你也不想在中转站画了GPT-5.5的钱,买到的模型却是写着GPT-5.5的deepseek-v4-pro,对吧?
早在2024年,便有学者 发现可以通过数次提问来鉴别LLM的身份。
作为一篇社区博客,本文将谈论如何构造一个提问,使得这个提问能最大化不同的模型的响应的区别;然后,本文将探讨如何基于不同的模型对此提问的响应构造一个文本分类模型。最后,本文还将在文末开源一个简化版的LLM身份分类器(为了方便没有GPU的坛友运行,是10分类的)。
那么,闲话休提,让我们开始吧。
早在上一篇博客 中,我们提到了GCG等基于优化的可解释性方法。那么,为什么我们不能对商业模型使用基于优化的可解释性方法呢?
对于 GPT-5.5、Gemini 这类部署在云端、通过 API 访问的商业模型,我们无法像对开源模型那样直接进行基于梯度或连续优化的可解释性探测。原因有而。首先,我们无法获取梯度信息。商业模型的权重、结构都是黑盒,用户仅能拿到文本输出,无法对输入进行反向传播。这使得 GCG这类需要计算损失对输入 token 梯度的方法完全不可用。此外,就是因为采样与随机性不可控。商业模型往往强制开启一定程度的随机采样(temperature、top-p 等),即使输入完全相同,输出也可能浮动,这让精确的梯度估计或基于损失的优化变得极不稳定。
因此,要在这种受限环境下最大化不同模型输出的差异,我们必须放弃任何依赖模型内部信息的白盒方法,转而使用纯粹的黑盒搜索策略——遗传算法正是一个合适的选择。
遗传算法(Genetic Algorithm, GA)是一种模拟自然界优胜劣汰过程的启发式搜索算法。它维护一个由若干候选解组成的“种群”,每一代通过选择、交叉、变异 三类操作推动种群向更优的方向演化。在我们的场景中,每个候选解是一条提示文本(由一系列单词拼接而成),适应度则由“不同模型对该提示的响应之间的嵌入距离”来定义。算法迭代地让距离更大的个体存活、重组、变异,最终找到一条能最大限度拉开模型响应的提示。
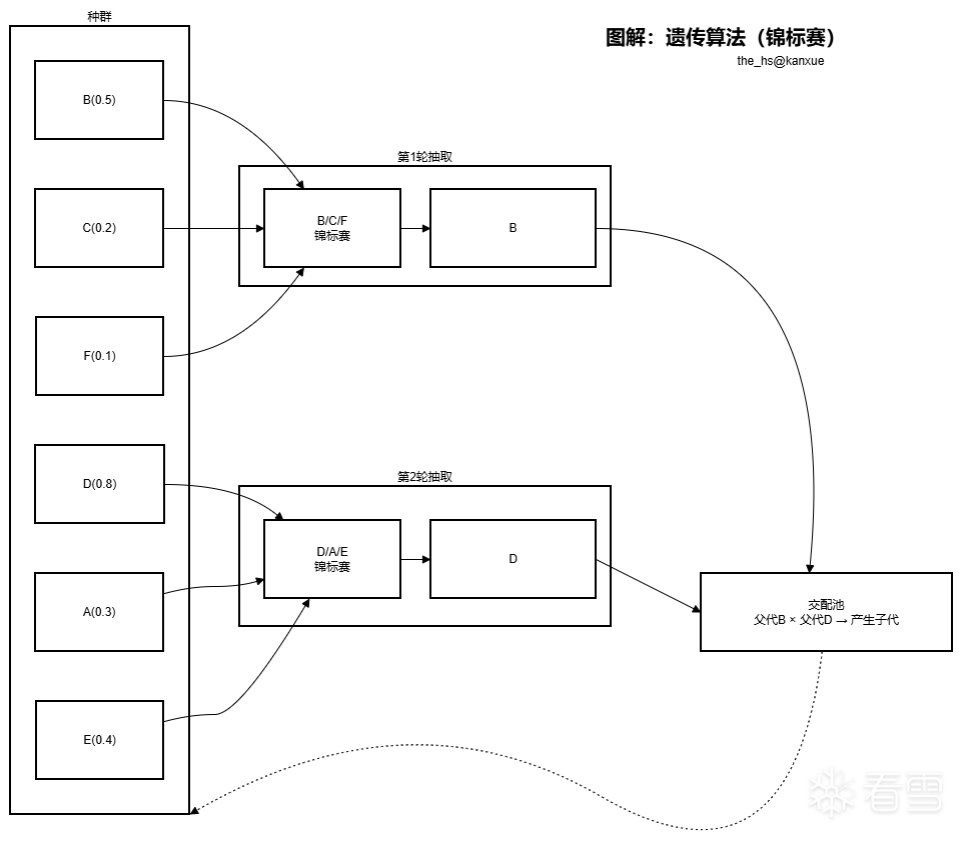
