大家好我是TeddyBe4r, 好久不见,这次给大家带来,图拓扑编译器开发指南。
本文是图拓扑签名系列的第一篇,介绍叶子节点注入(LeafNode Inject)和定位(LN Located)的完整实现思路与工程细节。后续 Part2 将在此基础上引入拓扑形状编码,构建双层水印体系。具体代码考虑在写完系列之后再开源V2或者部分V3版本的。扫描器因为有自己的静态分析框架所以不打算开源,大家只能自己研发扫描器了可能需要自己实现一个IR提升加CFG重建。ICFG以及一些优化。
软件水印是版权保护和溯源追踪的重要手段。传统的字符串水印、常量水印很容易被静态扫描识别并手动抹除。基于控制流图(CFG)拓扑结构的水印方案理论上更难被简单 patch,但实现复杂,且容易被编译器优化静默消除。
之所以选择在 LLVM Pass 层做,是因为能在 IR 级别操控 CFG,比在二进制层 patch 更干净,也不依赖特定架构。
之前尝试过一版纯拓扑水印(通过 dummy 子图的形状编码 nibble),遇到的核心问题是:
这一版(Part1)的思路是退一步:先解决"注入后能不能在二进制层可靠找到"的问题,把定位和编码解耦。定位用特征指令序列(SAS),编码留给后续 Part2 的拓扑形状,我一共写了三版
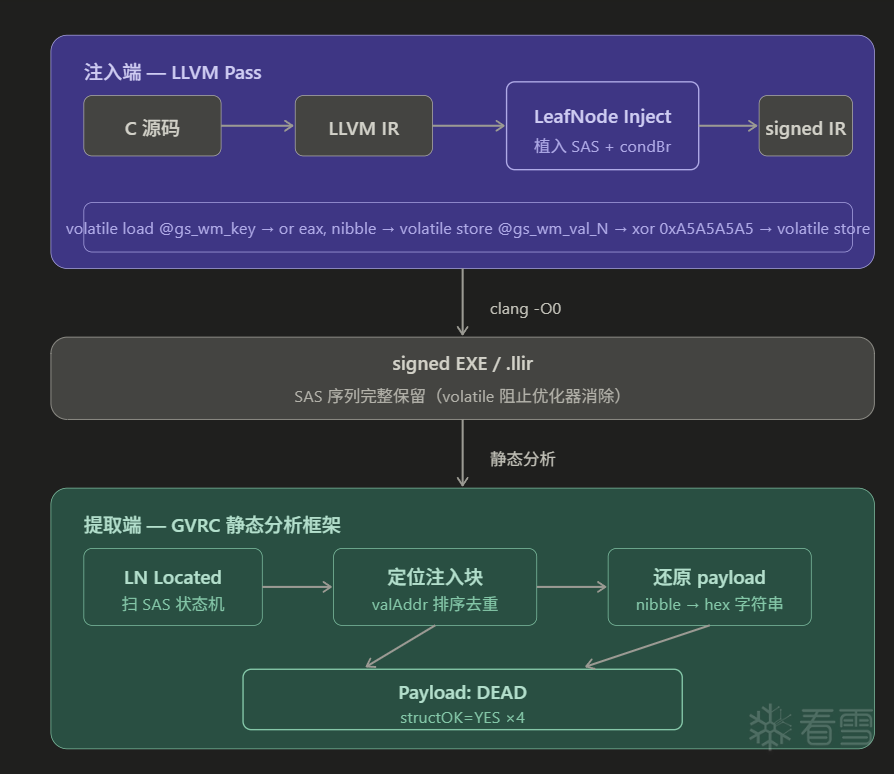
主要架构是分为两个端的
CFG 里的叶子节点(outDegree=0,即含 ret 指令的块)是注入的理想位置:
和选 outDegree=1 的中间块相比,叶子节点不会影响后续块的前驱关系,引入的 CFG 变化最小。但是说实话我分析了DAG的OPT找到了更好的方法去做这个事情等我完全版的时候就会把纯粹的Graph DIff 加上去但是工作量太大了,对于一个人来说属实不太友好。
SAS(Signature Access Sequence)是植入叶子节点的特征指令序列,由 3 个 volatile 操作构成:
全部标记 volatile 的原因是阻止 SCCP 和 GVN 把全局变量推导为编译期常量。之前没有 volatile 的版本在 -O1 下会被整个消除,加了之后 -O2 也能保留。
校验写的目的是让提取端能够验证结构完整性:enc XOR 0xA5A5A5A5 == chk,如果二进制被 patch 过,这个等式大概率不成立。
注入流程分四步。
第一步,找叶子节点
Pass 遍历函数里所有 BasicBlock,筛选条件是 terminator 为 ReturnInst 且后继数为 0。这类块是函数的自然出口,注入后只需在末尾追加代码,不会影响前驱块的跳转关系,是改动最小的注入点。
第二步,split 叶子块
对选定的叶子块调用 splitBasicBlock,以原来的 ret 指令为分割点,把块拆成两半。前半段保留所有原始指令,末尾由 split 自动插入一条无条件跳转到后半段(leafTail);后半段只含原来的 ret。这一步必须在创建 sentinelBB 之前完成,否则中间窗口期会有无 terminator 的空块挂在函数上,pass-pipeline 内联验证器会直接崩溃。
第三步,植入 SAS
在前半段末尾的无条件跳转之前,插入特征指令序列。先 volatile load @gs_wm_key 作为定位锚点,接着 or %k, nibble 把水印值编码进低4位,然后 volatile store 写入 @gs_wm_val_N,再 xor 0xA5A5A5A5 做校验运算,最后再 volatile store 覆盖写一次。五条指令全部或依赖 volatile,SCCP 和 GVN 均无法推导其值,DCE 也无法消除。
第四步,替换 terminator,接入 sentinelBB
创建 sentinelBB,内部只有两条指令:volatile store 0xC0FFEE00|(idx<<8) → @gs_wm_magic 和 unreachable。然后把前半段末尾 split 插入的无条件跳转删掉,换成 condBr(always_false, sentinelBB, leafTail)。always-false 条件的构造方式是 volatile load @gs_cv,平方后与 0 比较小于,平方永远非负所以条件永远为 false,但因为 load 是 volatile 的,SCCP 看不到这个结论,无法删掉 sentinelBB 分支。
至此注入完成,原始函数行为不变,leafTail 的 ret 是唯一实际执行的出口,这里的FakeBranch 也可以换成其他的可控随机行为作为跳转条件甚至你想还可以加上MBA混淆使其FakeBranch更不容易被识别,我举几个例子
condBr 的条件是 sq = gs_cv * gs_cv; sq < 0(平方永远非负,所以永远 false),gs_cv 也是 volatile 的,阻止 SCCP 推导。
叶子节点收集:
splitBasicBlock 时序问题:
必须先 split,再创建 sentinelBB。如果先创建 sentinelBB 再 split,中间窗口期会有一个无 terminator 的空块挂在函数上,pass-pipeline 内联验证器会崩溃。
多 nibble 复用同一叶子:
当叶子节点数量少于需要的 nibble 数时,会对同一个叶子反复注入。每次注入都对上一次注入产生的 leafTail 继续操作,结果是叶子块被拆成多段,每段末尾各挂一个 sentinelBB。这是当前实现的一个限制,Part2 会改成每个叶子只注入一次。
提取端运行在自研的静态分析框架上,输入是 .llir 格式的反汇编文本,框架解析后得到 CCFG/CBasicBlock/CInstruction 的内存表示。
最初设计里 sentinel 块(含 mov gs_wm_magic, 0xC0FFEExx 的不可达小块)是定位入口。但实测发现,当同一个叶子节点被注入多次时,多个 sentinel 块在编译后会被合并到同一个连续区域,不再是独立的小块,前驱关系也变得混乱。
所以放弃 sentinel 定位,改为直接扫 SAS 模式。
.llir 使用 Intel 语法,操作数在 m_vecOperands[0].m_strRaw 里是整串,格式如:
因为一直感觉自己写的静态分析框架够用就一直用的Intel语法代替的IR,所以会看到形似汇编的东西,但是实际上汇编已经包含了一些信息,我的LLIR还增加了一些其他的东西 用于提升更多的语义细节,所以看到我的IR和Intel语法类似不要惊讶。
几个解析细节,这里实现上的细节还是要看一下的:
用状态机按顺序匹配这5条指令:
任何一步不匹配都回到 IDLE 重新开始,避免误判。
每条 SASRecord 里有:
按 valAddr 数值升序排列(60208C < 602090 < 602094 < 602098),对应 nibble 0~3,拼接得到完整 payload。
去重处理:同一 valAddr 在多个函数里重复注入时只保留第一次出现的记录。
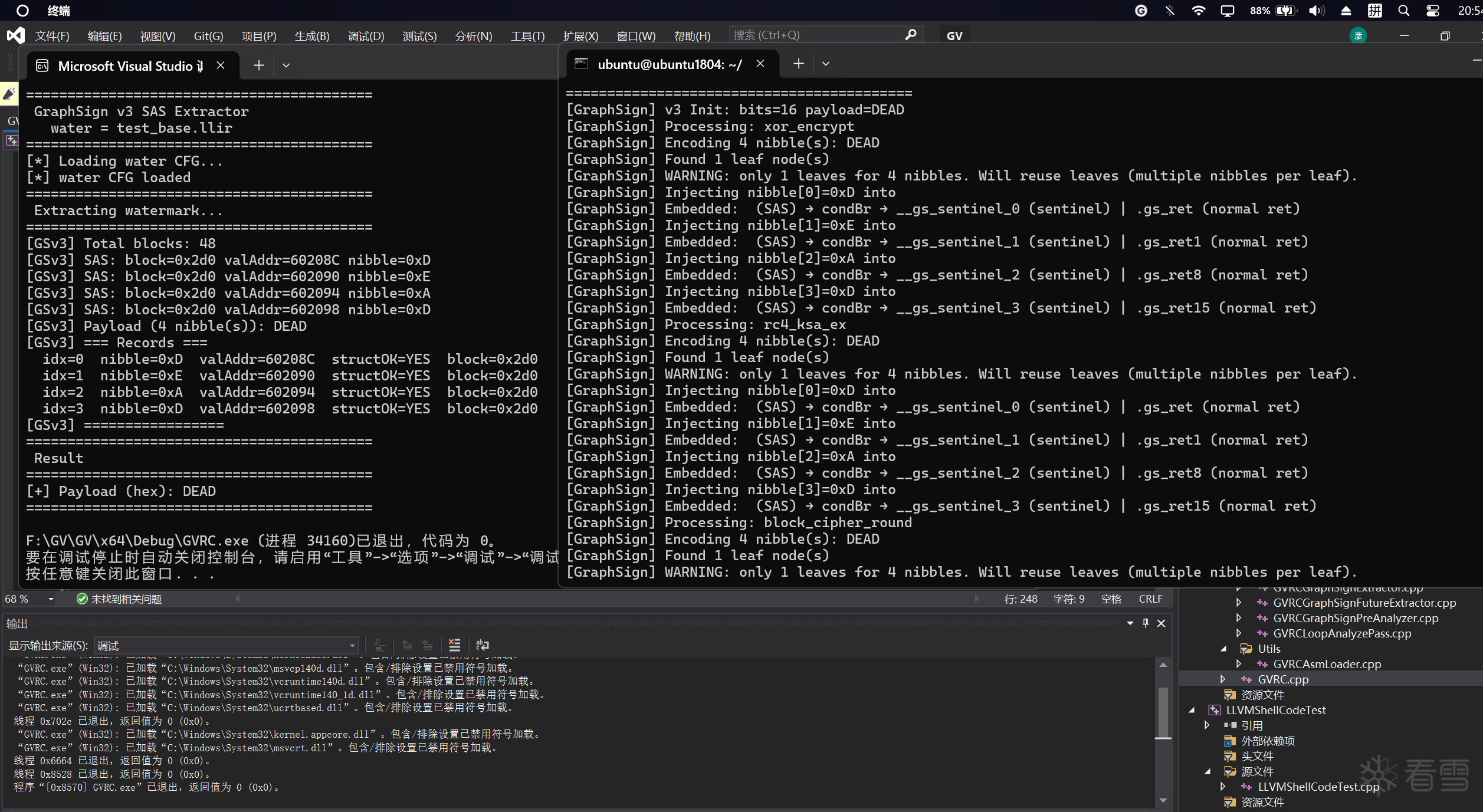
4个 nibble 全部还原,structOK=YES,XOR 校验通过。
-O2 实测 SAS 序列完整保留,EXE 体积仅增加约 200 bytes(相对 12864 bytes 的基准)。
当前局限:
Part2 计划:
SAS 退化为纯定位锚点(or eax, 0 不携带有效 nibble),真正的 nibble 编码进 condBr 之后的 CFG 拓扑子图形状(复用 v2 的 DummySubgraph 方案)。攻击者即使找到 SAS 序列并读出立即数,拿到的也只是无意义的 0,真正的水印在形状里。
V3的双层结构:
缺一不可,提取器必须同时理解两套机制才能还原 payload。
| 变量名 |
初始值 |
用途 |
@gs_wm_key |
0xDEAD5A5A |
水印区识别 tag,SAS 定位锚点 |
@gs_wm_val_N |
0 |
第 N 个 nibble 的编码槽 |
@gs_wm_magic |
0xC0FFEE00 |
sentinel 完整性 magic |
@gs_cv |
1 |
always-false 条件的 volatile 源 |
| 优化 Pass |
影响 |
应对 |
| SCCP |
推导全局变量为常量 |
volatile 阻止 |
| GVN |
消除冗余 load |
volatile 阻止 |
| SimplifyCFG |
删除 always-false 分支 |
volatile 阻止条件推导 |
| DCE |
删除无用 store |
volatile store 不可消除 |
| InstCombine |
折叠 or 立即数 |
nibble 仍在操作数里 |
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。






