这次拿到的是一个 Cocos2d-x + Lua 写的棋牌马甲包,目标很明确:把它的请求签名 sign 还原出来,方便后续做接口分析。
但这个app主要难在两点:
整条链路大概是这样:
先用 jadx 看 Java 层,入口 Application 是 goPMyRxdApp。
这壳一共四层,每层都是 RC4 + zlib 的组合,密钥不是写死的,是拿包名/类名做凯撒位移 getNewKey(seed, shift) 现算出来的:
或者按逻辑所示直接在absolutePath + /ltUREWDi/librnbqzphi.so中拉下来这个so即可
此so的关键函数有:
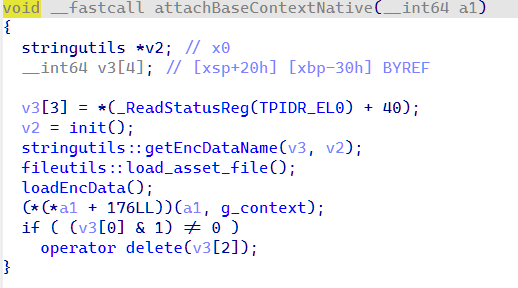
梳理其加载业务dex的逻辑:密钥和资源名都是拿入口类名 goPMyRxdApp 去掉末尾 3 个字符(goPMyRxd)再 getNewKey 算出来的:encName = getNewKey(keyStr, 4) 是 assets 里加密资源的文件名,rc4Key = getNewKey(keyStr, 3) * 2 是 RC4 密钥(注意它把结果重复了一遍)。解密就是 RC4 之后跳过头 4 字节的长度,剩下 zlib.decompress
可以写一份离线脚本得到dex
麻烦的是第三层那个子 so。它不落地,只在内存里,而且被自定义 linker 改过,段信息都不对,直接 dump 内存也修不成正常 ELF。
这里的思路是借用他自己的linker修复逻辑后dump:hook 它自己的 linker,等它把段都映射好、relocation 还没改之前那一刻下手。静态分析过 master_linker(sub_250E338)的调用序列,最佳 dump 点是 relocate 派发函数(sub_2510444)的入口:此时代码和数据都已经解密到位、映射进 LOAD0 了,但 rela/symtab/strtab 还是干净的,soinfo 也被两次 prelink 填满了。
dump 完三个段,再把 soinfo 里读出来的 strtab/symtab/rela 等信息拼回一个标准 ELF 头。修完得到 libcocos2dlua_child_v3.so,45.5MB,6w 多个函数,能正常拖进 IDA解析。
修复参考:7caK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2U0N6r3k6A6L8%4c8Q4x3X3g2U0L8$3#2Q4x3V1j5I4x3o6j5H3z5e0c8Q4x3X3g2Z5N6r3#2D9
看雪ID:乐子人:https://bbs.kanxue.com/homepage-872365.htm
后面所有的 opcode 分析、函数定位都基于这个修好的子 so。
脱壳脱到这里,dex 和子 so 都有了,但真正要分析的业务逻辑全在 lua 里,而磁盘上根本找不到明文 lua——它们要么被 XXTEA 加密塞在 assets 里,要么干脆打包进资源,运行时才解出来交给 LuaJIT。所以得在「lua 已经被解密、即将喂给 LuaJIT 装载」的那一刻把它截下来。这一步是后面 opcode 还原和反编译的输入,没有它什么都谈不上。
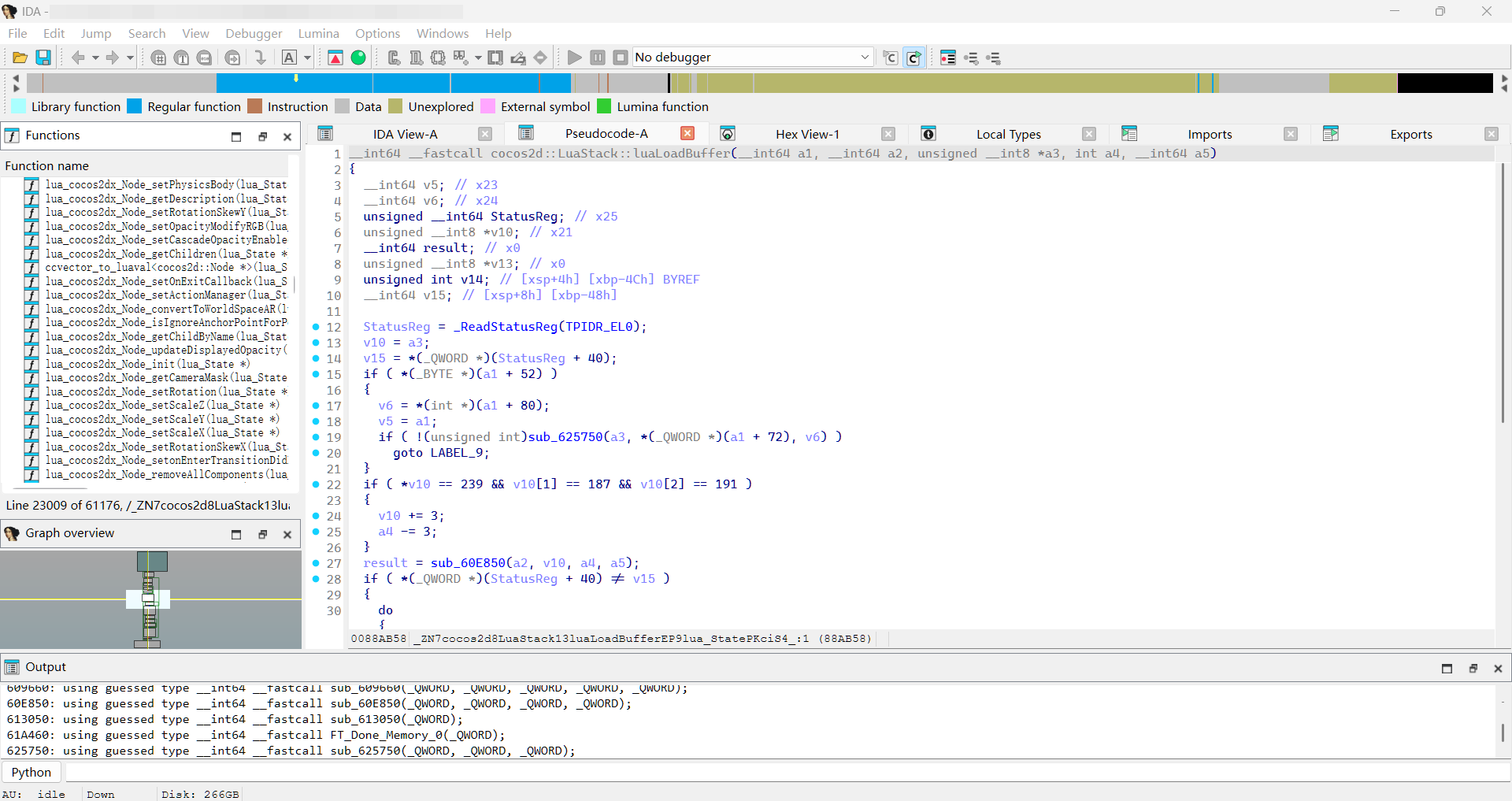
定位思路是抓 Cocos 的 lua 装载入口。Cocos2d-x 里所有 lua 脚本最终都从 cocos2d::LuaStack::luaLoadBuffer 进去,它内部如果发现启用了 XXTEA 就先解密、再把明文丢给底层的 luaL_loadbufferx 装载。所以有两个可以下手的点:
我两个点都 hook 了,入口处当验证、底层 body 当主力,谁先稳定拿到明文用谁。注意那个底层 thunk 是经过 GOT 间接跳转的,地址不固定,得先把 GOT 解析一遍才能定位到真正的 body:
dump 的时候顺手按文件头分个类,方便后面处理——1B 4C 4A 开头(\x1bLJ)是 LuaJIT 字节码,存成 .luajit;纯可打印文本是明文 lua 源码,存成 .lua;再用「size + 头部 hex + name」去重,避免同一脚本反复装载存一堆:
跑起来进游戏逛一圈,让它尽量多触发脚本装载,最后 pull 下来:
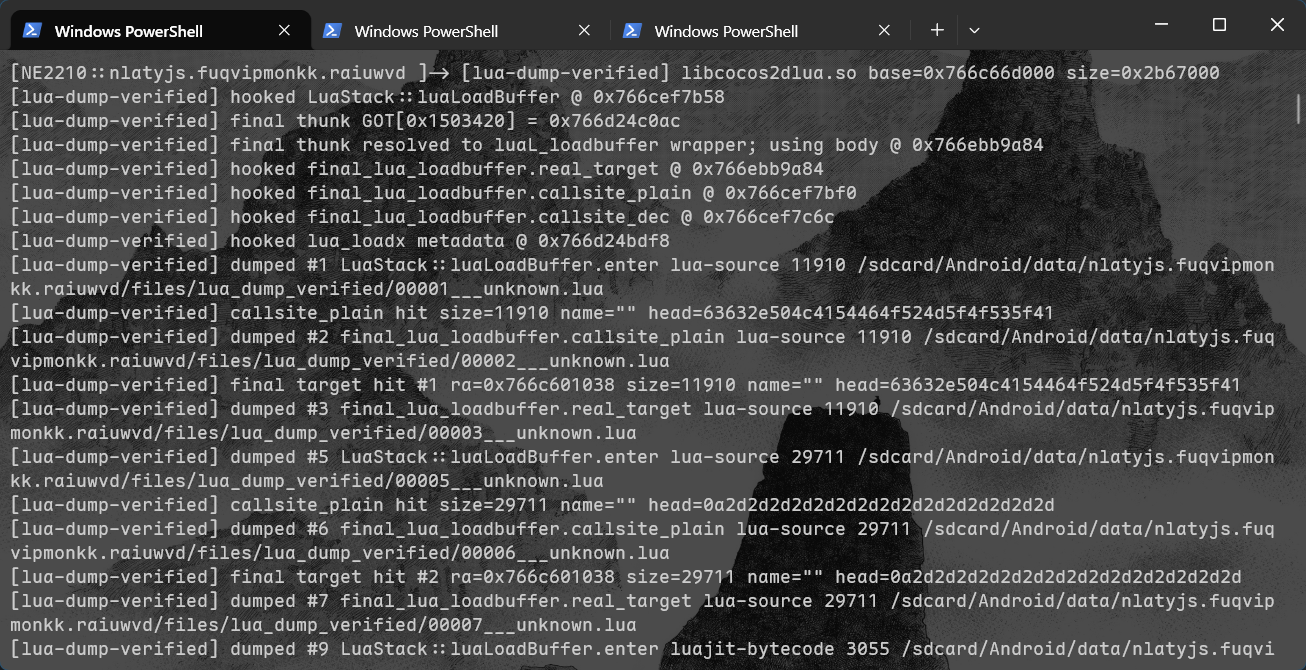
一共落地 900 多个文件,其中 47 个是明文 lua 源码(这部分直接就能看),850 个是 LuaJIT 字节码 .luajit——但这 850 个拖进任何反编译器都是乱码,因为它们是用魔改过 opcode 的 LuaJIT 编译的。这就引出了下一章。
这是最难搞的。原版 LuaJIT 的 opcode 编号是固定的,魔改版把编号重新排列了,所以直接拿标准反编译器解析字节码会全部错位、崩溃。必须先在 IDA 里把魔改编号 → 真实语义这张表逆出来。
但这里要先解决一个问题:上来 IDA 里六万多个函数,sub_XXXX 一片,怎么定位哪个函数是 VM 的分发循环、哪段数据是 opcode 表?
LuaJIT 的解释器有个很好认的结构特征,不管怎么魔改都跑不掉:它是 computed-goto 风格的「取指 → 查表 → 间接跳转」循环,编译到 arm64 上一定长这样——用一个寄存器当字节码指针、自增取 4 字节、拿低 8 位当索引去查一张函数指针表、BR 跳过去。所以不靠符号也能找,方法有几条,我是组合着用的:
定位到的主分发循环在子 so 的 0xbe901c:
这段把魔改的关键全暴露了:UXTB(取最低字节)说明 op 就是指令的低 8 位,UBFX ...#8,#8 / ...#16,#16 说明 A/B/C/D 字段的位置和原版完全一样。也就是说:
标准 LuaJIT 的 BC_AD 指令编码(A/B/C/D 字段布局)一点没改,魔改的只是 op → handler 这个查表关系。 换句话说,只要我把那张表搞到手,磁盘上的字节码本身可以原样喂给标准解析器,不用动编码。
顺带也拿到了两个后面要用的关键值:分发表的基址在 X22,表相对 X22 的偏移是 0xF70(动态 dump 时直接读 X22+0xF70 就是这么来的)。
分发循环只告诉我们运行时拿 X22+0xF70 这张表来跳,但 X22 是运行时才填好的寄存器,静态文件里这张表在哪、怎么填的,得去找填表的那段初始化代码。
顺着 X22+0xF70 这个表被写入的地方做交叉引用,找到初始化函数 sub_BCE930。它的 F5 伪代码很干净,就是一个循环把 handler 地址逐个写进分发表:
读这段伪代码能抠出三个常量,它们就是 opcode 表的全部秘密:
定位到这三个常量之后,opcode 表的还原就完全离线化了——根本不用在 IDA 里手点 105 次,写个脚本从修好的子 so 文件里把 OFFSET_TABLE 读出来、逐个加基址就行:
剩下的就是对每个 handler 做指纹识别,定出它到底是哪条指令。
为了不出错,我用了两种方法对着验:
两边结果完全一致,连 0x6c == 0x6d 共用同一个 handler(0xbeaac4)这种都对得上。
判定语义靠的是 handler 里的特征指令,举几个例子:
子 so 里其实有两张分发表,第二张是用 NEON 从 word_1210E92 填进 a1+4888 的 hotcount/JIT 表。这就解释了为什么魔改编号 0x61–0x70 是 FORL/ITERL_HOT/LOOP_HOT/JMP_FAST 这一类——作者是把 JIT 热度计数从 loop/call 指令里拆出来单独编了号,并没有改指令本身的语义。摸清楚这点之后,这几个扩展 opcode 在反编译里基本可以当 NOP / 普通 LOOP / CALL 处理。
opcode 映射拿到了,接下来用 ljd(LuaJIT Decompiler,Aussiemon 那个 fork,支持 2.0/2.1)来反编译。驱动脚本是 decompile_modded.py。
先说清楚整体思路,不然后面那个关键修复会看不懂。
前面 3.1 已经确认过:魔改动的只是 opcode → handler 的编号,标准 LuaJIT 的 BC_AD 指令编码(4 字节里 A/B/C/D 各字段的位置和宽度)一点没改。也就是说,磁盘上这堆 .luajit 字节码,除了「第一个字节那个 op 号被换了」,其它全是标准的。
ljd 解析字节码时,是拿 op 号 去查它自己的一张分发表 ljd.rawdump.code._MAP,_MAP[op] 给出这条指令对应的指令类(MOV / CALL / ADDVV …)。标准 ljd 的 _MAP 是按原版 LuaJIT 编号排的,所以如果拿魔改字节码直接喂进去,那么每个 op 都将查错指令类,全盘错位。
那么一般有两条路:
我选择走 B。_MAP 本来就是个 [256] 的查找数组,重排它只是换个索引,干净得多。decompile_modded.py 干的核心就这一件事。
要注意,这套映射和第 3 章那两份 CSV 不是一回事:
第一步,频率打底。 写个最小的容器解析器(只走 LJBC header + 每个 proto 的 4 字节指令流,不需要懂任何 opcode 语义),把 850 个 chunk 里第一个字节做直方图。任何 Lua 程序里 JMP/MOV/CALL/TGETS 一定是高频指令——实测 0x68 出现 28728 次、0x49 出现 85441 次,先把这些高频字节圈成候选锚点。
第二步,已知形状的小函数定锚。 挑一个结构被唯一确定死的小 proto 来对位置。比如有个 proto 一眼就是 return string.format("%%%02X", string.byte(arg)),它的指令序列被强约束成:
把这段的实际字节挨个位置比对,就能一次性钉死 GGET=0x46、TGETS=0x49、KSTR=0x3E、MOV=0x1B、CALL=0x52、CALLT=0x54。再找几个含循环、含表构造的小函数补 JMP/FORI/TNEW 等,锚点滚雪球,56 项就齐了。
第三步,验证闭环。 把推出来的映射喂 ljd,看反编译能不能成立、sign 能不能复现。能跑通、salt 对得上,就反证这批映射是对的。
另外提一句,这套排列不是简单平移:比较类 0x00–0x0B 偏移为 0(原样),但常量块(KSTR 等)被挪到 0x3E 起、上值块(UGET 等)挪到 0x37 起,两块的先后顺序被对调了,不存在一个统一的 +N。所以只能锚点逐个定,没法靠一个公式推完。
回到 ljd。最终的映射分两批喂进去:一批就是上面方法得到的 56 项 OPMAP,另一批是我用 3.4 的 IDA 指纹补出来的 complete_opmap()(主要补算术/扩展类),加起来 82 个,sign 相关 chunk 里 0 个 unknown:
建表的代码本身很短,但有个极其关键的设计——newmap[魔改字节] 指向标准指令类,但这个指令类对象身上的 .opcode 属性,保持原版 LuaJIT 的值不动:
为什么 .opcode 一定要留标准值?因为 ljd 内部除了用 _MAP 选指令类,还在大量地方直接拿 instruction.opcode 做数值范围判断(比如判断一条指令是不是 ITERL/FORL/ISNEXT、是不是跳转)。这两套用法必须分开:
如果让标准 .opcode 也跟着变成魔改字节,第二套判断就全错了。下面 4.3 那个崩溃就是这么来的。
设计想清楚了,但 ljd 自带的 code.read() 偏偏违反了上面的分工。它解码每条指令时,会顺手把 instruction.opcode 覆盖成当前读到的那个字节——在魔改字节码里,这个字节就是魔改编号。
后果是灾难性的。比如 CALL 在这个 VM 里魔改编号是 0x52:_MAP[0x52] 确实正确给出了 CALL 指令类(没问题),但紧接着 read() 把这条 CALL 指令的 .opcode 也写成了 0x52。而标准 ljd 在 builder.py:281 判断「是不是迭代器循环」用的是 0x52 <= opcode <= 0x54(标准编号里那是 ITERL/IITERL/...)。于是这条 CALL 被误判成迭代器,走进 _build_iterator_warp,去访问一个 CALL 指令根本没有的字段,直接抛:
修复就是 patch 掉 code.read:照常用魔改字节查 _MAP 选指令类,但绝不回写 .opcode,让它保持 code.init(STD) 时设好的标准值:
这一步是整个反编译能跑通的决定性修改。
.opcode 修对之后,绝大多数 chunk 已经能跑了,但还有少数热路径 / JIT 形态的块,会在构建迭代器循环时撞 _build_iterator_warp 里的一个断言(它假定循环块倒数第二条一定是 ITERC/ITERN)。魔改 VM 把 hotcount 拆出去单独编号后(见 3.4),这个假设偶尔不成立。
补一个兜底:发现倒数第二条不是迭代器指令时,就退化成普通控制流 warp,别硬走迭代器逻辑:
注意这里 it.opcode 比的也是标准 opcode——又一次印证 4.2 那个设计:内部判断一律走标准 opcode。
install_opmap() 里那几个 handle_invalid_functions=True / catch_asserts=True 是配套的容错开关:单个块或单个 pass 出问题时,吞掉异常、尽量产出能看的结果,而不是让整个 proto 崩掉。
每个 proto 走的是 ljd 标准那套 AST pipeline,只是每步都套了容错:
slotworks(消临时变量)和 unwarper(把控制流 warp 还原成 if/for/while)这两步噪声最大——后面第 6 节 sign 翻车,根子就在 slotworks 对 slot 的复用/重命名上。
850 个 .luajit,反编译成功 845 个。
在还原出来的 Lua 里搜 sign,搜出三套独立的签名体系:
主目标是第一套 HTTP API。反编译出来的 sign4Url 长这样:
顺手确认了一下 sha1 模块(chunk 00079),就是标准的 sha.lua(kikito 版本),sha1.hmac 是标准 HMAC-SHA1,输出小写 hex。
到这步看起来公式都有了,结构也清楚,应该能算了。结果——
拿真实抓包样本套公式,本地复算 sign,全错。
我把能想到的组合全穷举了一遍:素材里那个 slot1 到底是请求类型、还是 appid、还是 POST/GET、还是 timestamp、还是 nonce,× 参数子集、× 分隔符、× 要不要 urlencode、× 两个候选密钥……几千种组合,一个都没中。
冷静分析,原因有两个,而且都是反编译的 slot 复用噪声坑的:
这俩 upvalue 在 ljd 还原之后编号根本不可靠,跨函数的 slot 也被复用重命名了。靠纯静态阅读去猜 HMAC 素材的精确拼接,自由度太大,根本收敛不了。 所以这种我放弃硬猜,直接frida上动态。
但动态也有个坑:HMAC 的素材是 Lua 用 .. 拼出来的纯 Lua 字符串,它既不走 C-API 的 lua_tolstring,sha.lua 又是纯 Lua 位运算、不调 native 的 SHA1——所以常规的那些 hook 点全都抓不到这个素材。
这里换个思路:Lua 里只要 .. 拼出一个新字符串,它最终一定会经过 LuaJIT 的字符串 intern 函数被驻留下来。顺着 lua_pushlstring(0xbd51f8)反编译,找到它调用的 sub_BCB83C,这个就是 lj_str_new(L, str, len),地址 child+0xBCB83C。
所有拼出来的字符串都会从这里过,而且 sign 素材里明文带着 HMAC 密钥和竖线分隔符,过滤起来很方便:
frida输出:
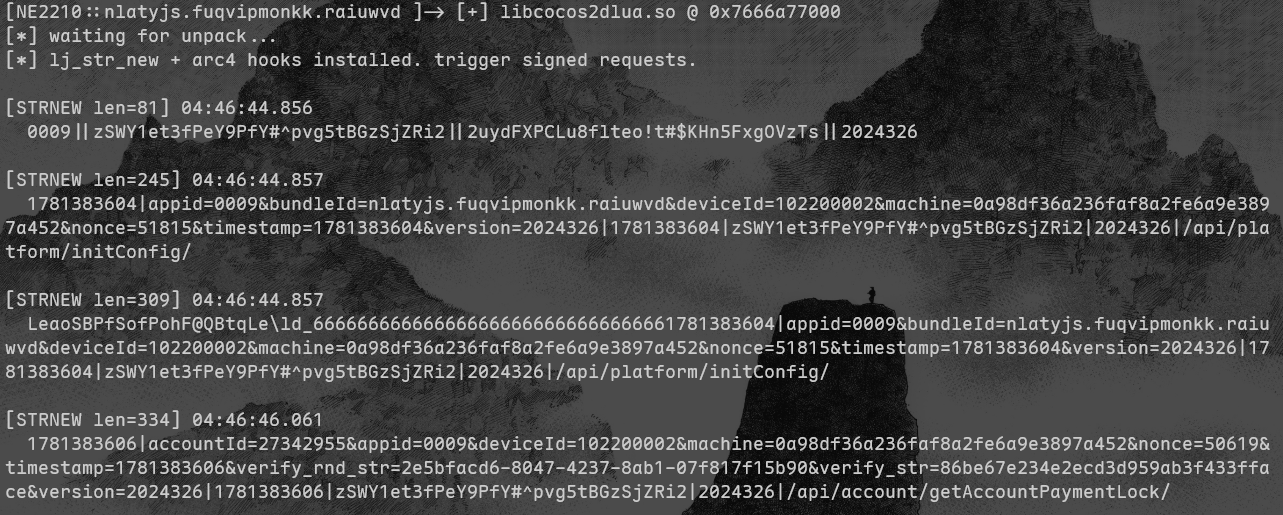
frida启用游戏,lj_str_new 命中,抓到 /api/customerService/live800/ 这个接口的真实 HMAC 输入:
同一时刻还抓到一条 LeaoSBPfSofPohF... 开头、后面跟一长串 666... 的字符串,这正是标准 HMAC 的内层块 (KEY XOR 0x36) ‖ 0x36 填充 ‖ message(那串 6 就是 0x36 填到 64 字节块),算是实锤了它就是标准 HMAC-SHA1,没有自定义魔改。
真实素材一摆出来,6 段结构一目了然:
各字段:
密钥的来源也清楚了:res/cocos/btn_jian.png / btn_close3.png 这俩图片里做了隐写,读出来按 "||" 拆,得到 appid ‖ HMAC_KEY ‖ RC4_KEY ‖ version 四元组。换 build / 换 appid 的时候,只要把这四元组换掉就行,这个 HMAC_KEY 在同一个 build 里跨会话是稳定的,不是热更下发的。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。