选择操作是遗传算法中筛选亲本的关键步骤。锦标赛选择(Tournament Selection)因其简单且不易过早收敛而被广泛使用。下图展示了一次典型的三元锦标赛选择流程:
在我们的代码中,k 取 3,即每次随机抽取 3 条候选提示,保留其中使模型响应距离最大的那条作为父代,重复多次填满交配池。这种方式平衡了选择压力与种群多样性,即使适应度较差的个体也有极小概率参与繁殖,避免搜索陷入局部最优。
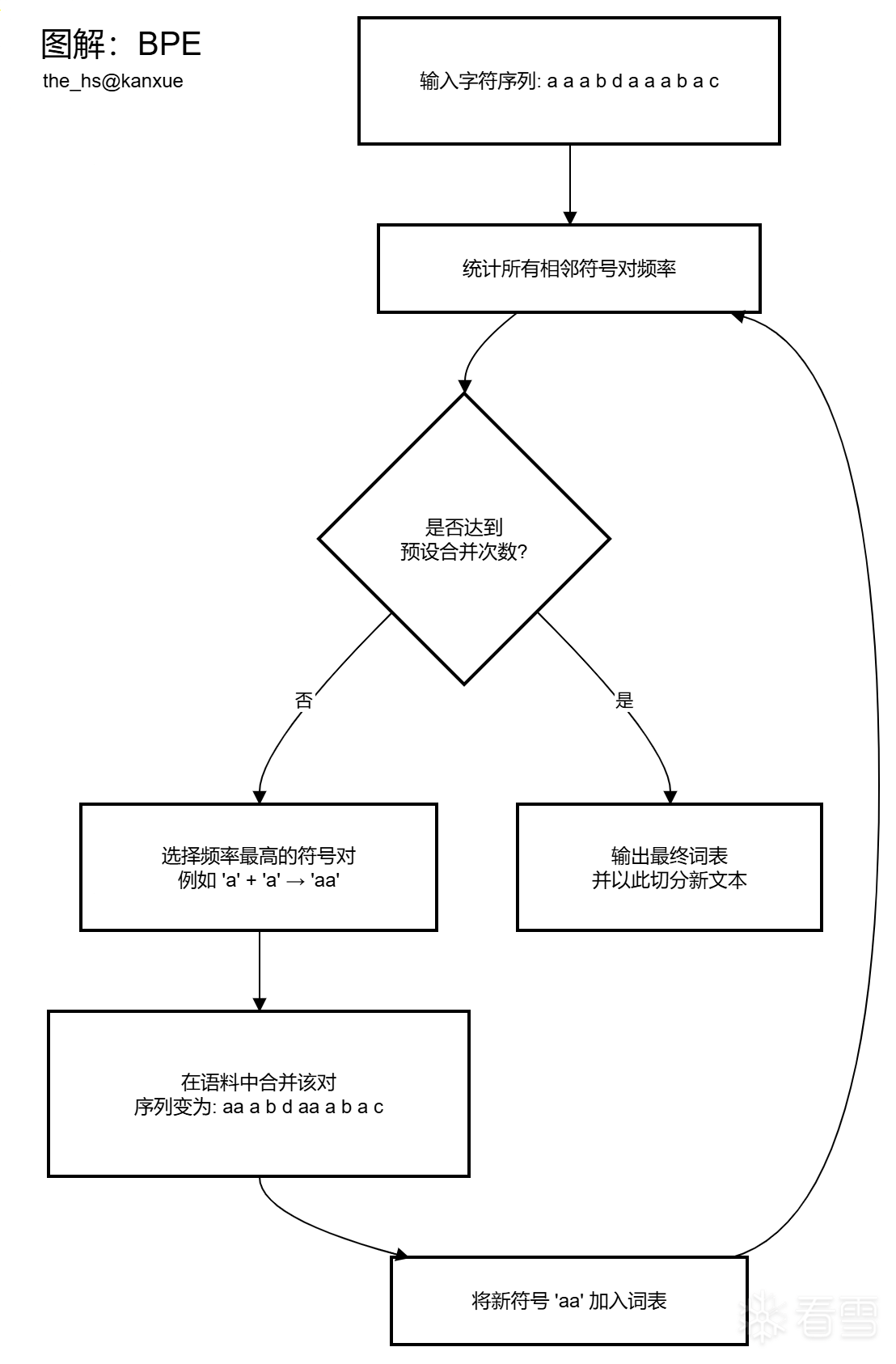
字节对编码(BPE)是现代大语言模型中最主流的子词分词算法。它的核心思想很朴素:从最细粒度的字符开始,反复将文本中出现频率最高的一对相邻符号合并成一个新符号,从而逐步构建出包含常见字符组合、词根、乃至完整单词的词表。训练完成后的分词器在面对新文本时,就按照当初合并的顺序,贪心地把输入切分成词表中存在的、尽可能长的子词单元。这样一来,无论遇到多罕见甚至从未见过的词汇,模型总能用一连串更小的、已知的子词“拼”出它的表示,避免了传统词级别分词中大量未登录词直接变成<unk>的窘境。
下面这张图用一个简单例子演示了 BPE 的迭代合并过程:假设初始词汇表就是字符 {a, b, c, d},训练语料中反复出现字符串 "aaabdaaabac"。算法首先统计相邻符号对的频率,发现 "aa" 出现次数最多,于是将其合并为一个新符号 "aa";接着在更新后的序列里 "aa" 与 "a" 组成的 "aaa" 又成为最高频对,再次合并……如此循环,直到达到预设的合并次数或词表大小。最终,原始字符序列会被切分成一组子词单元,每个单元都对应词表里的一个独立 token。
从上面的流程可以看出来,BPE 词表的内容和大小完全取决于训练它所用的语料以及预设的超参数(如词表容量、允许的最大合并步数)。不同的模型,哪怕都用 BPE 分词器,只要它们训练的语料不同、词表尺寸不同、或者在实现细节上对 Unicode 规范、标点处理、空白保留等规则有差异,最终得到的合并优先级列表就会不一样。同一段文字,在 GPT-4 的 tokenizer 下可能被切成 10 个 token,到了 Gemini 的 tokenizer 里就可能变成 12 个——因为某个常见词在一个词表里是独立 token,在另一个词表里却被拆成了两个更小的子词。这种分歧正是我们稍后利用嵌入距离来“指纹识别”模型身份的基础:相同的文本在不同模型内部经历的分词路径不同,导致其上下文化的语义表征也自然地产生了系统性的偏移。
既然商业模型是黑盒,我们唯一能做的就是不断尝试不同的输入,观察输出,再调整输入方向。遗传算法恰好匹配这种“试错—评估—择优—变异”的范式。每条候选提示就是一个个体,它的适应度由“将该提示分别喂给不同模型后,各模型响应之间的嵌入距离”来定义——距离越大,说明这几个模型对同一个问题的理解越不一致,这条提示就越有区分力。遗传算法的选择、交叉、变异三个操作则负责在由词汇组合构成的巨大离散搜索空间里,沿着适应度升高的方向迭代前进:选择让高分提示更大概率存活并繁殖;交叉把两条已经表现不错的提示的片段拼接,可能产生更优的组合;变异则以小概率随机替换、插入或删除提示中的词汇,防止搜索卡在局部最优。这个框架早在对抗样本生成领域就有成功案例,比如在 NLP 中搜索能绕过内容审核的对抗性短语,本质思想一致——只不过我们不是在找“能骗过模型”的输入,而是在找“能让多个模型表现得迥然不同”的输入。
当我们只区分两个模型时,最大化它们响应之间的余弦距离是直接的。但假如要同时区分三个甚至更多模型,适应度函数的设计就需要更谨慎。一个直觉的方案是把所有两两模型对之间的距离加起来,然而这个“距离之和”会导致严重的盲区:假设我们正在区分模型 A、B、C,某条提示使 A 与 B 的距离极高、A 与 C 的距离也极高,但 B 与 C 的距离几乎为零。这条提示的“距离之和”仍然可以很大,因为两项高值把总分拉上去了;但在实际分类场景中,B 和 C 几乎无法被区分,这条提示的鉴别价值就大打折扣。
将优化目标改为所有两两距离的乘积(或等价的几何平均)则可以强制避免这种“偏科”。乘积对任何一个极小值极度敏感——只要有一对模型的距离趋于零,整个适应度就会崩掉。这迫使搜索算法必须找到一条能让每一对模型的输出都均匀拉开的提示,不存在被“放水”的模型对。换句话说,距离乘积最大化等价于在保证没有一个维度薄弱的前提下,整体拉开所有模型的嵌入分布,这正是构建可靠多分类判别器所需要的数据特征。
遗传算法的核心逻辑在上文已经解释清楚,这里直接给出最关键的适应度计算与主循环代码片段,帮助读者对整体流程有一个具体的感知。
上面是针对两个模型的简化版。当需要同时区分多个模型时,只需将适应度改为所有两两配对的嵌入距离之乘积。锦标赛选择、单点交叉和随机变异的实现沿用了经典遗传算法的范式,读者可根据上文给出的参数(种群大小、变异率、锦标赛规模 k=3 等)自行组装,此处不再逐行罗列。
需要特别说明的是,代码产出的原始提示词虽然在数学意义上最大化了一组模型间的响应距离,但从人类的视角看往往是一堆词汇的机械堆砌,缺乏连贯的句法和可读性。本文最终使用的那条提示并非代码的直接输出,而是在多次遗传算法迭代中筛选出距离表现优秀的候选后,由笔者手工调整语序、修补语法、使其读起来像一句正常人会说出的话。这种“人机协同”的打磨过程牺牲了一小部分区分度,换来了在实际使用中更不易引起模型警觉的自然文本——毕竟如果一条提示看起来明显是机器生成的对抗样本,某些商业模型可能会触发安全拒绝机制,反而拿不到响应。
出于简略考量,最终获得的完整提示词不在此处给出。感兴趣的读者可在本文附件中获取,其中还包含了针对该提示在不同模型上的响应样本以及对应的嵌入距离矩阵。这里仅做一个概括性说明:经过遗传算法搜索和人工润色后,这条提示在参与测试的 10 个主流商业及开源模型上,使任意两个模型响应嵌入之间的最小余弦距离达到了 0.4 以上——对于经过对齐训练的现代大模型而言,这意味着它们在面对完全相同的输入时,输出产生了足够显著且稳定的分化,为下一步训练判别器提供了干净的数据基础。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-6-16 01:54
被the_hs编辑
,原因: title
上传的附件: