首页
课程
问答
CTF
社区
招聘
峰会
发现
排行榜
知识库
工具下载
看雪20年
看雪商城
证书查询
登录
注册
首页
社区
课程
招聘
发现
问答
CTF
排行榜
知识库
工具下载
峰会
看雪商城
证书查询
社区
原创软件
发新帖
2
1
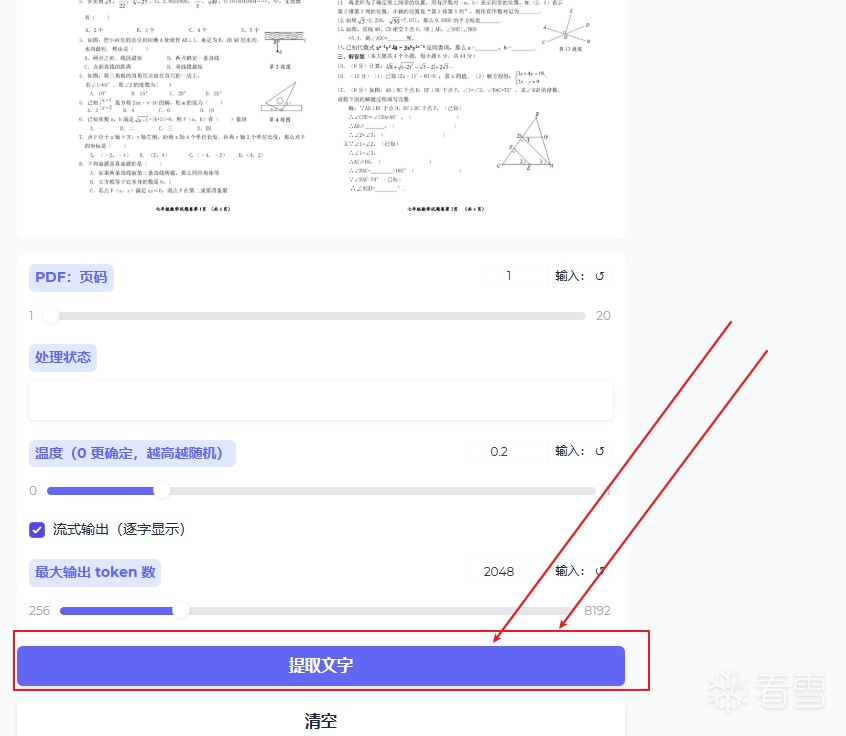
LightOnOCR-2-1B:图片 / PDF文字识别
发表于: 2026-4-28 17:36
1588
LightOnOCR-2-1B:图片 / PDF文字识别
mb_loxjvzen
2026-4-28 17:36
1588
软件功能
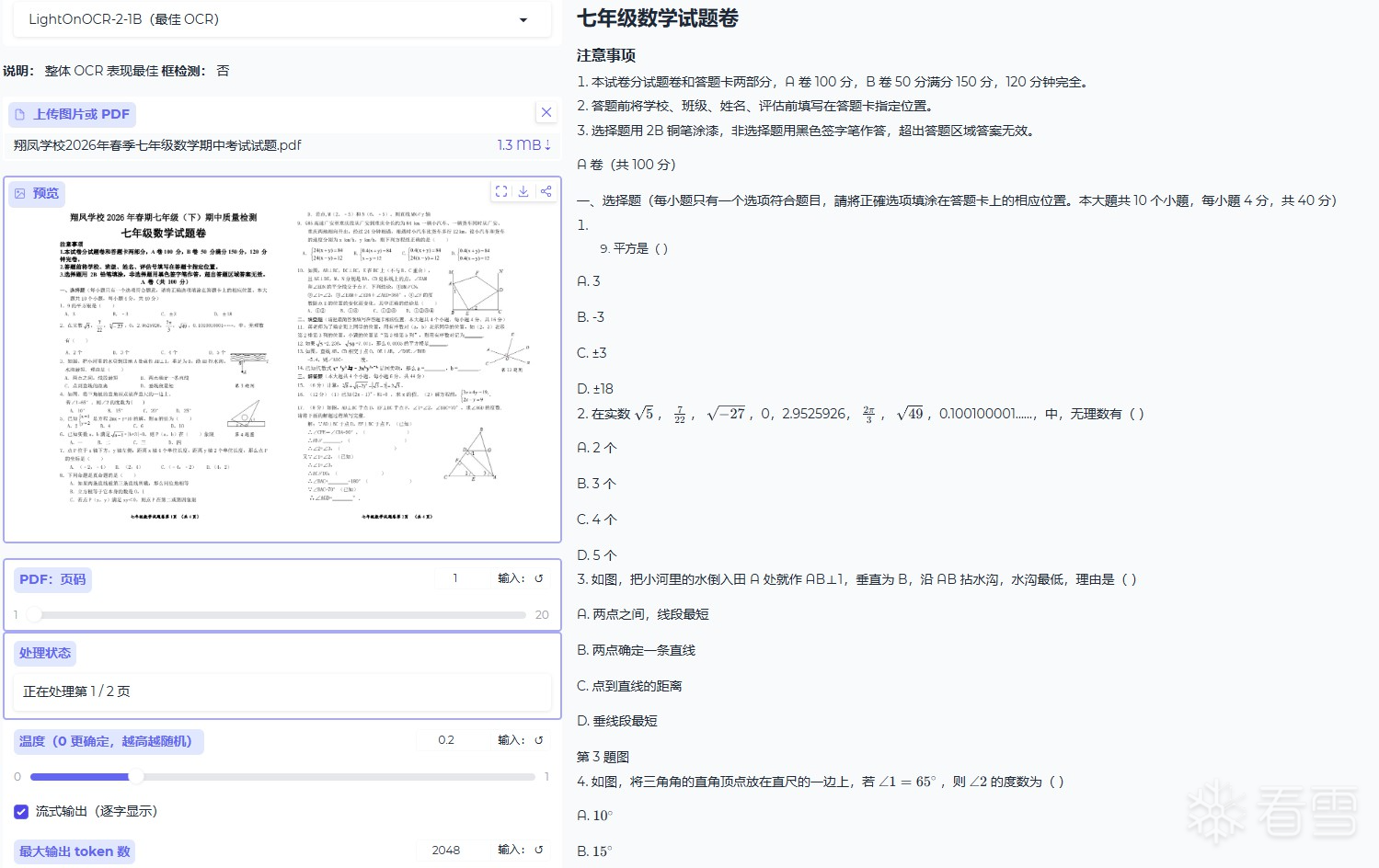
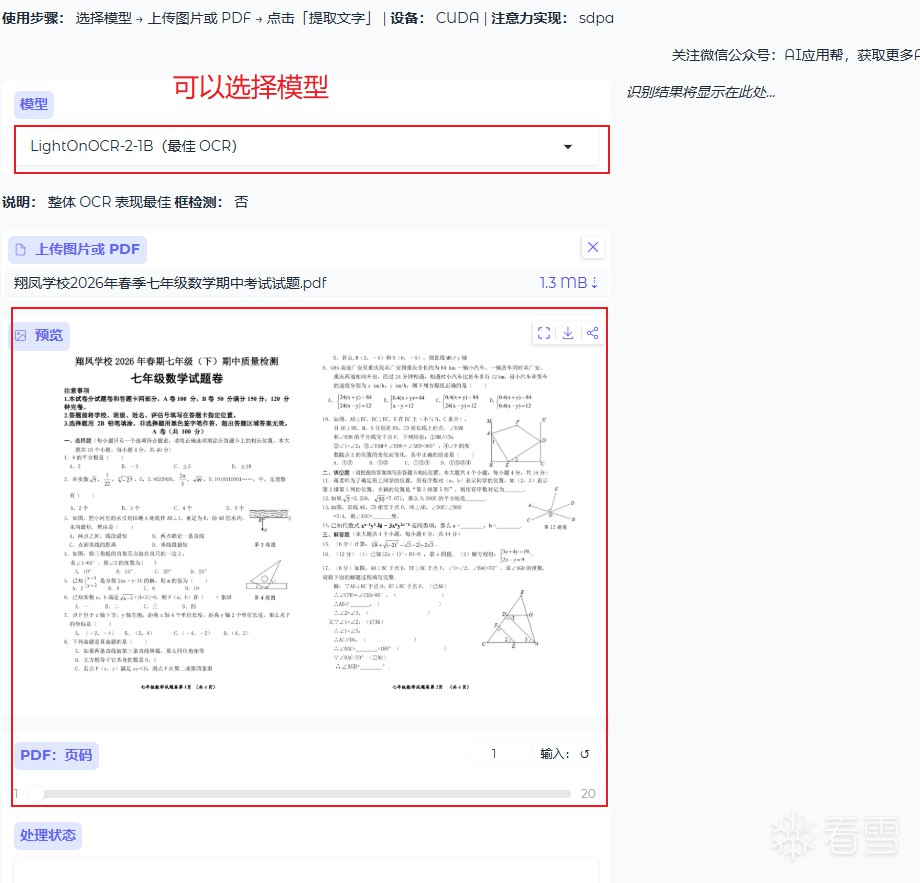
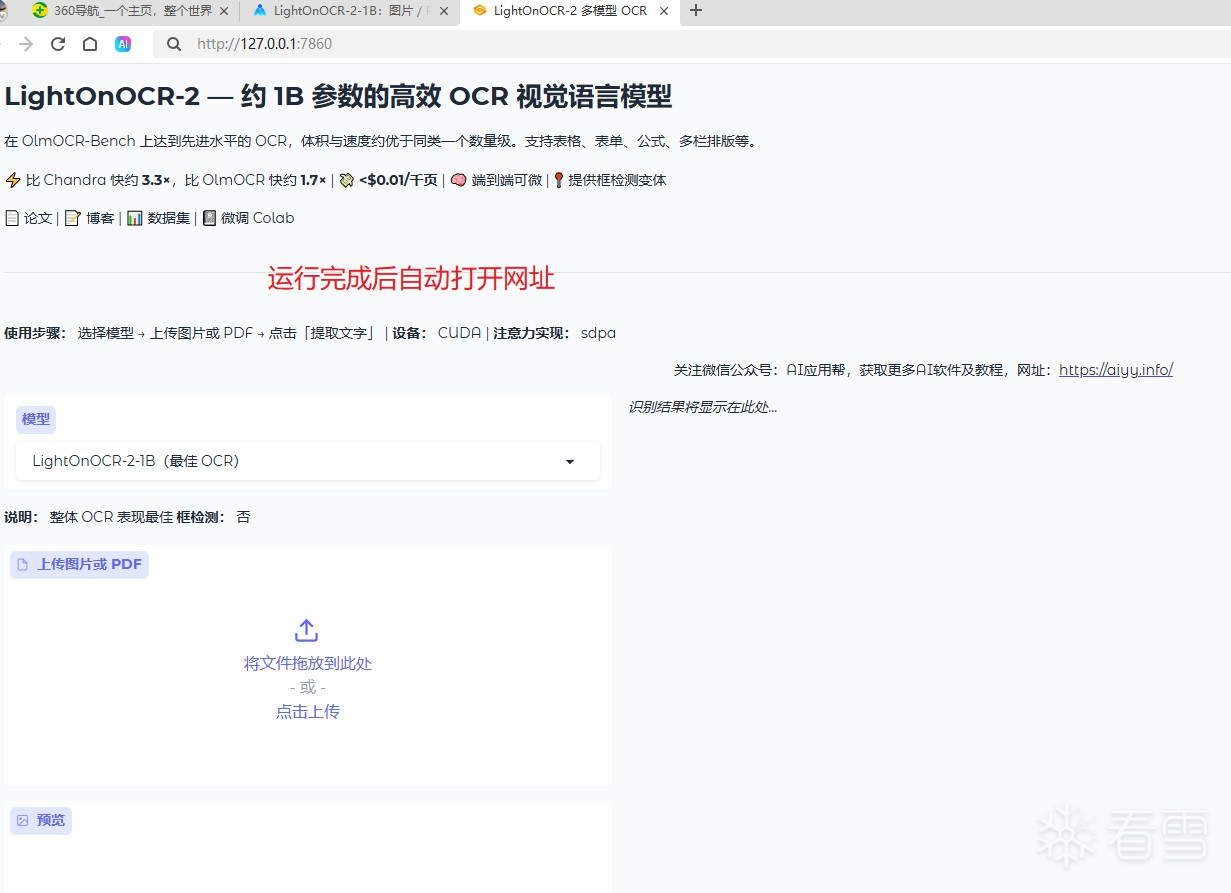
端到端高效识别:支持 PDF、扫描文件、图片等多种文档格式一键转换,自动生成语序连贯、整洁纯净的文本,摒弃传统多步骤 OCR 繁琐流程,操作更简洁。
识别精度出众:于 OlmOCR-Bench 测试基准中达到业界顶尖性能,针对法语文本、arXiv 学术论文、各类扫描文档的识别稳定性全面升级。
轻量高效低耗:模型仅 10 亿参数,整体体积约为同类工具的九分之一,推理速度大幅提升,有效降低显存、算力等硬件资源消耗。
专业公式解析:强化数学公式及 LaTeX 语法识别解析能力,输出格式标准规范,完美适配学术内容编辑、二次引用等需求。
排版精准还原:优化多栏布局、复杂版式适配能力,精准把控文本阅读顺序,搭配智能文本标准化处理,大幅减少人工二次修改工作量。
应用场景
文档数字化归档:批量处理纸质合同、档案资料、扫描文件,快速完成文字转化,方便资料检索、储存与内容复用。
学术论文整理:一键提取 PDF 论文正文、公式等核心内容,快速产出可编辑文本,助力科研笔记整理、文献引用与内容编辑。
企业轻量化部署:硬件适配门槛低,可低成本搭建企业文档识别服务,适配各类降本需求,助力办公流程自动化升级。
图文资料规整处理:智能规范化提取截图、图片内文字,适配文案翻译、内容总结、知识库录入等各类文字处理工作。
本地离线安全处理:全程本地运行、一键上传解析,无需云端传输数据,充分保障文件信息安全,满足隐私保密类使用需求。
冰与火的战歌:Windows内核攻防实战高级班!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
收藏
・
2
免费
・
1
打赏
分享
分享到微信
分享到QQ
分享到微博
赞赏记录
参与人
雪币
留言
时间
wx_晨梦
感谢你的贡献,论坛因你而更加精彩!
2026-7-16 12:00
查看更多
赞赏
×
1 雪花
5 雪花
10 雪花
20 雪花
50 雪花
80 雪花
100 雪花
150 雪花
200 雪花
支付方式:
微信支付
赞赏留言:
快捷留言
感谢分享~
精品文章~
原创内容~
精彩转帖~
助人为乐~
感谢分享~
最新回复
(
1
)
啊你好哇123
雪 币:
528
能力值:
( LV1,RANK:0 )
在线值:
发帖
0
回帖
319
粉丝
0
关注
私信
啊你好哇123
2
楼
这个怎么收费的
2026-5-5 15:48
0
游客
登录
|
注册
方可回帖
回帖
表情
雪币赚取及消费
高级回复
返回
mb_loxjvzen
7
发帖
10
回帖
0
RANK
关注
私信
他的文章
LightOnOCR-2-1B:图片 / PDF文字识别
1588
Excel批量处理大师v1.2
1247
word批量处理工具箱v2.2
1191
[分享]办公神器,OfficeAI助手 For WPS/Office v0.7.2.5
1851
驱动总裁 2.20.0.8 在线版 + 网卡版 + 离线标准版 + 离线精简版(封装专用)
2071
关于我们
联系我们
企业服务
看雪公众号
专注于PC、移动、智能设备安全研究及逆向工程的开发者社区
看原图
赞赏
×
雪币:
+
留言:
快捷留言
为你点赞!
返回
顶部