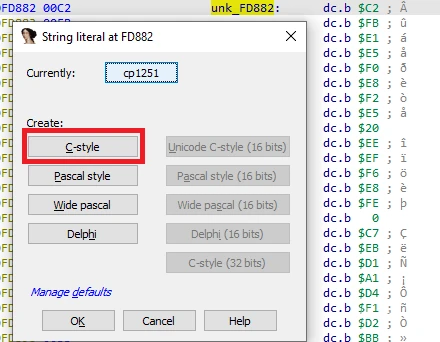
大多数 IDA 用户可能会分析使用英语或其他拉丁字母的软件。因此,用于字符串文本的默认值(Windows 上的操作系统系统编码和 Linux 或 macOS 上的 UTF-8)通常已经足够好了。不过,偶尔也会遇到使用其他语言的程序。
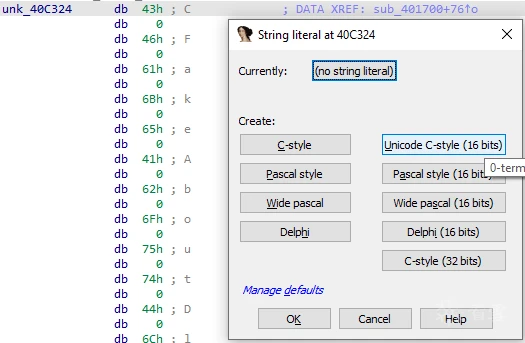
如果程序使用宽字符串,通常只需在创建字符串文本时使用相应的 "Unicode C-style "选项即可:
一般来说,Windows 程序倾向于使用 16 位宽字符串(wchar_t为 16 位),而 Linux 和 Mac 则使用 32 位字符串(wchar_t为 32 位)。不过,也有例外情况,您可以根据所分析的特定二进制文件使用其中一种。
提示:您可以使用加速器快速创建特定字符串类型,例如 Alt + A,U 表示 Unicode 16 位。
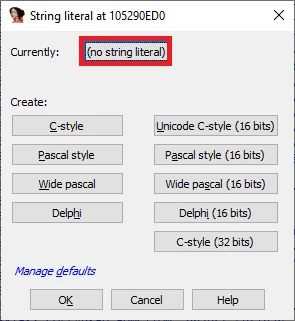
在某些情况下,被分析的二进制文件使用的编码可能与 IDA 选定的编码不同,甚至在同一文件中存在多个互不兼容的编码。在这种情况下,你可以为单个字符串文本分别设置编码,或者为所有新字符串全局设置编码。
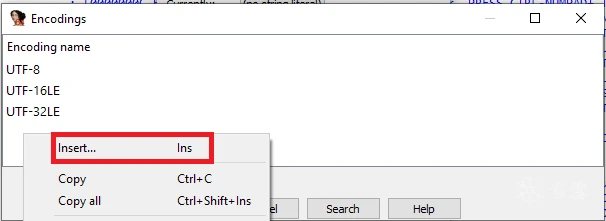
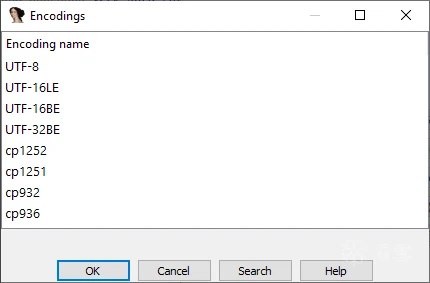
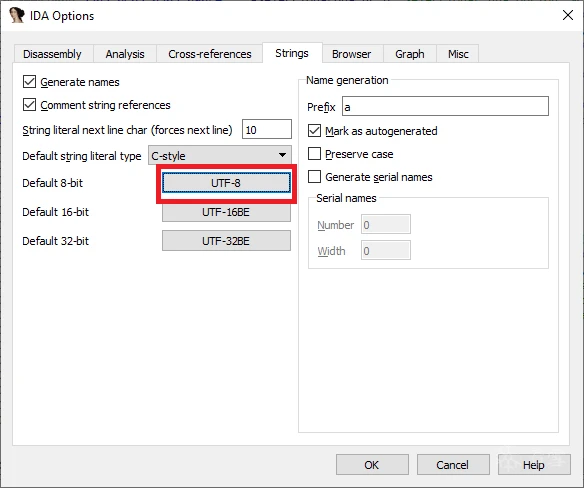
在默认列表中添加自定义编码(通常为 UTF-8、UTF-16LE 和 UTF-32LE):
编码名称可以使用
在 Linux 或 macOS 上,运行 iconv -l查看可用编码。
注意:并非所有系统都支持某些编码,因此你的 IDB 可能会因系统而异。
从现在起,快捷键 A 将使用新的默认编码创建字符串文本,但您仍可以根据具体情况覆盖它,如上所述。
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!