-
-
[原创]Metasploit Framework载荷生成过程源码分析
-
发表于: 2022-4-7 10:50 12662
-

在MSF中,当执行run指令开始运行一个exploit模块时lib/msf/core/encoded_payload.rb文件中的Msf::EncodedPayload#generate会被调用,目的是根据用户的配置生成指定的载荷. 该方法的调用流程是: generate_raw => encode => generate_sled => {self.encoded = (self.nop_sled || '') + self.encoded}, 最终载荷的组成是nop雪橇 + 解码器存根(除去最后的0-4个字节, 这些拼到payload中来对齐) + 编码后的payload.
Msf::EncodedPayload#encode: 如果没有指定encoder, 这个方法会依次尝试符合cpu架构和平台架构的各个编码器. 每个编码器都可能对载荷进行反复编码(用户可指定迭代次数). 如果编码成功了(载荷中没有坏字节, 载荷的大小(包含nop滑板)大于要求的最小字节数), 则停止编码.
Msf::Encoder#encode -> do_encode -> MetasploitModule#decoder_stub => MetasploitModule#encode_block. 后面这两个方法产生的字符串拼接起来得到编码后的payload. 各个编码器都会覆写这两个方法. 不同编码器会实现一个MetasploitModule类. 下面以x86/shikata_ga_nai编码器为例:
由decoder_stub生成的解码器存根中, 有一个"XORK"的标志, 这个标志是给key占位的. 把它替换成一个real_key, 即一个在encode方法中调用obtain_key方法生成的, 不带坏字节的key. 这个key是在编码中加密用的.
将生成的存根(替换上real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:
将原始payload按4个字节一个block, 使用encode_block进行编码(不够4字节时在末尾用0填充).
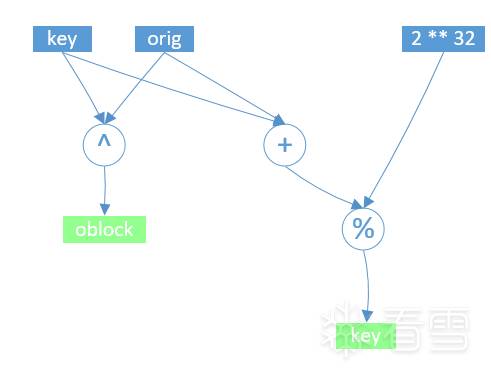
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示. orig是原始字节(4字节). oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
Msf::EncodedPayload#generate_sled: 生成nop雪橇, 会加在编码后的payload前面. 如下为一个最简单的nop雪橇生成器:
用了6年Ruby,最近终于回想起来当初学习它的初衷...
mov esi,0xbf9f2758 ; 第二个操作数为real_key
fcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址
pop ebx ; sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b
; 偏移0x10, 循环体的开始处
xor [ebx+0x12],esi ; 0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码
add ebx,byte +0x4
db 0x03
; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx + 0x12] ; 原始数据和第一个key相加, 得到下一个key
; loop 0x10 ; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部
mov esi,0xbf9f2758 ; 第二个操作数为real_key
fcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址
pop ebx ; sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b
; 偏移0x10, 循环体的开始处
xor [ebx+0x12],esi ; 0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码
add ebx,byte +0x4
db 0x03
; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx + 0x12] ; 原始数据和第一个key相加, 得到下一个key
; loop 0x10 ; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部
ESP[0]: FPUControlWord;
ESP[4]: FPUStatusWord;
ESP[8]: FPUTagWord;
ESP[0x0c]: FPUDataPointer; // 指向上一条FPU指令
ESP[0x10]: FPUInstructionPointer;
ESP[0x14]: FPULastInstructionOpcode;
ESP[0]: FPUControlWord;
ESP[4]: FPUStatusWord;
ESP[8]: FPUTagWord;
ESP[0x0c]: FPUDataPointer; // 指向上一条FPU指令
ESP[0x10]: FPUInstructionPointer;
ESP[0x14]: FPULastInstructionOpcode;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mov esi,0xbf9f2758 ; 第二个操作数为real_key
fcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址
pop ebx ; sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b
; 偏移0x10, 循环体的开始处
xor [ebx+0x12],esi ; 0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码
add ebx,byte +0x4
db 0x03
; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx + 0x12] ; 原始数据和第一个key相加, 得到下一个key
; loop 0x10 ; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部
|
|
1
2
3
4
5
6
|
ESP[0]: FPUControlWord;
ESP[4]: FPUStatusWord;
ESP[8]: FPUTagWord;
ESP[0x0c]: FPUDataPointer; // 指向上一条FPU指令
ESP[0x10]: FPUInstructionPointer;
ESP[0x14]: FPULastInstructionOpcode;
|
- 在Metasploit中,一段编码载荷的总体生成流程是:
- 将不同汇编代码片段组成载荷汇编代码,并编译成机器码。
- 生成解码器存根。
- 将原始载荷机器码按4字节对齐,并用编码器编码。
- 生成nop雪橇。
- 最终shellcode:nop雪橇 + 解码器存根(除去最后的0-4个字节, 这些拼到payload中来对齐) + 编码后的payload。
- 编码器: 用于消除载荷中的坏字节(如'\x00'), 以及为载荷编码。而去除坏字节的方式即是进行编码,而非传统的将push 0替换成xor ecx, ecx和push ecx这样的方法。
- 如果在栈溢出时是将shellcode放到栈上从栈顶开始往下的位置,则在使用shikata_ga_nai编码器时需要使用nop雪橇,因为该编码器将获取的FpuSaveState结构体数据放到了栈上,且会覆盖栈顶以下多个字节,所以需要通过nop雪橇提供足够的空间,避免覆盖了shellcode。
- a -> b: 表示方法a调用了方法b
- a => b: 表示先调用方法a再调用方法b
- a -> b => c: 表示在方法a的实现中, 依次调用了b和c
- a => {...}: 花括号中是Ruby语句
- M1::C1#f1: 表示模块M1下的C1类的实例方法f1
- M1::C1.f1: 表示模块M1下的C1类的类方法f1
-
在MSF中,当执行
run指令开始运行一个exploit模块时lib/msf/core/encoded_payload.rb文件中的Msf::EncodedPayload#generate会被调用,目的是根据用户的配置生成指定的载荷. 该方法的调用流程是:generate_raw=>encode=>generate_sled=> {self.encoded = (self.nop_sled || '') + self.encoded}, 最终载荷的组成是nop雪橇 + 解码器存根(除去最后的0-4个字节, 这些拼到payload中来对齐) + 编码后的payload.-
Msf::EncodedPayload#generate_raw->generate_complete->Msf::Payload::Windows::ReverseTcp.generate->generate_reverse_tcp: 产生汇编代码, 并通过Metasm::Shellcode.assemble(Metasm::X86.new, combined_asm).encode_string进行汇编得到字节码. -
Msf::EncodedPayload#encode: 如果没有指定encoder, 这个方法会依次尝试符合cpu架构和平台架构的各个编码器. 每个编码器都可能对载荷进行反复编码(用户可指定迭代次数). 如果编码成功了(载荷中没有坏字节, 载荷的大小(包含nop滑板)大于要求的最小字节数), 则停止编码.-
Msf::Encoder#encode->do_encode->MetasploitModule#decoder_stub=>MetasploitModule#encode_block. 后面这两个方法产生的字符串拼接起来得到编码后的payload. 各个编码器都会覆写这两个方法. 不同编码器会实现一个MetasploitModule类. 下面以x86/shikata_ga_nai编码器为例:-
decoder_stub: 生成解码器存根. 各个编码器会独立实现该方法. 在该方法的上下文中,state.orig_buf为未编码payload,state.buf最后会保存编码后的payload.-
generate_shikata_block:- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 创建了大量
- 解码器存根的后几个字节会被切出, 放到
state.buf开头. 其目的是使state.buf以4字节对齐.
-
-
由
decoder_stub生成的解码器存根中, 有一个"XORK"的标志, 这个标志是给key占位的. 把它替换成一个real_key, 即一个在encode方法中调用obtain_key方法生成的, 不带坏字节的key. 这个key是在编码中加密用的.-
将生成的存根(替换上
real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:1234567891011121314mov esi,0xbf9f2758; 第二个操作数为real_keyfcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址pop ebx ;sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b; 偏移0x10, 循环体的开始处xor [ebx+0x12],esi ;0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码add ebx,byte+0x4db0x03; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx+0x12] ; 原始数据和第一个key相加, 得到下一个key; loop0x10; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部 - 如下为28字节的FPU环境变量结构体(引用自: https://www.boozallen.com/insights/cyber/shellcode/shikata-ga-nai-encoder.html)123456
ESP[0]: FPUControlWord;ESP[4]: FPUStatusWord;ESP[8]: FPUTagWord;ESP[0x0c]: FPUDataPointer;//指向上一条FPU指令ESP[0x10]: FPUInstructionPointer;ESP[0x14]: FPULastInstructionOpcode;
-
-
将原始payload按4个字节一个block, 使用
encode_block进行编码(不够4字节时在末尾用0填充).-
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示.orig是原始字节(4字节).oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
-
-
-
-
Msf::EncodedPayload#generate_sled: 生成nop雪橇, 会加在编码后的payload前面. 如下为一个最简单的nop雪橇生成器:-
modules/nops/x86/single_byte.rb- 从一堆无用指令中取一定数量指令, 比如:
nop;xchg eax,edi;cdq;dec ebp;inc edi;aaa;daa;das;cld;std;clc;stc;cmc;cwde;lahf;wait;salc等
- 从一堆无用指令中取一定数量指令, 比如:
-
-
-
用了6年Ruby,最近终于回想起来当初学习它的初衷...
-
Msf::EncodedPayload#generate_raw->generate_complete->Msf::Payload::Windows::ReverseTcp.generate->generate_reverse_tcp: 产生汇编代码, 并通过Metasm::Shellcode.assemble(Metasm::X86.new, combined_asm).encode_string进行汇编得到字节码. -
Msf::EncodedPayload#encode: 如果没有指定encoder, 这个方法会依次尝试符合cpu架构和平台架构的各个编码器. 每个编码器都可能对载荷进行反复编码(用户可指定迭代次数). 如果编码成功了(载荷中没有坏字节, 载荷的大小(包含nop滑板)大于要求的最小字节数), 则停止编码.-
Msf::Encoder#encode->do_encode->MetasploitModule#decoder_stub=>MetasploitModule#encode_block. 后面这两个方法产生的字符串拼接起来得到编码后的payload. 各个编码器都会覆写这两个方法. 不同编码器会实现一个MetasploitModule类. 下面以x86/shikata_ga_nai编码器为例:-
decoder_stub: 生成解码器存根. 各个编码器会独立实现该方法. 在该方法的上下文中,state.orig_buf为未编码payload,state.buf最后会保存编码后的payload.-
generate_shikata_block:- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 创建了大量
- 解码器存根的后几个字节会被切出, 放到
state.buf开头. 其目的是使state.buf以4字节对齐.
-
-
由
decoder_stub生成的解码器存根中, 有一个"XORK"的标志, 这个标志是给key占位的. 把它替换成一个real_key, 即一个在encode方法中调用obtain_key方法生成的, 不带坏字节的key. 这个key是在编码中加密用的.-
将生成的存根(替换上
real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:1234567891011121314mov esi,0xbf9f2758; 第二个操作数为real_keyfcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址pop ebx ;sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b; 偏移0x10, 循环体的开始处xor [ebx+0x12],esi ;0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码add ebx,byte+0x4db0x03; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx+0x12] ; 原始数据和第一个key相加, 得到下一个key; loop0x10; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部 - 如下为28字节的FPU环境变量结构体(引用自: https://www.boozallen.com/insights/cyber/shellcode/shikata-ga-nai-encoder.html)123456
ESP[0]: FPUControlWord;ESP[4]: FPUStatusWord;ESP[8]: FPUTagWord;ESP[0x0c]: FPUDataPointer;//指向上一条FPU指令ESP[0x10]: FPUInstructionPointer;ESP[0x14]: FPULastInstructionOpcode;
-
-
将原始payload按4个字节一个block, 使用
encode_block进行编码(不够4字节时在末尾用0填充).-
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示.orig是原始字节(4字节).oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
-
-
-
-
Msf::EncodedPayload#generate_sled: 生成nop雪橇, 会加在编码后的payload前面. 如下为一个最简单的nop雪橇生成器:-
modules/nops/x86/single_byte.rb- 从一堆无用指令中取一定数量指令, 比如:
nop;xchg eax,edi;cdq;dec ebp;inc edi;aaa;daa;das;cld;std;clc;stc;cmc;cwde;lahf;wait;salc等
- 从一堆无用指令中取一定数量指令, 比如:
-
-
Msf::Encoder#encode->do_encode->MetasploitModule#decoder_stub=>MetasploitModule#encode_block. 后面这两个方法产生的字符串拼接起来得到编码后的payload. 各个编码器都会覆写这两个方法. 不同编码器会实现一个MetasploitModule类. 下面以x86/shikata_ga_nai编码器为例:-
decoder_stub: 生成解码器存根. 各个编码器会独立实现该方法. 在该方法的上下文中,state.orig_buf为未编码payload,state.buf最后会保存编码后的payload.-
generate_shikata_block:- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 创建了大量
- 解码器存根的后几个字节会被切出, 放到
state.buf开头. 其目的是使state.buf以4字节对齐.
-
-
由
decoder_stub生成的解码器存根中, 有一个"XORK"的标志, 这个标志是给key占位的. 把它替换成一个real_key, 即一个在encode方法中调用obtain_key方法生成的, 不带坏字节的key. 这个key是在编码中加密用的.-
将生成的存根(替换上
real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:1234567891011121314mov esi,0xbf9f2758; 第二个操作数为real_keyfcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址pop ebx ;sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b; 偏移0x10, 循环体的开始处xor [ebx+0x12],esi ;0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码add ebx,byte+0x4db0x03; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx+0x12] ; 原始数据和第一个key相加, 得到下一个key; loop0x10; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部 - 如下为28字节的FPU环境变量结构体(引用自: https://www.boozallen.com/insights/cyber/shellcode/shikata-ga-nai-encoder.html)123456
ESP[0]: FPUControlWord;ESP[4]: FPUStatusWord;ESP[8]: FPUTagWord;ESP[0x0c]: FPUDataPointer;//指向上一条FPU指令ESP[0x10]: FPUInstructionPointer;ESP[0x14]: FPULastInstructionOpcode;
-
-
将原始payload按4个字节一个block, 使用
encode_block进行编码(不够4字节时在末尾用0填充).-
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示.orig是原始字节(4字节).oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
-
-
-
decoder_stub: 生成解码器存根. 各个编码器会独立实现该方法. 在该方法的上下文中,state.orig_buf为未编码payload,state.buf最后会保存编码后的payload.-
generate_shikata_block:- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 创建了大量
- 解码器存根的后几个字节会被切出, 放到
state.buf开头. 其目的是使state.buf以4字节对齐.
-
-
由
decoder_stub生成的解码器存根中, 有一个"XORK"的标志, 这个标志是给key占位的. 把它替换成一个real_key, 即一个在encode方法中调用obtain_key方法生成的, 不带坏字节的key. 这个key是在编码中加密用的.-
将生成的存根(替换上
real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:1234567891011121314mov esi,0xbf9f2758; 第二个操作数为real_keyfcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址pop ebx ;sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b; 偏移0x10, 循环体的开始处xor [ebx+0x12],esi ;0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码add ebx,byte+0x4db0x03; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx+0x12] ; 原始数据和第一个key相加, 得到下一个key; loop0x10; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部 - 如下为28字节的FPU环境变量结构体(引用自: https://www.boozallen.com/insights/cyber/shellcode/shikata-ga-nai-encoder.html)123456
ESP[0]: FPUControlWord;ESP[4]: FPUStatusWord;ESP[8]: FPUTagWord;ESP[0x0c]: FPUDataPointer;//指向上一条FPU指令ESP[0x10]: FPUInstructionPointer;ESP[0x14]: FPULastInstructionOpcode;
-
-
将原始payload按4个字节一个block, 使用
encode_block进行编码(不够4字节时在末尾用0填充).-
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示.orig是原始字节(4字节).oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
-
-
generate_shikata_block:- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 创建了大量
- 解码器存根的后几个字节会被切出, 放到
state.buf开头. 其目的是使state.buf以4字节对齐.
- 创建了大量
Rex::Poly::LogicalBlock实例:- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 每个这类实例中有
-
Rex::Poly::LogicalRegister实例: 用于代表特定cpu架构下的寄存器编码.- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
- 初始化:
-
loop_inst.generate: 反复执行Rex::Poly::Permutation#do_generate, 直到其返回值buf中没有坏字节.-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
- 每个这类实例中有
@perms列表(实例初始化的时候, 二参及以后的参数形成的列表转为@perms), 列表中的每一项代表一条可选的指令. -
@perms的元素既可以是代表机器码的字符串, 也可以是Proc实例(它们可通过调用Proc#call返回代表机器码的字符串). - 使用
Rex::Poly::LogicalBlock#rand_perm方法可随机选@perms中的一条指令. -
Rex::Poly::LogicalBlock#depends_on使这些实例关联起来. 其中一个实例为loop_inst, 而代码行loop_inst.generate(block_generator_register_blacklist, nil, state.badchars)则是用它生成"多态缓存"(polymorphic buffer), 在generate中该实例以及通过depends_on关联起来的实例都会被用到.
- 初始化:
count_reg = Rex::Poly::LogicalRegister::X86.new('count', 'ecx'), 其中二参'ecx'会传给Rex::Arch::X86.reg_number, 这个方法将'ecx'先转为大写, 然后传给Ruby的原生方法Object#const_get, 这个方法会查询Rex::Arch::X86模块中定义的常量, 最终找到Rex::Arch::X86::ECX常量, 其值即为ecx寄存器编码. - 在block实例中调用
regnum_of(<Rex::Poly::LogicalRegister实例>), 可得到对应的寄存器编码.
-
generate_block_list(state, level): 采用递归的方法生成一个state.block_list列表.- 对当前block实例的
@depends列表中的每个block调用generate_block_list方法, 把得到的结果附加到state.block_list列表. - 把
[ self, perm ]附加到state.block_list列表.self是本block变量,perm是用rand_perm生成的. - 同1, 不过
@depends变为@next_blocks.
- 对当前block实例的
- 迭代上一步得到
block_list列表, 把每一项中的perm转成对应的指令机器码, 拼接到state.buffer, 得到解码器存根的机器代码.
-
将生成的存根(替换上
real_key之后)反汇编(可用Rex::Assembly::Nasm.disassemble方法,并用puts打印), 可看到如下汇编代码:1234567891011121314mov esi,0xbf9f2758; 第二个操作数为real_keyfcmovu st5 ; 目的是将FPUDataPointer填充到上述结构体. (执行任意fpu指令都可达到此目的)fnstenv [esp-0xc] ; 把FpuSaveState结构体保存到栈上的esp-0xC处, 则栈顶会保存FPUDataPointer, 即上面fcmovu指令的地址pop ebx ;sub ecx,ecx ; ecx置零, 作为循环计数器mov cl,0x4b; 偏移0x10, 循环体的开始处xor [ebx+0x12],esi ;0x12即是上面fcmovu指令的地址到这段存根的下一个字节的地址的距离, 所以这条指令即是对编码部分的前4个字节开始解码add ebx,byte+0x4db0x03; 这段存根少了loop指令, 会在上面xor后还原出来, 如下:; add esi, [ebx+0x12] ; 原始数据和第一个key相加, 得到下一个key; loop0x10; 机器码是\xe2\xf5, \xf5应该是表示从loop指令的下一条指令的地址开始减去11, 得到的地址即为循环头部 - 如下为28字节的FPU环境变量结构体(引用自: https://www.boozallen.com/insights/cyber/shellcode/shikata-ga-nai-encoder.html)123456
ESP[0]: FPUControlWord;ESP[4]: FPUStatusWord;ESP[8]: FPUTagWord;ESP[0x0c]: FPUDataPointer;//指向上一条FPU指令ESP[0x10]: FPUInstructionPointer;ESP[0x14]: FPULastInstructionOpcode;
-
encode_block: 使用的是从Msf::Encoder::XorAdditiveFeedback中继承的encode_block编码方法. 算法如下图所示.orig是原始字节(4字节).oblock是输出的编码后的4字节. 将key和orig相加后截取低4个字节, 作为下一轮编码用的key.
-
modules/nops/x86/single_byte.rb- 从一堆无用指令中取一定数量指令, 比如:
nop;xchg eax,edi;cdq;dec ebp;inc edi;aaa;daa;das;cld;std;clc;stc;cmc;cwde;lahf;wait;salc等
- 从一堆无用指令中取一定数量指令, 比如:
[招生]科锐逆向工程师培训(2024年11月15日实地,远程教学同时开班, 第51期)
赞赏





