
能力值:
 ( LV2,RANK:10 )
( LV2,RANK:10 )
|
-
-
2 楼
 看看
|
能力值:
( LV2,RANK:10 )
|
-
-
3 楼
继续请教,谢谢先
|

能力值:
![]() (RANK:410 )
(RANK:410 )
|
-
-
4 楼
当然是根据下面的结构计算出来的。
typedef struct tagLOGFONT { // lf
LONG lfHeight; = F4FFFFFF
LONG lfWidth; = 00000000
LONG lfEscapement; = 00000000
LONG lfOrientation; = 00000000
LONG lfWeight; = 90010000
BYTE lfItalic; = 00
BYTE lfUnderline; = 00
BYTE lfStrikeOut; = 00
BYTE lfCharSet; = 86
BYTE lfOutPrecision; = 00
BYTE lfClipPrecision; = 00
BYTE lfQuality; = 00
BYTE lfPitchAndFamily; = 00
TCHAR lfFaceName[LF_FACESIZE]; = CBCECCE5 '= 宋体'
} LOGFONT;
|
能力值:
( LV2,RANK:10 )
|
-
-
5 楼
谢谢老大!
那就是说long是4个字节(5个long就是20个字节了),byte是一个字节(8个type就是8个字节了),那就是TCHAR是4个字节了,对吧
|
能力值:
![]() (RANK:410 )
(RANK:410 )
|
-
-
6 楼
前面你说的没有错,不过TCHAR是一个字节,不是4个字节,只是lfFaceName变量是一个TCHAR变量数组,他的大小就是1个字节*LF_FACESIZE=n个字节。而LF_FACESIZE被定义32,所以lfFaceName是1*32=32个字节大小。也就是说这个变量最小可以变1个字节内容,最大可以放31个字节的内容(最后一个字节必须为零)。
|
能力值:
( LV2,RANK:10 )
|
-
-
7 楼
那就糊涂了
要是TCHAR是1个字节
怎么计算 LOGFONT 是32个字节呢?
继续请教,谢谢先
|

能力值:
 ( LV9,RANK:850 )
( LV9,RANK:850 )
|
-
-
8 楼
TCHAR是一个字节没错,但是那是一个数组,"宋体"这个字符串有四个字节,
所以算起来是五个long(4*5) + 8个BYTE(1*8) + strlen("宋体")(4个字节) = 32
|
能力值:
( LV2,RANK:10 )
|
-
-
9 楼
“宋体”=CBCECCE5,请问这个是怎么得到的?
谢谢先
|

能力值:
( LV2,RANK:10 )
|
-
-
10 楼
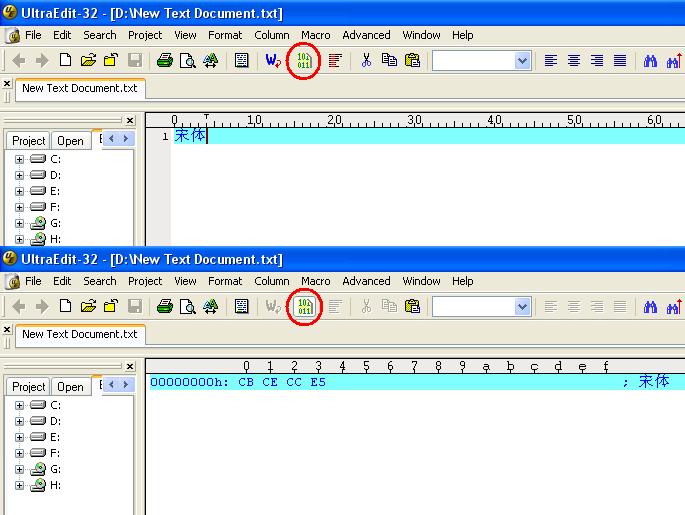
用记事本新建一个文本文件,写入“宋体”两个字,保存的时候选ANSI编码,再用16进制编辑器打开就看到了CB CE CC E5
|
能力值:
( LV2,RANK:10 )
|
-
-
11 楼
用记事本新建一个文本文件,写入“宋体”两个字,保存的时候选ANSI编码
===我建立了
但是使用UE打开的时候,就是只有“宋体”两个字,并没有CB CE CC E5
不知为什么?
不过我现在知道那个是GBK的编码了,就是不知怎么样才能更好将汉字转化成编码?
谢谢先
|
能力值:
( LV2,RANK:10 )
|
-
-
12 楼
路过,学习!
|
能力值:
( LV2,RANK:10 )
|
-
-
13 楼
晕,新来乍到看的头晕
|
能力值:
( LV2,RANK:10 )
|
-
-
14 楼
不是吧?UE这么经典的工具还没研究过?
|
能力值:
( LV2,RANK:10 )
|
-
-
15 楼
谢谢icersg大侠!!!
我是菜鸟,感觉那个UE也是功能很强大的 呢
使用UE有段时间了,文本文件比较大的我都是使用UE打开,要是使用记事本打开很快就死机
但是UE的高级功能,比如如何使用UE写Java,C++,asm倒是没有搞过
我都是使用相关的IDE来做 的
|
|
|
|





