原本是朋友在调试一个看起来比较新的变速器驱动,整体来说支持两种变速模式,一种是进程级,这种用了HOOK,中规中矩的实现,原理网上都有。另一种是”系统级内核全局变速“,这个模式初步看了下有些特殊,已知的关键点没被修改,也没hook。比较好奇是怎么实现的,花了几天时间分析,也有一些有意思的地方,发个文章记录一下。
写了个简单的驱动,直接调用KeQueryPerformanceCounter会被加速,那么从这里入手应当没问题。
KeQueryPerformanceCounter网上其他相关文章或多或少都有涉及,只写一下关键调用路径:
核心逻辑在最后一层的HvlGetReferenceTimeUsingTscPage中,主要是读__rdtsc()然后做一些运算:
没开嵌套虚拟化,所以rdtsc肯定没被动手脚,调用链里涉及到的相关函数指针及代码确实都没修改。为了缩小范围及进一步排除,跳过前面几层,直接调用HvlGetReferenceTimeUsingTscPage,甚至把代码抠出来直接执行也是被加速,那么猫腻一定在这段代码里面,对其逻辑做一些分析简化:
unk3固定是0,那就等价于:count = (__rdtsc() * HvlpReferenceTscPage->factor) >> 64;
排除hook以及rdtsc,剩下唯一的可能就是改变了factor(HvlpReferenceTscPage + 8)。
多次观察验证:
看起来很简单,但实际上分析才刚刚开始。
当朋友按照这个结论去测试时,发现HvlpReferenceTscPage+8根本就没法改,可以读,但只要写入就会发生WHEA_UNCORRECTABLE_ERROR(0x124)蓝屏,我最初一直认为是写内存方式不对,但是朋友最后发现了一些规律:
当我也切换为HyperV,果然出现0x124蓝屏:
从蓝屏栈可以看到是写内存时发生MCE异常,VBS没开而且也不像是VBS的表现,应当是hypervisor发现某些异常后,主动向虚拟机内注入的MCE,触发原因可能是EPT物理页属性只读。
理论上有一种简单的解决办法:不要直接改HvlpReferenceTscPage+8,而是自己分配一块内存,然后把指针替换到HvlpReferenceTscPage。但样本驱动不是这么干的,应当有它的原因,比如PG或者为了隐蔽?具体什么原因不重要,最关键同时也最让我好奇的是,如果真的是因为EPT页只读触发的蓝屏,那样本驱动是怎么让页变成可写的?
正面硬刚VMP是下策,所以首先尝试的思路是对常用内存相关函数下断点,没看出变速驱动有什么特殊操作,就是普普通通的IoAllocateMDL + Map,传的参数与自己的测试代码也是一模一样。 那么这个驱动在写内存前,必然还有其他操作在配合。此时要么直面VMP,要么调试HyperV,没找到能用的VMP插件,调HyperV现实一点。
首先验证猜测,确认是不是因为EPT不可写而注入的MCE:
可以证实MCE蓝屏确实是因为物理页不可写导致,接下来的关键问题是要分析变速驱动是如何让GPA从只读变成可读写的。
理论上在没有通过EFI等方式Patch hvix64.exe的情况下,要从Guest内实现改变EPTP内的GPA属性就三种方式:
验证完自己能想到的两种方式但没有线索后,只能回到标准思路:
这个思路肯定行得通,但是仔细想一下,vmfunc(0)这种唯一无VMExit的方式可以排除,那么即使想不到它具体用的什么方式,也可以确定过程中一定会产生vmexit。
所以最终我用了一个偷懒的思路,统计未开启和开启加速时的vmexit事件,对比分析差异:
反复跑几遍,最后发现的规律是:
接下来就是具体分析这些rd/wrmsr,直接在guest_rip或者在HyperV这边的rd/wrmsr_exit_handler处下断点,再观察rd/wrmsr执行前/后VCPU ecx,edx,eax的值,就可以知道读写了哪些寄存器,以及读写的具体数据。
在HyperV的wrmsr_exit_handler处下断点,多次观察后首先发现这样一个规律:
如果只是读MSR倒也没什么,但写MSR比较可疑。搜一下MSR 0x40000021,找到这样两个相对比较有用的文档:
综合这些文档,可以知道以下关键信息:
结合这些信息和上面所说的变速驱动读写0x40000021的规律,可以进一步明确其每一步的含义:
此外还有一个最最关键的信息:
结合推测,变速驱动禁用reference tsc page的目的,很有可能是禁用后HyperV就会在EPT中将对应Page的从只读变为读写。
调整测试代码,在修改内存前也加上这个操作,终于可以顺利写入HvlpReferenceTscPage;同时也在HyperV这边进行验证:
解决这个页面写入问题之后,再次遇到新的问题:
原因是GuestOS内确实变速了,但Hypervisor这边没变,而GuestOS是将时钟设备配置为OneShot模式,在这种模式下,写到时钟设备的“到期时间”是一个绝对时间,这个绝对到期时间的计算方法是:HalpHvCounterQueryCounter() + ClockInterval,这里的HalpHvCounterQueryCounter其实等同于调用KeQueryPerfCounter(),所获取到的Counter值是10倍加速后的结果,而时钟设备是由Hypervisor模拟,Hypervisor这边的时间是以正常速度流逝,所以最终时钟到期时间会越来越晚,对于GuestOS来说就是时钟中断被大幅延迟,最终DPC/线程调度全部跟着延迟,分时系统遇到这种情况必然假死。
这个结论的分析和验证过程如下:
HOOK HalpClockTimer+0x80指向的HalpHvTimerArm确实也是一种解决办法,但样本驱动用了另一种方案:通过两个MSR接口,额外启动另一个时钟设备,并配置为period模式,周期为1ms。怎么发现的这两个MSR,绕了一圈最后还是通过VMEXIT统计对比发现的差异,变速样本驱动在写了0x40000021之后,会继续写0x400000B2/B3这两个MSR,只是VM运行过程中vmexit本身就比较频繁,这两个WRMSR退出事件和0x40000021中间还有一大堆其他vmexit,导致最初没注意到。
这两个MSR也是HyperV自己定义的,在前面的文档中一样有描述。主要用途其实跟LAPIC Timer差不多:
变速驱动主要是执行wrmsr(0x400000B2,0x1D1A);wrmsr(0x400000B3,0x2710),其中0x1D1A表示周期性模式+自动启用+Vector D1+DirectMode,Vector D1对应Windows的HalpTimerClockInterrupt,0x2710=1ms。这样的话即使Win自己配置到时钟设备的绝对时间是加速后的,但是变速驱动额外启动了1ms周期性时钟用于给OS维持稳定的心跳,最终就不会卡死。
至此就知道关键流程:
按照这个逻辑,就可以复刻变速驱动的“全局系统级变速”模式。
有心人可能会对0x40000021这个接口感兴趣,简单看了下应当不太好利用,因为当写入值bit 0为0时,wrmsr_handler_0x40000021其实并不是加上”W“权限,而是直接”恢复”原来的页映射。在HyperV里叫Overlay Page,简单理解就是贴一张新的A4纸到原来的纸上,如果要禁用,那就把贴上去的A4纸撕下来,将原来的A4纸原样“显示”出来,纸上的内容还是原来的样子。另外,虽然看起来可以通过0x40000021将任一Page贴到另一个Page之上,但是新Page权限以及Page中数据是由Hypervisor强制填充,即使自己先写好也会被清零。当然我没有深究,如果感兴趣的可以自己再调一下看看。
最后看一下(__rdtsc() * HvlpReferenceTscPage->factor) >> 64这个运算的意义及变速原理,Windows对factor的计算逻辑是:
传的参数是: unk(10000000i64, 0i64, 3.19xxxx, 0i64);
其中10000000是代码逻辑中写死的QPC频率;3.19xxxx是tsc频率;
这几行代码里面混着大数乘除法+定点浮点数,看着可能有点迷糊,但其实等价于:
我的机器tsc频率是3.2GHZ,按公式计算得到0xcccccccccccccc,有点怪,看到一串0xcc多少有点怀疑是不是哪搞错了,其次这个值与Win算出来的确实有点差异。
实际上是正确的,运算结果只是恰好等于0xcccccccccccccc而已,然后Win并不会通过CPUID/MSR去获取CPU的标称tsc频率,而是在启动时候用一个很短的时间去动态测算CPU的真实tsc频率,算出来的频率会是3.19xxxxxxxxGHZ,而不是标称3.2G,那么最终多少会有点误差。
这个运算的目的则是在CPU的tsc频率与Win的QPC频率之间算一个系数,用于频率转换,因为QPC在新一点的机器上一般都是建立在TSC基础之上(CPU要支持iTSC),在支持iTSC的情况下,QPC频率是代码写死的固定10MHZ,TSC频率却取决于CPU,tsc频率肯定不会等于10Mhz,那么必然要在中间做一层转换。至于为什么还要乘以2^64,因为如果不这么干,那就不可避免要涉及到浮点数运算有性能代价,不想用浮点数,又想保留小数点确保精度,最终就引入了定点数。VMX的tsc scaling也一样,只不过用的是2^48,微软直接用了2^64。
按照2^64 * qpc_freq / tsc_freq计算出factor之后,就可以通过逆运算 __rdtsc()*factor>>64 得到以10MHZ为基准的QPC计数值。将Factor调大,自然也就可以实现倍速,本质上跟以前的修改kuser_data差不多,都是干扰参与计算的数据,最终改变计算结果,只是修改的位置不同;
3. 以上MSR仅在虚拟机模式才有,但变速驱动在物理机上用的也是类似的方式,只是改了KeQueryPerfCounter所使用的另一个page中的factor,与虚拟机场景有一些差异,但基本也是一样的rdtsc*factor>>64运算逻辑,而且更简单,因为看了下我的物理机上本身时钟模式就是Period,实测物理机上似乎也并不会出现假死问题;
4. 至于检测,本地检测最简单的方式就是按照公式结合tsc频率,计算出原始值然后对比,但要注意的是Windows是动态计算出的tsc频率,理论上原始factor值本身就有一定误差,所以如果仅仅只进行极低倍率的变速,有可能会误判;
5. 如果直接用IDA F5去看HyperV的vcpu_run_loop函数,在某些版本的HyperV上可能看不到正确逻辑,因为紧跟VMResume和VMLanuch的一条跳转指令对IDA F5有一定干扰;
6. vcpu_run_loop与vmexit_dispatch:
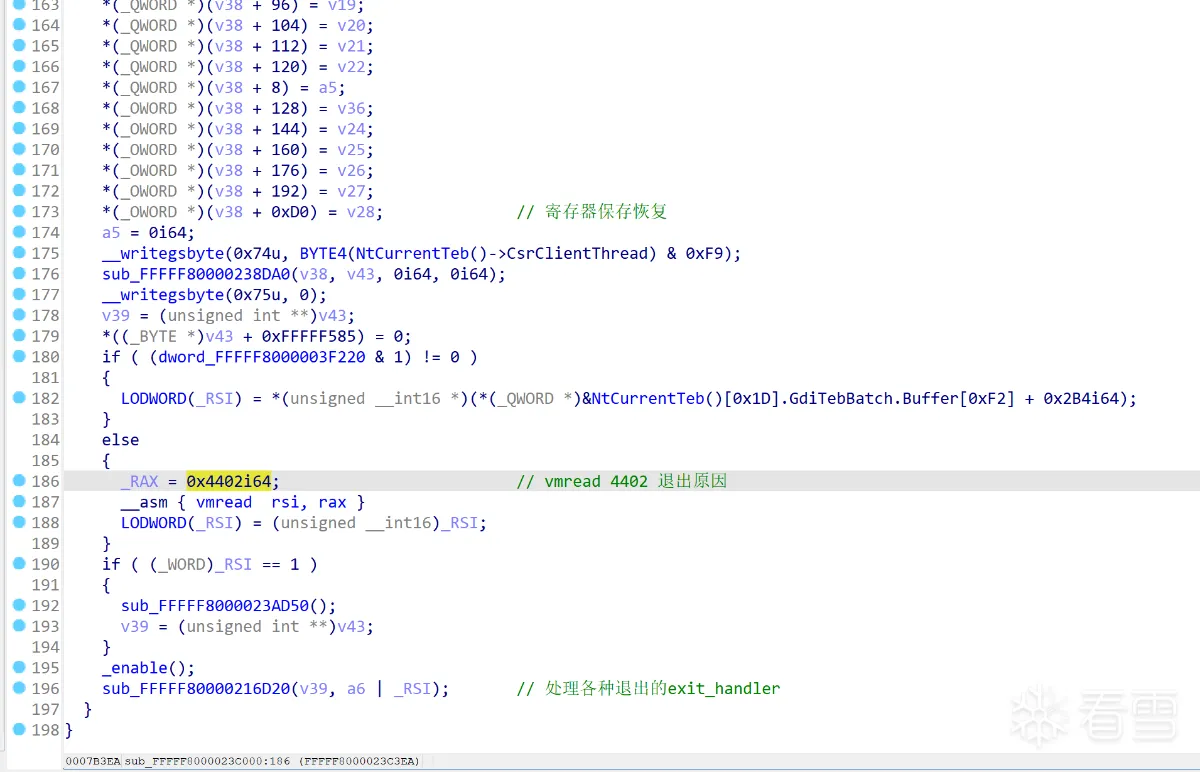
搜索0x4402常量定位vcpu循环线程:
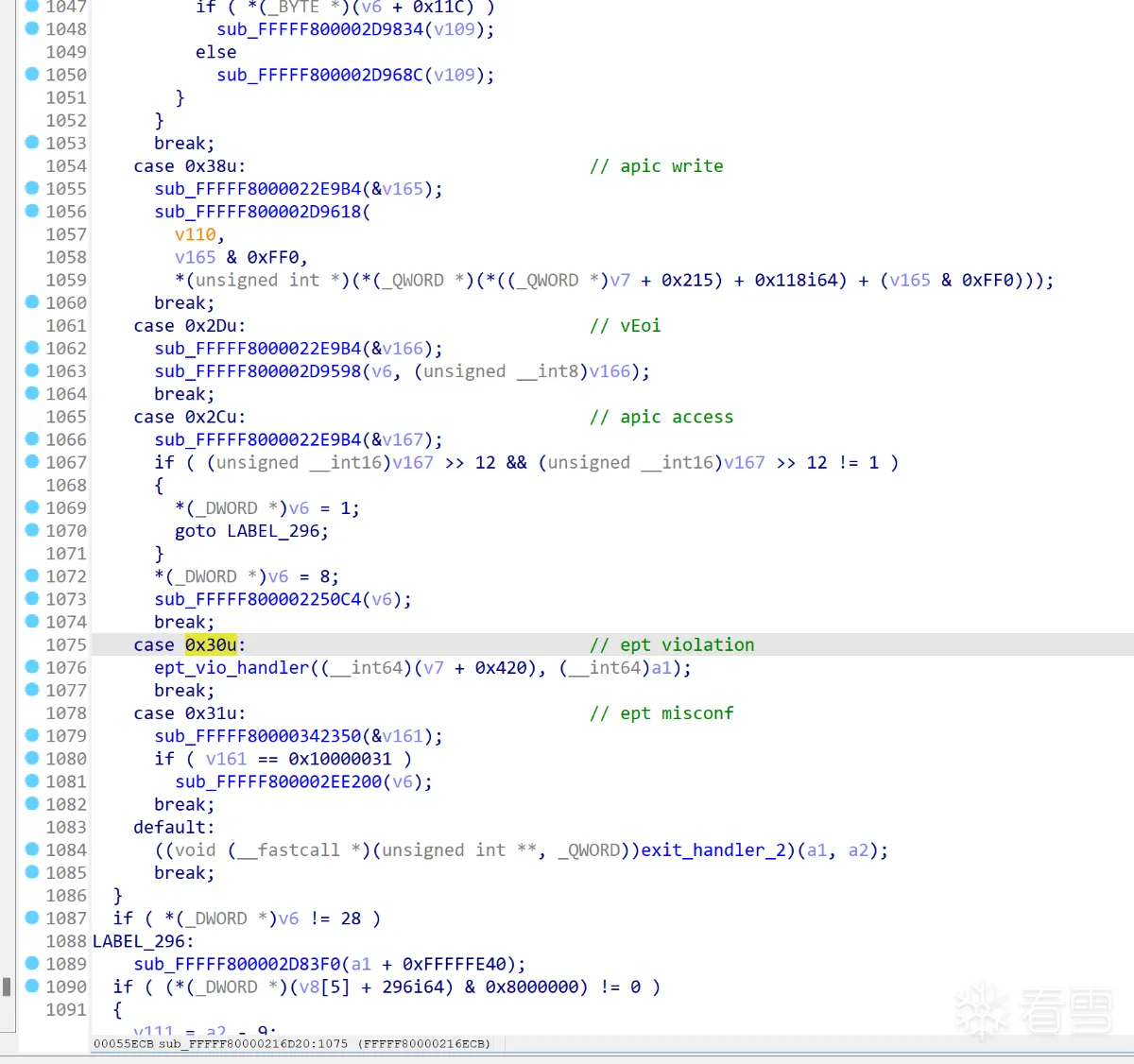
vmeixt_dispatch内针对各种vmexit的处理,根据switch_case定位各种exit的处理函数:
KeQueryPerformanceCounter
HalpPerformanceCounter + 0x70;
HalpHvCounterQueryCounter
HalpHvTimerApi
HvlGetReferenceTimeUsingTscPage
KeQueryPerformanceCounter
HalpPerformanceCounter + 0x70;
HalpHvCounterQueryCounter
HalpHvTimerApi
HvlGetReferenceTimeUsingTscPage
__int64 __fastcall HvlGetReferenceTimeUsingTscPage(int a1, __int64 a2)
{
v2 = __rdtsc();
LODWORD(a2) = HIDWORD(v2);
v2 = (unsigned int)v2;
a2 = (unsigned int)a2;
a2 = *((_QWORD *)HvlpReferenceTscPage + 2)
+ (((v2 | (a2 << 32)) * (unsigned __int128)*((unsigned __int64 *)HvlpReferenceTscPage + 1)) >> 64);
v5 = a2;
a1 = *(_DWORD *)HvlpReferenceTscPage;
if ( *(_DWORD *)HvlpReferenceTscPage == v3 )
return v5;
}
__int64 __fastcall HvlGetReferenceTimeUsingTscPage(int a1, __int64 a2)
{
v2 = __rdtsc();
LODWORD(a2) = HIDWORD(v2);
v2 = (unsigned int)v2;
a2 = (unsigned int)a2;
a2 = *((_QWORD *)HvlpReferenceTscPage + 2)
+ (((v2 | (a2 << 32)) * (unsigned __int128)*((unsigned __int64 *)HvlpReferenceTscPage + 1)) >> 64);
v5 = a2;
a1 = *(_DWORD *)HvlpReferenceTscPage;
if ( *(_DWORD *)HvlpReferenceTscPage == v3 )
return v5;
}
struct HvRTP
{
uint32_t unk1;
uint32_t unk2;
uint64_t factor;
uint64_t unk3;
//........
};
//上面IDA伪代码中的HvlpReferenceTscPage大致就是上面这么一个结构体指针, 核心逻辑简化后等价于:
__int64 __fastcall HvlGetReferenceTimeUsingTscPage()
{
count = HvlpReferenceTscPage->unk3 + (__rdtsc() * HvlpReferenceTscPage->factor) >> 64;
return count;
}
struct HvRTP
{
uint32_t unk1;
uint32_t unk2;
uint64_t factor;
uint64_t unk3;
//........
};
//上面IDA伪代码中的HvlpReferenceTscPage大致就是上面这么一个结构体指针, 核心逻辑简化后等价于:
__int64 __fastcall HvlGetReferenceTimeUsingTscPage()
{
count = HvlpReferenceTscPage->unk3 + (__rdtsc() * HvlpReferenceTscPage->factor) >> 64;
return count;
}
8: kd> k
00 ffffbf81`3a347918 fffff807`276f7adb nt!KeBugCheckEx
01 ffffbf81`3a347920 fffff807`24db1740 nt!HalBugCheckSystem+0xeb
02 ffffbf81`3a347960 fffff807`27826c93 PSHED!PshedBugCheckSystem+0x10
03 ffffbf81`3a347990 fffff807`276f9411 nt!WheaReportHwError+0x393
04 ffffbf81`3a347a60 fffff807`276f9858 nt!HalpMcaReportError+0xb1
05 ffffbf81`3a347bc0 fffff807`276f96f0 nt!HalpMceHandlerCore+0x134
06 ffffbf81`3a347c20 fffff807`276f9922 nt!HalpMceHandler+0xe0
07 ffffbf81`3a347c60 fffff807`276f8bd6 nt!HalpMceHandlerWithRendezvous+0x62
08 ffffbf81`3a347c90 fffff807`276fb4fb nt!HalpHandleMachineCheck+0x62
09 ffffbf81`3a347cc0 fffff807`27756e39 nt!HalHandleMcheck+0x3b
0a ffffbf81`3a347cf0 fffff807`276281be nt!KiHandleMcheck+0x9
0b ffffbf81`3a347d20 fffff807`27627de8 nt!KxMcheckAbort+0x7e
0c ffffbf81`3a347e60 fffff807`430a72eb nt!KiMcheckAbort+0x2a8
8: kd> k
00 ffffbf81`3a347918 fffff807`276f7adb nt!KeBugCheckEx
01 ffffbf81`3a347920 fffff807`24db1740 nt!HalBugCheckSystem+0xeb
02 ffffbf81`3a347960 fffff807`27826c93 PSHED!PshedBugCheckSystem+0x10
03 ffffbf81`3a347990 fffff807`276f9411 nt!WheaReportHwError+0x393
04 ffffbf81`3a347a60 fffff807`276f9858 nt!HalpMcaReportError+0xb1
05 ffffbf81`3a347bc0 fffff807`276f96f0 nt!HalpMceHandlerCore+0x134
06 ffffbf81`3a347c20 fffff807`276f9922 nt!HalpMceHandler+0xe0
07 ffffbf81`3a347c60 fffff807`276f8bd6 nt!HalpMceHandlerWithRendezvous+0x62
08 ffffbf81`3a347c90 fffff807`276fb4fb nt!HalpHandleMachineCheck+0x62
09 ffffbf81`3a347cc0 fffff807`27756e39 nt!HalHandleMcheck+0x3b
0a ffffbf81`3a347cf0 fffff807`276281be nt!KiHandleMcheck+0x9
0b ffffbf81`3a347d20 fffff807`27627de8 nt!KxMcheckAbort+0x7e
0c ffffbf81`3a347e60 fffff807`430a72eb nt!KiMcheckAbort+0x2a8
unsigned __int64 unk(__int64 a1, unsigned __int64 a2, unsigned __int64 a3, __int64 *a4)
{
__int64 v7; // rdi
__int64 v8; // rcx
__int64 v9; // r9
__int64 v10; // rdx
__int64 v11; // rbx
v7 = 64i64;
do
{
v8 = 2 * a2;
v9 = (2 * a1) | (a2 >> 63);
v10 = a1 >> 63;
a1 = v9 - a3;
v11 = 2 * a2;
if ( (v10 | (unsigned __int64)v9) < a3 )
a1 = v9;
a2 = v11 | 1;
if ( (v10 | (unsigned __int64)v9) < a3 )
a2 = v8;
--v7;
}
while ( v7 );
if ( a4 )
*a4 = a1;
return a2;
}
unsigned __int64 unk(__int64 a1, unsigned __int64 a2, unsigned __int64 a3, __int64 *a4)
{
__int64 v7; // rdi
__int64 v8; // rcx
__int64 v9; // r9
__int64 v10; // rdx
__int64 v11; // rbx
v7 = 64i64;
do
{
v8 = 2 * a2;
v9 = (2 * a1) | (a2 >> 63);
v10 = a1 >> 63;
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2023-10-5 12:43
被lidowx编辑
,原因: 加两个图








