接 上一篇 固件分析--工具、方法技巧浅析(上)
在进行固件分析时,你可能会碰到某种程度上是加密的文件。在这种情况下,你首先需要确认是否是整个文件都加密了还是只有其中一块。如果是加密的,你可能还需要检查一下其详细信息。
计算熵是一种感知给定字节序列是否压缩或加密的有效手段。熵值大,意味着有可能是加密的或是压缩过的。熵值低,则正好相反。 不过,即使得到具体的熵值,也并不是总能立刻得到准确的判断。
binwalk 含有一个内建的熵计算器可以输出 2D 的图形结果。在熵值可视化方面,这个工具相当不错。不过,其输出的数据仅仅包含两个维度,一些细微的数据可能难以体现。
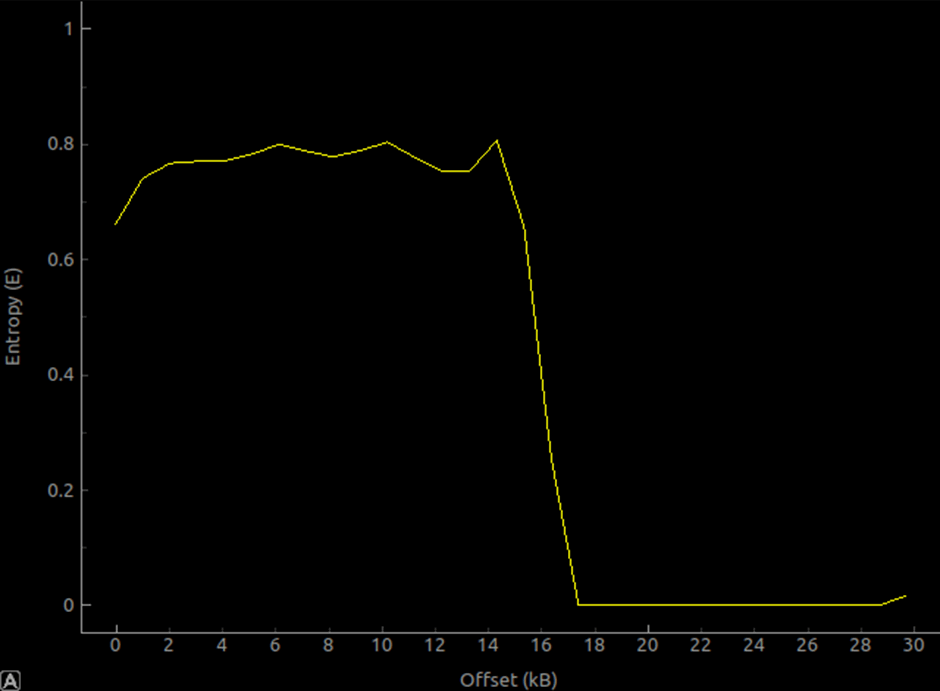
上图是 STM32F4 bootloader 的熵值。实际上,开头 16kb 的内容主要是裸机启动的 thumb bytecode(同时,这部分代码很有可能经过有针对性地简缩和优化过),使得该部分的熵值相对较高。尽管如此,熵值离 1 仍然远着呢,所以,很明显该部分并没有加密。后面 12kb 主要是 oxFF 字节,因此这部分计算出来的熵值极其的低,大部分几乎接近于 0 。
![11_binwalk_entropy.png] (https://raw.githubusercontent.com/StrokMitream/magic_images/master/translating_11_binwalk_entropy.png)
上图是一个加密过的大固件(超过 100 mb)的熵值图。该文件的熵值非常非常接近于 1 (高熵) 。不过,其中一些细小的凹陷处(0mb,90mb以及最右端处),表明这些地方的加密略有瑕疵。不放过这些细节,对接下来的分析可能会有帮助。
[ binvis.io ] 是一款相当不错的全彩二进制可视化分析工具。只要你不介意将文件上传到别人的服务器上,对小文件的分析,binvis.io 还是相当给力的。
binvis standalone binvis ] 的 C# 低度开发项目,好久之前就停止开发了。表面看起来,这个项目与 binvis.io 没有任何关联,但是,在离线分析上,尤其是大文件分析上,它确实做得很好。
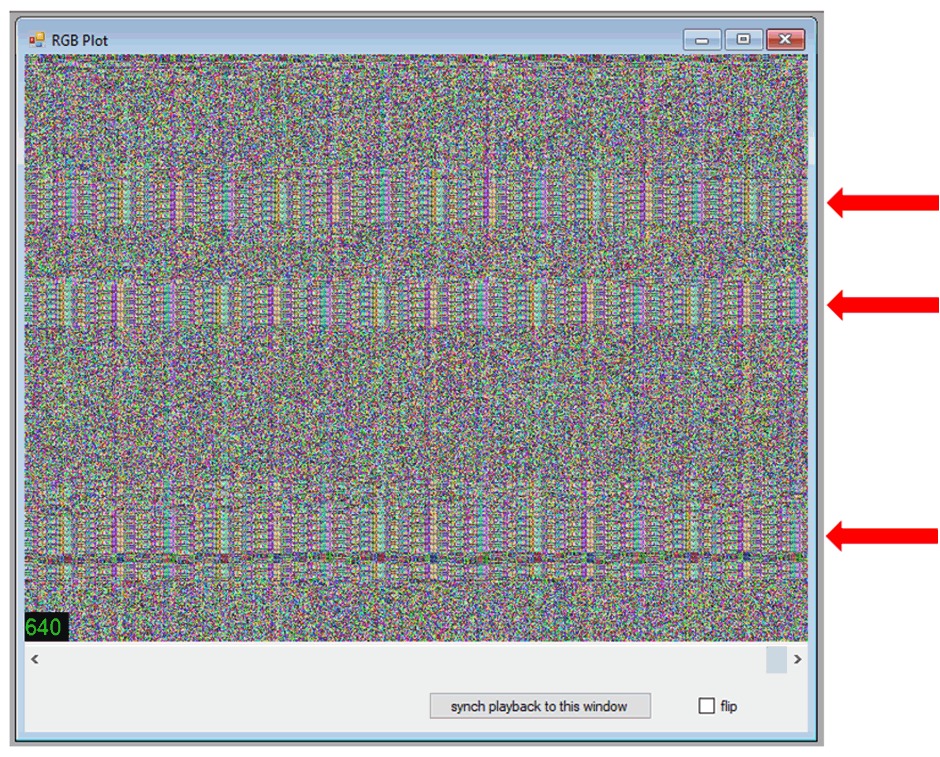
例如,RGB-plot ( 尽管没有 binvis.io 的输出光鲜亮丽)-- 是快速查看文件中是否有重复模式或低熵值区域存在的有效工具。
上图的例子是分析某大品牌路由器疑似加密的固件文件。从图中可以快速了解到,“加密”并非想象中的如此。你看到的固件文件中重复的模式,很有可能是某种程度上的加密,比如说 XOR(异或),而密钥则需要对该文件进行进一步的静态分析才可能找到(如果运气不太好,碰到了 ECB 模式的 AES,想要解密可能会难一些)。
有位牛人写了一篇“从数学角度探讨加密与压缩的差异”,请 参考 。
上述的大部分工具,都是针对运行有操作系统的 SoCs 固件设计的。不过有时,你也可能会碰到裸机 MCU 的固件。这种情况下,需要考虑其他策略来理解固件。
<a name="0gydd"></a>
如果可以上手,请先阅读 datasheet。千万不要低估这些 datasheet 的价值。我说 datasheet 可不是那些只有 60 页的产品销售说明,我说的是 1000+ 的编程手册,配合处理器核手册一起使用。
往往,datasheet 并不是公开的,存在隐秘的位置而却可供使用。有时,datasheet 存放在芯片的官网上等待下载。下面列举一些找 datasheet 的途径:
如果你实在是找不到任何 datasheet(可能性极低),你将要能识别出 entry-point 和固件的加载地址。可以试着在强大的 Google,一些论坛,源码或者其他 Web 角落里找找解答。如果有针对目标芯片的 工具链,那么往往也会有该工具的源码,这也许会引导你走向正确的方向。
没错,在裸机环境固件分析方面,IDA 依然是最有用(和通用)的反汇编工具。当谈论用 IDA 分析裸机二进制文件,即使是单独为此写一篇文章也不为过。不过,我们只是讨论分析裸机二进制文件的一般规则,只需要了解 加载地址(load address) 和 启动点(entry point) 这两个概念就行。
The load address is the address in memory that the binary is being executed from. The entry point is the location within the binary where the processor starts exeuting.
另外,你还需要清楚地知道你所分析的固件的背景信息。清楚其运行的处理器核心及其特性将会极大地有助于分析。如果你分析的是运行在 Cortex-M 系列芯片上的固件,那么想必对 infocenter.arm.com 这个网站不会陌生吧。
我们举个例子。我会用最常见的 ARM 裸机二进制文件来演示。
我们来看下 STM32F405 的 bootloader 。我们手头上有一个芯片,可以无限制地访问内存,可以 dump 任何东西,很方便上手。而 STM32 的 datasheet 都在网上公开,所以我们用 Google 大法找到了 [ STM32F405 ] 的。
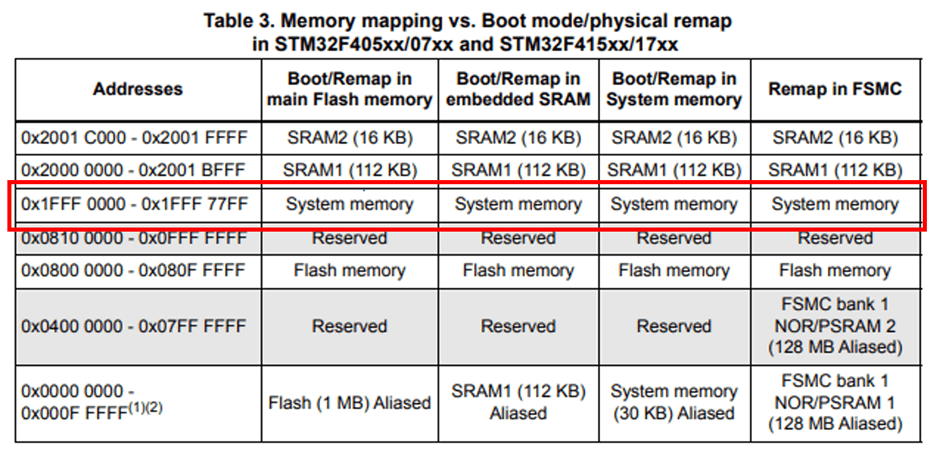
该 datasheet 显示,bootloader 位于“system memory”区。不过,具体是在哪个位置呢 ?
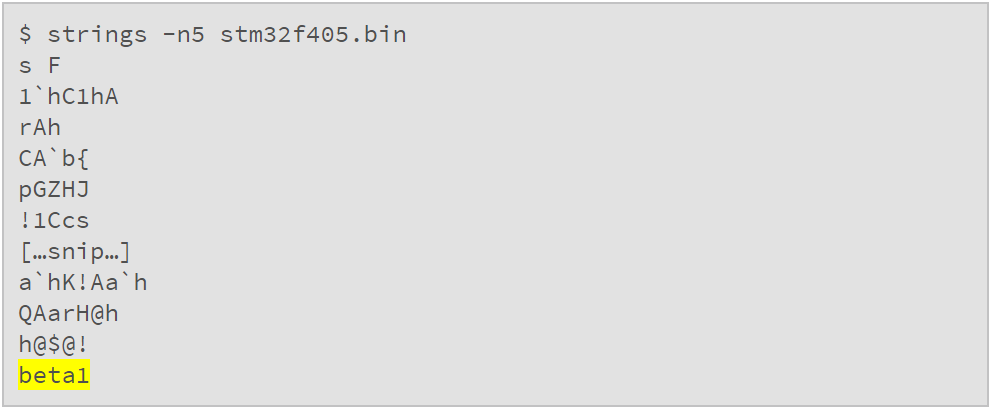
没错,这个表格告诉我们“system memory”在0x1fff0000 处。0x1fff0000 至 0x1fff77ff 的 bootloader 提取出来,我们就可以进行更为完整的检测了。比如看看是否包含字符串:
绝大部分是无意义的垃圾,只有一个有意义的字符串。或许换个编码方式可以探查出更多:
果然,相当不错,竟然还有内存引用地址,不错。
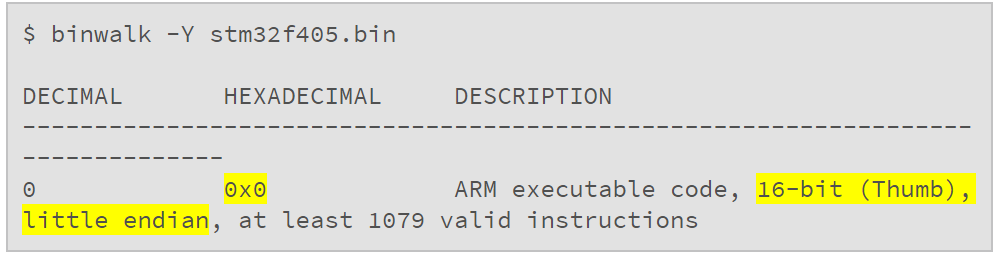
我们也可以检测该代码运行的目标处理器架构,大端还是小端。对此,我们可以(再次)使用 binwalk 。binwalk 早已内置有操作码扫描器,只需添加 -Y 选项激活使用。现在,它并不是进行 magic-byte 扫描。取而代之的是,利用 Capstone engine 来检测针对主流系统架构的有效指令,采集包括合法的指令序列,架构和字节端序。仅是想快速分析手头上的固件这是相当有用的方法,无论你之前对该固件有多少了解。binwalk 对 STM32F405 bootloader 分析:
有一点必须强调,就是 binwalk -Y 只是一个检测文件中是否包含有效字节序列是手段。它并不会返回关于固件本身的其他信息,仅仅判断是否存在有效的 bytecode 而已。
该结果表明,从 0 偏移起,Capstone 引擎检测到有效的小端 Thumb 码—— 1079 个有效指令,相当长的一段代码。知道了这些,接下来我们可以把该固件加载到 IDA 中。
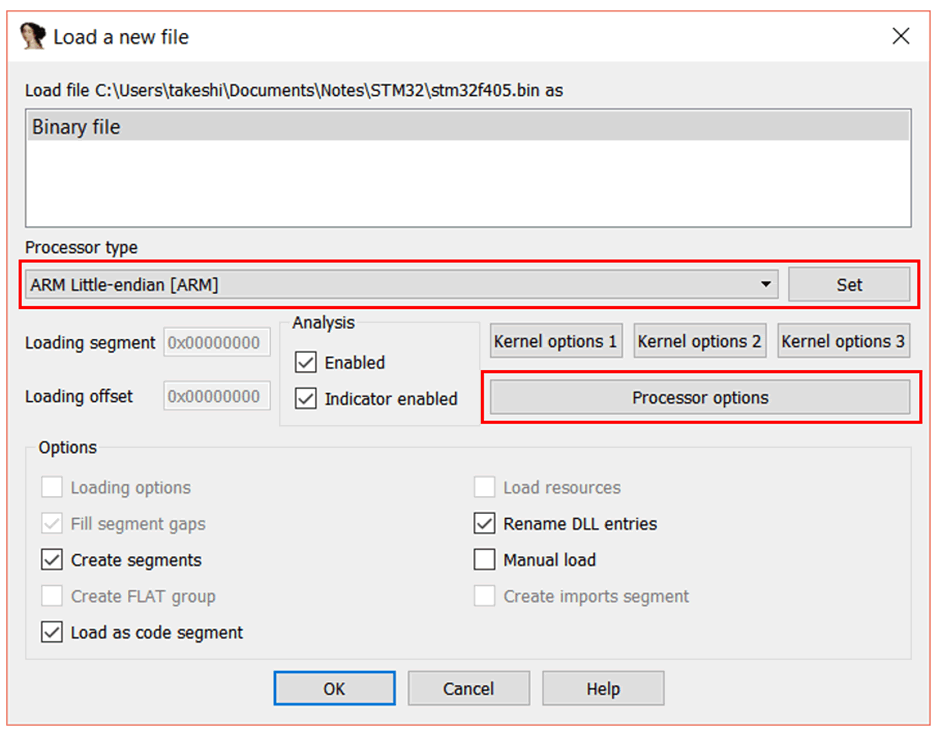
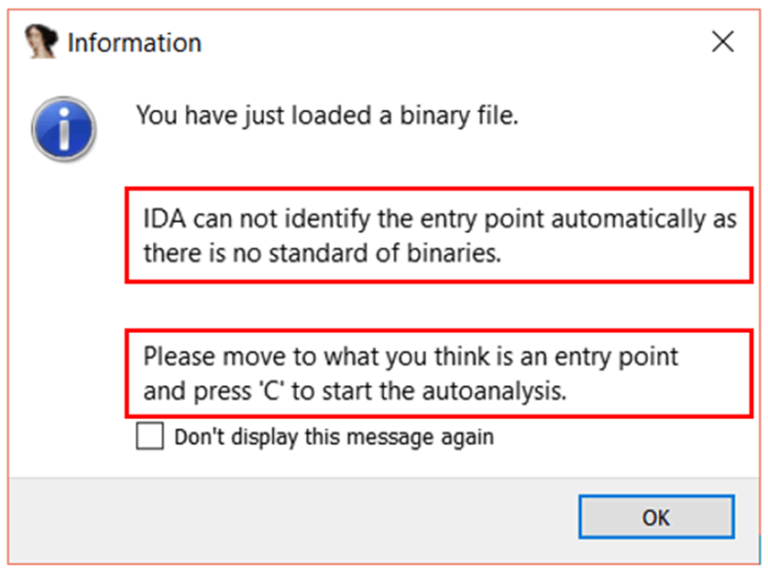
在 IDA 中打开该文件,将会看到弹出窗口。当前条件下,IDA 处理不了,所以需要修改“Processor Type(处理器类型)”为“ARM Little-endian [ARM](ARM 小端)”,然后点“Set(设置)”。
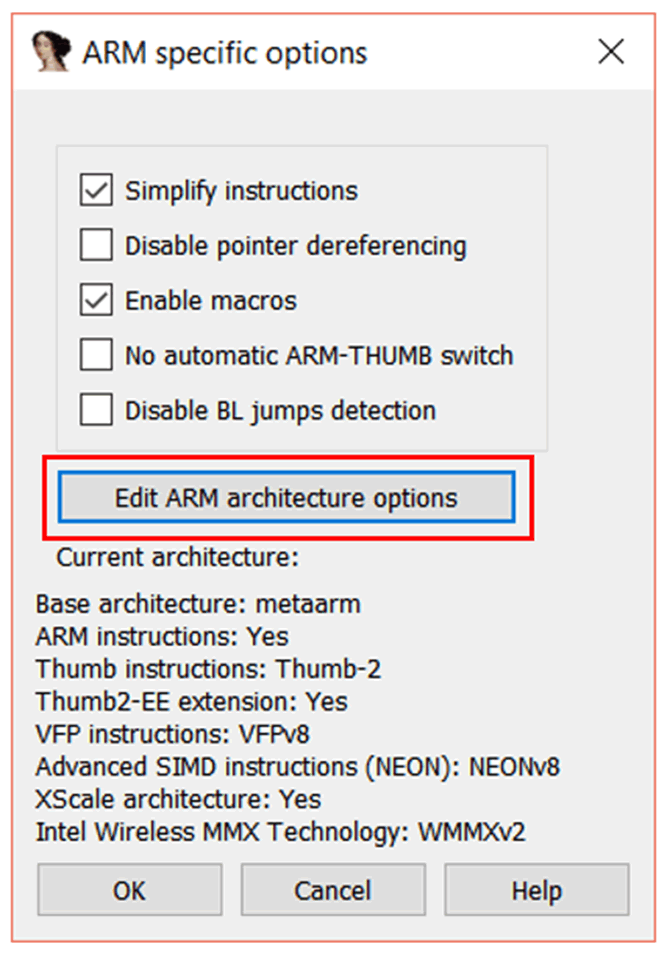
如果你想排除 ARM 代码(只保留 Thumb),可以这样设置:
点击“Edit ARM architecture options(编辑 ARM 架构选项)”按钮。
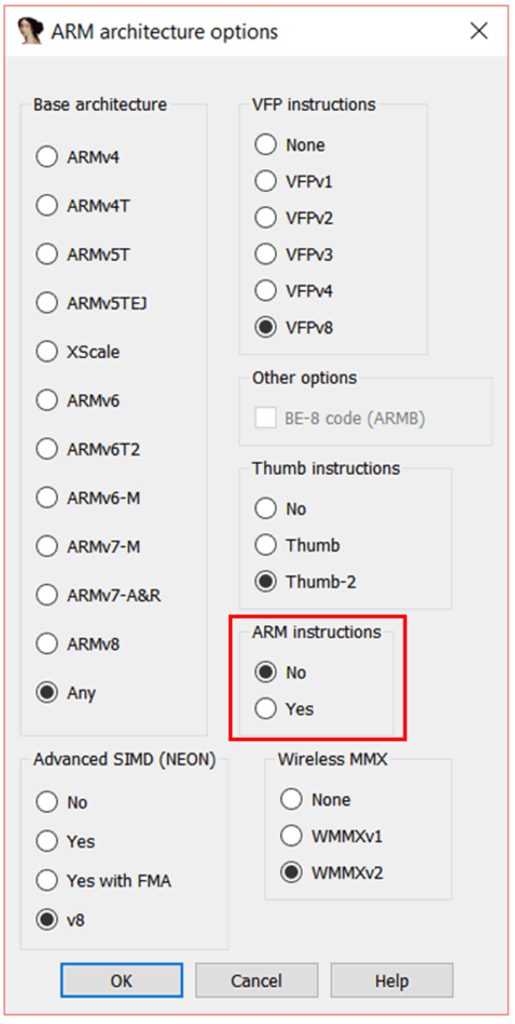
在“ARM architecture options(ARM 架构选项)”窗口,设置“ARM instructions(ARM 指令)”为“No”。保持 Thumb 指令部分设置默认不动。点击“OK”“OK”“OK”,IDA 将会再次提醒你——这次是让你配置内存空间。
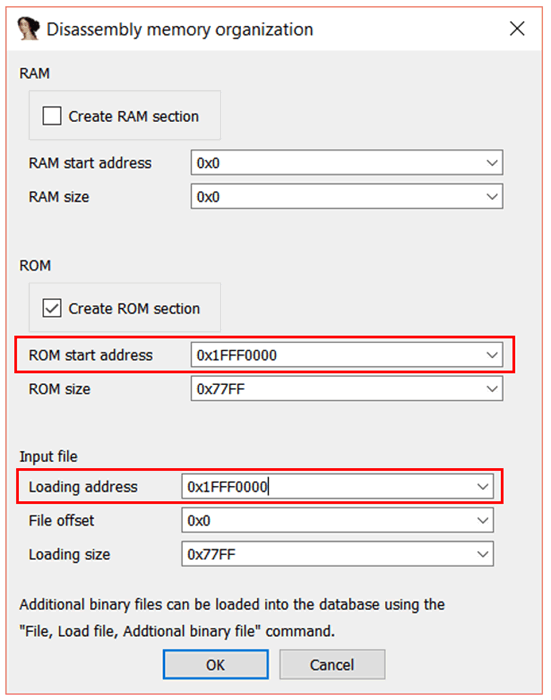
我们此前已经知道,bootloader 从地址 0x1FFF0000 处拉起。因此在 “ROM start address”处输入 0x1FFF0000 。同样,我们还需要将设置“Loading address”映射到这个位置,所以也设置为 0x1FFF0000 。
点击“OK ”,此时可能会有弹出提示,可以通过 Alt + G 的快捷键来在 ARM 和 Thumb 之间切换。有时这是一个不错的小技巧,不过并不是很简单易懂,因此接下来我们来稍微深入一下。
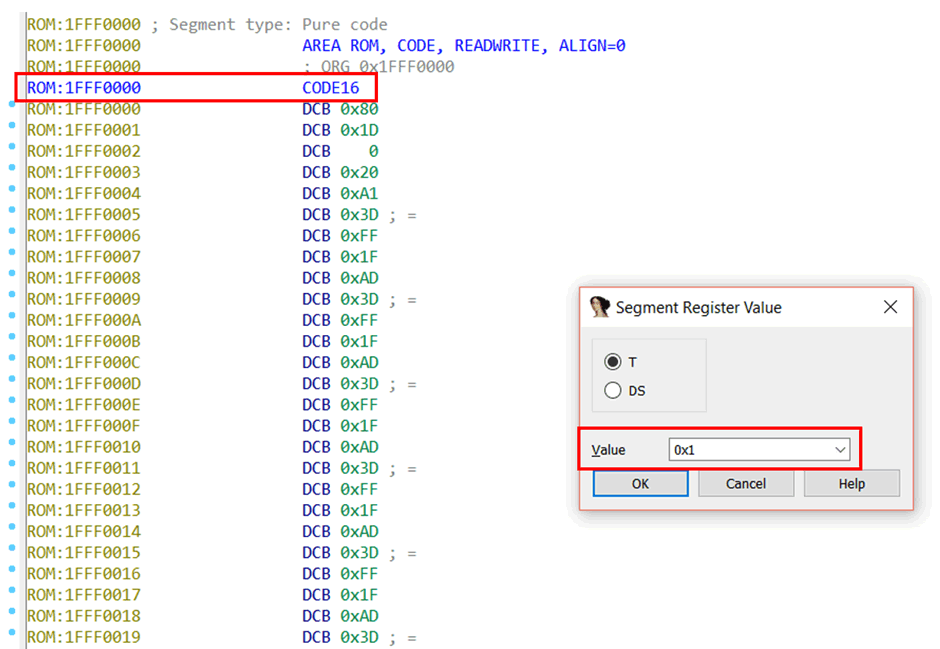
当二进制文件加载到 IDA 后,如果你点击一个地址(举例来说,这里我们是 0x1FFF0000 )然后按 Alt+G ,那么弹出“Segment Register Value”窗口。
![19_SegmentRegisterValue.png]
“Value”处的 0x1 意味着在该点( 0x1FFF0000 )后面的代码将会被看作 Thumb 指令。该处的设置反映到 ARM processor status register 将会是“T”标记。而“T”标记被设置为 1 意味着 Thumb code 执行,0 的话则是 ARM code 执行。
提醒一下,“CODE16”标记也会加到该地址处。如果“T”flag 被设置为 0x0,ARM 代码执行。在这种情况下,CODE32 将会添加到该处。
你可以选择文件中的任何一处地址,将其 Value 设置为 0x0,那么该地址后面的所以代码将会被看作 ARM 。因为我们此处是想要 Thumb 指令,所以设置 Value 为 0x1 。
OK IDA,我们把这个搞定。
我们可以通过 [ 中断向量表 ] 弄清楚 entry point。我们只需知道向量表中哪个入口是 Reset vector(重置向量)即可,因为重置向量就是我们的 entry point。是的,你猜的没错,重置向量是机器重启后 CPU 开始执行代码的地址。
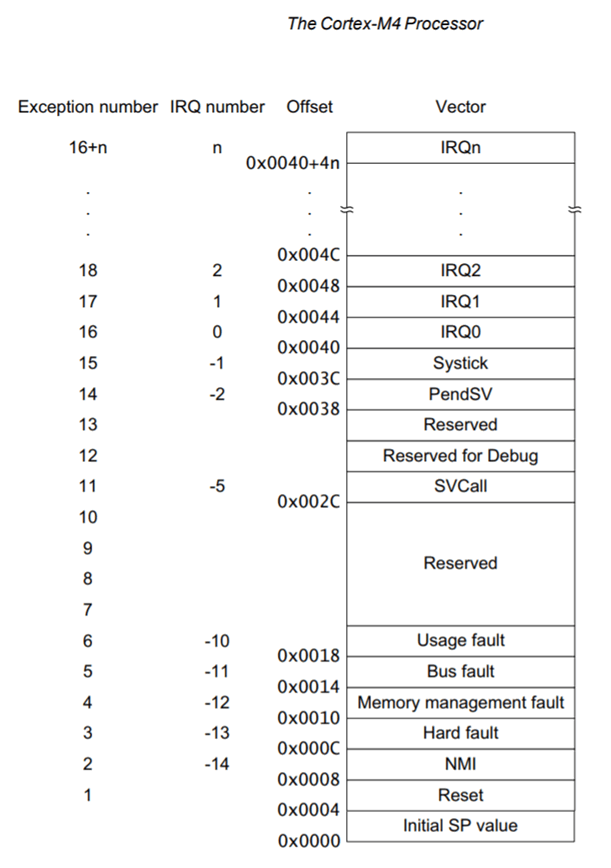
这块 STM32F405 是 Cortex-M4 内核的,所以可以 Google 一下 Cortex-M4 的向量表。在 [ Cortex-M4 设备通用指 南 ]中,我们发现了这个:
这相当有意思,我们且先记下来。另外,还有这个:
这张表表明,指向 0x0 偏移的是栈指针的初始位置,偏移 0x4 处是重置向量,指向 0x8 的指针是 Non-Msakable 中断,等等。而中断向量是处理器启动后开始执行代码的地址。
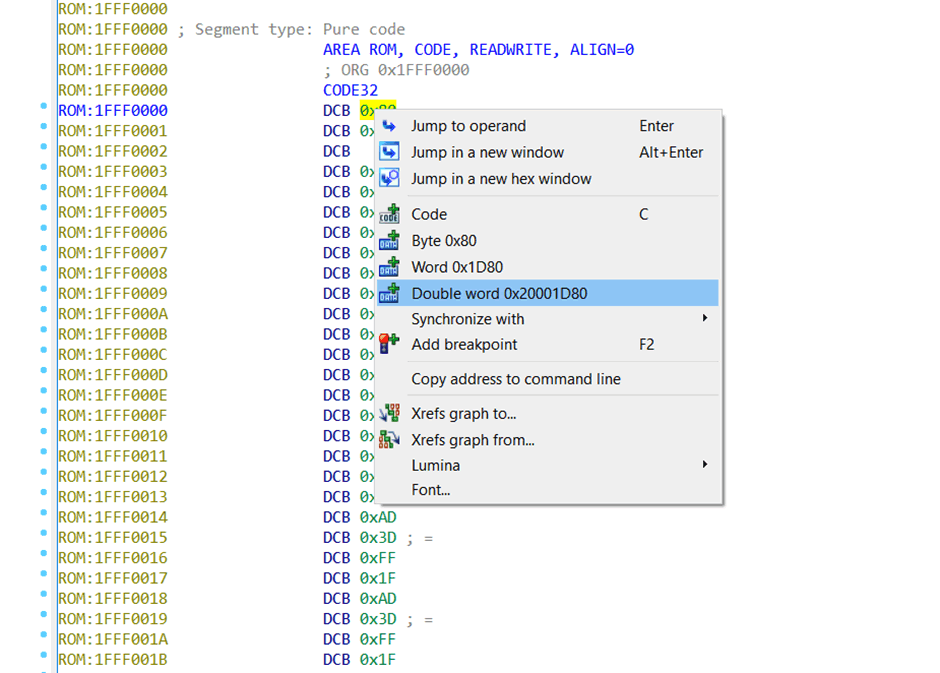
在 IDA 里,我们可以定义位于地址 0x0 , 0x4 , 0x8 的数据为 “双字”(即 32 位宽)。右击地址 0x1FFF0000 的字节,选择“Double word(双字)”, 0x1FFF0004 等同理。
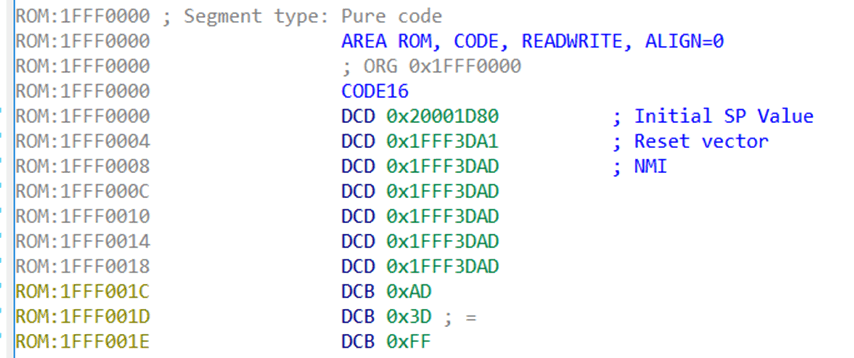
来看下下图。我自行添加了一些注释,这样看起来就明了清楚。偏移为 0x0 处的是初始栈指针,指向的是 SRAM 中一段内存(从 datasheet 中得知的),所以这讲得通。
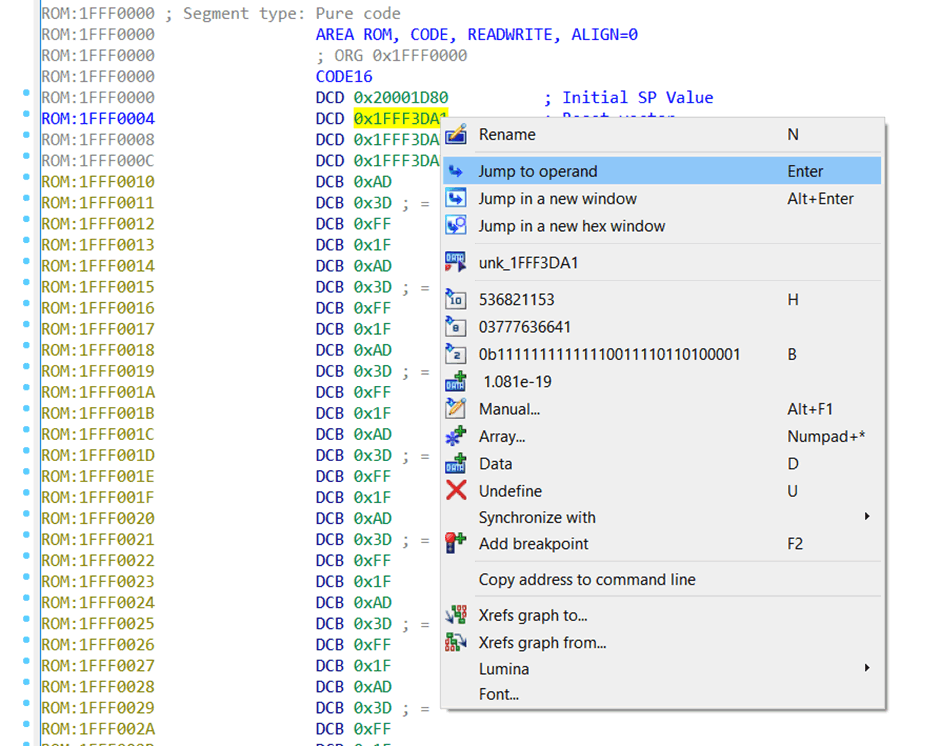
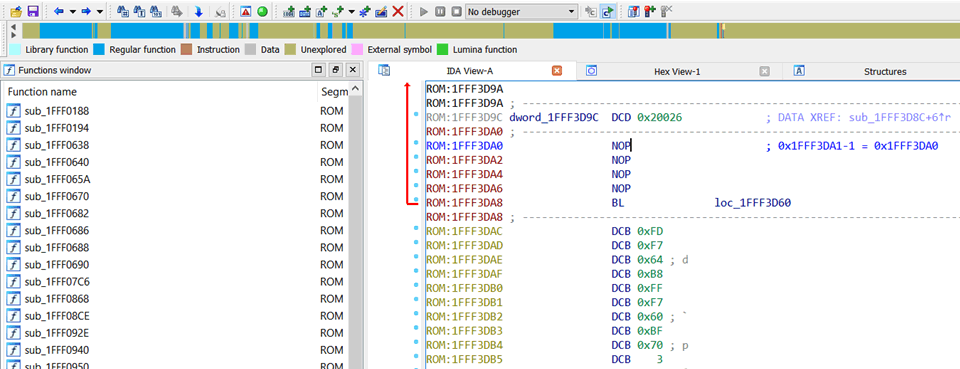
重置向量, 0x1FFF3DA1 ,同样是合情合理。我们跳到这个位置看下。可以高亮选择,让后按“Enter”键,或者选择“Jump to operand”。
不过,记得先前 Cortex-M4 手册中说的! 在 Thumb 模式下,重置向量的最低有效位已经加 1 了。所以,实际的重置向量是(Reset vector - 1)。
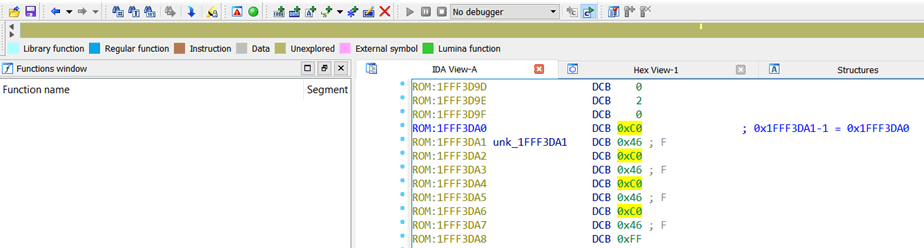
注意到 IDA 顶部的 褐黄色的条了吗 —— 这表明到目前为止,尚未解析出文件的任何内容来。我们将改变这种情况。
选中 Reset vector 的地址,减 1,按“C”,IDA 将会开始反汇编。
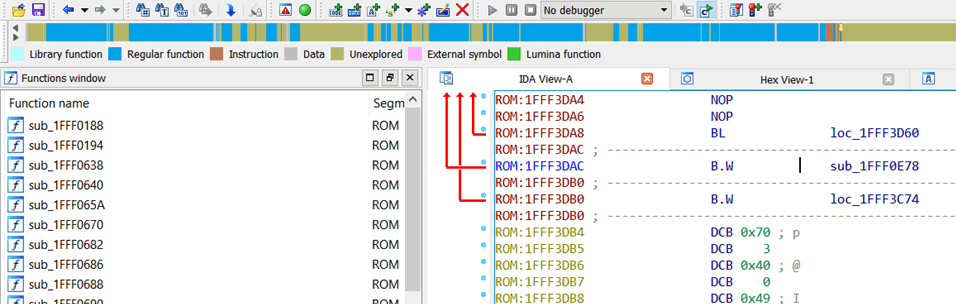
Well,看起来有意思。许多子例程被定义,所以状态条上的蓝色部分也逐渐增多。顺着这些向量表中唯一的指针进行下去,将会有更多蓝色浮现。
从这里,你可以开始研究固件内部错综复杂的工作原理了。
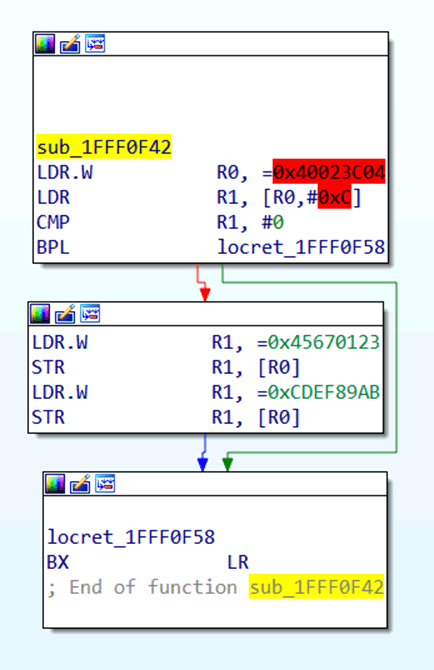
Pokey-pokey. 我们来快速看下这个子例程,只是让大家更快上手。在该例程中,可以看到值 0x40023C04 被加载到 R0 寄存器,然后值 0x45670123 和 0xCDEF89AB 被顺序写入内存的 0x40023C04 位置。
红色高亮标记部分的内存地址是将要访问到的地址,并未映射到 IDA 文件中。因此,内存 0x40023C04 处的内容并没有映射到当前的 IDA 文件中。我们实际上也不需要真正地映射过来,不过你可能想到 datasheet 中看看这个地址到底是做什么用的。
通过浏览 STM32F4 的 datasheet ,我们可以了解到 0x40023C04 位于 Flash接口寄存器的内存段:
而且,相对基地址 0x40023C00 偏移 0x4 与 Flash key register (FLASH_KEYR)。
看,datasheet 列出了数值 0x45670123 和 0xCDEF89AB —— 这两个是解锁 Flash 控制器的寄存器。所以,这就是这个子例程完成的事情。
记得准备好 datasheet ,以便随手翻阅,这东西还是很管用的。
在网上的某个角落里有 IDA Scripts 用来辅助 IDA 嵌入式固件分析。 IDA Python Embedded Toolkit 是一套众所周知的工具,可以降低对裸机固件逆向分析的难度。不过,通常来说,在网上谷歌查找具体的芯片型号的相关资料往往不会让人失望,这将节省许多时间。网上存在的众多特异性(有针对性的)代码,将有助于逆向难以捉摸的芯片固件。
[招生]科锐逆向工程师培训(2024年11月15日实地,远程教学同时开班, 第51期)
最后于 2019-10-1 22:58
被StrokMitream编辑
,原因: 2019-10-01,修改一些标题格式。