这是一个 Windows 内核态卷过滤驱动,做的事情是:开启保护后,系统盘上任何写入都会被悄悄重定向到空闲扇区。重启之后,磁盘自动回到保护开启时的样子。 类似网吧/教室那种还原卡,只是纯软件实现,没有任何硬件介入。
核心机制叫"写时重定向"(copy-on-write redirection),关键的取巧之处是:$Bitmap 本身也被驱动重定向了,所以它在物理磁盘上永远是保护开启那一刻的快照——这意味着不用自己维护空闲扇区表,直接读 $Bitmap 就行。
没有第三方依赖,纯 WDK,Apache License 2.0。配套有一个 MFC 用户态管理程序 QHEngineUI,把 .sys 和 .inf 作为资源嵌入 exe,一键安装、勾选要保护的卷、开启/关闭保护。
本文记录设计取舍、几次大的方案推翻、写完后跑 CrystalDiskMark 才发现的真正瓶颈、以及一些我事后觉得有意思的小坑。
github开源链接:SysRestoreDriver(Apache License 2.0)
适用场景就那几样:网吧 / 教室 / 图书馆 / 展会样机、本地软件试用沙箱(装一堆软件、改注册表、删系统文件,重启即清)、给家里老人小孩的机器防误操作。
仅支持 NTFS。目前在 Win10 22H2 和 Win11 23H2 上实测通过,包括"正常写入后重启"、"异常断电模拟后重启"、"开关保护重启循环"三组场景。Win7 / Win8 / Win8.1 理论兼容,但没测。
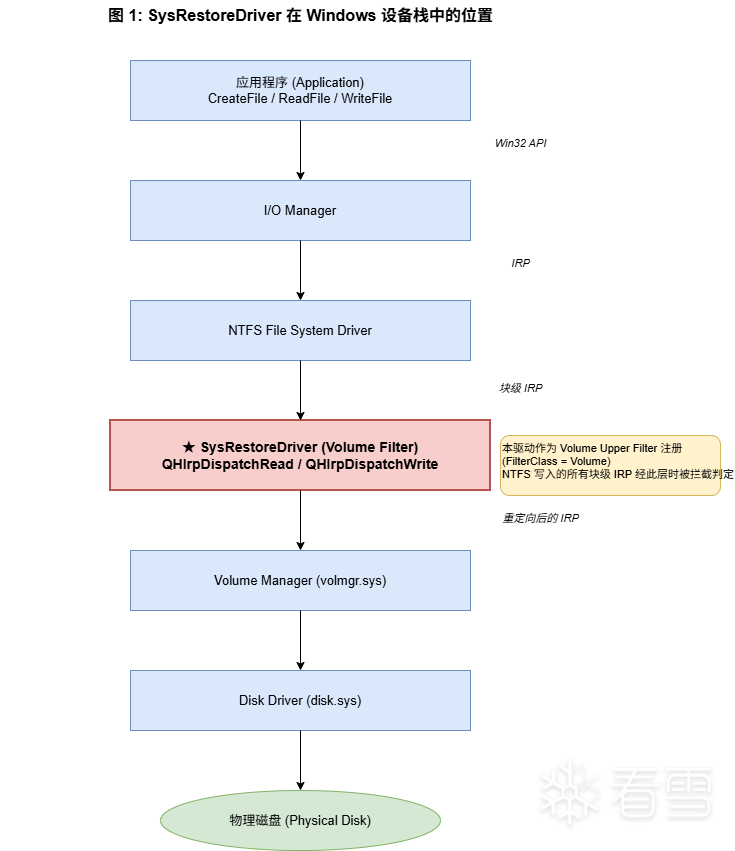
选择卷过滤而不是文件过滤(minifilter),原因很直接:minifilter 拦不到 NTFS 元数据的写入。$Bitmap、$MFT 这些元数据被 NTFS 内部更新时不会产生文件级 IRP,minifilter 完全无感。而卷过滤位于 NTFS 文件系统的下层,所有块级写入都要经过——这恰恰是还原驱动需要的"全覆盖"。
驱动注册为 Volume Upper Filter(FilterClass = Volume),系统挂载任何 NTFS 卷时,自动 attach 一个过滤设备上去。每个卷独立判断是否开启保护:根目录有 _qh_protect_state.data 且首字节 = 1 才激活,否则一律透传。
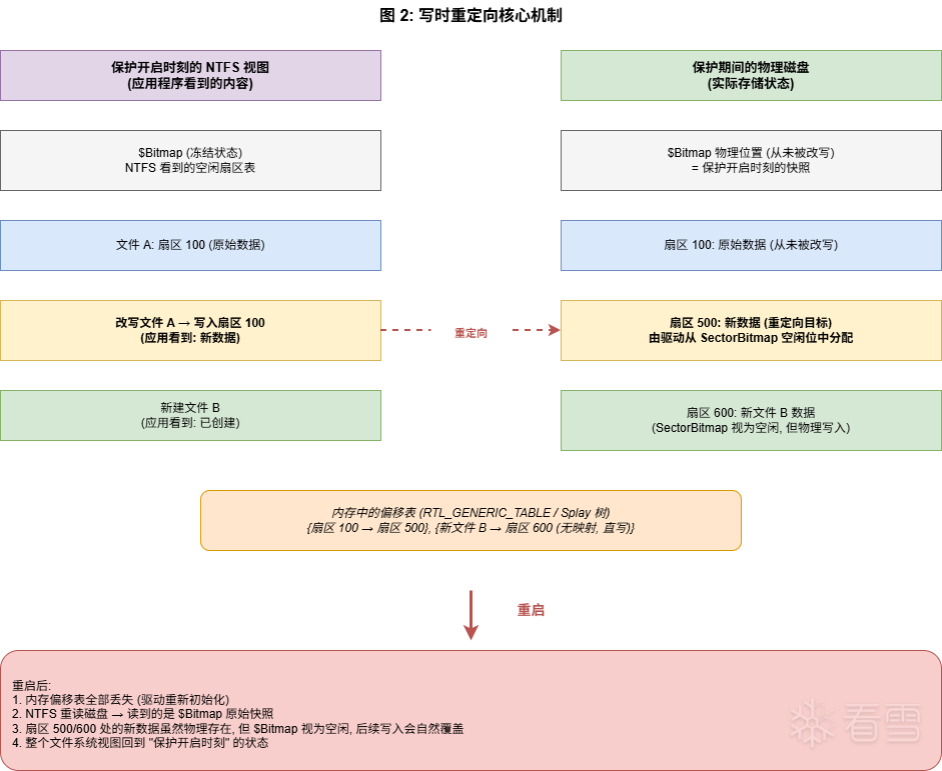
机制本身两句话能讲明白:
但真正让这套设计成立的,是第三件事:$Bitmap 自己也被驱动重定向。
这个观察看着不起眼,但它解决了所有难题。NTFS 看到的空闲扇区表(也就是 $Bitmap),从保护开启那一刻起就再也不会被真实改写——所有对它的写入都被重定向到别处了。所以物理磁盘上的 $Bitmap,就是保护开启时刻的快照。重启之后,驱动重新挂载、内存表全部丢失、NTFS 重新读盘——读到的就是那张快照,整个文件系统瞬间回到保护开启那一刻。
那些重定向期间被分配到的目标扇区(Y、W、…),数据虽然还物理存在于磁盘上,但 NTFS 的 $Bitmap 把它们标为空闲,后续写入会自然覆盖。无需任何"提交"或"清理"步骤。
这一节是整篇的重点。每个决策都讲:最初想法 → 演变过程 → 最终方案 → 变化原因。少数地方我花了不短的时间才想明白,过程值得记录。
最初的设想是:自己维护一张空闲扇区位图。200GB 的 C 盘按 512B 扇区算,约 4 亿位,需要 35MB 内存——这个量级勉强能接受。但如果是 2TB 卷呢?350MB。20TB 呢?3.5GB。内存条不够的用户立马蓝屏。
于是又退一步:把位图写到磁盘扇区里,需要时局部读取。但这立刻引出另一个问题——位图自己也是写操作的对象,每次更新位图都要触发新的 IRP,多次扇区读写会把性能打到地板上。
转折点是反向思考的一句话:既然 $Bitmap 也被我重定向了,它在磁盘上就永远是保护开启时刻的状态。那它本身就是一张天然的、不会被污染的空闲扇区位图——为什么要再自己造一张?
所以最终方案是:驱动启动时把 $Bitmap 的簇级位图从磁盘读出来,在内存里展开成扇区级 SectorBitmap。1TB 卷约 256MB,从 NonPagedPool 分配(IRP 派遣可能在 DISPATCH_LEVEL 触达,必须不可分页)。
这一步本质上是"借力打力"——NTFS 自己已经在维护一份高度优化的空闲扇区数据结构,去复用它,而不是再造一份。
SectorBitmap 用 Microsoft 公开的 RTL_BITMAP 系列 API 做了一层薄包装 QH_BITMAP。选 RTL_BITMAP 的几个理由:
(原始扇区 → 重定向目标扇区) 这张映射表的数据结构,最初执着于"必须 O(1) 查找的哈希表"——毕竟读写 IRP 路径上每个扇区都要查一次。
第一步尝试把 klib 的 khashl.h 移植到内核态。klib 是一套头文件唯一的轻量 C 库,理论上"应该"能移植,毕竟它不依赖 libc。我花了不少时间适配(替换内存分配、去除标准库依赖),跑起来后却频繁卡死——具体原因到最后也没完全定位,但稳定性问题在内核里是绝对的红线。
退而求其次,改用 RTL_GENERIC_TABLE——基于 Splay 树,O(log N) 查找。两个理由:
剥离 klib 还有个意外收益——许可证清洁度。klib 是 MIT,并不冲突,但少一个第三方依赖等于少一份审计成本。最终代码库零第三方依赖,纯 WDK。
未来计划在稳定之后自实现 per-bucket 锁的开链哈希表,但那是后话。
最初按簇做映射:原始簇 → 重定向簇。这是直觉上最自然的选择——NTFS 的最小分配单元就是簇,元数据全部是按簇组织的。
实际跑起来才意识到一个问题。NTFS 的簇默认 4KB(8 个 512B 扇区)。考虑一个簇里只有部分扇区被使用的场景——比如 _ _ * _ * * _ _(* 表示被使用,_ 表示空闲)。如果按簇重定向,写其中任一扇区都要:
每次小写入都多一次完整的簇读 IO。CDM 跑下来性能直接砍半,这是灾难性的。还原驱动的卖点本来就是"开了保护不会显著变慢",如果开了之后性能砍半,这个产品的使用价值就没了。
改成扇区级映射后,IRP 范围有多少扇区就操作多少扇区,精确匹配,无谓拷贝。代价是偏移表条目变多——按簇 1 条记录变成按扇区最多 8 条——但 Splay 树的 O(log N) 查找完全吃得消,内存增长也可控。
这是整个项目里我反复推翻自己最多的一个点。问题本身简单:驱动启动时怎么知道"上次有没有开启保护"? 但因为驱动会重定向所有写入,常规的"在某处存个标志位"全都行不通。
第一个直觉是注册表。用户态在 HKLM\SYSTEM\...\Services\SysRestoreDriver\ 下记一个值,驱动启动时读。
问题瞬间冒出来:用户在保护开启状态下关闭 D 盘保护,他对注册表的写入会被驱动重定向。也就是说,他把注册表里的"D 盘开启保护"删了,但这个删除操作实际写到了某个空闲扇区。重启之后,物理磁盘上的注册表 hive 文件根本没被改过——D 盘依然被认为是开启保护的。
试图绕过:能不能"暂停重定向",让那次注册表写入直通磁盘,然后恢复重定向?理论上可以,但要解决的问题一堆:
每一个都不是小工程。这条路放弃。
退而想:写第二个驱动,一个文件过滤系统(minifilter),它能感知文件级 IO。在用户态修改注册表时,minifilter 拦截到、计算这条注册表项落在哪个物理扇区、通过共享内存通知卷过滤驱动"这个扇区放行不要重定向"。
听起来不错,写起来全是雷:
而且核心矛盾没解决:这么复杂的机制,仅仅是为了存"开 / 关"这一个 bit。这就跟为了拧一颗螺丝去造一台机床一样。
又想:用户态软件安装时,在 NTFS 空闲簇里挑一个扇区,把那个扇区号写注册表。这个扇区由驱动直接读写,不经过文件系统。
问题更隐蔽,等想清楚已经晚了:NTFS 不知道这个扇区被驱动私自占用了。下次启动时,文件系统可能已经把这个扇区分配给某个文件、写了新数据,驱动按记录的扇区号去读,读到的是文件内容——保护状态判断完全错乱。
最后想通的方案,反而是最朴素的:在卷根目录创建一个固定大小的隐藏文件 _qh_protect_state.data,1MB 大小,首字节存 1/0 表示开 / 关。
关键设计:这个文件的所有物理扇区被驱动加入 ProtectRanges(直写放行扇区区间表),读写时直通真实磁盘,绕过重定向。
ProtectRanges 是一个 init 阶段一次性填充、之后只读的静态小数组(嵌入 DEVICE_EXTENSION,上限 8 段,实际仅占 3-4 段),IRP 路径上无锁线性扫描。它的填充流程:
由此达成的几个不变量:
完全不依赖注册表。
ProtectRanges 的机制不只用于状态文件。还有一个隐蔽的坑:NTFS 的 $Volume 元数据(MFT 记录 #3)维护着 dirty flag,干净关机时 NTFS 会清这个 flag。如果这个写入被重定向,物理磁盘上的 dirty bit 永远停在保护开启那一刻。几次重启后,Windows 累计判定"未干净关机",会触发 WinRE 修复模式。
解决方法很对称:把 MFT #3 主区与 $MFTMirr 的对应镜像两个扇区也加入 ProtectRanges。一共两段,再加状态文件的一两段,总数不超过 4 段,远在 8 段上限之内。
早期版本试过把 pagefile.sys / hiberfil.sys / bootstat.dat 也加入直写放行——理由直觉上很合理,这些都是系统关键文件,被拦截会带来麻烦。
测试时却没人察觉到一个关键问题:这些文件可能在保护期间被用户态动态扩缩容。pagefile.sys 尤其严重,Windows 在内存压力下会自动伸缩页面文件大小。新分配的扇区不在已快照的 ProtectRanges 里,写入会被驱动重定向 → 系统后续读 pagefile 时读到错位数据 → 蓝屏或更糟。
所以最后的规则很简单:ProtectRanges 只收录扇区位置在保护期间永远不变的实体。状态文件 1MB 固定不动,MFT 元数据物理位置由文件系统固定分配——这两类是安全的。其他系统文件一概不放,宁可它们走重定向。
最初的初始化点选在 IOCTL_VOLUME_ONLINE 控制码处理函数里——这个 IOCTL 是 mount manager 在卷上线时发的,听起来就是"卷已经上线,可以初始化了"。
实测下来发现一个严重问题:IOCTL_VOLUME_ONLINE 到达时,NTFS 不一定已经挂载完毕。状态文件需要通过 ZwCreateFile 打开 → 必须等 NTFS 就绪 → 此时打开会失败。
研究后改用 IoRegisterBootDriverReinitialization 注册的回调。这个回调由系统保证在所有 Boot 驱动加载完成后调用,意味着 NTFS 必然已经挂载——是文件操作的最早安全时机。
对于动态插拔介质(U 盘等),仍然走 IOCTL_VOLUME_ONLINE 路径执行初始化(因为它们不在 Boot 驱动列表里),但要等 BootReinitDone == 1 后才允许激活保护,防止系统盘还没初始化完就先启动 U 盘的保护。
写完核心机制后才意识到一个隐患。考虑这个场景:
理论上这是个 bug。最稳的解法是写一个 minifilter 拦截文件删除 IRP,拿到文件的 extent 表,发自定义 IOCTL 通知卷过滤驱动"这些扇区释放了,可以从偏移表里删掉"。
权衡之后当前版本不处理。理由:
这是已知限制,写在 README 里。如果未来真有用户反馈空间耗尽,我也不打算再补 minifilter了,到时候添加一个定时自检空闲剩余空间(检查$Bitmap),然后更新偏移表,让出空闲空间的工作项即可,但是需要注意的是这个工作项可能会有性能问题,因为它 遍历 + 删除 偏移表和空闲扇区记录表项,所以必须在被保护磁盘空间即将耗尽时调用。
注意 ProtectRanges 是静态嵌入而不是指针——它在 init 阶段一次性填充、之后只读,IRP 路径上的 QHIsSectorProtected 完全无锁,省掉一对 mutex 切换。
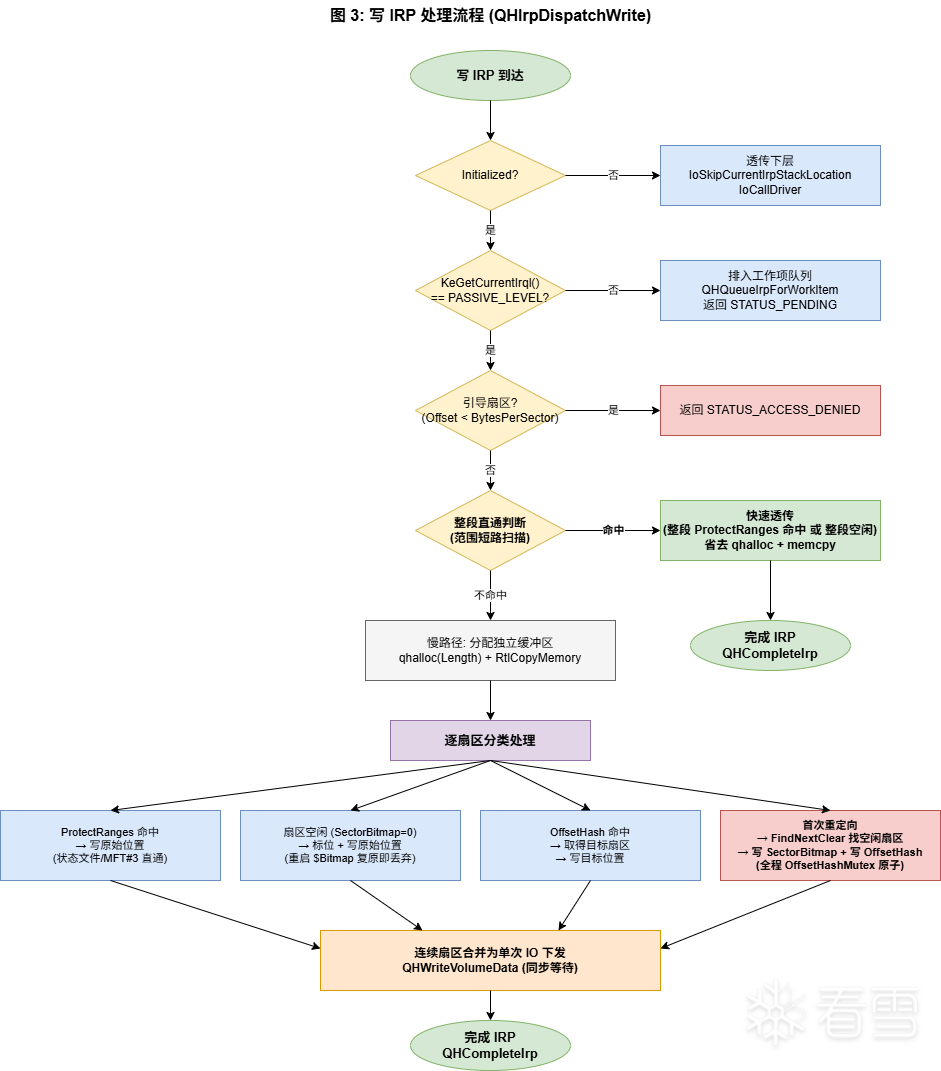
写路径是整个驱动里最复杂的部分。按流程图节点逐步讲解:
步骤 1-3:早期过滤
步骤 4:范围短路(fast-path)
这是一个性能关键的优化。绝大多数写 IRP 要么整段命中 ProtectRanges(状态文件 / MFT 元数据),要么整段落在空闲扇区上(新文件分配)。这两种情况都不需要重定向,直接透传就行。
慢路径每次进入要 qhalloc(Length) 分配一个 1MiB 的缓冲区 + RtlCopyMemory 拷贝用户数据——这两步开销很大。fast-path 用 RtlAreBitsClear 和 QHAreSectorsProtected 两次扫描判断整段是否符合条件,省掉这一大块开销。
实测净收益 +5% 写性能。听起来不多,但代码只有 30 行,风险也小,留下了。
步骤 5-6:慢路径分类处理
每个扇区分三种情况:
第 3 种情况的并发安全很关键。如果把"查 hash"和"分配 + 写 hash"拆到两段不同的锁里,两个并发写同一扇区的 IRP 会各自判定"未命中"、各自分一个新扇区、各自写 hash、后写的覆盖前写的——结果一份数据落在前一个扇区永久泄露,hash 表只指向后一个扇区,前一个 IRP 的数据永久丢失。
锁顺序约定:OffsetHashMutex 外,BitmapMutex 内。全代码库无反向嵌套,无死锁风险。
步骤 7:合并连续 IO
逐扇区生成的物理写入如果在磁盘上连续,合并成一次大 IO 下发。LastScanIndex 的提示策略让连续写拿到的重定向目标也是连续的,所以这一步通常能把 IO 数量降到接近 1。
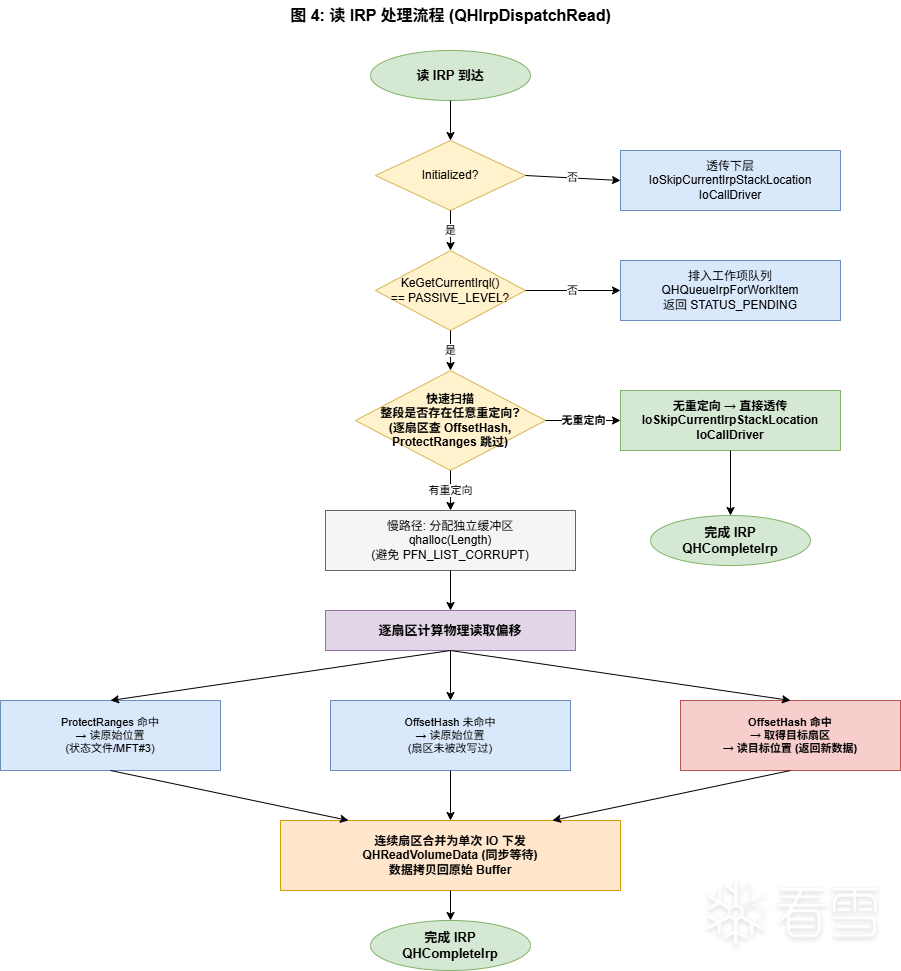
读路径比写路径简单一截:
与写路径的关键差异:
读路径有个 fast-path:快速扫描整段范围,只要有任一扇区没有重定向,就走慢路径。其实更严格地说,只有"整段无重定向"才能直接透传。但这个扫描本身要逐扇区查 OffsetHash,在 SEQ Q1 这种大块顺序读的场景下,1MiB / 4KiB = 256 个扇区每个都要查一次 Splay 树——这是读路径性能损失的主要来源(SEQ Q1 约 −41%)。
权衡之后还是保留了这个 fast-path,因为绝大多数顺序读都是无重定向的,不能让所有读都走慢路径分配独立缓冲区。
机制本身在第三节已经讲过,这里补一点细节性的观察。
重启之后会发生这几件事,按顺序:
那些重定向期间被分配出去的目标扇区,物理上仍然在磁盘上保留着数据。但因为 $Bitmap 把它们标为空闲,NTFS 后续的写入会自然覆盖它们。无需任何主动的"清理"或"提交"步骤——这正是 COW redirect 相比 COW copy 优雅的地方。
在 Win10 22H2 / NVMe SSD / 60GB 系统盘上用 CrystalDiskMark 8.0.4 实测(1 GiB × 5 轮):
几个观察:
没对比同类商业方案(Deep Freeze / PowerShadow 等)。这些厂商不公布基准数据,第三方独立评测也极少,没有可信参照。如果读者手头有可复现的对比数据,欢迎反馈。
这一节是写完核心功能后调优阶段的真实记录。试过的几条路里只有一条留下了,其他全撤了——记录一下,免得有同样想法的人重走一遍。
就是第六节讲的 fast-path。写 IRP 一进来先用 RtlAreBitsClear + QHAreSectorsProtected 看一眼整段是不是要么整段在 ProtectRanges 里,要么整段空闲。命中其一就直接透传,省掉 1MiB qhalloc + memcpy 和慢路径的逐扇区循环。
实测只有 +5%,比想象的少很多——大多数 CDM 测试场景下整段空闲的命中率其实不高(CDM 会先把测试文件预分配好,第二轮起所有扇区都已经被占用了,走的全是慢路径)。但代码简单、风险低、留下。
读路径范围短路:想法跟写路径对称——整段都没重定向就直接透传。结果 SEQ Q1 Read 反而退化 5–11%,没完全搞清楚原因,可能是 QHHashGet 大范围扫一遍比按需逐扇区还慢?读本来损失就只有几个百分点,不值得为这点不确定性引入修改,撤了。
慢路径锁合并:每个扇区原本要抢 3-4 次 mutex(BitmapMutex 测占用 → 释放 → OffsetHashMutex 查 hash → 释放 → ...),合并成一次大临界区。理论上应该有提升,结果 CDM 测下来完全没变化。FAST_MUTEX 在这台 NVMe 上太便宜了,锁切换根本不是瓶颈。徒增代码复杂度,撤。
异步 IO 流水线:这是花时间最多的一条。写了批次结构、完成例程、引用计数、槽位限流(MAX_INFLIGHT=16),目标是让一个写 IRP 里的多个段并发跑——理论上能把总延迟从 sum(每段) 压到 max(每段)。
实测 +5%。为啥这么少?因为 LastScanIndex 让连续写拿到的重定向目标也是连续的,IO 合并之后通常就剩 1 段,根本没东西可以并发。CDM 这种"预分配 + 反复重写同一段"的负载特别坑这个优化。
不是说这条路死了。"解压一堆小文件"这种天然多段的负载可能还有用,但要专门做稳定性测试才敢上,CDM 测不出来就先撤了。
CDM SEQ 写不能代表所有写负载。它的特点决定了控制流优化基本没用:1MiB 大块 → IO 合并几乎完美;文件预分配 + 5 轮重写 → 第二轮起全走慢路径;重定向目标连续 → 物理上还是顺序写。
真正的瓶颈不在控制流。剩下的延迟里大头是:
这两个不动,光优化锁和分支没意义。
防御性缓冲区不能动。试过去掉那个 qhalloc + RtlCopyMemory,直接把父 IRP 的 MDL 系统地址传给下层——蓝屏。这条路堵死了,别再试。
留给以后或者社区贡献者:
写这个驱动之前,我在用户态写了 10 年 C++。这是第一次写 Windows 内核驱动。
最大的反差感是:用户态写错了,崩溃个进程;内核态写错了,崩溃整台机器。第一个 bug 花了大半天定位——栈申请几个 WCHAR[2048],立刻蓝屏。后来才知道内核栈默认就 12KB,几个大数组就爆。
第二件让我吐血的事,是写完整个项目后才发现:Windows 有官方的驱动样例集合,挂在 b1dK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6E0K9h3y4J5L8%4y4G2k6Y4c8Q4x3V1k6i4K9h3&6V1L8%4N6K6i4K6u0V1k6s2u0A6N6X3g2J5i4K6u0V1M7$3q4E0M7r3I4W2M7#2!0q4x3#2)9^5x3q4)9^5x3W2!0q4y4W2)9&6y4#2!0m8z5g2!0q4y4#2)9&6c8W2!0m8y4g2!0q4z5g2)9^5x3g2)9&6x3#2!0q4y4W2)9&6b7#2)9^5z5g2!0q4z5q4!0n7c8W2)9&6z5g2!0q4y4q4!0n7z5q4!0m8b7g2!0q4c8W2!0n7b7#2)9^5b7#2!0q4z5q4)9^5y4#2!0n7x3#2!0q4y4g2!0n7x3q4)9&6x3g2!0q4z5q4)9^5x3#2!0n7c8q4!0q4y4g2!0n7x3q4)9&6x3g2!0q4y4#2!0n7b7W2)9&6y4g2!0q4y4q4!0n7z5q4)9^5x3q4!0q4y4g2!0m8y4q4!0m8y4#2!0q4y4g2)9&6b7#2)9^5z5q4!0q4x3#2)9^5x3q4)9^5x3R3`.`.
第三件是,整个开发过程没用 WinDbg——单纯因为不知道有这个工具。所有的内核态调试就是"出蓝屏 → 盯着代码看 → 查资料 → 改 → 再装一次"。一个 bug 平均要这样跑十几次。等项目写完才知道双机调试是怎么回事,多少有些哭笑不得。
[内核课程]《Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-6-11 06:39
被encoder编辑
,原因:






