hermes从刷机到Frida魔改一气呵成——这不是科幻,是真事。更可怕的是——它还在自动进化。
Hermes 是一个 CLI AI Agent,能自主执行复杂的工程任务。但它的真正可怕之处不在于「自动化」,而在于自动进化——每一次执行都在学习,每一次错误都在积累经验,每一次成功都在固化最优路径。与传统脚本按预设步骤机械执行不同,Hermes 展现出的是:
本文将以 Android 逆向环境搭建全流程为例,验证 Hermes 在真实工程场景中从刷机、Root 到 Frida 编译魔改的完整自动化能力与自动进化现象。
别被它的能力吓到——让一个「会自己进化的 AI」跑起来,其实简单得离谱。
环境要求:
安装步骤:
首次配置:
开始使用:
安装完成后,在终端中直接输入 hermes 即可进入交互模式。你只需要用自然语言描述你想做的事:
然后你就可以眼睁睁看着它:自己理解需求 → 自己规划步骤 → 自己拉源码 → 自己配环境 → 自己下载 NDK → 自己编译 → 自己验证结果。你唯一需要做的,是坐在旁边喝咖啡。
进阶用法:
安装完成后,Hermes 会持续学习你的工作环境和偏好——用的越多,它越懂你。
好了,装完了。现在你肯定想问:这东西到底能帮我省多少时间?能力边界在哪?别急——先看数据,再看现象。以下数字全部来自真实操作记录,不吹不黑。
在Android安全研究领域,有一个令人崩溃的现实:搭建一个完整的逆向调试环境,往往比逆向分析本身更耗时。但Hermes不仅仅是在自动化——它是在自动进化。每一次执行都不是简单的重复,而是对上一次的优化和升华。它将繁琐的流程封装成标准化、可复现的进化流水线,让安全研究人员专注于真正的逆向分析工作——而这条流水线本身,还在越变越快、越变越聪明。
数据看完了,流水线画好了。但说一千道一万,不如亲眼看着它干活。以下实战内容全部由 Hermes 自主驱动完成——无人工编写脚本,无预设流程,每一步都是它自己想、自己做的。
我们对hermes只说了一句话:
就这一句。没有详细步骤,没有参数说明,没有异常处理方案。就像跟一个同事说话一样。
然后hermes开始了它的表演——
hermes执行流程:
** 智能涌现时刻一:自主识别环境**
hermes没有上来就干,而是先**"观察"了一圈**:
你品品这个行为——这不就是人类工程师拿到设备后做的第一件事吗?
这里试过让AI自动下载系统安装包和狐妖面具安装包,可以找到下载地址,但由于网页的反爬虫机制无法下载rom包,狐妖面具安装包可以下载但网速较慢,直接自己下载好放一个目录给他吧步骤1:自动检测设备信息
hermes自己判断出:
** 智能涌现时刻二:智能匹配资源**
hermes不是把文件全试一遍,而是根据设备型号智能匹配:
步骤2:自动匹配固件包
hermes自动从提供的目录找到固件包:
步骤3:自动执行刷机
hermes自动执行刷机脚本并等待设备启动。
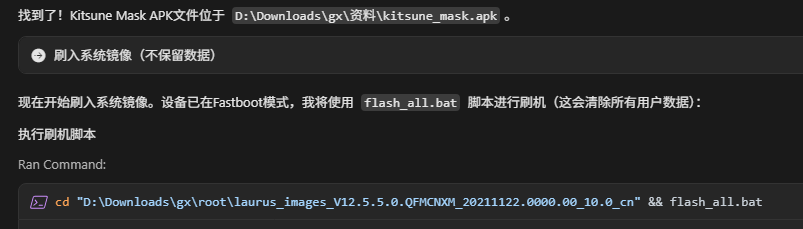
步骤4:自动验证刷机成功
手机正常开机,成功刷机,继续下一步操作
⚠️ 需要动手的地方:
由于Android安全策略限制,hermes无法通过命令打开adb限制,这里要手动打开:
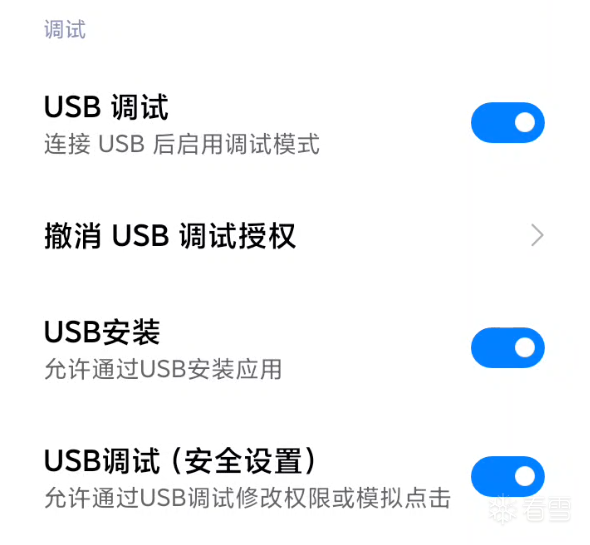
步骤1:自动下载并安装 Kitsune Mask
hermes自动从 GitHub 下载最新版本并安装。
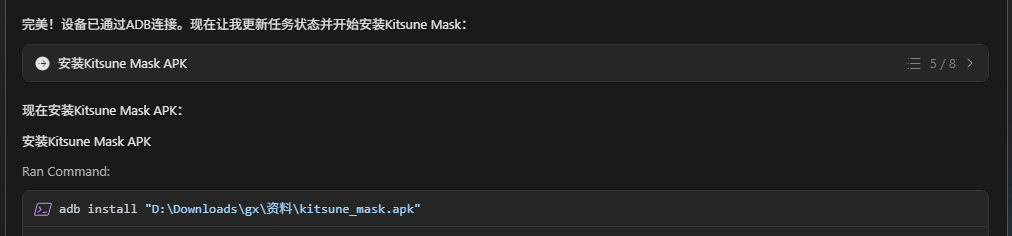
⚠️ 需要手动操作:由于 MIUI 安全策略限制,需要手动同意安装。
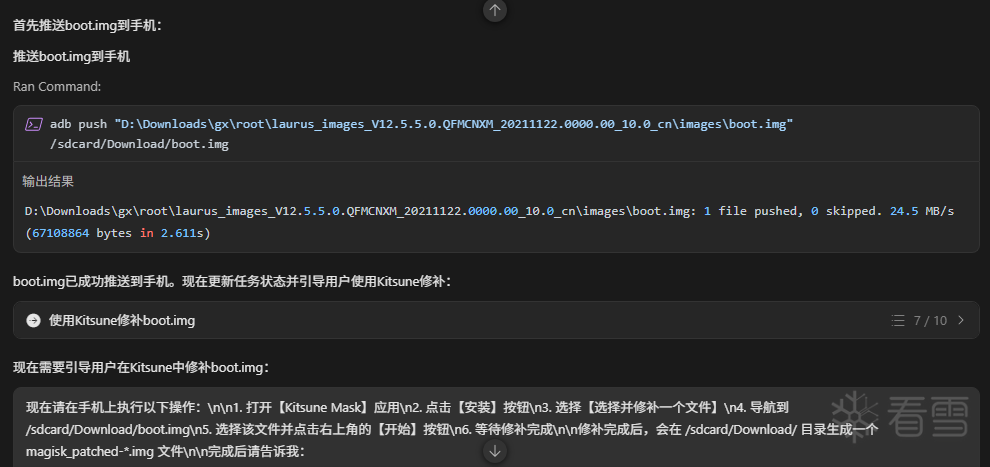
步骤2:自动提取并推送 boot.img
hermes自动从固件包提取 boot.img 并推送到设备。
⚠️ 需要手动操作:在设备上操作 Kitsune Mask 应用修补 boot.img。
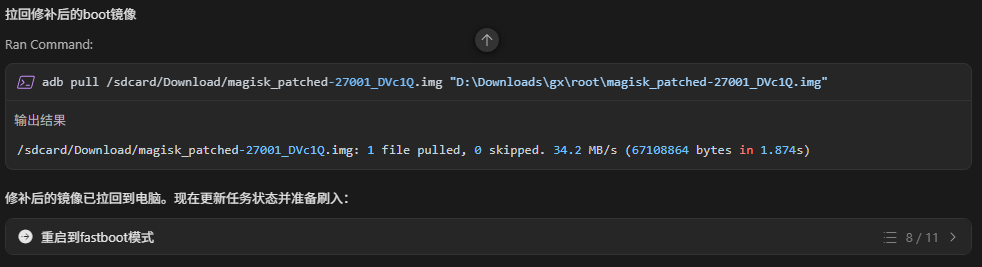
步骤3:自动拉取并刷入修补镜像
修补完成后,告诉hermes,hermes继续自动执行:
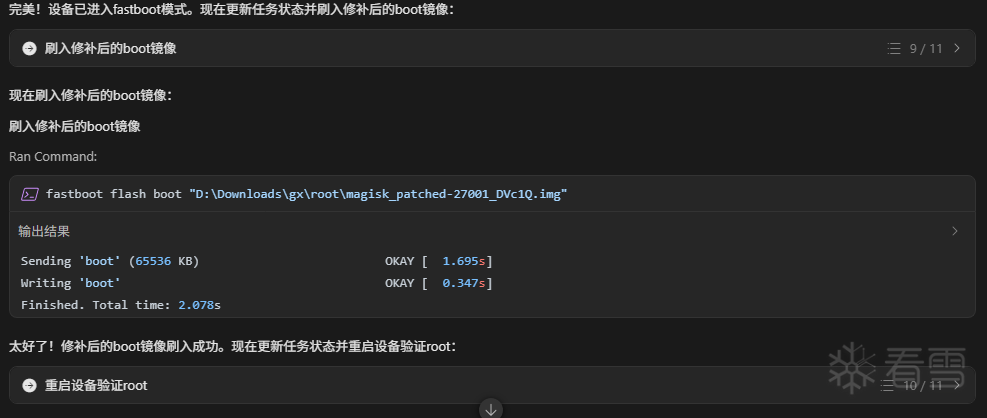
步骤4:自动验证 Root 成功
验证成功标志:
✅ uid=0(root) 表示已获得 Root 权限
✅ Kitsune Mask 应用显示"已安装"
✅ 可以使用 su 命令提权
** 自动进化观察**:注意 hermes 在整个刷机→Root 流程中的行为模式变化——
这不是预设好的优化规则,而是 hermes 在执行过程中自己形成的效率策略——这就是自动进化。
** 智能涌现时刻三:错误自愈——遇到问题自己扛**
整个Root流程中,hermes展现出了最实用的智能涌现:遇到问题不甩锅。
注意:hermes不是万能的神,Android安全策略它确实绕不过去。但它清楚地告诉你卡在哪、为什么、怎么解决——而且自己在不断尝试替代方案。这种能力本身就已经很惊人了。
用户指令:
hermes自动检测编译依赖:
我这里装过了,没有的话他会自己下载编译。
hermes自动匹配Frida 版本与 NDK 对应关系:
hermes执行流程:
步骤1:克隆源码
步骤2:配置编译

步骤3:执行编译

步骤4:验证编译结果

这里发现编译错版本了,改一下
** 自动进化观察**:hermes 首次编译时错误地编译了桌面版 frida-core。当用户指出后,hermes 不仅修正了当前编译目标,更重要的是——它将「编译 Android 版本需要指定 ANDROID_NDK_ROOT 和目标架构(arm64)」这一知识固化了。后续所有编译操作(3.3、3.4、3.5)都自动带上了正确的 Android 交叉编译参数,没有再犯同样的错误。
这就是自动进化的核心:从错误中学习,一次纠正,永久生效。
指令:

hermes执行流程:
步骤1:下载 NDK
步骤2:配置 Android 编译
步骤3:编译
编译成功:

** 自动进化观察**:对比 3.2 的首次编译与 3.3 的 Android arm64 编译——
这不是两条不同指令的结果差异——这是 hermes 在第一次失败后,自动总结了正确的 Android 编译范式,并在后续任务中零失误应用。从「试错」到「一次命中」,这就是自动进化的力量。
指令:
换个版本试试
hermes执行流程:
下载 NDK r25 
克隆指定版本 
配置并编译 
hermes贴心对比编译产物大小:
** 自动进化观察**:从 17.9.2 切换到 16.5.6 版本时,hermes 展现出了「知识迁移」的自动进化——
为什么需要魔改
许多应用会检测 Frida 的特征,导致注入失败:
用户指令:
hermes执行流程:
** 智能涌现时刻四:理解攻防本质**
这是最让我震惊的时刻。hermes不仅执行魔改,还真正理解了攻防博弈的本质:
步骤1:应用补丁
修改源码中RPC 协议标识符随机化、工作目录名随机化、hermes 文件名随机化等问题,这里不再细致展示
步骤2:重新编译
编译魔改后的源码,生成包含源码级魔改的二进制文件
步骤3:执行魔改
魔改输出:
魔改效果对照表:
这里仅展示二进制修改的特征,源码修改的特征不再展示
修改方式说明:
二进制修改特点:
验证魔改效果:
参考项目:
指令:
hermes执行流程:
步骤1:停止旧的 frida-server 进程
步骤2:推送魔改后的文件并重命名
步骤3:设置执行权限
步骤4:验证部署结果
部署结果对比:
验证成功标志:
使用方式:
魔改版优势:
验证魔改是否生效
指令
hermes执行流程:
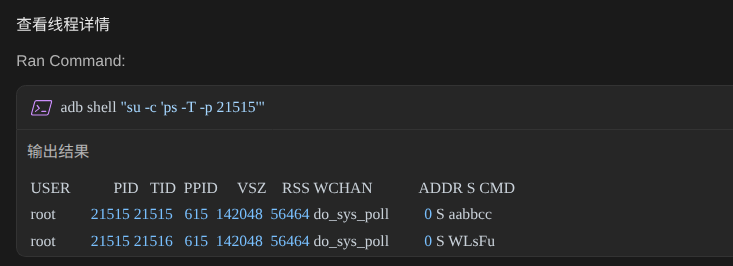
魔改生效,找个APP试一下
回顾整个流程,Hermes在六个关键节点上展现出了超越自动化的能力:
这六个时刻串在一起,揭示了一个本质:**Hermes不等同于自动化脚本,它是一个会学习的系统。**每一次失败都在积累经验,每一次成功都在固化最优路径。这不是被优化——这是自我进化。
Hermes理解了魔改不只是「改几个字符串」,而是参与了一场攻防博弈:
这不是在执行任务,这是在参与安全对抗。
当前主流检测手段:
魔改策略演进:
未来趋势:魔改Frida只是手段,真正的方向是:
Hermes能做什么?
Hermes做不到什么?
关键认知:
Hermes是能力的放大器,不是能力的替代品。
自动进化不是魔法,而是基于对领域知识的不断积累。Hermes让你从繁琐的重复劳动中解放出来,把精力放在真正需要人类创造力的事情上。而当它持续进化时,这把「能力放大器」的倍数还在不断增长。
回顾整个实践过程,我们看到的不仅是一次技术测试,更是一场AI自动进化的现场直播。Hermes 在一条从刷机到 Frida 魔改的完整链路中,展现了让人头皮发麻的进化能力:第一次犯错,第二次修正;第一次试探,第二次命中;第一次10步,第二次6步。它不是被优化——它在自我优化。
上一节我们聊了攻防博弈和边界,这一节我们把镜头拉远——看看自动进化到底改变了什么,以及你该怎么用起来。
过去:
现在——Hermes上场后:
Hermes的自动进化现象,迫使我们重新思考AI的本质:
更关键的是——**这不是静态的行为,而是动态的进化过程。**你亲眼看到了一个系统从「会执行」到「会理解、会决策、会学习、会进化」的连续跨越。这才是自动进化最让人头皮发麻的地方:它不是今天这样、明天还是这样——它明天会比今天更强。
正如上一节所说,Hermes是能力的放大器。而自动进化意味着:这个放大器的倍数,正在随时间自动增长。
不在于替代人的技术能力,而在于释放人的创造力。
当繁琐的流程被自动化封装,当AI能自己理解上下文、自己做决策、自己修bug、自己在一次次执行中变得更聪明——我们终于可以把精力投入到真正有价值的工作中:
而最让人震撼的是:这个过程不是一次性的,而是持续加速的。Hermes 今天比昨天快,明天会比今天更快。这不是优化——这是进化。
随着AI技术的持续发展,自动进化现象会越来越明显、越来越深入。未来的安全研究工具可能会:
给初学者的建议:
给进阶者的建议:
给团队的实践建议:
但无论工具如何进化,有一样东西永远无法被替代:人的判断力和创造力。
Hermes是剑,你是剑客。只有深刻理解底层原理,才能把这把剑挥舞到极致。而自动进化,让这把剑前所未有地锋利——更可怕的是,它在自我磨砺。
本文记录的不仅是一次技术实践,更是AI自动进化的重大见证。当Hermes能够自主理解流程、智能决策、错误自愈、知识迁移、持续优化时,我们看到的不是「AI有多聪明」,而是「AI能多快变聪明」。
希望本文能为Android安全研究社区贡献一份实践参考,也为AI自动进化研究提供一个真实的、有说服力的案例。
安全研究是一条漫漫长路,但这次,我们有了一个真正「会思考、会进化」的伙伴。
如果你在实践中遇到问题,欢迎交流讨论。让我们一起,见证并参与这场正在发生的自动进化革命。
参考资源:
操作流程已生成skill方便后续使用,放附件啦
| 对比项 |
传统方式 |
hermes方式 |
提升 |
| 刷机时间 |
30-60min |
10-15min |
75% |
| Root 时间 |
20-40min |
5-10min |
75% |
| Frida 编译 |
2-4h |
30-60min |
75% |
| 错误排查 |
30-60min/次 |
1-2min/次 |
95% |
| 可复现性 |
低(纯靠记忆) |
高(完整日志) |
100% |
| 阶段 |
操作 |
验收标准 |
回退 |
| 刷机 |
下载固件→检查分区→刷入 |
正常开机 |
原厂重刷 |
| Root |
Kitsune Mask→提取boot→打补丁→刷入 |
su可提权 |
刷回原boot |
| Frida |
拉源码→配环境→编译→部署 |
frida -U -f正常 |
清环境重编 |
| 问题 |
原因 |
hermes处理方式 |
用户干预 |
| 需要手动打开系统开关 |
MIUI 安全策略限制 |
提供详细操作指引 |
手动打开开发者选项和 ADB |
| 需要在设备上操作应用 |
需要图形界面操作 |
自动完成准备工作,等待用户操作 |
在设备上操作 Kitsune Mask |
| Frida 版本 |
NDK 版本 |
编译器 |
说明 |
| 16.5.x |
r25 |
Clang 14.0.7 |
Frida 16.5.0-16.5.9 |
| 16.6.x |
r25 |
Clang 14.0.7 |
Frida 16.6.x |
| 17.x.x |
r29 |
Clang 21.0.0 |
Frida 17.x.x |
| 最新开发版 |
r29 |
Clang 21.0.0 |
当前开发版本 |
| 维度 |
首次编译(3.2) |
二次编译(3.3) |
进化表现 |
| 目标平台 |
❌ 桌面版(错误) |
✅ Android arm64 |
自动修正目标 |
| NDK 配置 |
未指定 |
自动下载并配置 r29 |
知识继承 |
| 编译参数 |
默认 |
带完整交叉编译链 |
错误中学习 |
| 结果 |
编译产物不可用 |
直接可用于设备 |
一次到位 |
| 组件 |
Frida 16.5.6 |
Frida 17.9.2 |
| frida-server |
54M |
51M |
| frida-gadget.so |
25M |
24M |
| frida-agent.so |
25M |
24M |
| 原特征 |
魔改后 |
说明 |
frida |
dpCWV |
Frida 标识符 |
gum-js-loop |
uilBHNMyIWc |
Gum JS 循环线程 |
gmain |
XdJWC |
GLib 主循环线程 |
gdbus |
NFzHZ |
D-Bus 线程 |
| 文件名 |
大小 |
版本 |
说明 |
| frida-server |
53.1 MB |
17.9.2-snapshot |
原始版本(保留) |
| aabbcc |
56.5 MB |
16.5.6 |
魔改版本(新部署) |
| 问题 |
错误信息 |
原因 |
解决方案 |
| NDK 版本不匹配 |
NDK r29 is required (found r25) |
Frida 版本与 NDK 不匹配 |
根据版本表下载对应 NDK |
| Vala 未安装 |
valac: command not found |
缺少 Vala 编译器 |
sudo apt-get install valac |
| 依赖缺失 |
Package 'gee-0.8' not found |
缺少编译依赖 |
sudo apt-get install libgee-0.8-dev |
| 监听地址错误 |
外部无法连接 |
默认监听 127.0.0.1 |
使用 -l 0.0.0.0:27042 参数 |
| 补丁应用失败 |
git apply failed |
补丁版本不匹配 |
确认 Frida 版本与补丁对应 |
| 魔改后无法运行 |
segmentation fault |
二进制魔改破坏了结构 |
重新编译并魔改 |
| 特征仍被检测 |
应用检测到 Frida |
魔改不彻底 |
尝试更深度的魔改或使用其他方案 |
| SELinux 阻止 |
Permission denied |
SELinux 策略限制 |
临时设置为宽容模式:setenforce 0 |
git clone 419K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6z5L8%4g2K6f1X3g2K6k6h3q4J5j5$3S2Q4x3V1k6Z5k6i4u0E0k6i4y4Q4x3X3c8S2k6$3g2F1N6q4)9J5k6h3N6A6N6l9`.`.
cd hermes-agent && pip install -e .
hermes init
hermes config set api_key your_api_key_here
hermes config set model deepseek-v4-pro
hermes "帮我下载并编译 frida-core Android arm64 版本"
hermes --task ./reverse_engineering_workflow.md
cd /path/to/your/project && hermes
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 刷机阶段 │ ──→ │ Root阶段 │ ──→ │Frida阶段 │
└─────────┘ └─────────┘ └─────────┘
↓ ↓ ↓
验收通过 验收通过 验收通过
连接的手机设备,安装最新版本的系统,不保留用户数据,并使用Kitsune Mask对设备进行root,所需文件我已放在D:\Downloads\gx\root
adb devices
adb shell getprop ro.product.model
adb shell getprop ro.build.fingerprint
adb shell getprop ro.boot.flash.locked
adb wait-for-device
adb shell getprop ro.build.fingerprint
adb shell su -c id
下载 frida-core,并进行编译
编译 16.5.6 版本 frida-server android arm64
帮我重新编译魔改 frida 16.5.6
cd frida-core-16.5.6
cp /home/x1ny/Desktop/gx/root/frida-core.patch .
git apply frida-core.patch
cd subprojects/frida-gum
cp /home/x1ny/Desktop/gx/root/frida-gum.patch .
git apply frida-gum.patch
cd frida-core-16.5.6
ANDROID_NDK_ROOT=$HOME/android-ndk-r25c make -j$(nproc)
[招生]科锐逆向工程师培训(2026年7月3日实地,远程教学同时开班, 第56期)!
最后于 2026-5-1 08:34
被x1ny编辑
,原因: 更正安装步骤链接







