偶然一阵醒意袭来,偶然进到论坛看到有两篇关于VMProtect的技术文章让我想起了多年以前我也曾花了一段时间研究过VMProtect还写了不少相关的代码,于是惊坐起翻起了许久未曾改过的相关代码仓库甚是感慨遂有了这篇文章
这篇文章不会有过于详细的技术分享但也并非标题党,文题中的”通解“就是指的对于VMProtect甚至一系列包括Themida在内的许多代码保护方案的通用解法,之所以打引号是以为所谓通用解法也只是指解题思路基本相同。
要寻求通解那么我们就需要先说下这类代码保护的基本思路和架构,这里我就简化:
VMProtect这种代码虚拟机是栈虚拟机(Themida的是堆虚拟机)其工作逻辑是在当前线程的栈当中找空间来储存代码执行的Context上下文,最主要的就是要储存被保护代码执行所需要的寄存器值,因此VMProtect的Context在最终代码执行的时候是和虚拟机代码本身的栈数据混搭穿插在栈中间的,由于VMProtect在代码保护的时候就要追踪栈空间的变动,因此Context的分布还是随机动态调整的,这进一步增加分析难度。
VMProtect的代码保护采取的是将原始代码汇编编译转换成一套自定义的opcode然后每个opcode有它的一个或者多个(代码可以不同但是逻辑功能必定相同)opcode的执行代码片段就是所谓的”handler”,这些handler在开发的时候需要针对opcode进行针对性设计,所以其变化演进相对很慢(这就是VMProtect这类代码虚拟机比较大的弱点),将代码转换成它自己的opcode序列以后,就形成了它自己的一套汇编代码,然后这段汇编代码还可以当成普通汇编那样处理,要么继续生成另外一套opcode套娃要么堆opcode进行等价替换变形插花(思路都是在代码量执行效率当中取个平衡),opcode编码完毕以后,就有一套对应的opcode处理代码,此时将ocpode的处理代码变形插花然后联合框架代码就形成了最的程序。
了解其思路以后,我们就可以来设计我们的“通解”思路了,我这里只给出一个针对实现理解代码和最终干预代码执行流程的”通解“,做到完整代码还原只给出大体思路。(注意:对于绕过反调试这种和代码保护无关的方法本文就不涉及了,尽管r3下也有通解,但是这些方法公开会很快被针对)
首先针对于比较简单的流程干预思路,主要有以下几个步骤:
拿到代码执行记录
简化代码
染色还原context偏移
匹配Hanlder特征,还原opcode伪代码执行记录
简化opcode
带opcode伪代码调试确定干预意图
接管代码执行进行干预
重编译opcode到汇编(实现代码还原)
下面分步骤介绍:
1.拿到代码执行记录
对于很多想学习VMProtect的来说,其实这一步并不顺畅,因为公开的工具太少,x64dbg自带的追踪又太慢,对VMProtect这种Handler代码越来越大越多的情况用更快的代码执行记录方法会节省很多时间,我个人首推JIT转译代码虚拟机,也就是我自己使用的方法,在虚拟机代码入口接管执行流程,然后将代码放到一个堆代码虚拟机中执行,这个虚拟机的opcode就是原始代码,hander就是转译后的代码本身,寄存器存放位置就是实际的寄存器位置以及一个小堆空间,用于存放虚拟机执行占用的1-2个寄存器),这种方法好处非常多,实现简单(不需要编写handler,不需要定义opcode),效率够高,支持sm代码自修该,由于是jit也支持动态条件干预(比如对于循环执行检测直接跳过重复代码记录)。
拿到代码记录以后我们就会有一份从代码进入虚拟机到执行完毕退出虚拟机的完整代码执行记录,类似:
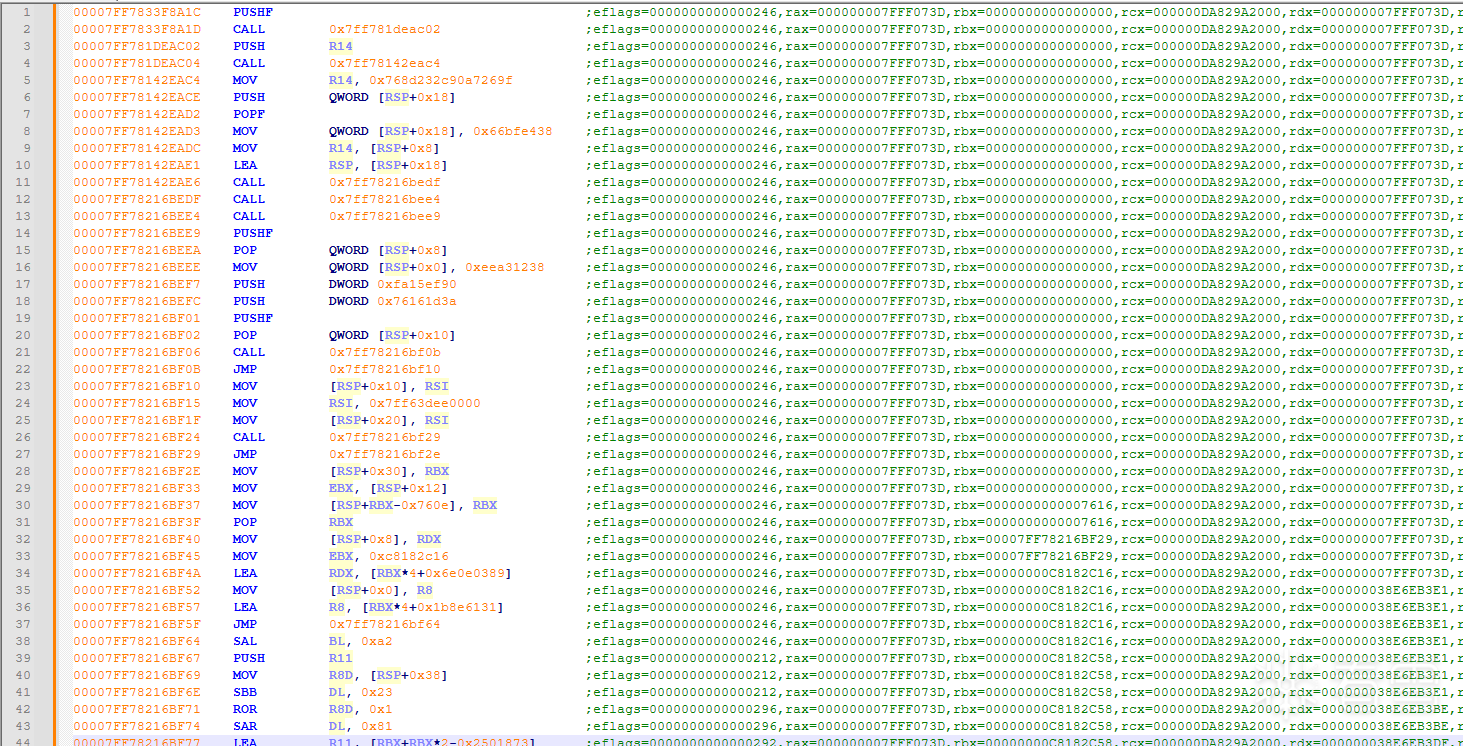
执行记录包括了常用寄存器,eflags值和代码地址以及具体执行的代码二进制数据(不少情况下,能拿到完整的代码执行记录就已经能够实现软件破解效果了,只需要控制入口数据比如用虚拟机快照功能跑出授权和未授权的代码执行记录,通过文本对比工具一眼就能看到具体判断逻辑处从而定位出准确的代码干预点,然后在这个点反转控制流就实现破解,根本无需分析一行汇编代码),有了这些数据就来到了第二步
1.简化代码
拿到代码执行记录以后,这个记录可能是海量的,超多的重复执行代码,而且是经过高度插花,混淆,变形替换的代码,直接分析是不可能分析的,打死都不能这样分析,因此我们要想办法简化代码,由于代码执行记录是自上而下的且带有寄存器值,因此有通用简化的办法,这里最核心的优化手段就是等价替换,没有什么复杂的技术,但是实现方法就各有各的办法了,我使用的方法是自己写了一个轻量的汇编匹配替换语言,大概长下面这个样子:
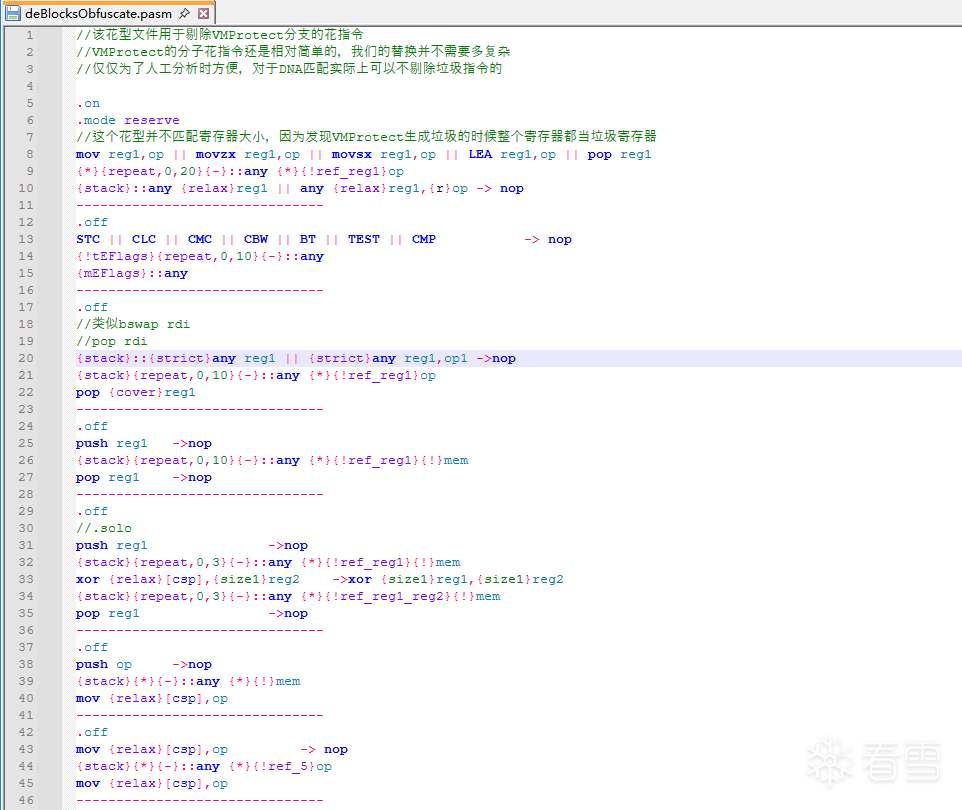
这里再贴点我当时写代码的一些用法注释,大概就能明白我的意思了:
有了通用的语义以后,我们就可以不断的积累各种等价替换花型,然后堆代码执行等价替换,无论VMProtect经过多少混淆,只要等价花型积累到一定数量,最终都能大大简化代码,况且我们这里简化代码的目的并非是要让代码能够清晰可读,而是只要简化到能够匹配出hander特征就够了,这样我们就能知道代码对应的hander是哪个,至于代码如何巧妙的执行的,我们其实并不关心,比如当代码简化到下面情况,就差不多了:
00007FF7825429E4 JMP R9
00007FF7826B37CD MOVZX EDI, BYTE [RBP-0x1]
00007FF7826B37D2 MOV R8D, 0x1703c7ae
00007FF7826B37D8 LEA RSI, [R8*4+0x652b39ae]
00007FF7826B37E0 XOR DIL, R11B
00007FF7826B37E3 LEA RAX, [RSI+RSI*4-0x12666cea]
00007FF7826B37EB XCHG RSI, RAX
00007FF7826B37ED ADD AX, 0x602
00007FF7826B37F1 ROR DIL, 0x1
00007FF7826B37F4 DEC DIL
00007FF7826B37F7 ADD RSI, 0xcbb2bb0e
00007FF7826B37FE LEA R8, [R8*4-0x13d9137e]
00007FF7826B3806 XOR DIL, 0x10
00007FF7826B380A BTS AX, AX
00007FF7826B380E MOV ECX, ESI
00007FF7826B3810 SBB DIL, 0x90
00007FF7826B3814 NOT R8B
00007FF7826B3817 BTS R8W, 0x18
00007FF7826B381D MOVZX R10D, AL
00007FF7826B3821 XOR R11B, DIL
00007FF7826B3824 ROR AL, CL
00007FF7826B3826 OR CX, CX
00007FF7826B3829 BSWAP R8
00007FF7826B382C ADC RDI, RSP
00007FF7826B382F DEC ECX
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-5-9 12:26
被SpringB编辑
,原因:




