本文将以多个真实的堆相关的漏洞以及一些高质量的研究文章为例,介绍在真实漏洞场景下的堆利用技巧,主要是介绍各种现实漏洞场景的堆布局技巧。
vuln obj : 存在漏洞的对象,比如存在堆溢出的对象。
target obj: 漏洞利用时需要篡改的对象,比如利用堆溢出时,我们想覆盖的对象。
GitHub & BLOG
当来利用堆溢出的时候,我们需要找一个 gadget object 来进行利用
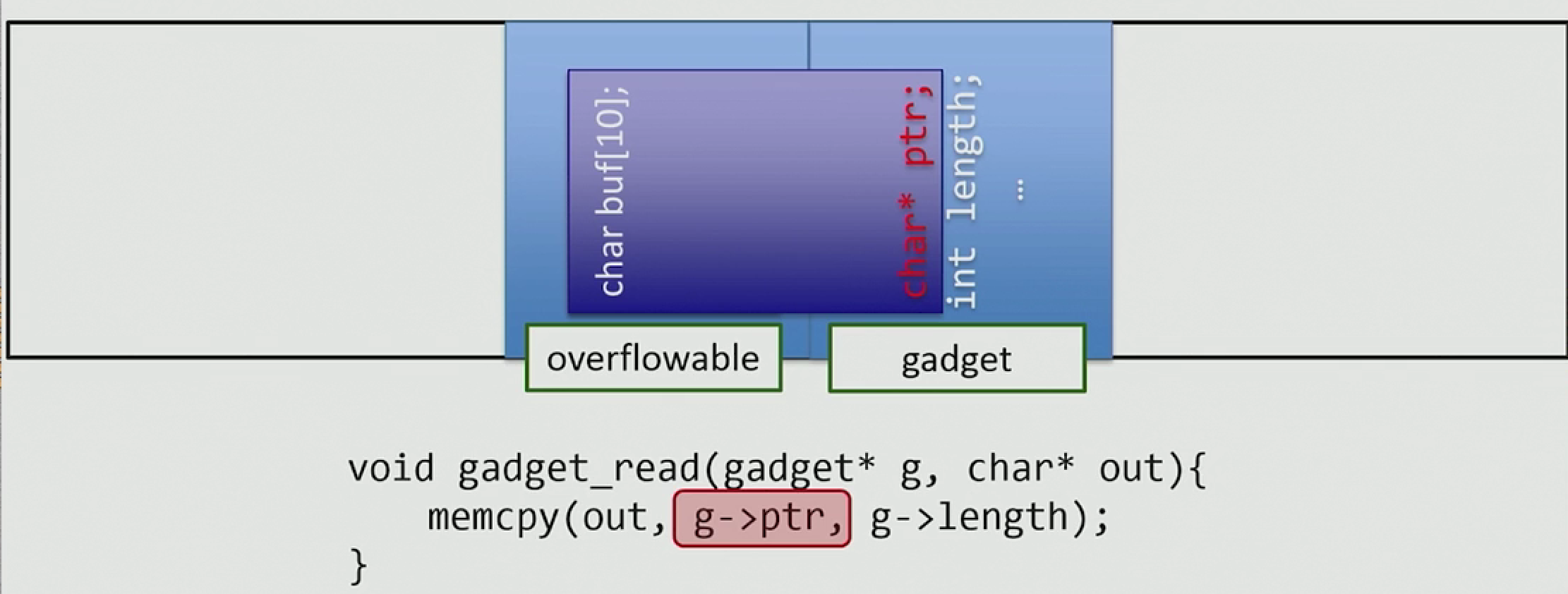
常用的 gadget object 类型:
此外利用堆漏洞非常重要的是进行堆布局,为了进行堆布局我们需要找到外部输入可控的内存操作原语,搜索内存操作原语时需要关注三个要素:
然后根据不同的内存控制原语采用合适方式进行堆布局,常见搜索内存操作原语的思路是在代码中找含有malloc,new,realloc,std::vector,std::string的调用点,然后判断是否可以由外部输入触发。
作者提到进行堆布局的时候,可以选用占位式堆喷,如图所示:
此外为了提升溢出到 gadget 的概率我们可以先把内存碎片清理了,然后再进行占位式堆喷,这样 vuln obj 和 gadget obj 大概率会相邻分配。
如果分配 gadget object 的时候会有一些小对象的分配从而导致影响内存布局,我们可以先在堆上占位一些小的内存块,然后在分配 gadget 前释放一些小的内存块,这样小对象就会落在之前占位的小内存块中,避免影响 vuln obj 和 gadget object 之间的布局。

Assuming the gadget object is the one which allocates the unwanted allocations, one way to deal with this issue is to do the following:
漏洞是一个整数溢出导致的堆溢出
在分配内存前有一个检查,但由于 chunk_size 在 32 位系统下下也是 uint64_t 的,所以当 chunk_size > SIZE_MAX 时(比如 0xFFFFFFFFFFFFFFFF),会通过检查,然后下面分配的时候就会整数溢出。
从文件中解析 chunk_size 的代码如下
因此通过这个漏洞我们可以实现一个堆溢出,vuln obj 的大小可控,溢出的内容可控,由于是整数溢出后面可能会拷贝大量的数据(比如 0xFFFFFFFFFFFFFFFF),最终可能会由于访问到没有映射的内存导致进程崩溃。
因此,利用这种类型的整数溢出漏洞,我们需要找到一些路径,让溢出发生后,不会拷贝过量的数据,对于这个漏洞来说我们可能有以下两种方式:
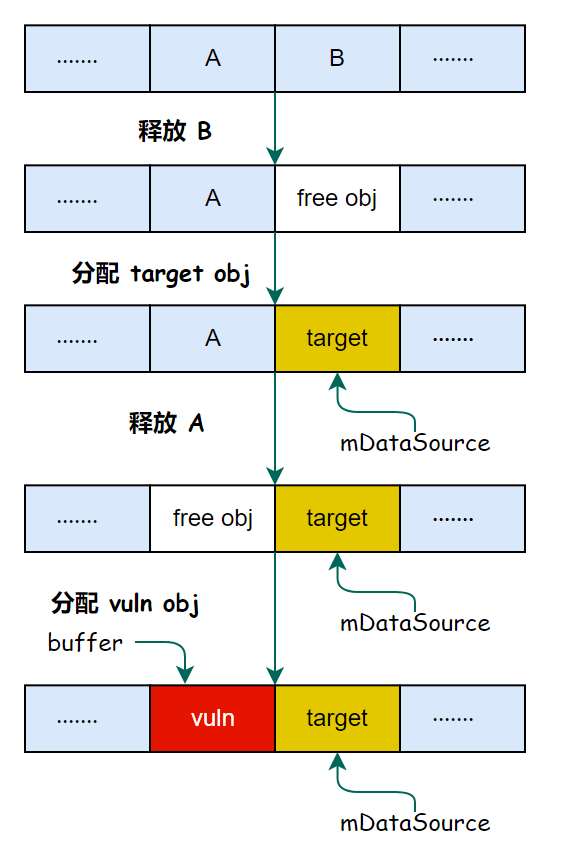
该漏洞的利用采取的是第二种方式,即溢出到 mDataSource 对象 (其类型 MPEG4DataSource ),然后把该对象的虚表劫持,从而劫持 readAt 这个虚函数调用。
那么利用该漏洞的 target obj 就是 mDataSource 对象,如果要利用该漏洞,buffer 和 mDataSource 的内存布局如下:
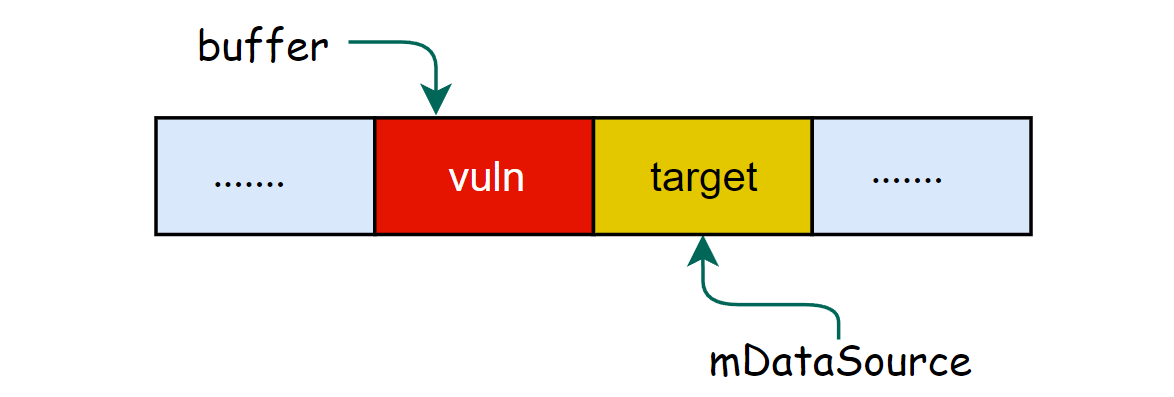
下面就介绍如何利用程序中的逻辑来整理堆的布局,实现上述的布局,首先需要分析源码定位 vuln obj 和 target obj 的分配方式,当解析到 stbl 标签时,会分配 mDataSource 对象(target obj),当解析 tx3g 标签时就会分配 vuln obj 并触发溢出。
然后再看看程序用的内存分配器的一些特点,其使用的是 jemalloc ,jemalloc的大概思路是把内存块分成大小相同的 object,然后返回给申请者,类似于内核的 slub 分配器。
由于堆分配器的实现,堆在初始情况下先分配的对象的地址会比后分配的对象的地址小,这时如果直接先分配 target obj 的话,vuln obj 就会在 target obj 的后面,因此无法溢出到 target obj.
