UPX 手动脱壳实战:从 GDB 到完整 ELF 的七步还原
测试环境:Arch Linux / glibc 2.41 / UPX 5.2.0 / GDB 16.3
本帖同步发布于:
吾爱破解:18cK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3f1#2x3Y4m8G2K9X3W2W2i4K6u0W2j5$3&6Q4x3V1k6@1K9s2u0W2j5h3c8Q4x3X3b7J5x3e0p5K6x3o6R3$3i4K6u0V1x3g2)9J5k6o6q4Q4x3X3g2Z5N6r3#2D9
0x01 UPX 干了什么
UPX 是一个压缩壳。它把 ELF 的代码段和数据段压缩,然后把自己的解压代码贴在文件里。程序启动时:
- UPX stub 先跑,把压缩数据解压到内存
- 解压完跳到
_start,动态链接器接管,跟正常程序一样跑
file 看到的是 "statically linked, no section header"。加壳后的文件确实没有 PT_INTERP(ldd 也会说"不是动态可执行文件"):
$ file hello_packed
hello_packed: ... statically linked, no section header
$ ldd hello_packed
不是动态可执行文件
$ readelf -l hello_packed | grep INTERP
(空的——packed 文件里确实没有解释器)
但别被骗了。原程序是动态链接的——PT_INTERP 和 PT_DYNAMIC 被 UPX 压进压缩数据里了,只在解压后才出现在内存中。证据是 strace 运行它的时候,照样能看到 ld.so 在加载 libc。
也就是说:壳是静态的,但里面包着一个动态链接的程序。这就是为什么 catch syscall read 能截到 ld.so——壳跑完之后,原程序的动态链接器照常开工。
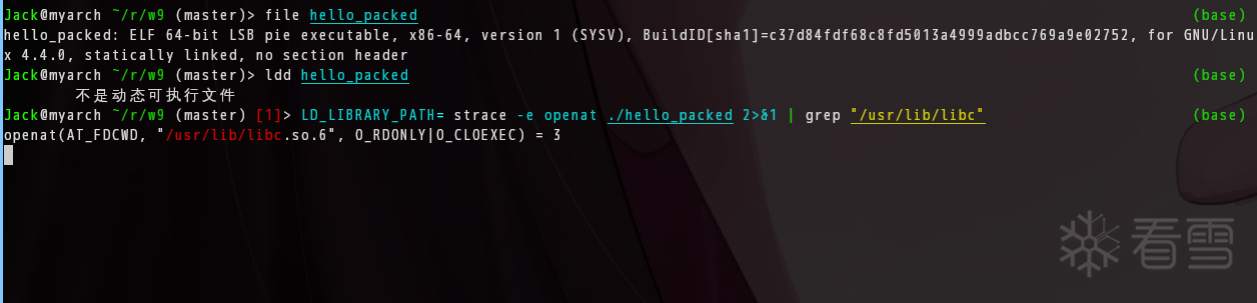
0x02 starti — 停在起点
$ gdb hello_packed
(gdb) starti
停在 0x00007ffff7ffd958。这个地址一看就不是我们程序的 _start(入口点在 0x1090 附近,不该在高位地址)——这里是 UPX stub 的第一条指令。原程序还被压着,GDB 站在壳的门外面。
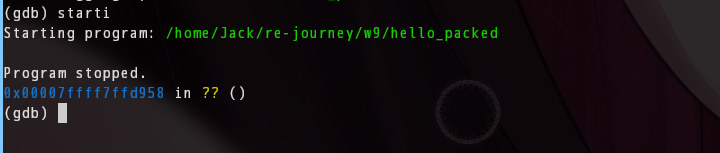
0x03 catch syscall read — 等解压完成
(gdb) catch syscall read
(gdb) c
停在 Catchpoint 1 (call to syscall read)。这时候 UPX 已经把原程序解压到内存了。
为什么是 read? 因为 UPX 解压是纯用户态操作,不触发 syscall,壳自己不会碰 read。但解压完成后,动态链接器 ld.so 必须通过 read() 系统调用加载 libc——这是内核强制路径,壳躲不开。断在 read 就是断在"壳刚跑完、真程序要醒了"的那个瞬间。
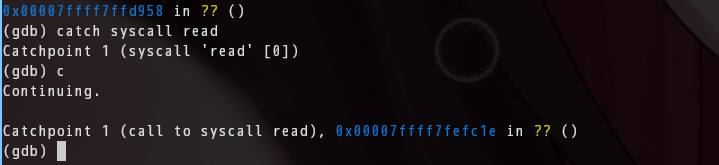
0x04 info proc mappings — 找解压出来的 ELF
(gdb) info proc mappings
在输出里找这几段连续的映射:
0x7ffff7ff8000 0x7ffff7ff9000 0x1000 r-- ← ELF header 段
0x7ffff7ff9000 0x7ffff7ffa000 0x1000 r-xs ← 代码段 (memfd)
0x7ffff7ffa000 0x7ffff7ffb000 0x1000 r-- ← rodata 段
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 rw- ← data 段
代码段(r-xs)是 memfd 映射的——UPX 用 memfd_create 创建匿名文件把解压后的代码写进去。ELF header 通常就在代码段紧前面那个 r-- 页。
验证一下:
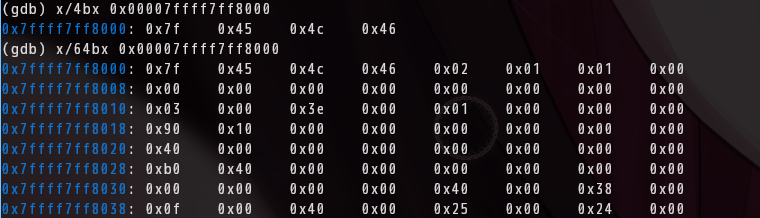
(gdb) x/4bx 0x7ffff7ff8000
0x7ffff7ff8000: 0x7f 0x45 0x4c 0x46 ← ELF magic
对了,就是它。0x7ffff7ff8000 就是解压后 ELF 的基址,后面的流程全部基于这个地址。
0x05 逐条找 PT_LOAD — 精确定位边界
ELF header 告诉我们 program headers 的位置和数量:
| 字段 |
偏移 |
含义 |
| e_phoff |
+32 (8B) |
program headers 表从哪开始 |
| e_phnum |
+56 (2B) |
共多少条 program header |
(gdb) x/gx 0x7ffff7ff8000+32 → e_phoff = 0x40
(gdb) x/hx 0x7ffff7ff8000+56 → e_phnum = 15
Program headers 表从 0x7ffff7ff8000 + 0x40 开始,共 15 条。每条 56 字节,结构如下:
| 偏移 |
字段 |
大小 |
说明 |
| 0 |
p_type |
4B |
类型 (1=PT_LOAD) |
| 4 |
p_flags |
4B |
权限 (R=4, W=2, X=1) |
| 8 |
p_offset |
8B |
文件中的偏移 |
| 16 |
p_vaddr |
8B |
虚拟地址 |
| 32 |
p_filesz |
8B |
文件中的大小 |
我们只需要 p_type = 1(PT_LOAD)的条目。翻来覆去就四行有用。用 x/7gx 逐条查看:
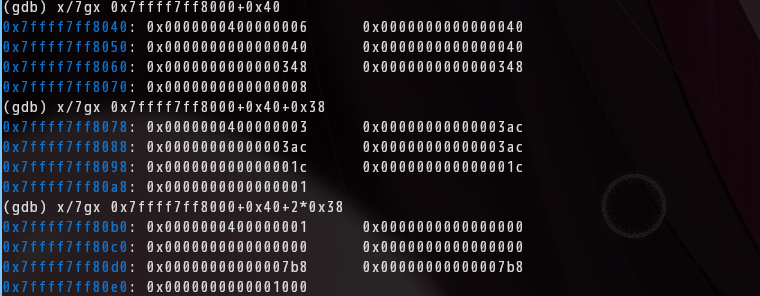
(gdb) x/7gx 0x7ffff7ff8000+0x40 # PHDR 0: p_type=6 (PT_PHDR, 跳过)
(gdb) x/7gx 0x7ffff7ff8000+0x40+0x38 # PHDR 1: p_type=3 (PT_INTERP, 跳过)
(gdb) x/7gx 0x7ffff7ff8000+0x40+2*0x38 # PHDR 2: p_type=1 ✅ PT_LOAD
每条输出的第一个 8 字节的低 4 字节就是 p_type。找到 p_type=1 后,读后面的值:
0x7ffff7ff80b0: 0x0000000400000001 ← p_type=1, p_flags=4 (R)
0x0000000000000000 ← p_offset = 0x0
0x0000000000000000 ← p_vaddr = 0x0
...
0x00000000000007b8 ← p_filesz = 0x7b8
用同样方式找完所有 15 条,得到 4 条 PT_LOAD:
| LOAD |
p_flags |
p_offset |
p_vaddr |
p_filesz |
内容 |
| ② |
R (4) |
0x0 |
0x0 |
0x7b8 |
ELF header + 辅助段 |
| ③ |
RX (5) |
0x1000 |
0x1000 |
0x249 |
.text 代码段 |
| ④ |
R (4) |
0x2000 |
0x2000 |
0x1c0 |
.rodata 只读数据 |
| ⑤ |
RW (6) |
0x2dd0 |
0x3dd0 |
0x270 |
.data + GOT 表 |
为什么是四条? 不是规定,是这个程序恰好四条。一个 ELF 有几个 p_type=1 的 program header 就有几个 LOAD 段。
0x06 dump + 拼接 → 完整 ELF
根据上一步的 p_offset + p_filesz,精确 dump 四个段:

退出 GDB 后,用 cat_segments.py 按文件偏移拼接。**注意——不能直接 cat!**我第一次就是 cat dump1 dump2 dump3 dump4 > extracted 然后 ./extracted,直接 SIGSEGV。因为段之间有空隙:LOAD 1 在文件 offset 0x7b8 结束,LOAD 2 从 0x1000 才开始,中间差了一大段。cat 把四个段直接粘死,loader 按 p_offset 去读的时候全错位了。必须按 p_offset 定位、用脚本段间补零:
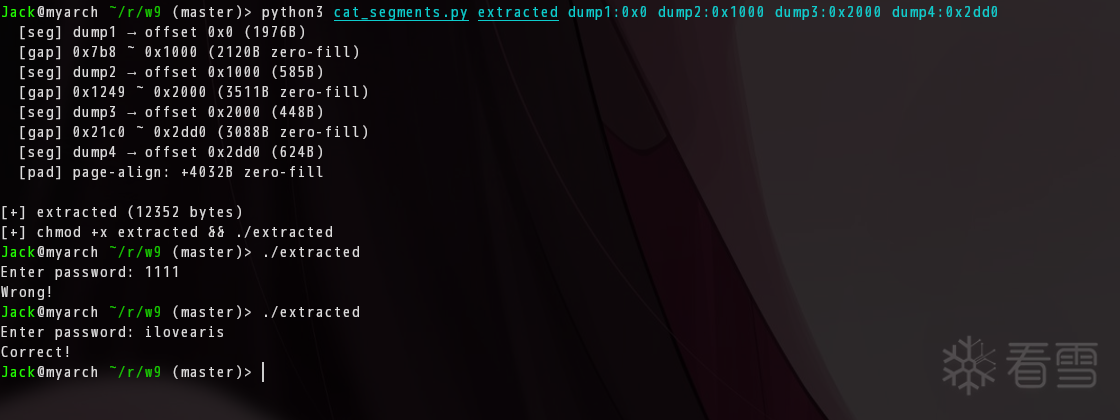
$ python3 cat_segments.py extracted dump1:0x0 dump2:0x1000 dump3:0x2000 dump4:0x2dd0
验证:
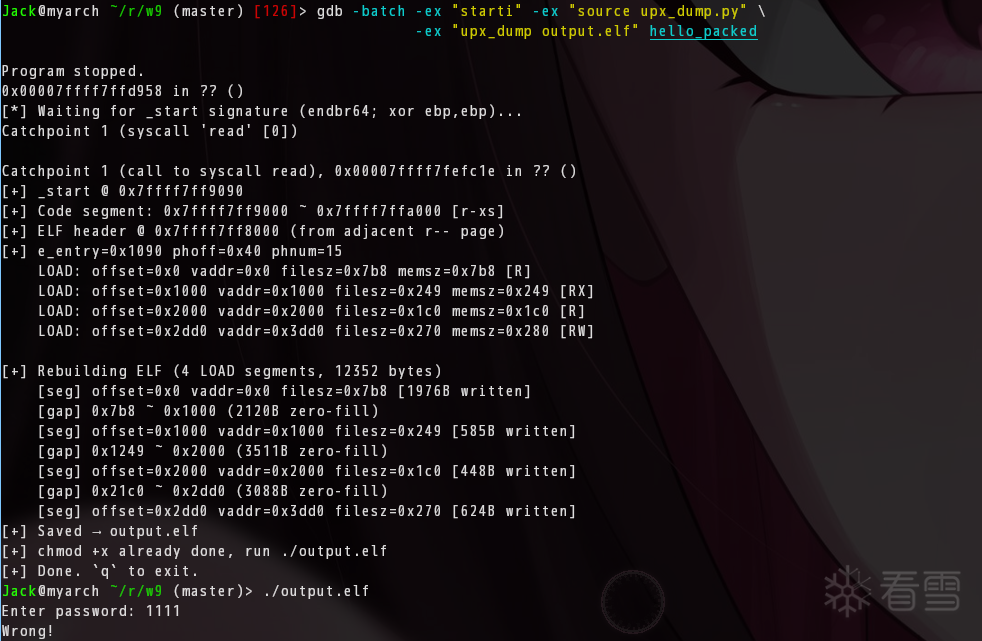
$ ./extracted
Enter password: 1111
Wrong!
$ ./extracted
Enter password: ilovearis
Correct!
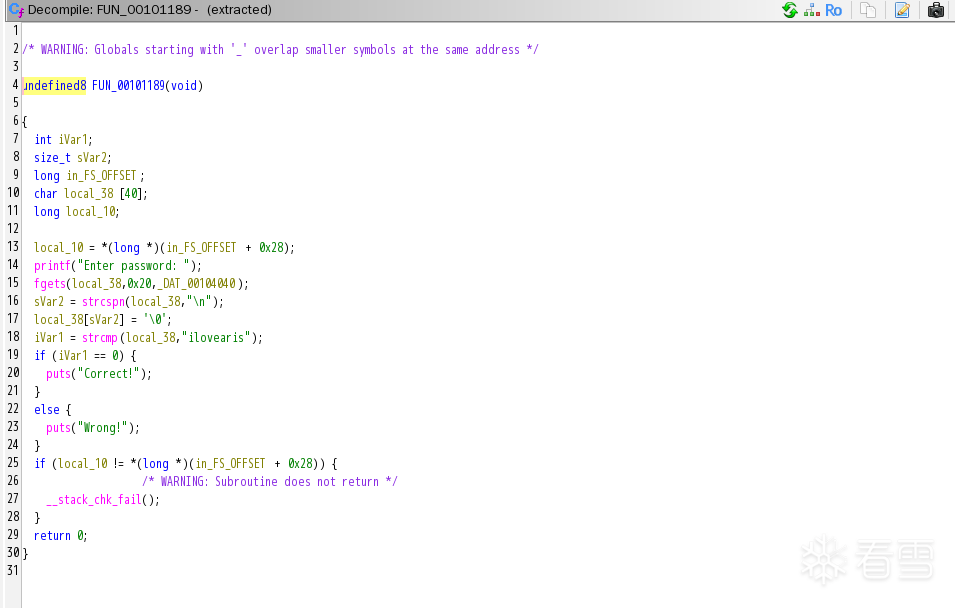
Ghidra 里打开也正常——程序逻辑完整恢复。
0x07 脚本 + 常见问题
自动化脱壳脚本
不想每次手动走六步?我让 AI 帮我写了一个 upx_dump.py:
$ gdb -batch -ex "starti" -ex "source upx_dump.py" \
-ex "upx_dump output.elf" hello_packed
一行跑完,直接产出可执行 ELF。脚本自动完成:catch read → 搜 _start → 解析 ELF → 按 PT_LOAD 拼接 → 段间补零。
ps:我不敢保证脚本的兼容性,手动dump永远是最兼容的方式。
手动拼接脚本
上面手动流程需要 cat_segments.py:
python3 cat_segments.py output.elf dump1:0x0 dump2:0x1000 dump3:0x2000 dump4:0x2dd0
参数格式:文件名:文件偏移(hex),顺序任意,脚本自动按 offset 排序并补零填充。
Q: 这个时候就有弹幕要问啦:哎主播主播!既然最后还是用脚本填充零,那我 dump 的时候直接 dump 整页然后 cat dump1 dump2 dump3 dump4 > extracted 不就行了吗?根本不需要后续补零!
我的回答:程序可以跑,但不够干净。整页 dump 会把 LOAD 段尾部多余的零填充或相邻映射的垃圾数据也带进去。Loader 按 p_filesz 加载,不读多余数据,所以不影响执行。但 md5 对不上、readelf 可能报警告,文件也比原版胖。精确到字节就是干净——反正是脚本做的事,不费我的手。
Q: 为什么 /proc/PID/exe 拿不到解压后的文件?
大部分 UPX 变体在 memfd_create 创建匿名文件后直接在当前进程里跳转,不像某些变体用 fexecve 开新进程。/proc/PID/exe 指向的是磁盘上的原始加壳文件,不是内存里解压出来的那个。所以必须手动 dump。
两个脚本见附件:
- cat_segments.py — 手动 dump 后拼接用
- upx_dump.py — GDB 一键自动脱壳
总结
UPX 手动脱壳的核心就三步:
- 等解压 —
catch syscall read,卡在动态链接器加载 libc 的时刻
- 定位边界 — 从 ELF header 找到 program headers,逐条找 PT_LOAD 的 p_offset + p_filesz
- 精确 dump — 按 p_vaddr 读取内存、按 p_offset 写回文件、段间补零
不需要理解 UPX 的压缩算法。不需要猜 OEP。不需要假设栈帧结构。只要程序是动态链接的,ld.so 就必然调 read()——这是内核 ABI 规定的,壳改不了。
致谢:本篇由我的AI--Aris协助完成。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-6-17 15:09
被Hex_编辑
,原因:






