ptmalloc是glibc中对堆的实现,也是CTF中经常遇到的利用点。这里主要介绍malloc和free的实现思路以及我的看法,便于大家阅读相关部分代码。
malloc_state是ptmalloc中的所有的堆的管理结构,是一个静态的全局变量,他的作用是记录每个arena的当前状态。main arena的malloc state位于libc的数据段,是一个初始化了的静态变量,被动态ld程序映射到进程的mmap内存段。
参数req是用户请求的数据区的大小,是chunk_head后面的部分,因此转换后的size包含chunk_head。
struct malloc_state
{
__libc_lock_define (, mutex); //锁
int flags;
int have_fastchunks; //如果fastbin不为空,这个字段就被置位
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
mchunkptr top; //指向top chunk
mchunkptr last_remainder; //指向切割后剩下的last reminder
/* Normal bins packed as described above */
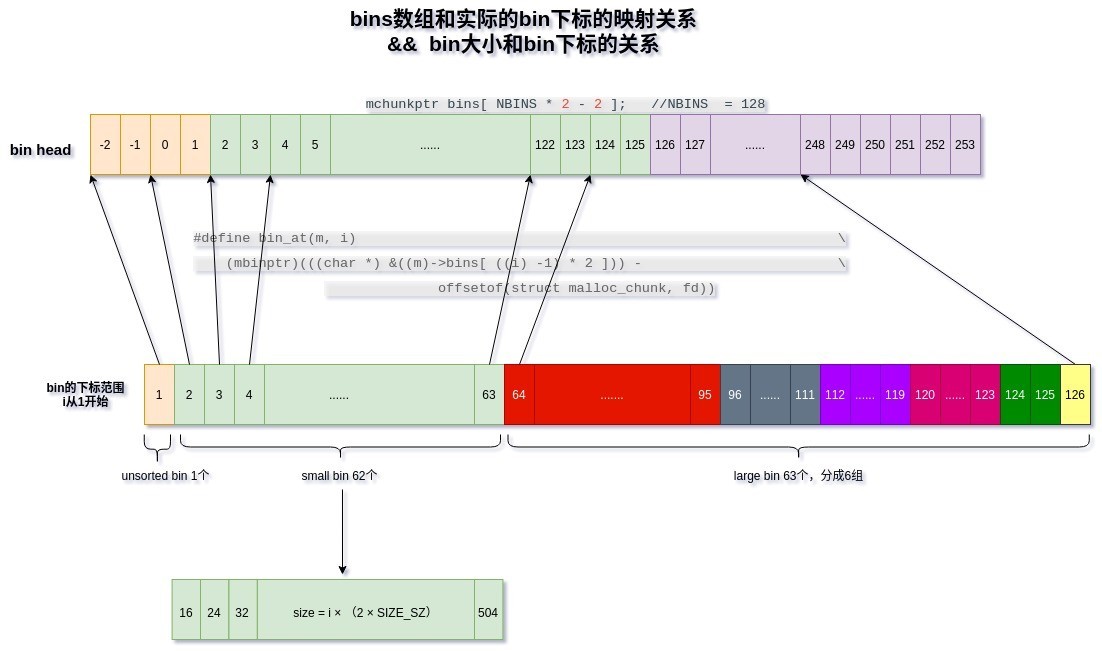
mchunkptr bins[NBINS * 2 - 2];
unsigned int binmap[BINMAPSIZE]; //bin的位图
struct malloc_state *next;
struct malloc_state *next_free;
INTERNAL_SIZE_T attached_threads; //引用当前arena的线程数量
INTERNAL_SIZE_T system_mem; //记录当前一个获取的系统内存
INTERNAL_SIZE_T max_system_mem;
};
static struct malloc_state main_arena = //main
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
}; 分配chunk时,由于当前分配的chunk正在使用,所以物理相邻的下一个chunk的prev_size字段无效,因此可以被当前chunk使用。从size的转换来分析这个过程:
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
MINSIZE : \
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) 参数req是用户请求的数据区的大小,是chunk_head后面的部分,因此转换后的size包含chunk_head。
四、fastbin(32位)
#define request2size(req) \
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
MINSIZE : \
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) 1、fastbin是malloc_chunk*类型的指针数组,是单链表的表头
malloc_state{
....
mfastbinptr fastbinsY[NFASTBINS];
....
} 2、支持的默认最大数据空间为64字节,但实际上最大可以为80字节,步进为8字节,64位下双倍。也就是fastbin最多有10个,下标为0~9,64位也是一样。
malloc_state{
....
mfastbinptr fastbinsY[NFASTBINS];
....
} 2、支持的默认最大数据空间为64字节,但实际上最大可以为80字节,步进为8字节,64位下双倍。也就是fastbin最多有10个,下标为0~9,64位也是一样。
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK)) 可以通过调用mallopt设置fastbin的最大值,mallopt调用set_max_fast设置全局变量global_max_fast,初始化时默认设置为DEFAULT_MXFAST,也就是说只使用下标0~7一共8个fastbin。
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK)) 可以通过调用mallopt设置fastbin的最大值,mallopt调用set_max_fast设置全局变量global_max_fast,初始化时默认设置为DEFAULT_MXFAST,也就是说只使用下标0~7一共8个fastbin。
如何根据传入的chunk size计算bin head?bin_index(sz)计算出size对应的bin的下标i , bin_at(m, i)根据下标i计算出对应的bin数组指针。
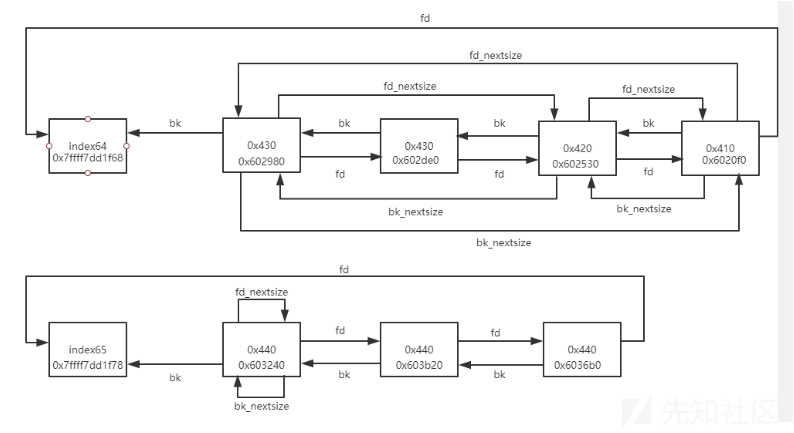
large bin有两条组织线:和普通的chunk一样通过fd、bk从大到小组织,另一条线就是通过fd_nextsize和bk_nextsize对相同大小的块进行划归,也即是对于相同大小的块,只有第一个块的fd_nextsize和bk_nextsize参与链接,这么做的目的我认为是可以跳掉中间很多不必要的比较,加快对空闲的large chunk的搜索速度!
main arena通过sbrk扩展堆,thread arena通过mmap扩展堆,因此非主线程的堆在mmap地址段。
_libc_malloc其实支持自定义堆分配函数,只要让钩子变量指向自己实现的函数,就可以用字节实现的malloc了!
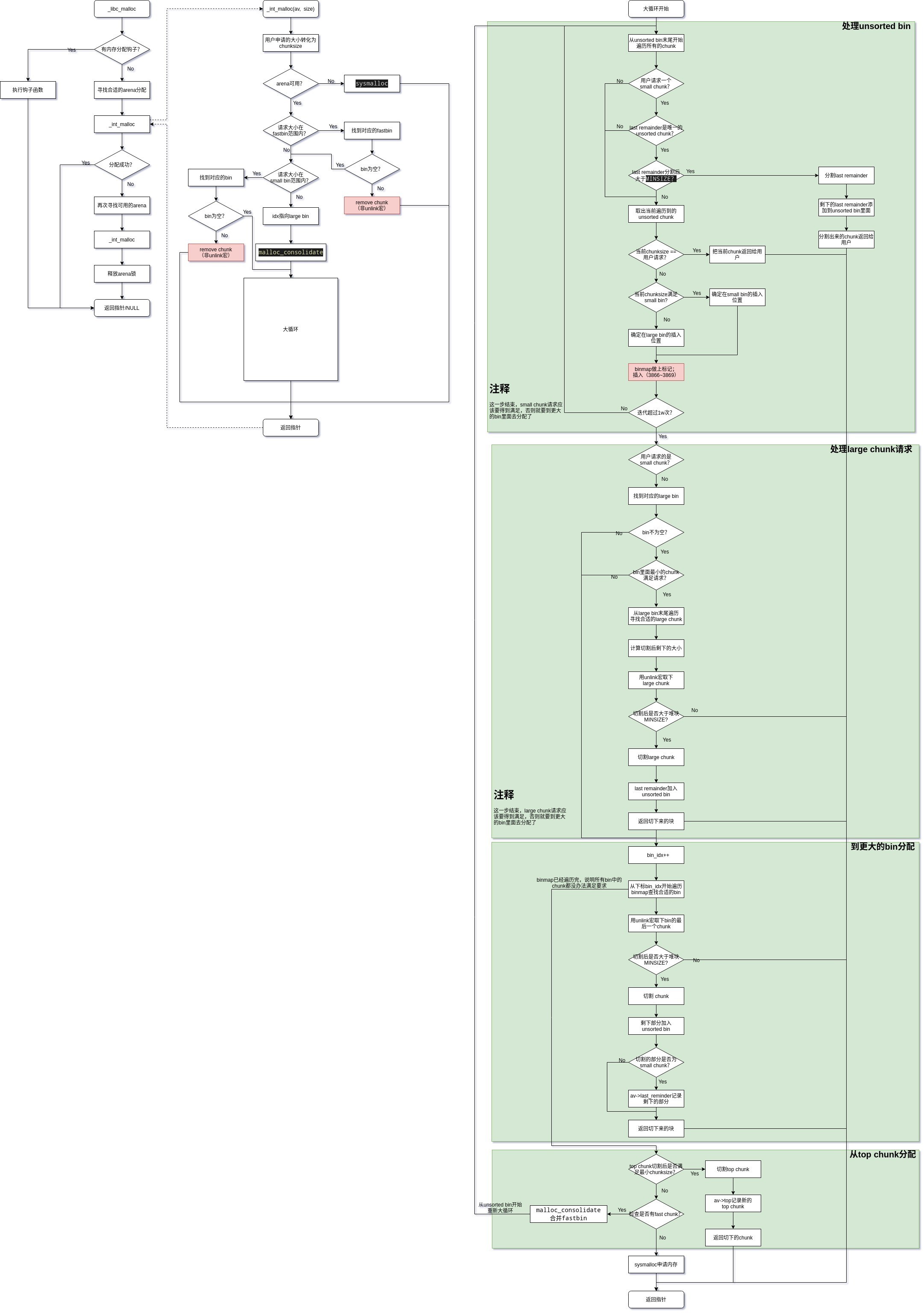
首先遍历fastbin和small bin,希望可以从中分到chunk,当然这是最理想的状态。
从fastbin和small bin中没有找到堆块,接下来就开始合并fastbin中的堆块,合并完了之后全部添加到unsorted bin,接着进入下面的大循环。
进入大循环有2条路径:1、请求的堆块为large chunk。2、small bin中对应的那个bin为空(small bin分配失败!)