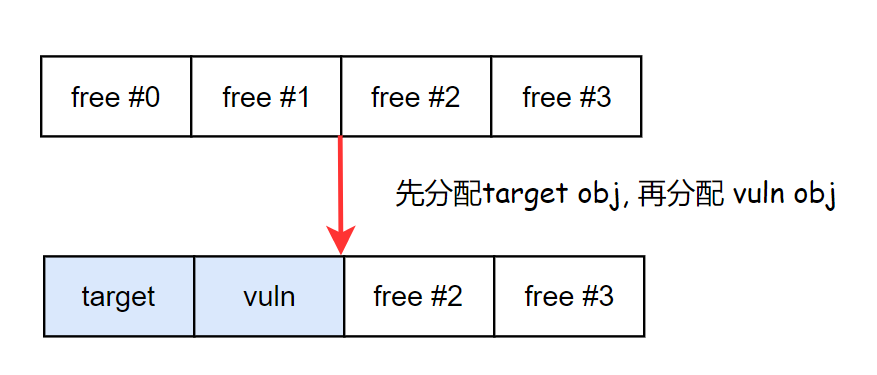
假如先分配 vuln obj 的话,由于漏洞触发点的内存分配和数据溢出是一起发生的,也是无法覆盖到 mDataSource。
或者我们可以利用jemalloc的LIFO特性,先把后面的块释放了,然后把前面的块释放了,然后再先分配 target obj 后分配 vuln obj,也可以实现上述的布局。
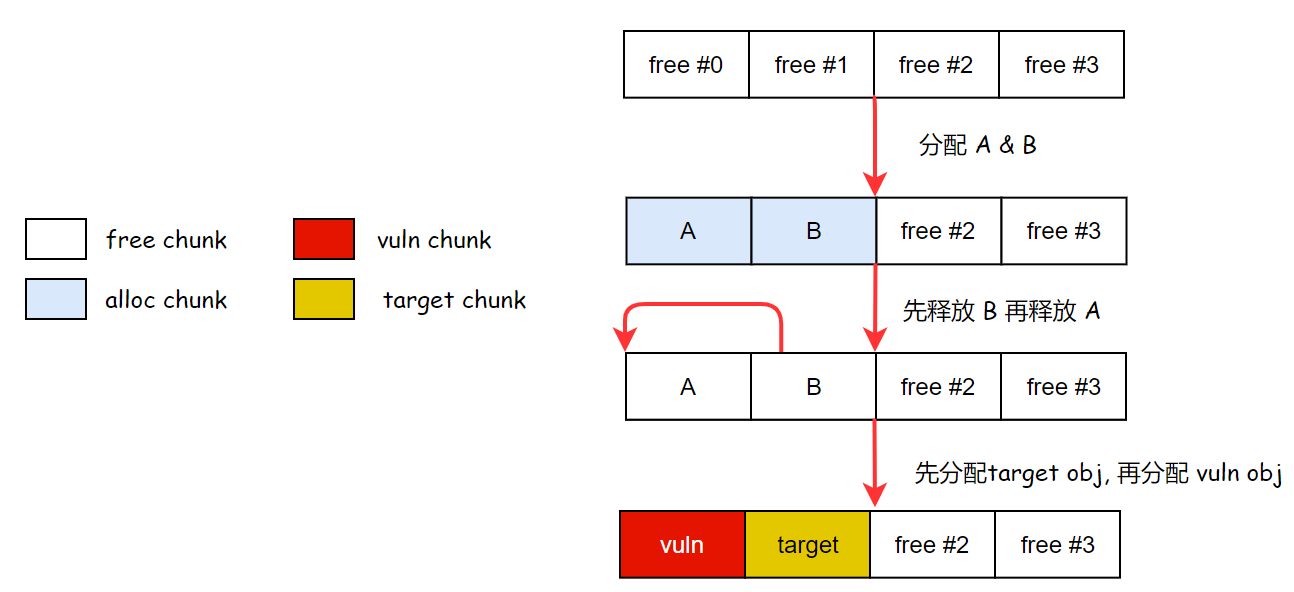
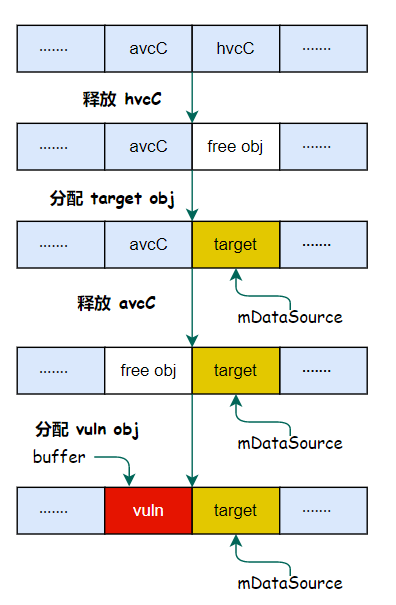
exploit 里面的思路是采用占位对象,然后通过控制占位对象的分配与释放,来完成布局,示意图如下:
要完成上述布局,关键点在于需要找到可以通过用户输入(mp4文件)控制 分配/释放 的代码逻辑,在 libstagefright 中我们可以利用 avcC 和 hvcC 来进行占位,通过这两个标签的特点为:
利用 avcC 和 hvcC 来占位的示例图如下:
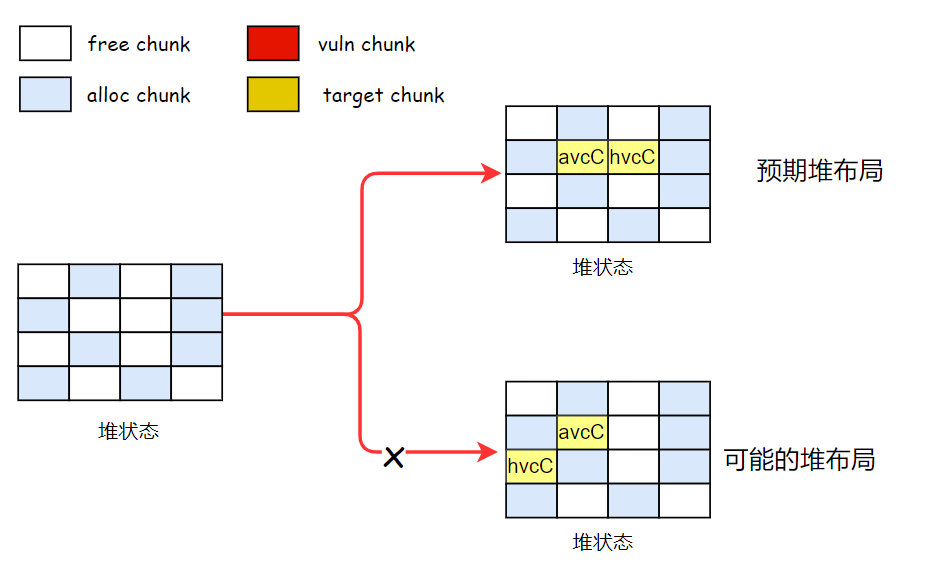
为了稳定的完成堆布局,还需要解决内存碎片的问题,上述布局成立的前提是 avcC 和 hvcC 对象是相邻的,如果内存中存在内存碎片的话,这两个对象是有可能不相邻的。
为了解决这个问题常用的方式是首先把之前的内存碎片清掉(即大量分配内存,把之前堆中碎片的内存块申请完),之后再申请内存的时候,我们分配到的内存块的顺序就会符合我们的预期了。
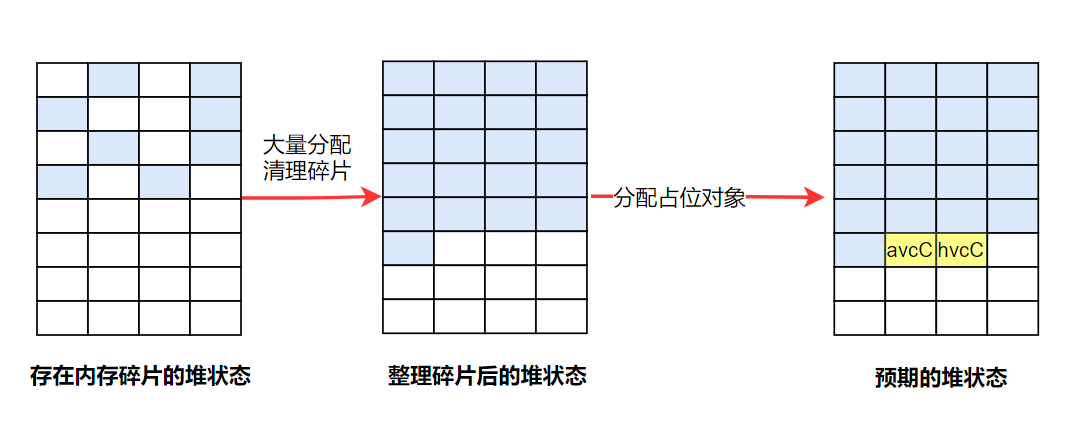
exploit 中使用的是 pssh 标签来清理内存碎片,原因是程序在解析 pssh 标签时会根据标签中的数据分配内存,内存的大小和内容可控,且分配出来的内存在整个文件解析完成后才会被释放,因此直接在输入文件中放置多个 pssh 标签就可以完成内存碎片的清理工作。
完成堆布局后现在就可以溢出到 mDataSource 对象 (其类型 MPEG4DataSource ),接下来的利用思路就是覆盖对象的虚表,把虚表劫持到我们伪造的需要,然后对象进行虚函数调用的时候就可以劫持pc。
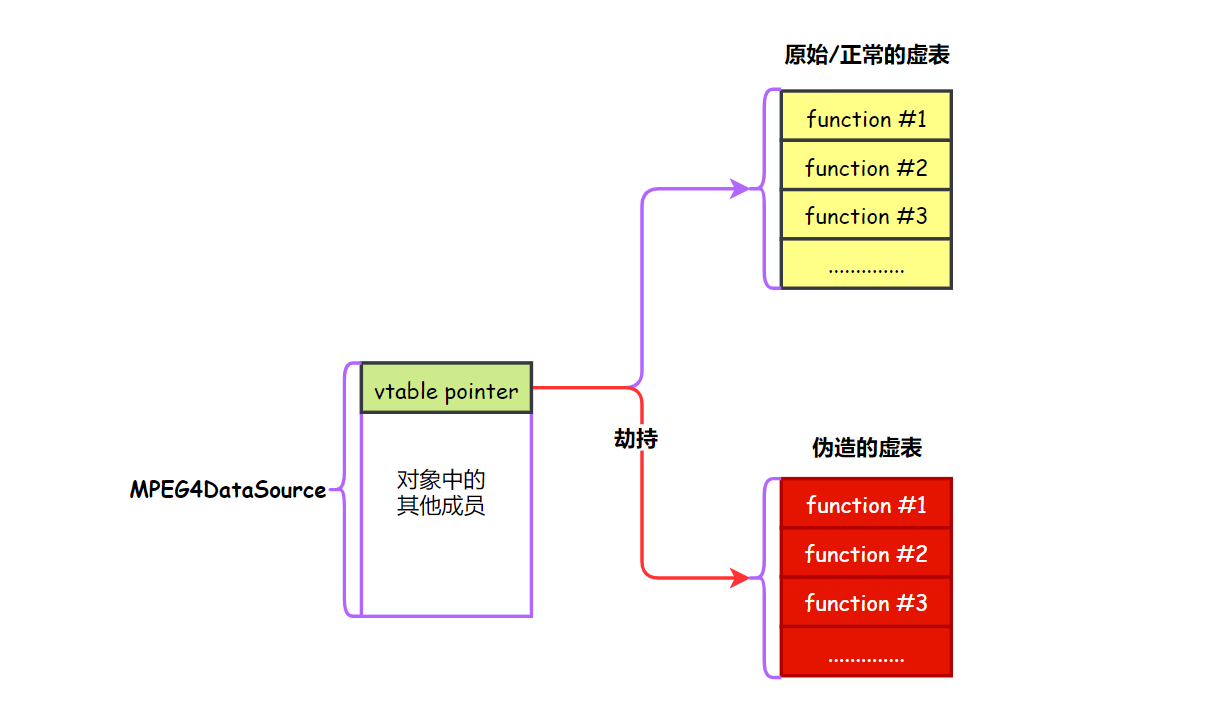
目前的问题是如何知道 伪造的虚表 的地址,获取地址一般有两种方式:
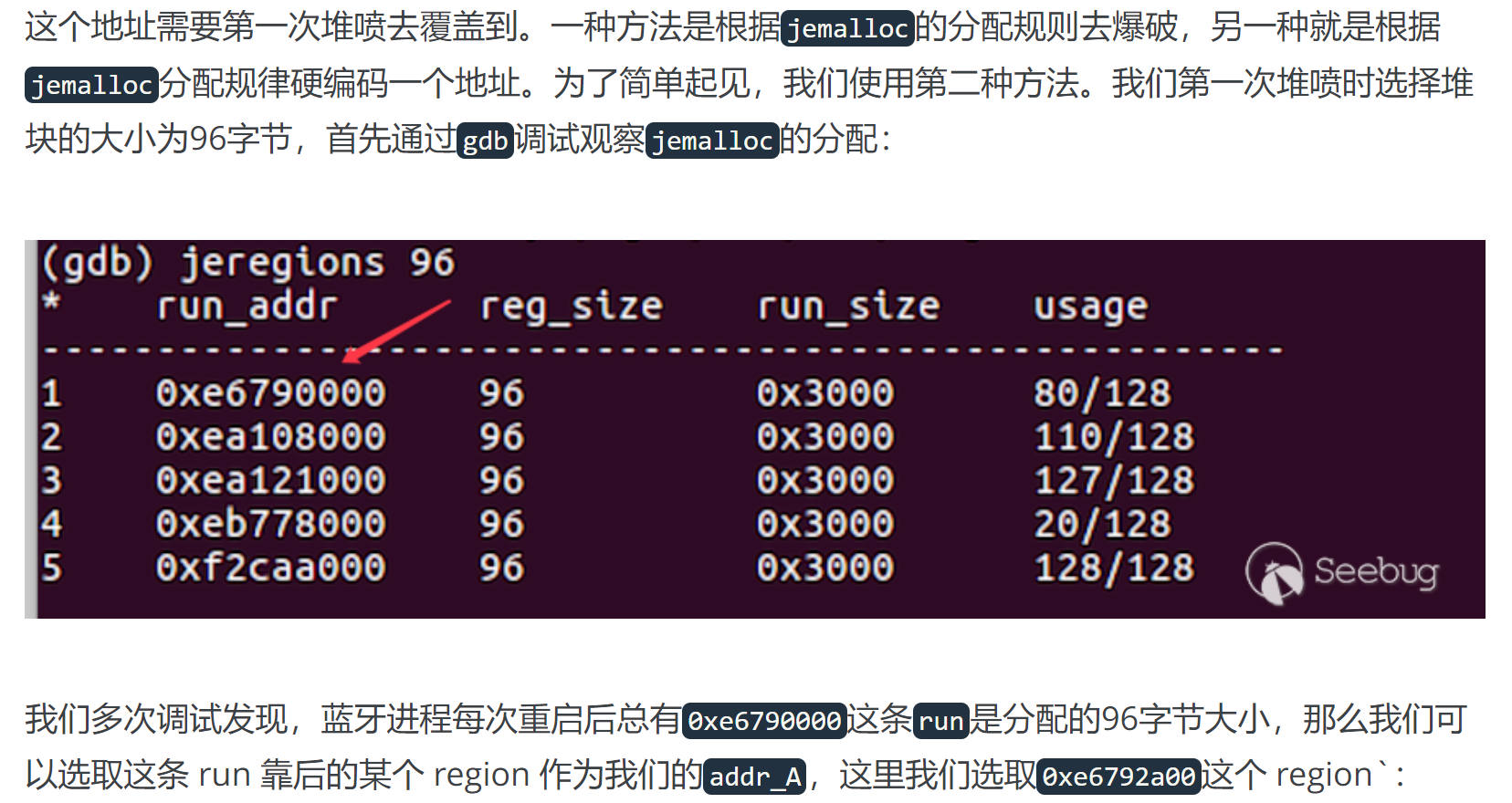
这里使用的是堆喷射技术,以32位系统为例,堆喷射的思路大概是由于进程虚拟地址空间的大小限制,当程序分配大量内存时(比如 0xff000 字节时), 尽管存在随机化,我们依然可以以极大的概率在某个具体的地址(0xf7500000)上布置我们的数据。
利用大量的内存分配可以让进程的某个地址存放我们的数据,数据的内容如何控制呢,按照我的理解,我们在进行堆喷的时候尽量按页对齐去分配,然后以页为单位进行数据布局,就可以实现在可预测的地址,布置可控的数据,具体的偏移和布局还需要调试确认。
exploit 中的堆喷射思路如下

小结
该漏洞的利用非常经典,主要的特点如下:
主要可以学习的思路有:
漏洞是8字节的溢出, vuln obj 的大小可控。

作者通过不断调整 vuln obj 的大小来触发漏洞,然后分析 crash 的上下文,最后在32字节的run中找到了合适的 target obj (fixed_queue_t),该对象中有个函数指针,可以用于劫持控制流。
为了实现控制 pc,还利用堆喷在可预测的地址上布置了数据,布置的过程主要靠尝试和调试。
小结
该漏洞利用最直接借鉴的思想是通过不断尝试 vuln obj 的大小,来找到潜在的 target obj,这种思路比较有通用性,也可以减少人工搜索 target obj 的工作量,甚至会发现一些比较神奇的对象。
还有就是 jemalloc 的堆喷可以通过观察 regions 的内存布局来提升成功率。
这组漏洞利用包含两个漏洞,一个信息泄露漏洞(CVE-2020-3847)和一个堆溢出漏洞(CVE-2020-3848)。
CVE-2020-3847 的成因是内存申请的大小和访问内存时的偏移检查有问题,漏洞触发流程:
CVE-2020-3848 的漏洞成因是分配内存时分配的是 0x20 字节,但是拷贝数据时最多可以拷贝 0xff 字节。
为了实现 Zero Click 的漏洞利用,作者经过分析发现只能通过创建 SDP 连接来让目标分配内存,且一个设备最多只能创建 30 个 SDP 连接,创建 30 个 SDP 连接后实际会分配的对象和关系如下图
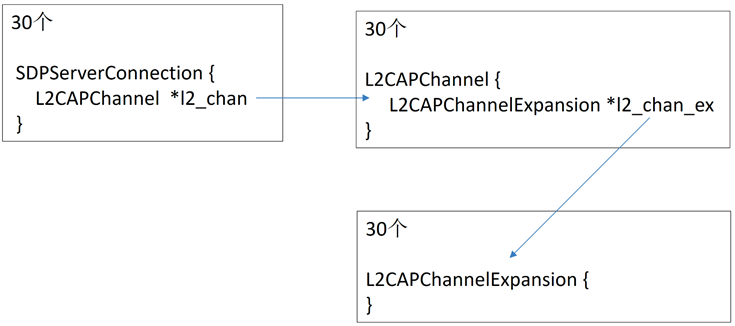
随后作者通过释放其中的几个 SDP 连接对象,并结合信息泄露漏洞来检查当前堆布局是否可以用于利用,即vuln obj 后面是否存在可以用于利用的对象。
大概思路应该是通过一些内存的申请释放看能否让 vuln obj 后面放置可利用的对象。
小结
主要启示在于:
这篇文章涉及3个漏洞,本节主要涉及其中2个被利用的漏洞,即 CVE-2020-12352 和 CVE-2020-12351,比较有意思的是作者在编写 CVE-2020-12352 的 POC 时,触发了 CVE-2020-12351.
CVE-2020-12351 是一个栈变量未初始化漏洞导致的信息泄露,作者通过随机的发送一些报文进行尝试,最终可以通过该漏洞泄露出 内核和堆的地址。
CVE-2020-12352 是一个类型混淆漏洞,漏洞的成因是把 struct amp_mgr 对象当作了 struct sock 对象传入了 sk_filter 函数进行处理。
经过分析,通过控制 sock 结构体 (即被类型混淆的 amp_mgr 对象)的 sk_filter 指针可以完成漏洞利用, struct sock 的结构体布局如下:
可以看到 sk_filter 字段位于 sock 结构体偏移 0x110 处,但是 struct amp_mgr 的大小为 0x70,由于 slub 分配器的特性, amp_mgr 结构体实际会在 kmalloc-128 处分配,所以 sk_filter 字段实际位于 amp_mgr 结构体后面第二个内存块中,如下图所示:
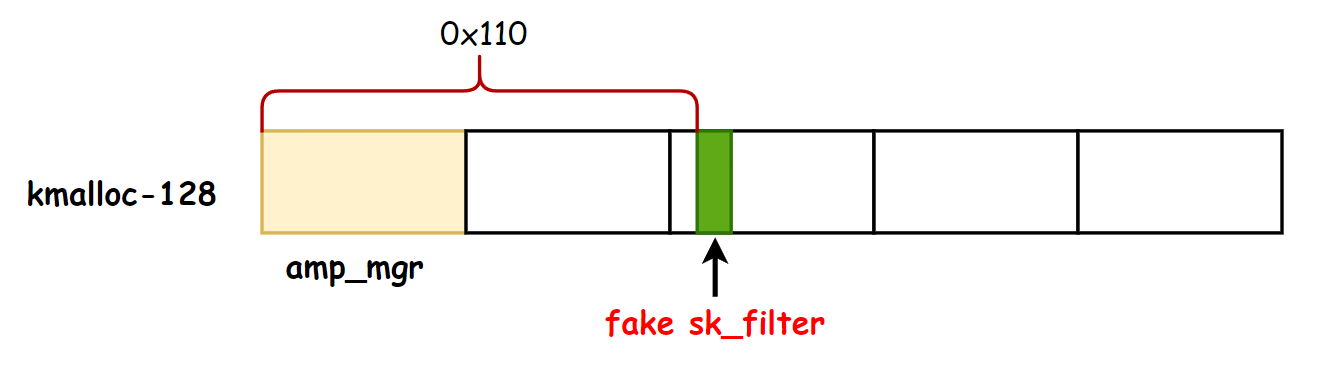
amp_mgr 分配在 kmalloc-128 中,当 amp_mgr 被当作 sock 结构传入 sk_filter 函数处理时,其访问 sk->sk_filter 时,实际访问的是图中标红区域。
因此目前的问题是如何控制 fake sk_filter 字段,作者的思路是首先分配 amp_mgr ,然后再 kmalloc-128 中分配两块内存,从而控制 fake sk_filter 字段.
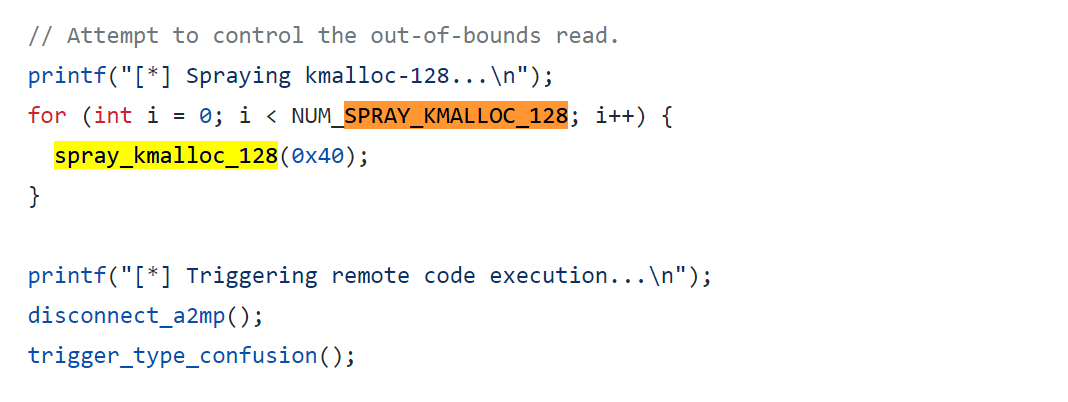
上述思路的关键是需要找到可以远程从 kmalloc-128 中分配内存的原语,常见思路是在协议栈代码中搜索内存申请函数(比如 kmalloc, kzalloc等),不过作者没有找到上述的原语,最终是利用 kmemdup 操作实现的内存申请,代码如下
大概堆布局思路如下:
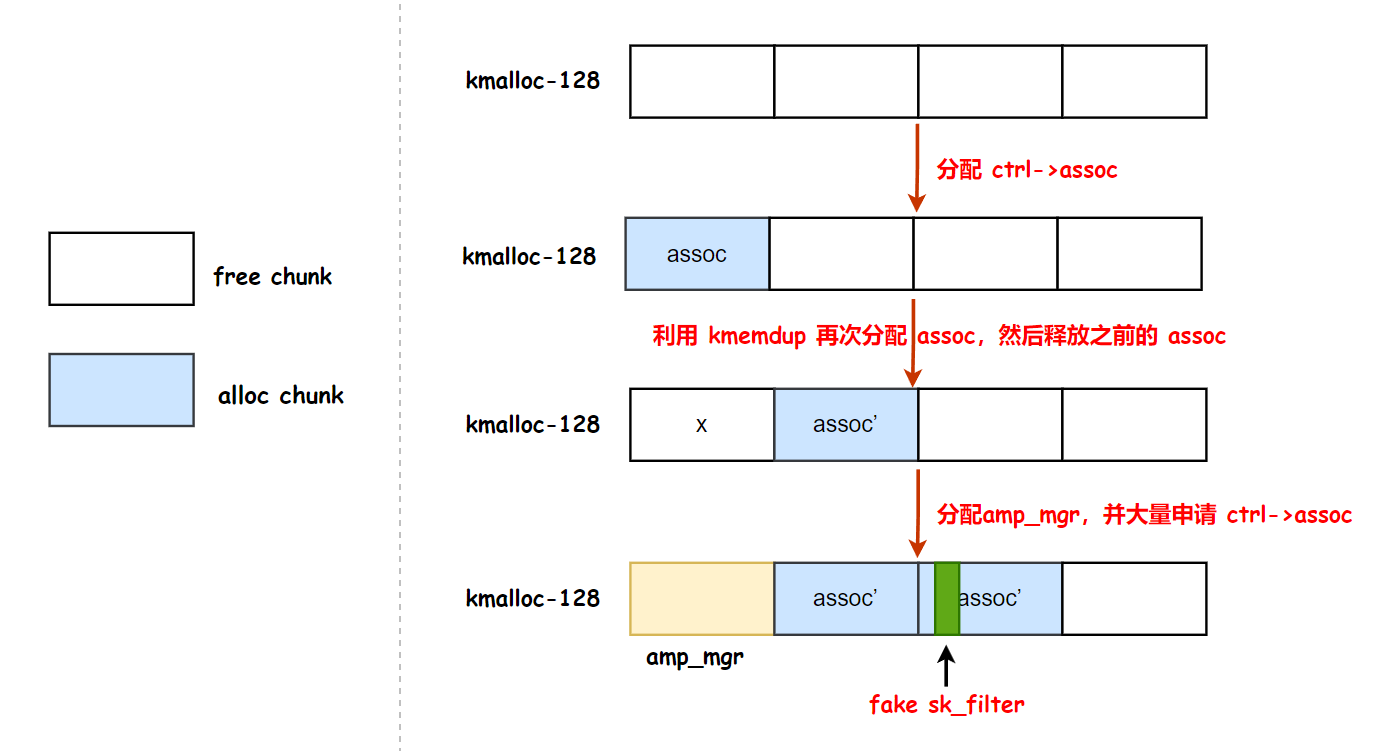
不过看 exploit 里面的堆布局思路,貌似是直接先分配多个 ctrl->assoc,然后释放掉最后一个 assoc 和 amp_mgr,最后重连,就有一定概率会达到上面的布局,从而完成利用。
堆布局相关代码片段:
小结
文章中利用的漏洞是固件在解除 TDLS 连接时 由于解析 FT IE 时没有检查长度导致的堆溢出漏洞
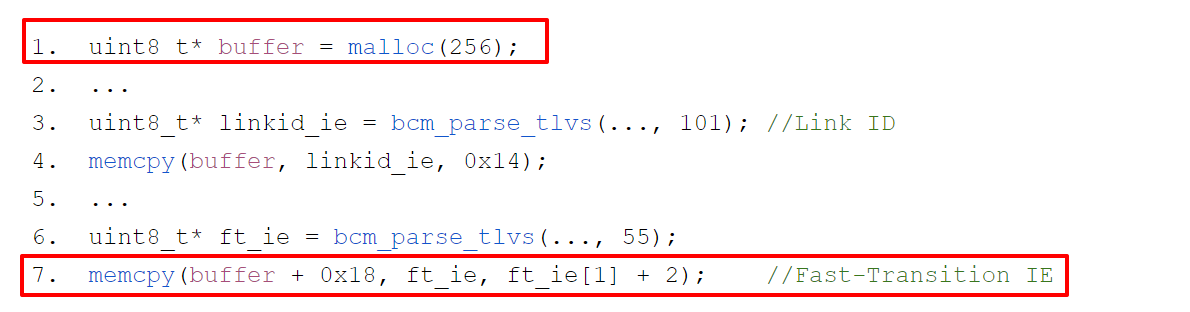
因此我们就有了一个堆溢出漏洞,vuln obj 的大小是 256 字节,下面就需要找被溢出的对象,以及寻找堆布局的方式。
作者首先逆向分析了固件中的堆分配器,然后通过 固件代码 patch、内存dump等手段实现了一个堆的可视化工具,可以跟踪固件的内存申请和释放、可视化某个时刻的堆内存布局:

图中红色表示正在使用的内存块,灰色表示处于 free 状态的内存块。
然后我们如果尝试解除 TDLS 连接并发送恶意的FT IE触发漏洞,由于堆分配器的实现,此时 malloc(256) 会分配到 0x1f03fc 这块内存,我们也就可以溢出到 0x1f0520 后面的块。
此外经过作者的不断尝试发现,堆状态非常稳定,每次 创建/解除 TDLS 连接 时堆的状态基本是一样的,这样如果能在这个堆状态下完成利用,exploit的稳定性应该也是比较高的,不过如果程序中有一些可用于堆布局的原语(内存申请、释放),可能可以改变这个内存布局,不过作者没有尝试,而是在当前内存状态下完成了利用。
因此 vuln obj 是 0x1f03fc 这块内存,target obj 是 0x1f0520 后面的内存块。
对于堆溢出的利用常见的思路有两种:
修改堆中对象的数据,比如对象的长度字段,堆中的指针等,然后利用程序对对象的操作来进行后续的利用
vuln obj 和 target obj 的内存 dump 如下:
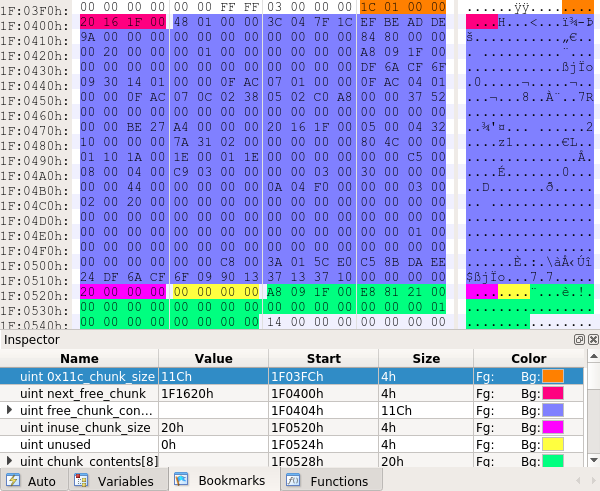
可以看到 target obj 的头不由两个看着像指针的值,不过经过修改尝试发现这两个指针好像没有人用,因此目前只能尝试修改内存块的 头部字段,由于 target obj 所在内存块是 inuse 状态,所以头部字段中只有 size 字段是有效的。
在 glibc 的堆溢出 中常用的方式是修改 size 字段来构造重叠的堆块,这里也是这样的思路,由于目标系统中堆的使用情况比较复杂, 作者采取的方式是,写脚本自动化地测试,即尝试把 target obj 的 size 字段修改成不同的值,然后检查操作完成后的堆状态。
经过测试,作者发现把 target obj 的 size 字段覆盖为 72 并断开 TDLS 连接,堆中出现了重叠的堆块:
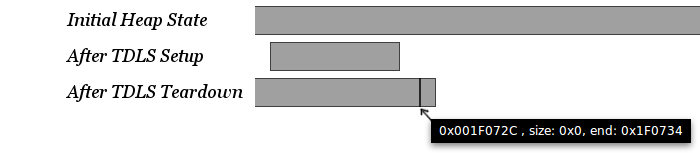
可以看到在断开 TDLS 连接后,0x1f072c 这个 0 字节的 chunk 位于一个大的空闲块中间。
创建重叠堆块后,还需要一个控制内存分配的原语,用于分配到重叠的块,然后修改它的 size 和 next 指针,从而实现任意地址写,固件处理 action 帧的代码中就存在这样的逻辑:

A 是一个全局变量,利用 A 的分配和申请逻辑,可以获取一个生命周期、大小、内容可控的内存控制原语。
最后利用堆分配的 best-fit 特性,修改 chunk 的 next 指针,实现把一个已分配的块链接到空闲块的链表里面,然后实现任意地址写,最后的利用手法如下:
首先利用任意地址写,往一个初始化阶段分配的堆块中布置 shellcode(由于没有地址随机化,系统启动过程中分配的一些堆内存的位置会固定),然后修改 堆中定时器的函数指针,最后等待定时器到期,执行 shellcode.
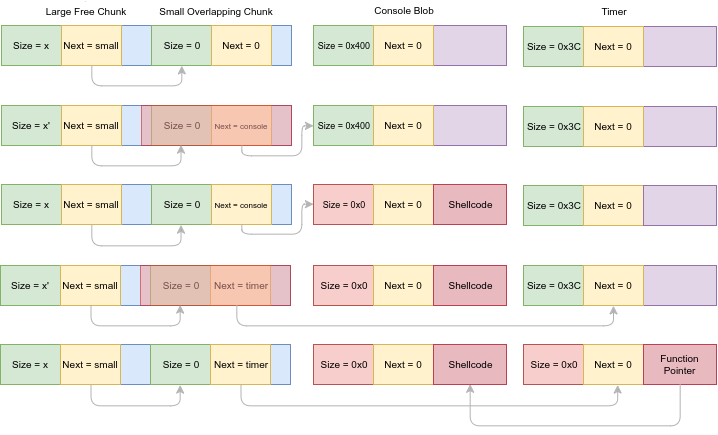
选择把处于使用中的堆块链入空闲块链表的原因是:处于使用的块的 next 指针为0,这样就不会导致内存分配器在分配内存时由于遍历链表导致崩溃。
小结
漏洞成因是 sudo 在解析命令行参数时存在堆溢出,vuln obj 的大小和内容可控。
目前问题就是寻找 target obj,作者的思路是fuzz,通过随机选择 vuln obj 的大小、溢出的大小、setlocale 涉及的相关环境变量(用于控制溢出前的内存块布局),最后通过对 crash 的上下文去重,发现了三种可用于利用的场景,本节将介绍通过覆盖 service_user 完成利用的过程。
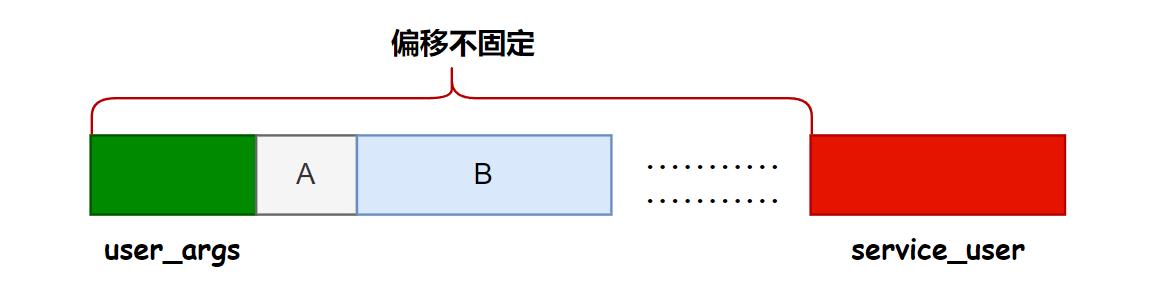
首先通过调整 poc 和调试,能够发现在堆上确实是存在 service_user 结构,不过调试发现其和 vuln obj 的偏移过大,直接去尝试覆盖 service_user 程序会由于中间的一些数据被覆盖而崩溃,且两者的偏移也不固定。
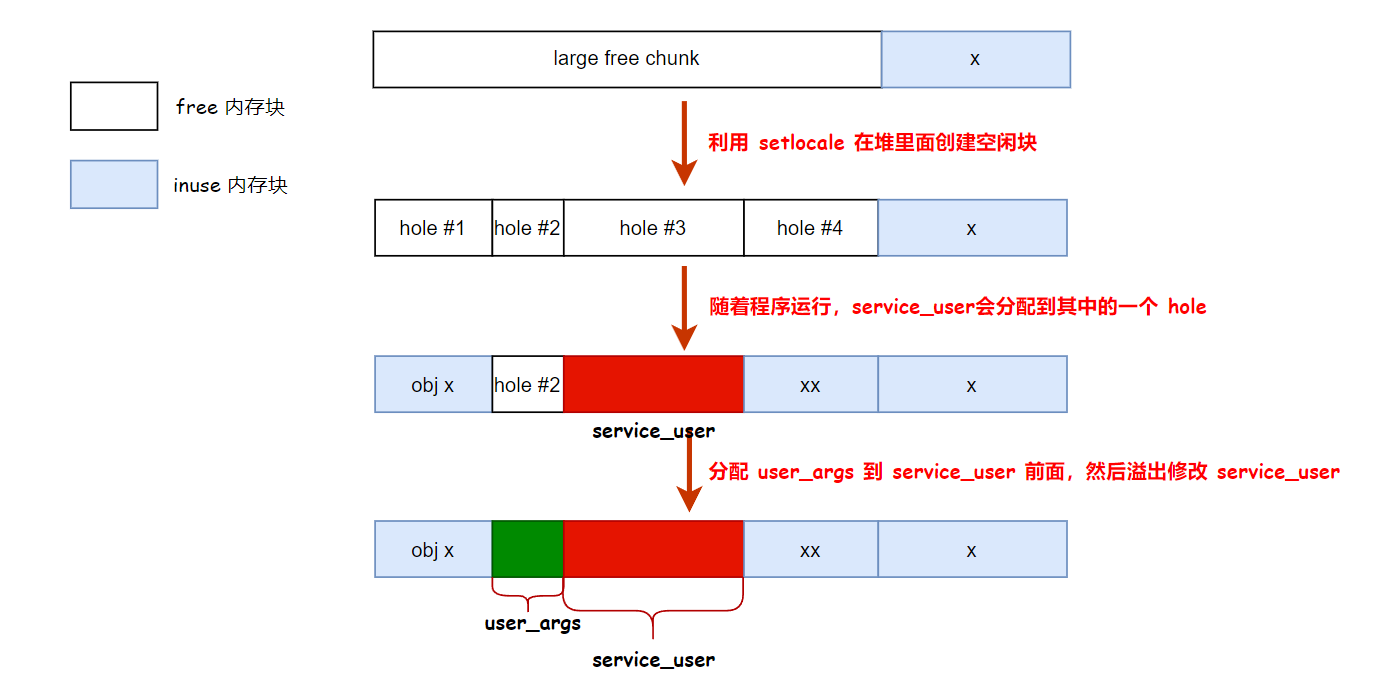
为了解决这个问题,可以利用 setlocale 函数中的 内存分配/释放 操作进行堆布局,让 user_args 落在 service_user 的前面。
setlocale 函数在解析环境变量(比如LC_CTYPE, LC_MESSAGES, LC_TIME等)时,会申请内存并把环境变量的值拷贝到申请的内存中,申请的内存在函数退出前会被释放。
通过利用 setlocale 函数的逻辑和堆分配器的机制,我们提前在堆中创建一些 free 的堆块,让 service_user 分配到其中的一个空闲块,这样在漏洞触发时就能在 service_user 前面留一个 free 堆块,这时我们将 user_args 分配到 service_user 前面就可以稳定溢出service_user 了,大概流程图如下所示:
小结
漏洞是 Zoom 在进行密钥协商时存在一个堆溢出,堆溢出的情况如下:
漏洞利用的环境是 win10 + 32位的 Zoom 软件。
首先利用堆溢出实现信息泄露,常见的思路是分配一些带 length 字段的对象,然后覆盖length字段从而 leak 出一些数据,经过一番分析没有发现能够回显的这种对象。
最后发现,可以给目标 Zoom 客户端发送特定的请求,让对端 Zoom 向我们的服务器发起 https 请求,请求的 url 部分可控,有种 SSRF 的感觉。
接下来就是利用这个 bug 进行信息泄露,具体来说就是利用溢出把 URL 末尾的 \x00 覆盖掉,然后让目标客户端向我们的服务的发起请求,就可以泄露 URL 后面的内存数据了。
这里选择泄露的对象是 TLS1_PRF_PKEY_CTX,这个对象是 openssl 进行 TLS 协商时创建的,对象中存在指向 DLL 的指针,通过泄露这个指针可以可以拿到 DLL 的基地址。
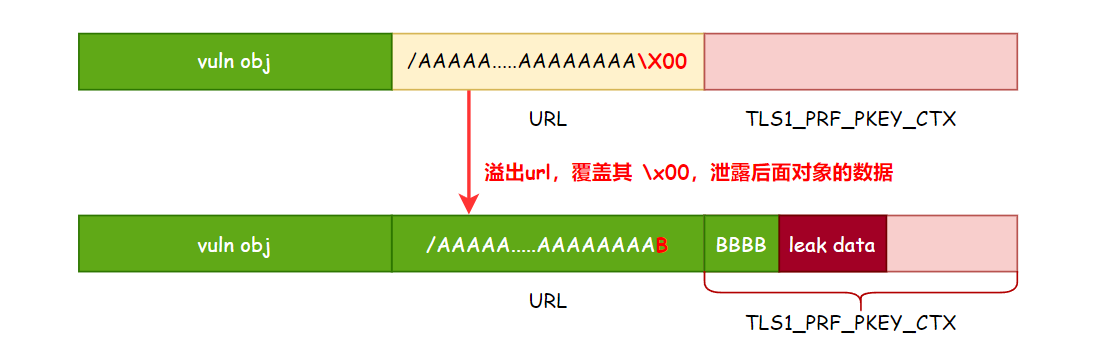
如果堆布局按照预期就能在我们的服务器收到泄露的数据

不过由于 LFH 分配器的随机化和内存状态的不确定性,成功率还是比较低,作者采取了一些措施来提升成功率:

完成信息泄露后,下一步就是找一个对象控制 PC, 这一步使用的是 FileWrapperImpl 该对象会在客户端被呼叫响铃的时候被不断的创建和删除,因此使用堆溢出覆盖其虚表即可劫持控制流。

为了劫持虚表还需要进行堆喷,攻击者可以发起请求让目标客户端加载 gif 图片,而且没有大小限制,利用这个机制就可以进行堆喷。
第二部的过程中也会存在很多不确定性,比如溢出 vuln obj 的过程中可能会覆盖到堆中的其他类的虚表,作者的解决方案如下:
小结
漏洞是在解析图片时存在整数溢出导致的堆溢出
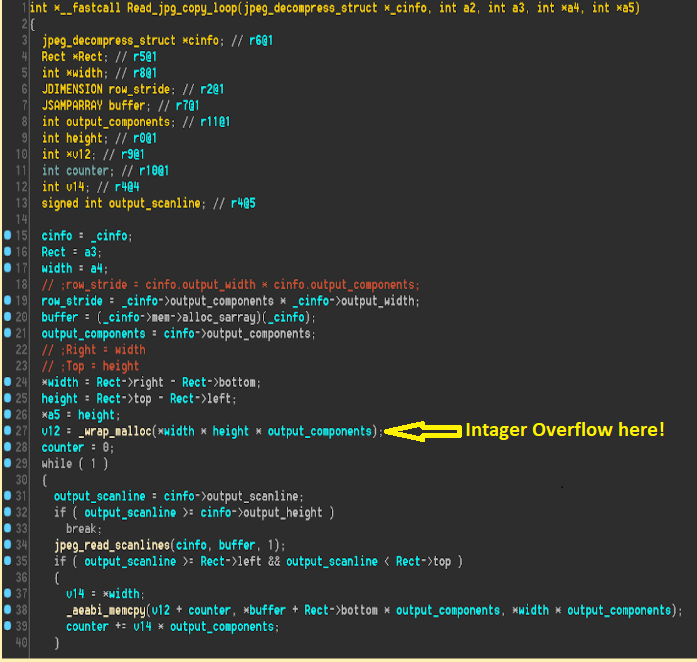
首先根据 width, height, output_components 计算分配内存的大小,然后从文件中一段一段读入内存,如果 width * height * output_components 发生整数溢出,后面从文件中读取内容时就会溢出。
之前提到过利用整数溢出漏洞需要找到终止拷贝的条件,或者在访问到非法地址前劫持控制流,这里采用的是覆盖拷贝过程中会用到的函数指针,在循环访问到非法地址前劫持控制流。
作者通过分析循环中的一些函数调用,发现在 jpeg_read_scanlines 函数和子函数里面会使用 cinfo 结构体中的一些的函数指针
target obj 找到了不过由于没有找到合适的内存控制原语,没法进行完美的堆布局,作者最终采取的策略是通过调试和观察漏洞触发前后的堆状态,来搜索可能用于利用的 vuln obj 大小。
首先通过分析知道 cinfo 分配在 0x5000 的 run 中,然后查看 cinfo 前面的一些run中的使用情况,发现可以通过分配 0xe0 的内存,然后往后溢出即可覆盖 cinfo .

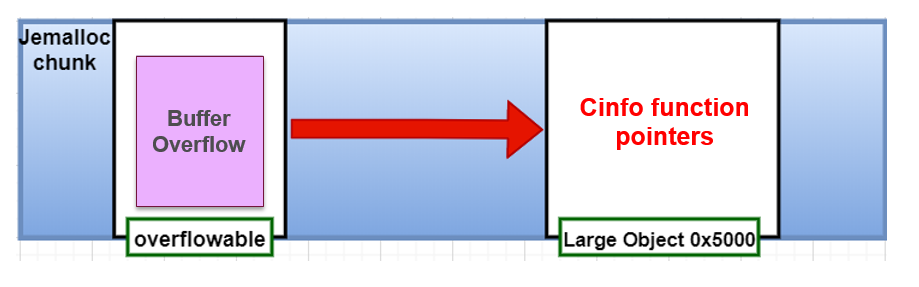
原文作者到这里就没继续了,这种方式有点撞运气的成分,如果进程在之前有些其他分配就可能会导致偏移不一致,不过原文中也提到了,我们可以溢出多一点总是能够溢出到函数指针的。
小结
漏洞利用链包含两个漏洞:
利用未初始化漏洞的思路是堆喷带有函数指针的结构体,然后释放这些结构体,最后触发未初始化漏洞并获取未初始化的内存内容,从而获取 virglrenderer 库的地址。

获取 libc 的地址的思路是申请大块内存,内存中就会包含libc 的地址
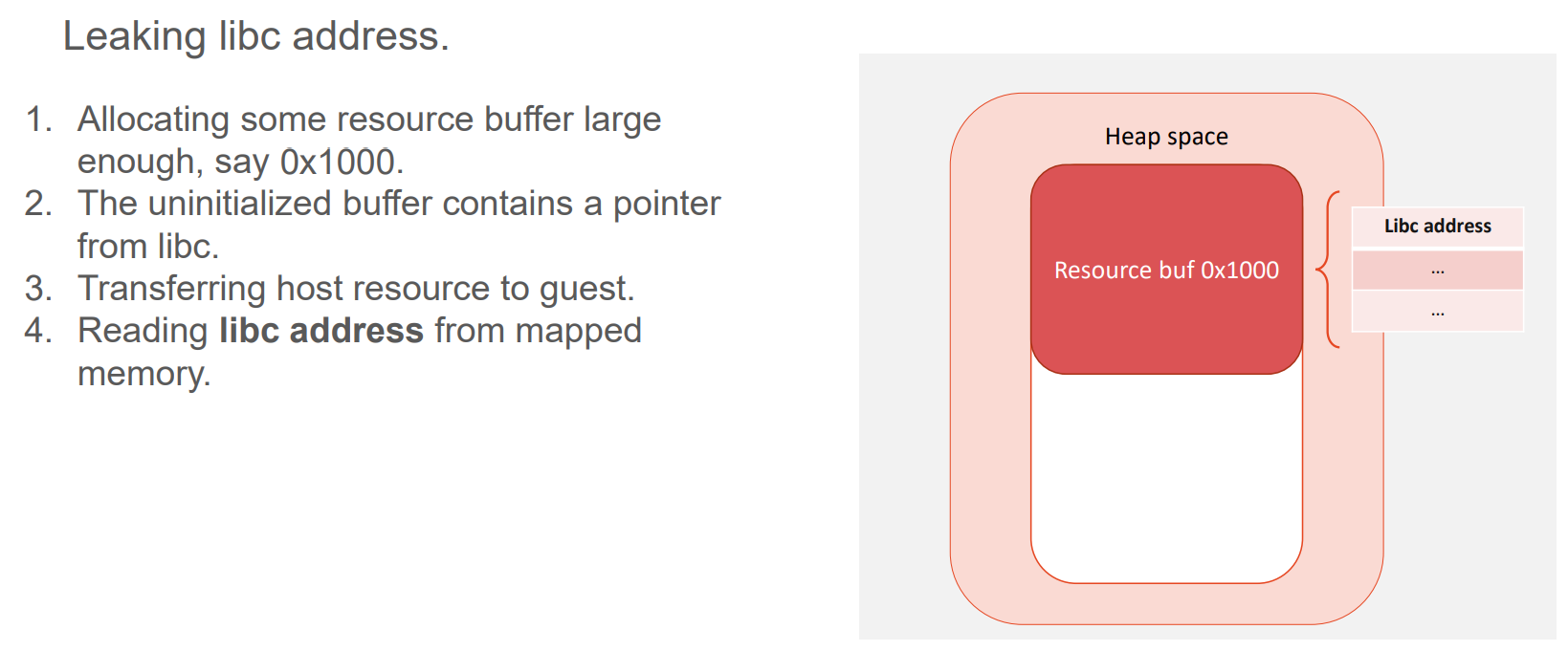
堆溢出的利用思路是堆喷多个 vrend_resource 对象,然后利用溢出修改下一个 vrend_resource 对象的指针,从而实现任意地址写
溢出前,两个 vrend_resource 对象的布局
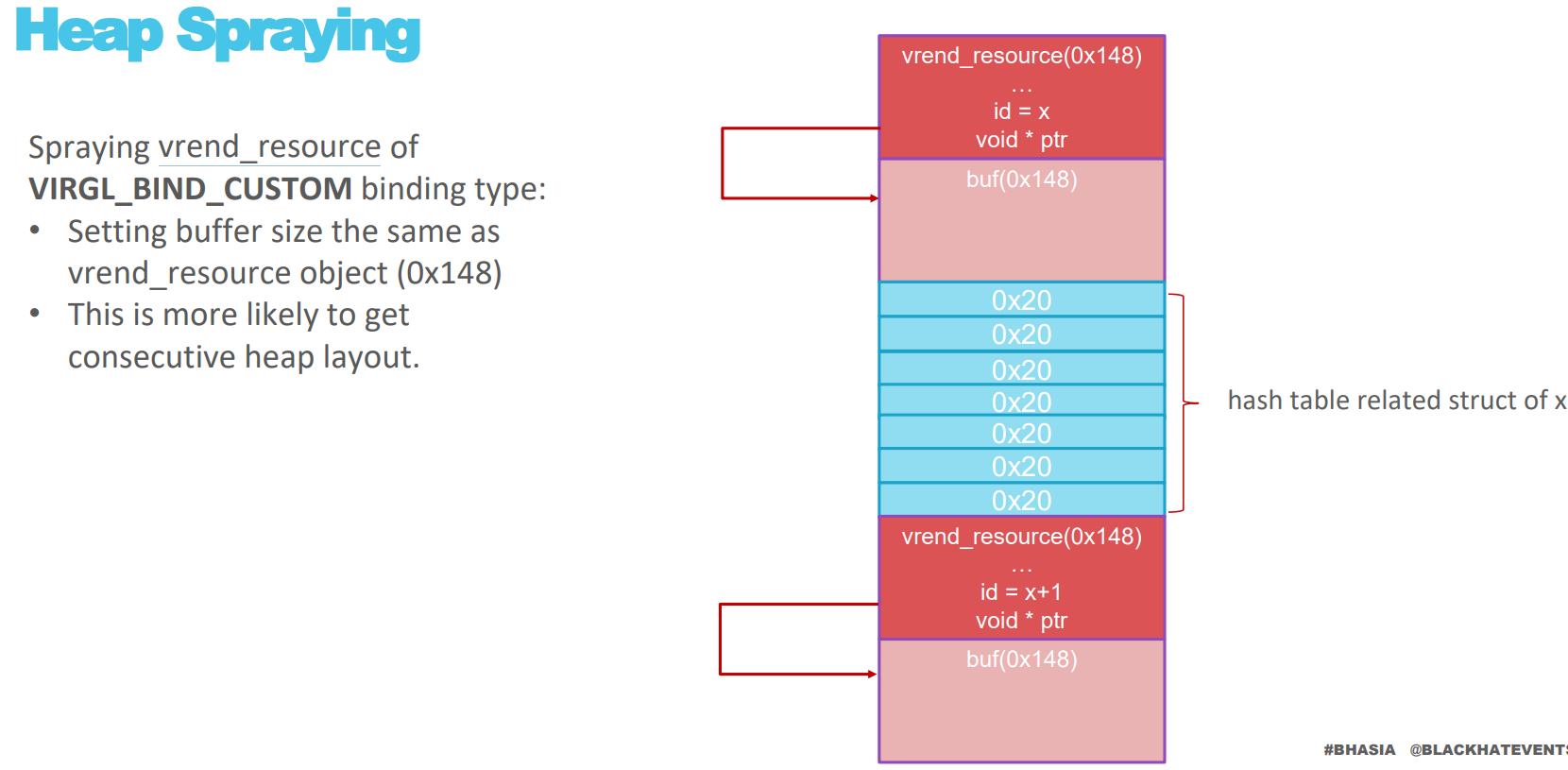
溢出后,第二个 vrend_resource 对象的指针修改为任意地址,然后利用程序的逻辑就可以实现任意地址写
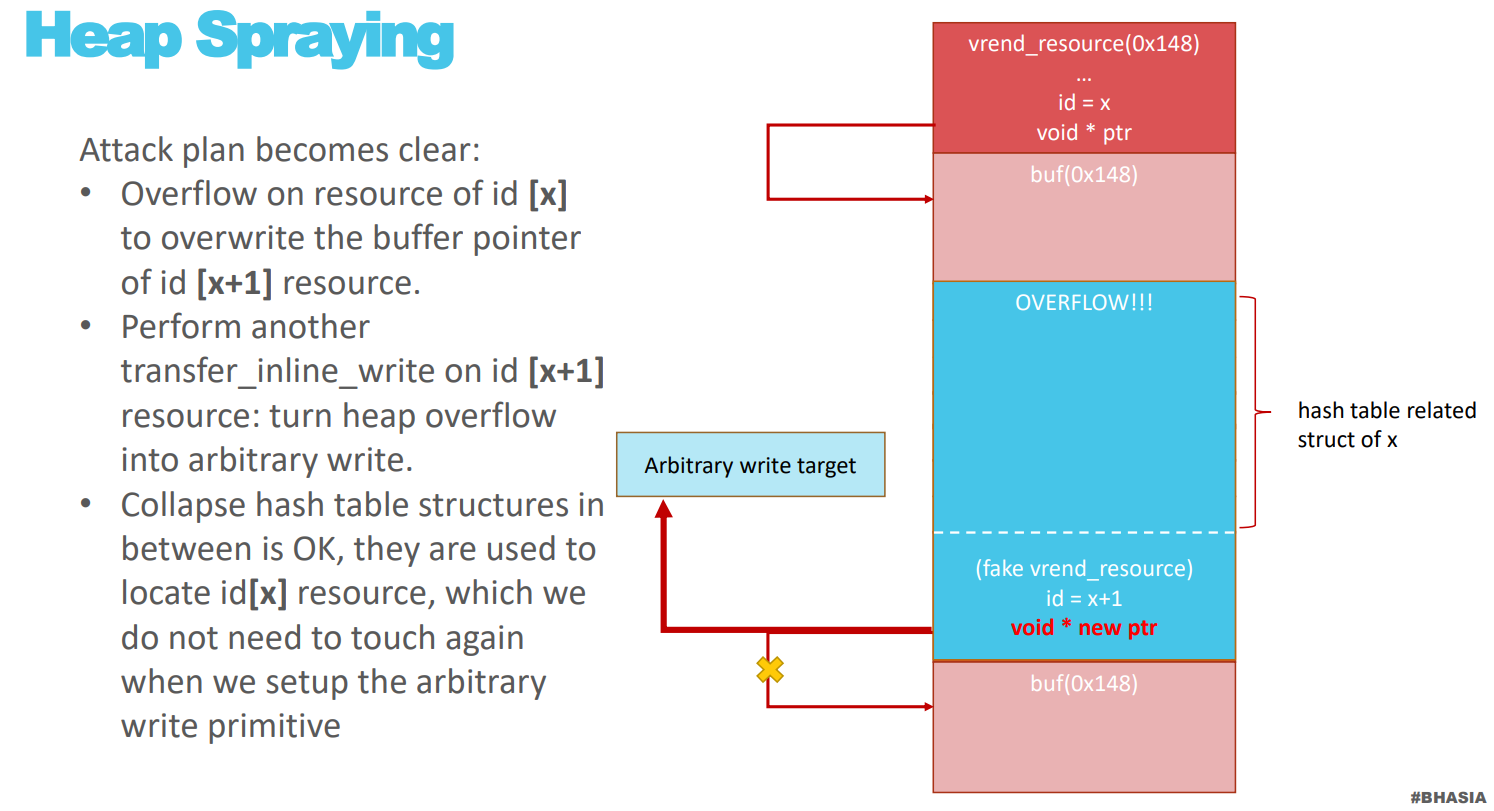
小结
主要就是介绍如何在 ios 的内核里面进行占位式堆布局。
具体思路是先清理堆中的内存碎片,然后用多个 victim object 包着一个 vuln object ,这样就能提升溢出到 victim object 的成功率,如下图所示
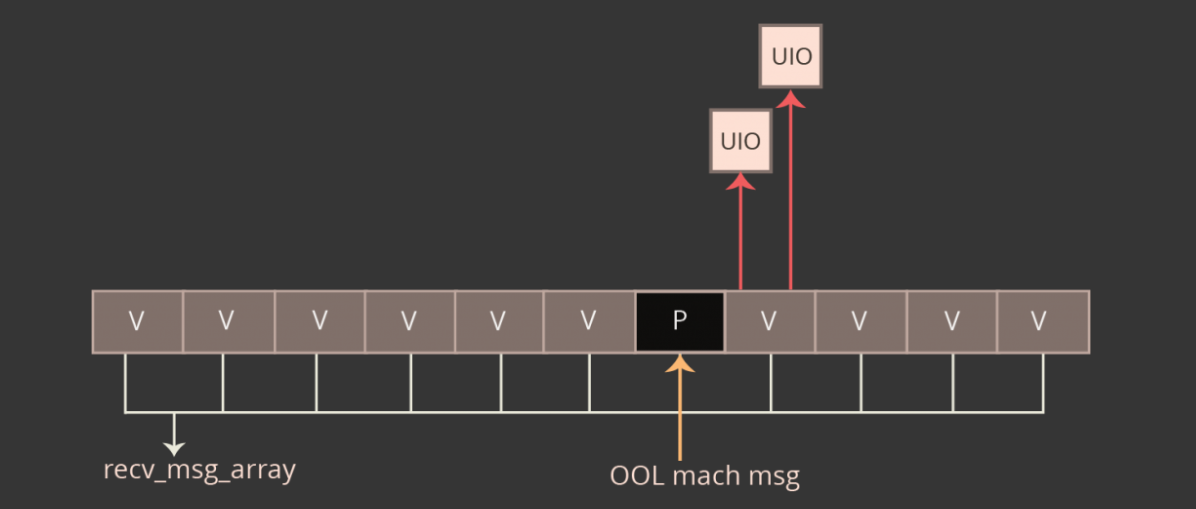
其中: V 表示 victim object, P 表示用于占位的对象,后面溢出的时候就会把 P 释放,然后分配 vuln object.
为了进一步增加漏洞利用的成功率,可以多创建几个用于漏洞利用的区域,多次触发漏洞来提升成功率,如下图所示:

小结
通过在 vuln obj 前后多包裹几个 victim object 和 创建多个漏洞利用区域来提升成功率的思路值得借鉴。
https://http://www.cnblogs.com/hac425/p/15371359.html
https://github.com/hac425xxx/heap-exploitation-in-real-world
https://http://www.cnblogs.com/hac425/p/15371359.html
https://github.com/hac425xxx/heap-exploitation-in-real-world
case FOURCC('t', 'x', '3', 'g'):
{
uint32_t type;
const void *data;
size_t size = 0;
if (!mLastTrack->meta->findData(
kKeyTextFormatData, &type, &data, &size)) {
size = 0;
}
if (SIZE_MAX - chunk_size <= size) { // <---- attempt to prevent overflow
return ERROR_MALFORMED;
}
uint8_t *buffer = new uint8_t[size + chunk_size];
if (size > 0) {
memcpy(buffer, data, size);
}
if ((size_t)(mDataSource->readAt(*offset, buffer + size, chunk_size))
< chunk_size) {
delete[] buffer;
buffer = NULL;
return ERROR_IO;
}
case FOURCC('t', 'x', '3', 'g'):
{
uint32_t type;
const void *data;
size_t size = 0;
if (!mLastTrack->meta->findData(
kKeyTextFormatData, &type, &data, &size)) {
size = 0;
}
if (SIZE_MAX - chunk_size <= size) { // <---- attempt to prevent overflow
return ERROR_MALFORMED;
}
uint8_t *buffer = new uint8_t[size + chunk_size];
if (size > 0) {
memcpy(buffer, data, size);
}
if ((size_t)(mDataSource->readAt(*offset, buffer + size, chunk_size))
< chunk_size) {
delete[] buffer;
buffer = NULL;
return ERROR_IO;
}
status_t MPEG4Extractor::parseChunk(off64_t *offset, int depth) {
uint32_t hdr[2];
if (mDataSource->readAt(*offset, hdr, 8) < 8) {
return ERROR_IO;
}
uint64_t chunk_size = ntohl(hdr[0]);
uint32_t chunk_type = ntohl(hdr[1]);
off64_t data_offset = *offset + 8;
if (chunk_size == 1) {
if (mDataSource->readAt(*offset + 8, &chunk_size, 8) < 8) {
return ERROR_IO;
}
chunk_size = ntoh64(chunk_size); // 从文件中获取 8 字节的 chunk_size
status_t MPEG4Extractor::parseChunk(off64_t *offset, int depth) {
uint32_t hdr[2];
if (mDataSource->readAt(*offset, hdr, 8) < 8) {
return ERROR_IO;
}
uint64_t chunk_size = ntohl(hdr[0]);
uint32_t chunk_type = ntohl(hdr[1]);
off64_t data_offset = *offset + 8;
if (chunk_size == 1) {
if (mDataSource->readAt(*offset + 8, &chunk_size, 8) < 8) {
return ERROR_IO;
}
chunk_size = ntoh64(chunk_size); // 从文件中获取 8 字节的 chunk_size
int main(int argc, char** argv) {
int i = 0;
char* min_ptr = (char*)0xffffffff;
char* max_ptr = (char*)0;
for (i = 0; i < ALLOC_COUNT; ++i) {
char* ptr = mmap(NULL, ALLOC_SIZE,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
if (ptr < min_ptr) {
fprintf(stderr, "new min: %p\n", ptr);
min_ptr = ptr;
}
if (ptr + ALLOC_SIZE > max_ptr) {
fprintf(stderr, "new max: %p\n", ptr + ALLOC_SIZE);
max_ptr = ptr + ALLOC_SIZE;
}
memset(ptr, '\xcc', ALLOC_SIZE);
}
fprintf(stderr, "finished min: %p max %p\n", min_ptr, max_ptr);
((void(*)())0xf7500000)();
}
int main(int argc, char** argv) {
int i = 0;
char* min_ptr = (char*)0xffffffff;
char* max_ptr = (char*)0;
for (i = 0; i < ALLOC_COUNT; ++i) {
char* ptr = mmap(NULL, ALLOC_SIZE,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
if (ptr < min_ptr) {
[招生]科锐逆向工程师培训(2025年3月11日实地,远程教学同时开班, 第52期)!










