接触OLLVM也有好长一段时间了,但一直停留在应用层面,接下来一段时间打算从进一步研究OLLVM。俗话说柿子先挑软的捏,如果说OLLVM提供的几种混淆方式有辈分之分,那么虚假控制流(Bogus Control Flow) 跟它的兄弟控制流平坦化(Control Flow Flattening) 比起来就是弟中弟,我们就从去除OLLVM虚假控制流混淆开始吧!
GitHub仓库:bluesadi/debogus
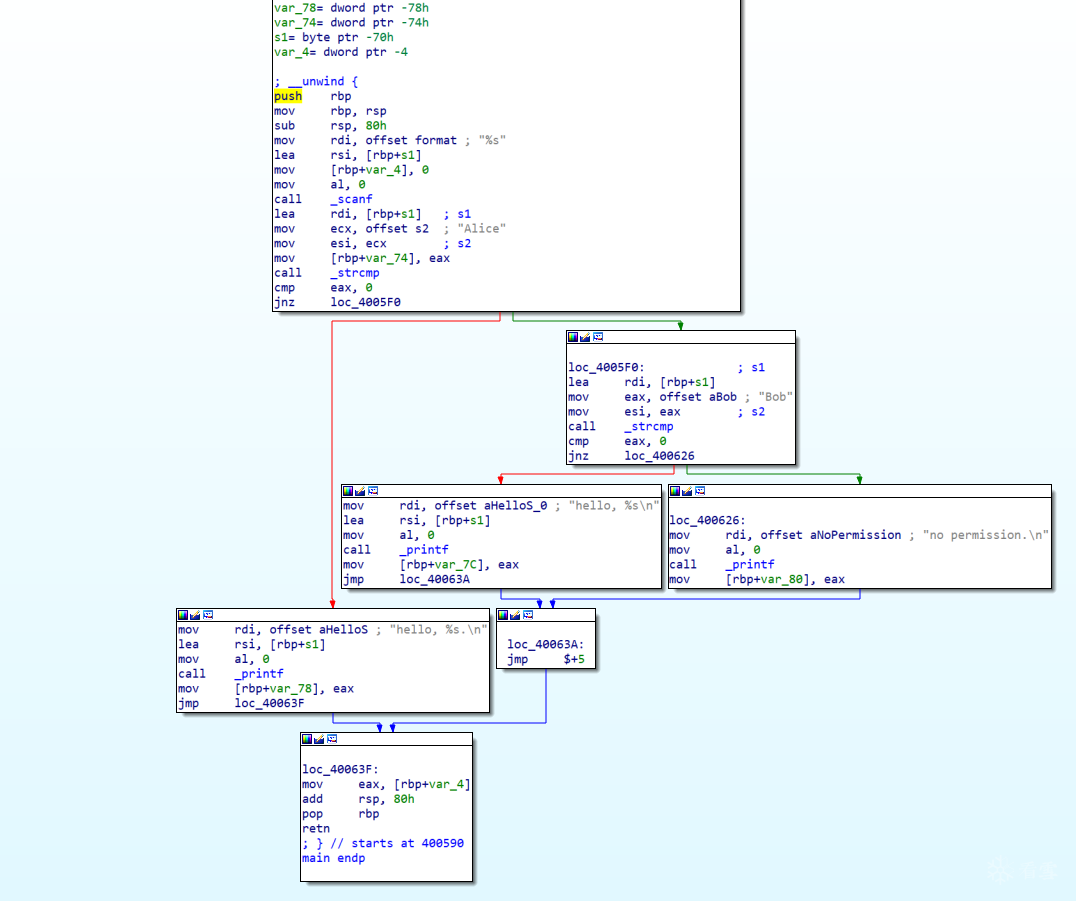
虚假控制流混淆通过加入包含不透明谓词 的条件跳转(也就是跳转与否在运行之前就已经确定的跳转,但IDA无法分析)和不可达的基本块 ,来干扰IDA的控制流分析和F5反汇编。
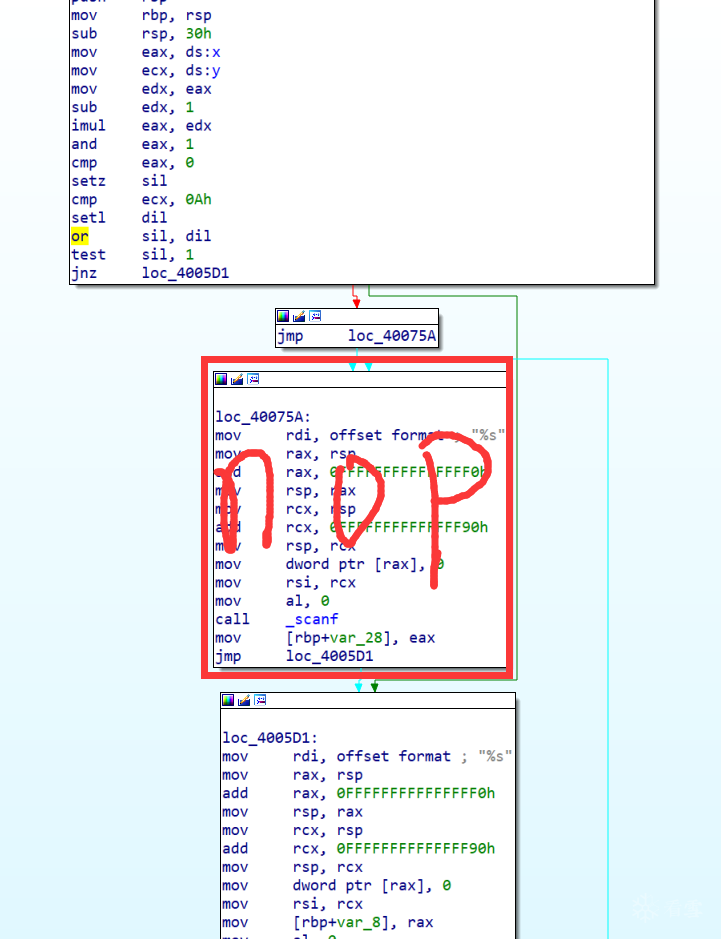
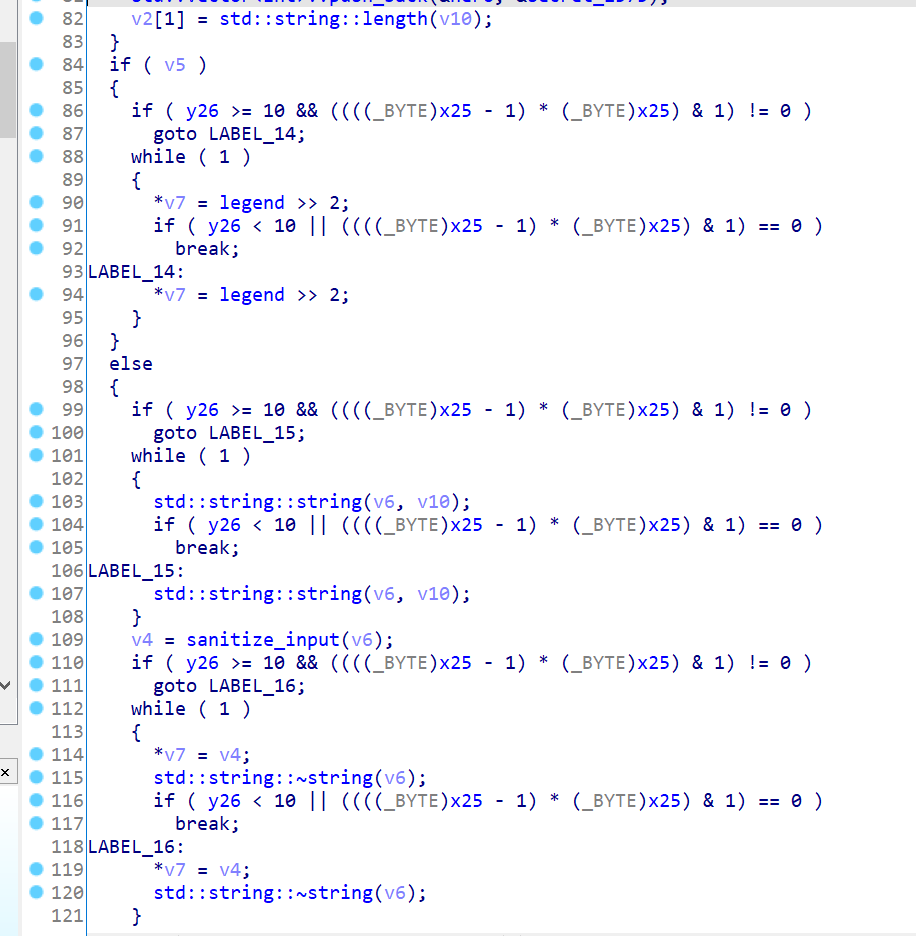
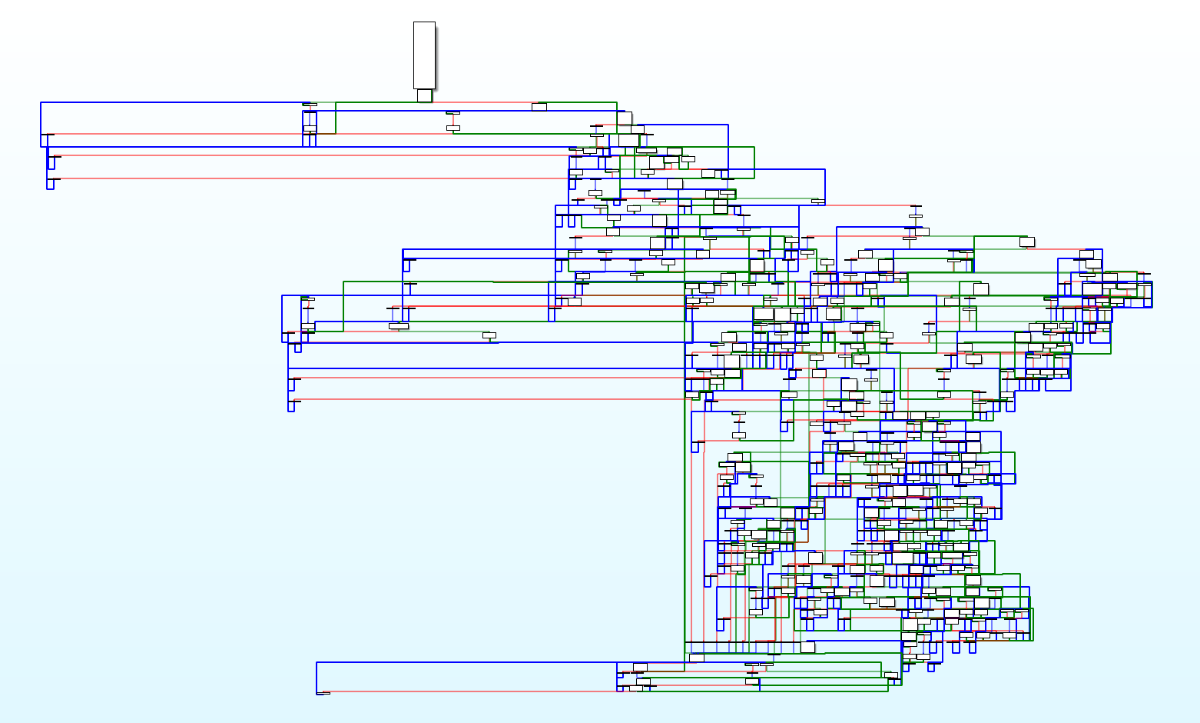
正常编译,在IDA中查看程序的CFG,还是比较清晰的:-ollvm -bcf 选项后编译,可以看到整个程序的流程图变得十分复杂:x 和y 位于.bss段 ,并且通过交叉引用发现没有被修改过,也就是说x和y在运行过程中一直为0 。这里的x 和y 被称为不透明谓词 ,所谓不透明,就是IDA难以推断其在运行时的值,但我们都知道它就是0:
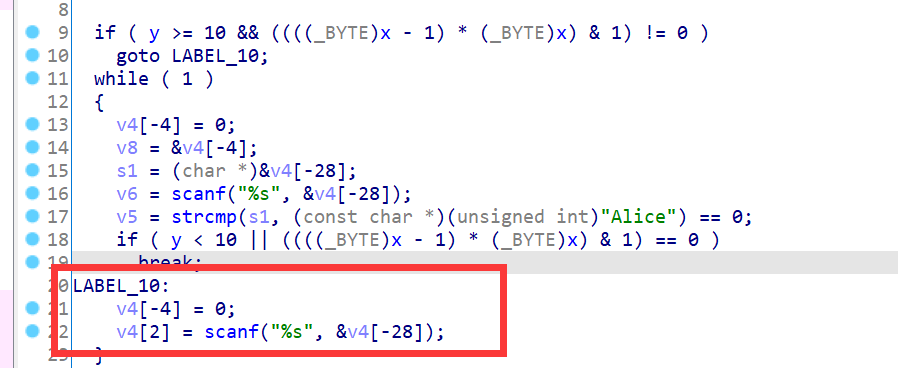
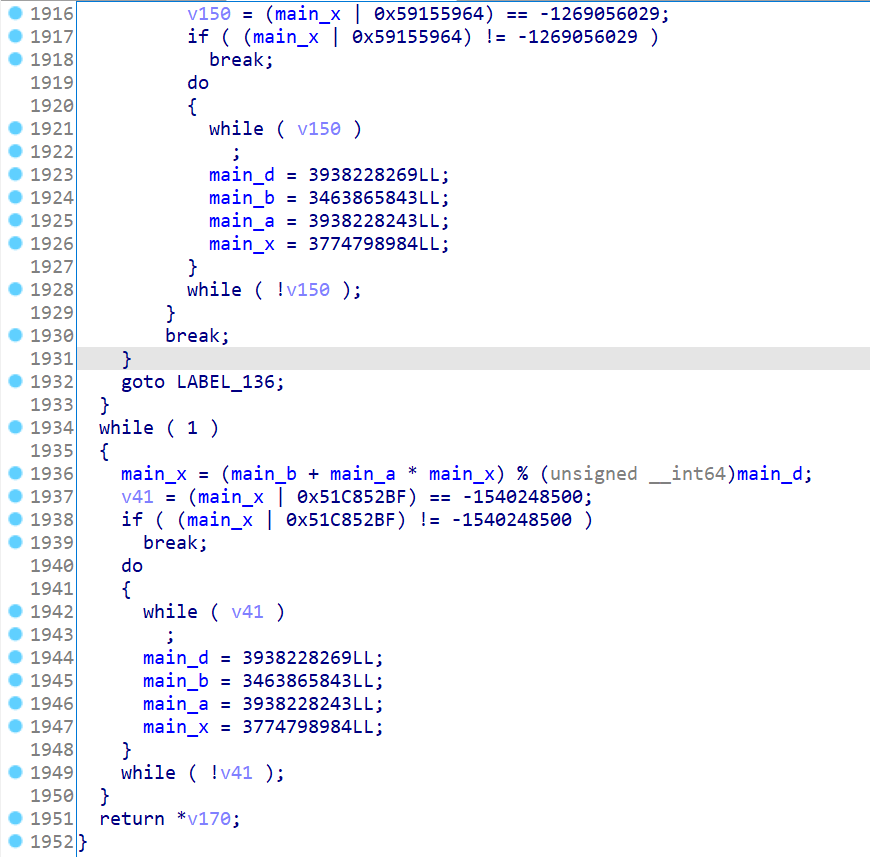
在图中y >= 10 && ((((_BYTE)x - 1) * (_BYTE)x) & 1) != 0 是一个恒为false的条件,而y < 10 || ((((_BYTE)x - 1) * (_BYTE)x) & 1) == 0 是一个恒为true的条件。不可达的基本块 :
利用符号执行去混淆的基本思路是:先找到目标函数的所有基本块,再通过符号执行遍历目标函数所有可达的基本块,剩下的就是不可达的基本块。把不可达的基本块全部nop掉,就能使IDA的F5反汇编正常分析。
angr加载二进制文件:
获取目标函数的函数的所有基本块:
cfg是Control Flow Graph的缩写。注意cfg.nodes() 中除了会包含函数本身的基本块之外,还会包含函数里调用的其他函数的基本块,所以这里用一个node.addr >= start_address and node.addr <= end_address 把函数中调用的其他函数的基本块筛掉。
Hook掉目标函数中调用的所有其他函数:
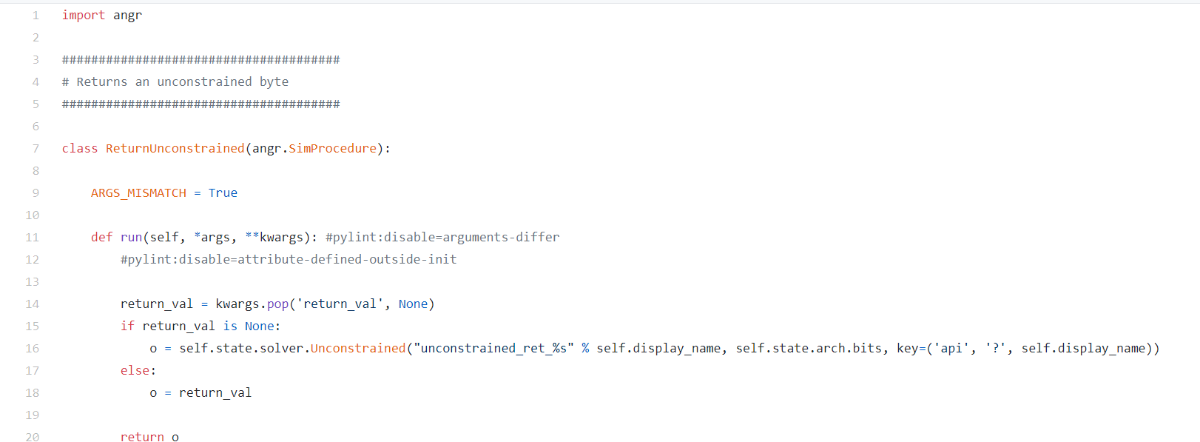
angr.SIM_PROCEDURES["stubs"]["ReturnUnconstrained"]()是ReturnUnconstrained 类的一个实例,在符号执行过程中它会返回一个无约束的符号,简单来说就是一个可以返回任何值的函数。静态链接 的文件时,angr的符号执行模拟器会陷入到复杂的库函数中,导致跑的时间非常长或者根本跑不出来,这也是我把基本块的分析范围限制在目标函数内的原因。cq674350529/deflat 显然就没有处理这个问题。
然后是符号执行的过程:
从目标函数开始,simgr.step() 逐块执行,一直到没有active 状态为止(可以认为是运行结束)。control_flow 中。
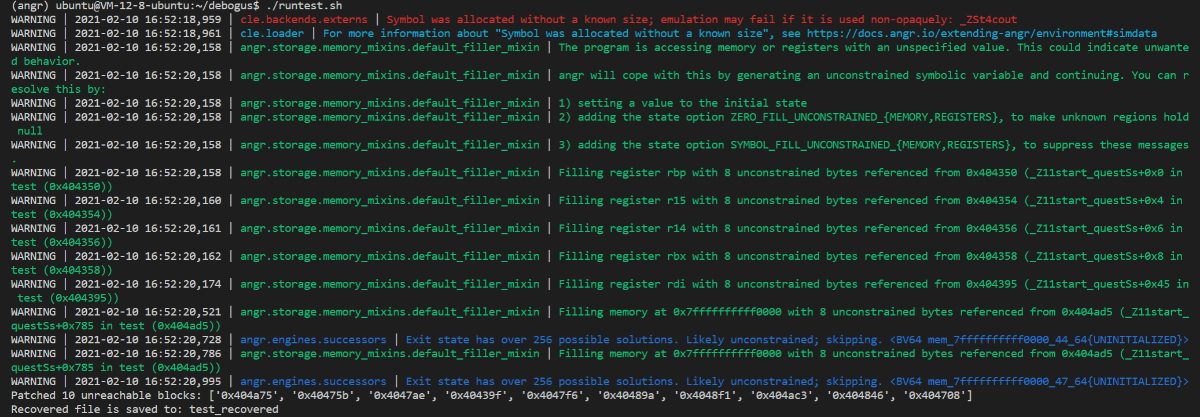
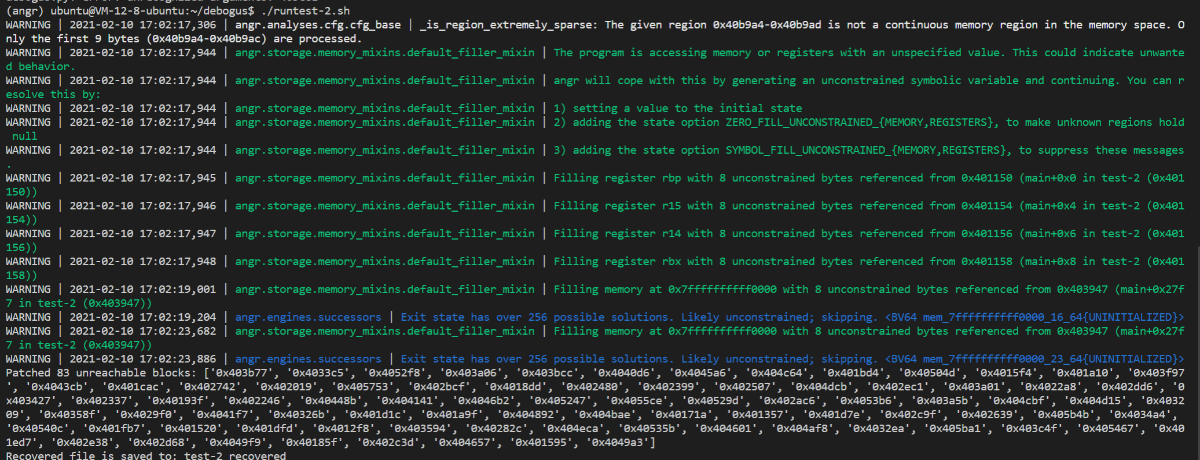
最后nop掉没有被执行到的基本块:
最后将去混淆的结果保存到另一个文件中
这里我们直接用BUUCTF上的一道题测试:[XMAN2018排位赛]Dragon Quest
把所有不透明谓词改为0也能使IDA的F5反汇编恢复正常,用idapython脚本就能实现,因为不是文章的重点就简单贴一下代码好了233:
这种方法的优点是脚本写起来简单,也不用考虑静态链接还是动态链接的问题,缺点是面对虚假控制流的变体可能无能为力。
在上面的脚本中为了防止angr陷到库函数里面,我把符号执行的范围限定在了目标函数内。这样的缺陷是如果有多个函数被混淆了,就要运行很多次脚本。可以加入一个深度参数--depth ,距离目标函数的调用深度不超过depth的函数都会被去混淆,这是一个改进方案,不过感觉代码量很大就没实现了呜呜。
另一个可以改进的地方是在去掉不可达的基本块之后,还可以顺便把跳转到这个基本块的jnz 指令改成jmp 指令,可能对以后要研究的去除虚假控制流变体有帮助。
我对angr的研究也不是特别深入,因此这个去混淆脚本也许不能适用于所有情况(比如上面那个魔改虚假控制流),不过应对OLLVM的虚假控制流混淆应该没有问题。Rimao师傅还提出了一个“怎么区分虚假控制流还是输入导致的分支”问题,欢迎大家讨论吧233。
int main(){
char name[100];
scanf("%s", name);
if (strcmp(name, "Alice") == 0) {
printf("hello, %s.\n", name) ;
} else if (strcmp(name, "Bob") == 0) {
printf ("hello, %s\n", name);
} else {
printf("no permission.\n") ;
}
}
int main(){
char name[100];
scanf("%s", name);
if (strcmp(name, "Alice") == 0) {
printf("hello, %s.\n", name) ;
} else if (strcmp(name, "Bob") == 0) {
printf ("hello, %s\n", name);
} else {
printf("no permission.\n") ;
}
}
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-f','--file', help='The path of binary file to deobfuscate')
parser.add_argument('-s','--start', help='Start address of target function')
parser.add_argument('-e','--end', help='End address of target function')
args = parser.parse_args()
if args.file == None or args.start == None or args.end == None:
parser.print_help()
exit(0)
filename = args.file
start_address = int(args.start, 16)
end_address = int(args.end, 16)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-f','--file', help='The path of binary file to deobfuscate')
parser.add_argument('-s','--start', help='Start address of target function')
parser.add_argument('-e','--end', help='End address of target function')
args = parser.parse_args()
if args.file == None or args.start == None or args.end == None:
parser.print_help()
exit(0)
filename = args.file
start_address = int(args.start, 16)
end_address = int(args.end, 16)
import angr
proj = angr.Project(filename, load_options={'auto_load_libs': False})
import angr
proj = angr.Project(filename, load_options={'auto_load_libs': False})
target_blocks = set()
cfg = proj.analyses.CFGFast()
cfg = cfg.functions.get(start_address).transition_graph
for node in cfg.nodes():
if node.addr >= start_address and node.addr <= end_address:
target_blocks.add(node)
target_blocks = set()
cfg = proj.analyses.CFGFast()
cfg = cfg.functions.get(start_address).transition_graph
for node in cfg.nodes():
if node.addr >= start_address and node.addr <= end_address:
target_blocks.add(node)
function_size = end_address - start_address + 1
target_block = proj.factory.block(start_address,function_size)
for ins in target_block.capstone.insns:
if ins.mnemonic == 'call':
proj.hook(int(ins.op_str, 16), angr.SIM_PROCEDURES["stubs"]["ReturnUnconstrained"](), replace=True)
function_size = end_address - start_address + 1
target_block = proj.factory.block(start_address,function_size)
for ins in target_block.capstone.insns:
if ins.mnemonic == 'call':
proj.hook(int(ins.op_str, 16), angr.SIM_PROCEDURES["stubs"]["ReturnUnconstrained"](), replace=True)
control_flow = set()
state = proj.factory.blank_state(addr=start_address, remove_options={angr.sim_options.LAZY_SOLVES})
simgr = proj.factory.simulation_manager(state)
control_flow.add(state.addr)
while len(simgr.active) > 0:
for active in simgr.active:
control_flow.add(active.addr)
simgr.step()
control_flow = set()
state = proj.factory.blank_state(addr=start_address, remove_options={angr.sim_options.LAZY_SOLVES})
simgr = proj.factory.simulation_manager(state)
control_flow.add(state.addr)
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2021-2-11 07:02
被34r7hm4n编辑
,原因: