新型恶意软件通常会依据代码相似性, 或者某些厂商所谓恶意软件DNA或基因组分析来将其归类为某种已知恶意软件.
在这里, 我将描述一个简单的PoC, 例如“DnA GeNoMe mAlWaRe AtTrIbUtIoN EnGiNe”
它基于代码相似性采取两个特征来对恶意软件进行聚类:
首先, 使用以下代码通过r2pipe管道连接Radare2来提取二进制程序中的字符串:
接下来, 使用以下代码提取基本块:
之后, 对每个基本块进行掩饰, 即将块内的立即数和偏移量用0覆写(“掩盖”). 因为在不同二进制程序的不同偏移位置的值是不同的, 比如该值是会随着二进制程序版本而变化的内存地址, 所以这样的掩饰能确保基本块能在不同的位置下也能进行比较. 我们可以通过以下代码使用capstone:
最后但同样重要的是, 我们输出以tab分隔的字符串和基本块:
就是这样. 上述代码都保存在这个文件里 extract_features.py.
为了能输入大量样本并将输出格式化为Gephi的可用格式, 我们可以使用 extract_all.sh:
1.将 extract_features.py 和 extract_all.sh 以及一个包含有你样本的samples文件夹放置在同一目录下. 目录结构如下所示:
2.运行 ./extract_all.sh. 你的文件结构现在应该会像下面这样:
3.在Gephi中打开for_gephi.csv(依次点击File -> Import spreadsheet…)并作为邻接表导入.
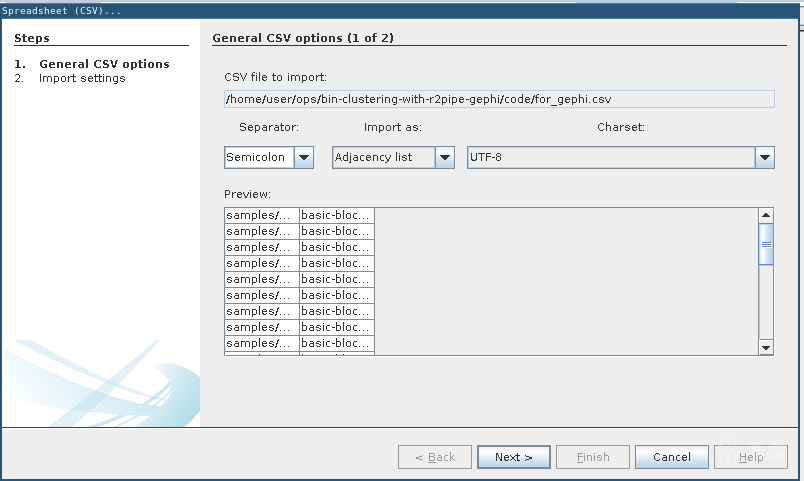
4.在导入设置界面上只需点击“Finish”.
5.导入报告中应该不会有错误警告
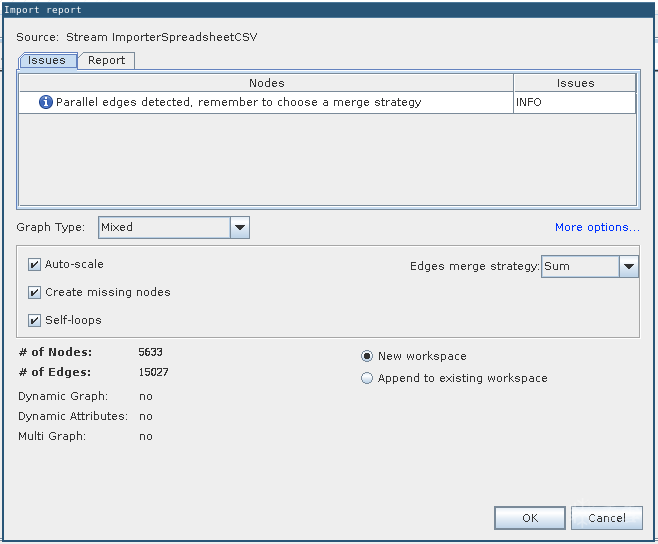
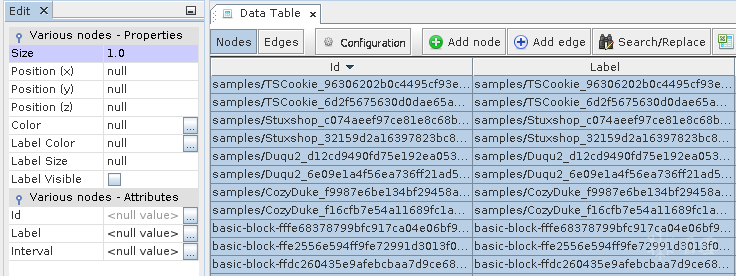
6.接下来转到“Data Laboratory”, 选取所有的节点, 右击并选择“Edit node”.
7.在属性窗口设置大小为1.0以及颜色为浅灰色.
8.接下来, 仅选择样本节点并将它的大小设置为20.0以及颜色为红色.
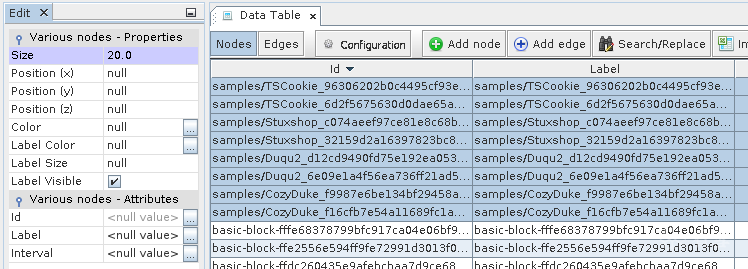
9.转到概要(“Overview”)视图, 并选取“ForceAtlas 2”布局, 随后点击“Play”.
10.当聚类结束时点击“Stop”, 然后转到“Preview”点击“Refresh”. 随后导出你的聚类图.
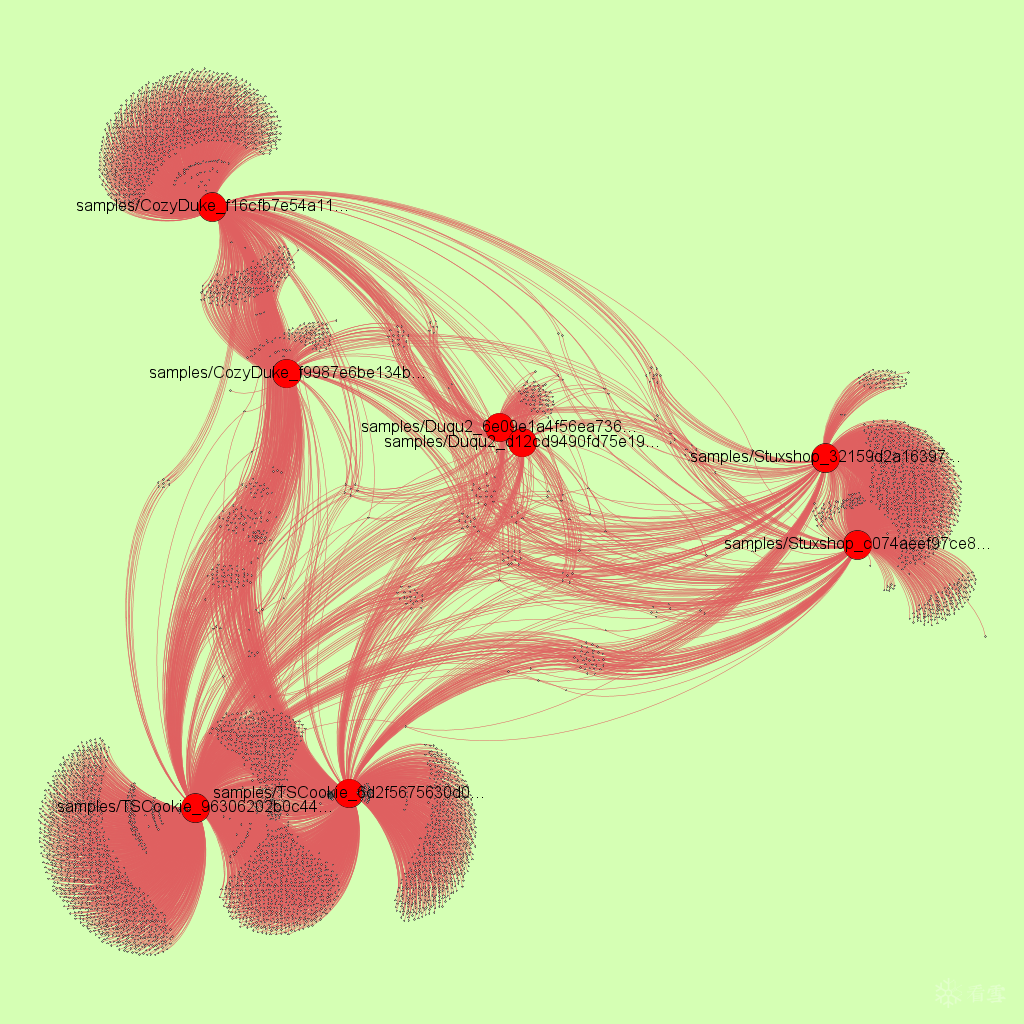
更新1: 11. 多花些时间设置颜色并应用“Yifan Hu”布局, 以及短暂播放一下“ForceAtlas 2”以防重叠, 你就能得到非常酷的聚类图像:

从结果图像可以看出, 两两相关的恶意样本都聚类在了一起, 即力导向图里通过基本块和字符串边而拉在一起.
显然, 与简单的PoC相比, 真实的聚类需要花费更多精力完成. 但是, 代码和字符串的相似性匹配是准确的. 因此, 如果掩饰后的基本块在两个样本均存在, 那么这意味着两个样本共享了某份代码, 至少共享了该基本块. 这里重要的是共享代码十分有意义, 例如许多二进制文件共享库代码. 虽然仅有少量指令的基本块显然也并不代表着有意义的代码共享, 但如果你在样本之间的关键函数中找到了一些共享的基本块代码, 那么它们很有可能就是相关的.
当你使用Gephi通过力导向图进行聚类时, 你还可以轻易计算出共享基本块的数量, 或根据特征的相似程度使用其他度量将不同的二进制程序归类到一起.
我希望这个简单的PoC能让人们开始进行共享代码和代码相似度分析的工作. 如果你在此基础上做了一些很酷的事, 请务必告知我 —— 我非常乐意看见这样的成果.
原文链接: Binary clustering with r2pipe, capstone and Gephi
翻译: 看雪翻译小组 Vancir
校对: 看雪翻译小组 Nxe
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课