大循环的主要功能是:
1、将unsorted bin里面所有的chunk都添加到small bin和large bin里面去。走到大循环这一步,说明前面的fastbin已经被合并过并且全部添加到了unsorted bin里面,所以这个时候fastbin是空的!但是在添加的过程中,如果遇到unsorted chunk的大小正好满足用户请求的大小,则直接退出添加过程,并将当前遍历到的chunk返回给用户。last remainder是unsorted chunk整理完了到最后才处理的,满足nb为small chunk这一条件即可从last remainder中分割一块返回给用户,剩下的last remainder继续加入到已经被清空的unsorted bin里面。到了这一步,small chunk请求应该要得到满足了,如果没有得到满足,说明需要到更大的bin里面分配。总之,大循环的第一个功能就是把unsorted chunk重新添加到各个bin,分配堆块只是它顺手完成的工作,当然能分配固然是好事,这样可以省好多事哈哈哈哈!
2、如果用户请求的是large chunk,那么large chunk的分配工作也是在大循环里面完成的。处理完unsorted bin紧接着就是处理large bin。
3、走到第三步说明严格按照用户请求的大小来分配堆块是不可行的,因此要向更大的bin申请堆块。这一步是通过扫描arena里面的binmap来寻找的。
4、如果到这里还没分到堆块,说明所有的bin都没有合适的堆块可以分配,只能向top chunk求救了。如果top chunk大小满足条件可以分割,OK直接从top chunk上切一块下来,剩下的作为新的top chunk。但是如果top chunk太小满足不了请求,只能再回过头到fastbin里面看看还有没有机会了,所以接下来会通过检查arena的have_fastchunk字段来判断fastbin是否为空,如果fastbin不为空,哈哈哈说明还有救,可以继续调用malloc_consolidate函数合并fastbin到unsorted bin,再跳到第1步重新遍历。这里可能会有疑问,fastbin不是前面已经合并过了么,不应该为空么,怎么到这里又有了呢?我的理解是,对于线程堆,可能当前线程睡眠的时候又有其他线程释放堆块到fastbin,对于主线程堆可能就不存在这种情况。
5、最后这里已经没有办法了,向sysmalloc求救,具体sysmalloc还没有研究......
关于last reminder块,这个块比较特殊,他的字面意思为从一个稍大的chunk割下一部分后剩下的部分。但是通过看代码,只有当割下的那部分是small chunk,那么剩下的才被当做last reminder并且被arena的last_reminder指针所记录。但是不变的是,不管怎么割,最后剩下的总是被放到unsorted bin。
if (in_smallbin_range (nb)) //只有请求的chunk为small chunk,那么剩下的才能作为last reminder
av->last_remainder = remainder; binmap是arena里面的位图结构,每个bit位都与一个bin对应,1表示bin不为空,0表示bin为空。
关于top chunk的解释,在malloc被第一次调用之前,堆区域还没被初始化堆空间为0,这个时候是没有topchunk的,此时的arena的top指针还是要指向unsorted bin。因此代码里面提供了inital_top宏来检查是否是第一次使用堆,通常使用if(av->top == initial_top(av))来判断。
if (in_smallbin_range (nb)) //只有请求的chunk为small chunk,那么剩下的才能作为last reminder
av->last_remainder = remainder; binmap是arena里面的位图结构,每个bit位都与一个bin对应,1表示bin不为空,0表示bin为空。
[注意]传递专业知识、拓宽行业人脉——看雪讲师团队等你加入!
最后于 2020-4-12 10:54
被极目楚天舒编辑
,原因: 勘误
上传的附件: